钻石标准介绍,EIP-2535 钻石
文章详细介绍了EIP-2535 Diamonds标准的概念和实现,解决了以太坊智能合约的24KB大小限制,并提供了一种组织和扩展智能合约系统的新方法。文中包含了关于如何避免智能合约存储变量冲突的详细策略,及其在ERC721代币实现中的应用实例,适合对以太坊智能合约开发有一定基础的读者。
在2018年,我正在实现一个ERC721代币,该代币能够拥有/占有/控制其他ERC721代币和ERC20代币。为此,我遵循了ERC998可组合非同质化代币标准,这是ERC721的一个扩展。
我需要实现ERC721函数和ERC998函数,以及一些实现自定义功能的函数。
我发现自己无法做到这一点,因为我遇到了24KB的最大合约大小限制。Solidity合约会被编译成字节码,这些字节码会被部署并存储在以太坊网络上。如果合约的字节码超过24KB,那么它将被以太坊网络拒绝。
有很多方法可以减少智能合约的字节码,例如缩小错误信息,调整编译器优化设置及使用Solidity库的外部函数。
其中一些选项我不想采用,有些选项则帮助不够。此外,如果我需要太多外部函数,这些解决方案没有解决问题,因为外部函数会增加字节码。
或许我可以创建一个第二个合约来保存一些ERC721代币所需的外部函数和状态变量。但对于我来说,让ERC721代币的一些函数和状态分割到另一个合约中是没有意义的,这将增加管理ERC721代币在两个或更多合约中存在的状态的复杂性。
我希望有一个存储空间来存放所有状态变量,并且有一个以太坊地址,能够设计和实现没有字节码大小限制的所有功能。我希望所有功能能够直接、方便地读取和写入状态变量,以相同的方式进行操作。如果能够拥有可选的、无缝的升级功能:能够替换函数、删除它们,并添加新功能,而不需要重新部署所有内容,那就太好了。能够在部署后,以一致、系统的方式扩展智能合约系统。
经过大量的工作、反馈、帮助和经验,我们有了EIP-2535 Diamonds及其参考实现。这是一个最终的以太坊智能合约标准。许多项目已经在生产中实现了EIP-2535,并且有一系列的安全审计。
什么是钻石
对于外部世界(如用户界面、其他智能合约和软件/脚本)来说,钻石看起来像一个具有单一以太坊地址的单一智能合约。但在内部,其利用一组称为“切面”(facets)的合约来处理其外部函数。
当另一个智能合约或用户界面等外部软件程序对钻石进行函数调用时,钻石会检查是否有包含该函数的切面,并在存在时使用它。
了解这些内容,可以理解钻石:
-
钻石是一个智能合约。其以太坊地址是外部软件与之交互的单一地址。
-
从内部来看,钻石使用一组称为切面的合约来实现其外部函数。
-
所有状态变量存储数据都存储在钻石中,而不是在其切面中。
-
切面的外部函数可以直接读取和写入存储在钻石中的数据。这使得切面的编写简单且gas高效。
-
钻石是通过一个fallback函数实现的,该函数使用delegatecall将外部函数调用路由到切面。
-
钻石通常没有自己的外部函数——它使用切面处理外部函数,这些函数读取/写入其数据。
EIP-2535指定了添加/替换/移除函数和切面的机制和合约接口,以及检查钻石以找出其具有的函数和切面,以及记录升级的接口。EIP-2535使得能够编写与任何和所有钻石协同工作或集成的软件。
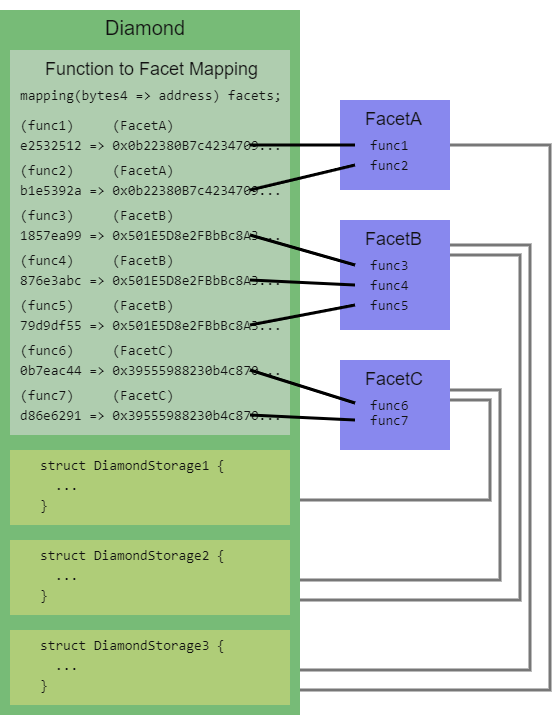
以下是一些图像,帮助可视化钻石。第一张图显示如何将函数映射到存放函数代码的切面:
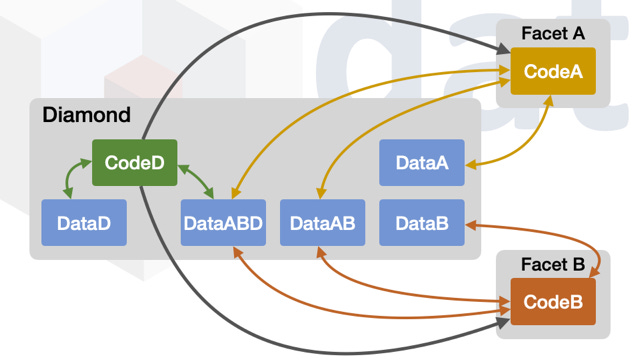
下一张图显示所有状态变量数据存储在一个钻石代理合约中,并且钻石使用的代码来自切面。请记住,切面中的代码可以定义具有状态变量的结构体,但所有存储的值都存储在钻石代理合约中,而不是在切面中。这张图还显示切面可以在钻石代理合约中具有自己的数据,并且还可以与其他切面共享数据。这张图仅为示例。
组织钻石的切面
切面可以像文件系统一样进行组织。文件系统通常被组织如下:
-
相关且类似的数据放在同一个文件中。
-
相关且类似的文件放在同一个文件夹中。
-
相关且类似的文件夹放在同一个父文件夹中。
钻石的切面可以类似地组织:
-
类似且相关的函数可以放在同一个切面中。
-
类似且相关的切面可以放在同一个文件夹中。
-
类似且相关的文件夹可以放在同一个父文件夹中。
例如,在实现ERC721代币时,来自ERC721标准的外部函数可以在同一个'ERC721Facet'中实现,而自定义功能可以放在另一个切面中。
即使24KB的最大合约大小限制被取消,我仍然会使用EIP-2535 Diamonds,因为它提供了一个系统化的方式来组织、升级和扩展智能合约系统。
最初,EIP-2535 Diamonds的创建是为了解决24KB合约限制,但事实证明它的用途超出了这一点。它提供了一个构建更大智能合约系统的框架,并且合约系统可以在生产中不断增长。
保持数据正确
Solidity使用数字地址空间在合约中存储数据。第一个状态变量存储在位置0,第二个状态变量存储在位置1,依此类推。
钻石的切面共享相同的存储地址空间,因为它们具有相同的钻石,切面只读取和写入钻石中的状态变量,而不在其自身中。如果你不理解这一点,你需要理解delegatecall是如何工作的,因为所有切面的外部函数都是通过从钻石的delegatecall调用的。
如果处理不当,这将成为一个问题。例如,假设一个钻石有两个切面:FacetA和FacetB。假设FacetA声明状态变量'uint first;'和'bytes32 second;',而FacetB声明状态变量'uint first;'和'string name;'。
两个切面都在位置0存储`uint first`,所以两个切面都可以毫无问题地读取和写入该变量。
但是两个切面在位置1读取和写入不同的内容——'bytes32 second'和'string name'。它们在位置1上相互干扰,或搞砸了对方的数据,因为它们以不同的数据解释和写入位置1的信息。这就是为什么同一钻石的切面需要按照相同顺序声明相同状态变量的原因,如果它们在同一位置上读取和写入。
需要存在策略,以便于切面以相同顺序声明相同的状态变量。如果有好的策略,这实际上并不是一个问题,即使在升级情况下。
继承存储
一种简单的策略是创建一个合约,声明所有切面使用的状态变量。它可以被称为'Storage'或其他名称。然后可以被每个切面继承。这种策略有效,并且在生产中成功地使用过。但是它有局限性,在我看来,我发现了一个相似但更好的策略。
继承存储的局限性在于,它阻止了切面的重用。如果你部署了一个使用继承存储的切面,那么你可能无法在具有不同状态变量的不同钻石中重新使用该已部署的切面。
在我看来,另一个局限性是意外将内部函数或局部变量命名为状态变量相同名称的几率太高而发生名称冲突。尤其是在具有100个或更多状态变量的大型钻石中。但是或许可以通过使用防止此类命名冲突的代码命名约定来克服这一点。
