第14章. 以太坊虚拟机
本章节深入探讨了以太坊虚拟机(EVM)的架构、指令集、运行机制以及状态管理,并详细介绍了EVM指令集、以太坊状态的存储方式 Merkle-Patricia Trie。同时还探讨了Gas机制,用于限制计算资源使用和预防拒绝服务攻击。分析了EVM的各项限制,探讨了以太坊虚拟机(EVM)未来升级方向。
以太坊协议和运行的核心是以太坊虚拟机,简称EVM。正如你可能从名称中猜到的那样,它是一个计算引擎,与微软的.NET框架的虚拟机或其他字节码编译编程语言(如Java)的解释器没有太大区别。在本章中,我们将详细了解EVM,包括它的指令集、结构和操作,以及以太坊状态更新的背景。
什么是EVM?
EVM是以太坊中处理智能合约部署和执行的部分。从一个EOA到另一个EOA的简单价值转移交易实际上不需要涉及到它,但其他任何事情都需要涉及到EVM计算的状态更新。从高层次来看,在以太坊区块链上运行的EVM可以被认为是一个全局的去中心化计算机,包含数百万个可执行对象,每个对象都有自己的永久数据存储。
EVM是一个准图灵完备的状态机:“准”是因为所有执行过程都被限制在有限数量的计算步骤中,这个数量取决于任何给定的智能合约执行可用的gas量。因此,停机问题被“解决”了(所有程序执行都会停止),并且避免了执行可能(意外或恶意地)永远运行,从而导致整个以太坊平台完全停止的情况。我们将在后面的章节中更详细地探讨停机问题。
EVM有一个基于堆栈的架构,将所有内存中的值存储在堆栈上。它的字长为256位,主要是为了方便本地的哈希和椭圆曲线操作,并且它有几个可寻址的数据组件:
- 一个不可变的程序代码ROM,加载了要执行的智能合约的字节码
- 一个易失性内存,每个位置都被显式地初始化为零
- 一个瞬态存储,只持续单个交易的持续时间(并且不是以太坊状态的一部分)
- 一个永久存储,是以太坊状态的一部分,也被初始化为零
还有一个在执行期间可用的一组环境变量和数据。我们将在本章的后面部分更详细地介绍这些。
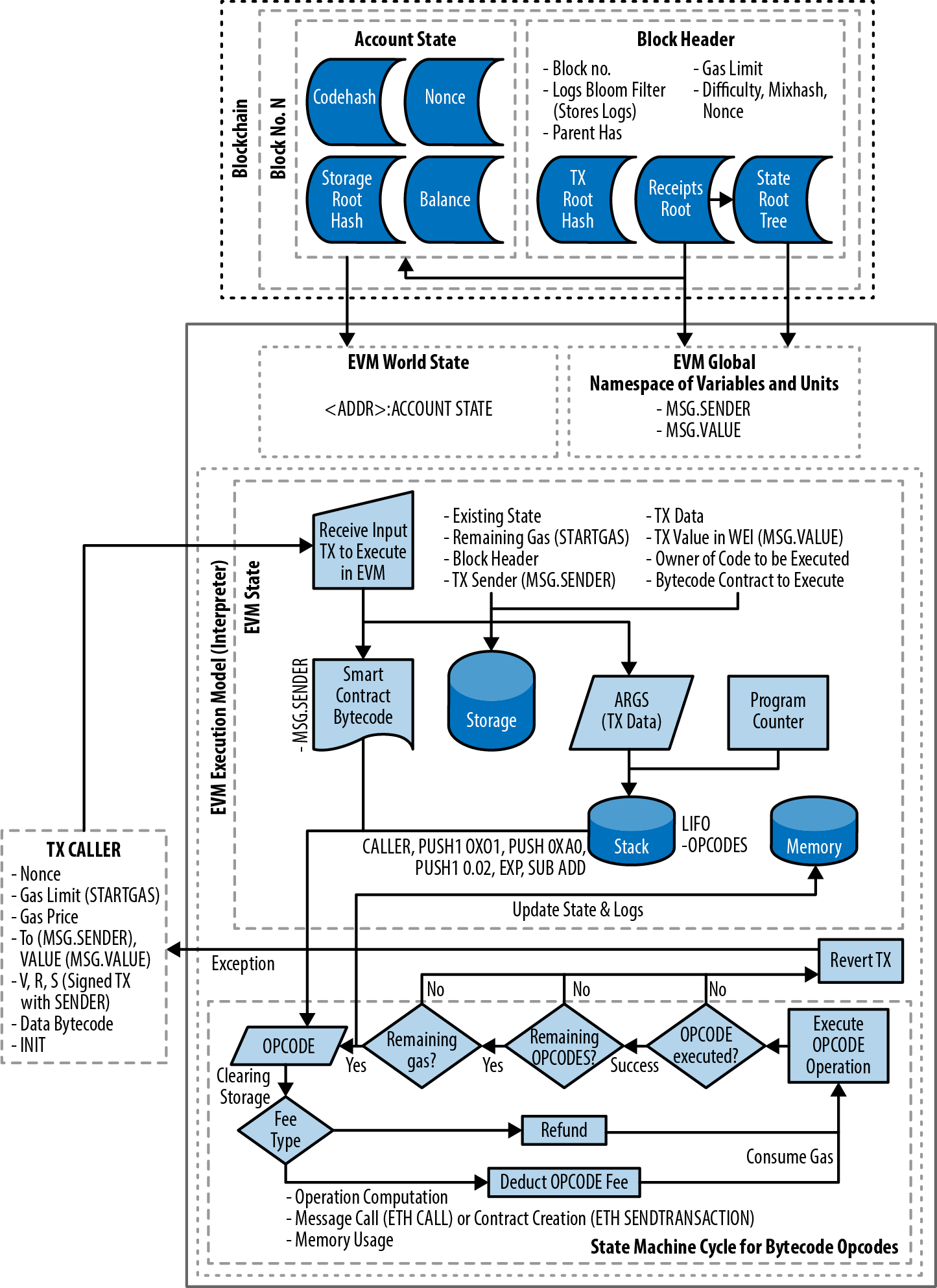
图14-1. EVM架构和执行上下文
与现有技术的比较
术语虚拟机通常应用于真实计算机的虚拟化,通常通过诸如VirtualBox或QEMU之类的虚拟机监控器,或者整个操作系统实例,例如Linux的KVM。这些必须分别提供实际硬件和系统调用以及其他内核功能的软件抽象。
EVM在更有限的领域中运行:它只是一个计算引擎,因此,它只提供计算和存储的抽象,类似于Java虚拟机(JVM)规范。从高层次的角度来看,JVM旨在提供一个与底层主机操作系统或硬件无关的运行时环境,从而实现跨各种系统的兼容性。诸如Java或Scala之类的高级编程语言(使用JVM)或C#(使用.NET)被编译成它们各自虚拟机的字节码指令集。以同样的方式,EVM执行它自己的字节码指令集(在下一节中描述),诸如Solidity、Vyper和Yul之类的高级智能合约编程语言被编译成这些字节码指令集。
因此,EVM没有调度能力,因为执行顺序是在外部组织的:以太坊客户端通过经过验证的区块交易来确定哪些智能合约需要执行以及以何种顺序执行。从这个意义上讲,以太坊世界计算机是单线程的,就像JavaScript一样。EVM也没有任何“系统接口”处理或“硬件支持”——没有物理机器可以与之交互。以太坊世界计算机是完全虚拟的。
其他区块链在做什么?
EVM绝对是加密货币领域中使用最广泛的虚拟机。大多数其他的L1和L2区块链都使用EVM来保持与所有现有工具和框架的兼容性,并直接从以太坊社区吸引项目和开发者。
然而,近年来出现了一系列不同的虚拟机:Solana VM、Wasm VM、Cairo VM和Move VM可能是最著名和最有趣的虚拟机,每个都有其优点和缺点。它们采用不同的智能合约开发方法:
自定义语言
像Cairo和Move这样的一些平台已经创建了专门用于编写智能合约的编程语言。这类似于以太坊如何使用Solidity和Vyper作为其虚拟机EVM的语言。
标准语言
其他的,例如Solana和那些使用WebAssembly(Wasm)的平台,允许开发者使用广泛使用的编程语言来编写智能合约。例如,这些平台通常支持使用Rust进行智能合约开发。
这些替代虚拟机与EVM不同的另一个领域是交易的并行化。我们已经说过EVM按顺序处理交易,没有任何形式的并行化。一些项目看到了这个缺点并试图改进它。例如,Solana VM和Move VM都可以处理交易的并行执行,即使这并不总是可能的——也就是说,当两个交易通过与相同的合约交互来修改同一块存储时,它们不能并行执行。
我们必须说,这些改进虚拟机性能的努力不仅仅是在以太坊之外进行的。事实上,很多团队都在努力突破EVM当前的限制,试图添加并行化和其他很酷的功能,例如从EVM字节码到本地机器代码的提前编译(AOT)或即时编译(JIT)。
EVM指令集(字节码操作)
EVM指令集提供了你可能期望的大多数操作,包括:
- 算术和按位逻辑运算
- 执行上下文查询
- 堆栈、内存和存储访问
- 控制流操作
- 日志记录、调用和其他运算符
除了典型的字节码操作之外,EVM还可以访问账户信息(例如,地址和余额)和区块信息(例如,区块号和当前gas价格)。
让我们通过更详细地查看可用的操作码以及它们的作用来开始我们对EVM的探索。正如你可能期望的那样,所有操作数都取自堆栈,并且结果(如果适用)通常会放回堆栈的顶部。
可用的操作码可以分为以下几类:
算术运算
算术操作码指令包括:
ADD // 将堆栈顶部的两个项目相加
MUL // 将堆栈顶部的两个项目相乘
SUB // 将堆栈顶部的两个项目相减
DIV // 整数除法
SDIV // 带符号的整数除法
MOD // 取模(余数)运算
SMOD // 带符号的取模运算
ADDMOD // 任意数的加法取模
MULMOD // 任意数的乘法取模
EXP // 指数运算
SIGNEXTEND // 扩展一个二进制补码有符号整数的长度
SHA3 // 计算内存块的Keccak-256哈希值
请注意,除非另有说明,否则所有算术运算都以2256为模进行,并且零的零次幂00被认为是1。
栈操作
栈,内存和存储管理指令包括:
POP // 从堆栈中删除最上面的项目
MLOAD // 从内存中加载一个字
MSTORE // 将一个字保存到内存中
MSTORE8 // 将一个字节保存到内存中
SLOAD // 从存储中加载一个字
SSTORE // 将一个字保存到存储中
TLOAD // 从临时存储中加载一个字
TSTORE // 将一个字保存到临时存储中
MSIZE // 获取活动内存的大小(以字节为单位)
PUSH0 // 将值0放在堆栈上
PUSHx // 将x字节的项目放在堆栈上,其中x可以是1到32(全字)范围内的任何整数
DUPx // 复制第x个堆栈项目,其中x可以是1到16范围内的任何整数
SWAPx // 交换第1个和第(x+1)个堆栈项目,其中x可以是1到16范围内的任何整数
流程控制操作
用于控制流程的指令包括:
STOP // 停止执行
JUMP // 将程序计数器设置为任何值
JUMPI // 有条件地更改程序计数器
PC // 获取程序计数器的值(在对应于此指令的增量之前)
JUMPDEST // 标记跳转的有效目标
系统操作
用于执行程序的系统的操作码包括:
LOGx // 附加一个包含x个主题的日志记录,其中x是0到4范围内的任何整数
CREATE // 创建一个具有相关代码的新账户
CALL // 消息调用到另一个账户,即运行另一个账户的代码
CALLCODE // 消息调用到当前账户,使用另一个账户的代码
RETURN // 停止执行并返回输出数据
DELEGATECALL // 消息调用到当前账户,使用另一个账户的代码,但保留当前发送者和值
STATICCALL // 静态的消息调用到账户,即它不能更改任何账户的状态
REVERT // 停止执行,恢复状态更改但返回数据和剩余的gas
INVALID // 指定的无效指令
SELFDESTRUCT // 停止执行,如果在创建合约的同一事务中执行,则注册要删除的账户。
// 请注意,非常不鼓励使用它,并且操作码被认为是已弃用的。
逻辑运算
用于比较和位运算的操作码包括:
LT // 小于比较
GT // 大于比较
SLT // 带符号的小于比较
SGT // 带符号的大于比较
EQ // 等于比较
ISZERO // 简单的NOT运算符
AND // 按位AND运算
OR // 按位OR运算
XOR // 按位XOR运算
