网络稳定性之路
本文介绍了ethrex客户端在P2P网络层面的多项优化,旨在提升节点稳定性、降低带宽消耗并增强同步可靠性。
1. 发现 Ping:当对等节点过度询问你的邻居时,你可能需要在回答前稍等片刻
执行客户端如何相互发现
两个执行客户端需要在约 5k–10k 个匿名对等节点组成的网络中相互发现,才能通过 RLPx 交换区块或交易。discv4 协议规定了这种行为,这是以太坊节点自 Frontier 时代开始使用的基于 UDP 的 Kademlia 变体,discv5 也位于其旁。其结构遵循标准的 Kademlia:
- 每个节点都有一个 256 位的身份标识,源自 secp256k1 公钥。
- 节点维护一个包含 256 个 k-bucket 的路由表,每个 bucket 最多容纳 k = 16 个联系人,按与其自身 ID 的 XOR 距离索引。规范对这两个数字都有明确规定。
- 节点向已知对等节点发送
FindNode(target_id),该节点在Neighbors数据包中返回其已知的最多 16 个最近的联系人。通过对随机或特定目标的重复查找,可以填充路由表。
端点证明 机制防止了该协议被滥用。discv4 规范指出:“仅当 FindNode 的发送方已通过端点证明程序得到验证时,才应发送 Neighbors 回复。” 在从对等节点获得 FindNode 响应之前,你必须与其完成一次最近的 Ping/Pong 交互,并且该对等节点会将你标记为已验证状态 12 小时。没有这条规则,任何人都可以伪造源 IP,发送 FindNode,然后让网络向受害者发送包含 16 个节点的 Neighbors 数据包,将 Kademlia 变成一个 UDP 放大器。discv5 采用了不同的方法(WHOAREYOU 挑战-响应),目标相同:以密码学方式证明对方拥有其声称的端点。
另一部分是重新验证。规范对此提及甚少,只说明当你向一个已满的 bucket 中插入新联系人时,需要 ping 最久未被看到的条目,如果该条目未回复则将其驱逐。规范并未规定定期的重新验证速率。不过每个客户端都会自行实现,因为路由表中充斥失效条目会浪费查找时间,并且任何超过 12 小时的联系人都将超出端点证明窗口,其 FindNode 请求将被丢弃。
每个客户端所做的实现选择是其重新验证的积极程度。Geth 大约每 1 秒 选择一个随机失效联系人,以每秒约一个 ping 的稳定速率进行。Reth 运行一个 10 秒的周期,在每个 tick 收集所有过期条目并批量 ping 最多 32 个(crates/net/discv4/src/lib.rs 中的 re_ping_oldest)。Nethermind 没有专门的重新验证循环;其 DiscoveryApp 运行带有自适应退避的 Kademlia 查找循环,而 ping 作为节点状态转换和 bucket 驱逐挑战的副作用发生(NodeLifecycleManager.cs)。
这是两种处于相反极端的合理策略。ethrex 早期的设计选择了频谱上的另一个点,我们着手改善其产生的操作行为。
先前设计产生流量峰值的地方
旧代码的两个相互作用属性驱动了大部分 discv4 数据包速率:
