哪个 AI 编程助手在 Solidity 语言上表现更出色
- Trail of Bits
- 发布于 2024-11-24 18:25
- 阅读 3063
评估各个 AI 编程助手在 Solidity 语言上的表现
- 原文链接:blog.trailofbits.com/2024...
- 译者:AI翻译官,校对:翻译小组
- 本文链接:learnblockchain.cn/article…
由 Artem Dinaburg 撰写
AI 驱动的代码助手(如 GitHub 的 Copilot、Continue.dev 和 Tabby)正在使软件开发变得更快、更高效。不幸的是,这些工具在 Solidity 上的表现往往不佳。因此,我们决定改进它们!
为了使使用 AI 驱动的工具编写、编辑和理解 Solidity 更加容易,我们:
- 在 Tabby 和 Continue.dev 中添加了对 Solidity 的支持,这两个是本地的、保护隐私的 AI 驱动编码助手
- 创建了一个自定义代码补全评估工具 CompChomper,以评估不同模型在 Solidity 代码补全方面的表现
我们还在不同量化级别上评估了流行的代码模型,以确定哪些模型在 Solidity 上表现最佳(截至 2024 年 8 月),并将它们与 ChatGPT 和 Claude 进行了比较。我们的结论是:本地模型与大型商业产品相比表现良好,甚至在某些补全风格上超越了它们。
然而,尽管这些模型很有用,尤其是在原型设计时,我们仍然希望提醒 Solidity 开发者不要过于依赖 AI 助手。我们审查了使用 AI 辅助编写的合约,发现其中存在多个 AI 引起的错误:AI 生成的代码在已知模式下表现良好,但在实际需要处理的自定义场景中表现不佳。这就是为什么我们建议进行全面的单元测试,使用自动化测试工具,如 Slither、Echidna 或 Medusa——当然,还有来自 Trail of Bits 的付费 安全审计。
AI 助手改进
在 Trail of Bits,我们既进行审计,也编写了相当多的 Solidity,并迅速使用我们能找到的任何提高生产力的工具。一旦 AI 助手添加了对本地代码模型的支持,我们立即想要评估它们的工作效果。遗憾的是,Solidity 语言的支持在工具和模型层面上都很缺乏——所以我们提交了一些拉取请求。
Trail of Bits 为 Continue.dev 和 Tabby 添加了 Solidity 支持。这项工作还需要对 tree-sitter-wasm 进行上游贡献,以便惠及其他使用 tree-sitter 的开发工具。
我们愿意为其他 AI 驱动的代码助手添加支持;请 联系我们,看看我们能做些什么。
哪种模型最适合 Solidity 代码补全?
没有经过基准测试的内容不会引起关注,这意味着在大型语言代码模型中,Solidity 被忽视。Solidity 在大约零个代码评估基准中出现(即使是 MultiPL,包括 22 种语言,也缺少 Solidity)。可用的数据集通常质量较差;我们查看了一个开源训练集,发现其中包含的 .sol 扩展名的垃圾代码多于真正的 Solidity 代码。
我们希望改善大型语言代码模型中的 Solidity 支持。然而,在我们能够改进之前,必须先进行测量。那么,流行的代码模型在 Solidity 补全方面的表现如何(在我们进行这项工作时,2024 年 8 月)?
