Sig Engineering - 第四部分 - Solana 账本和区块存储
- syndica
- 发布于 2024-11-28 11:37
- 阅读 1995
本文深入探讨了Solana区块链的账本结构,包括其设计动机、组成部分(如区块和Shreds),以及它如何作为Solana区块链的骨干发挥作用。
本文是我们定期发布的、概述 Sig 工程更新的系列博客文章的第 4 部分。你可以在这里找到其他 Sig 工程文章。
区块链技术通过引入一种在设计上具有固有安全性和可信度的方法,彻底改变了我们记录信息的方式。任何区块链系统的核心都是账本,它确保了数据的完整性、透明性和安全性。在所有区块链中,Solana 以其无与伦比的速度和可扩展性而脱颖而出。Solana 账本是其性能的核心,它不仅是交易的记录,还是一个经过精心调整以最大限度提高性能的去中心化数据库。
在这篇博文中,我们将探讨 Solana 的账本。我们将揭示其设计背后的动机,剖析其组件,如区块和 shreds,并了解它如何作为 Solana 区块链的支柱发挥作用。在我们的下一篇博文中,我们将扩展本文以解释我们如何在 Sig 中实现 Solana 的账本。
如果你想知道来自 Syndica 的 Sig 验证器客户端是什么,请查看我们的介绍性博文。
背景:Solana
Solana 的核心职责是存储信息、分发信息和允许更改该信息。这意味着 Solana 是一个数据库。区块链与传统数据库的区别在于其独特的数据存储方法以及该方法如何解锁去中心化的信任。
Solana 存储两种类型的信息:账户和交易。
账户就像你电脑上的文件。它们回答了这个问题:“现在存在什么信息?”一个账户可能包含诸如“我有 100 美元”或“我被允许在治理中投票”之类的信息。AccountsDB 是 Sig 中负责存储账户的组件。之前,我们发布了一篇关于 AccountsDB 的深入博文。
交易回答了这个问题:“信息是如何随时间变化的?”一笔交易可能包含诸如“我付给某人 100 美元”或“我提交了一项提案的投票”之类的信息。交易存储在一个区块链中,这就是 区块链 这个词的由来。
?
注意: 在本文中,我们将使用诸如“验证器客户端”、“节点”和“RPC”之类的术语。有关所有这些术语的背景知识,请查看我们的验证器解释文章。
Solana 的账本
在 Solana 中,账本是一个包含每笔交易历史记录的数据库。
为了促进共识,大量交易被组合在一起形成区块。这引入了一个潜在的网络延迟问题,因此 Solana 将它们分成更小的部分,称为 entries 和 shreds,我们将在下面的 传播区块:Entries 和 Shreds 部分中探讨。
Solana 验证器的几乎每个组件都使用账本。例如,当用户搜索交易状态时,RPC 服务需要从账本中读取信息。许多其他组件,如共识、Turbine、Gossip 和历史证明,也使用账本。
交易
一笔交易代表对存储在 Solana 账户中的信息的任何更改。让我们更精确地定义什么是交易,它来自哪里,以及它做什么。
组成
一个交易是一条消息,其中包含描述状态应如何更改的指令和授权这些更改的签名。
pub const Transaction = struct {
signatures: []const Signature,
message: Message,
}