NOT // 按位NOT运算
BYTE // 从完整宽度的256位字中检索单个字节
环境操作
处理执行环境信息的操作码包括:
GAS // 获取可用的gas量(在减少此指令的gas消耗后)
ADDRESS // 获取当前正在执行的账户的地址
BALANCE // 获取任何给定账户的账户余额
ORIGIN // 获取启动此EVM执行的EOA的地址
CALLER // 获取直接负责此执行的调用者的地址
CALLVALUE // 获取负责此执行的调用者存入的以太币数量
CALLDATALOAD // 获取负责此执行的调用者发送的输入数据
CALLDATASIZE // 获取输入数据的大小
CALLDATACOPY // 将输入数据复制到内存中
CODESIZE // 获取当前环境中运行的代码的大小
CODECOPY // 将当前环境中运行的代码复制到内存中
GASPRICE // 获取原始交易指定的gas价格
EXTCODESIZE // 获取任何账户的代码大小
EXTCODECOPY // 将任何账户的代码复制到内存中
RETURNDATASIZE // 获取当前环境中先前调用的输出数据的大小
RETURNDATACOPY // 将先前调用输出的数据复制到内存中
区块操作
用于访问当前区块信息的操作码包括:
BLOCKHASH // 获取最近完成的256个区块之一的哈希值
COINBASE // 获取区块受益人的地址,用于区块奖励
TIMESTAMP // 获取区块的时间戳
NUMBER // 获取区块号
PREVRANDAO // 获取前一个区块的RANDAO混合值。 此操作码取代了自 The Merge 硬分叉以来的 DIFFICULTY 操作码。
GASLIMIT // 获取区块的gas限制
以太坊状态
EVM 的工作是通过计算有效的状态转换来更新以太坊状态,这是智能合约代码执行的结果,由以太坊协议定义。这方面导致以太坊被描述为基于交易的状态机,这反映了外部参与者(即,账户持有人和验证者)通过创建、接受和排序交易来启动状态转换的事实。 此时考虑什么构成以太坊状态是有用的。
在顶层,我们有以太坊世界状态。 世界状态是以太坊地址(160 位值)到账户的映射。在较低级别,每个以太坊地址代表一个账户,该账户包括以太币余额(存储为账户拥有的 wei 数量)、nonce(表示如果它是 EOA 则从此账户成功发送的交易数量,或者如果它是合约账户则由此创建的合约数量)、账户的存储(这是仅由智能合约使用的永久数据存储)和账户的程序代码(同样,仅当账户是智能合约账户时)。 EOA 将始终没有代码和空存储。
当交易导致智能合约代码执行时,将根据正在创建的当前区块和正在处理的特定交易来实例化 EVM,其中包含所需的所有信息。 特别是,EVM 的程序代码 ROM 加载了被调用合约账户的代码,程序计数器设置为零,存储从合约账户的存储加载,内存设置为全部为零,并且所有区块和环境变量都被设置。 一个关键变量是此执行的 gas 供应,它设置为交易开始时发送者支付的 gas 量(有关更多详细信息,请参阅“执行期间的 Gas 记账”)。 随着代码执行的进行, 根据已执行操作的 gas 成本降低 gas 供应。 如果在任何时候 gas 供应小于零,我们会得到一个 out-of-gas (OOG) 异常:执行立即停止,并且交易被放弃。 除了发送者的 nonce 递增以及其以太币余额下降以支付区块受益人为执行代码到停止点所使用的资源外,不会应用对[以太坊状态]的任何更改 。 在此点,您可以将 EVM 视为在以太坊世界状态的沙盒副本上运行,如果由于任何原因无法完成执行,则此沙盒版本将被完全丢弃。 但是,如果执行确实成功完成,那么真实世界状态将更新以匹配沙盒版本,包括对被调用合约的存储数据、创建的任何新合约以及启动的任何以太币余额转移所做的任何更改 。
代码执行是一个递归过程。合约可以调用其他合约,每次调用都会导致另一个 EVM 围绕调用的新目标实例化。每个实例化都有其沙盒世界状态从上面一级的 EVM 的沙盒初始化。每个实例化(上下文)还被赋予了指定数量的 gas 作为其 gas 供应(当然不超过上面一级剩余的 gas 量),因此它本身可能会由于被给予太少的 gas 以完成其执行而停止并出现异常。 同样,在这种情况下,沙盒状态将被丢弃,并且执行返回到上面一级的 EVM。
以太坊无状态性
虽然在撰写本文时(2025 年 6 月),所有以太坊节点都必须计算并维护最新状态 - 即我们之前称之为世界状态的内容 - 以便能够通过重新执行它包含的所有交易来检查每个新区块的正确性 ,但有计划摆脱它,至少部分摆脱。
这个想法是让一组受限制的参与者,例如搜索者和构建者,仍然需要访问状态以创建和发布新区块,而所有其他节点都可以在没有它的情况下以加密方式验证这些区块。 这被称为 无状态性。
无状态性在以太坊路线图中仍然遥遥无期,因为它需要对核心协议进行一些修改:
已确立的提议者-构建者分离 (ePBS)
将用交易填充区块的创建区块工作与将其提议给 P2P 网络的工作分开。 第一个是由高度专业化的实体(称为搜索者和构建者)完成的,他们能够创建超优化的区块,而第二个则由以太坊验证器节点完成。 这已经是主网上的现实,即使它尚未正式纳入协议中。 事实上,大多数以太坊区块已经由一小部分大型构建者构建。
Verkle 树
替换以太坊当前用于存储状态的数据结构:Merkle-Patricia trie。 这大大减少了验证状态正确性所需的密码证明的大小,并使验证速度比传统的 Merkle-Patricia trie 快。
注意
正在测试其他基于哈希的二叉树,以可能替换 Verkle 树。 核心思想只是拥有一个用于状态的数据结构,使其可以创建快速且易于验证的小型证明。
这两个升级的结合可能会导致这样一种情况,即只有拥有更强大的硬件并且想要创建区块的大型实体才需要存储和访问完整状态。 与新区块一起,他们将创建一个加密见证:证明基于他们包含在区块中的交易正确计算了新状态的最小数据集。
所有其他节点(包括验证器节点)仅存储状态根,它是整个状态的哈希值。 当他们收到一个新区块时,他们使用相关的见证来验证其正确性。
这使得运行以太坊节点非常轻量级,因为您不必存储完整状态,甚至不需要重新执行所有交易(在 EVM 中),但您仍然能够验证一切是否正确,因此您无需信任第三方。 您甚至可以在您的智能手机上运行一个节点……
即使研究进展迅速,我们可能还需要几年才能在主网上实现无状态性。
Merkle-Patricia Trie
目前,以太坊状态使用一种非常特殊的数据结构存储,称为修改后的 Merkle-Patricia trie。 我们在上一节中简要提到了 Merkle-Patricia 树(我们将称其为 MPT),但了解其工作原理以及为什么以及以太坊如何使用它作为存储状态的方式(而不仅仅是这样……)非常重要,因为同样的推理适用于 Verkle tries。 在深入研究 MPT 之前,您需要了解 Merkle 树,因为它们代表了构建 MPT 的基础。
Merkle 树
Merkle 树是一种非常古老的数据结构,由 Ralph Merkle 于 1988 年发明,旨在构建更好的数字签名。 当您需要能够验证某些数据是否存在于数据库中并且没有被篡改时,它们非常有效,而无需发送整个数据库来证明它。
从数据集合开始创建 Merkle 树很容易。 您需要将数据分成几个块; 然后,将这些块哈希在一起,并以递归方式重复最后一个步骤,直到只获得一个最终块。 该块代表Merkle 根:所有用于创建树的数据的一种数字指纹。
让我们从头开始创建一个二叉 Merkle 树 - Merkle 树的最简单形式 - 这样您就可以更熟悉它。 我们从八个数据块开始 - 您可以将它们视为英语中的不同单词。 我们使用特定的哈希函数对每个块进行哈希处理——正如第 4 章中已经提到的那样,以太坊使用 Keccak-256 哈希函数——获得 Merkle 树的叶子,在图 14-2 中表示为 hash_1、hash_2 等等。 然后,我们将每对叶子连接起来并再次对其进行哈希处理,创建 hash_12、hash_34 等等。 我们重复此连接和哈希处理的过程两次,直到得到一个最终结果,该结果代表我们的 Merkle 根:hash_12345678。
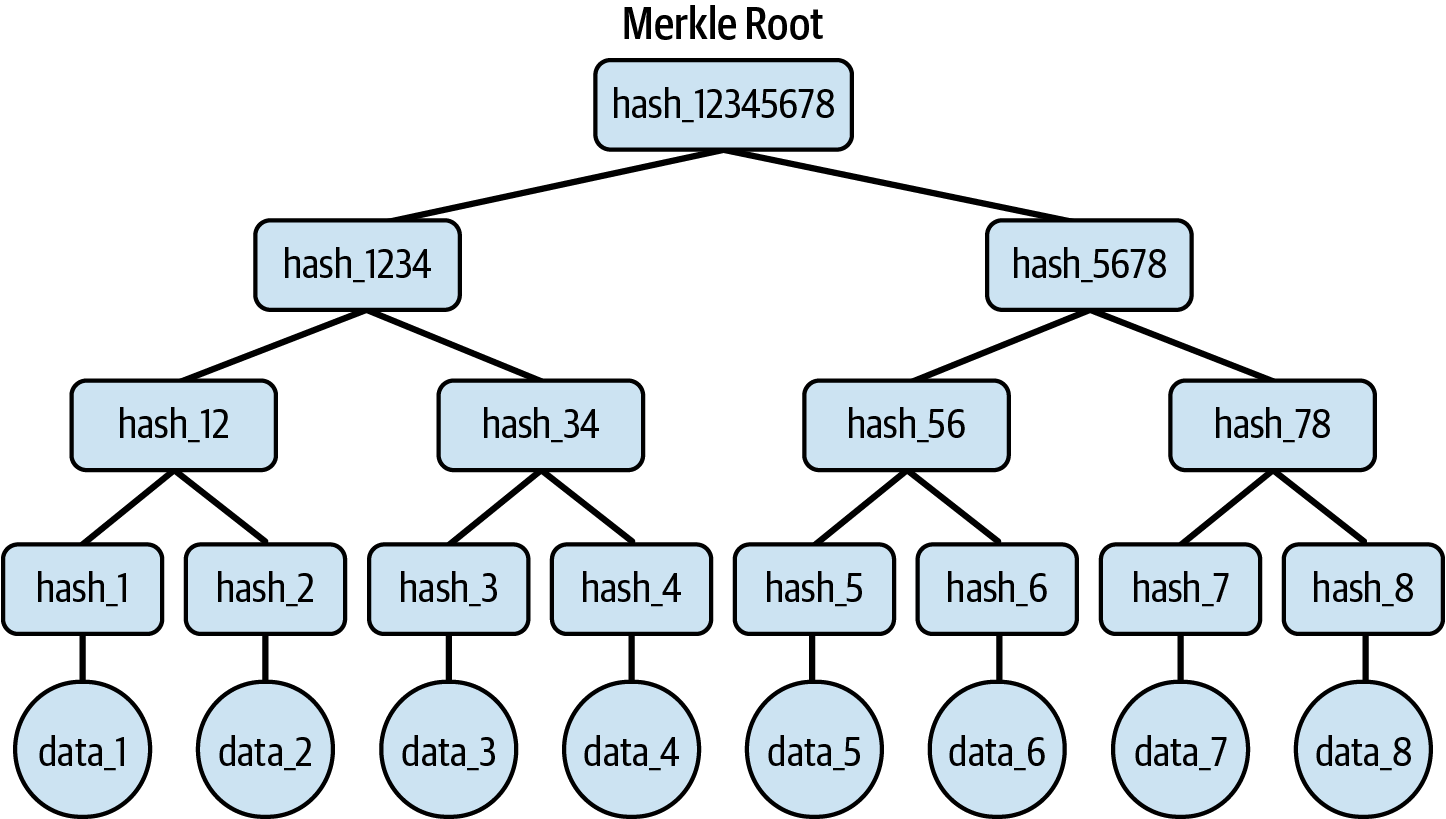
图 14-2。二叉 merkle 树
现在,您可能会问为什么我们需要 Merkle 树来存储数据。 与仅将每个块存储在传统数据库中相比,它不是更复杂吗?
