EVM深度分析之数据存储
以太坊虚拟机EVM的作用是将智能合约代码翻译成可以在以太坊上执行的机器码,并且提供一个沙盒运行环境,在运行期间不能访问宿主机的网络,文件,系统,即使不同的合约之间也有有限的访问权限。
以太坊虚拟机EVM的作用是将智能合约代码翻译成可以在以太坊上执行的机器码,并且提供一个沙盒运行环境,在运行期间不能访问宿主机的网络,文件,系统,即使不同的合约之间也有有限的访问权限。
EVM的特点
官方给出的EVM主要的设计目标如下:
- 简单性,操作码尽可能少且低级,数据类型尽可能少,虚拟机的结构尽可能简单。
- 确定性,EVM的语句没有产生歧义的空间,结果在不同机器上的执行结果是确定一致的。
- 节约空间,EVM的组件尽可能紧凑。
- 区块链定制化的,必须可以处理20bytes的账户地址,自定义32bytes密码学算法等等。
- 简单、安全模型,Gas的计价模型应该是简单易行准确的。
- 便于优化,以便即时编译(JIT)和VM的性能优化。
EVM基本信息
以太坊是一种基于栈的虚拟机,基于栈的虚拟机数据的存取为先进后出(也即后进先出),在后面介绍EVM指令的时候会看到这个特性。同时基于栈的虚拟机实现简单,移植性也不错,这也是以太坊选择基于栈的虚拟机的原因。

EVM采用了32字节(256bit)的字长,最多可以容纳2014个字,字为最小的操作单位。
EVM数据管理
接下来看一下EVM的数据是如何管理的。
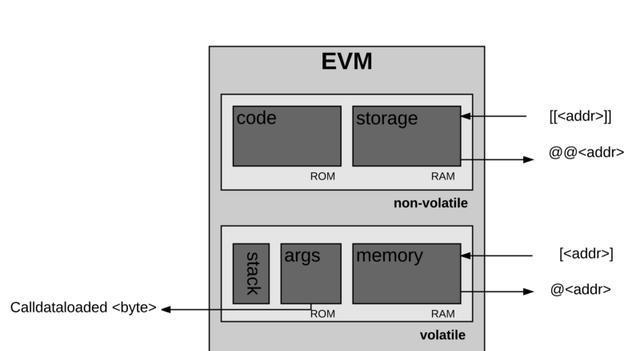
可以看到code和storage里存储的数据是非易失的(non-volatile),而stack,args,memory里存储的数据是易失的(volatile),其中code的数据是智能合约的二进制源码,是非易失的很好理解,部署合约的时候data字段也就是合约内容会存储在EVM的code中。
如果要操作这些存储结构里的数据,就需要用到EVM指令,由于EVM的操作码被限制在一个字节以内,所以EVM最多容纳256条指令,目前EVM已经定义了约142条指令,还有100多条用于以后的扩展。这142条指令包括了算法运算,密码学计算,栈操作,memory,storage操作等。
接下来看一下各个存储位置的含义;
Stack(栈)
stack可以免费使用,没有gas消耗,用来保存函数的局部变量,数量被限制在了16个,当在合约里中声明的局部变量超过16个时,再编译合约就会遇到Stack too deep, try removing local variables错误。
介绍几个EVM操作栈的指令,在后面分析合约的时候会用到;
- Pop指令(操作码0x50)用来从栈顶弹出一个元素;
- PushX指令用来把紧跟在后面的1-32字节元素推入栈顶,Push指令一共32条,从Push1(0x60)到Push32(0x7A),因为栈的一个
字是256bit,一个字节8bit,所以Push指令最多可以把其后32字节的元素放入栈中而不溢出。 - DupX指令用来复制从栈顶开始的第1-16个元素,复制后把元素在推入栈顶,Dup指令一共16条,从Dup1(0x80)到Dup16(0x8A)。
- SwapX指令把栈顶元素和从栈顶开始数的第1-16个元素进行交换,Swap指令一共16条,从Swap1(0x01)一直到Swap16(0x9A)。
Args(参数)
args也叫calldata,是一段只读的可寻址的保存函数调用参数的空间,与栈不同的地方的是,如果要使用calldata里面的数据,必须手动指定偏移量和读取的字节数。