pub const Message = struct {
header: MessageHeader,
account_keys: []const Pubkey,
recent_blockhash: Hash,
instructions: []const CompiledInstruction,
}
每个指令都是一个请求,要求特定的 Solana 程序对当前保存在账户中的信息进行修改。将指令捆绑在一起可确保它们将以原子方式按顺序执行。原子执行是全有或全无:这意味着_每个_ 指令都需要成功完成,否则整个交易失败并且不进行任何更改。
每个签名是由私钥生成的密码学授权,通常由钱包管理。签名授权支付交易费用,并且 Solana 程序使用它们来决定正确的用户是否已批准每条指令。这可以防止用户对其不应访问的账户进行更改。
生命周期
当用户发起旨在导致链上更改的操作时,例如在去中心化交易所将 USDC 兑换为 SOL,Solana 交易就开始了。交易所生成一个未签名的交易,该交易被发送到用户的钱包以供批准。在用户批准后,钱包使用用户的私钥对其进行签名,并使用 sendTransaction 将其发送到 RPC 节点。RPC 节点将已签名的交易转发给领导者进行处理。
领导者是负责生成下一个区块的 Solana 验证器节点。它执行交易的指令,从而导致状态更改。它使用这些更改更新 AccountsDB,并将包含此交易的区块存储在其账本中。然后,它使用 Turbine 协议在网络上广播该区块。
![]() ? 点击图片放大
? 点击图片放大
其他验证器接收该区块并将其存储在他们的账本中。他们执行区块中的交易以验证其有效性,此过程称为 replay。如果三分之二的验证器同意结果,则该区块将被最终确定,并且状态更改将变为永久性。否则,该区块将被丢弃。
用户可以使用交易签名在 Solscan 等平台上跟踪他们的交易。该平台使用 getTransaction 查询 RPC 节点,并且 RPC 节点在其账本中查找该交易。验证器最终会删除旧交易以节省空间,因为截至本文撰写之日,整个账本已经有数百 TB。一旦一个 epoch 完成,一个名为 Old Faithful 的单独应用程序会将其存档在 Filecoin 上,整个账本可在那里公开访问并永久存储。
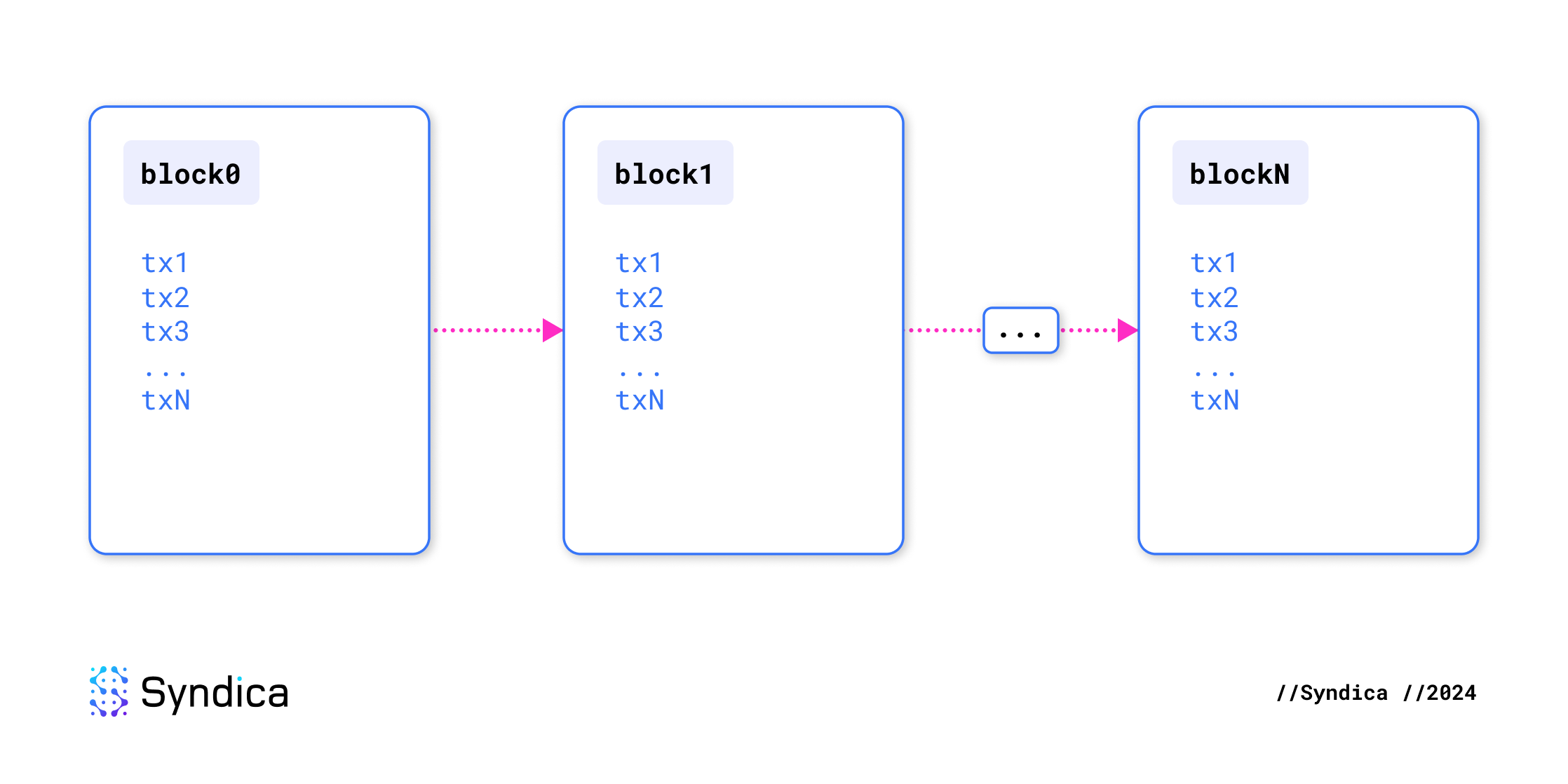
区块
区块链账本是一系列区块,每个区块包含一系列交易。因此,区块链本质上只是一系列交易。最初,区块链是空的,不存储任何信息。交易会逐渐添加或删除数据,并且它们的顺序对于确定任何给定时间的状态至关重要。它不仅仅是一组区块,而是一个有序的指令序列。
与交易一样,区块也是原子的:它们要么作为一个整体被接受,要么被拒绝。如果 лидер 提出的区块中甚至包含一个不正确的交易,则整个区块将被拒绝。
 ? 点击图片放大
? 点击图片放大
为什么存在区块?
区块对交易进行分组以简化共识。如果没有区块,对每笔交易单独达成共识将通过大量的投票压垮网络带宽。高频率还会导致分叉并可能导致网络停止。
为了有效地对多个交易达成共识,我们将一组间隔(在 Solana 中为 400 毫秒)内的所有交易捆绑到一个区块中。这减少了网络需求并最大限度地减少了分叉条件,从而确保了可靠的运行。
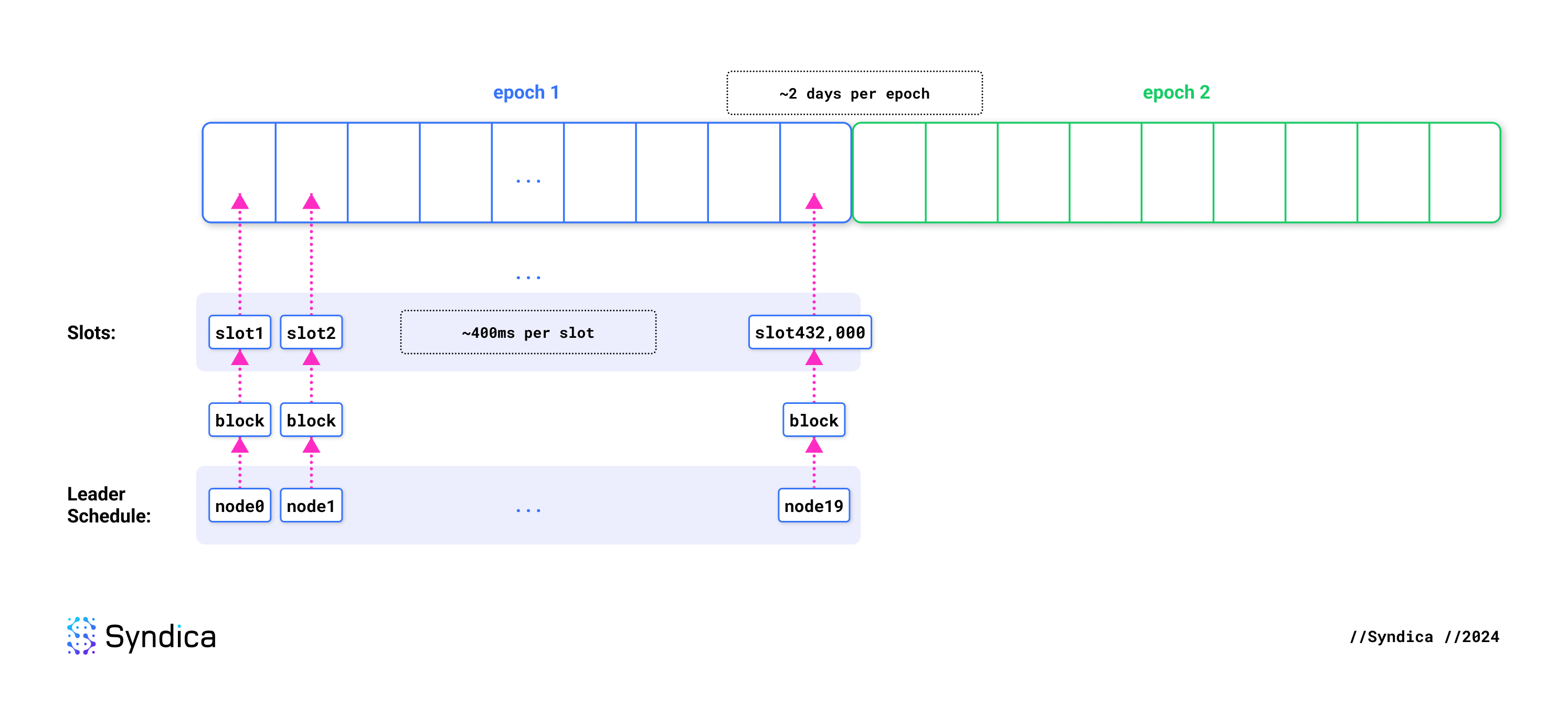
如何创建区块?