答案是肯定的,与将每个块存储在键值或 SQL 数据库中相比,它要复杂得多。 我们使用这些数据结构的唯一原因是它们在提供廉价的加密证明方面非常有效,证明任何一个块都存在于整个数据集并且没有被操纵。 事实上,如果我们使用普通数据库来存储数据,并且被要求提供我们有特定块的证明,我们需要发布我们的整个数据集,以便读者可以确定我们没有说谎。
让我们使用我们之前的示例来在实践中看到这一点。 假设我们要证明 data_1 包含在数据集中。 天真的方法是提供整个数据集,从 data_1 到 data_8:总共八个项目。 使用 Merkle 树,我们只需要提供 hash_2、hash_34 和 hash_5678。 然后,任何人都可以自行计算 Merkle 根,并将其与我们最初计算的(公开共享的)进行比较。 如果它们匹配,您可以完全确定 data_1 是初始数据集的一部分,如图 14-3 所示。
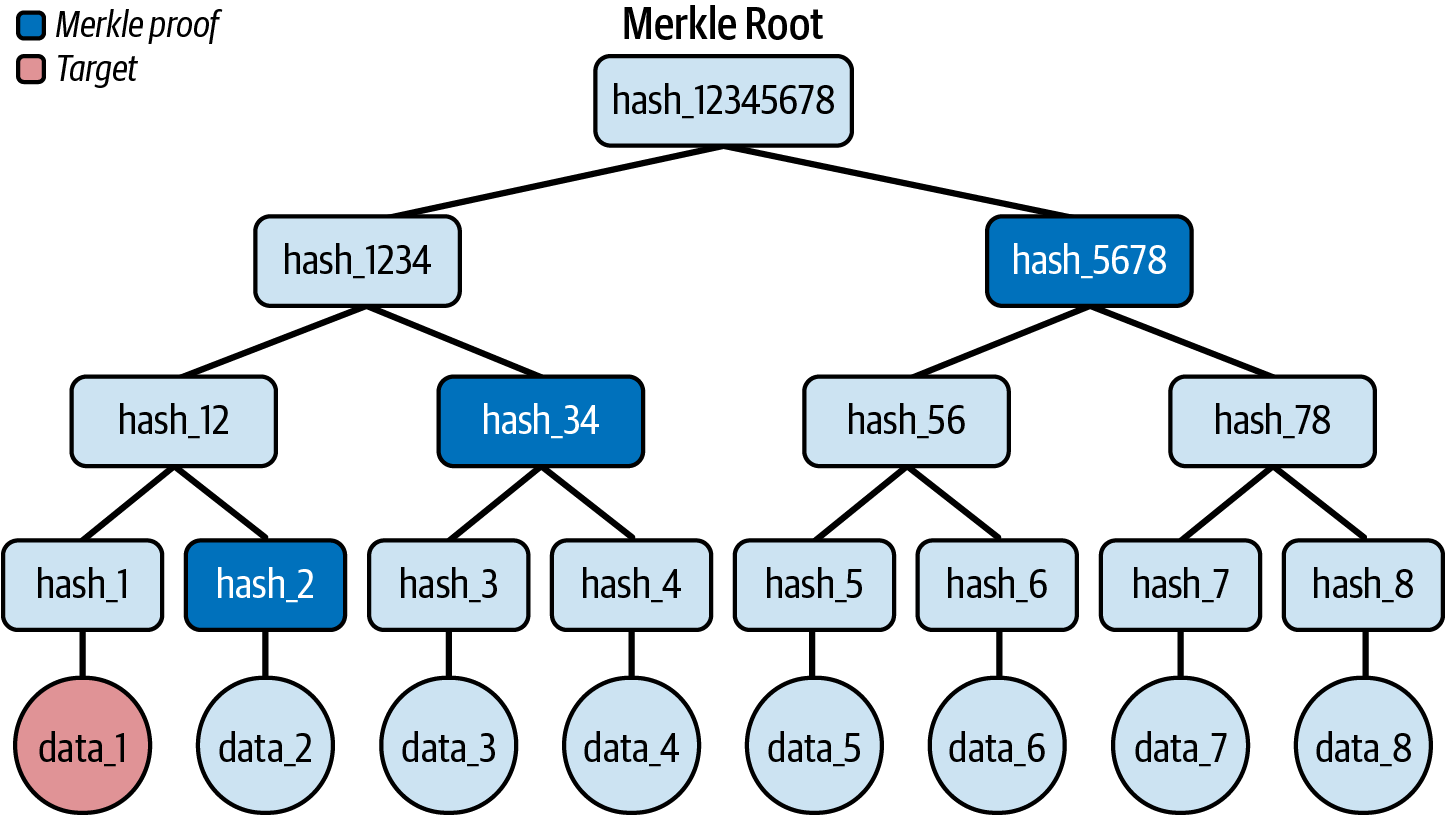
图 14-3. 用于验证 data_1 包含在树中的 Merkle 证明
提示
要重建 Merkle 树,您可以按照以下步骤操作:
- 哈希 data_1 并获得 hash_1。
- 将 hash_1 与提供的 hash_2 连接起来,对其进行哈希处理,并获得 hash_12。
- 将 hash_12 与提供的 hash_34 连接起来,对其进行哈希处理,并获得 hash_1234。
- 将 hash_1234 与提供的 hash_5678 连接起来,对其进行哈希处理,并获得最终的 Merkle 根。
请注意,我们仅使用三个项目,而使用没有 Merkle 树的朴素方法我们需要使用八个项目。 这只是一个玩具示例 - 当您拥有大量数据时,节省的更多。
用数学术语来说,Merkle 树提供 O(log(n)) 复杂度,而天真方法的线性 O(n) 复杂度,如图 14-4 所示。
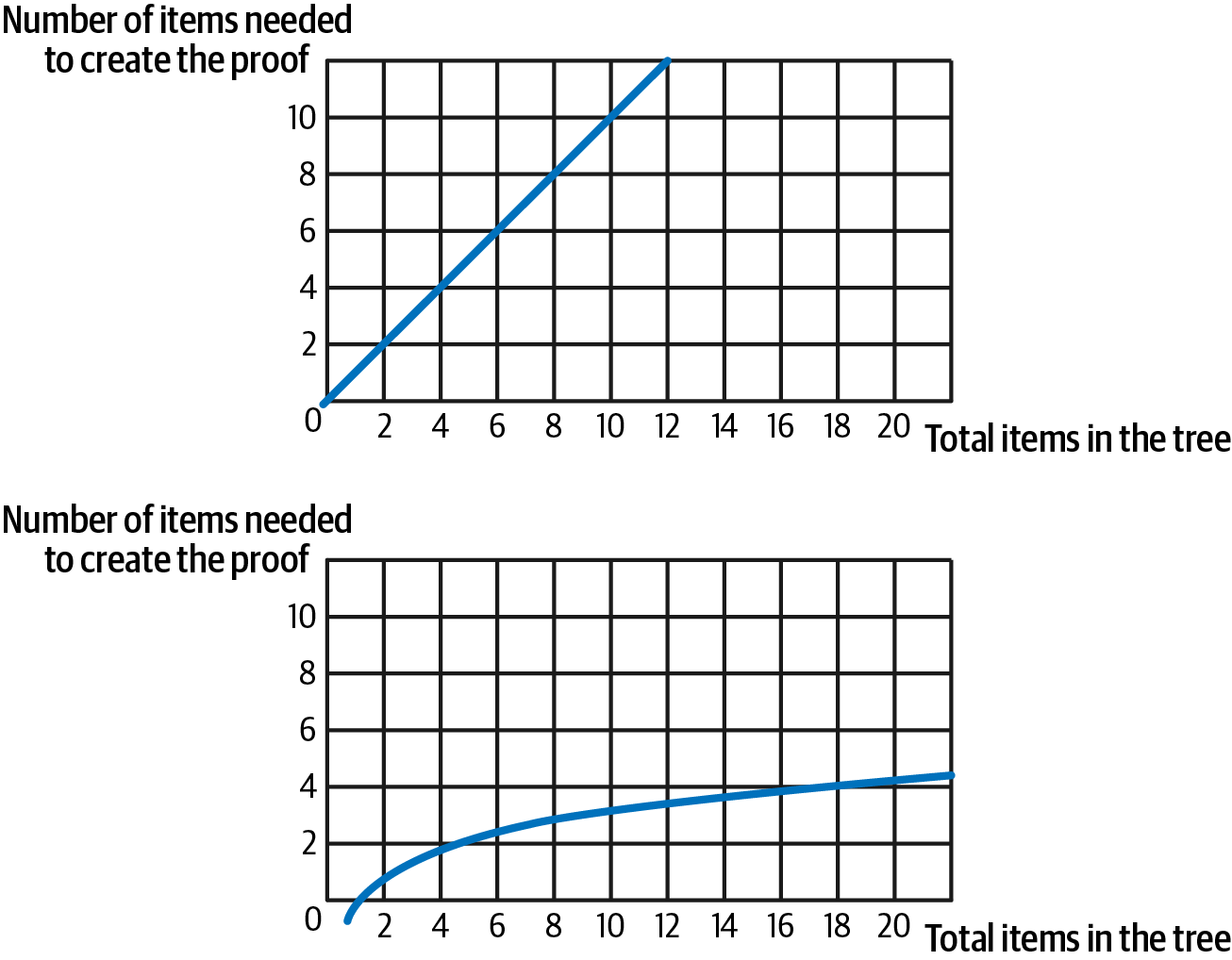
图 14-4。O(n) 线性复杂度(顶部)与 O(log(n)) 复杂度(底部)
在以太坊世界中,这意味着提供关于地址余额、交易结果或特定智能合约的字节码的证明更便宜也更容易。
比特币中的 Merkle 树
比特币开创了区块链技术中使用 Merkle 树的先河。 事实上,每个比特币区块都包含包含在同一区块中的所有交易的 Merkle 根,因此不能在不修改整个区块头(也损害 PoW)的情况下修改任何一个。
以太坊中的 Merkle-Patricia trie
以太坊采用了相同的概念并将其应用于自身,并针对其特定需求进行了一些修改。 Merkle 树非常适合永不更改的永久数据,例如比特币交易。 然而,以太坊状态不断变化 如你所见,这个合约所做的只是持有一个持久状态变量,该变量被设置为运行此合约的最后一个账户的地址。
如果你查看 BytecodeDir 目录,你会看到 opcode 文件 Example.opcode,其中包含示例合约的 EVM opcode 指令。在文本编辑器中打开 Example.opcode 文件将显示以下内容:
PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH1 0xE JUMPI PUSH0 PUSH0 REVERT JUMPDEST POP PUSH1 0xA9 DUP1 PUSH1 0x1A PUSH0 CODECOPY PUSH0 RETURN INVALID PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH1 0xE JUMPI PUSH0 PUSH0 REVERT JUMPDEST POP PUSH1 0x4 CALLDATASIZE LT PUSH1 0x26 JUMPI PUSH0 CALLDATALOAD PUSH1 0xE0 SHR DUP1 PUSH4 0xF8A8FD6D EQ PUSH1 0x2A JUMPI JUMPDEST PUSH0 PUSH0 REVERT JUMPDEST PUSH1 0x30 PUSH1 0x32 JUMP JUMPDEST STOP JUMPDEST CALLER PUSH0 PUSH0 PUSH2 0x100 EXP DUP2 SLOAD DUP2 PUSH20 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF MUL NOT AND SWAP1 DUP4 PUSH200xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF AND MUL OR SWAP1 SSTORE POP JUMP INVALID LOG2 PUSH5 0x6970667358 0x22 SLT KECCAK256 JUMPI 0xBB RETURNDATACOPY SWAP15 CALLVALUE 0xB3 0xB1 SMOD BLOBHASH STATICCALL MCOPY PUSH10 0x856E7132D8FEED4D83B6 0xB2 0xBE PUSH30 0x8B43532C818BFD64736F6C634300081B0033000000000000000000000000
使用 --asm 选项编译示例会在我们的 BytecodeDir 目录中生成一个名为 Example.evm 的文件。它包含 EVM 字节码指令的稍微高级的描述,以及一些有用的注释:
/* "Example.sol":61:171 contract Example {... */
mstore(0x40, 0x80)
callvalue
dup1
iszero
tag_1
jumpi
revert(0x00, 0x00)
tag_1:
pop
dataSize(sub_0)
dup1
dataOffset(sub_0)
0x00
codecopy
0x00
return
stop
sub_0: assembly {
/* "Example.sol":61:171 contract Example {... */
mstore(0x40, 0x80)
callvalue
dup1
iszero
tag_1
jumpi
revert(0x00, 0x00)
tag_1:
pop
jumpi(tag_2, lt(calldatasize, 0x04))
shr(0xe0, calldataload(0x00))
dup1
0xf8a8fd6d
eq
tag_3
jumpi
tag_2:
revert(0x00, 0x00)
/* "Example.sol":109:169 function test() public {... */
tag_3:
tag_4
tag_5
jump // in
tag_4:
stop
tag_5:
/* "Example.sol":154:164 msg.sender */
caller
/* "Example.sol":138:151 contractOwner */
0x00
0x00
/* "Example.sol":138:164 contractOwner = msg.sender */
0x0100
exp
dup2
sload
dup2
0xffffffffffffffffffffffffffffffffffffffff
mul
not
and
swap1
dup4
0xffffffffffffffffffffffffffffffffffffffff
and
mul
or
swap1
sstore
pop
/* "Example.sol":109:169 function test() public {... */
jump // out
auxdata: 0xa264697066735822122057bb3e9e34b3b10749fa5e69856e7132d8feed4d83b6b2be7d8b43532c818bfd64736f6c634300081b0033
}
--bin 选项生成机器可读的十六进制字节码:
6080604052348015600e575f5ffd5b5060a980601a5f395ff3fe6080604052348015600e575f5ffd5b50600436106026575f3560e01c8063f8a8fd6d14602a575b5f5ffd5b60306032565b005b335f5f6101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff16021790555056fea264697066735822122057bb3e9e34b3b10749fa5e69856e7132d8feed4d83b6b2be7d8b43532c818bfd64736f6c634300081b0033
你可以使用 “EVM 指令集(字节码操作)” 中给出的 opcode 列表来详细调查这里发生了什么。然而,这相当困难,所以让我们从检查前四个指令开始:
PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE
这里,我们有 PUSH1 后跟一个值为 0x80 的原始字节。这个 EVM 指令获取程序代码中 opcode 之后的单个字节(作为字面值),并将其推送到堆栈上。可以将大小高达 32 字节的值推送到堆栈上,如:
PUSH32 0x436f6e67726174756c6174696f6e732120536f6f6e20746f206d617374657221
