Yul初学者指南
本文介绍了Yul语言的基础知识,Yul是一种用于在智能合约中编写汇编语言的中间编程语言。文章通过示例讲解了Yul的变量赋值、操作、循环、条件语句、存储和内存管理,以及如何执行合约调用。
## 什么是 Yul?
Yul 是一种中间编程语言,可以用于在智能合约内部编写一种形式的汇编语言。虽然我们经常看到 Yul 在智能合约中使用,但你可以完全用 Yul 编写一个智能合约。理解 Yul 可以提升你的智能合约水平,使你理解 Solidity 内部发生了什么,从而帮助你节省用户的 Gas 费用。我们可以用以下语法在智能合约中识别 Yul。
assembly { // 执行操作 }
在本文的其余部分,我们将通过示例讨论使用 Yul 的基本知识,我鼓励你在 Remix 中进行练习。
## 变量赋值、操作和评估
我们需要讨论的第一个主题是简单操作。Yul 支持 `+`、`-`、`*`、`/`、`%`、`**`、`<`、`>` 和 `=`。注意,`>=` 和 `<=` 不包含在内,Yul 没有这些操作。此外,评估的结果不是布尔值 true 或 false,而分别为 1 或 0。话不多说,让我们开始学习一些 Yul!
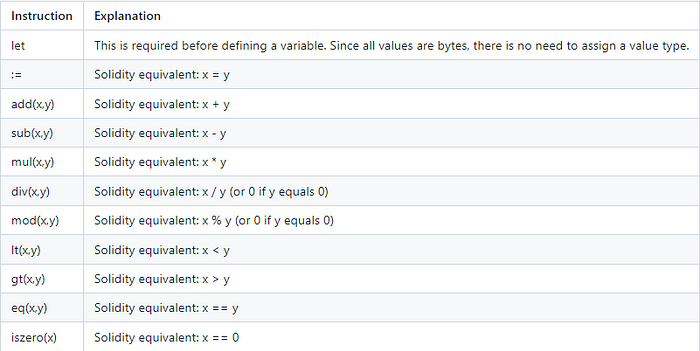
在继续之前,我们来快速看一个示例。
function addOneAnTwo() external pure returns(uint256) { // 我们可以在 Yul 代码中访问 Solidity 的变量 uint256 ans;
assembly {
// 在 Yul 中赋值变量
let one := 1
let two := 2
// 将两个变量相加
ans := add(one, two)
}
return ans;
}
## 循环和条件语句
为了学习这两者,我们来写一个函数,计算在一个序列中有多少个偶数。
function howManyEvens(uint256 startNum, uint256 endNum) external pure returns(uint256) {
// 我们将返回的值
uint256 ans;
assembly {
// for 循环的语法
for { let i := startNum } lt( i, add(endNum, 1) ) { i := add(i,1) }
{
// 如果 i == 0,则跳过此迭代
if iszero(i) {
continue
}
// 检查 i % 2 == 0
// 我们可以使用 iszero,但我想给你展示 eq()
if eq( mod( i, 2 ), 0 ) {
ans := add(ans, 1)
}
}
}
return ans;
}
`if` 语句的语法与 Solidity 非常相似,但是我们不需要将条件放在括号中。对于 `for` 循环,注意在声明 `i` 和递增 `i` 时使用了大括号,但在评估条件时没有。此外,我们使用 `continue` 来跳过循环的某次迭代。我们还可以在 Yul 中使用 `break` 语句。
## 存储
在我们深入了解 Yul 的工作原理之前,我们需要对智能合约中的存储有一个良好的理解。存储由一系列插槽组成。智能合约有 2²⁵⁶ 个插槽。在声明变量时,我们从插槽 0 开始,并从那里递增。每个插槽的长度为 256 位(32 字节),这就是 `uint256` 和 `bytes32` 的名字来源。所有变量都转换为十六进制。如果使用了变量,例如 `uint128`,则不会占用整个插槽来存储该变量。相反,它会在左侧填充 0。让我们看一个例子以更好地理解。
// 插槽 0 uint256 var1 = 256;
// 插槽 1 address var2 = 0x9ACc1d6Aa9b846083E8a497A661853aaE07F0F00;
// 插槽 2 bytes32 var3 = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
// 插槽 3 uint128 var4 = 1; uint128 var5 = 2;
`var1`:由于 `uint256` 变量等于 32 字节,因此 `var1` 占用插槽 0 的全部。存储在插槽 0 中的是:`0x0000000000000000000000000000000000000000000000000000000000000100`。
`var2`:地址略微复杂。由于只占用 20 字节的存储,因此地址在左侧用 0 填充。存储在插槽 1 中的是:`0x0000000000000000000000009acc1d6aa9b846083e8a497a661853aae07f0f00`。
`var3`:这一项可能看起来很简单,插槽 2 被整个 `bytes32` 变量占用。
`var4` 和 `var5`:记得我提到 `uint128` 会在左侧填充 0 吗?好吧,如果我们将变量有序排列,使它们的存储之和小于 32 字节,我们可以把它们放在一个插槽中!这称为打包变量,可以节省 Gas。让我们查看插槽 3 中存储的内容:`0x0000000000000000000000000000000200000000000000000000000000000001`。注意 `0x000000000000000000000000000002` 和 `0x000000000000000000000000000001` 完美地适配于同一个插槽。这是因为它们都占用 16 字节(一个插槽的一半)。
现在是时候学习更多的 Yul 了!
