解读SEDA IVM:验证专家
- decipherclub
- 发布于 2025-03-20 16:37
- 阅读 1998
本文深入探讨了SEDA的互操作性验证模块(IVM),这是一个去中心化的、可编程的验证框架,旨在为跨虚拟机提供安全和专门的链间通信。文章详细解释了IVM的核心组件,包括模块、去中心化求解器网络、证明者合约、独立覆盖网络、RPC数据提供商和SEDA主链,并阐述了数据请求在IVM中的生命周期,以及IVM在安全性、活跃性、可编程性和模块化灵活性方面的独特优势。
在 本文的第一部分 中,我提出了关于以下内容的一些有力论点:
- 向模块化堆栈的转变,
- 模块化如何创造专家,
- 验证市场和验证专家的崛起,
在本文中,我们将探索模块化互操作时代中一个新兴的验证专家,即 SEDA IVM。
我们将深入探讨:
- IVM 究竟是什么,
- IVM 的核心组件,
- 这些组件如何协同工作,
- 以及,最重要的是,是什么让 IVM 独一无二
Decipherers 们,系好安全带,让我们首先从我们常用的 100 字定义开始。
SEDA IVM 百字介绍
SEDA 的 互操作性验证模块 (IVM) 是一个去中心化的、可编程的验证框架,旨在提供定制化的 Oracle 程序,能够跨所有 VM 进行验证,以提供安全和专业的跨链通信。
与传统的验证模型(例如多重签名或中心化中继器)不同,IVM 提供了一个模块化的、即插即用的系统,任何互操作性协议、基于意图的桥或链抽象层都可以集成无需许可和密码学安全的验证。
每个 IVM 都运行在 SEDA 的可编程 Oracle 基础设施上,允许为不同的网络、RPC 端点和安全设置自定义验证规则。
最重要的是,IVM 确保状态验证以防篡改和去中心化的方式进行。
我们现在对 IVM 有了一个基本的定义,但还有很多东西需要解读。
为了理解这些属性以及它们如何工作:
- 让我们首先了解所涉及的核心组件
- 然后了解所有这些组件如何组合并协同工作
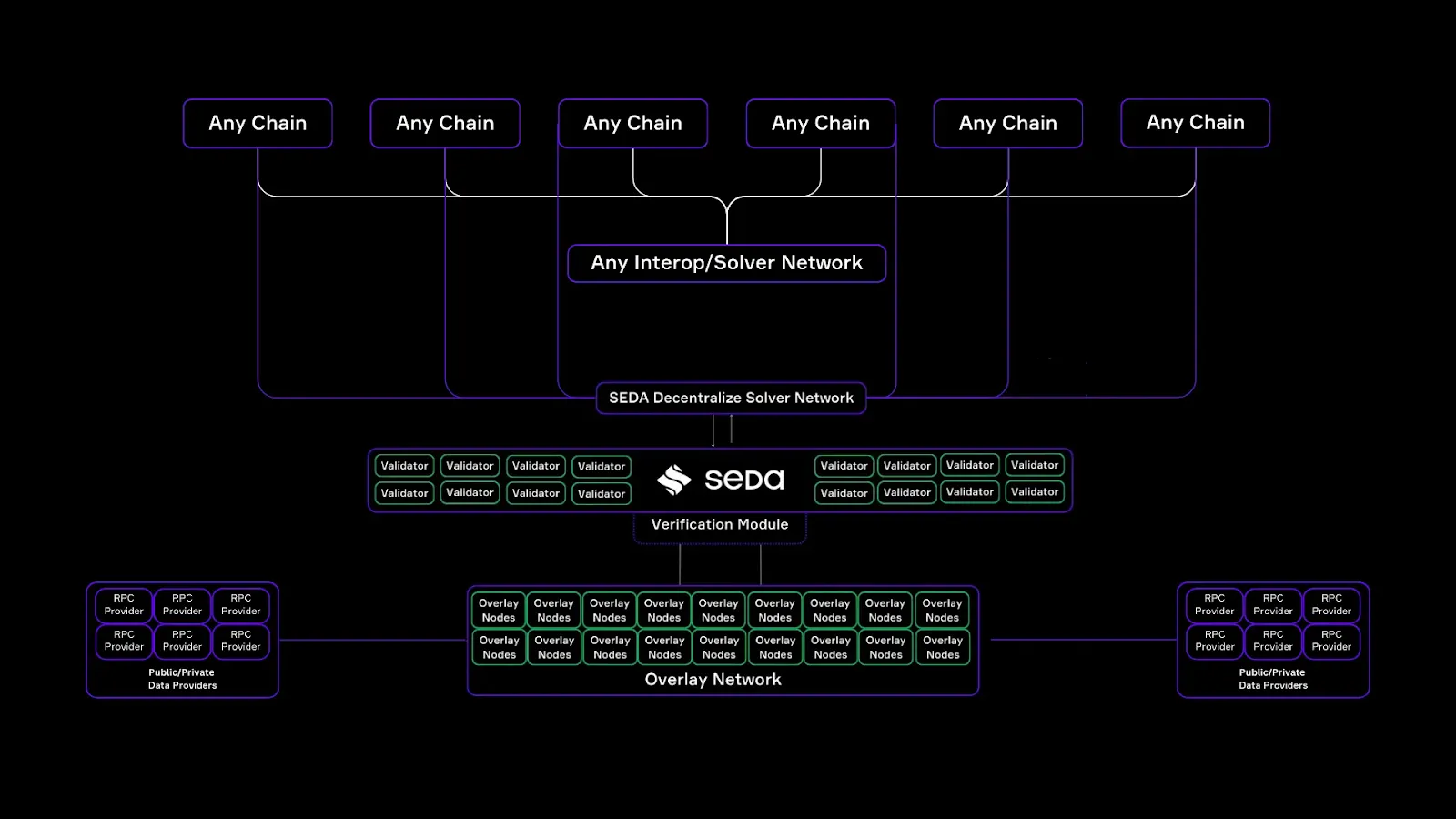
IVM 的核心组件
 来源:SEDA
来源:SEDA
- 模块: 在 SEDA IVM 的基础上,Oracle 程序充当可编程逻辑层,用于定义验证如何运作。 这使开发人员能够定义自己的验证规则、数据源和处理逻辑。