来自 example.opcode 的第二个 PUSH1 opcode 将 0x40 存储到堆栈的顶部(将已经存在的 0x80 向下推一个槽)。
接下来是 MSTORE,它是一个内存存储操作,将一个值保存到 EVM 的内存中。它接受两个参数,并且像大多数 EVM 操作一样,从堆栈中获取它们。对于每个参数,堆栈被“弹出”——也就是说,堆栈上的顶部值被取下,并且堆栈上的所有其他值都向上移动一个位置。MSTORE 的第一个参数是内存中要保存的值的地址。对于这个程序,我们在堆栈的顶部有 0x40,所以它从堆栈中移除并用作内存地址。第二个参数是要保存的值,这里是 0x80。在执行 MSTORE 操作之后,我们的堆栈再次为空,但是我们在内存位置 0x40 处有值 0x80(十进制的 128)。
下一个 opcode 是 CALLVALUE,它是一个环境 opcode,将启动此执行的消息调用所发送的以太币量(以 wei 为单位测量)推送到堆栈的顶部。
我们可以继续以这种方式逐步执行此程序,直到我们完全理解此代码生效的底层状态更改,但这在现阶段对我们没有帮助。我们将在本章的后面部分再讨论它。
合约部署代码
在 Ethereum 平台上创建和部署新合约时使用的代码与合约本身的代码之间存在一个重要但细微的差别。要创建新合约,需要一个特殊的交易,其 to 字段设置为特殊的 0x0 地址,并且其 data 字段设置为合约的初始化代码。当处理这样的合约创建交易时,新合约账户的代码不是交易的 data 字段中的代码。相反,会实例化一个 EVM,其程序代码 ROM 中加载了交易的 data 字段中的代码,然后将该部署代码执行的输出作为新合约账户的代码。这样,就可以使用部署时的 Ethereum 世界状态以编程方式初始化新合约,设置合约存储中的值,甚至发送以太币或创建更多的新合约。
当离线编译合约时——例如,在命令行上使用 solc——您可以获得部署字节码或运行时字节码。部署字节码用于新合约账户初始化的每个方面,包括当交易调用这个新合约时实际最终执行的字节码(即,运行时字节码)以及基于合约构造函数初始化所有内容的字节码。另一方面,运行时字节码正是当调用新合约时最终执行的字节码,仅此而已;它不包括在部署期间初始化合约所需的字节码。
让我们以我们在前面章节中创建的简单 Faucet.sol 合约为例:
// SPDX-License-Identifier: GPL-3.0
pragma solidity 0.8.27;
contract Faucet {
// Give out ether to anyone who asks
function withdraw(uint256 _withdrawAmount, address payable _to) public {
// Limit withdrawal amount
require(_withdrawAmount <= 1000000000000);
// Send the amount to the address that requested it
_to.transfer(_withdrawAmount);
}
// Function to receive Ether. msg.data must be empty
receive() external payable {}
// Fallback function is called when msg.data is not empty
fallback() external payable {}
}
要获取部署字节码,我们将运行 solc --bin Faucet.sol。如果我们只想获取运行时字节码,我们将运行 solc --bin-runtime Faucet.sol。如果你比较这些命令的输出,你会发现运行时字节码是部署字节码的子集。换句话说,运行时字节码完全包含在部署字节码中。
在链上部署合约的 CREATE 与 CREATE2
CREATE 和 CREATE2 是仅有的两个允许你在链上部署新合约的 opcode。它们之间的主要区别与新创建合约的结果地址有关。使用 CREATE,目标地址的计算方式如下:
address = keccak256[rlp(sender_address ++ sender_nonce)][12:]
它是发送者地址及其 nonce 的 RLP 编码的 Keccak-256 哈希的最右边的 20 个字节。
CREATE2 是在 2019 年的君士坦丁堡硬分叉期间添加的,目的是让开发者创建新合约,其中结果地址不依赖于发送者的状态(即,nonce)。事实上,它的行为与 CREATE opcode 完全相同,但是目标地址的计算方式如下:
address = keccak256(0xff ++ sender_address ++ salt ++ keccak256(init_code))[12:]
其中:
init_code是新合约的部署字节码。salt是一个 32 字节的值(从堆栈中获取)。
反汇编字节码
反汇编 EVM 字节码是一种了解高级 Solidity 在 EVM 中如何运作的好方法。你可以使用一些反汇编器来执行此操作:
- Ethersplay 是 Binary Ninja(一个反汇编器)的 EVM 插件。顺便说一句,要使用插件,你需要购买 Binary Ninja 的完整应用程序。
- Heimdall 是一个高级 EVM 智能合约工具包,专门用于字节码分析和从未经验证的合约中提取信息。
在本节中,我们将使用 Heimdall 来生成图 14-21。在获得 Faucet.sol 的运行时字节码之后,我们可以将其提供给 Heimdall,以查看 EVM 指令的外观。
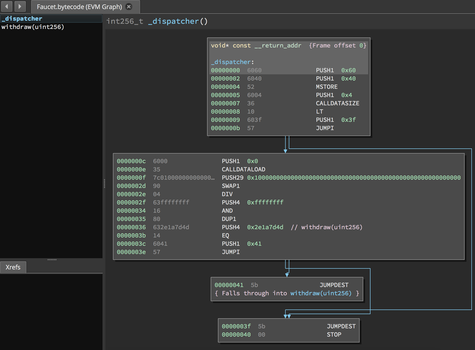
图 14-21。反汇编 Faucet 运行时字节码
安装 Heimdall
首先,你需要确保你的计算机上安装了 Rust。如果未安装,请运行以下命令:
$ curl https://sh.rustup.rs -sSf | sh
然后,依次运行以下两个命令:
$ curl -L http://get.heimdall.rs | bash
$ bifrost
现在,你应该已正确安装 Heimdall。你可以通过运行以下命令来验证:
$ heimdall --version
你应该看到类似以下内容:
$ heimdall --version
heimdall 0.8.4
注意
有关如何安装 Heimdall 的最新信息,请参阅你可以在 GitHub 仓库 中找到的官方文档。
使用 Heimdall 反汇编字节码
现在我们已正确安装 Heimdall,我们准备生成你在图 14-21 中看到的相同图表。从我们的 Faucet.sol 合约的运行时字节码开始,你可以运行以下命令:
$ heimdall cfg <在此处插入运行时字节码>
以下是此命令应如下所示的示例:
$ heimdall cfg 608060405260043610610…
现在,你应该看到一个名为 output 的新文件夹。进入它,然后再次进入生成的名为 local 的文件夹。在这里,你应该找到文件 cfg.dot:
$ cd output
$ cd local
$ ls # 现在你应该看到该文件
由于它是一个 .dot 文件,因此我们需要一个特殊的程序才能正确打开它。在本示例中,我们将使用一个网站,该网站允许我们粘贴 .dot 文件的内容,然后为我们生成图形。
首先,你需要复制 .dot 文件的内容:
$ cat cfg.dot
此命令会将文件的全部内容打印到屏幕;复制它,打开一个 控制流图 (CFG) 在线生成器,然后将其粘贴到网页的左侧,如图 14-22 所示。
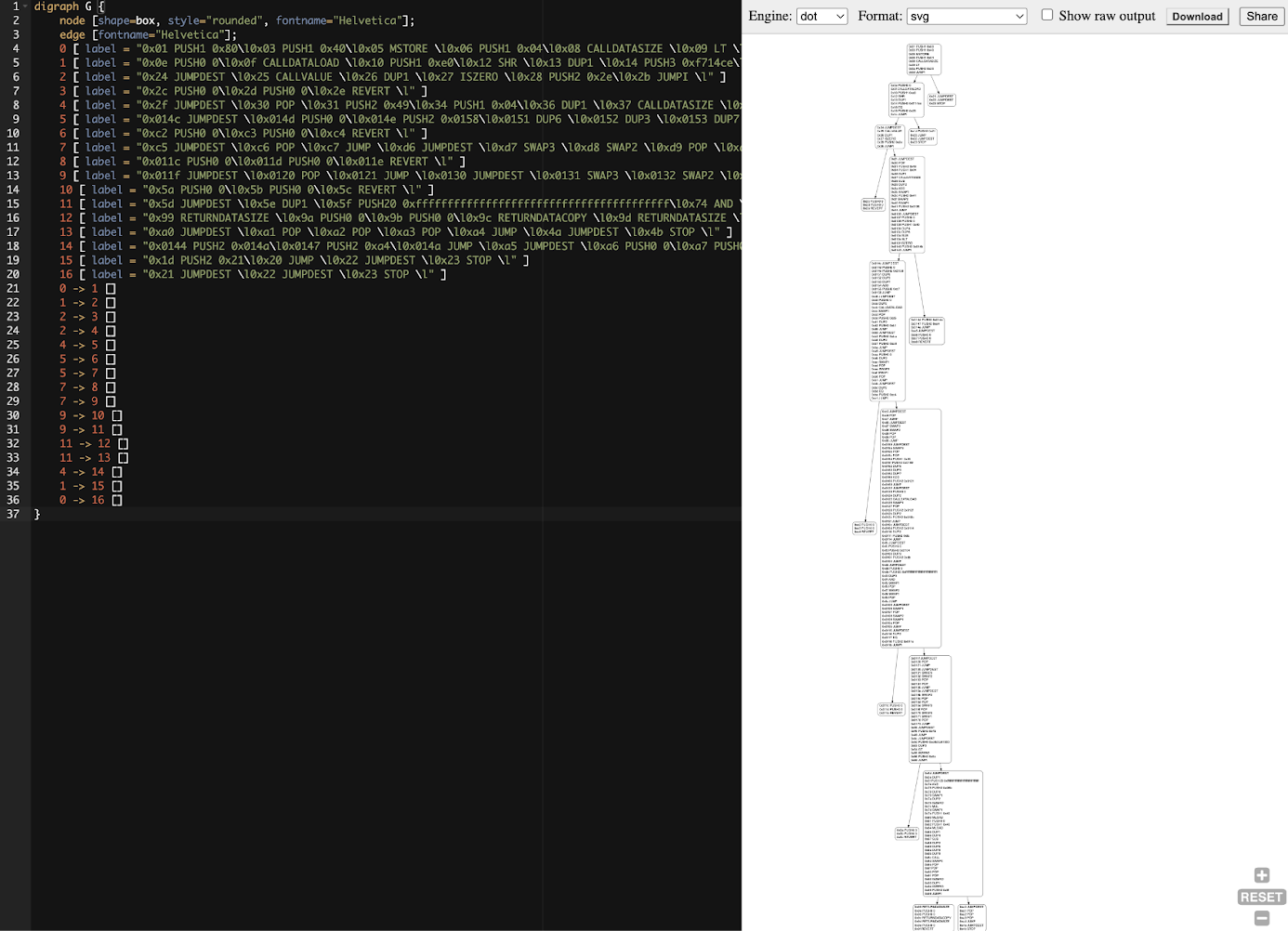
图 14-22。Faucet.sol 合约的控制流图 (CFG)
图 14-23 显示了 Faucet.sol 合约的初始字节码。如你所见,它以与之前的 Example.sol 合约相同的模式开始:PUSH1 0x80 PUSH1 0x40 MSTORE。
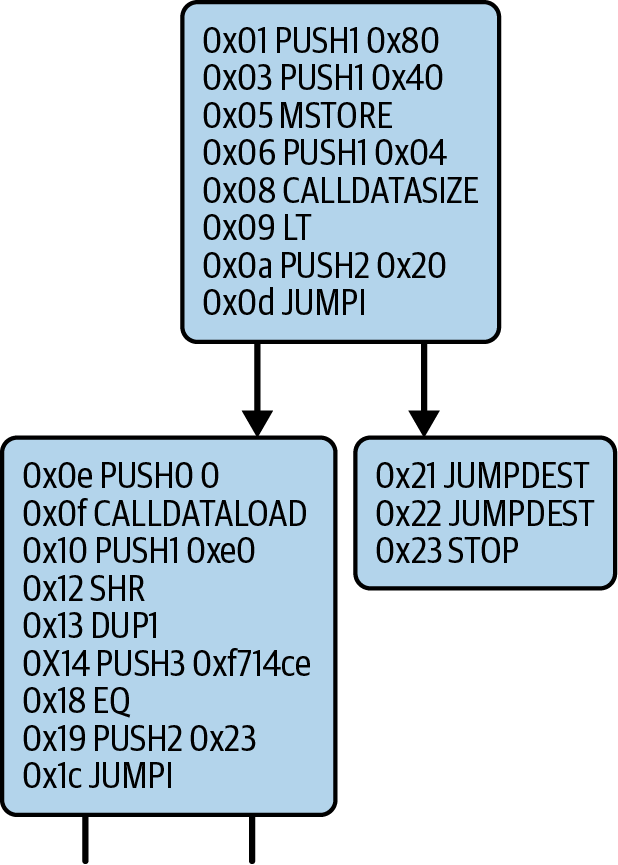
图 14-23。放大 CFG 图的第一部分
当你将交易发送到 ABI 兼容的智能合约时(你可以假定所有合约都是),该交易首先与该智能合约的调度器交互。调度器读取交易的 data 字段,并将相关部分发送到适当的函数。我们可以在反汇编的 Faucet.sol 运行时字节码的开头看到调度器的示例。在熟悉的 MSTORE 指令之后,我们看到以下指令:
PUSH1 0x04
CALLDATASIZE
LT
PUSH2 0x0020
JUMPI
正如我们所见,PUSH1 0x04 将 0x04 放置到堆栈的顶部,否则该堆栈为空。CALLDATASIZE 获取与交易一起发送的数据的大小(以字节为单位)(称为 calldata),并将该数字推送到堆栈上。在执行这些操作之后,堆栈如下所示:
Stack
<来自 tx 的 calldata 的长度>
0x4
下一个指令是 LT,是 "less than" 的缩写。LT 指令检查堆栈上的顶部项是否小于堆栈上的下一项。在我们的例子中,它检查 CALLDATASIZE 的结果是否小于 4 字节。
为什么 EVM 会检查交易的 calldata 是否至少为 4 字节?这是因为函数标识符的工作方式。每个 Solidity 函数都由其 Keccak-256 哈希的前 4 个字节标识。通过将函数的名称及其所有参数放入 keccak256 哈希函数中,我们可以推断出其函数标识符。在我们的例子中,我们有:
keccak256("withdraw(uint256,address)") = 0x00f714ce...