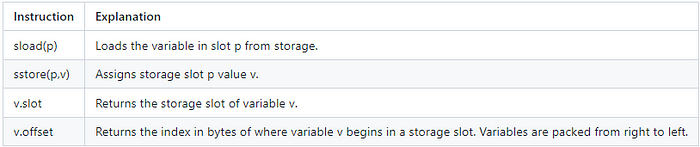
让我们看另一个例子!
function readAndWriteToStorage() external returns (uint256, uint256, uint256) {
uint256 x;
uint256 y;
uint256 z;
assembly {
// 获取 var5 的插槽
let slot := var5.slot
// 获取 var5 的偏移量
let offset := var5.offset
// 将 x 和 y 从 Solidity 赋值给插槽和偏移量
x := slot
y := offset
// 在插槽 0 中存储值 1
sstore(0,1)
// 将 z 赋值为插槽 0 的值
z := sload(0)
}
return (x, y, z);
}
`x` = 3。因为我们知道 var5 被打包在插槽 3 中,这很合理。
`y` = 16。因为我们知道 `var4` 占用插槽 3 的一半,这同样也合理。因为变量是从右到左打包的,所以我们得到 var5 的起始索引 16。
`z` = 1。`sstore()` 将插槽 0 的值赋值为 1。然后,我们用 `sload()` 将 z 赋值为插槽 0 的值。
在继续之前,你应该将这个函数添加到你的 Remix 文件中。它将帮助你查看每个存储插槽中存储的内容。
// 输入是我们想要读取的存储插槽 function getValInHex(uint256 y) external view returns (bytes32) { // 由于 Yul 使用十六进制,因此我们希望以 bytes 返回 bytes32 x;
assembly { // 将插槽 y 的值赋值给 x x := sload(y) }
return x; }
现在让我们看一些更复杂的数据结构!
// 插槽 4 和 5 uint128[4] var6 = [0,1,2,3];
在处理静态数组时,EVM 知道要分配多少插槽用于我们的数据。针对这个特定数组,我们每个插槽打包 2 个元素。因此,如果你调用 `getValInHex(4)`,它将返回 `0x0000000000000000000000000000000100000000000000000000000000000000`。如我们所期望,从右到左读取时,我们看到值为 0 和 1。插槽 5 包含 `0x0000000000000000000000000000000300000000000000000000000000000002`。
接下来,我们将看动态数组。
// 插槽 6 uint256[] var7;
试着调用 `getValInHex(6)`。你将看到它返回 `0x00`。因为 EVM 不知道需要分配多少存储插槽来存储动态数组,我们无法在这里存储数组。相反,将使用当前存储插槽(插槽 6)的 keccak256 哈希作为数组的起始索引。从这里开始,我们所要做的就是将所需元素的索引相加,以便检索其值。
下面是一个演示如何查找动态数组元素的代码示例。
function getValFromDynamicArray(uint256 targetIndex) external view returns (uint256) {
// 获取动态数组的插槽
uint256 slot;
assembly {
slot := var7.slot
}
// 为起始索引获取插槽的哈希
bytes32 startIndex = keccak256(abi.encode(slot));
uint256 ans;
assembly {
// 将起始索引和目标索引相加以获取存储位置;然后加载相应的存储插槽
ans := sload( add(startIndex, targetIndex) )
}
return ans;
}
在这里,我们检索到数组的插槽,然后使用 `add()` 操作并结合 `sload()` 获取我们所需数组元素的值。
你可能会问,是什么阻止我们与另一个变量的插槽发生冲突?这完全有可能,但是极不可能,因为 2²⁵⁶ 是一个非常大的数字。
映射的行为与动态数组类似,只是我们将插槽与键结合哈希。
// 插槽 7 mapping(uint256 => uint256) var8;
为了演示,我将映射值设置为 `var8[1] = 2`。现在让我们看一个如何获取映射中键值的示例。
function getMappedValue(uint256 key) external view returns(uint256) {
// 获取映射的插槽
uint256 slot;
assembly {
slot := var8.slot
}
// 对键和插槽值进行哈希
bytes32 location = keccak256(abi.encode(key, slot));
uint256 ans;
// 加载指定位置的存储插槽并返回 ans
assembly {
ans := sload(location)
}
return ans;
}
如你所见,代码与我们找到动态数组元素时非常相似。主要区别在于我们哈希了键和插槽。
在存储部分的最后一部分中,我们将学习嵌套映射。阅读之前,我建议你基于目前为止学到的知识,自己实现一个如何读取嵌套映射值的函数。
// 插槽 8 mapping(uint256 => mapping(uint256 => uint256)) var9;
在这个示例中,我将映射值设置为 `var9[0][1] = 2`。以下是代码,让我们深入探讨!