- 发送给 ethrex 的每个
Neighbors响应(最多 16 个节点)都会立即触发对每个节点的Ping,理由是希望这些新联系人尽快有资格参与下一次FindNode查找。我们发送的一个FindNode会在响应中扩散为 16 个出站 ping,这是 1:16 的放大。 - 重新验证循环在每个 tick 都通过一个紧凑的
for循环遍历所有失效联系人。当有数千个联系人时,其中大多数在任何给定时刻都处于 12 小时端点证明窗口之外(我们在启动时执行大部分查找,之后很少再联系大多数联系人),每个重新验证 tick 都会产生一波 ping 脉冲。
第一个补丁 #6394 将 per-neighbor ping 从 handle_neighbors(crates/networking/p2p/discv4/server.rs)中移除。新联系人通过常规的重新验证循环处理,而不是在收到 Neighbors 时立即被 ping。同一个 PR 添加了一个追踪器,使我们仅接受针对我们自己发送的 FindNode 请求的 Neighbors 响应,这关闭了一个未经请求的表注入向量,而仅靠放大修复无法捕捉到它。
同一个 PR 还将 REVALIDATION_CHECK_INTERVAL 从 12 小时降低到 30 秒,理由是:如果没有到达时的立即 ping,重新验证循环必须足够频繁地运行,以便在合理的时间窗口内 ping 新联系人。这部分需要第二次改进:重新验证循环仍然在做“在这个 tick 中 ping 所有失效联系人”的事情,所以每个 FindNode 产生的脉冲式 1:16 放大变成了每 30 秒一次稳定波动的 ping。
在收到我们一台服务器上的 Hetzner 警告后,我们改进了 Grafana 指标以更好地追踪出站流量。在稳定状态下,我们观察到约 29k UDP packets/sec。相比之下,Geth 大约以 1 ping/sec 运行。
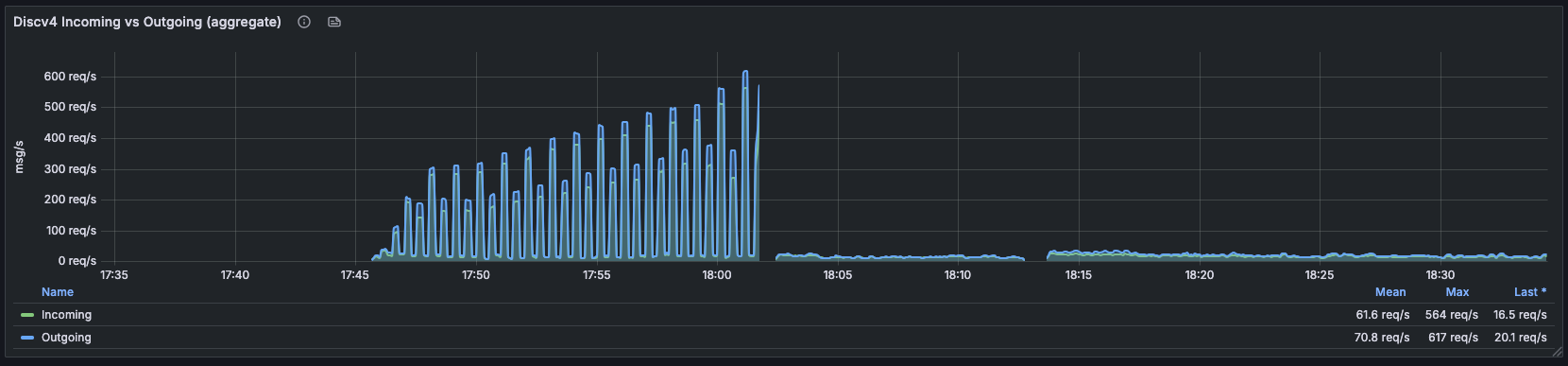
discv4 入站/出站汇总。 部署前状态:每约 30 秒,当重新验证 tick 触发且所有失效联系人同时被 ping 时,峰值飙升至 617 req/s。部署后约 18:02:平坦地处于 16–20 req/s 范围,更宽时间窗口内平均为 61.6 / 70.8 req/s。
同样的修复也应用于 discv5,其中根本问题更为明显,因为失效阈值设置得太低(下文详述):
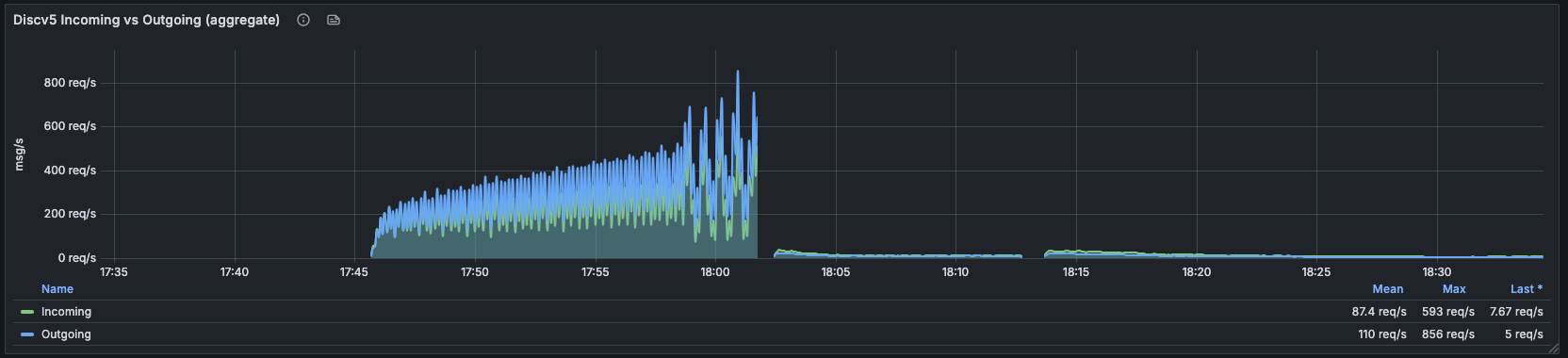
discv5 入站/出站汇总。 部署前:持续 200–600 req/s,出站峰值高达 856 req/s。部署后:骤降至个位数 req/s(窗口内平均 87.4 / 110 req/s;最终读数:7.67 / 5 req/s)。
更少的邻居,拜托了
#6438 是适当的修复:
- 蓄水池采样式重新验证。 每个 tick 从经过过滤的 peer 表中的所有失效联系人中,均匀随机地选择一个符合条件的联系人,并且仅 ping 这一个。ping 速率现在受限于周期间隔,而不是表大小,这是先前代码不具备的特性。
