迈向语义区块分块——分片
文章探讨了以太坊语义区块分块(Semantic Block Chunking)的架构方案,提议将区块重构为多个独立可验证的语义单元。通过引入独立的区块访问列表(CAL)来传输状态差异,该方案能够实现流式验证和并行执行,旨在应对区块 Gas 限制提升带来的传播延迟和验证压力。
随着区块 Gas 限制(Block gas limits)的增加,以太坊区块的大小不可避免地会增长。我们不能依赖被压缩、传播然后再执行的单体区块(Monolithic blocks)。在某些时刻,我们需要引入区块分块(Block chunking),以减少延迟、平滑传播,并在关键路径上减轻验证者(Validators)的负担。
在之前的一篇文章中,我描述了语义化 Payload 分块及其背后的动力。现在,我想进一步深化这个想法:真正的进步来自于将语义分块(Semantic chunks)视为一等对象(First-class objects),并更进一步,将分块访问列表(Chunk Access Lists, CALs)从分块本身中分离出来。
分类法回顾
关于区块分块,有几种截然不同的思考方式:
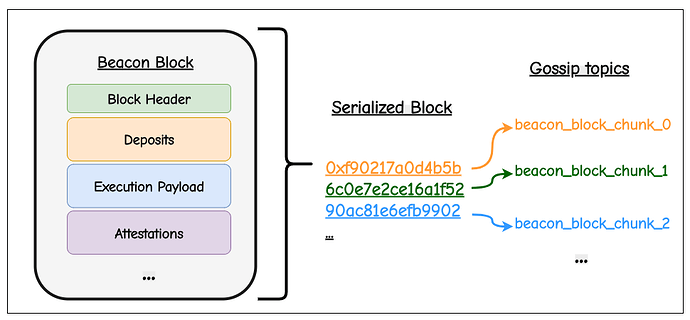
(1) 在基础层面,可以简单地将 RLP 序列化的区块视为字节流,并将其切割成固定大小的切片。这些碎片易于传播,且非常适合传输协议,但它们没有任何意义:在整个区块重新组装完成之前,验证者无法对其进行任何操作。这种非语义化分块 (non-semantic chunking) 有助于带宽平滑和数据可用性,但并不能改善执行延迟。
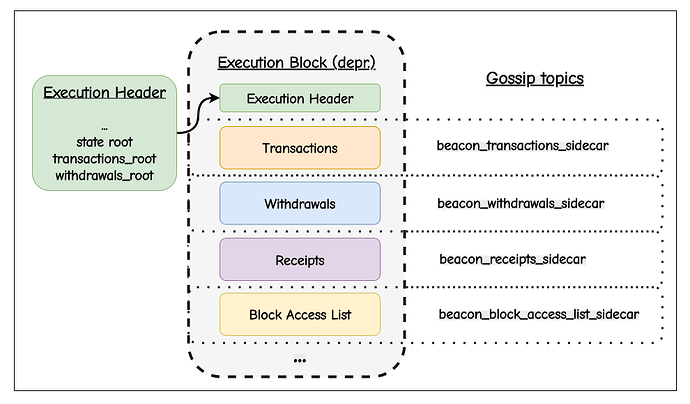
(2) 结构上的进步是沿其自然模式边界拆分区块。在这里,Header、交易列表、提款(Withdrawals)、收据(Receipts)和执行输出都将作为独立对象进行传播。这些部分对应于协议定义的字段,并且允许(例如)在获取完整主体之前部分获取 Header,或优先处理证明(Attestations)。然而,这些组件通常只有在一起时才有意义:执行仍然需要完整的 Payload,因此对验证者延迟的改善仍然有限。
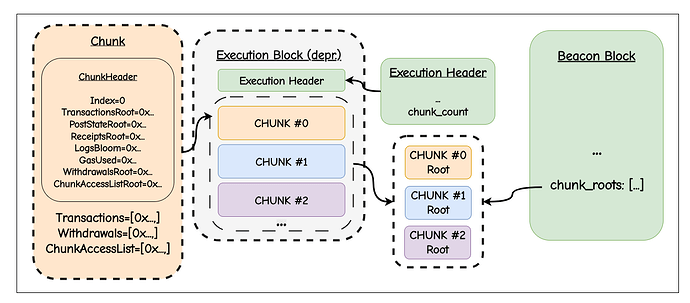
(3) 更具雄心的版本是重新定义区块本身,将其视为一系列自包含的 分块 (chunks)。每个分块都携带自己的 Header、交易和后状态根(Post-state root),并且作为一个对象是可以独立验证的。通过将一个分块的后状态连接到下一个分块的前状态(Pre-state),分块链构成了规范区块。这超越了分解,变成了组合式语义分块 (compositional semantic chunking):分块不仅仅是碎片,而是协议的新语义单元。验证者可以在第一个分块到达时立即开始执行,而无需等待完整区块到达。这开启了真正的流式验证(Streaming validation),并为每分块证明(Per-chunk proofs)和并行证明铺平了道路。