为了给急于了解结果的人提前剧透:我们测试的最佳商业模型是 Anthropic 的 Claude 3 Opus,而最佳本地模型是你可以舒适运行的参数数量最大的 DeepSeek Coder 模型。对于某些类型的代码补全任务,本地模型也优于大型商业模型。
我们还了解到:
- 量化为 4 位的较大模型在代码补全方面优于同种类的较小模型。
- CodeLlama 几乎肯定从未在 Solidity 上进行过训练。
- CodeGemma 在 Ollama 中的支持在这个特定用例中微妙地损坏。
请继续阅读以获取更详细的评估和我们的方法论。
评估代码补全
编写良好的评估非常困难,而编写完美的评估是不可能的。 部分出于必要,部分为了更深入地理解 LLM 评估,我们创建了自己的代码补全评估工具 CompChomper。
CompChomper 使评估 LLM 在你关心的任务上的代码补全变得简单。你可以指定要使用的 git 仓库作为数据集,以及你希望测量的补全风格。CompChomper 提供了预处理、运行多个 LLM(本地或通过 Modal Labs 在云中)和评分的基础设施。尽管 CompChomper 仅在 Solidity 代码上进行了测试,但它在很大程度上是语言无关的,可以轻松重新用于测量其他编程语言的补全准确性。
有关 CompChomper 的更多信息,包括我们评估的技术细节,可以在 CompChomper 源代码和文档 中找到。
我们测试了什么
起初我们开始评估流行的小型代码模型,但随着新模型的不断出现,我们无法抗拒添加 DeepSeek Coder V2 Light 和 Mistral 的 Codestral。测试模型的完整列表是:
- CodeGemma 2B, 7B(来自 Google)
- CodeLlama 7B(来自 Meta)
- Codestral 22B(来自 Mistral)
- CodeQwen1.5 7B(来自 Qwen Team, Alibaba Group)
- DeepSeek Coder V1.5 1.3B, 6.7B(来自 DeepSeek AI)
- DeepSeek Coder V2 Light(来自 DeepSeek AI)
