永远的Hello World,永远的a + b
- Nigdle
- 发布于 2024-03-23 13:05
- 阅读 1943
永远的Hello World,永远的a + b
一:Fork the sui project
- 点击 $\mathit{GitHub}$ 进入 $\mathit {Sui}$ 存储库。
- 找到 $\mathit {Fork}$,将该库分叉存储到你自己的账号下。
- 来到你自己的分叉,找到绿色的 $\mathit {Code}$ 按钮,复制其中的 $\mathit {HTTPS}$ 地址。
- 切换到你的终端命令行,
cd进入你想要存放代码的位置,通过git clone <https url>的方式,将其拉取到本地;或者直接在 $\mathit {VsCode}$ 的欢迎页,选择克隆 $\mathit {Git}$ 仓库...,在绑定账号后即可一键拉取。 - 如果你是通过
git clone的方式,那么在拉取结束后,通过cd sui即可进入对应文件夹,也可以通过 $\mathit {VsCode}$ 打开对应的文件夹进行开发;如果你是直接通过 $\mathit {VsCode}$ 克隆的库,那么此时就已经进入了对应的位置,可以进行后续操作。
二:永远的 Hello World
不管你是用上述哪种方式将代码拉取到本地,现在你都已经在 $\mathit {VsCode}$ 中来到了对应的文件夹,我们在这里来创建属于我们的第一个程序:sui move new my_first_package,这行命令将创建一个名为 $\mathit {my_first_package}$ 的空包。
进入新创建的文件夹,在其中可以发现一个名为 $\mathit {sources}$ 的文件夹,和一个名为 $\mathit {Move.toml}$ 的代码文件,后者是一个清单文件,主要用来定义一些依赖项、地址名的映射等功能,等以后实际用到了再详细进行解释,现在,我们只需要将目光放到前者,所编写的代码我们都需要放到这里面(除一些特殊的,比如测试代码以外)。
通过 touch my_first_package/sources/my_module.move 可以创建我们的第一个名为的 $\mathit {my_module.move}$ 的代码文件,将其打开并编写我们的 $\mathit {Hello World}$。
module my_first_package::my_module {
use std::debug;
use std::string;
public fun hello_world() {
debug::print(&string::utf8(b"Hello World"));
}
#[test]
fun hello_world_text() {
hello_world();
}
}module <address>::<module_name> 是每一份代码文件的开始,由于在 $\mathit {Move.toml}$ 当中赋予了 $\mathit {my_first_package}$ 一个地址,所以这里可以直接用其替代以提高可读性,$\mathit {module_name}$ 一般与文件同名,这样有利于其它文件导入该份代码后的调用。
第二、三行是通过 $\mathit {use}$ 关键词将标准库中的部分内容($\mathit {debug、string}$)导入到该份代码,如果想要调用自己写的其它代码,也是类似的格式:use <address>::module_name,如果还想要更精细化到具体函数,那么只需要在后面再跟两个冒号以及具体的函数名即可。<br>当然,可能会存在导入模块同名的情况,不用担心,$\mathit {move}$ 提供了 $\mathit {as}$ 关键词,例如 use std::string as S,就可以用 $\mathit S$ 来代替 $\mathit {string}$,这样就解决了可能会同名的问题。
第五、六、七行是一个公共的(谁都可以调用的)的函数,这个函数很简单,调用 $\mathit {debug}$ 模块下的 $\mathit {print}$ 函数,将 $\mathit {Hello World}$ 通过 $\mathit {string}$ 模块下的 $\mathit {utf} \text {8}$ 函数转化成字符串后打印输出,这里需要加上引用&,因为 $\mathit {print}$ 函数接收的参数就是引用类型的。
