以太坊数据 — 交易收据树和日志简化
- kikura3
- 发布于 2022-07-08 20:29
- 阅读 1877
本文深入探讨了以太坊中的交易收据Trie和日志结构,详细介绍了交易收据各个组成部分、它们的用途及其对智能合约的影响。系统阐述了日志的存储方式及如何通过事件日志进行有效的数据检索。此外,还解释了使用Trie结构的好处,特别是在轻客户端中如何实现高效的数据验证和查询。
以太坊数据 — 交易收据 Trie 和日志简化

交易收据包含交易结果(状态和日志),并以 Trie 结构组织。收据数据存储在状态数据库中,其根哈希存储在区块头中。收据 Trie 包含哪些信息?谁能够从中受益?让我们深入探讨这些问题。
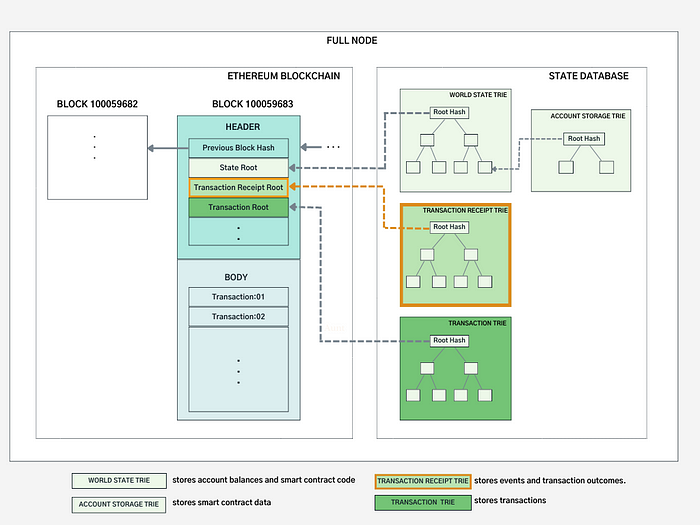
以太坊全节点 — 交易收据 Trie
智能合约以两种不同的方式在区块链中存储信息:账户存储和日志。账户存储包含任何定义智能合约状态的数据,且合约可以访问。日志用于存储合约不需要但必须被其他链外应用(前端、分析等)访问的信息。值得注意的是,日志存储比账户存储便宜得多。
考虑一个简单的Token合约,允许用户拥有不可替代(即唯一)Token,这些数据可以这样存储:
- Token所有权 → 账户存储:智能合约显然应该知道谁拥有哪个Token。为了使合约能够证明所有权并提供所有权转移功能,Token ID 和 Token所有者 应存储在账户存储中。
- Token所有权历史 → 日志:合约只需知道当前的Token所有权即可运作。然而,追踪Token的所有权历史对投资者或决策者显得很重要。这些信息可以在每次铸造或转移Token时记录到日志中。从而能够聚合日志以揭示这些洞察。
- 用户界面通知 → 日志:当Token被铸造(创建)时,前端应用可能希望向Token所有者展示确认和其他细节。由于交易是异步的,智能合约无法将值返回给前端。相反,当铸造发生时,可以将信息写入日志。前端随后可以监听通知并向用户展示。
- 链外触发器 → 日志:当你想出于各种原因将Token转移到另一个区块链(例如,玩构建在不同区块链上的游戏)时,你可以发起向公共网关的转移,该交易将记录转移。公共网关随后会提取该信息并在另一条链中铸造相应的Token。
当智能合约想要记录上述场景的数据时,可以发出事件(如下面所示),然后写入到交易收据的日志记录中。

简单的不可替代Token合约 — 事件
每个交易只有一个交易收据。除了日志记录,收据还包括状态、消耗的 Gas 和日志 Bloom,我们将在下面详细介绍。