EVM提供的用于操作calldata的指令有三个:
calldatasize返回calldata的大小。calldataload从calldata中加载32bytes到stack中。calldatacopy拷贝一些字节到内存中。
通过一个合约来看一下如何使用calldata,假如我们要写一个合约,合约有一个add的方法,用来把传入的两个参数相加,通常会这样写。
pragma solidity ^0.5.1;
contract Calldata {
function add(uint256 a, uint256 b) public view returns (uint256) {
return a + b;
}
}
当然我们也可以用内联汇编的形式这样写。
contract Calldata {
function add(uint256 a, uint256 b) public view returns (uint256) {
assembly {
let a := mload(0x40)
let b := add(a, 32)
calldatacopy(a, 4, 32)
calldatacopy(b, add(4, 32), 32)
result := add(mload(a), mload(b))
}
}
}
首先我们我们加载了0x40这个地址,这个地址EVM存储空闲memory的指针,然后我们用a重命名了这个地址,接着我们用b重命名了a偏移32字节以后的空余地址,到目前为止这个地址所指向的内容还是空的。
calldatacopy(a, 4, 32)这行代码把calldata的从第4字节到第36字节的数据拷贝到了a中,同样calldatacopy(b, add(4, 32), 32)把36到68字节的数据拷贝到了b中,接着add(mload(a), mload(b))把栈中的a,b加载到内存中相加。最后的结果等价于第一个合约。
而为什么calldatacopy(a, 4, 32)的偏移要从4开始呢?在EVM中,前四位是存储函数指纹(函数选择器)的,计算公式是bytes4(keccak256(“add(uint256, uint256)”)),从第四位开始才是args。
Memory(内存)
Memory是一个易失性的可以读写修改的空间,主要是在运行期间存储数据,将参数传递给内部函数。内存可以在字节级别寻址,一次可以读取32字节。 EVM提供的用于操作memory的指令有三个:
- mload 加载一个字从stack到内存;
- sstore存储一个值到指定的内存地址,格式mstore(p,v),存储v到地址p;
- mstore8存储一个byte到指定地址 ;
当我们操作内存的时候,总是需要加载0x40,因为这个地址保存了空闲内存的指针,避免了覆盖已有的数据。
Storage(存储)
Storage是一个可以读写修改的持久存储的空间,也是每个合约持久化存储数据的地方。Storage是一个巨大的map,一共2^256个插槽,一个插糟有32byte。 EVM提供的用于操作storage的指令有两个:
- sload用于加载一个字到stack中;
- sstore用于存储一个字到storage中;
solidity将定义的状态变量,映射到插糟内,对于静态大小的变量从0开始连续布局,对于动态数组和map则采用了其他方法,下面介绍。
状态变量
Storage初始化的时候是空白的,默认是0。