值得注意的是,这些方法并不一定相互排斥:我们可以采用 (3),同时将交易、提款、执行输出等从分块中分离出来,并将它们与 (2) 的语义分块方法相结合。此外,分块也可以在序列化之后、压缩之前进行拆分,如 (1) 所述。
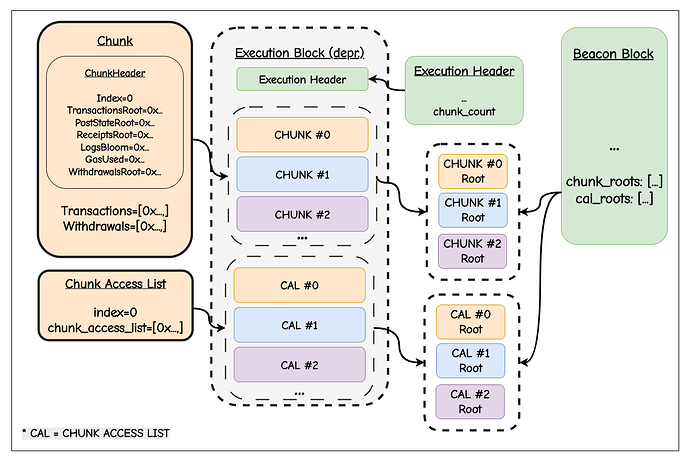
作为新语义单元的分块
我们不再将区块视为单一的执行 Payload,而是将其重构为多个分块。我们今天所熟知的区块在概念上被重新构建,现在仅由一个 Header 和若干分块组成。Header 承诺了一个 Slot 中所有分块的执行,包括最后一个分块的后状态根。
分块架构
在 CL 上,每个 ExecutionChunk 包含:
class ExecutionChunk(Container):
chunk_header: ExecutionChunkHeader # 带有执行承诺的 Header
transactions: List[Transaction, MAX_TRANSACTIONS_PER_PAYLOAD]
withdrawals: List[Withdrawal, MAX_WITHDRAWALS_PER_PAYLOAD]
ExecutionChunkHeader 包含了通常在区块 Header 中预期的字段:
class ExecutionChunkHeader(Container):
index: int
txs_root: Root
post_state_root: Root # 可以移除以减少哈希开销
receipts_root: Root
logs_bloom: Bloom
gas_used: uint64
withdrawals_root: Root
正如 proto 在这份关于 Flash BALs 的文档中所描述的,后状态根可以从分块 Header 中移除,以减少哈希开销。这是一个有趣的想法,它使设计更接近于区块现在的样子(即,没有中间状态根)。
技术约束
协议实施了严格的边界以确保可预测的执行:
- Gas 限制:每个分块必须遵守
CHUNK_GAS_LIMIT = 2^24(16,777,216) Gas 的硬性限制。 - 最大分块数:每个区块最多
MAX_CHUNKS_PER_BLOCK = 16个分块。 - 最低填充要求:非末尾分块必须至少填充 50%(≥ 2**23 Gas),以防止效率低下的碎片化。
- 提款位置:提款仅包含在最后一个分块中,以保持一致性。
- 状态连续性:分块 i 的后状态成为分块 i+1 的前状态。分块边界充当中间状态根,但如果额外的哈希增加了过多的开销,这些中间状态根可以被移除。
- 区块原子性:通过按顺序排列分块并仅考虑最后一个分块的执行输出,我们近似于当前定义的区块。
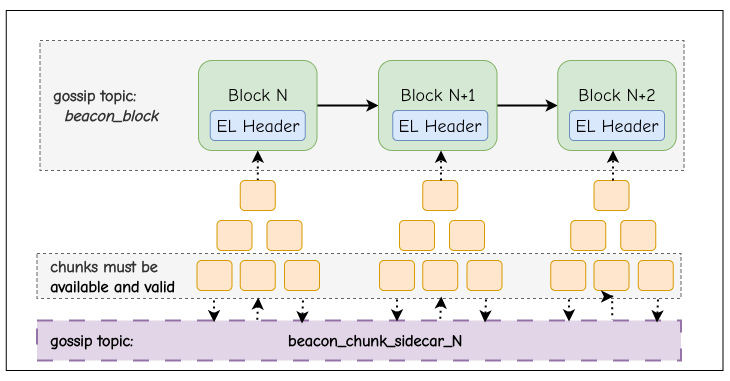
这使分块从一种传播技巧转变为区块结构的语义重新定义。验证者可以通过流式验证过程在分块到达时独立执行它们,但只有在序列中的每个分块都成功执行时,区块才有效。
CAL 架构:状态差异作为独立对象
假设我们将区块拆分为分块,那么我们应该将区块级访问列表(Block-level Access List, BAL)放在哪里?