- 去中心化求解器网络: 这充当 SEDA 和所有连接的区块链网络之间的通信层,其中部署了 Prover 合约。
- Prover 合约: Prover 合约 是最终的集成点,验证结果在目标链上进行解析和验证。 这是一个通用的验证合约,可以部署在任何区块链中。
此外,Prover 合约标准化了所有链上的验证过程,无需互操作协议为每个网络构建自定义验证逻辑。
- 独立覆盖网络: 将其视为负责验证链上状态的核心证明层。 它由数千个以去中心化和无需许可方式运行的独立节点组成。
- RPC 数据提供商: 可靠的状态验证需要访问来自不同区块链网络的准确、最新数据。 SEDA 旨在连接到公共和私有 RPC 端点,确保 IVM 可以从多个来源访问高质量的状态数据。
- SEDA 主链: SEDA 主链充当最终的验证层,所有验证结果都在这里聚合、以密码学方式签名和存储。
💡 注意: SEDA 主链至关重要,因为它负责一些必要的职能,例如批量处理和聚合验证证明、权益证明安全、防篡改的密码学签名。
我们将在下一节中阅读更多相关信息。
现在让我们了解所有这些组件是如何组合在一起的。
SEDA IVM 中数据请求的生命周期
掌握所有这些组件如何组合在一起的最好方法是,了解 IVM 中数据请求的完整生命周期。
步骤 1:触发验证请求
验证生命周期开始于源链上的事件需要跨链验证时,例如桥存款、基于意图的交易或互操作协议在执行前触发验证。
- 用户通过
SedaCoreV1::postRequest提交请求。 - 请求详细信息和费用存储在合约上。
- 生成一个唯一的
请求 ID并添加到待处理请求队列中。
在这个阶段,验证请求被构建、记录和准备用于链下处理。
步骤 2:SEDA IVM 的链下处理
- 求解器网络检测到请求
- 来自去中心化求解器网络中的单个求解器检测到验证请求,并将其转发到 SEDA 网络。
- 该请求包含元数据、事件详细信息和验证所需的 relevant 合约状态。
- 请求转发到覆盖节点网络
- 然后,该请求移动到覆盖节点,在那里形成一个随机选择的覆盖节点秘密委员会来执行实际验证。这种随机化是使用 可验证随机函数(RFC 9381) 完成的。
- 覆盖节点查询源链
- 选定的覆盖节点查询预定义的 RPC 端点(根据 IVM 配置设置),并从源区块链检索必要的数据。
- 用于安全数据证明的提交-揭示方案
- 每个覆盖节点最初以加密形式提交其计算结果,防止过早的数据暴露,这可能会导致对抗性操纵。