pragma solidity ^0.5.1;
contract C {
uint256 a;
uint256 b;
uint256 c;
uint256 d;
uint256 e;
uint256 f;
function test() public {
f = 0xc0fefe;
}
}
用solc --bin --asm --optimize test.sol编译合约,可以看到;
tag_5:
/* "test.sol":167:175 0xc0fefe */
0xc0fefe
/* "test.sol":163:164 f */
0x5
/* "test.sol":163:175 f = 0xc0fefe */
sstore
这段汇编执行的是sstore(0x5, 0xc0fefe),把0xc0fefe存储到0x5这个位置,在EVM中声明变量不需要成本,EVM会在编译的时候保留位置,但是不会初始化。
当通过指令
sload读取一个未初始化的变量的时候, 不会报错,只会读取到零值0x0。
struct 结构体
结构体的初始化和变量是一样的;
pragma solidity ^0.5.1;
contract C {
struct Tuple {
uint256 a;
uint256 b;
uint256 c;
uint256 d;
uint256 e;
uint256 f;
}
Tuple t;
function test() public {
t.f = 0xC0FEFE;
}
}
编译得到:
tag_5:
/* "test.sol":219:227 0xC0FEFE */
0xc0fefe
/* "test.sol":213:216 t.f */
0x5
/* "test.sol":213:227 t.f = 0xC0FEFE */
sstore
/* "test.sol":182:234 function test() public {... */
分析编译后的汇编发现结果和状态变量的行为是一致的。
定长数组
定长数组EVM很容易知道类型和长度,所以可以依次排列,就像存储状态变量一样。
pragma solidity ^0.5.1;
contract C {
uint256[6] numbers;
function test() public {
numbers[5] = 0xC0FEFE;
}
}
编译合约,可以看到一样的汇编。
tag_5:
/* "test.sol":110:118 0xC0FEFE */
0xc0fefe
/* "test.sol":105:106 5 */
0x5
/* "test.sol":97:118 numbers[5] = 0xC0FEFE */
sstore
但是使用定长数组就会有越界的问题,EVM会在赋值的时候生成汇编检查,具体的内容在下篇合约分析中讨论。
固定大小的变量都是尽可能打包成32字节的块然后依次存储的,而一些类型是可以动态扩容的,这个时候就需要更加灵活的存储方式了,这些类型有映射(map),数组(array),字节数组(Byte arrays),字符串(string)。
映射(map)
通过一个简单的合约学习map的存储方式;
pragma solidity ^0.5.1;
contract Test {
mapping(uint256 => uint256) items;
function test() public {
items[0x01] = 0x42;
}
}
