以太坊如何管理数据?
- shaneauerbach
- 发布于 2022-12-07 14:37
- 阅读 118
本文探讨了以太坊虚拟机(EVM)如何管理数据,包括EVM的状态数据和非状态数据,以及使用以太坊数据时面临的挑战,如合约代码是编译后的字节码、合约源代码的私有性、合约之间的调用关系复杂、合约代码的可变性以及合约存储的探索难度。文章还讨论了分叉和重组对以太坊数据一致性的影响。
以太坊如何管理数据?
我们探索以太坊数据以及使用这些数据时遇到的挑战。
我们首先描述了以太坊虚拟机和它维护的状态和非状态数据。然后,我们讨论了包括解释已编译的字节码、观察合约间的调用等等挑战。
— 什么是 EVM?
了解以太坊虚拟机(EVM)
什么是 EVM?
以太坊虚拟机(EVM)有时被称为世界计算机。全球数千个节点across the world执行相同的代码以维持相同的状态。
EVM 状态是如何维护的?
图 1 说明了 EVM 状态管理和数据结构。我们从一个任意的状态 n-1 开始,在这个状态中,EVM 的实例有三种类型的状态数据:
- 账户余额(以 ETH 为单位)和 nonce。图 1 显示了两个地址 (0xa5…37 和 0x93…af),每个地址都有 5 ETH。每个地址还有一个 nonce(未显示),它代表了该地址的交易计数。
- 合约代码。图 1 显示了一个简单合约的伪代码,该合约部署在 0x93…af,维护一个存储变量 x,并且每次账户收到至少 1 ETH 的转账时,该变量都会递增。
- 合约存储。图 1 显示了 0x93…af 的合约存储作为一个键值对的字典,包括条目 x:1。
按下回车键或单击以全尺寸查看图像
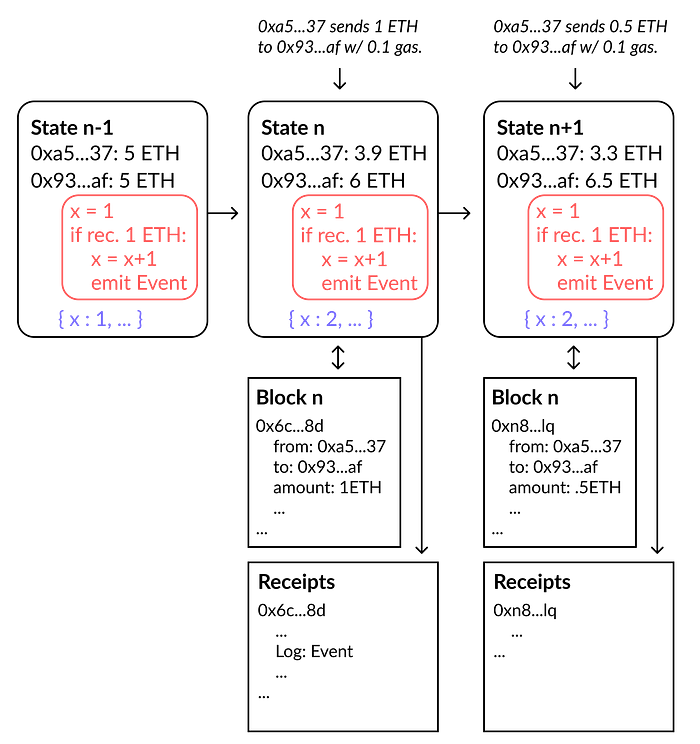
图 1:EVM 区块和状态的说明
让我们来模拟一个例子。账户 0xa5…37 向合约 0x93…af 发送 1 ETH,提交/待处理的交易位于“mempool”中,直到它被包含在一个区块中。这个例子交易消耗 0.1 ETH 的 gas。根据 EIP1559,其中一部分会被销毁。在提议者创建了 区块 n 之后,验证者会验证它的合法性。新的区块会在网络中传播,接收节点会运行由包含的交易触发的代码,以将其状态更新为 状态 n。因为收到了 1 ETH, x 在存储中从 1 递增到 2,并且 Event 在与交易关联的收据日志中发出。从状态 n 到 n+1,只发送了 0.5 ETH。运行合约代码,但是既不会递增 x,也不会发出事件,因为不满足 if 条件。
我们推荐 Timothy McCallum 的 深入以太坊的世界状态 和 vasa 的 深入以太坊:数据是如何存储在以太坊中的?。
存在哪些非状态 EVM 数据?