- 不要对已经有 ping 在传输中的联系人再次发起 ping。 以前,
Contact::was_validated()仅检查上次验证的时间戳,因此一个 100ms 前刚刚发送 ping 且仍在等待响应的联系人看起来是未验证的,下一个周期会再次 ping 它。现在,现有的传输中 ping 必须要么成功落地,要么超时(30 秒),我们才会发送另一个 ping。 - discv5 有自己的 bug。 它的
REVALIDATION_INTERVAL(即失效阈值,而非循环 tick)设置为 30 秒,而 discv4 是 12 小时,因为我们当时使用重新验证间隔来追踪待处理的联系人。每个 discv5 联系人都看起来永远失效,循环从不停止寻找任务。已将其常量调整一致。
这些名称容易混淆,为明确起见:REVALIDATION_CHECK_INTERVAL 指循环运行的频率(现在为 1 秒);REVALIDATION_INTERVAL 指联系人需要达到多老才会被考虑重新 ping(12 小时,与端点证明窗口匹配)。1 秒循环的每个 tick 选择一个失效联系人并 ping 它,因此 ping 速率受限于 tick 速率,而不是失效联系人的数量。
这里出现了一个更通用的模式。最初的“ping 我们听到的每个邻居”设计是一种积极的验证策略:构建稳固快速的 peer 表,代价是高数据包速率。而解决此问题的朴素方法(将所有未验证的联系人推入一个队列,让重新验证循环处理它)则有相反的故障模式:队列增长速度快于处理速度,在启动后查找最密集时堆积最严重,因此它也没有边界。蓄水池采样在这两个极端之间找到了平衡点。队列是隐式的(它就是路由表),我们以不依赖于其满载程度的速度处理它。对长期运行的节点而言,用一些收敛延迟换取稳定、有界的数据包速率是正确的权衡,其他客户端如 geth 出于相同原因也采用此方法。
| #6394 之前 | #6394 之后(问题状态) | #6438 之后 | geth | reth | |
|---|---|---|---|---|---|
每个 FindNode 的 ping 数 |
16(放大) | 0 | 0 | 0 | 0 |
| 重新验证 ping/秒 | 脉冲式 | 无界(观察到 29k/s) | ~2/秒 | ~1/秒 | 每 10 秒最多 32 个(脉冲式) |
| discv5 失效阈值 | 30秒 | 30秒 | 12小时 | 12小时 | 不适用 |
| 当 ping 正在传输时重新 ping | 每个周期 | 每个周期 | 仅在 30 秒超时后 | livenessChecks/3 | 每个 peer 一个进行中的 ping |
一个带有干净数据库的 ethrex 节点现在可以在 3 分钟内达到 22 个 peer,15 分钟内达到 100+ 个,同时 discv4 数据包速率稳定在新的基线上。“Cached nodes”曲线显示了从具有热 peer 缓存(约 10 分钟内填满表)的重启中恢复的情况;“Started from scratch”曲线是同一个节点清空数据库后重启,此时 peer 发现执行完整的 Kademlia 漫步,但仍然在大致相同的时间内完成:

2. GetPooledTransactions:停止向一百个对等节点询问同一个哈希
交易如何在网络上移动
一旦两个执行客户端通过 RLPx(基于 TCP 的加密、帧化的 P2P 传输)连接起来,它们就使用 eth wire 协议。该协议定义了交易如何在内存池之间传播。流程包含三个消息,自 eth/65(EIP-2464,2020年1月)以来一直是这样:
NewPooledTransactionHashes(0x08):“我有这些交易,这里是它们的哈希(并且,自 eth/68 起,还包括类型和大小)。”当一个对等节点新了解到某个交易时,会发送此消息。规范规定每条消息的软限制为 4096 项(约 150 KiB)。GetPooledTransactions(0x09):[request-id, [hash₁, hash₂, ...]]。“给我这些哈希对应的交易数据。”每个请求的软限制为 256 个哈希(约 8 KiB)。PooledTransactions(0x0a):响应,顺序与请求相同,允许响应者跳过其没有的交易。
规范解释了这种先公告后获取的设计:“随着以太坊主网上活动量和交易规模的增长,用于交易交换的网络带宽成为节点运营商的重大负担。此次更新通过采用类似区块传播的两层交易广播系统来减少所需带宽。” 在 eth/65 之前,每个对等节点都会将完整的交易数据推送给所有其他对等节点。对于 50 个对等节点和平均几百字节的交易大小,你会收到同一个交易 50 次。将公告与获取分离,让接收方在拉取任何交易数据之前可以针对自己的内存池进行去重。
问题在于,公告仍然来自所有对等节点。八卦协议依靠冗余工作:一个广播到网络上的交易会在一秒左右到达每个连接良好的节点,因为每个节点都会将哈希转发给其所有对等节点。如果有一百个对等节点,你会在短时间内从所有 100 个节点那里听到一个热门交易。协议期望如此;这正是设计的全部意义所在。接收方在发出 GetPooledTransactions 之前进行去重。
客户端如何处理这个问题各不相同。Reth 的 TransactionFetcher(crates/net/network/src/transactions/fetcher.rs)维护两个结构:一个全局的跨所有哈希的“进行中或已排队”集合,以及每个哈希的 TxFetchMetadata,其中包含一个备选 peer 的 LRU 缓存,以便在首次请求失败时重试命中不同的 peer。Nethermind 将去重委托给交易池本身;Eth65ProtocolHandler 使用 _txPool.IsKnown(hash) 和 NotifyAboutTx 过滤公告,并且交易池使用一个 _retryCache 来记录第二个 peer 的公告作为备选,而不是新的请求。
ethrex 的早期路径没有相应的层,这正是我们着手添加的。
先前设计产生额外出站请求的地方