function getMappedValue(uint256 key1, uint256 key2) external view returns(uint256) {
// 获取映射的插槽
uint256 slot;
assembly {
slot := var9.slot
}
// 对键和插槽值进行哈希
bytes32 locationOfParentValue = keccak256(abi.encode(key1, slot));
// 将父键与嵌套键进行哈希
bytes32 locationOfNestedValue = keccak256(abi.encode(key2, locationOfParentValue));
uint256 ans;
// 从存储中加载位置的槽并返回 ans
assembly {
ans := sload(locationOfNestedValue)
}
return ans;
}
我们首先获取第一个键(0)的哈希。然后我们将其与第二个键(1)进行哈希。最后,我们从存储中加载插槽以获取我们的值。
恭喜你,完成了 Yul 中存储部分的学习!
## 读取和写入打包变量
假设你想将 `var5` 改为 4。我们知道 `var5` 位于插槽 3,因此你可能会尝试像这样做:
function writeVar5(uint256 newVal) external {
assembly {
sstore(3, newVal)
}
}
使用 `getValInHex(3)` 我们看到插槽 3 已被重写为 `0x0000000000000000000000000000000000000000000000000000000000000004`。这会造成问题,因为现在 `var4` 已被重写为 0。在本节中,我们将讨论如何读取和写入打包变量,但我们首先需要了解更多关于 Yul 的语法。
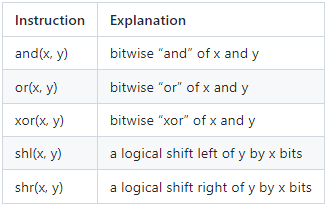
如果你对这些操作不熟悉,不要担心,我们将通过示例逐一讲解。
让我们从 `and()` 开始。我们将取两个 `bytes32` 并尝试 `and()` 操作,看看它的返回值是什么。
function getAnd() external pure returns (bytes32) {
bytes32 randVar = 0x0000000000000000000000009acc1d6aa9b846083e8a497a661853aae07f0f00;
bytes32 mask = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
bytes32 ans;
assembly {
ans := and(mask, randVar)
}
return ans;
}
如果你查看输出,我们看到 `0x0000000000000000000000009acc1d6aa9b846083e8a497a661853aae07f0f00`。这是因为 `and()` 操作会查看两个输入的每一位,并比较它们的值。如果两个位都是 1(可以用二进制思考:活跃或非活跃),那么我们保留该位。否则它将被设置为 0。
现在看看 `or()` 的代码。
function getOr() external pure returns (bytes32) {
bytes32 randVar = 0x000000000000000000000000ffffffffffffffffffffffffffffffffffffffff;
bytes32 mask = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
bytes32 ans;
assembly {
ans := or(mask, randVar)
}
return ans;
}
这次输出为 `0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff`。这是因为它查看是否至少有一个位处于活动状态。让我们看看如果我们将 mask 变量更改为 `0x00ffffffffffffffffffffff0000000000000000000000000000000000000000`,输出将会改变为 `0x00ffffffffffffffffffffff9acc1d6aa9b846083e8a497a661853aae07f0f00`。注意第一个字节是 `0x00`,因为两个输入对于第一个字节没有任何活跃位。
`xor()` 则略有不同。它要求一个位处于活动状态 (1),另一个位处于非活动状态 (0)。以下是代码演示。
function getXor() external pure returns (bytes32) {
bytes32 randVar = 0x00000000000000000000000000000000000000000000000000000000000000ff;
bytes32 mask = 0xffffffffffffffffffffffff00000000000000000000000000000000000000ff;
bytes32 ans;
assembly {
ans := xor(mask, randVar)
}
return ans;
}
输出是 `0xffffffffffffffffffffffff0000000000000000000000000000000000000000`。关键的区别在于我们看到输出中的唯一活动位是当 `0x00` 和 `0xff` 对齐时。
`shl()` 和 `shr()` 是相似的。两者都将输入值向左或向右移动指定的位数。让我们看一些代码!