这个合约很简单,就是创建了一个key和value都是uint256类型的map,并且在用0x01作为key存储了0x42,用solc --bin --asm --optimize test.sol编译合约,得到如下汇编。
tag_5:
/* "test.sol":119:123 0x01 */
0x1
/* "test.sol":113:118 items */
0x0
/* "test.sol":113:124 items[0x01] */
swap1
dup2
mstore
0x20
mstore
/* "test.sol":127:131 0x42 */
0x42
/* "test.sol":113:124 items[0x01] */
0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d
/* "test.sol":113:131 items[0x01] = 0x42 */
sstore
/* "test.sol":82:136 function test() public {... */
jump // out
分析一些这段汇编就会发现0x42并不是存储在key是0x01的位置,取而代之的是0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d这样一段地址,这段地址是通过keccak256( bytes32(0x01) + bytes32(0x00) )计算得到的,0x01就是key,而0x00表示这个合约存储的第一个storage类型变量。
所以key的计算公式就是keccak256(bytes32(key) + bytes32(position))
多个映射map
假设我们的合约有两个map
pragma solidity ^0.5.1;
contract Test {
mapping(uint256 => uint256) itemsA;
mapping(uint256 => uint256) itemsB;
function test() public {
itemsA[0xAAAA] = 0xAAAA;
itemsB[0xBBBB] = 0xBBBB;
}
}
编译得到
tag_5:
/* "test.sol":166:172 0xAAAA */
0xaaaa
/* "test.sol":149:163 itemsA[0xAAAA] */
0x839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3
/* "test.sol":149:172 itemsA[0xAAAA] = 0xAAAA */
sstore
/* "test.sol":195:201 0xBBBB */
0xbbbb
/* "test.sol":149:155 itemsA */
0x0
/* "test.sol":178:192 itemsB[0xBBBB] */
dup2
swap1
mstore
/* "test.sol":178:184 itemsB */
0x1
/* "test.sol":149:163 itemsA[0xAAAA] */
0x20
/* "test.sol":178:192 itemsB[0xBBBB] */
mstore
0x34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395