区块包含导致状态改变的交易。将一个区块想象成类似于 git 软件中使用的 diff 会更直观,因为它记录了一组更改。话虽如此,这是一个有些不完整的 diff:一个区块只记录了启动状态更改的交易,而不是执行对状态的影响,这可能涉及合约之间的许多内部交易。
EVM 实例为每个已处理的交易生成一个收据。虽然收据是链下的,并且存储在每个节点上,但它们是可验证的:每个收据的哈希都包含在区块中。反过来,收据包含日志/事件,这些事件是由交易中调用的智能合约发出的数据。在示例合约代码中,emit Event 将创建一个日志,其中包含智能合约指定的数据。
我们推荐 Ethereum.org 的 EVM 文档; ConsenSys 的 以太坊、智能合约和世界计算机; 以及 evm.codes 上的 关于 EVM 页面。
使用以太坊数据时遇到的挑战
以太坊是一个公共区块链,任何人都可以通过运行 geth 或其他客户端来运行一个节点。新的节点通过接收网络上的区块并按顺序处理它们来赶上当前的状态。
人们可能期望访问和解释以太坊等公共区块链上的所有数据会很容易。唉,事实并非如此。让我们来探索一下这些分布式系统是如何复杂的。
链上合约代码是已编译的字节码
智能合约开发者使用可读的代码编写,通常具有丰富的注释和规范(如 Natspec),使用 Solidity (类似 JS) 和 Vyper (Pythonic) 等语言。还有更底层的选项,如 Yul(+)。
然而,存储在区块链上并在每个节点上执行的智能合约代码是已编译的 EVM 字节码,通常以十六进制表示。虽然它是可执行的,但可能难以解释和/或反编译来理解智能合约的工作原理。
合约源代码通常是私有的
智能合约开发者可以选择通过将他们的 Solidity/Vyper/Yul 合约提交给像 Etherscan 这样的服务来公开他们的合约,这些服务会编译提交的内容,并检查生成的字节码是否与 EVM 状态中的字节码匹配。但许多开发者会将其智能合约源代码保密,要么是因为他们认为公开源代码的优势有限,要么是因为他们担心源代码可能会暴露可能的安全问题或漏洞。
另一个可能公开也可能不公开的合约源代码对象是 应用程序二进制接口(ABI),它告诉其他服务如何调用合约以及如何解释其事件/日志。如果没有 ABI,可能难以调用合约或解释其日志。你或许可以猜测合约的至少一部分 ABI:确定其一般用途,并假设其函数和事件与该用途的标准合约模板(例如,ERC20、ERC721)的函数和事件相同。或者,你可以使用函数签名数据库,如 sig.eth.samczsun 或 4byte.directory。如果字节码是由标准编译器生成的,也可能通过分析反汇编的字节码来推断 ABI 的部分内容(例如,whatsabi)。这是一个例子,其中一个用 Yul 编写的合约被攻击者利用,损失约 100 万美元,攻击者对反编译的汇编代码进行了逆向工程,找到了一个没有标准检查的未使用 approve 函数。总之,只要你可以找出与这些函数和事件对应的 ABI 部分,你就可以调用函数和解释日志。
合约调用其他合约(且可观察性较差)
EVM 上的每个智能合约计算都由一个签名的交易启动。目前,只有外部拥有的账户(EoA)可以签署交易。但是,由交易调用的智能合约可以调用其他合约,而这些合约又可以调用其他合约。这些合约之间的调用通常被称为内部交易。几乎任何适度复杂的智能合约系统都会涉及内部交易。
内部交易的一个常见用例是使用代理来实现可升级性。如果你想允许你的用户做一些复杂的事情,但你也希望能够升级/更新/修复该复杂事情的执行方式,你可以让用户与代理合约交互,该代理合约调用一个实现合约,其地址写在代理的存储中。当你准备好升级实现逻辑时,部署升级后的实现合约,然后调用代理以将其存储的指针重置为新合约。图 2 说明了这个想法。