Slot 是指预期恰好产生一个区块的时间单位。每个 slot 持续约 400 毫秒。Epoch 是 432,000 个 slot 的集合,持续约两天。
在每个 epoch 开始时,会生成一个领导者计划表,根据验证器的权益大小将 slot 分配给验证器。当验证器被指定为某个 slot 的领导者时,它负责生成该 slot 的区块。当该 slot 到达时,所有交易都会转发给该验证器。它会收集并执行尽可能多的交易,随意决定包含哪些交易以及如何对其进行排序。
 ? 点击图片放大
? 点击图片放大
传播区块:Entries 和 Shreds
Solana 的一个独特方面是如何优化区块以减少传播过程中的网络延迟。区块被分成更小的部分,称为 entries,entries 又被进一步分解为 shreds。
传统的区块生产
大多数区块链系统将区块作为单个单元生成。在创建一个区块后,下一个区块生产者必须接收它、处理它,然后在它之上构建下一个区块。这会导致显着的延迟和性能瓶颈,因为其他节点必须等待接收整个区块,然后才能处理任何交易。
回想一下,区块的存在是为了共识。它们必须在时间上足够远,否则共识就会失败。如果区块产生的太快,一些节点将没有时间在下一个区块到达之前处理它们。这将导致对存在哪些区块产生分歧,从而导致分叉。最好的情况是,分叉会被丢弃,从而损害可靠性和延迟。最坏的情况是,共识失败,导致网络停止。
因此,出现了一种正反馈机制。在生成下一个区块之前等待完整的区块需要更长的时间间隔,从而导致更大的区块和更长的处理时间,最终稳定在高区块时间。
Solana 区块生产
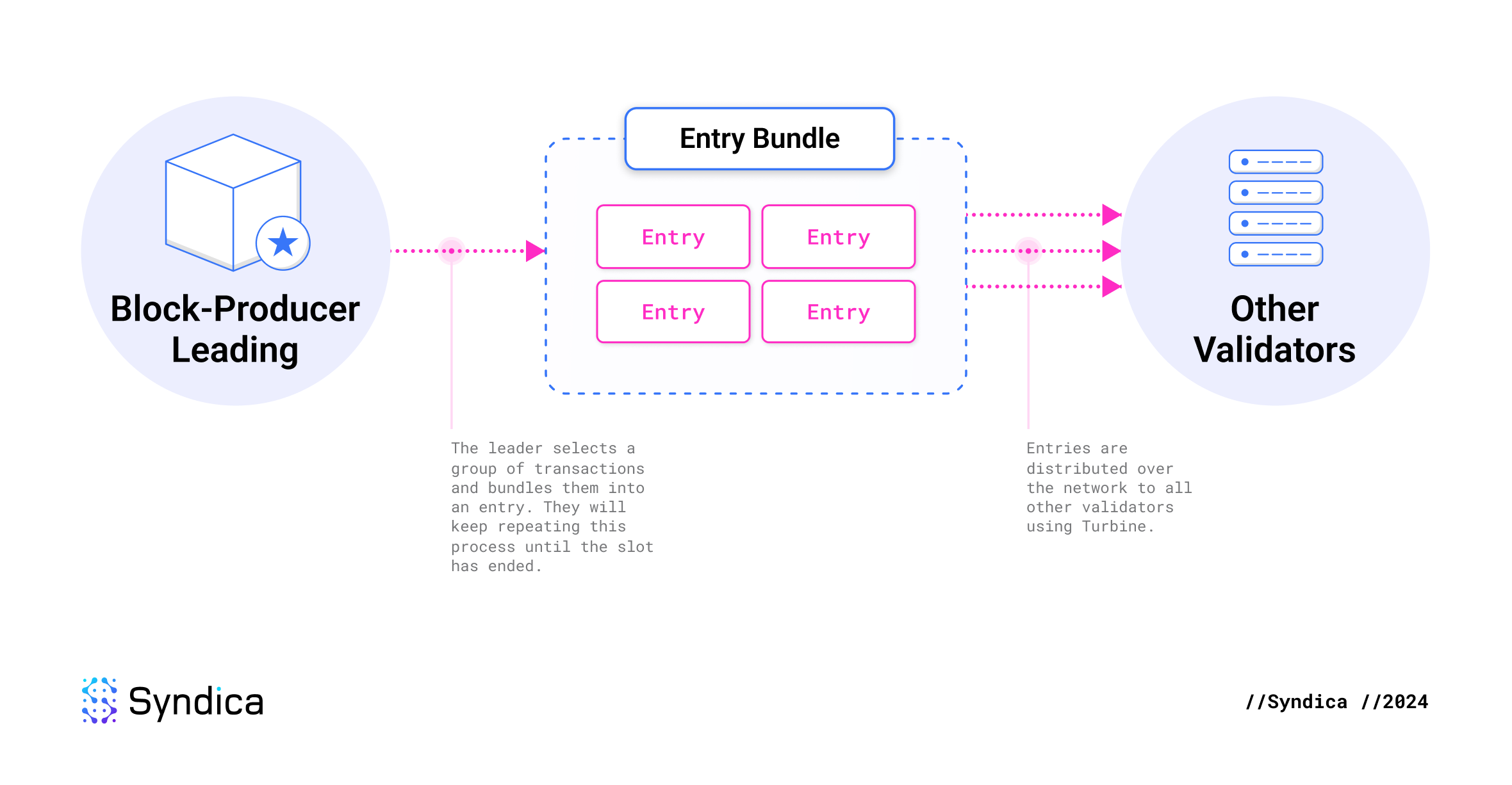
Solana 采取了不同的方法。在 Solana 中,每个节点在区块完全生成之前就开始处理区块中的交易。这怎么可能?