因此,withdraw(uint256,address) 函数的函数标识符为 0x00f714ce,因为这些是结果哈希的前 4 个字节。函数标识符始终为 4 个字节长,因此,如果发送到合约的交易的整个数据字段小于 4 个字节,则没有该交易可能与之通信的函数,除非定义了回退函数。因为我们在 Faucet.sol 中实现了这样的回退函数,所以当 calldata 的长度小于 4 个字节时,EVM 会跳转到此函数。
LT 从堆栈中弹出前两个值,如果交易的数据字段小于 4 个字节,则将 1 推送到堆栈上。否则,它会推送 0。在我们的示例中,让我们假设发送到我们合约的交易的数据字段小于 4 个字节。
PUSH2 0x0020 指令将字节 0x0020 推送到堆栈上。在执行此指令之后,堆栈如下所示:
Stack
0x0020
0x1
下一个指令是 JUMPI,代表 "jump if"。它的工作方式如下:
jumpi(label, cond) // 如果 "cond" 为真,则跳转到 "label"
在我们的例子中,label 是 0x0020,它位于我们智能合约中的回退函数所在的位置。cond 参数为 1,这是之前 LT 指令的结果。要用文字表达整个序列,如果交易数据小于 4 个字节,则合约会跳转到回退函数。
在 0x20 处,在两条 JUMPDEST 指令之后,仅跟随一条 STOP 指令,因为尽管我们声明了一个回退函数,但我们使其为空。正如你在图 14-24 中所见,如果我们没有实现回退函数,则合约会抛出异常。
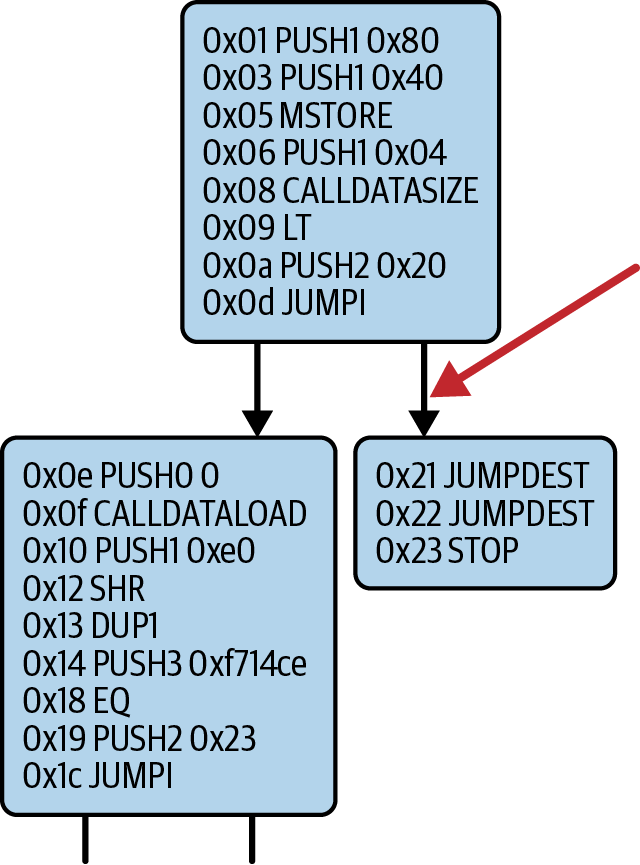
图 14-24。JUMPI 指令导致回退函数
注意
Heimdall 表示从偏移量等于 0x01 开始的字节码,即使 EVM 实际上将其解释为从偏移量 0x00 开始。在前面的示例中,如果条件为真,则 JUMPI 指令告诉 EVM 跳转到偏移量 0x20,但在图中,偏移量 0x20 在此处表示为 0x21。根据经验,你只需要将 EVM 的每个偏移量加一就可以在图上找到它。
让我们检查调度器的中心块。假设我们收到的 calldata 大于 4 个字节,则 JUMPI 指令不会跳转到回退函数。相反,代码执行将继续执行以下指令:
PUSH0 0x0
CALLDATALOAD
PUSH1 0xe0
SHR
DUP1
PUSH3 0xf714ce
EQ
PUSH2 0X23
JUMPI
PUSH0 将 0 推送到堆栈的顶部,现在该堆栈再次为空。CALLDATALOAD 接受作为参数智能合约收到的 calldata 中的索引,并从该索引读取 32 个字节,如下所示:
calldataload(p) // 从字节位置 p 开始加载 32 字节的 calldata
由于 0 是从 PUSH0 命令传递给它的索引,因此 CALLDATALOAD 从字节 0 开始读取 32 字节的 calldata,然后将其推送到堆栈的顶部(在弹出原始 0x0 之后)。在 PUSH1 0xe0 指令之后,堆栈变为:
Stack
0xe0
<从字节 0 开始的 32 字节的 calldata>
SHR 对堆栈上的 32 字节值元素执行 0xe0 位(224 位,28 字节)的逻辑右移。通过将 calldata 向右移动 28 个字节,它隔离了 calldata 的前 4 个字节。事实上,在向右移动时,所有位都会在第一个位之前移动,并且会被丢弃,而新位则设置为 0。请记住,calldata 的前 4 个字节表示我们要触发的函数的函数标识符。
逻辑位移示例
你可以通过一个示例更好地理解这一点。假设堆栈是:
Stack
0x1234567890 // 一个 5 字节元素
我们只想获取前两个字节(即,0x1234)。为了仅使用 EVM 操作码来实现此目的,我们可以执行以下操作:
PUSH1 0x18 // 这表示十六进制的数字 24,24 位 = 3 字节
SHR
事实上,通过将堆栈中的项目向右移动 3 个字节(请记住,每个字节在此处表示为 2 个十六进制数字),我们获得以下项目:
0x0000001234 | 4567890
4567890 部分被丢弃,剩下的只是:
Stack
0x1234
所有前导零都可以忽略,因为它们并不重要。
新的堆栈是:
Stack
<以数据发送的函数标识符>
下一个指令是 DUP1,它复制堆栈中的第一个项目。堆栈现在是:
Stack
<以数据发送的函数标识符>
<以数据发送的函数标识符>
现在有一条 PUSH3 指令,后跟推送数据 0xf714ce。此操作码只是将(推送)数据推送到堆栈上。在此操作码之后,堆栈如下所示:
Stack
0xf714ce
<以数据发送的函数标识符>
<以数据发送的函数标识符>
现在,0xf714ce 看起来你很熟悉吗?你还记得我们的 withdraw(uint256,address) 函数的函数标识符是什么吗?它是 0x00f714ce……请注意,它们是相同的数字,因为可以忽略前导零。
下一个指令 EQ 会弹出堆栈的前两个项目并比较它们。这是调度器执行其主要工作的地方:它比较交易的 msg.data 字段中发送的函数标识符是否与 withdraw(uint256,address) 的函数标识符匹配。如果它们相等,则 EQ 会将 1 推送到堆栈上,该堆栈最终将用于跳转到 withdraw 函数。否则,EQ 会将 0 推送到堆栈上。
假设发送到我们合约的交易的确以 withdraw(uint256,address) 的函数标识符开头,则我们的堆栈已变为:
Stack
1
<以数据发送的函数标识符> (现在已知为 0x00f714ce)
接下来,我们有 PUSH2 0x23,它是在合约中 withdraw(uint256,address) 函数所在的地址。在此指令之后,堆栈如下所示:
Stack
0x23
1
<以 msg.data 发送的函数标识符>
JUMPI 指令是下一个,它再次接受堆栈上的前两个元素作为参数。在本例中,我们有 JUMPI(0x23, 1),它告诉 EVM 执行跳转到 withdraw(uint256,address) 函数的位置,并且可以继续执行该函数的代码。
图灵完备性和 Gas
正如我们已经提到过的,简单来说,如果一个系统或编程语言可以运行任何程序,那么它就是图灵完备的。然而,这种能力有一个非常重要的警告:有些程序需要永远才能运行。一个重要的方面是,我们无法仅通过查看程序来判断它是否需要永远才能执行。我们必须实际执行该程序并等待它完成才能找到答案。当然,如果需要永远才能执行,我们将必须永远等待才能找到答案。这被称为停机问题,如果它没有得到解决,那将是 Ethereum 的一个大问题。
由于停机问题,Ethereum 世界计算机面临着被要求执行永不停止的程序的风险。这可能是意外或恶意造成的。我们已经描述了 Ethereum 如何像单线程机器一样运行,没有任何调度程序,因此如果它陷入无限循环,那将意味着 Ethereum 将变得不可用。
有了 gas,就有一个解决方案:如果在执行了预先指定的最大计算量之后,执行还没有结束,则 EVM 会停止程序的执行。这使得 EVM 成为准图灵完备的机器:它可以运行你输入其中的任何程序,但前提是该程序必须在特定的计算量内终止。这个限制在 Ethereum 中不是固定的——你可以付费来增加它,直到达到最大值(称为区块 gas 限制),而且每个人都可以同意随着时间的推移而增加这个最大值。尽管如此,在任何时候,都存在一个限制,并且在执行期间消耗过多 gas 的交易会被停止。
在以下各节中,我们将研究 gas 并详细检查它是如何工作的。
什么是 Gas?