钻石存储
如果切面在不同位置上存储数据,实际上同一钻石的不同切面并不需要以相同的顺序声明相同的状态变量。
如前所述,Solidity自动在存储位置0开始存储状态变量并逐个递增。但是,我们并不一定要使用Solidity的默认存储布局机制。我们不必从位置0开始存储数据。我们可以指定在地址空间中开始存储数据的位置。对于不同切面,我们可以指定不同位置来存储数据,因此可以防止具有不同状态变量的不同切面发生存储位置的冲突。这就是钻石存储的作用。
我们可以将一个唯一字符串哈希化以获取随机存储位置并在此位置存储一个结构体。这个结构体可以包含我们想要的所有状态变量。唯一字符串可以作为特定功能的命名空间。
例如,我们可以实现一个ERC721Facet。这个切面可以在'keccak256("com.myproject.erc721");'位置存储一个名为'ERC721Storage'的结构体。该结构体可以包含与ERC721相关的所有状态变量,这些状态变量由ERC721Facet读取和写入,而与其他内容无关。这具有几个不错的优势。其中之一是ERC721Facet是可重用的。ERC721Facet可以仅部署一次,已部署的ERC721Facet可以与多个使用不同状态变量的不同钻石一起使用。另一个好处是ERC721Facet没有杂乱无章地包含它不使用的状态变量声明。
钻石存储的另一个好处是,Solidity库的内部函数可以像任何切面函数一样访问钻石存储。Solidity库是不同切面之间共享内部函数的好方法。我写了一篇关于与钻石存储一起使用Solidity库的博客文章: Solidity Libraries Can't Have State Variables -- Oh Yes They Can!
钻石存储对于创建可重用的切面尤为有用。这些切面只需部署一次,便可由许多不同的钻石重用。当前的钻石参考实现对于DiamondCutFacet、DiamondLoupeFacet和OwnershipFacet切面使用钻石存储。这些可以仅部署一次,并被许多不同的钻石使用。
有关钻石存储的更多信息和其他代码示例,请参见这篇博客文章:钻石存储是如何工作的。我还推荐阅读理解以太坊上的钻石。
AppStorage
AppStorage类似于继承存储,但它解决了名称冲突问题——意外命名为状态变量的内容与内部函数或局部变量相同名的问题。尽管这似乎是一个微不足道的问题,但在实践中,我发现它非常好,因AppStorage还以更便于浏览和阅读的方式区分代码。如果你关心代码可读性,你会喜欢AppStorage。
AppStorage强制实施了一种命名或访问约定,确保状态变量的命名不会与其他内容发生冲突。
一个名为AppStorage的结构体被写入一个Solidity文件。AppStorage结构体包含将在切面之间共享的状态变量。为使用它,切面导入AppStorage结构体,并在切面中声明`AppStorage internal s;`作为第一个也是唯一的状态变量。然后,切面通过结构体如`s.myFirstVariable`、`s.mySecondVariable`等在函数中访问所有状态变量。以下是一个示例:
// AppStorage.sol
struct AppStorage {
uint256 secondVar;
uint256 firstVar;
uint256 lastVar;
...