- 只有在提交所有承诺后,它们才会同时公布其结果。
- 通过 DR Tally 进行数据处理和过滤
- 结果通过 数据请求(DR)Tally 函数 进行数据过滤、聚合和清理。
- DR Tally 遵循 IVM 的预定义指令,确保只有有效、非冲突的结果才能传递下去。
- 此步骤有 2 个重要的 阶段:
- 执行阶段,由 覆盖节点 运行,从多个外部来源获取和处理数据。 由于网络请求和数据源可能不同,因此此阶段是非确定性的。
- Tally 阶段,由 SEDA 链验证器 运行,以确定性方式处理执行结果。 它会聚合多个执行报告,应用 tally 指令,并确保链级别的共识。
- 执行阶段,由 覆盖节点 运行,从多个外部来源获取和处理数据。 由于网络请求和数据源可能不同,因此此阶段是非确定性的。
💡
注意:关键区别在于,执行阶段与外部数据源交互,使其受到可变条件的影响,而 tally 阶段仅在执行结果上运行,确保了可重复且共识驱动的过程。
对于好奇的人:执行和 Tally 阶段 👇
执行阶段和 Tally 阶段之间的区别在确保 SEDA 验证模型中的安全性和可靠性方面发挥着至关重要的作用:
- 非确定性与确定性处理:
- 执行阶段 涉及获取链下数据,由于数据可用性和来源的变化,使其成为非确定性的。
- Tally 阶段 完全是确定性的,因为它基于预定义的 tally 指令和执行报告运行,确保所有验证器都得出相同的结果。
- 防止数据操纵:
- 由于执行与外部来源交互,因此通过覆盖节点中的密码学承诺和冗余来维护数据完整性。
- Tally 阶段通过强制执行确定性共识来消除主观性,确保只有经过验证的结果才能上链。
- 共识可靠性:
- 因为 tally 阶段由所有主链验证器执行,它确保数据聚合是可验证的,并且无法被操纵。
- 这可以防止恶意节点在执行级别影响数据的情况。
在此阶段,SEDA 已经收集、验证和处理了数据请求,而没有任何单点故障,并且经过验证的数据现在可以进行密码学签名。
步骤 3:批量提交和密码学证明生成
一旦覆盖节点达成共识,验证结果就会准备好提交到目标链。
- SEDA 主链聚合并批量处理经过验证的数据
- 最终聚合的验证结果被批量处理以提高效率。 一个批次包含多个经过验证的请求,从而优化了 gas 成本。
- SEDA 链上的验证器对批次进行签名