- Starcoder2 3B, 7B(来自 BigCode Project)
我们进一步评估了每种模型的多种变体。完整权重模型(16 位浮点数)通过 HuggingFace Transformers 本地提供,以评估原始模型能力。GGUF 格式的 8 位量化(Q8)和 4 位量化(Q4_K_M)由 Ollama 提供。这些模型是开发者可能实际使用的模型,测量不同的量化有助于我们理解模型权重量化的影响。
为了形成良好的基线,我们还评估了 GPT-4o 和 GPT 3.5 Turbo(来自 OpenAI),以及 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3.5 Sonnet(来自 Anthropic)。
部分行补全结果
部分行补全基准测量模型完成部分代码行的准确性。你会在输入函数调用时使用此场景,并希望模型自动填充正确的参数。以下是部分行补全的可视化表示:想象一下你刚刚输入了 require(。哪个模型会插入正确的代码?
function transferOwnership(address newOwnerAddress) external {
require(
*_ownerAddress = newOwnerAddress
}图 1:蓝色是提供给模型的前缀,绿色是模型应该写的未知文本,橙色是提供给模型的后缀。在这种情况下,正确的补全是 msg.sender == *_ownerAddress);。
从部分行完成结果中最有趣的收获是,许多本地代码模型在这项任务上表现优于大型商业模型。这可能会随着更好的提示而改变(我们将发现更好提示的任务留给读者)。
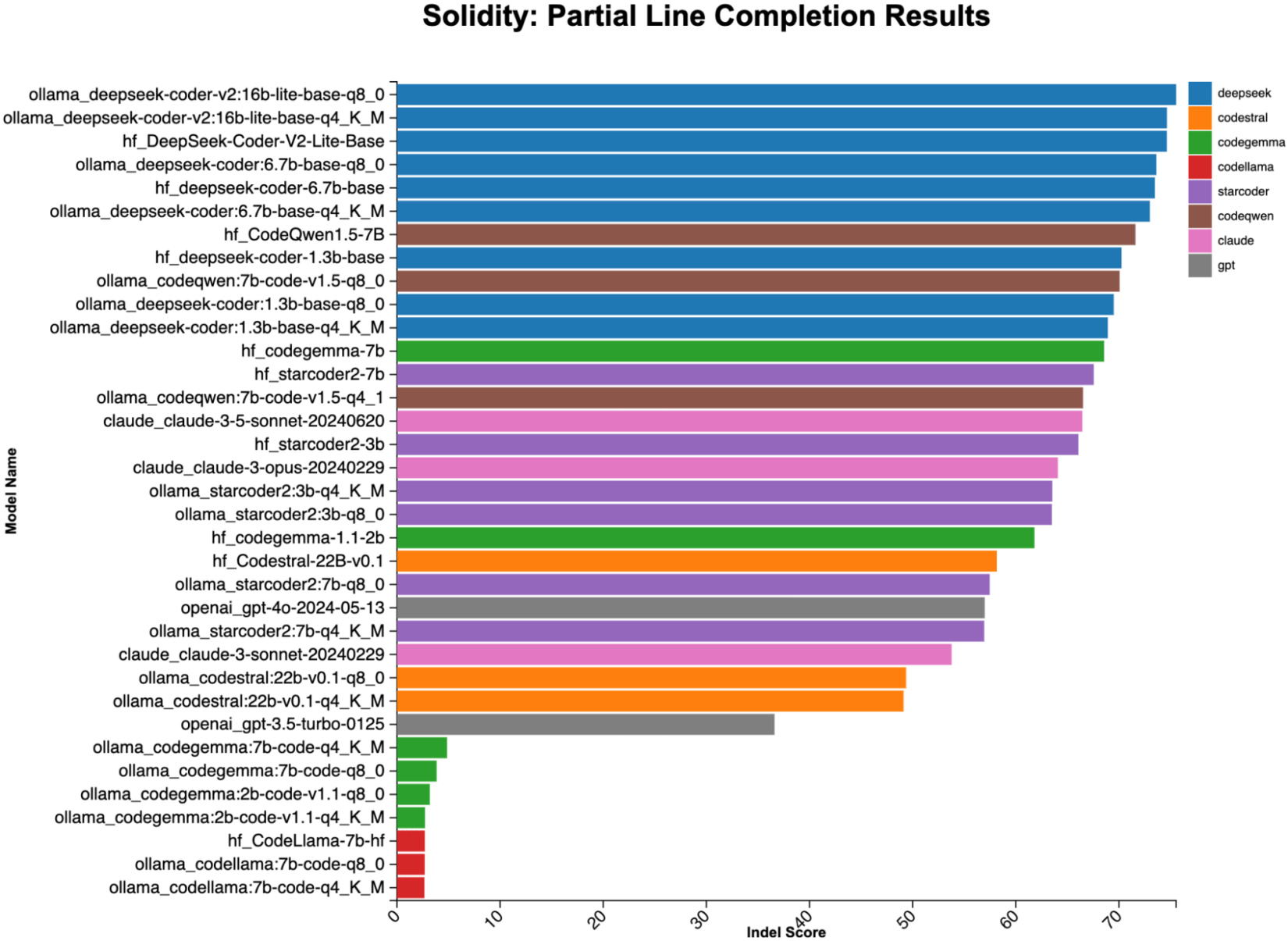
图 2:来自流行编码 LLM 的部分行完成结果。在这项测试中,本地模型的表现明显优于大型商业产品,前几名主要由 DeepSeek Coder 衍生品占据。我们测试的本地模型是专门为代码完成训练的,而大型商业模型则是为指令跟随训练的。(最高分 = 98。)
整行补全
整行补全基准测试衡量模型在给定前一行和下一行的情况下,完成整行代码的准确性。你使用此功能的场景是,当你输入函数名称时,希望 LLM 填充函数体。这种基准测试通常用于测试代码模型的中间填充能力,因为完整的前一行和下一行上下文可以减轻评估代码完成时的空白问题。以下是此任务的可视化表示。