function shlAndShr() external pure returns(bytes32, bytes32) {
bytes32 randVar = 0xffff00000000000000000000000000000000000000000000000000000000ffff;
bytes32 ans1;
bytes32 ans2;
assembly {
ans1 := shr(16, randVar)
ans2 := shl(16, randVar)
}
return (ans1, ans2);
}
输出为:
`ans1`: `0x0000ffff00000000000000000000000000000000000000000000000000000000`
`ans2`: `0x00000000000000000000000000000000000000000000000000000000ffff0000`
首先看 `ans1`。我们执行 `shr()` 左移 16 位(2 字节)。正如你所见,最后两个字节从 `0xffff` 变为 `0x0000`,而前两个字节向右移动了两个字节。了解这一点后,`ans2` 看起来也就不复杂了;所有发生的事情只是位向左移动而已。
在我们写入 `var5` 之前,让我们先写一个读取 `var4` 和 `var5` 的函数。
function readVar4AndVar5() external view returns (uint128, uint128) {
uint128 readVar4;
uint128 readVar5;
bytes32 mask = 0x00000000000000000000000000000000ffffffffffffffffffffffffffffffff;
assembly {
let slot3 := sload(3)
// and() 操作将 var5 设置为 0x00
readVar4 := and(slot3, mask)
// 我们将 var5 的旧位置左移到 var4 的位置
readVar5 := shr( mul( var5.offset, 8 ), slot3 )
}
return (readVar4, readVar5);
}
输出是 1 和 2,如预期的那样。要检索 `var4`,我们只需使用一个掩码来将值设置为 `0x0000000000000000000000000000000000000000000000000000000000000001`。然后我们返回赋值为 1 的 `uint128`。在读取 `var5` 时,我们需要右移 `var4`。这留下了 `0x0000000000000000000000000000000000000000000000000000000000000002`,我们可以返回它。需要注意的是,有时你需要在读取值时同时进行移位和掩码处理,才能读取到一个 storage 插槽中打包的多个变量的值。
好的,我们终于准备好将 `var5` 的值改为 4 了!
function writeVar5(uint256 newVal) external {
assembly {
// 加载插槽 3
let slot3 := sload(3)
// 清除 var5 的掩码
let mask := 0x00000000000000000000000000000000ffffffffffffffffffffffffffffffff
// 隔离 var4
let clearedVar5 := and(slot3, mask)
// 格式化新值到 var5 的位置
let shiftedVal := shl( mul( var5.offset, 8 ), newVal )
// 将新值与隔离的 var4 组合
let newSlot3 := or(shiftedVal, clearedVar5)
// 将新值存储到插槽 3
sstore(3, newSlot3)
}
}
第一步是加载存储插槽 3。接下来,我们需要创建一个掩码。与读取 `var4` 时相似,我们希望隔离该值至 `0x0000000000000000000000000000000000000000000000000000000000000001`。下一步,我们将新值格式化为 `var5` 的插槽,使它看起来像 `0x0000000000000000000000000000000400000000000000000000000000000000`。与读取 `var5` 的情况不同,这次我们需要将我们的值向左移动。最后,我们将使用 `or()` 将我们的值合并为 32 字节的十六进制,并将该值存储到插槽 3。通过调用 `getValInHex(3)` 来检查我们的工作。它将返回 `0x0000000000000000000000000000000400000000000000000000000000000001`,这是我们期待看到的。
太好了,你现在知道如何读取和写入打包的存储插槽啦!