按下回车键或单击以全尺寸查看图像

图 2:使用代理模式来允许在实现合约中进行升级
这些设计有一些变体:可以使用代理纯粹作为可更新的注册表,将用户转发到另一个合约。另一种方法是使用 DELEGATECALL 模式,其中来自被调用合约的代码在调用合约的存储上执行,从而允许在相同的状态存储上更新功能。
在你的收件箱中获取 Shane Auerbach 的故事
免费加入 Medium,以获取 这位 作家的更新。
订阅
订阅
至关重要的是,这些内部交易不会在区块中显式记录。恢复它们需要使用 debug_traceTransaction 方法或检测自定义 EVM 客户端。后一种方法被 Etherscan 和 Tenderly 等服务采用。
我们推荐 zeroFruit 的 DelegateCall:在 Solidity 中调用另一个合约函数,以及 Ethereum Stack Exchange 上的 访问合约内部交易 和 检测 EVM。
合约代码不再是不可变的
以太坊最初的 CREATE 代码将合约部署到一个地址,该地址基于一个哈希值,其中包括部署者地址和他们的 nonce,即账户发起的交易计数。资金可以在合约部署之前或之后发送到合约。如果调用了 SELFDESTRUCT 指令,合约代码和存储可以被删除,并且余额可以发送到指定的方,但不能再使用 CREATE 在该地址重新部署任何东西,因为原始部署者的 nonce 会增加。
Constantinople 升级引入了 CREATE2,允许开发者在确定性地址部署合约,只要该地址还没有部署代码。它类似于 CREATE,因为它在部署地址的哈希值中包含了部署者的地址,但不同之处在于它用合约的初始化代码和用户选择的种子(“salt”)替换了部署者的 nonce。CREATE 合约永远不会与 CREATE2 合约冲突,因为 CREATE2 将 0xFF 作为哈希的第一个字节输入。
CREATE2 还启用了“变形合约”,其中给定地址的代码可以更改。图 3 和下面的说明展示了这个逻辑:
按下回车键或单击以全尺寸查看图像
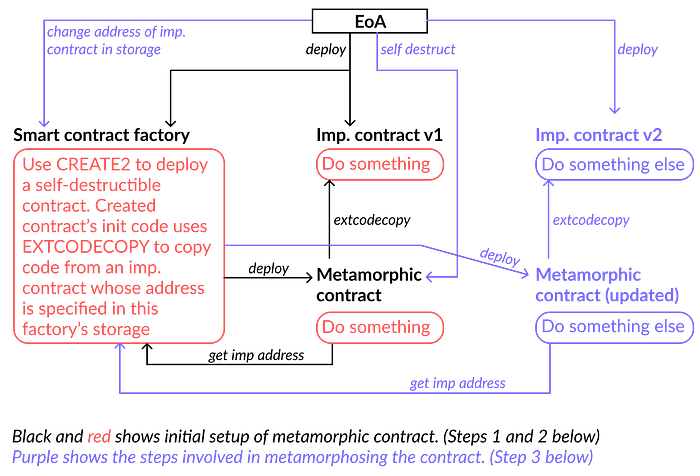
图 3:更改变形合约中的代码
- 创建一个智能合约工厂,即一个创建和部署合约的合约,作为变形合约的部署者。使该工厂能够使用 CREATE2 部署一个可自毁的变形合约。由工厂创建的变形合约的初始化代码应该指示它复制实现合约的代码,该实现合约的地址在工厂的存储中指定。
- 使用你想要在变形合约中的代码创建实现合约 v1。将实现合约 v1 的地址放在工厂的存储中。使用智能合约工厂来部署变形合约,它将在其 init 中调用工厂以找到实现合约的地址,它将使用 EXTCODECOPY 复制该实现合约的代码。
- 当你希望升级实现时,即变形变形合约:a) 在实现合约 v2 中部署新的逻辑,b) 在变形合约中调用 SELFDESTRUCT,c) 将工厂的存储中从实现合约 v1 到 v2 的指针替换,d) 使用工厂重新部署变形合约。因为部署者、初始化代码和 salt 保持不变,所以来自实现合约 v2 的新代码将部署到与之前使用的地址相同的地址,从而实现变形。
CREATE2 也有重大的安全影响:用户可能对其与某个合约地址的交易的影响充满信心,但却发现该地址的代码已更新。使用代理结构也存在一些这种风险,但代理结构更清晰/更容易检测,因为用户至少在理论上可以看到它们指向新的升级。