- SEDA 主链应用使用 PoS 验证器的密码学签名,确保验证证明是防篡改的,并且可以在链上验证。
- 然后,签名的批次存储在 SEDA 链上,使其不可变且可审计。
- 求解器检索签名的批次
- 求解器从 SEDA 主链中获取批次以及密码学证明,并准备将其提交到目标链上的 Prover 合约。
- 签名的批次提交到 Prover 合约
- 求解器通过 Secp256k1ProverV1::postBatch 提交签名的批次。
- 此批次包含:
- 结果根( 即,结果的 merkle 根)
- 验证器根( 即,验证器集的 merkle 根)
- 提交批次时,求解器还提供:
- 来自验证器的批次签名
- 验证验证器的公钥包含在验证器树中的 Merkle 证明。
- 这些证明确保签名来自 Prover 合约已知的最新验证器集中列出的验证器。
在此阶段,验证证明已完成,并准备好在目标区块链上进行验证。
💡
注意: 应该注意的是,要达成接受共识,必须有66.67% 的验证器同意,这进一步提高了系统的可靠性。
步骤 4:目标链上的结果验证
在经过验证的证明到达目标链后,Prover 合约会在执行最终交易之前确保其真实性。
- Prover 合约解析证明
- 目标链上的 Prover 合约接收来自求解器的证明。
- 然后,它会解析证明并准备对其进行验证。
- 密码学验证证明
- 该证明使用 SEDA 基于 secp256k1 的密码学验证,通过
Secp256k1ProverV1::verifyResultProof进行验证。 - 验证确保证明包含在存储在 SEDA 主链上的签名批次中。
- 该证明使用 SEDA 基于 secp256k1 的密码学验证,通过
- 成功的验证会触发费用分配
- 一旦证明通过验证,费用将根据 SEDA 的三层费用模型分配给相关的网络参与者。
在此阶段,验证请求已完全通过身份验证,并且系统已准备好处理最终的跨链执行。
步骤 5:最终请求完成和目标链上的状态更改
验证完成后,目标合约会处理最终的状态转换。
- Prover 合约向目标合约确认验证
- 目标智能合约接收来自 Prover 合约的确认,证明该证明有效。
- 执行跨链交易
- 一旦证明通过验证,就可以执行依赖于此证明的跨链交易。 例如:
- 如果证明是为了验证跨链资金转移,则资金会释放到目标链上的用户。
- 如果证明是为了验证基于意图的操作,则执行会在目标协议上继续进行。