}
// StakingFacet.sol
import "./AppStorage.sol"
contract StakingFacet {
AppStorage internal s;
function myFacetFunction() external {
s.lastVar = s.firstVar + s.secondVar;
}
}
重要的是,在使用它的所有切面中,`AppStorage internal s;`被声明为第一个和唯一的状态变量。这使得在存储地址空间中的位置为0。因此,如果所有切面将其声明为第一个和唯一的状态变量,那么切面之间的存储数据将正确对齐。切面中请不要直接添加更多状态变量,因为这将与在AppStorage结构体中声明的状态变量冲突。如需添加更多状态变量,请将它们添加到AppStorage结构体的末尾或使用钻石存储。
AppStorage的使用比钻石存储更为便利,因为在每个函数中,钻石存储要求获取指向结构体的指针,而在AppStorage中,`s`结构体指针在整个切面中自动可用。
AppStorage相较于继承存储的另一优势在于,AppStorage可以被Solidity库以与钻石存储相同方式访问。AppStorage结构体始终存储在位置0,因此,Solidity库中的内部函数可以利用这一点来初始化‘s’存储指针,以指向AppStorage结构体。以下是一个示例:
//LibAppStorage.sol
struct AppStorage {
uint256 secondVar;
uint256 firstVar;
uint256 lastVar;
...
}
library LibAppStorage {
function diamondStorage()
internal
pure
returns (AppStorage storage ds) {
assembly {
ds.slot := 0
}
}
function myLibraryFunction() internal {
AppStorage storage s = LibAppStorage.diamondStorage();
s.lastVar = s.firstVar + s.secondVar;
}
function myLibraryFunction2(AppStorage storage s) internal {
s.lastVar = s.firstVar + s.secondVar;
}
}
对AppStorage结构体的存储指针也可以作为参数传递给库函数,如上面的`myLibraryFunction2`函数所示。
AppStorage可以与合约继承一起使用。这是通过在合约中声明'AppStorage internal s;'来做到的。然后,使用AppStorage的所有切面继承该合约。
AppStorage对于应用或项目特定的切面特别有用,这些切面不会在使用不同存储的不同钻石之间被重用。AppStorage可以与钻石存储在同一切面中一起使用,这种做法是常见的。
AppStorage在普通智能合约中也很有用,因为它使代码更具可读性,并防止名称冲突。
查看这篇关于AppStorage的博客文章以获取更多信息:Solidity中的状态变量AppStorage模式
钻石部署
通过在钻石的构造函数中添加至少一个切面来添加‘diamondCut’或其他升级功能,完成钻石的部署。一旦部署,可以使用升级功能添加更多切面。
可以通过在钻石构造函数中添加钻石将永远拥有的所有切面,并且不添加任何形式的升级功能来创建‘单切钻石’。这种类型的钻石是不可升级的。
这里有一个脚本链接,展示如何部署一个钻石:https://github.com/mudgen/diamond-3-hardhat/blob/main/scripts/deploy.js
钻石升级
EIP-2535 Diamonds指定了‘diamondCut’函数,该函数用于在一次交易中添加/替换/移除任意数量的切面和功能。在执行升级时,在单个交易中操作是重要的,确保钻石随时不会处于不一致状态。