/* "test.sol":178:201 itemsB[0xBBBB] = 0xBBBB */
sstore
/* "test.sol":120:206 function test() public {... */
jump // out
itemsA的位置是0,key是0xAAAA:
# key = 0xAAAA, position = 0
keccak256(bytes32(0xAAAA) + bytes32(0))
'839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3'
itemsB的位置是1,key是0xBBBB:
# key = 0xBBBB, position = 1
keccak256(bytes32(0xBBBB) + bytes32(1))
'34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395'
用solc --bin --asm --optimize test.sol编译合约,得到如下汇编。
/* "test.sol":166:172 0xAAAA */
0xaaaa
/* "test.sol":149:163 itemsA[0xAAAA] */
0x839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3
/* "test.sol":149:172 itemsA[0xAAAA] = 0xAAAA */
sstore
/* "test.sol":195:201 0xBBBB */
0xbbbb
/* "test.sol":149:155 itemsA */
0x0
/* "test.sol":178:192 itemsB[0xBBBB] */
dup2
swap1
mstore
/* "test.sol":178:184 itemsB */
0x1
/* "test.sol":149:163 itemsA[0xAAAA] */
0x20
/* "test.sol":178:192 itemsB[0xBBBB] */
mstore
0x34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395
/* "test.sol":178:201 itemsB[0xBBBB] = 0xBBBB */
sstore
/* "test.sol":120:206 function test() public {... */
jump // out
可以看到,存储的地址和我们推到的一样。
动态数组
在其他语言中,数组只是连续存储在内存中的一系列相同类型的元素,取值的时候都是采用首地址+偏移量的形式,但是在solidity中,数组是一种映射。数组在存储器中是这样存储的:
0x290d...e563
0x290d...e564
0x290d...e565
0x290d...e566
虽然看起来像是连续存储的,但实际上访问的时候是通过映射来查找的。增加了数组类型的意义在于多了一些数组的方法,便于我们更好的理解和编写代码,增加的特性有:
- length表示数组的长度,一共有多少元素;
- 边界检查,当读取或者写入时索引值大于length就会报错;
- 比映射更加复杂的存储打包行为;
- 当数组变小时,自动清除未使用的空间;
- bytes和string的特殊优化让短数组(小于32字节)存储更加高效;
编译合约