- 一旦证明通过验证,就可以执行依赖于此证明的跨链交易。 例如:
- 待处理的请求标记为已完成
- 然后,
请求 ID将从网络上的待处理队列中删除。 - 事件在链上发出,提供可验证的验证记录。
- 然后,
干得漂亮。 🎉
这完成了验证的整个生命周期,以及使用 SEDA IVM 安全执行的跨链交易。
SEDA 的 IVM 只是另一种验证机制?
在这一点上,很自然地会问:这与现有解决方案有什么不同?
在我的研究中,我发现了一些关键方面,这些方面使 SEDA IVM 在解决模块化跨链互操作性的挑战方面独特、专业并且更好。
为了充分理解 SEDA IVM 与其他验证模型的不同之处,我们将分析其在以下关键方面的特征:
- 安全方面
- 活跃性方面
- 无需许可的可编程性方面
- 模块化的灵活性方面
1. 安全方面
评估 Oracle 优势的最好方法之一是评估其安全方面。
让我们了解 IVM 有多安全:
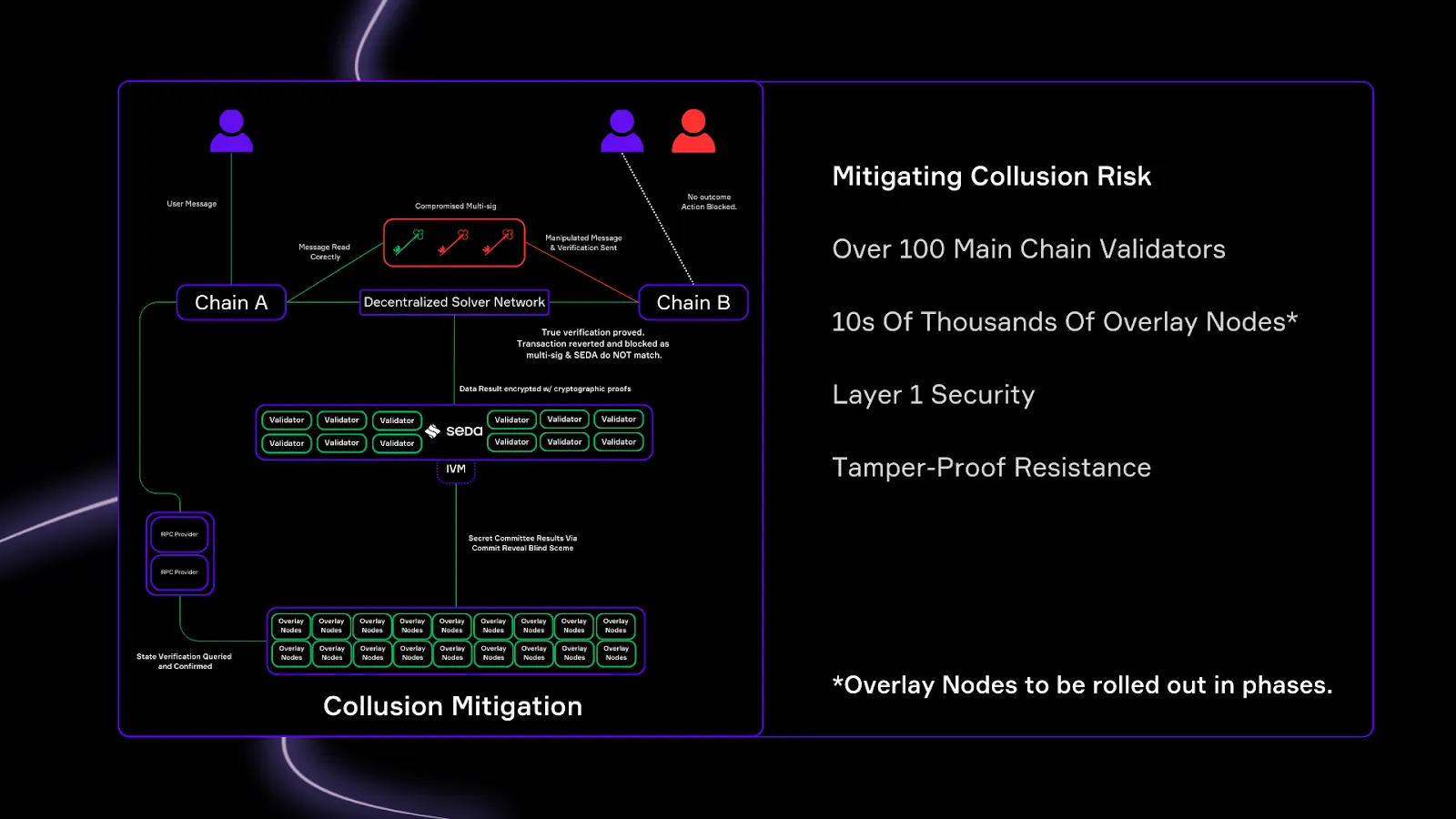
1.1 降低共谋风险
多重签名(多重签名)模型中最大的漏洞之一是签名者之间共谋的风险。
这种风险背后有两个关键原因:
- 在大多数多重签名设置(例如,3-of-5 或 4-of-7 配置)中,攻击者只需要破坏几个私钥即可接管验证。 一旦达到阈值,整个系统就会受到威胁,从而允许未经授权的跨链交易。
- 许多互操作协议仍然控制着他们的 多重签名验证堆栈,这意味着用户信任一小群参与者。 如果签名者共谋(或被贿赂),他们可以伪造验证证明并在目标链上触发未经授权的转移。
但是,SEDA 在很大程度上减轻了此类共谋。
 来源:
来源:- 权益证明保护的验证
- 与多重签名不同,SEDA IVM 从 SEDA 主链继承了安全性,SEDA 主链由 权益证明(PoS) 共识模型保护。
- 安全性不是依赖于一小群私钥持有者,而是锚定在一个去中心化的验证器网络上。 这意味着操纵验证将需要对整个 SEDA 链进行 66% 的攻击,这比贿赂少数几个多重签名者要困难得多。
- 去中心化的求解器和覆盖网络
- IVM 验证不依赖一组固定的验证器,而是使用一个动态的、无需许可的网络:
- 求解器- 监控 Prover 合约并提交验证请求。
- 覆盖节点 - 形成随机的“秘密委员会”来验证状态
- IVM 验证不依赖一组固定的验证器,而是使用一个动态的、无需许可的网络:
- SEDA 验证器强制执行链上签名:
- SEDA IVM 中生成的所有验证证明都必须由 SEDA 主链的验证器集在提交之前进行密码学签名。
- 这可确保即使恶意中继器尝试伪造验证结果,该证明也会因缺少有效的 PoS 支持的签名而在合约级别被拒绝。
💡 共谋变得更加困难,因为攻击者需要控制多个验证请求中随机选择的大多数覆盖节点。
1.2 消除碎片化的验证堆栈
传统跨链验证的另一个主要挑战是安全区域的碎片化。
这意味着:
- 每个新路由都需要一个新的验证堆栈
- 自定义多重签名模型需要为每个链配对(例如,Ethereum ↔ Solana、Solana ↔ Avalanche)设置不同的验证器集。 因此,协议必须维护具有不同验证器组合的多个安全区域。
- 验证碎片化使扩展变得困难。
- 一些互操作性提供商提供第三方多重签名验证器,允许开发人员组合多个提供商来验证跨链消息。
- 但是,并非所有验证器都支持每个区块链,这意味着互操作协议必须混合和匹配不同路由上的不同验证器,从而导致安全不一致。
SEDA 的 IVM 通过 单一安全区域 解决了这种碎片化问题。
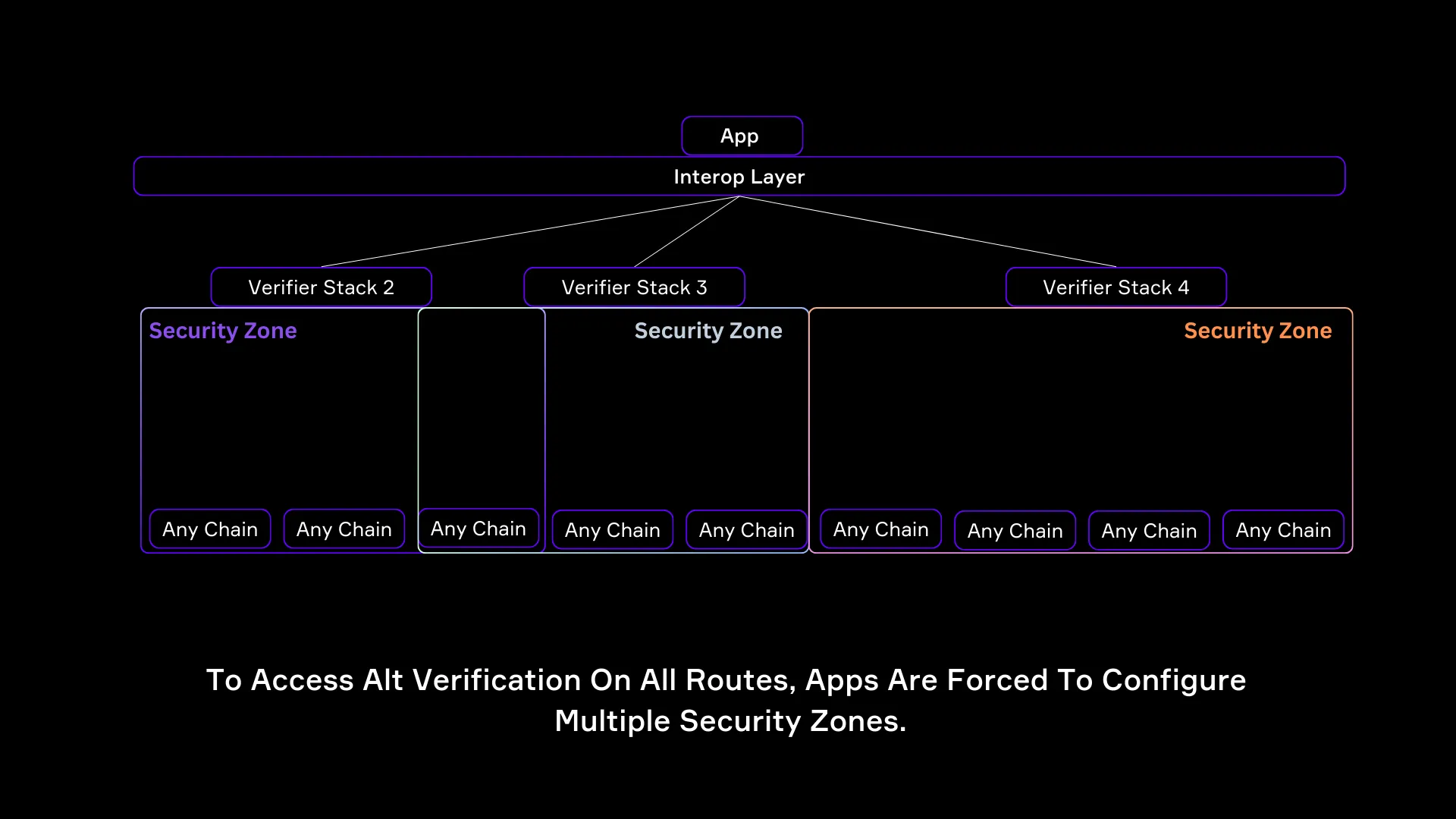
- 所有链和所有路由的一个安全区域
- SEDA IVM 建立一个单一的、统一的安全区域。 这意味着无论在哪里部署 Prover 合约,验证都将可用,而无需为每个新集成重新配置多个安全区域。
- 无需许可的 Prover 合约创建一个标准化的安全层
- 一旦一条链部署了 Prover 合约,通过 IVM 的 SEDA 证明在所有使用 IVM 的互操作协议中都有效,从而为所有网络创建一个单一的标准化的验证框架。
注意: 截至目前,Prover 合约 专为与 EVM 兼容的链而设计。 扩展到非 evm 链是一项未来的功能,并且是 SEDA 团队路线图的一部分。
1.3 密码学防篡改的实施
一个有趣的发现是 SEDA 的主链如何实施密码学防篡改以避免此问题:
- 通过 SEDA 主链进行防篡改的证明聚合
- SEDA 的主链充当验证正确性的最终仲裁者,确保仅接受经过密码学签名的的证明。 这意味着所有验证结果都必须由 PoS 验证器签名才能被中继,从而防止中继器进行欺诈性修改。
- 提交-揭示方案阻止数据操纵