‘diamondCut’函数也可以选项性地在升级时通过delegatecall执行任意外部函数。这是为了初始化状态变量或进行需要的升级变更。
这里有一个测试脚本链接,展示了各种钻石升级示例:https://github.com/mudgen/diamond-3-hardhat/blob/main/test/diamondTest.js
保持状态变量安全
在升级过程中,重要的是不损坏状态变量。在升级过程中正确处理状态变量非常简单。
可以做以下事项:
-
要添加新的状态变量到AppStorage结构体或钻石存储结构体,请将它们添加到结构体的末尾。这是合理的,因为现有的切面无法覆盖新存储位置的状态变量。
-
可以将新的状态变量添加到用于映射的结构体的末尾。
-
状态变量的名称可以更改,但如果不同切面使用相同存储位置的不同名称,那可能会造成混淆。
请勿进行以下操作:
-
如果使用AppStorage,则不要在AppStorage结构体之外声明和使用状态变量。除了钻石存储可以使用。
-
不要将新的状态变量添加到结构体的开头或中间。这会使新状态变量覆盖现有状态变量数据,而所有在新状态变量之后的状态变量将引用错误的存储位置。
-
不要直接将结构体放入结构体中,除非你不打算在内部结构中添加更多状态变量。你将无法在升级中向内部结构添加新状态变量。这是合理的,因为结构体占用固定数量的存储位置。在内部结构中添加新的状态变量会导致下一个状态变量在内部结构之后被覆盖。在映射中使用的结构体可以在升级时扩展,因为这些结构体随机存储在基于keccak256哈希的存储位置中。
-
不要将新的状态变量添加到用于数组的结构体中。
-
使用钻石存储时,不要为不同结构体使用相同的命名空间字符串。这是显而易见的。在同一位置的两个不同结构体将相互覆盖。
-
不要允许任何切面能够调用`selfdestruct`。这很简单。只需确保在任何切面源代码中不存在`selfdestruct`命令,且不允许通过delegatecall调用该命令。因为`selfdestruct`可能会删除钻石使用的切面,或者`selfdestruct`也可能被用来删除一个钻石代理合约。
如果你理解Solidity是如何将存储位置分配给状态变量的,这些规则将是合理的。我强烈建议阅读并理解Solidity文档中的这一部分:存储中的状态变量布局
下面是一个文章链接,展示将新状态变量添加到钻石的示例:
关于钻石升级工作的更详细信息可以在这篇文章中找到:钻石升级是如何工作的
使用Loupe函数检查钻石
Loupe是一种特殊的放大镜,用于查看和检查钻石。
EIP-2535 Diamonds指定了四个标准函数,用于展示一个钻石拥有的切面和函数。这些被称为loupe函数。有关loupe函数的更多信息请看这里:钻石Loupe函数
louper.dev是一个用于显示钻石信息和执行其功能的网站。
钻石术语是什么?
这是一种概念模型。真实的物理钻石具有不同的侧面、不同的切面。以太坊钻石同样具有不同的侧面、切面,以及相关函数的集合。在获得实现钻石的经验后,你的思维将区分与公共核心紧密关联的不同函数集合 - 以太坊地址和钻石的状态。在某种程度上,这类似于物理钻石的切面连接到共同的中心。
有时,升级被称为cut。对物理钻石不熟悉的人可能会好奇,作为一种非常坚硬的物质,钻石是如何被切割的。但这就是零售钻石是如何制作的。它们被物理切割以制作或增加切面。
Loupe是一种特殊的放大镜,用于查看和检查钻石。
开始制作自己的钻石
使用一个现有的钻石实现来开始制作你的钻石。
这是一篇包含钻石实现的智能合约安全审计列表的博客文章:EIP-2535 Diamonds实现的智能合约安全审计
了解更多
订阅此博客:
订阅
加入EIP-2535 Diamonds Discord:https://discord.gg/kQewPw2
在推特上关注我并与我交流:https://twitter.com/mudgen
推荐阅读
?
- 原文链接: eip2535diamonds.substack...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