pragma solidity ^0.5.1;
contract C {
uint256[] chunks;
function test() public {
chunks.push(0xAA);
chunks.push(0xBB);
chunks.push(0xCC);
}
}
使用remix调试合约可以看到storage部分的存储内容;
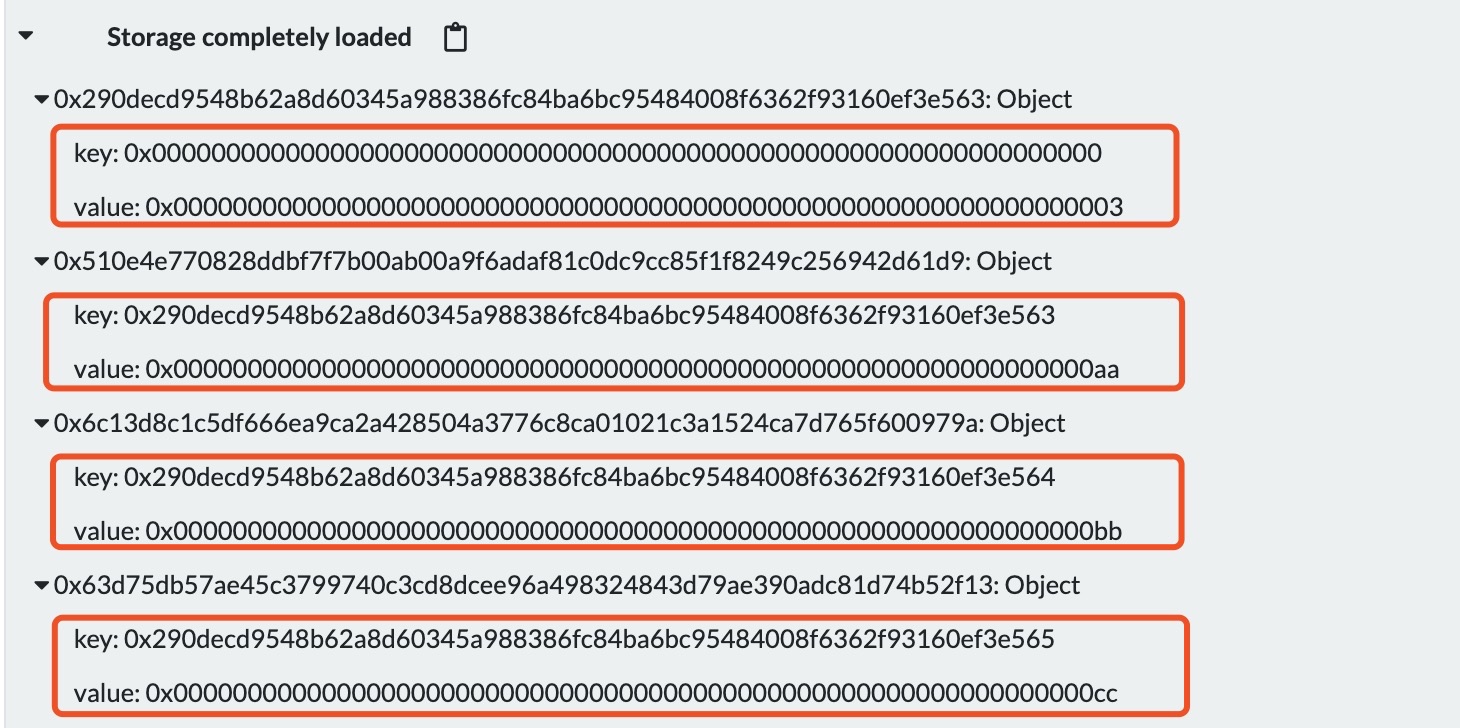
因为动态数组在编译期间无法知道数组的长度,提前预留存储空间,所以solidity就用chunks变量的位置存储了动态数组的长度,而具体的数据地址通过计算keccak256(bytes32(0))算得数组首地址,再加数组长度偏移量获得具体的元素。
这里的 0 表示的是chunks变量的位置哦
动态数据打包
数组与映射相比,有更加优化的打包行为,编译合约;
pragma solidity ^0.5.1;
contract C {
uint128[] s;
function test() public {
s.length = 4;
s[0] = 0xAA;
s[1] = 0xBB;
s[2] = 0xCC;
s[3] = 0xDD;
}
}
使用remix调试合约可以看到storage部分的存储内容;
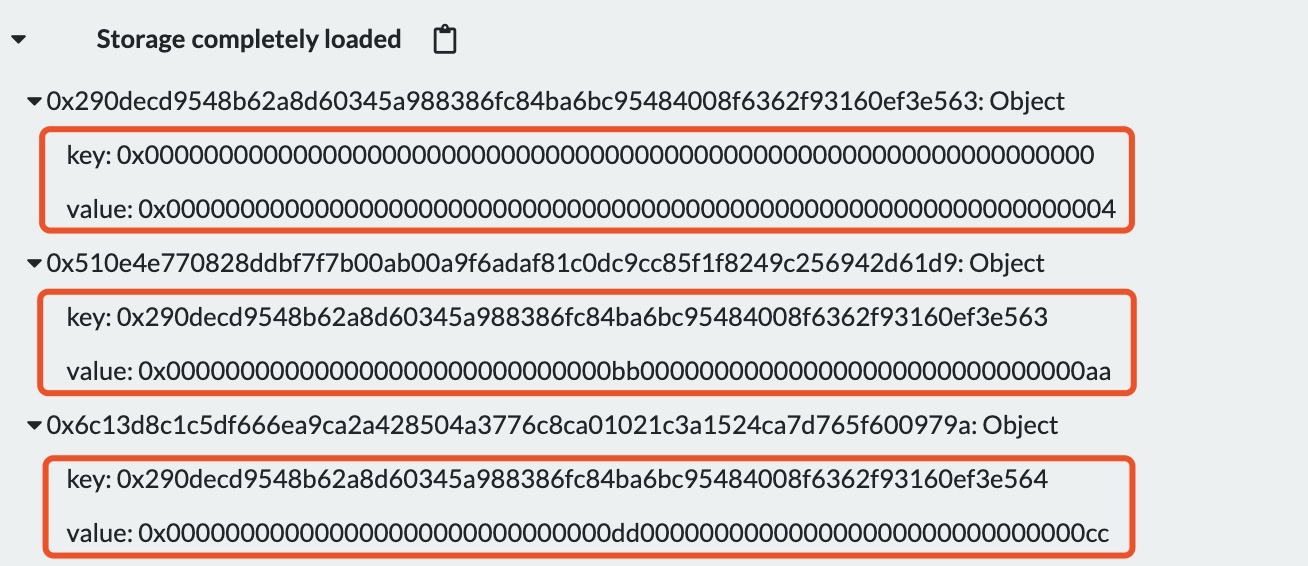
可以发现4个元素并没有占据4个插槽,而只有两个,solidity一个插糟的大小是256bit,s的类型是uint128,编译器做了一个优化,对数据进行了更优化的打包策略,可以最大限度的节约Gas。
看一些各项操作所花费Gas的表格;
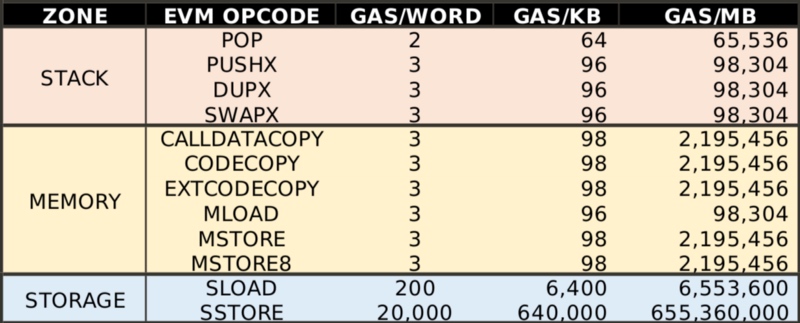
其中数据的持久化操作sstore是消耗Gas最多的操作,在合适的场景下使用数组可以利用编译器优化节约大量的Gas。
字节数组和字符串
bytes和string是EVM特殊优化的类型:
pragma solidity ^0.5.1;
contract C {
bytes s;
function test() public {
s.push(0xAA);
s.push(0xBB);
s.push(0xCC);
}
}
最后用remix编译得到:
key: 0x0000000000000000000000000000000000000000000000000000000000000000
value: 0xaabbcc0000000000000000000000000000000000000000000000000000000006
当bytes和string的长度小于31字节的时候可以这样放到一个插槽里,但是当大于31字节的时候,就采用存储动态数组的方式。
总结
EVM的存储器就是一个健值数据库,当改变里面的任何一点东西,根节点的校验和也会改变,如果两个根节点拥有相同的校验和,存储的数据就能保持一致。
本文作者是深入浅出区块链共建者清源,欢迎关注清源的博客,不定期分享一些区块链底层技术文章。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录

Memory 标题下的sstore,应该是mstore。估计作者笔误了。
mload 加载一个字从stack到内存 MLOAD(offset) reads a (u)int256 from memory 这个应该是从内村的offset位置加载到stack