图 3:蓝色是给模型的前缀,绿色是模型应该写的未知文本,橙色是给模型的后缀。在这种情况下,正确的完成是:
require(msg.sender == _ownerAddress);在这项任务中,大型模型领先,Claude3 Opus 以微弱优势击败 ChatGPT 4o。然而,最佳本地模型与最佳托管商业产品非常接近。本地模型的能力差异很大;其中,DeepSeek 衍生品占据了前列。
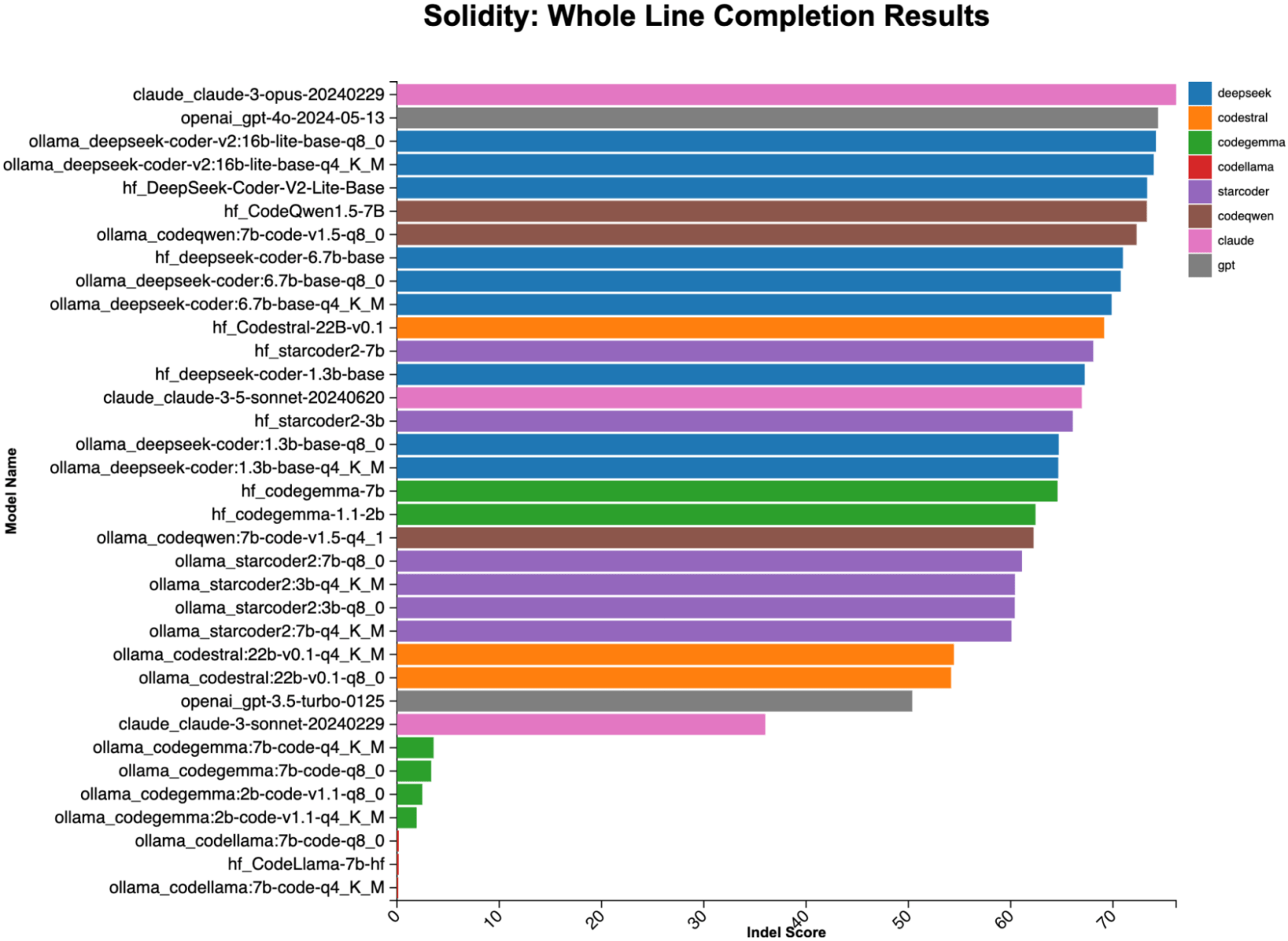
图 4:来自流行编码 LLM 的整行完成结果。尽管商业模型仅略微优于本地模型,但结果非常接近。(最高分 = 98。)
我们学到了什么
总体而言,最佳本地模型和托管模型在 Solidity 代码完成方面表现良好,并非所有模型都是平等的。我们还了解到,对于这项任务,模型大小比量化级别更为重要,较大但量化程度更高的模型几乎总是优于较小但量化程度较低的替代品。
表现最佳的是 DeepSeek coder 的变体;表现最差的是 CodeLlama 的变体,显然没有经过 Solidity 的训练,以及通过 Ollama 的 CodeGemma,在以这种方式运行时似乎出现了某种灾难性故障。
查看我们的结果并得出 LLM 可以生成良好 Solidity 的结论可能很诱人。请不要这样做!代码生成与代码完成是不同的任务。 在我们看来,使用 AI 辅助进行智能自动补全以外的任何操作仍然是一个严重的风险。如前所述,LLM 中的 Solidity 支持通常是事后考虑,训练数据稀缺(与 Python 相比)。尚未创建的模式或构造无法可靠地由 LLM 生成。这不是一个假设性问题;我们在审计过程中遇到了 AI 生成代码中的错误。
一如既往,即使是人类编写的代码,也没有严格测试、验证和第三方审计的替代品。
接下来是什么
现在我们已经有了一组适当的评估和性能基准,我们将对所有这些模型进行微调,以便更好地完成 Solidity!这个过程已经在进行中;我们会在 Solidity 语言微调模型完成后尽快更新大家。