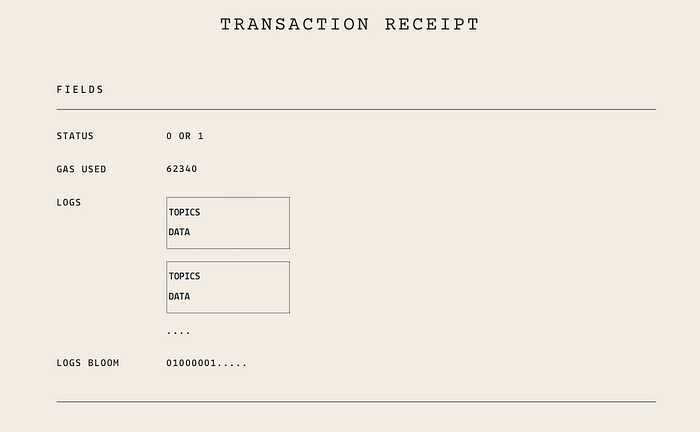
交易收据 — 字段
状态
状态为 0 或 1。它作为调用者判断交易是否成功的线索。由于交易是异步的,调用者需要等到区块被挖掘后才能从交易收据中读取状态。
💁 当交易被回滚(由于耗尽 Gas 或条件失败)时,所有事件也会被回滚。调用者只能读取状态,无法读取日志事件的信息,因为记录的事件也会被回滚。唯一了解发生了什么的方法是检查客户端节点的跟踪记录,里面包含执行的详细信息。消耗的 Gas
这是区块中所有先前交易(包括当前交易)消耗的全部 Gas。
日志
日志只是日志记录的集合。单个日志记录包括主题和数据。主题是一个列表,包含事件的签名以及任何索引字段。单个日志记录可以包含最多四个主题。主题的存储容量有限,并不推荐存储大量数据。通常,任何可能在日志搜索中出现的数据都应存储在主题中,因为它们是被索引的。其他信息存储在数据字段中。

交易收据 — 日志记录索引
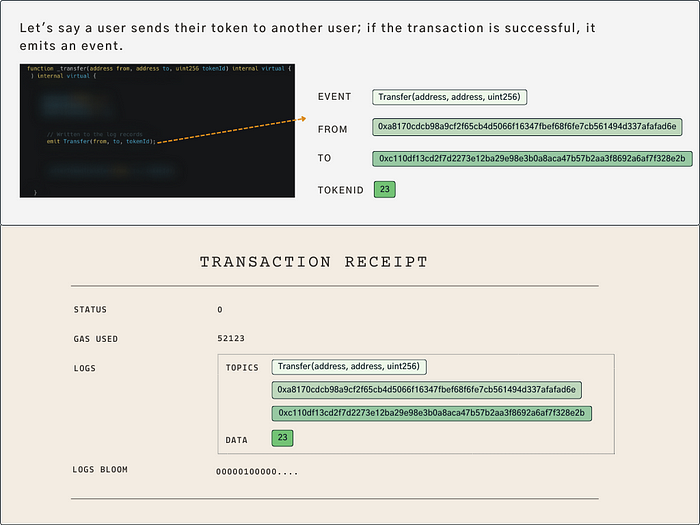
交易收据 — 日志记录创建
由于字段 事件名称, from, to 被索引,以下查询可以高效检索:
- 列出今天发生的所有Token转移。
- 返回该用户(钱包地址)在过去一小时内出售的所有Token。
- 获取该用户在上周购买的所有Token列表。
然而,由于 tokenId 未被索引并存储在 data 字段中,任何查询检查 “今天有哪个 tokenId 的转移吗?” 将会非常缓慢。
由于索引所需的额外计算,存储在主题中比存储在数据字段中稍微贵一点。让我们看看下面的章节如何进行索引。
日志 Bloom
假设我们想要
找到在特定区块中由特定用户(钱包)出售的所有Token。
我们可以解析日志来回答这个问题,因为“from”地址被捕获。然而,为了确定这一点,我们必须在区块中的所有交易中进行搜索。
考虑到该区块包含 500 个交易,我们的搜索需要遍历所有交易的所有日志记录(主题和数据)。我们能否为每个交易创建一个字段,指示我们所寻找的信息是否存在于该笔交易的日志中?Bloom Filter。
在进一步讨论之前,让我们通过一个简单的列表搜索示例来看一下 Bloom Filter。假设我们想知道某个用户是否存在于给定列表中。最简单的方法是遍历列表。但是,如果列表包含数千个用户,这将变得过于昂贵并且非常缓慢。为了提高搜索效率,我们可以通过哈希和映射列表中的每个用户来创建一个高效的索引,如下所示。

Bloom Filter 构造 — 简化