Solana 的创新之处在于,在构建区块时,领导者会持续流式传输交易。当领导者选择一些交易包含在其区块中时,它_立即_(在区块完成之前)将交易发送到网络的其余部分。这组交易称为 entry。“区块”然后被定义为领导者在 slot 期间生成的所有 entries 的集合。
这消除了区块生产期间的等待时间,因为其他节点在区块完成时已经处理了该区块。唯一的延迟是最终数据包的网络延迟,之后下一个领导者立即开始流式传输下一个区块的 entries。这是一个最佳解决方案,仅受互联网基础设施物理限制的约束。
 ? 点击图片放大
? 点击图片放大
Shred
为了在网络上有效地分发 entries,它们被分解为 shreds。通过将 shreds 的大小调整为类似于网络数据包,并使用纠删码来确保可靠的交付,可以实现高性能。
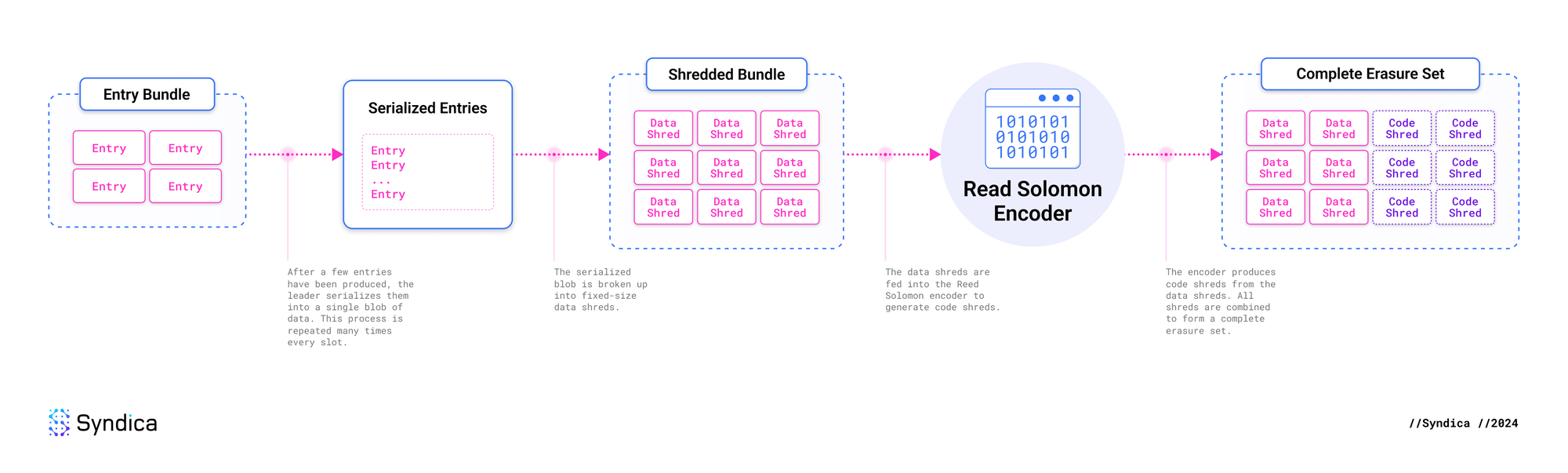
在领导者生成一组 entries 后,它会将它们序列化为单个大的数据 blob,然后将其分成更小的片段,称为 shreds。
这些片段中的每一个都成为 data shred。为防止任何 data shreds 丢失,会提前使用纠删码从它们派生出冗余的数据片段,称为 code shreds。这是一种纠错形式,能够以计算方式恢复丢失的 shreds。
Erasure set 是从一组 entries 生成的所有 data shreds 和 code shreds 的集合。其最大大小为 32 个 data shreds 和 32 个 code shreds。
此伪代码说明了从一组 entries 创建 erasure set 的过程。
entry_bundle = [entry1, entry2, entry3]
## 将 entries 转换为数据片段
entry_blob = bincode.serialize(entry_bundle)
data_fragments = entry_blob.split_into_chunks(chunk_size=1000)
## 从数据片段获取纠删码
code_fragments = reed_solomon_encode(data_fragments)
## 将片段转换为 shreds
data_shreds = [DataShred(fragment) for fragment in data_fragments]
code_shreds = [CodeShred(fragment) for fragment in code_fragments]
erasure_set = data_shreds + code_shreds
Shred 传播和大小
每个网络都有一个最大字节数,可以作为单个有凝聚力的单元传输。在大多数网络中,该限制至少为 1232 字节。如果消息超过限制,则必须将其分成更小的数据包并单独传输。
我们不希望 shreds 被分成更小的部分。如果它们被分成更小的部分,则会增加数据丢失的可能性。为避免碎片化,shreds 的大小被调整为适合此 1232 字节的限制。4 个字节保留给 nonce,因此 shreds 的最大大小为 1228 字节。
shreds 的固定大小还使验证器客户端能够对内存使用情况进行假设,从而提高性能。
纠删码