每个 NewPooledTransactionHashes 到达,无论我们是否已经在 30 毫秒前从另一个 peer 那里看到过该哈希,都会触发一个完整的 GetPooledTransactions 请求。问题的结构是:假设每秒有 H 个热门交易通过八卦协议流出,有 P 个对等节点,接收方会收到大约 H × P 个公告,但只需发送 H 个出站请求(每个唯一哈希一个)。而早期路径是每个公告发送一个出站请求,在公告高峰期(一个热门 DEX 交易或 NFT 铸造可能在几百毫秒内通过八卦协议发送数百个交易),跨 peer 的倍增效应会在出站 RLPx 面板上显示为每秒数千个请求,而公告速率低一个数量级。
修复:两个 PR
#6437 添加了结构性组件:一个传输中追踪器。该结构位于每个连接维护的 RLPx 状态中(crates/networking/p2p/rlpx/connection/server.rs 中的 requested_pooled_txs: HashMap<u64, (NewPooledTransactionHashes, Vec<H256>, Instant)>),以请求 ID 为键,存储我们询问的哈希以及请求时间戳。一个 30 秒超时(INFLIGHT_TX_TIMEOUT)会清理过时条目。传入的公告会检查传输中的集合,我们丢弃任何已经在进行中的哈希。在收到响应时、连接拆除时以及超时清理时进行清理。
#6443 随后添加了时间维度的部分。即使在去重之后,对每个幸存的公告都发送一个 GetPooledTransactions 也不是理想的,因为该消息是一个列表,所以我们应该进行批量处理。该 PR 在每个连接的状态中添加了 pending_tx_requests: Vec<(NewPooledTransactionHashes, Vec<H256>)>,以及一个 50 毫秒的 tick(TX_REQUEST_BATCH_INTERVAL)来处理它:通过 NewPooledTransactionHashes::merge() 合并哈希,按 256 个哈希(规范的软限制)分块,并作为每个块发送一个请求。
在部署这两个 PR 后,出站速率与公告速率解耦:
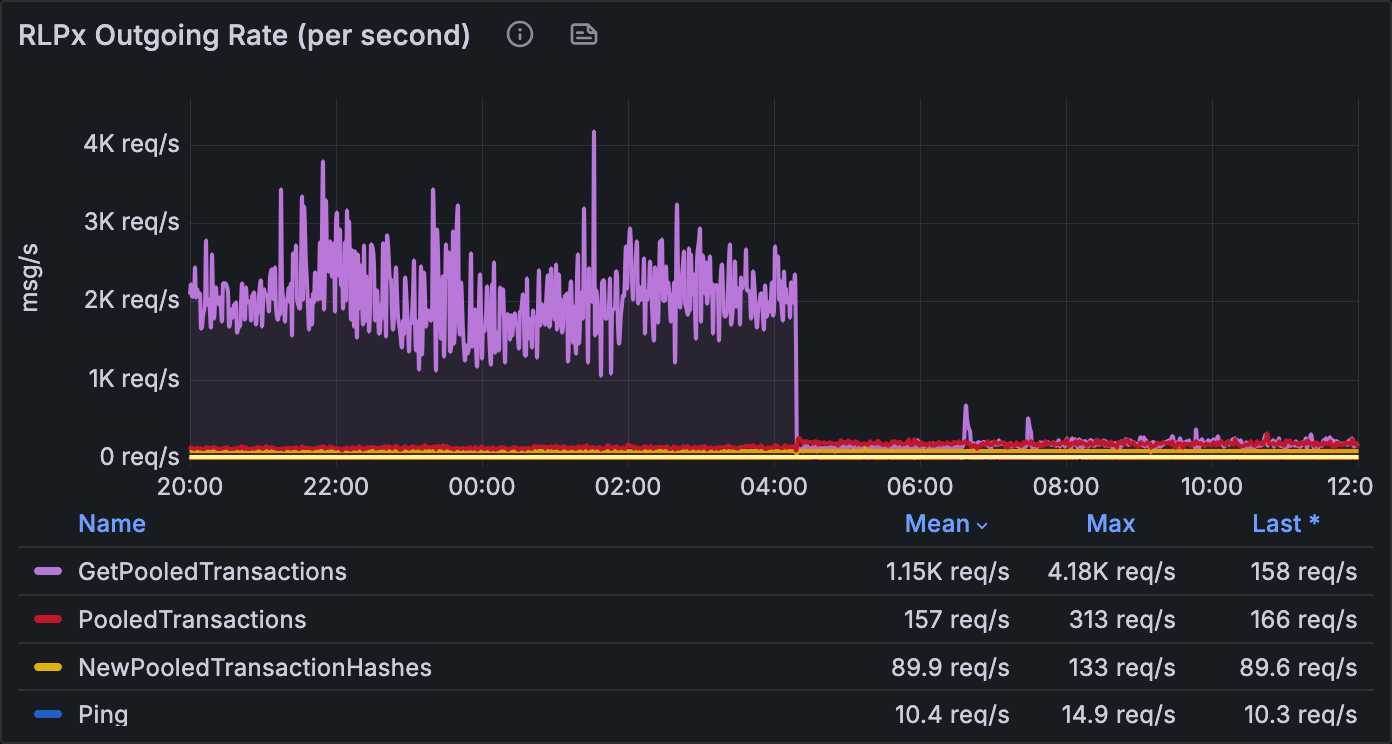
RLPx 出站速率(每秒)。 部署前:
GetPooledTransactions出站持续保持在 2K–4K req/s(平均 4.18K req/s)数小时,而传入的NewPooledTransactionHashes仅运行在约 90 req/s。每个公告都被回显并再次回显为独立的出站请求。部署后约 04:30:GetPooledTransactions骤降至 最终 158 req/s,而NewPooledTransactionHashes保持不变约 90 req/s。我们的出站请求速率现在与唯一交易数成正比,而不是与告诉我们每个交易的 peer 数量成正比。
第 1 节中相同的积极/队列权衡在此处出现。积极: 到达时立即发送请求,更快地将交易纳入内存池,但浪费带宽处理重复。队列: 缓冲一段时间,去重,发送更少的请求,代价是交易进入池之前增加了一点延迟。50 毫秒足够短,以至于内存池包含延迟远低于典型的区块间隔(主网上的多秒),也远低于大多数 peer 的入站去重窗口;并且足够长,以至于在一个 50 毫秒窗口内有一百个 peer 公告的热门交易会压缩成一个请求。当上游有大量流量时,你吸收并去重,而不是镜像回传。