- 覆盖节点首先提交他们的结果,然后再公布它们,从而防止他们根据其他人的提交有策略地更改他们的响应。
📝
应该注意的是,虽然这可以阻止对数据的策略性操纵,但它本身并不能保证数据的正确性 - 源数据的完整性仍然取决于来自 RPC 提供商或其他经过身份验证的来源的数字签名。
2. 活跃性方面
跨链验证中一个被忽视但至关重要的方面是活跃性 - 系统即使在面对节点故障、拥塞或意外中断时也能持续运行的能力。
虽然许多传统的验证模型都存在停机风险,但以下是 SEDA IVM 旨在确保持续活跃性保证的方式:
2.1 分布式验证:没有单点故障
与多重签名或中心化中继器不同,SEDA IVM 将验证分布在多个独立的组件中:
- 权益证明(PoS)保护的主链:
- SEDA 主链受到100 多个验证器的保护,从而确保共识和数据完整性。 如果一部分验证器遇到停机时间,剩余的活跃验证器将继续处理验证证明,从而防止整个网络发生故障。
- 具有数千个节点的覆盖网络:
- 覆盖网络由数千个独立节点组成,负责获取、处理和验证链下数据。
- 如果某些覆盖节点离线,分布式模型可确保其他节点自动介入以维持无缝验证。
由于 SEDA 拥有 100 多个主链验证器和数千个覆盖节点,因此活跃性风险已大大降低。
3. 无需许可和可编程性方面
作为开发人员,另一个非常吸引我的突出特点是其可编程验证框架。
与规定必须如何执行验证的严格安全模型不同,SEDA IVM 提供完全的可配置性,使协议能够:
- 通过指定需要验证的链和交易来定义验证路由。
- 通过选择哪些 RPC 端点、API 或验证器参与验证过程来选择和修改数据源。
- 无缝升级模块,使互操作性提供商能够添加对新链和Token的支持,而无需彻底修改其验证堆栈。
- 自定义聚合和过滤逻辑,以确保仅将最相关的、准确的数据用于验证。
- 设置覆盖节点秘密委员会的复制因子,从而平衡去中心化、成本和效率。
这种高度的可编程性使 IVM 成为一个灵活且面向未来的验证层,从而确保与任何虚拟机、桥或互操作模型兼容。
让我用一个复制因子的例子来解释这一点。
在大多数多重签名验证设置中,协议在固定的安全参数内运行,依赖于一个小的验证器集(例如,2-of-3 或 4-of-7 配置)。 这些有限的签名者组引入了中心化风险,并创建了一个无法有效扩展的静态验证模型。
IVM 通过引入可编程复制因子消除了这种限制,从而使协议能够:
- 动态调整执行委员会中覆盖节点的数量