Gas 是 Ethereum 的单位,用于衡量在 Ethereum blockchain 上执行操作所需的计算和存储资源。与仅考虑以千字节计的交易大小的比特币相比,Ethereum 必须考虑交易和智能合约代码执行执行的每个计算步骤。
交易或合约执行的每个操作都需要花费固定数量的 gas。来自 Ethereum “黄皮书” 的一些示例包括:
- 将两个数字相加需要花费 3 gas
- 计算 Keccak-256 哈希需要花费 30 gas + 每 256 位哈希数据花费 6 gas
- 发送交易需要花费 21,000 gas
Gas 是 Ethereum 的一个重要组成部分,并发挥双重作用:作为以太币(volatile)价格与验证者所做工作的的回报之间的缓冲,以及作为防御 DoS 攻击的手段。为了防止网络中意外或恶意的无限循环或其他计算资源浪费,每笔交易的发起者都需要设置他们愿意支付的计算量的限制。因此,gas 系统会阻止攻击者发送“垃圾邮件”交易,因为他们必须按比例支付他们消耗的计算、带宽和存储资源。
执行期间的 Gas 核算
当需要 EVM 完成交易时,首先会为它提供等于交易中 gas 限制指定的数量的 gas 供应。执行的每个 opcode 都有 gas 成本,因此,当 EVM 逐步执行程序时,EVM 的 gas 供应会减少。在每个操作之前,EVM 都会检查是否有足够的 gas 来支付操作的执行费用。如果没有足够的 gas,则会停止执行并回滚交易。
如果 EVM 在没有耗尽 gas 的情况下成功到达执行结束,则使用的 gas 成本将作为交易费用支付给验证者,并根据交易中指定的 gas 价格转换为以太币:
验证者费用 = gas成本 × gas价格
gas 供应中剩余的 gas 将退还给发送者,同样根据交易中指定的 gas 价格转换为以太币:
剩余 gas = gas 限制 – gas 成本
退还的以太币 = 剩余 gas × gas 价格
如果交易在执行期间“耗尽 gas”,则操作会立即终止,并引发 OOG 异常。该交易会被回滚,并且对状态的所有更改都会被回滚。尽管交易未成功,但发送者仍将被收取交易费用,因为验证者已经执行了到该点的计算工作,并且必须因此获得补偿。
Gas 核算注意事项
EVM 可以执行的各种操作的相对 gas 成本经过仔细选择,目的是为了最好地保护 Ethereum blockchain 免受攻击。计算量更大的操作需要花费更多的 gas。例如,执行 SHA3 函数的成本(30 gas)是 ADD 操作(3 gas)的 10 倍。更重要的是,某些操作(例如 EXP)需要根据操作数的大小额外支付费用。使用 EVM 内存以及在合约的链上存储中存储数据也需要花费 gas。
将 gas 成本与实际资源成本相匹配的重要性在 2016 年得到了证明,当时一名攻击者发现并利用了成本不匹配。攻击者生成了计算量非常大的交易,导致 Ethereum 主网几乎停止运行。这种不匹配通过硬分叉(代号为“Tangerine Whistle”)来解决,该硬分叉调整了相对 gas 成本。
Ethereum 未来的 Gas 核算
Gas 计量过去是,现在仍然是 Ethereum 如何处理网络中所有交易负载的一个极其重要的部分。重要的是要理解 gas 成本是某些行为的关键激励因素。将来,不同的 opcode 消耗多少 gas 可能会发生一些变化。
例如,在引入 EIP-4844 blob 交易的 Cancun 升级之前,所有 L2 都在 Ethereum 上发布他们的数据,作为交易的 calldata 的一部分。这些数据永远存储在 Ethereum 的所有节点上。现在 L2 有更好的方法可以通过 blob 交易在 Ethereum 上发布他们的数据,因此将来 calldata 可能会变得比现在更昂贵,以鼓励 rollup 使用 blob 交易并减轻节点永远存储所有这些数据的负担。
Gas 成本与 Gas 价格
虽然 gas 成本 是 EVM 中交易使用的计算和存储量的度量标准,但 gas 本身也有以以太币计价的价格。在执行交易时,发送者会指定他们愿意为每个 gas 单位支付的 gas 价格(以以太币计),从而允许市场决定以太币价格与计算操作成本之间的关系(以 gas 衡量):
交易费用 = 使用的总 gas × 支付的 gas 价格(以以太币计)
在构建一个新区块时,Ethereum 网络上的验证者可以选择提供更高 gas 价格的待处理交易。因此,提供更高的 gas 价格将激励验证者包含你的交易并更快地确认。
在实践中,交易的发送者将设置一个高于或等于预期使用 gas 量的 gas 限制。如果 gas 限制设置得高于消耗的 gas 量,则发送者将收到超额部分的退款,因为验证者仅针对他们实际执行的工作获得补偿。
重要的是要清楚 gas 成本和 gas 价格之间的区别。回顾一下:
- Gas 成本 是执行特定操作所需的 gas 单位的数量。
- Gas 价格 是你将交易发送到 Ethereum 网络时愿意为每个 gas 单位支付的以太币金额。
提示
虽然 gas 有价格,但不能“拥有”或“花费”。Gas 仅存在于 EVM 内部,作为正在执行的计算工作量的计数。发送者被收取以太币的交易费用,该费用被转换为 gas 以进行 EVM 核算,然后转换回以太币作为支付给验证者的交易费用。
负 Gas 成本
Ethereum 鼓励删除已使用的存储变量,方法是退还合约执行期间使用的一些 gas。EVM 中只有一种具有负 gas 成本的操作:将存储地址从非零值更改为零 (SSTORE[x] = 0) 值得退款。退还的 gas 量不是固定的,并且取决于此操作之前和之后存储槽的值。为了避免利用退款机制,交易的最大退款设置为 gas 成本总额的五分之一(向下舍入)。
过去,还有另一种具有负 gas 成本的操作:SELFDESTRUCT。删除合约(通过 SELFDESTRUCT)值得 24,000 gas 的退款。现在,SELFDESTRUCT opcode 已弃用,建议不再使用它。
提示
Gas 退款在交易结束时应用。因此,如果交易没有足够的 gas 来到达执行结束,则交易会失败,并且不给予任何退款。
区块 Gas 限制
区块 gas 限制是区块中所有交易可能消耗的最大 gas 量。它限制了可以放入区块的交易数量。
例如,假设我们有五个交易,它们的 gas 限制已设置为 30,000、30,000、40,000、50,000 和 50,000。如果区块 gas 限制为 180,000,则这些交易中的任何四个都可以放入一个区块,而第五个交易将必须等待未来的区块。如前所述,验证者决定将哪些交易包括到一个区块中。不同的验证者可能会选择不同的组合,主要是因为他们以不同的顺序从网络接收交易。
如果验证者尝试包括需要比当前区块 gas 限制更多 gas 的交易,则该区块将被网络拒绝。大多数 Ethereum 客户端会通过给出类似于“交易超过区块 gas 限制”的警告来阻止你发布此类交易。根据 Etherscan,在撰写本文时(2025 年 6 月),Ethereum 主网上的区块 gas 限制为 3600 万 gas,这意味着大约 1,428 个基本交易(即,ETH 转账)(每个消耗 21,000 gas)可以放入一个区块。
谁选择区块 Gas 限制?
在 2021 年 8 月 5 日引入 EIP-1559 之前,矿工(Ethereum 当时使用基于 PoW 的共识算法)有一种内置机制,他们可以通过该机制对区块 gas 限制进行投票,因此可以在后续区块中增加或减少容量。一个区块的矿工可以投票调整区块 gas 限制,调整因子为 1/1024 (0.0976%),可朝任何方向调整。这样做的结果是,根据矿工的哈希能力,可以基于网络的需求调整区块大小。
现在,验证者对 gas 目标 进行投票,也就是说,一个区块平均应该消耗多少提高 gas 上限会带来一些与网络去中心化相关的缺点。事实上,虽然更大的区块可以包含更多的交易,但也意味着区块更难及时验证,这可能导致使用普通硬件构建的以太坊节点的消亡,只留下强大的服务器来验证完整的区块。不仅如此,更大的区块也意味着更大的状态增长。最终结果与之前相同:只有大型服务器才能完全运行一个节点。
从历史上看,区块 gas 上限在协议升级期间一次性提高,如图 14-25 所示。它的值通常设置为核心开发者建议的水平,以确保所有客户端都能够处理交易负载并及时处理区块。
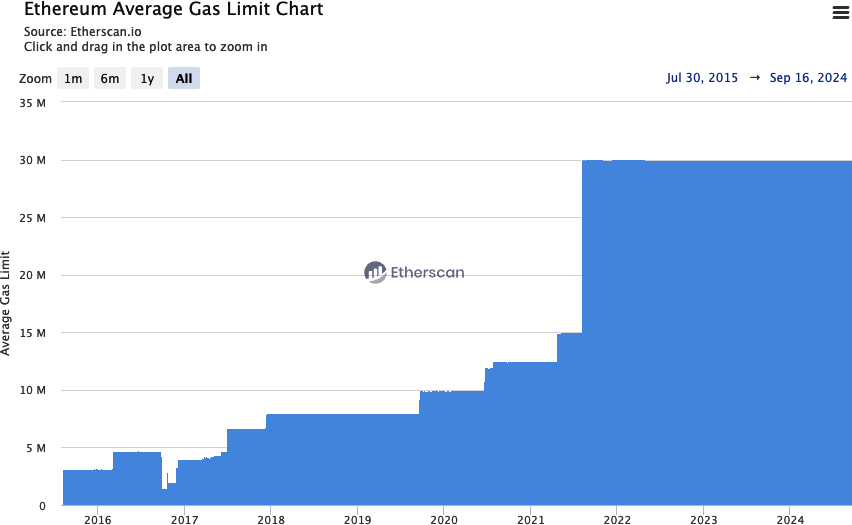
图 14-25. 以太坊平均 gas 上限图表
为什么不提高区块 Gas 上限?
即使区块 gas 上限看起来已经在三年多的时间里 "固定" 在 3000 万,但有了 PBS(参见 "以太坊无状态"),拥有先进硬件的角色构建区块(建造者),并将它们发送给提议者(验证者),以在 P2P 网络上发布,因此存在无限期提高区块 gas 上限的动机,同时保持实际使用的 gas 几乎恒定。
事实上,在 EIP-1559 之后,如果区块 gas 目标远高于实际使用的 gas,则基础费用会持续降低,以至于几乎所有的 gas 费用都流向验证者而不是被烧毁(基础费用被烧毁,从供应中移除这些 ETH)。
因此,验证者的优势是双重的:
- 他们可以保留 gas 费用供自己使用,而不是烧毁它们并减少 ETH 供应。
- 必要时,他们可以创建更大的区块,捕获大量的 MEV 活动,从而为他们带来更多的费用。
如果您对此感到好奇,请阅读 James Prestwich 的文章。
具体实现
每个以太坊节点都有本章中描述的 EVM 的具体实现。以下是其中最著名和最常用的列表:
Go-ethereum EVM
Geth 是采用最广泛也是最古老的执行客户端。它包含用 Go 编写的 EVM 的完整实现。
Execution-spec EVM
以太坊基金会在 GitHub 上维护一个 Python 存储库,其中包含与以太坊执行客户端相关的规范。它有一个用 Python 编写的完整 EVM 实现。
Revm
Revm 是在普通以太坊客户端之外使用最多的 EVM 实现之一,这归功于其出色的可定制性和适应性。
Evmone
Evmone 可能是最快的 EVM 实现。它用 C++ 编写,并由以太坊基金会的 Ipsilon 团队维护。
Besu EVM
Besu 是由 Consensys 维护的执行客户端。它有一个用 Java 编写的 EVM 的完整实现。
Nethermind EVM
Nethermind EVM 是用 C# 编写的执行客户端,它维护着 EVM 的完整实现。
最大的 EVM 升级:EVM 对象格式
EVM 对象格式 (EOF) 是自 2015 年 EVM 诞生以来最大的升级。事实上,尽管过去对 EVM 进行了一些修改,这些修改主要集中在 gas 计量方面或引入新的操作码,但 EVM 几乎与 Gavin Wood 最初创建时的状态相同。