Reth 完全不进行时间批量处理;它依赖每个 peer 的 pack_request_eth68 来用发送时刻队列中的任何内容填满 256 哈希预算,再加上基于容量的并发限制(整个集群 130 个并发请求,每个 peer 1 个)。这之所以有效,是因为 reth 从一开始就不会针对每个公告发送请求;队列是结构性的,而非时间性的。ethrex 的 50 毫秒窗口是能让我们在无需更深入重构的情况下获得大部分相同压缩效益的最小间隔。
3. 全同步:容忍你的对等节点,并在被催促时放慢速度
究竟什么是全同步?
执行客户端从创世区块构建到最新区块的最经典方式就是全同步。客户端下载区块头和区块体,并重新执行每一笔交易,从头开始构建状态。全同步的运行速度比 snap sync 慢得多(在主网上需要数天到数周),但相同的原语也驱动着追赶模式。关闭你的节点,等待几小时或几天,然后再打开,它会从你上次已知的状态开始执行直到当前最新区块之间的所有区块。
全同步有两个主要组成部分:头部下载阶段(决定你所在的链,获取直到同步目标的头部),然后是一个区块体下载并处理的阶段。头部下载是 peer 选择发挥作用的地方,因为它是整个过程中对 peer 质量最敏感的阶段。区块体可以并行化;头部是链式的。
Peer 评分应该如何工作
一个拥有许多 peer 的节点需要为每一个请求选择同伴:我们该问谁?一个失败的请求(超时、错误数据、peer 断开连接)会花费一个往返和一次重试;一个成功的请求则不会。标准模式是维护一个每个 peer 的分数,成功时增加,失败时减少,并在选择时偏向分数较高的 peer。确切的模型在不同客户端之间有所不同:
- reth 使用加法信誉。每个 peer 从 0 开始,惩罚是大负整数(
Timeout = -4096,BadMessage = -16384,BadProtocol = i32::MIN),一个周期性的tick()将分数衰减回 0,以此作为对仍然连接着的 peer 的“奖励”。受信任的 peer 有损失上限。当分数降至BANNED_REPUTATION = -51200以下时,会触发断开连接并封禁(crates/net/network-types/src/peers/reputation.rs)。 - nethermind 不为同步目的对 peer 评分;其
BySpeedStrategy根据TransferSpeedType.Headers的测量传输速度的 EMA 对 peer 进行排名,并在速度比率和最小速度变化阈值都触发时切换当前 peer(Nethermind.Synchronization/Peers/AllocationStrategies/BySpeedStrategy.cs)。这是一个速度计,而非信誉积分系统。 - ethrex 使用一个更窄的范围:
MAX_SCORE = 50, MIN_SCORE = -50,对于恶意行为使用MIN_SCORE_CRITICAL = -150(peer_table.rs:38-41)。分数以单位递增,且选择权重(peer_table.rs:1315)是分数范围的规范化函数。
难点在于:如何判断一个 peer 是没响应还是只是慢?