- 通过要求更大的委员会签署验证结果来增加高价值交易的去中心化。
- 通过减少低风险交易的委员会规模来优化成本和效率。
这种微调去中心化的能力使 SEDA IVM 成为一个高度灵活的验证系统,从而确保协议可以随着网络需求的演变而调整其安全模型。
然后,它是无需许可的。
SEDA IVM 是完全无需许可的,从而确保任何协议、链或互操作提供商都可以集成其验证层,而无需中央机构的批准或依赖。
其 开源 SDK 进一步实现了访问的民主化,降低了开发障碍,并允许团队进行实验、集成和迭代,而没有任何限制。
我将撰写一份专门的开发人员指南,介绍如何轻松地将 SEDA IVM 集成到他们的堆栈中。 很快,匿名者。
4. 模块化的灵活性方面
SEDA IVM 不是一个独立的验证模块,而是一个高度适应的系统,可以无缝地集成到不同的区块链环境中。
这意味着:
- 验证逻辑与链无关。
- 链下代理可以直接触发数据请求,从而开辟新的验证架构,其中外部参与者可以向 SEDA 提交请求,并在他们喜欢的链上接收批量处理的证明。
- 数据可以在验证层之间移植——一旦验证结果在 SEDA 主链上处理,就可以将其批量处理、签名并转发到存在 Prover 合约的任何网络。
这种级别的灵活性意味着 SEDA IVM 不受特定验证方法、链或互操作框架的限制——它是一个与互操作性无关的系统,可以支持任何验证要求,同时随着应用程序不断变化的需求进行扩展。
总结
随着行业转向模块化互操作性,对专业验证提供商的需求正在增长,从而确保应用程序可以选择满足其需求的定制安全模型。
我们已经看到验证专家的崛起,每个专家都在解决安全性、速度、去中心化和成本之间的不同权衡。 随着跨链生态系统的扩展,验证将继续分解为专业的、具有竞争力的市场,从而确保互操作性不仅更快,而且从根本上更安全和信任最小化。
作为构建者/协议,现在比以往任何时候都更容易自定义适合你的用例的正确验证方案 - 而不是依赖默认的验证技术。 (不再进行基于多重签名的验证)。
我会继续撰写更多关于如何学习、改进并将这些模块化部分集成到你的堆栈中的文章。
在那之前,祝你玩得愉快。
干杯,Decipherers。
进一步阅读
- 原文链接: decipherclub.com/deciphe...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