## 内存
好的,我们终于准备好学习内存系统了!
内存的行为与存储不同。内存不是持久的。意味着一旦函数执行结束,所有变量都会被清空。内存可以与其他语言的堆比较,但没有垃圾收集器。内存比存储便宜得多。内存的前 22 字的成本是线性计算的,但要小心,因为之后内存的成本变成了二次方。内存以 32 字节的序列布局。我们稍后会对此有更好的理解,但现在要了解的是 `0x00` - `0x20` 是一个序列(可以把它想象成一个插槽,尽管它们是不同的)。Solidity 将 `0x00` - `0x40` 分配为“临时空间”。这部分内存不能保证是空的,并用于某些操作。`0x40` - `0x60` 存储的是被称为“空闲内存指针”的位置,用于向内存写入新内容。`0x60` - `0x80` 是空的留位。`0x80` 是我们开始操作的地方。内存不会打包值。从存储中检索的值将存储在它们自己的 32 字节序列中(即 `0x80-0xa0`)。
内存用于以下操作:
- 外部调用的返回值
- 设置外部调用的函数值
- 从外部调用中获取值
- 以错误字符串回退
- 记录消息
- 使用 `keccak256()` 进行哈希
- 创建其他智能合约
以下是一些有用的 Yul 指令用于内存!
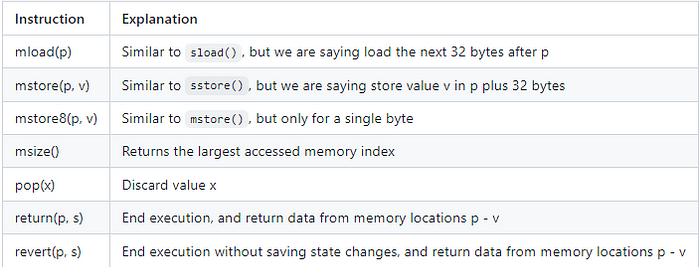
让我们检查一下更多的数据结构!
结构体和固定数组实际上行为相同,但由于我们在存储部分已有静态数组的讲解,所以我们在此查看结构体。看以下结构体。
struct Var10 { uint256 subVar1; uint256 subVar2; }
这没有什么不寻常,只是一个简单的结构体。现在让我们看一些代码!
function getStructValues() external pure returns(uint256, uint256) {
// 初始化结构体
Var10 memory s;
s.subVar1 = 32;
s.subVar2 = 64;
assembly {
return( 0x80, 0xc0 )
}
}
在这里,我们将 `s.subVar1` 设置为内存位置 `0x80` - `0xa0`,并将 `s.subVar2` 设置为内存位置 `0xa0` - `0xc0`。这就是我们要返回 `0x80` - `0xc0` 的原因。以下是每次事务结束前内存布局的表格。
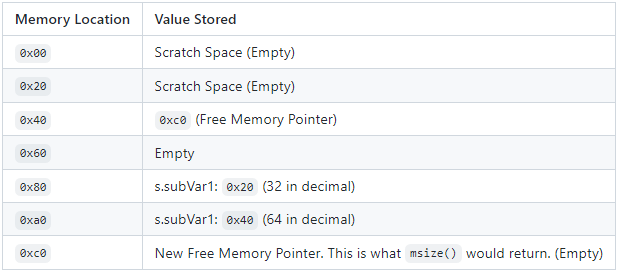
此部分需要记住:
- `0x00` - `0x40` 是空留位用于临时空间
- `0x40` 给予我们自由内存指针
- Solidity 为 `0x60` 留下了空间
- `0x80` 和 `0xa0` 用于存储结构体的值
- `0xc0` 是新的自由内存指针。
在内存部分的最后一部分,我想向你展示动态数组是如何在内存中工作的。我们将传递 `[0, 1, 2, 3]` 作为示例中参数 `arr`。作为该示例的附加功能,我们将向数组中添加一个额外的元素。在生产环境中执行时要小心,因为可能会覆盖另一个内存变量。下面是代码!