纠删码是 Solana 中使用的一种纠错形式,它使接收者能够恢复每个 data shred,即使某些 data shred 在传输过程中损坏或丢失。这是通过在 shreds 中包含冗余信息来实现的。
虽然传输冗余数据需要额外的时间和带宽,但冗余对于处理数据包丢失是必要的。纠删码是冗余的最有效形式,使其成为有价值的性能优化。
想象一下,我们有一个完美的网络,它总是传输每条消息。每个节点都可以依靠单个分配的对等方来准确发送每个数据包一次。此协议避免了冗余传输,从而最大限度地提高了带宽效率,但它不适用于实际网络。由于数据包丢弃或节点宕机,数据丢失是不可避免的。为确保所有节点都收到完整的数据,我们需要一种机制来确保每个节点都收到每条消息。
有三种潜在的解决方案可以解决此问题:
- 修复请求: 当节点缺少数据时,它会从其他节点请求数据。由于额外的通信,这增加了显着的延迟。节点必须检测到丢失的数据包,发送请求,然后再次等待。如果数据包在领导者首次发送时丢失,这将特别成问题,因为它会用无法服务的请求淹没网络。
- 冗余消息传递: 每个节点从不同的对等方接收每个数据包的多个副本。如果使用 2 倍冗余,则预计每个数据包至少从两个对等方到达。如果你丢失了一半的数据包,你希望只丢失每个数据包的一个副本并接收另一个副本。不幸的是,在大多数情况下,你将丢失某些数据包的两个副本,这意味着无法恢复完整消息。
- 纠删码: 使用下面解释的 Reed-Solomon 算法在所有数据包中均匀分布冗余,从而无需多次传输相同的数据包。使用 2 倍冗余,你可以丢失_任何_一半的消息,并且保证成功恢复。与冗余消息传递相比,这大大提高了成功率,这意味着必须发送的消息数量显着减少。
纠删码是最有效的解决方案。与修复请求和冗余消息传递相比,它在最大限度地提高可靠性的同时最大限度地减少了延迟和带宽使用。
Reed-Solomon
纠删码是如何工作的?总体思路很简单。每条消息都包含冗余信息,告诉你如何重建其他消息。有效地做到这一点需要一些巧妙的数学。
考虑一种天真的方法。假设我们有十条消息,每条消息 10 KB。我们可以将每条消息分成九个块,并将这些块作为冗余分发到所有其他消息中。每条消息增长到 19 KB。这使我们能够丢失任何消息并从其他消息中重建它。但是这种纠删码方案有一个很大的缺点:我们已经将数据大小增加了 90%,但仅针对 10% 的数据丢失进行了保护,这是非常低效的。针对 10% 的数据丢失进行保护应该只需要 10% 的额外数据。
Reed-Solomon 纠删码通过利用消息之间的数学关系来实现这一点。为了防止单个消息丢失,我们不会更改任何消息的大小。我们只需要添加一条额外的消息,称为 code 消息。代码消息不需要复制所有其他数据。它仅描述其他消息之间的_关系_,从而使我们能够从其他消息中重建任何丢失的消息。
如果这听起来太神秘了,我们需要深入研究数学才能理解它。
由于每条消息都是一个二进制数,因此你可以将每条消息重新解释为一个数据点。你可以根据 Lagrange Interpolation Theorem 将多项式拟合到这些数据点,该定理指出,k 次多项式由 k+1 个点唯一确定,如下所示。
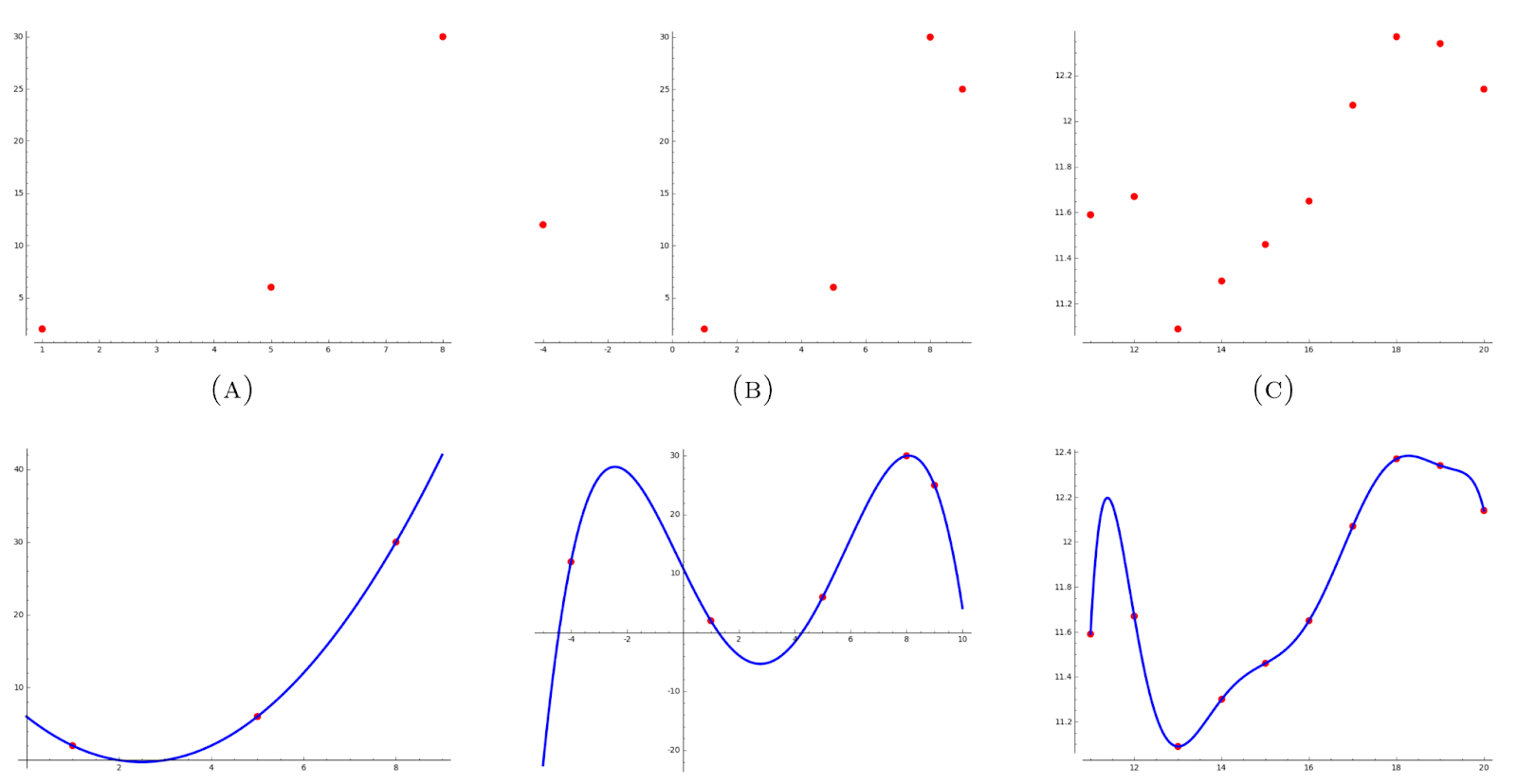 图片来源: Lagrange Interpolation - Daryl Deford, MIT
图片来源: Lagrange Interpolation - Daryl Deford, MIT