即使你对使用 CREATE 创建的合约没有特别的安全感。调用合约 C,假设它是使用 CREATE 由合约 B 创建的,而合约 B 又是由合约 A 使用 CREATE2 创建的。A 的所有者可以使用 SELFDESTRUCT 和 CREATE2 更新 B,从而重置其 nonce。然后可以将 B 的 nonce 递增到 C 创建时的值,然后可以使用由 B 调用的 SELFDESTRUCT 和 CREATE 升级 C。使用这些“级联复活”,如果你正在与使用 CREATE2 创建的合约的任何下游合约交互,你将面临一些意外合约升级的风险,这并不容易检测。
这些和其他考虑因素促使了 EIP-4758,这是一个当前提议通过将其更改为 SENDALL 来停用 SELFDESTRUCT,从而允许在不删除代码或存储的情况下恢复资金。它是即将到来的上海分叉的候选者,并且在 Ethereum Magicians 论坛上有一些引人入胜的讨论。
我们推荐 Michael Blau 的 用于检测变形智能合约的工具; Michael Fröwis 和 Rainer Böhme 的 并非所有代码都与 Create2 相同,0age 的 变形合约的希望与风险,Parity Technologies 的 关于 Parity 多重签名库自毁的验尸报告,以及 Parity Hack Trace 的 导致 153,037 个 ETH 被盗的 Parity 多重签名攻击。
合约存储可能难以探索
合约存储是一个键值对的字典。插槽通常按照它们在合约代码中出现的顺序分配给变量,但动态大小的数组、映射和类型嵌套周围有一些细微差别。即使你知道合约的源代码,你通常也无法通过挖掘存储来检索合约状态的完整版本,除非你确切地知道要查找的内容。要解释代理合约中的存储插槽,你需要知道你感兴趣的存储更改时实现合约的源代码。如果你不知道源代码,你真的会盲目地游荡。变量在存储中的表示取决于它的类型和高级语言的编译器。对于 Solidity:
- 固定大小的单值变量:如果合约中的前两个声明的变量是单值的,并且它们的大小总和大于 32 字节,则可以通过 RPC 调用任何以太坊节点来检索它们,分别使用
eth_getStorageAt(contract_address, 0x…0)和eth_getStorageAt(contract_address, 0x…1)。总大小小于或等于 32 字节的两个变量将被打包在一起存储在第一个存储插槽中。 - 动态大小的单值变量:string 和 bytes 不受单个存储插槽的 256 位的限制。如果动态大小的变量的长度小于或等于 31 字节,则其值与其长度一起打包在存储插槽中:该值存储在高位字节中,而 长度 * 2 存储在最低位字节中。如果变量的长度为 32 字节或更长,则只有 长度 * 2 + 1 存储在该插槽的最低位字节中,并且该值本身从 keccak256(storage_slot) 开始存储,并跨越所需的存储插槽数。长度上的 * 2 和 * 2 + 1 操作的设计使得我们知道偶数值表示可以从同一插槽的高位字节中检索的短变量,而奇数值表示变量的值从 keccak256(storage_slot) 开始存储。
- 多值的固定大小变量:假设第三个声明的变量是 uint256[2]。可以使用键 0x…2 和 0x…3 分别找到它的两个值。
- 动态大小的数组:如果下一个声明的变量是动态大小的数组,则数组的大小存储在 0x…4,然后该数组的索引零元素存储在该插槽的哈希值,即 keccak256(0x…4)。该数组的索引 k 元素存储在 keccak256(0x…4) + (k * elementSize)。