function getDynamicArray(uint256[] memory arr) external view returns (uint256[] memory) {
assembly {
// 数组存储在内存中的位置 (0x80)
let location := arr
// 数组的长度存储在 arr 中 (4)
let length := mload(arr)
// 获取下一个可用的内存位置
let nextMemoryLocation := add( add( location, 0x20 ), mul( length, 0x20 ) )
// 将新值存储到内存中
mstore(nextMemoryLocation, 4)
// 使长度加 1
length := add( length, 1 )
// 存储新的长度值
mstore(location, length)
// 更新空闲内存指针
mstore(0x40, 0x140)
return ( add( location, 0x20 ), mul( length, 0x20 ) )
}
}
在这里,我们做的是获取数组存储在内存中的位置。然后,我们获取数组的长度,数组长度存储在数组的第一个内存位置。要查看下一个可用的位置,我们向位置加 32 字节(跳过数组的长度),并将数组长度乘以 32 字节。在这里,我们将存储我们的新值(4)。接下来,我们按 1 更新数组长度。之后,我们还需要更新自由内存指针。最后,我们返回数组。
让我们再看看内存布局。
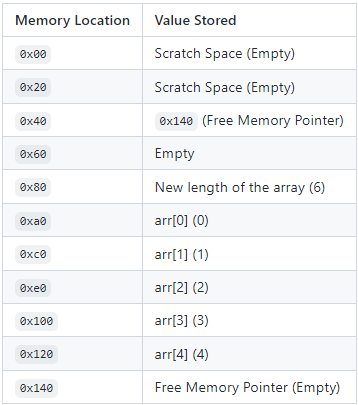
至此,内存部分的内容就结束了!
## 合约调用
在本文的最后一节中,我们将看看 Yul 中合约调用的工作原理。
在我们深入一些示例之前,我们需要先了解一些 Yul 操作。让我们看一下。
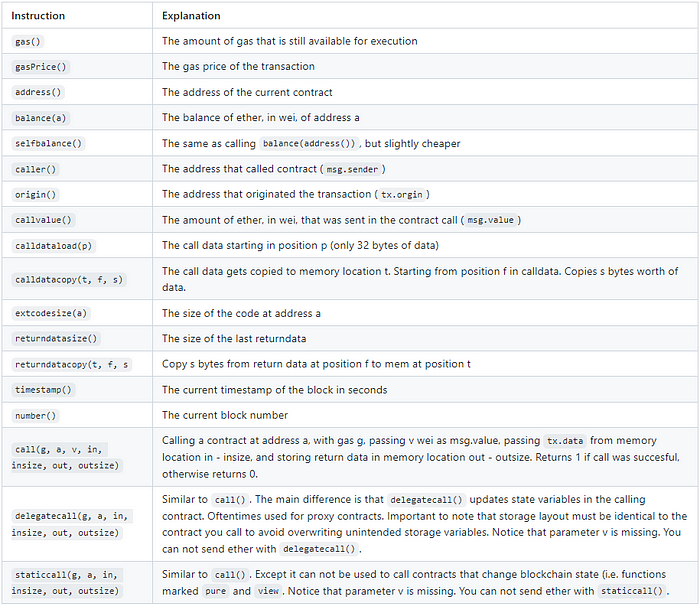
现在,让我们看一些新的合约做这些示例。首先,看看我们将要调用的合约。
pragma solidity^0.8.17;
contract CallMe {
uint256 public var1 = 1;
uint256 public var2 = 2;
function a(uint256 _var1, uint256 _var2) external payable returns(uint256, uint256) {
// 要求向合约发送了 1 ether
require(msg.value >= 1 ether);
// 更新 var1 和 var2
var1 = _var1;
var2 = _var2;
// 返回 var1 和 var2
return (var1, var2);
}
function b() external view returns(uint256, uint256) {
return (var1, var2);
}
}
这不是一个最先进的合约,但我们仍然会讨论它。这个合约有两个存储变量 `var1` 和 `var2`,分别存储在存储插槽 1 和 2。函数 `a()` 要求用户向合约发送至少 1 ether,否则将回退。接下来,函数 `a()` 更新 `var1` 和 `var2` 并返回它们。函数 `b()` 简单地读取 `var1` 和 `var2` 并返回它们。
在进入调用 `CallMe` 合约的合约之前,我们需要先理解函数选择器。让我们来看一下用于该交易的调用数据 `0x773d45e000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000002`。交易数据的前 4 个字节称为函数选择器(`0x773d45e0`)。这就是 EVM 知道你想要调用什么函数的方式。我们通过获取函数签名的字符串哈希的前 4 个字节来推导出函数选择器。所以函数 `a()` 的签名是 `a(uint256,uint256)`。计算这个字符串的哈希给我们 `0x773d45e097aa76a22159880d254a5f1db8365bc2d0f0987a82bda7dfd3b9c8aa`。看着前 4 个字节,我们可以看到它等于 `0x773d45e0`。可以注意到,签名中没有空格。这是重要的,因为添加空格将导致我们一个完全不同的哈希。你不需要担心从我们的代码示例中获取选择器,我将为你提供它们。
让我们开始查看存储布局。