头部下载:让分数影响选择(#6428)
头部下载循环中的三个更改:
-
选择现在是按分数加权的,而非均匀随机。 分数机制已经存在;但选择器没有读取它。现在选择按分数加权,同时保留足够的随机性,以便新 peer 仍然有机会被尝试,并且我们不会锁定到一个单一 peer。
-
成功时分数也增加。 以前我们仅在超时时减小分数,而没有在成功消息上增加分数,因此 ethrex 对 peer 质量的估计过于悲观。
另一方面,空响应不会被惩罚。 如果某个 peer 对接近链顶部的头部请求返回空体,那是告诉我们“我没有超过区块 X 的内容”,这在其已知链的边界上是正确的行为,而不是失败。非空的未连接响应(其中 headers[i].parent_hash != headers[i-1].hash())会受到惩罚;那些是无效的。
- 连续失败,而非累积失败。
consecutive_failures计数器的本意是“该 peer 已连续失败 N 次,丢弃它”。以前,计数器在成功响应后不会重置,因此一个长期存在、服务了数小时头部的 peer 可能会累积足够多的失败总数而被丢弃,尽管其总体成功率很高。修复后(crates/networking/p2p/sync/full.rs:149),计数器在每个成功的头部批次后重置为零。同样的修复也应用于 snap sync 中的等价代码路径。
每个请求的超时也从 15 秒降低到 5 秒(snap/constants.rs 中的 PEER_REPLY_TIMEOUT)。在旋转中有 42 个 peer 时,旧的 15 秒超时意味着简单的“问每个人,看谁回答”一轮可能需要 10 分钟以上,如果慢速 peer 首先出现在队列中的话。5 秒给了一个健康的 peer 足够的余地来响应,并且能快一个数量级地淘汰一个慢速 peer。
综合效果:选择循环将流量集中到那些一直有用的 peer 上,而一个不稳定的 peer 不再阻碍其后面所有人的进度。在像 hoodi 这样 peer 质量参差不齐的链上,即使个别 peer 变慢或无响应,头部下载也能持续进行。
逐块回退(#6464)
头部下载只是一部分。另一部分,#6464,处理执行问题。我们遇到了一个 hoodi 全同步在区块 443,055 处因批量执行期间的 StateRootMismatch 而失败的情况,无论我们使用哪个 peer 都是如此。
ethrex 的全同步执行路径是批量运行区块,而非逐一运行。批量路径在批处理中的区块之间维护一个共享的内存中状态视图,计算每个区块的状态差异,依次应用它们,并在批处理结束时将 Merkle 化根与网络期望的根进行核对。批量处理是一个真正的性能优势:它将 trie 工作的成本分摊到许多区块上,并允许我们将昂贵的 Merkle-Patricia 重新计算推迟到我们有了一组一致的状态更改可以一次性应用的时候。
不过,批量处理有比逐块处理更尖锐的故障模式。如果每个区块的状态视图观察到来自同一批量中兄弟区块的脏数据(例如,一个逻辑上应该仅在一个区块结束时提交的写入泄漏到下一个区块的读取集合中),则产生的状态根是错误的,整个批次失败。这正是在 hoodi 的 443,055 区块发生的情况。
我们可以追逐具体的问题,但批量处理是乐观的,预测所有可能的跨区块交互可能不现实,因此为了两全其美,我们更改了策略:当 add_blocks_in_batch 因一个执行后错误而失败时,我们通过流水线路径(run_blocks_pipeline,crates/networking/p2p/sync/full.rs:550-573)一次一个区块地重新运行相同的范围,该路径为每个区块使用一个全新的 VM 状态,避免了跨区块缓存污染问题。