至此,如果将程序发布上链再进行调用,是可以得到 $\mathit {debug}$ 的打印输出的,但是如果想要在本地环境测试的话呢?那就要用到第九行的#[test]。<br>这一行定义表明了接下去编撰的 $\mathit {hello_world_text}$ 函数只在测试时执行,而这个测试函数的内容也很简单,就是单纯地调用 $\mathit {hello_world}$。
sui move build进行构建,再通过sui move test进行测试,可以得到如下结果。<br>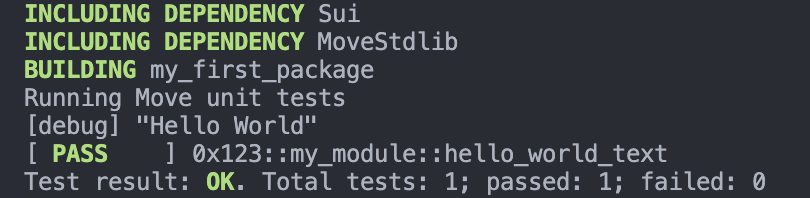 <br>其中,[$\mathit {debug}$] 后的内容就是我们输出的 $\mathit {Hello World}$。
<br>其中,[$\mathit {debug}$] 后的内容就是我们输出的 $\mathit {Hello World}$。
三:永远的 a + b
在通过测试的情形下完成的 $\mathit {Hello World}$,是不是跟大多数人心中的预期不符?尤其是跟一些已经学过的开发语言相比,这段代码显得非常臃肿?而且,虽然用 #[$\mathit {test}$] 的方式让测试函数只在测试时运行,可一旦代码量大起来,测试逻辑复杂,通篇不就更加冗杂了?<br>因此,我们用另一个例子,也就是 $\mathit a + \mathit b$ 来演示如何将测试用代码分离开,还大家一个干净整洁的编码环境。
根据之前的学习,我们已经知道了,$\mathit {sources}$ 文件夹下主要是放我们自己开发的功能模块的,那么测试代码呢?同理,只需要在与 $\mathit {sources}$ 同级别目录下创建一个 $\mathit {tests}$ 文件夹即可。<br>对应一个模块的测试代码,一般用 $\mathit {module_name_tests}$ 来命名。<br>
我们来更改 $\mathit {my_module.move}$,删除其中的原有代码,编写一个函数来执行 $\mathit a + \mathit b$:
module my_first_package::my_module {
public fun add(a: u64, b: u64): u64 {
a + b
}
}a: u64表示这个函数的第一个参数,需要传入一个u64类型的值,以a来命名。<br>函数后的: u64表示这个函数返回一个类型为u64的值。<br>a + b没有加分号,这不是错误,因为在 $\mathit {move}$ 语言当中,一个有返回值的块当中的最后一句不加分号的语句的结果,就相当于是其返回值,效果等同于return a + b;注意此时就必须加分号了。
接着我们把目光放到测试文件上,虽然将其独立了出来,但是还是需要用 #[$\mathit {test_only}$] 来注明这是测试时才载入的模块,用 #[$\mathit {test}$] 来注明这是测试时自动调用的函数。<br>测试模块开头的定义规则是类似的,都是module <address>::module_name,最后的模块名一般都是对应测试的功能模块的名称后加 $\mathit {_tests}$。<br>在这里,我们需要调用 $\mathit {my_module}$ 模块当中的函数 $\mathit {add}$,因此我们需要先将其导入,导入规则在之前有过解释,与导入标准库等其它功能模块类似。<br>在test_add函数当中,我们用到了assert,它需要传入两个参数,第一个参数是一个布尔类型的值,第二个参数是错误代码。<br>在这里,第一个参数用来传入我们通过add得到的结果与期望结果之间的相等判断,第二个参数暂时用 $\text 0$ 来传入,实际开发过程中请以具体情况来。
#[test_only]
module my_first_package::my_module_tests {
use my_first_package::my_module;
#[test]
fun test_add() {
assert!(my_module::add(1, 2) == 3, 0);
}
}此时,我们再来sui move test,我们可以得到一个充满生机的绿色 $\mathit {PASS}$。<br>如果想要尝试测试错误,只需要将上述测试代码上的期望结果另外填一个数即可,这个时候运行测试,会得到对应的报错信息。在实际开发过程中,就可以通过报错信息进行定位,快速找到问题所在。
四:加入组织,共同进步!
- Sui 中文开发群(TG)
- $\mathit{Move}$ 语言学习交流群: 79489587