EVM 仍然很棒。今天以太坊(以及所有其他 EVM 兼容的区块链)上发生的所有活动都离不开它。它也不是完美的,近年来,智能合约开发者不得不处理它的不同方面,并学习一些技巧来克服它的限制。
EOF 是一种可扩展且具有版本控制的 EVM 容器格式,在部署时进行一次性验证。在本节中,我们将探讨 EVM 的所有主要限制以及 EOF 如何克服这些限制。
注意
截至本书的最终修订版(2025 年 6 月),由于以太坊社区内部共识不足,EOF 升级已被无限期推迟。目前没有明确的实施时间表,并且最终可能永远不会被采用。尽管如此,我们认为本节对于理解 EOF 如何影响 EVM 和更广泛的以太坊生态系统仍然很有价值。
Jumpdest 分析
传统的 EVM 不会在创建时验证链上发布的字节码。一方面,这可能看起来不错,因为它允许你发布任何你想要的合约:你可以部署包含不存在的操作码的字节码,或者添加从未被触及或在 PUSH 操作中间截断的代码,而没有给出为了正确执行它所必须拥有的下一个立即值。这实际上增加了许多效率低下。事实上,EVM 必须在运行时检查所有内容,这增加了复杂性并降低了整体性能。这是一个包含在 EVM 字节码中不存在的操作码的示例:
600C600052602060000C
以下是将字节码翻译成人类可读的操作码:
[00] PUSH1 0C
[02] PUSH1 00
[04] MSTORE
[05] PUSH1 20
[07] PUSH1 00
[09] NOT-EXISTING
操作码 0C 不存在,当 EVM 到达该点时,它将 panic 并提前返回。请注意,先前字节码中的第二个字节也是 0C,但 EVM 在那里没有失败。不同之处在于,虽然最后一个 0C 字节被解释为操作码并且由于无效而失败,但另一个被解释为 push 数据,因为它是第一个 PUSH1 操作码的立即值。
此运行时检查的一个关键部分是 jumpdest 分析。每次执行合约时,每个客户端都需要在运行时执行此操作。让我们花一些时间了解此 jumpdest 分析以及为什么在传统的 EVM 中需要它。
提示
为了不必在每次调用合约时都在运行时执行 jumpdest 分析,一些以太坊节点实现为每个合约保存一个 jumpdest 映射。此映射在合约部署时创建并保存在节点的数据库中。
传统的 EVM 只有动态跳转(JUMP 和 JUMPI 操作码)来管理字节码的控制流。这非常方便,因为您只需两个操作码即可更改正常的操作流程。缺点是动态跳转非常昂贵,并且需要在运行时进行深入验证,即使在大多数情况下,也没有必要进行动态跳转。事实上,通常要跳转到的值在 JUMP 操作码本身之前立即被推送到堆栈。这是一个小例子:
…6009566006016101015b6001…
并翻译成人类可读的操作码:
[00] PUSH1 09
[02] JUMP
[03] PUSH1 06
[05] ADD
[06] PUSH2 0101
[09] JUMPDEST
[0a] PUSH1 01
正如你所看到的,跳转目标——即要跳转到的偏移量 0x09——只是通过一个 PUSH1 操作码在 JUMP 操作码之前立即被推送到堆栈中。EVM 将 0x09 推送到堆栈中,然后执行 JUMP 操作码,该操作码将先前推送的 0x09 作为输入并将执行移动到该偏移量处的指令。在 0x09 处,找到了一个 JUMPDEST 操作码,因此它被认为是有效的跳转目标,并且执行可以正确地继续进行。
为了不跳转到无效的目标,需要运行时验证。有效的目标只是不是 push 数据一部分的 JUMPDEST 指令。这对于理解非常重要:传统的 EVM 没有代码和数据之间的适当分离。因此,无论何时你在某些字节码中遇到字节 0x5b——JUMPDEST 操作码——你都不能完全确定它是一个真正的 JUMPDEST 操作码还是 push 数据的一部分,而没有分析整个合约。
看看下面的例子,它显示了这种微妙的差异:
…6009566006016101015b6001…
…6009566006016201015b6001…
这两个字节码看起来几乎相同;事实上,它们仅相差一位。但这足以在结果中产生巨大的差异。第一个字节码与前一个示例中显示的相同。第二个字节码以人类可读的格式看起来像这样:
[00] PUSH1 09
[02] JUMP
[03] PUSH1 06
[05] ADD
[06] PUSH3 01015b
[0a] PUSH1 01
如果你尝试执行第二个代码,它将由于无效的跳转目标而失败。这可能看起来有点奇怪,因为在偏移量 0x09 处,仍然存在 0x5b 字节,它代表 JUMPDEST 操作码。这里的问题在于,在这种情况下,0x5b 字节是 push 数据的一部分,因此它不能被认为是有效的跳转目标。这就是执行在该点失败的原因。
Jumpdest 分析是分析合约以了解哪些跳转目标有效,哪些无效的过程,以便当 EVM 执行合约时,它能够检测到无效的跳转目标并 panic。
假设你正在发送一个与合约 A 交互的交易。当 EVM 加载它时,它会立即执行 jumpdest 分析以保存有效的跳转目标映射,然后开始真正执行交易:
…6009566006016101015b60016015566006016201015b6001…
这是人类可读格式:
[00] PUSH1 09
[02] JUMP
[03] PUSH1 06
[05] ADD
[06] PUSH2 0101
[09] JUMPDEST
[0a] PUSH1 01
[0c] PUSH1 15
[0e] JUMP
[0f] PUSH1 06
[11] ADD
[12] PUSH3 01015b
[16] PUSH1 01
EVM 浏览所有字节码并创建一个映射,其中每个 0x5b 字节都被标记为有效或无效的跳转目标,如图 14-26 所示。
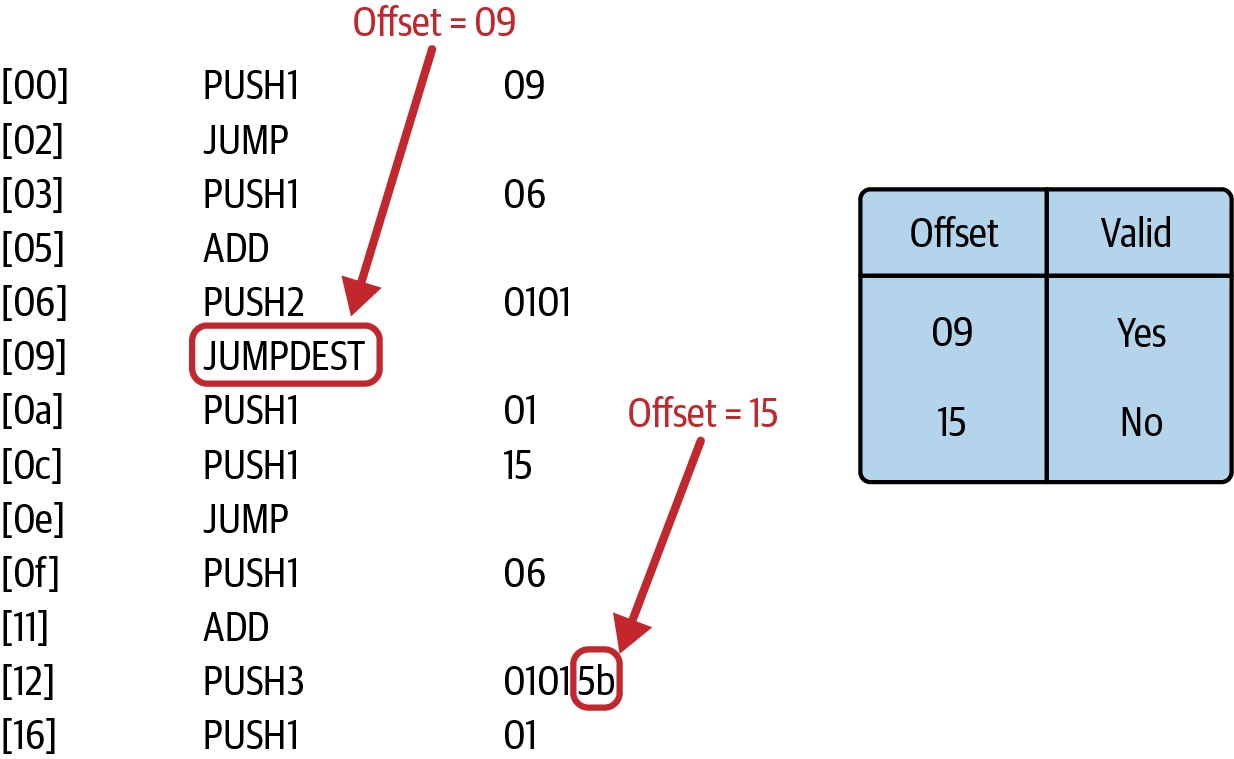
图 14-26. 客户端创建一个 jumpdest 映射以将有效跳转目标与无效跳转目标分开
添加和弃用功能
添加或弃用操作码或特定功能并不像看起来那么容易。虽然确实添加了不同的操作码,例如 BLOBHASH、BLOBBASEFEE、BASEFEE 等,但这总是很复杂,因为 EVM 的字节码是非结构化的且未经过验证。
看看下面的例子,其中包含一个无效的操作码,特别是 0x0C。假设这是一个部署在以太坊主网上的真实合约:
600C600052602060000C
这是人类可读格式:
[00] PUSH1 0C
[02] PUSH1 00
[04] MSTORE
[05] PUSH1 20
[07] PUSH1 00
[09] NOT-EXISTING
如果你尝试在 EVM 中执行这个小的字节码,你会看到当执行到达不存在的操作码时,它会失败。
假设未来的升级添加了一个新的操作码,MAX 操作码,它从堆栈中取出两个项目并返回包含较大值的项目。分配给它的字节是 0x0C。再次考虑之前的字节码(记住,我们假设它是部署在主网上的真实合约):
[00] PUSH1 0C
[02] PUSH1 00
[04] MSTORE
[05] PUSH1 20
[07] PUSH1 00
[09] MAX
现在这个字节码有一个完全不同的结果。事实上,它不再失败并成功返回。如果存在依赖于此合约由于(先前)不存在的操作码而总是失败的假设的合约,这可能会产生问题。
弃用功能更加困难,因为你不能依赖 EVM 的版本控制系统。因此,如果你删除一个操作码或更改它的工作方式,使用它的旧合约可能会中断,除了手动干预(通过创建一个新合约)之外,没有任何方法可以修复它。
当引入 EIP-2929 以更改状态访问操作码的 gas 计量时,一些合约中断是因为它们硬编码了要使用或期望的 gas 量。使它们再次工作的解决方案是引入 访问列表,你可以在其中预加载一些你确信会被交易触及的帐户和存储槽,并降低 gas 成本。
使升级更加困难的旧 EVM 的其他重要方面是 代码内省 和 gas 可观察性。由于诸如 GAS 甚至所有将 gas 作为输入的 *CALL 操作码等操作码,gas 可观察性是可能的,而由于诸如 CODESIZE、CODECOPY、EXTCODESIZE、EXTCODECOPY 和 EXTCODEHASH 等操作码,代码内省是可以实现的。
问题在于,如果 EVM 能够访问执行的某个点的剩余 gas,则智能合约的逻辑可以依赖于该逻辑。并且如果将来某些操作码的 gas 计量发生变化(这是一种不太罕见的现象),则对于依赖于旧 gas 计量的所有智能合约都可能存在问题。代码内省也是如此。
注意
如果没有代码内省,EOF 的未来版本可能会完全改变底层虚拟机,例如 Cairo VM 或 Wasm 或任何其他虚拟机,通过自动将所有合约的代码转换为具有相同功能的新虚拟机的代码。
代码和数据分离
旧的 EVM 不会对链上发布的字节码施加结构。真实代码和在该代码中使用的数据之间没有区别。一切都只是字节,并且在执行期间 EVM 会逐步解释它。
如果不查看整个合约,就无法说字节码的某个部分是代码还是数据。看下面的例子:
…730102030405060708090a0b0c0d0e0f101112131431…
[00] PUSH20 0102030405060708090a0b0c0d0e0f1011121314
[15] BALANCE
如果没有深入研究代码,你无法立即判断 0102030405060708090a0b0c0d0e0f1011121314 不能被解释为一系列操作码——0x01:ADD,0x02:MUL 等——而是代表我们要查询余额的固定地址的 push 数据。这对静态分析工具和形式验证不利,并且使智能合约更难以直接在链上正确处理可执行代码。
堆栈太深
我们现在要看一下 EVM 最令人讨厌的限制之一:“堆栈太深” 错误。如果你尝试编译以下智能合约,你将立即得到它:
// SPDX-License-Identifier: MIT
pragma solidity 0.8.27;
contract StackTooDeep {
function add(
uint256 a,uint256 b,uint256 c,uint256 d,uint256 e,uint256 f,uint256 g,uint256 h,uint256 i
) external pure returns(uint256) {
return a+b+c+d+e+f+g+h+i;
}
}
这是尝试编译合约时的输出:
solc StackTooDeep.sol --bin
Error: Stack too deep. Try compiling with `--via-ir` (cli) or the equivalent `viaIR: true` (standard JSON) while enabling the optimizer. Otherwise, try removing local variables.