分类(is_post_execution_error,full.rs:538-548)精确地定义了触发重试的条件:GasUsedMismatch、StateRootMismatch、ReceiptsRootMismatch、RequestsHashMismatch、BlockAccessListHashMismatch、BlobGasUsedMismatch。这些都是 EVM 仅在运行完整个区块后才能得出的结论;没有一个可以仅通过检查头部/区块体预先判断。
重试是安全的,因为 add_blocks_in_batch 是全有或全无的:它在批次中每个区块都成功之前,不会将批次的状态更改写入持久化存储。crates/blockchain/blockchain.rs:2180-2295 中的实现将执行结果累积在内存中,并仅在最后调用 store_block_updates。一个失败的批次将使数据库保持与批次前完全相同的字节状态,因此流水线重试从一个干净的基状态开始。
错误过滤器是有意设窄的。执行前验证错误(头部错误、区块体格式错误、甚至在进入 EVM 之前就捕获的 Gas 不匹配)不会触发回退。切换执行模式也无济于事(区块是无效的),无论如何重试它都会在拒绝之前消耗双倍的 CPU。这里还有一点轻微的 DoS 角度:如果回退对每个 InvalidBlock 变体都触发,一个向我们提供格式错误区块的 peer 可能会迫使我们对它执行两次。窄的过滤器将回退限制为一类错误上,这类错误很可能是在批量模式下发生的误报。
配合回退机制和更稳定的头部下载后,hoodi 现在无需人为干预即可从创世块全同步到最新区块,并且在停机后追赶的节点可以自动恢复上线。
总结
这些合并的综合效果,在我们的主网节点上观察如下:
- 发现流量稳定且有界。 数据包速率保持在低数十 req/s 的水平,因此使用带宽敏感型提供商的运营商可以运行节点而不会触发滥用阈值。
- 内存池带宽与唯一交易数成正比,而非与 peer 数量成正比。 出站
GetPooledTransactions速率与入站公告速率解耦。传输中的追踪器吸收了重复项,50 毫秒的批量窗口将来自许多公告 peer 的峰值压缩为一个请求。 - 头部下载在混合 peer 池中也能顺利进行。 选择循环集中在那些一直有用的 peer 上,慢速 peer 不再阻碍轮转,并且长期有用的 peer 不会因为长期会话积累的失败而被丢弃。
- 全同步能自动从边缘情况中恢复。 批量执行的误报会回退到逐块流水线路径,因此单个坏批次不再需要运营商干预。
其中一些修复(发现速率限制、传输中的追踪器、批量执行回退)说明了在网络代码中反复出现的一种模式:一个积极的实现可以在开发和长期运行的节点上正常工作,但在负载下会产生嘈杂的流量,因为网络具有反馈循环和放大因素,这些因素直到你测量它们时才会显现。发现修复的蓄水池采样加速率限制的形状和汇集交易修复的缓冲加批量形状共享一个结构,因为底层约束是相同的:当上游向外扇出时,正确的本地响应是吸收并去重,而不是镜像回传。
在相同的表面上,路线图上还有更多内容:跨重启持久化的 peer 评分、更细粒度的发现表维护,以及批量执行路径上的缓存污染工作。操作底线已经到位:稳定的 peer 数量、平坦的数据包速率,以及无需监管即可完成的同步运行。
- 原文链接: blog.lambdaclass.com/the...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