正如你可能注意到的,Bloom Filter 是通过取各个哈希的并集创建的。假设我们想知道 Xin、Kia 和 Eva 是否在列表中。 在不查询列表的情况下,我们可以利用 Bloom Filter 得到答案。
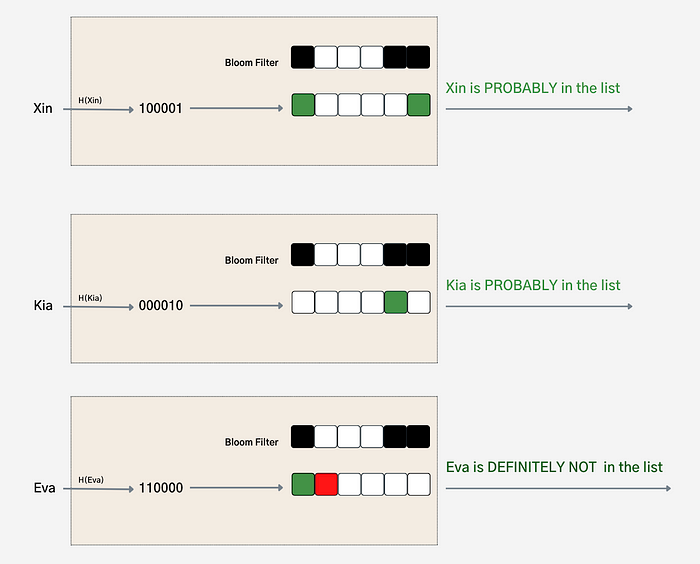
Bloom Filter 搜索 — 简化
Bloom Filter 是一种概率数据结构,可以表示“可能存在”或“确定不存在”。在这种情况下,Bloom Filter 不太适合确定 Xin 或 Kia 是否在列表中。要找出这一点,我们必须实际查询列表。然而,对于 Eva,它提供了明确的答案:她不在该列表中。Bloom Filter 极其有用,尤其是在你预期大多数答案为“确定不在”的情况下。
让我们回到在某个区块中查找特定用户出售的Token的例子。假设该事件在该特定的 500 个交易的区块中发生了两次。我们可以查询日志 Bloom(由主题生成),查看用户地址是否存在,而只在匹配时进行主题搜索,否则跳过下一个交易。
除了交易级别的日志 Bloom,EVM 会将每个交易的日志 Bloom 结合并在头部创建一个日志 Bloom。假设我们需要搜索相同的查询(特定用户出售的Token),但跨多个区块。我们不仅仅查询每个区块中每个交易的 Bloom,而是可以简单地查询头部的 Bloom。如果匹配,则继续查询交易日志 Bloom,否则跳过下一个区块。因此,Bloom Filters 有助于提高搜索效率。
为什么使用 Trie 结构
现在我们知道什么是交易收据,我们需要了解为什么它组织成 Trie 结构。
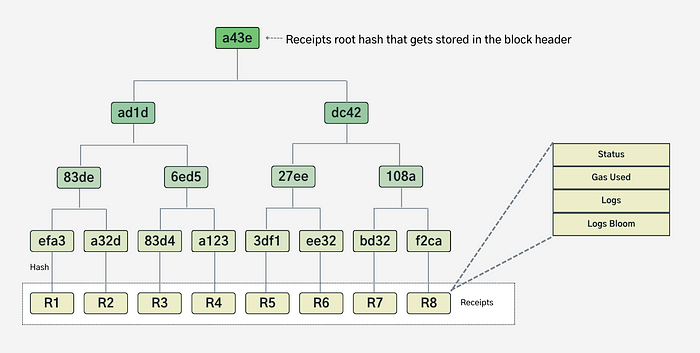
交易收据 Trie — Merkle
这种 Trie 构造的目的是使以太坊协议对轻客户端友好。因为轻客户端只存储区块头,所以必须向全节点请求查询,例如“检索钱包 X 在过去的 n 天内涉及的所有交易.”。由于区块链的固有假设是没有节点可以被信任,因此轻节点需要从全节点获取附加证明,这些结果被组织成 Merkle 树结构,从而允许通过网络有效地分发证明。这个 文章 有详细解释。
我希望这篇文章能让你对以太坊区块链中的交易收据 Trie 和事件日志有更好的理解。将在我未来的帖子中详细拆解 EVM 跟踪记录。如果你想在那篇帖子发布时接收到通知,请确保关注。如果有任何问题或评论,请随时联系我。 Twitter | LinkedIn
- 原文链接: medium.com/coinmonks/eth...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