--> StackTooDeep.sol:8:16:
|
8 | return a+b+c+d+e+f+g+h+i;
| ^
这个错误非常微妙,因为它是 EVM 工作方式的直接结果。事实上,即使你可以推送到堆栈中的最大项目数为 1,024,但 EVM 只能通过 DUP1..16 和 SWAP1..16 等操作码轻松访问其中的前 16 个元素。
在我们的 StackTooDeep 示例中,add 函数接受九个不同的参数,每个参数都需要放入堆栈中。然后,它执行八个加法以获得最终结果。问题在于这些细节。虽然最终操作看起来像一个大的单一加法,但实际上,编译器必须对每个加法进行分段并创建一个临时变量来保存需要保存在堆栈中的中间结果。因此,我们最终得到九个参数加上八个中间结果,总共需要 17 个堆栈项目。当编译器尝试引用堆栈中位置 17 或更高的变量时,它会失败,因为它没有任何能够轻松访问它的操作码。
为了更好地可视化该问题,你可以查看图 14-27,该图详细显示了每个步骤的堆栈组成。你可以轻松地看到变量 i 在执行结束时位于深度 17 处。编译器不允许局部变量或参数在函数范围内不容易访问,因此它会抛出“堆栈太深”错误。
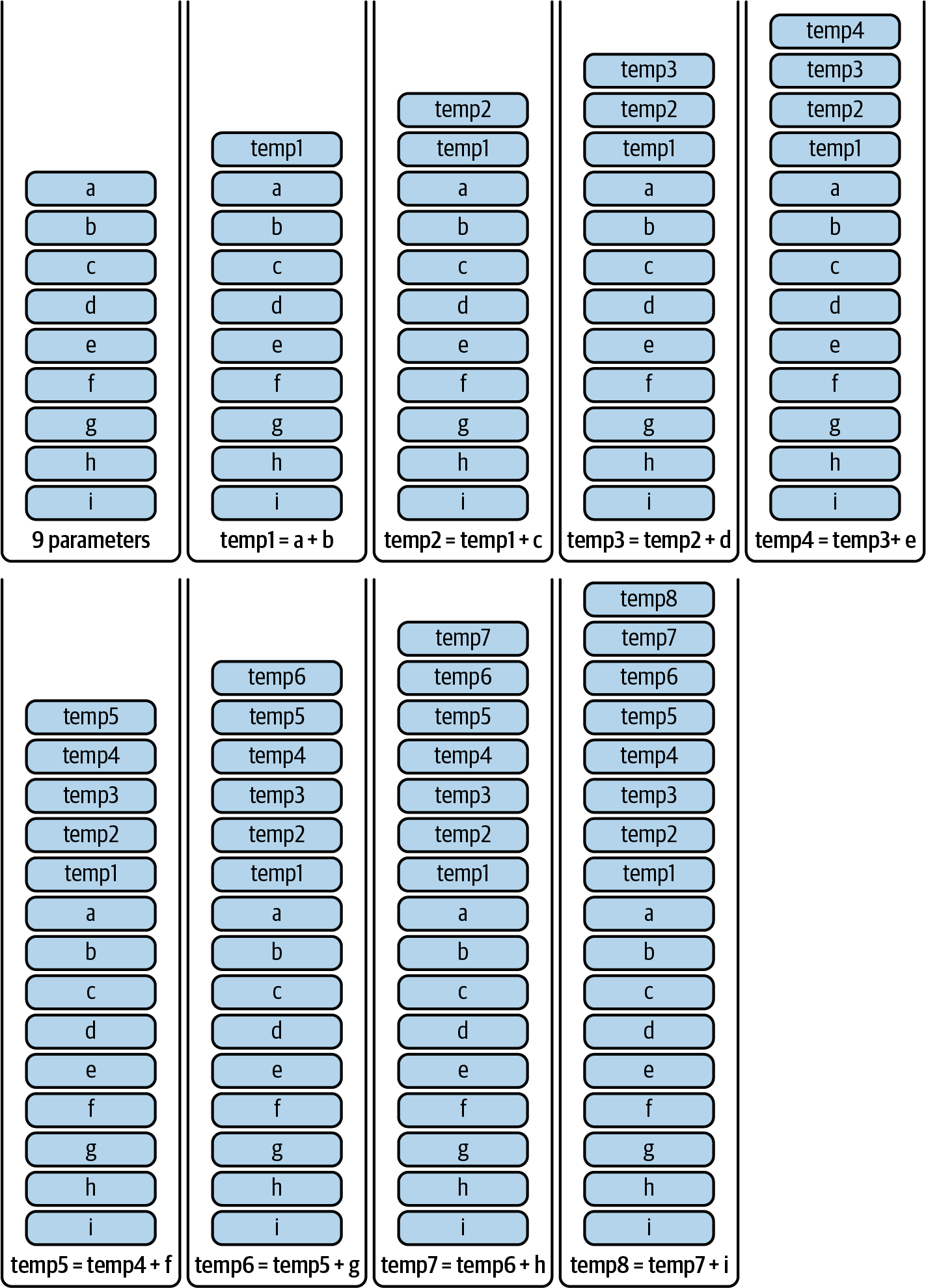
图 14-27. 每个步骤的堆栈组成
这只是一个非常简单的例子,它显示了智能合约开发人员在日常工作中必须克服的问题之一。尽管编译器在自动分析和管理这些情况方面变得越来越好,但 EVM 根据其当前的工作方式施加了一些硬性限制。
EOF
EOF 通过引入一种用于 EVM 字节码的容器格式来解决所有这些问题,该容器格式具有部署时的验证、版本控制系统以及代码和数据之间的完全分离。这是一个 EOF 有效字节码的示例:
EF00010100040200010008030001003004002000008000045F5FD1005FEC0000EF00010100040200010004030001001404000000008000025F5FEE00EF00010100040200010001040000000080000000000102030405060708090a0b0c0d0e0f10111213141516171819101a1b1c1d1e
这是翻译成人类可读格式:
Magic bytes EF00
EOF version 01
Stack validation data 01 0004
Code sections 02 0001 0008
Subcontainer section size 03 0001 0030
Data section size 04 0020
Header terminator 00
Stack: #ins, #outs, max stack 00 80 0004
Code 5F5FD1005FEC0000
Subcontainers EF00010100040200010004030001001404000000008000025F5FEE00
EF00010100040200010001040000000080000000
Data 000102030405060708090a0b0c0d0e0f10111213141516171819101
a1b1c1d1e
请稍等片刻——我们将在以下各节中解释所有内容。
改进
Jumpdest 分析以及所有 gas 和代码内省操作码已完全删除,现在被认为是未定义的。代码部分中的所有操作码必须有效,立即值(例如 push 数据)必须存在于代码中,并且不得有无法访问的指令。堆栈验证也在创建时执行。这使得堆栈下溢和溢出在执行期间不可能发生,从而无需在运行时进行所有这些检查,因为 EVM 可以假定合约已经遵守所有规则,因为它们已在部署时经过验证。
提示
这些验证保证提高了将 EVM 字节码 AOT 或 JIT 编译为机器原生代码的可行性。
动态跳转也被删除,并使用三个新的操作码引入了静态相对跳转:RJUMP、RJUMPI 和 RJUMPV,它们采用立即值,类似于 PUSH 操作码。请注意,使用 EOF 可以添加采用立即值的新指令,因为不再有 jumpdest 分析,并且所有内容都在创建时而不是在运行时进行检查。
正如你从上一节中的 EOF 容器中看到的那样,EOF 引入了 函数(即代码部分)的概念,隔离了每个函数的堆栈。旧的 EVM 只能通过依赖动态跳转来模仿这种行为:Solidity 或 Vyper 函数只是一个内部表示。
为此,添加了三个操作码——CALLF、RETF 和 JUMPF——和一个 返回堆栈(与 EVM 常用的操作数堆栈完全分离)。特别是,需要返回堆栈才能在跳转到函数之前保存执行信息,以便可以返回给调用者而不会丢失数据。图 14-28 可以帮助你更好地可视化其工作原理。
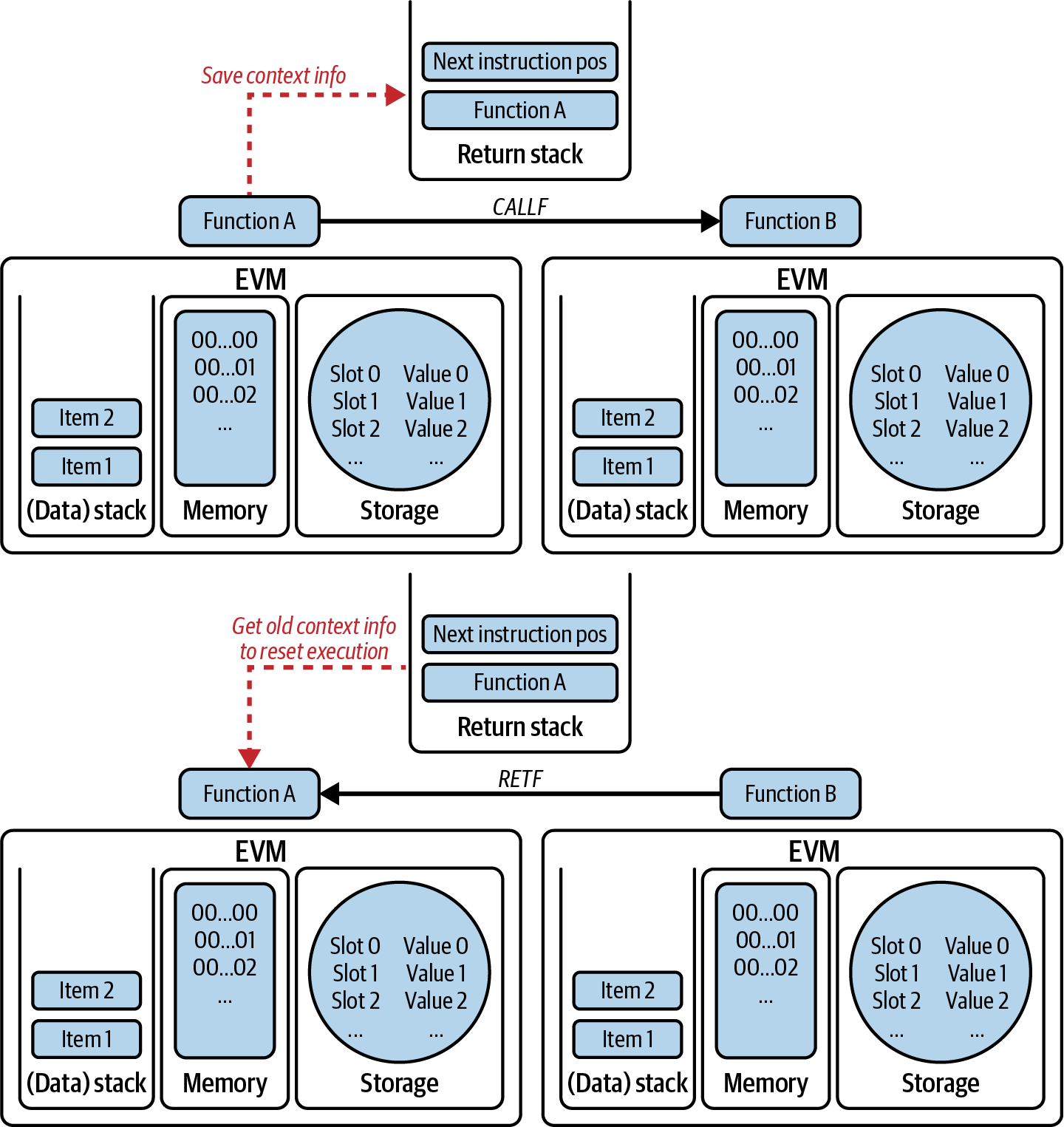
图 14-28. EOF 引入了函数或代码部分的概念
通过添加三个新的操作码:DUPN、SWAPN 和 EXCHANGE 来解决“堆栈太深”问题。前两个指令类似于旧的 DUP1..16 和 SWAP1..16,唯一的区别是它们采用一个立即值,表示要复制或交换的项目索引。该索引可以高达 256,远高于之前的 16 个的硬性限制。
EXCHANGE 操作码是一个新的操作码,允许你在堆栈中交换两个不同的项目(请注意,SWAPN 总是将第 n 个项目与第一个项目交换,而 EXCHANGE 可以将任意项目相互交换)。这对于实现 堆栈调度算法 的编译器特别有用,该算法尝试在给定一组变量和使用情况分析的情况下最大限度地减少堆栈流量。
CREATE 和 CREATE2 在 EOF 合约中已过时。而是引入了 EOFCREATE 和 RETURNCONTRACT 来提供创建新 EOF 合约的方法。
最后,添加了新的 CALL 指令来替换旧的、已删除的指令:EXTCALL、EXTDELEGATECALL、EXTSTATICCALL 和 RETURNDATALOAD。它们不允许指定 gas 限制(没有 gas 可观察性),也不需要 EVM 将保存子调用的返回数据的输出缓冲区。引入 RETURNDATALOAD 的具体原因是将上次执行的子调用的返回数据获取到调用者的堆栈上。
EOF 实战
让我们分析一下本节开头所示的 EOF 合约:
EF00010100040200010008030001003004002000008000045F5FD1005FEC0000EF00010100040200010004030001001404000000008000025F5FEE00EF00010100040200010001040000000080000000000102030405060708090a0b0c0d0e0f10111213141516171819101a1b1c1d1e
首先,我们有 EOF 标头,由以下内容组成:
Magic bytes EF00
由于 EIP-3541,需要 Magic bytes 来区分 EOF 合约与旧合约(以太坊主网中没有其他合约以 EF00 开头)。
然后,有 EOF 版本,它可以以平滑的方式导致将来对 EOF 格式进行升级:
EOF version 01
堆栈验证数据始终以标识符 01 开头,后跟“Stack”部分的大小。在此示例中,我们有一个 4 字节长的“Stack”部分:
Stack validation data 01 0004
代码部分以标识符 02 开头,后跟代码部分(又名函数)的数量及其相关大小。在这里,我们有一个代码部分,长 8 个字节:
代码部分 02 0001 0008
子容器部分大小以标识符 03 开头,后跟子容器的数量及其相关大小。在这里,我们有一个子容器,长 48 个字节(请记住,它始终采用十六进制格式):
子容器部分大小 03 0001 0030
数据部分大小以标识符 04 开头,后跟数据部分的大小。在这里,我们在数据部分中有 32 个字节:
数据部分大小 04 0020
最后,有标头终止符 00,它始终标记 EOF 标头的结尾:
标头终止符 00
堆栈部分显示了每个代码部分的输入和输出数量以及最大堆栈高度(在本示例中只有一个)。我们有零个输入和一个不返回的函数(80 是表示不返回函数的特殊字节),并且堆栈的最大高度等于 4:
堆栈:#ins、#outs、最大堆栈 00 80 0004
以下是包含 EVM 执行的 EVM 字节码的所有代码部分:
代码 5F5FD1005FEC0000
我们只有一个函数(代码部分),包含以下操作码:
PUSH0 PUSH0 DATALOADN 0 PUSH0 EOFCREATE 0 STOP
此代码首先通过前两个 PUSH0 操作码将 0-0 推送到堆栈上。然后,它从数据部分读取 32 个字节,从偏移量零开始(代码中的下一个立即值),并将它们推送到堆栈上。然后,通过最后一个 PUSH0 推送另一个 0。最后,调用 EOFCREATE,其中 0 作为立即数参数,它调用第一个子容器的第一个代码部分:
子容器 EF00010100040200010004030001001404000000008000025F5FEE00EF0001
0100040200010001040000000080000000
子容器部分包括包含在 EOF 字节码中的所有 EOF 子容器。在此示例中,我们有一个子容器。子容器是 EOF 格式的字节码:这个想法是你可以将 EOF 容器嵌套在其他 EOF 容器中。这对于工厂合约很有用。
最后,有一个数据部分,其中包含合约执行所需的所有数据。在这里,我们有 32 个字节的数据:
数据 000102030405060708090a0b0c0d0e0f10111213141516171819101a1b1c1d1e
为了完全理解它在做什么,可以将此分析递归地应用于此 EOF 字节码的子容器,但是,如果你有兴趣更深入地研究 EVM 的兔子洞,我们将把这项工作留给读者。
EVM 的未来
除了 EOF 之外,EVM 的未来是不确定的,并且将取决于开发人员和不同项目如何使用 EVM。但是,EVM 可以在一些有趣的领域进行扩展,例如 zk-EVM,它将提供附加到每个区块的零知识证明,以证明其正确执行。此外,EVMMAX 和 SIMD 将为 EVM 带来更多功能,使其能够更快地进行大量加密处理,这将特别有利于依赖加密的应用程序,例如隐私协议或 L2。
结论
在本章中,我们探索了 EVM,跟踪了各种智能合约的执行,并了解了 EVM 是如何执行字节码的。我们还了解了 gas,EVM 的会计机制,并了解了它如何解决停止问题并保护以太坊免受 DoS 攻击。此外,我们分析了 EOF,了解了它如何尝试修复传统 EVM 的不同流程。
接下来,在第 15 章中,我们将探索以太坊用于实现去中心化共识的机制。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录