使用多项式作为函数,你可以计算曲线上的 n 个额外点以进行冗余。这增加了一个安全网。如果你丢失了任何数据点,只要你不丢失超过 n 个数据点,你就可以使用剩余的点来重建原始多项式。一旦你有了多项式,你就可以通过在适当的位置评估它们来重新计算任何丢失的数据点。
有关这些数学概念的更详细和易于理解的解释,请查看此视频:
什么是 Reed-Solomon 码? 计算机如何恢复丢失的数据 - YouTube
vcubingx
97K 订阅者
什么是 Reed-Solomon 码? 计算机如何恢复丢失的数据
vcubingx
搜索
稍后观看
分享
复制链接
信息
购物
点按以取消静音
如果播放没有立即开始,请尝试重启设备。
更多视频
更多视频
你已退出帐号
你观看的视频可能会被添加到电视观看记录并影响电视推荐。为避免这种情况,请取消并使用电脑登录 YouTube。
取消确认
分享
包含播放列表
检索分享信息时出错,请稍后重试。
在观看
0:00
0:00 / 16:53 •直播
•
什么是 Reed-Solomon 码?
Data Shreds 和 Code Shreds
纠删码在传输 shreds 时应用。这是如何工作的?
首先,领导者获取一组最近生成的 entries,并将它们分组到一个将一起发送的 batch 中。这被称为 erasure set,因为 Reed-Solomon 纠删码将为整个 batch 生成。这些 entries 只是一个区块的一部分,并且可以在单个 slot 期间创建许多 erasure sets。
这些 entries 被序列化并合并到一个连续的数据 blob 中,然后分成最大 1003 字节的块。在纠删码方案中,这些块被称为数据 fragments。它们包含我们关心的实际数据,并且在与元数据结合使用时,这些 fragments 成为 data shreds。
为了进行识别,erasure set 中的每个 data shred 都被分配了一个从 0 到 data shreds 数量的唯一整数。这个数字被称为 shred index。
领导者的下一步是生成纠删码,但是需要多少个纠删码?这取决于 data shreds 的数量。对于从 0 到 32 的每个 data shreds 数量,Agave 的代码这里 指定了预期的 code shreds 数量。
假设每个 shred 的成功概率与其他 shred 的概率无关,则恢复整个 erasure set 的概率遵循二项分布。每个 erasure set - 及其成功概率 - 可以在此表 中找到。只要成功的 shred 交付率高于 65%,每个 erasure set 都有至少 99% 的恢复机会。较小的 erasure sets 比更大的 erasure sets 具有更高的恢复概率。
我们使用 Reed-Solomon 算法来生成纠删码。要将 shred 解释为数据点,它的 shred index 确定该点的 x 值,其 fragment 成为该点的 y 值。
计算曲线上的额外点并成为 code shreds,这些 code shreds 与 data shreds 一起分发到其他节点。与 data shreds 类似,erasure set 中的每个 code shred 都使用 shred index 从 0 到 code shreds 的数量进行编号。
 ? 点击图片放大