uint256 public var1; uint256 public var2; bytes4 selectorA = 0x773d45e0; bytes4 selectorB = 0x4df7e3d0;
注意到 `var1` 和 `var2` 的布局与合约 `CallMe` 一样。你可能记得我说过,为了使 `delegatecall()` 正常工作,布局必须与我们的其他合约完全相同。不过,我们可以在末尾添加其他变量(`selectorA` 和 `selectorB`),这样可以避免任何存储冲突。
我们现在准备好进行第一次合约调用。让我们从一个简单的 `staticcall()` 开始。以下是我们的函数。
function getVars(address _callMe) external view returns(uint256, uint256) {
assembly {
// 从内存加载插槽 2
let slot2 := sload(2)
// 移位以去掉 selectorB
let funcSelector := shr( 32, slot2)
// 将 selectorB 存储到内存位置 0x80
mstore(0x00, funcSelector)
// 静态调用 CallMe
let result := staticcall(gas(), _callMe, 0x1c, 0x20, 0x80, 0xc0)
// 检查调用是否成功,否则回退
if iszero(result) {
revert(0,0)
}
// 从内存返回值
return (0x80, 0xc0)
}
}
我们需要做的第一件事是从存储中检索 `b()` 的函数选择器。我们通过加载插槽 2 来做到这一点(两个选择器打包在一个插槽中)。然后,我们右移 4 字节(32 位)以隔离 `selectorB`。接下来,我们将在临时内存中存储函数选择器。现在我们可以进行静态调用。我们为这些示例传入 `gas()`,但如果你愿意,你可以指定所需的 Gas 数量。我们传入合约地址 `_callMe`。`0x1c` 和 `0x20` 表示我们想传入我们之前存储的最后 4 字节。因为函数选择器是 4 字节,但内存是以 32 字节的序列进行工作的(同样,记得我们从右到左存储)。`staticcall()` 的最后两个参数指定我们要将返回数据存储在内存位置 `0x80` - `0xc0` 中。接下来,我们检查函数调用是否成功,否则我们返回空数据。记住,成功的调用将返回 1。最后,我们返回内存中的数据,并看到值 1 和 2。
接下来让我们看 `call()`。我们将调用 `CallMe` 中的函数 `a()`。记得向合约发送至少 1 ether!我将传入 3 和 4 作为 `_var1` 和 `_var2` 用于本示例。以下是代码。
function callA(address _callMe, uint256 _var1, uint256 _var2) external payable returns (bytes memory) {
assembly {
// 加载插槽 2
let slot2 := sload(2)
// 隔离 selectorA
let mask := 0x000000000000000000000000000000000000000000000000000000000ffffffff
let funcSelector := and(mask, slot2)
// 将函数选择器存储
mstore(0x80, funcSelector)
// 复制 calldata 到内存位置 0xa0
// 跳过函数选择器和 _callMe
calldatacopy(0xa0, 0x24, sub( calldatasize(), 0x20 ) )
// 调用合约
let result := call(gas(), _callMe, callvalue(), 0x9c, 0xe0, 0x100, 0x120)
// 检查调用是否成功,否则回退
if iszero(result) {
revert(0,0)
}
// 从内存返回值
return (0x100, 0x120)
}
}