区块级访问列表 (EIP-7928) 是一个向区块添加状态位置(地址、存储键)+ 交易级状态差异(State Diffs)的提案,旨在实现独立于交易依赖关系的并行执行。
对于 Payload 分块,分块访问列表 (CALs) 作为 Sidecar 与分块分开传播,其中 CALs 包含其对应分块的状态差异:
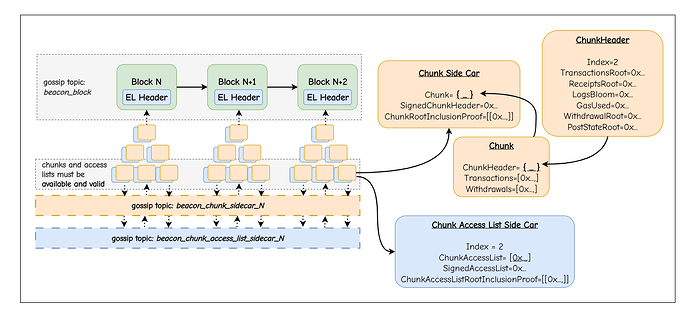
执行依赖关系
解决分块之间的依赖关系:
- 每个 CAL 包含其对应分块执行后的状态差异(账户更改、存储修改)。
- 每个分块 N 需要直到 N-1 为止所有前序分块的 CAL 并集才能被独立执行。这是因为 CALs 包含了重建所需前状态所需的状态更改:
apply_cals(parent_state, [cal_0, cal_1]) -> pre_state_for_chunk_2
- 要执行分块 N,验证者必须拥有:
chunk[N]本身CAL[0], CAL[1], ..., CAL[N-1](包含累积的状态差异)
这创建了一个累积依赖链,其中早期 CAL 的延迟到达会延迟所有后续分块的执行。然而,由于 CALs 通常很小,它们在网络中的传播速度很快。
设计考虑: 每一个 CAL 都可以携带一个相对于前状态(Chunk 0 之前)的差异,而不是编码相对于前状态(分块 0)或前一个分块(分块 1 到 n)的状态差异。这将允许验证者在不等待 CALs #0–2 的情况下执行(例如)分块 #3,仅需要 CAL #2。权衡之处在于 CAL #2 会变得更大,因为它必须包含自身的状态差异以及从早期分块累积的差异。
网络架构
CALs(包含状态差异)与分块的分离创造了截然不同的传播路径:
Gossip 主题:
- 分块(交易 + 提款)在
execution_chunk_sidecar_{subnet_id}上传输,其中subnet_id = chunk_index % 16。 - CALs(状态差异 + 访问信息)在
chunk_access_list_sidecar_{subnet_id}上传输,其中subnet_id = cal_index % 16。
分叉选择和两阶段验证
分叉选择仔细区分了分块可用性和区块有效性:
修改后的 Store
class Store:
# ... 现有字段 ...
chunks: Dict[Tuple[Root, ChunkIndex], ExecutionChunk]
chunk_access_lists: Dict[Tuple[Root, ChunkIndex], ChunkAccessList]
chunk_validation_status: Dict[Tuple[Root, ChunkIndex], bool] # 第一阶段
payload_chunk_availability: Dict[Root, bool] # 所有分块都存在
block_state_valid: Dict[Root, bool] # 第二阶段 - 最终状态与 Header 匹配
关键区别:分块可以被独立验证(Validated),但只有在验证了完整的状态转换后,区块才是有效的(Valid)。
执行引擎接口
两阶段验证反映在执行引擎 API 中:
## 第一阶段:独立分块验证
def notify_new_chunk(execution_engine, block_root, chunk, parent_root):
# 内部验证分块 - 交易、Gas、本地状态转换
return execution_engine.validate_chunk(block_root, chunk, parent_root)
def notify_new_chunk_access_list(execution_engine, block_root, index, cal):
# 提供带有状态差异的 CAL 以进行独立执行
execution_engine.new_chunk_access_list(block_root, index, cal)
## 第二阶段:完整的状态转换验证
def finalize_chunked_payload(execution_engine, block_root, expected_chunks, header):
# 验证:chunks[-1].post_state_root == header.state_root
# 这是确定区块有效性的地方
return execution_engine.verify_state_transition(block_root, expected_chunks, header)
区块有效性检查
协议在证明(Attestation)之前强制执行这两个阶段:
def is_block_valid(store: Store, block_root: Root) -> bool:
block = store.blocks[block_root]
# 第一阶段:所有分块均已单独验证
for i in range(len(block.body.chunk_roots)):
if not store.chunk_validation_status[(block_root, i)]:
return False # 分块验证失败
# 验证分块是否与承诺的根匹配
if hash_tree_root(store.chunks[(block_root, i)]) != block.body.chunk_roots[i]:
return False
# 第二阶段:完整状态转换已验证
if not store.block_state_valid[block_root]:
return False # 最终状态与 Header 不匹配
# 验证最后一个分块的后状态是否与 Header 匹配
final_chunk = store.chunks[(block_root, len(block.body.chunk_roots) - 1)]
if final_chunk.post_state_root != block.header.state_root:
return False # 状态转换无效
return True
验证者绝不能在 is_block_valid() 返回 true 之前进行证明,以确保:
- 所有分块均独立验证(第一阶段)。
- 最终状态转换与区块 Header 匹配(第二阶段)。
执行层架构
执行层实现流式验证,以便在分块到达时对其进行处理:
核心数据结构
在 EL 上,分块是自包含的执行单元:
class ExecutionChunk:
chunk_header: ExecutionChunkHeader # 在区块中的位置
transactions: Tuple[Transaction] # 完整的交易(未拆分)
withdrawals: Tuple[Withdrawal] # 仅在最后一个分块中
流式验证组件
EL 采用关键组件进行流式验证:
- StreamingChunkReceiver:管理每个区块的分块接收和验证。
- 跟踪分块的到达(可能是无序的)。
- 一旦满足依赖关系就立即验证。
- 维护每个分块的验证上下文。
- Chunk Processor:编排验证流水线。
- 顺序模式:使用前一个分块的后状态。
- 独立模式:将累积的 CALs 应用于父状态(Parent State)。
关键见解在于 CALs 包含了分块执行中的状态差异,从而能够实现独立验证而无需顺序依赖。
执行模式
根据可用数据,分块可以以两种模式执行:
def validate_chunk(chunk_index, chunk, dependencies):
if chunk_index == 0:
# 第一个分块直接使用父状态
pre_state = parent_state
elif previous_chunk_validated:
# 使用前一个后状态进行顺序执行
pre_state = chunks[chunk_index - 1].post_state
elif all_prior_CALs_available:
# 通过应用 CALs(包含状态差异)进行独立执行
# CALs 包含其分块的所有状态更改
pre_state = apply_CALs(parent_state, CALs[0:chunk_index])
# 执行分块交易
post_state = execute(pre_state, chunk.transactions)
assert post_state.root == chunk.post_state_root
两阶段验证:独立分块,有效状态转换
该架构将分块验证与区块验证分开:
第一阶段:独立分块验证(流式)
当每个分块到达时,验证者立即核实:
- 内部一致性:交易有效,遵守 Gas 限制。
- 本地状态转换:使用前一个分块的后状态,或将 CALs 应用于父状态。
- 分块承诺:执行分块交易后
post_state_root匹配。 - 不需要区块上下文:每个分块在隔离状态下进行验证。
这发生在区块 Header 到达之前,并且不知道最终状态根。可以通过验证提议者在分块 Header 上的签名来验证分块和 CALs。
第二阶段:区块状态转换验证
一旦所有分块都通过验证:
- 验证连续性:分块 N-1 的后状态必须等于分块 N 的前状态。
- 聚合输出:来自所有分块的总 Gas、收据、日志。
- 根据 Header 验证:最终状态根必须匹配
block.header.state_root。 - 原子决策:当且仅当所有分块都通过验证且最终状态匹配时,区块才有效。
## 第一阶段:每个分块独立验证
for chunk in arriving_chunks:
validate_chunk(chunk) # 无需完整区块即可快速失败
## 第二阶段:验证完整的状态转换
if all_chunks_valid:
final_state = chunks[-1].post_state_root
assert final_state == block.header.state_root # 区块有效性
这种分离使分块能够在流式处理期间快速失败,但保留了关键属性,即区块有效性取决于与承诺 Header 匹配的完整状态转换。
包含证明
每个分块和 CAL Sidecar 都包含一个 Merkle 包含证明(Inclusion Proof):
class ExecutionChunkSidecar(Container):
chunk: ExecutionChunk
chunk_signature: SignedChunkHeader
chunk_root_inclusion_proof: Vector[Bytes32, CHUNK_INCLUSION_PROOF_DEPTH]
这确保了即使分块无序到达或来自不同来源,验证者也可以在处理之前验证它们属于承诺的区块。
构建者(Builder)与本地区块生产
协议支持两种截然不同的分块生产流程:
构建者流程
- 构建者创建一个遵守所有约束的分块 Payload。
- 构建者发送包含
chunk_roots和chunk_access_list_roots的SignedExecutionPayloadBid。 - 提议者(Proposer)将这些承诺包含在信标区块(Beacon Block)中。
- 构建者作为 Sidecar 发布实际的分块和 CALs。如果构建者未能发布,则区块变为无效。
本地流程
- 提议者向本地执行引擎请求一个分块 Payload。
- EL 返回构建好的分块,同时遵守 Gas 限制和填充要求。
- 提议者在分块返回时开始发布它们。
- 提议者计算根:
chunk_roots = [hash_tree_root(chunk) for chunk in chunks],分块访问列表同理。 - 提议者发布一个包含这些承诺的信标区块。
与将区块生产外包给试图尽可能晚提交的实体(即提议者时间博弈)相比,在本地构建区块的提议者将从流式处理中获益更多。
其他生态系统中的相关方法
其他生态系统以不同的方式探索了并行化和“分块”。
Fuel 和 Solana 都依赖于预先声明其完整读/写集的交易:Fuel 对 UTXO 样式的资源强制执行显式访问列表,以将交易划分为并行的无冲突集合;而 Solana 的 Sealevel 运行时并发调度非重叠的账户写入,其 Turbine 协议纯粹为了传播而将区块数据分块为 Shreds。
Aptos 和 Starknet 使用 Block-STM,它投机性地并行执行所有交易,并回滚冲突,直到达到确定的顺序状态;而 Sui 应用了一种变体,其中非冲突的以对象为中心的交易可以完全绕过共识。
相比之下,NEAR 和 Polkadot 追求状态分片:NEAR 在分片之间拆分账户,并将每个分块聚合到一条链中;而 Polkadot 运行异构平行链,其有效性证明由中继链(Relay Chain)检查并使其可用。
Base 的 Flashblocks 引入了时间分块 (temporal chunking) 而不是分片或状态分区:在每个 2 秒的区块窗口内,排序器以预确认的形式流式传输十个“Flashblocks”(间隔约 200 毫秒),并带有受限的 Gas 预算。这些微区块通过公开子区块排序降低了延迟并改善了用户体验,但所有节点仍然处理一个全局状态,并且 Flashblocks 会合并到最终区块中,没有跨分片的复杂性。
与这些模型相比,语义化 Payload 分块保持了以太坊单一全局状态机的特性,但将分块提升为具有可验证交易后状态差异(CALs)的一等协议对象,从而实现了流式验证和每分块证明,而无需投机执行或跨分片异步。此外,得益于 CALs,我们不必止步于乐观并行化:交易可以实现完美的并行化,且独立于状态依赖关系。
为什么语义化分块很重要
非语义化分块有助于传输,但不会改变区块的本质。相比之下,所描述的语义分块方法:
- 重新定义了区块结构:每个分块都是具有自身验证规则和执行输出的一等协议对象。
- 支持流式验证:验证者并行化下载和执行,分块通过
notify_new_chunk()立即处理。 - 提高了模块化:CALs 将状态差异与交易数据分开封装,从而实现独立执行。
- 支持未来证明:可以为每个分块生成 ZK 或乐观证明,且证明时间有界(最大 16.7M Gas)。
- 保留了原子性:区块保持原子性——所有分块必须验证通过,区块才有效。
在 EL 上,我们可以期待具体的性能提升:
- 有界的内存和计算:每个分块最多消耗
CHUNK_GAS_LIMIT的资源。 - 快速拒绝:无效分块会快速失败,而不需要处理所有分块。
- 并行验证:可以使用 CALs(包含状态差异)并发验证多个分块。
共识层的语义化分块与执行层的流式验证相结合,将区块处理从单体操作转变为可组合、可流式传输的流水线,该流水线随着网络容量的增长而扩展,而不是被最大的原子单元所阻塞。
- 原文链接: ethresear.ch/t/toward-se...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