? 点击图片放大
稍后,当验证器仅收到 shreds 的子集时,它会反向运行相同的过程。首先,根据 shred indices 确定哪些 shreds 丢失。然后,使用 Lagrange interpolation 拟合多项式,并计算曲线上对应于丢失的 data shreds 的点。通过组合 data shreds 并将它们进行反序列化,验证器可以重建由领导者创建的原始 entries。
数据完整性
Shreds 还需要确保 erasure set 的数据完整性。我们需要以下保证:
- 验证器收到的 shreds 与领导者生成的 shreds 相同。
- 每个 shred 都正确指定其 erasure set 中的 shreds 总数。
- 每个声称是 erasure set 一部分的 shred 实际上都属于该集合。
如果保证了这些,则接收 shreds 的任何验证器都可以最终确定他们是否已收到完整且正确的 erasure set。如果没有这些保证,各种问题可能会破坏集群:
- 恶意行为者可以修改 shred 以包含他们所需的交易。
- 由于硬件故障,网络可能会在传输过程中意外修改数据。
- 领导者可能会谎报他们创建的 shreds 数量,并将不同的 shreds 分发给每个验证器,从而导致混淆或对哪些 shreds 应该构成 erasure set 产生分歧。
为了解决这些问题,shreds 包含 Merkle proofs 和加密签名。
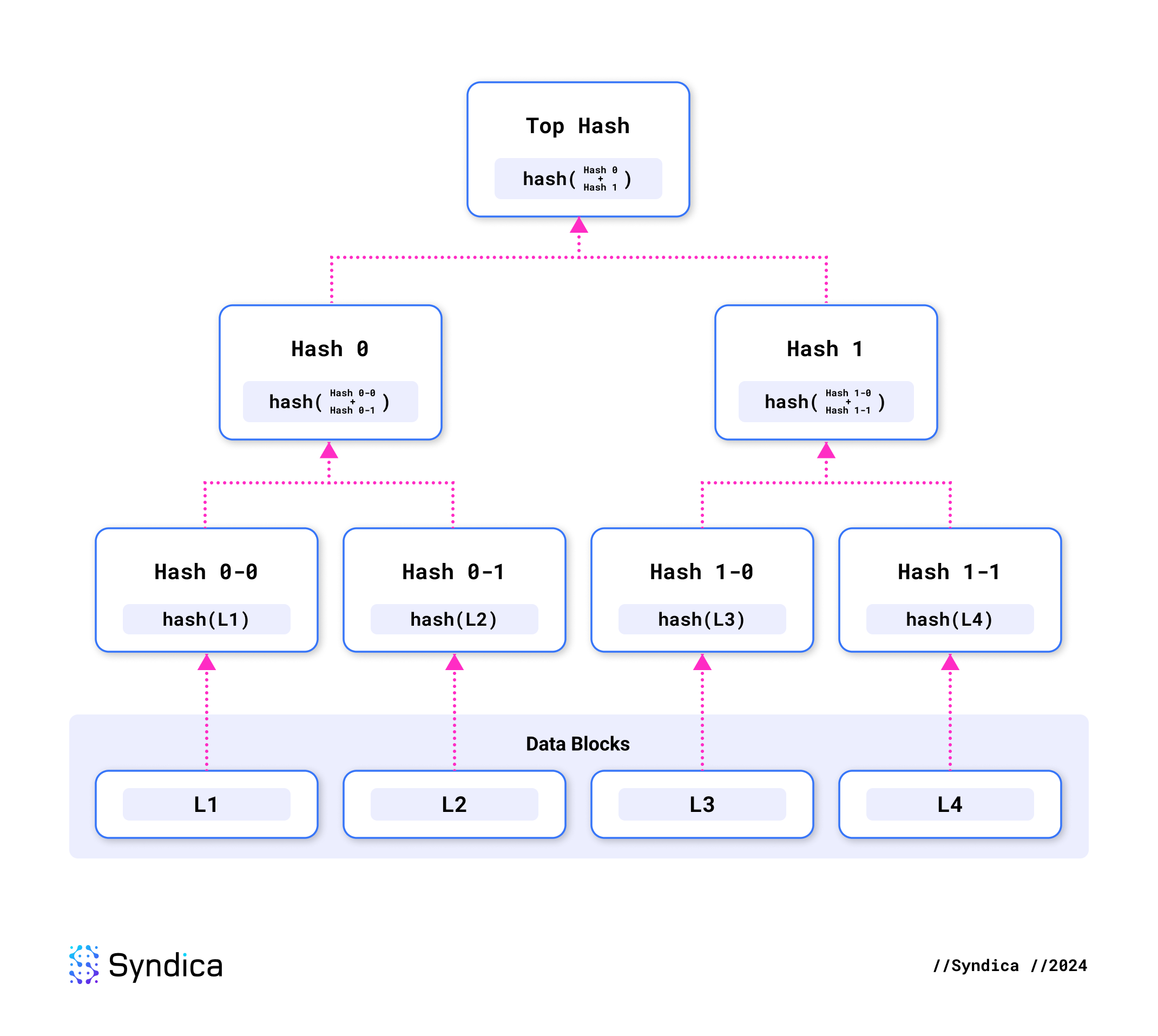
每个 shred 都包含一个 Merkle proof,这是一种用于验证特定数据是否属于较大数据集的密码学方法。
这是使用 Merkle tree 完成的,在 Merkle tree 中,每条数据(或 shred)都单独哈希。然后将这些哈希配对并递归地哈希在一起,形成哈希的层次结构树。这棵树的顶部哈希称为 Merkle root。
 ? 点击图片放大
? 点击图片放大
Merkle proof 仅包含从各个 shred 的哈希到 Merkle root 的路径上所需的哈希。例如,L4 的 Merkle proof 只需要包含哈希 0 和 1-0。使用 L4 和这两个哈希,你可以通过递归哈希三次来重现 Merkle root。
这允许验证两件事。首先,我们可以通过重现其哈希来验证当前 shred 中的数据是否正确。其次,我们可以通过验证到 Merkle root 的路径来确认此 shred 是整体 erasure set 的一部分。
领导者签名每个 erasure set 的 Merkle root,并且该签名包含在该 erasure set 的每个 shred 中。每个验证器都知道每个领导者的公钥,因此他们在收到每个 shred 后立即验证签名。这保证了 shred 来自领导者。
任何收到带有无效签名或 Merkle proof 的 shreds 都会被丢弃。
Blockstore
验证器需要一种方法来存储、读取和写入数据到他们的账本中。为此,他们将其存储在一个名为 Blockstore 的数据库中。
Blockstore 支持的三种操作类型是:
- 插入 shreds。
- 读取数据。
- 插入交易结果。
插入 Shreds
当验证器运行时,它会不断收到来自集群的 shreds,这些 shreds 需要插入到 Blockstore 中。