好的,和我们刚才的示例类似,我们需要先加载插槽 2。这一次,我们将掩码 `selectorB` 来隔离 `selectorA`。现在我们将在 `0x80` 存储选择器。由于我们需要从调用数据中获取参数,我们将使用 `calldatacopy()`。我们告诉 `calldatacopy()` 在内存位置 `0xa0` 存储我们的调用数据。我们还告诉 `calldatacopy()` 跳过前 36 个字节。前 4 个字节是 `callA()` 的函数选择器,接下来的 32 个字节是 `_callMe` 的地址(我们稍后会用到)。我们告诉 `calldatacopy()` 存储的字节大小是调用数据的大小减去 36 个字节。现在我们准备好进行合约调用了。与上次一样,我们传入 `gas()` 和 `_callMe`。但是这次我们传入的调用数据从 `0x9c`(`0x80` 内存序列最后 4 字节)到 `0xe0`,将数据存储在内存位置 `0x100` - `0x120` 中。再次,检查调用是否成功并返回输出。如果我们查看 `CallMe` 合约,我们会看到值已成功更新为 3 和 4。
为了额外澄清一下发生了什么,以下是我们返回之前内存的布局。
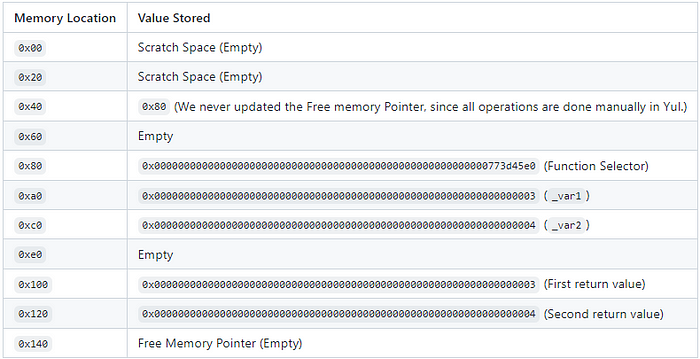
在最后一节中,我们将看 `delegatecall()`。代码将看起来几乎一样,但只有一个变化。
function delgatecallA(address _callMe, uint256 _var1, uint256 _var2) external payable returns (bytes memory) {
assembly {
// 加载插槽 2
let slot2 := sload(2)
// 隔离 selectorA
let mask := 0x000000000000000000000000000000000000000000000000000000000ffffffff
let funcSelector := and(mask, slot2)
// 将函数选择器存储 selectorA
mstore(0x80, funcSelector)
// 复制 calldata 到内存位置 0xa0
// 跳过函数选择器和 _callMe
calldatacopy(0xa0, 0x24, sub( calldatasize(), 0x20 ) )
//p
let result := delegatecall(gas(), _callMe, 0x9c, 0xe0, 0x100, 0x120 )
// 检查调用是否成功,否则回退
if iszero(result) {
revert(0,0)
}
// 从内存返回值 return (0x100, 0x120)
}
}
我们所做的唯一更改是将 `call()` 更改为 `delegatecall()`,并移除 `callvalue()`。我们不需要 `callvalue()`,因为 delegatecall 在它自己的状态中执行 `CallMe` 的代码。因此 `a()` 中的 `require()` 语句是检查是否有以太发送到我们的 `Caller` 合约。如果我们检查 `CallMe` 中的 `var1` 和 `var2`,我们会发现没有变化。然而,我们的 `Caller` 合约中的 `var1` 和 `var2` 已成功更新。
这结束了我们关于合约调用的部分,以及这份 Yul 的初学者指南。要进一步理解 Yul,请阅读 Yul 的文档和以太坊黄皮书,我将在下面提供链接。
Yul 文档: [https://docs.soliditylang.org/en/v0.8.17/yul.html](https://docs.soliditylang.org/en/v0.8.17/yul.html)
以太坊黄皮书: [https://ethereum.github.io/yellowpaper/paper.pdf](https://ethereum.github.io/yellowpaper/paper.pdf)
如果你有任何问题,或者希望我制作关于其他主题的教程,请在下方留言。
如果你想支持我制作教程,这是我的以太坊地址: 0xD5FC495fC6C0FF327c1E4e3Bccc4B5987e256794。
>- 原文链接: [medium.com/@MarqyMarq/be...](https://medium.com/@MarqyMarq/beginners-guide-to-yul-12a0a18095ef)
>- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,在这里修改,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