- 映射:如果下一个声明的变量是映射,则将其分配给 0x…5,但存储插槽留空。相反,对于映射中定义的键 x,它的值存储在插槽 keccak256(x,0x…5)。请注意,这意味着如果不了解映射中存在的所有键,则无法迭代合约存储中的映射。例如,你无法通过查看合约存储中的余额 (映射(地址,uint256)) 来确定 ERC20 的所有代币持有者,因为你需要知道代币持有者的地址才能找到他们的余额。
- 类型的组合:在类型以递归方式相互嵌套的地方,值的查找位置是通过递归应用上述结构来找到的。
我们推荐 Steve Marx 的 理解以太坊智能合约存储; Inuka Gunawardana 的 解码以太坊合约的存储; 以及 Harry Altman 的 Solidity 中的数据表示。
如果它刚刚发生,它可能并没有发生
分叉和重组意味着在给定时间点似乎是共识的一部分的最新区块最终可能会被丢弃,可能还有其中的一些交易和状态更新。图 4 显示了一个分叉,其中出现了两个竞争的有效区块 (区块 n:A 和 区块 n:B),只有当在其中一条链上出现一个额外的区块时才能解决。在这种情况下,区块 n:A 中没有包含在 区块 n:B 中的交易最终会被丢弃,即使一些将 区块 n:A 视为共识的节点可能已将该交易向用户表示为成功。
按下回车键或单击以全尺寸查看图像

图 4:在工作量证明链中快速解决的分叉
分叉和重组的严重程度各不相同。工作量证明共识过程可能会遇到可预测的模糊性,其中 2+ 个有效的竞争区块同时在网络中传播。这些可能会持续几个区块,但会随着一条链比另一条链增长而无需干预地解决。如果网络中的连接性降低,有时会出现更长的分叉。
当网络中的节点可能运行不同的客户端或相同客户端的不同版本时,共识可能会完全失败。虽然它们都应该遵循相同的共识规则,但如果一个客户端或一个客户端版本偏离,则可能会发生共识失败。其中的一个例子是 2020 年末由 geth 更新创建的硬分叉。
也有有意的硬分叉,通常是为了更新共识协议。Ethereum.org 维护了这些的历史。一个特别有争议的例子来自 2016 年推出的第一个以太坊 DAO,攻击者发现其智能合约中的漏洞并抽取了 5500 万美元。以太坊社区对如何回应存在分歧:他们可以简单地将以太坊的状态回滚到滥用发生之前的状态,从而使受害者完整并剥夺攻击者的收益。许多人确实采取了这种方法,但其他人认为,这种针对既定共识协议的协调行动违反了以太坊哲学核心的去中心化。因此出现了一个硬分叉,至今仍然存在,在恢复的社区和拒绝恢复的社区之间,后者产生的链被称为以太坊经典。
以太坊从工作量证明到权益证明的转变大大降低了重组的频率和大小。在合并之前,我们在边缘运行的一个节点平均每小时会经历一次重组。大多数只包含一个区块,但也有一些频率更长的重组。共识链中明确引用重组区块的区块百分比称为 ommer/叔叔率:它合并前略高于 5%。合并后,该比率在机械上为零,因为区块不引用 ommers。在我们运行边缘节点的合并后的几个月里,我们每天大约经历两次重组。我们目睹的每次合并后重组都涉及单个区块。我们推荐 Sam Lewis 的 调查权益证明以太坊中发生重组的原因 以了解更多信息。
结论
以太坊是一台公共计算机,其状态是由其用户的集体行为产生的。虽然每个有权访问节点的理论上都可以访问该状态,但在实践中,使用该数据存在许多挑战。
- 原文链接: blog.smlxl.io/how-does-e...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