在收到新的 shred 之后,第一步是验证其签名、Merkle proof 和 erasure set 元数据。一些元数据存储在 Blockstore 中,以验证未来的 shreds 与我们现在存储的 shreds 一致。
下一步是使用 Reed-Solomon 纠删码执行 shred 恢复。在识别出 shred 所属的 erasure set 之后,如果存在足够的 shreds,我们从 Blockstore 读取同一 erasure set 的其他 shreds。然后,我们使用 Reed-Solomon 重建丢失的 shreds。
最后,所有接收和恢复的 shreds 都作为从最早到最新的序列存储在 Blockstore 中。
插入后,恢复的 shreds 通过 Turbine 转发到其他节点。
读取数据
下一个操作是从 Blockstore 读取区块或交易。例如,在执行交易时,这在 replay 期间使用。
可以从 Blockstore 读取的一些数据类型包括:
- Shred
- Entry
- Block
- Transaction
- Transaction Status
- Block Rewards
- Block Time
虽然所有这些数据类型都可以从 Blockstore 读取,但大多数数据都存储在 shreds 中。交易、entries 和区块不会单独存储,因为它们会与 shreds 冗余。
一个常见的操作是从 Blockstore 读取交易。Blockstore 不是直接读取交易,而是找出哪个 shreds 集合有望包含该交易,找到这些 shreds,将它们转换为 entries,然后在其中找到交易。
插入交易结果
交易作为 shreds 存储在 Blockstore 中之后,验证器必须执行它们。领导者执行交易并在区块生产的 banking stage 期间存储结果。其他验证器在交易验证的 replay stage 期间执行交易。在 replay 期间,验证器首先从 Blockstore 中读取完整的 erasure set,然后执行其中的每个交易。
执行交易会产生 transaction status,其中包括诸如交易是否成功以及哪些账户被修改的信息。一旦完成整个区块,就会产生更多输出,例如领导者的区块奖励和生成区块的时间。在 replay 和 banking stages 中生成这些输出后,数据将被写入 Blockstore。
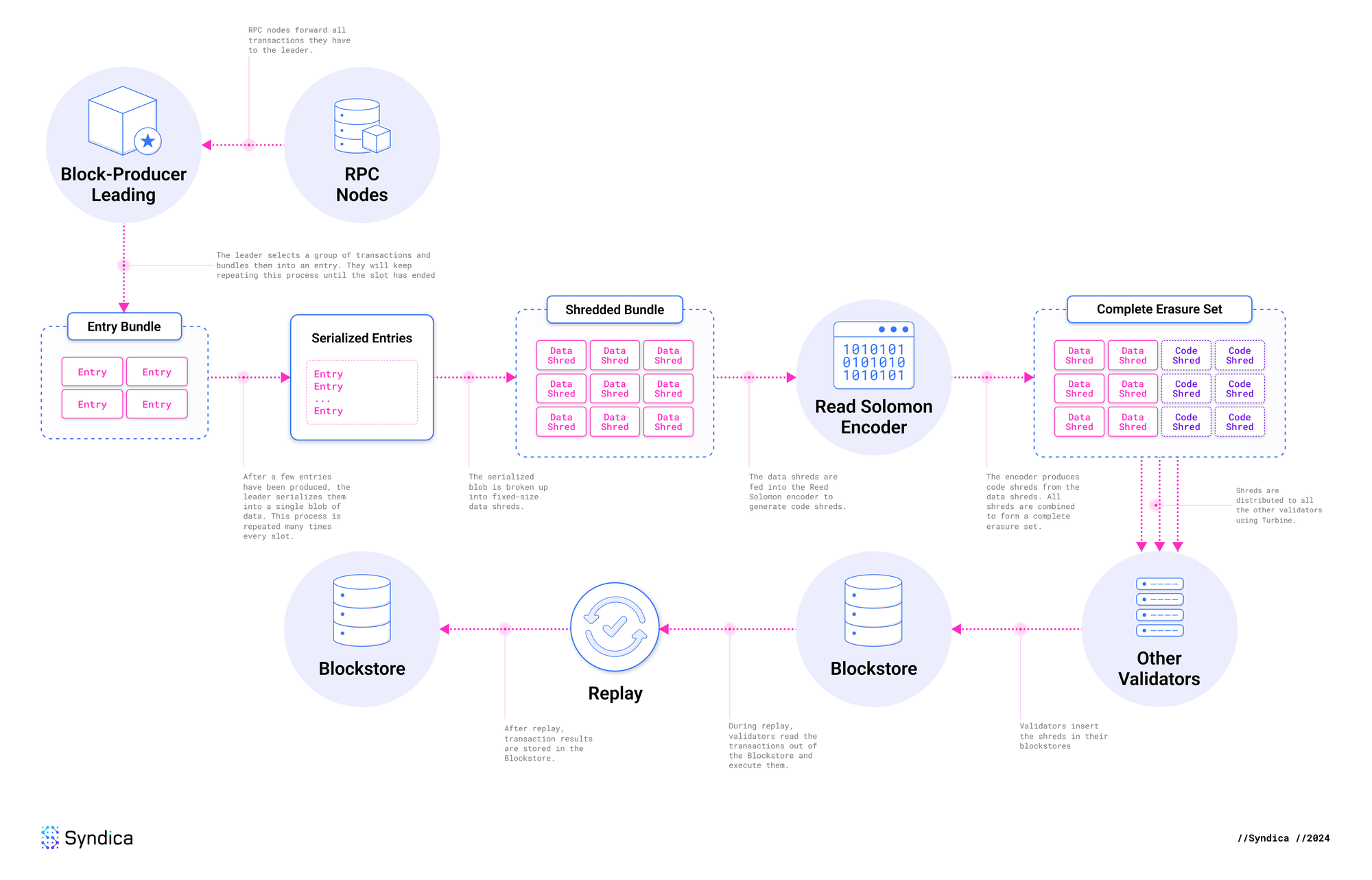
完整流程
此图说明了我们描述的完整流程,从 RPC 节点首次收到交易到交易状态存储在 Blockstore 中。
 ? 点击图片放大
? 点击图片放大
结论
Solana 账本是一个复杂的系统,它将纠删码与密码学相结合,以实现速度、可扩展性和弹性。它构成了 Solana 区块链的支柱,使验证器能够高效地处理、存储和共享交易数据。
在我们的下一篇文章中,我们将采用这些基本概念,并展示它们如何在 Sig 验证器中组合在一起。我们将探讨 Sig 账本的特定设计和实现,重点介绍使其模块化、灵活和高性能的工程决策。请继续关注下一篇文章。在 Twitter 上关注我们,以便第一时间知道它何时上线。
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~




