Vitalik:形式化验证程序的正确性
形式化验证(Formal Verification)是通过编写数学证明并由计算机自动验证程序正确性的技术。以太坊联合创始人Vitalik Buterin深入探讨了该技术在区块链、密码学和AI领域的应用,强调其在保证代码安全性、尤其是在智能合约和ZK-EVM等核心组件上的潜力。文章指出,形式化验证并非万能,存在规范遗漏、部分验证等缺陷,但通过AI辅助可大幅提升效率,形成“安全核心+边缘非安全代码”的新安全模型,有望实现防御方优势。
深入浅出谈形式化验证
深入浅出谈形式化验证
特别感谢 Yoichi Hirai、Justin Drake、Nadim Kobeissi 和 Alex Hicks 提供的反馈和审阅
在过去的几个月里,一种新的编程范式在以太坊前沿研究和开发圈子以及计算领域的许多其他角落迅速获得关注:直接在非常底层的语言(例如 EVM 字节码、汇编语言)或 Lean 中编写代码,并使用用 Lean 编写的可自动检查的数学证明来验证其正确性。
如果操作得当,这种方法既有潜力输出极其高效的代码,又比以往的程序设计方式安全得多。Yoichi Hirai 将其称为"软件开发的最终形态"。这篇文章将试图揭开这里正在发生的事情的基本面纱,说明软件形式化验证能做什么,以及在以太坊及其他领域,它的弱点和局限性在哪里。
什么是形式化验证?
形式化验证指的是编写数学定理的证明,使得这些定理可以被自动检查。为了给出一个相当简单但仍然有趣的例子,我们来看一个关于斐波那契数列的基本定理:每第三个数是偶数,其他都是奇数。
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 ...
一个简单的证明方法是归纳证明,每次向前推进三个。
首先,基础情况。设 F1 = F2 = 1,F3 = 2。通过观察,我们看到该命题("Fi 在索引为 3 的倍数时为偶数,否则为奇数")在 x = 3 之前成立。
现在,归纳情况。假设命题在 3k+3 之前成立,即我们已经知道 F3k+1、F3k+2、F3k+3 分别是奇数、奇数、偶数。我们可以计算下一组三个的奇偶性:
F3k+4 = F3k+2 + F3k+3 = 奇数 + 偶数 = 奇数
F3k+5 = F3k+3 + F3k+4 = 偶数 + 奇数 = 奇数
F3k+6 = F3k+4 + F3k+5 = 奇数 + 奇数 = 偶数
因此,我们从知道命题在 3k+3 之前成立,推进到知道命题在 3k+6 之前成立。我们可以反复应用这个推理,从而确信该规则对所有整数成立。
这个论证对人类来说是有说服力的。但如果你想证明一个复杂一百倍的东西,并且你想真的真的确定没有犯错误呢?那么,你可以制作一个让计算机信服的证明。
这就是它的样子:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-1)-- 斐波那契数列定义:fib 0 = 0, fib 1 = 1, fib 2 = 1 (索引偏移 1)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-2)def fib : Nat → Nat
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-3) | 0 => 0
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-4) | 1 => 1
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-5) | n + 2 => fib (n + 1) + fib n
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-6)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-7)-- 断言:fib (3k+1) 是奇数,fib (3k+2) 是奇数,fib (3k+3) 是偶数。
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-8)-- 等价于:从 fib 3 开始的每第三个斐波那契数是偶数。
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-9)-- 我们通过对 k 进行归纳一次性证明所有三个,因为下一个块的每个情况
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-10)-- 都从前一个块构建而来。
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-11)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-12)theorem fib_triple (k : Nat) :
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-13) fib (3 * k + 1) % 2 = 1 ∧
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-14) fib (3 * k + 2) % 2 = 1 ∧
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-15) fib (3 * k + 3) % 2 = 0 := by
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-16) induction k with
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-17) | zero => decide
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-18) | succ k ih =>
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-19) -- 将新索引重写为 (something) + 2 的形式,以便展开 fib。
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-20) refine ⟨?_, ?_, ?_⟩
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-21) · show (fib (3 * k + 3) + fib (3 * k + 2)) % 2 = 1
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-22) omega
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-23) · show (fib (3 * k + 3) + fib (3 * k + 2) + fib (3 * k + 3)) % 2 = 1
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-24) omega
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-25) · show (fib (3 * k + 3) + fib (3 * k + 2) + fib (3 * k + 3)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-26) + (fib (3 * k + 3) + fib (3 * k + 2))) % 2 = 0
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb1-27) omega
这是同样的推理,但用 Lean 表达,Lean 是一种常用于编写和验证数学证明的编程语言。
这看起来与我上面给出的“人类”证明不同,这是有充分理由的:对计算机(在旧的“计算机”意义上——一个由 if/then 语句组成的“确定性”程序,而不是 LLM)来说直观的东西,与对人类来说直观的东西截然不同。在上面的证明中,你并没有强调 fib(3k+4) = fib(3k+3) + fib(3k+2) 这一事实,而是强调 fib(3k+3) + fib(3k+2) 是奇数,而 Lean 那个名字相当宏大的 omega 策略会自动将其与它对 fib(3k+4) 定义的理解结合起来。在更复杂的证明中,有时你必须在每一步明确指定是什么数学定律允许你进行正在进行的步骤,有时会使用像 Prod.mk.inj 这样晦涩的名称。但另一方面,你可以在一步之内展开巨大的多项式表达式,并简单地通过写一行像 "omega" 或 "ring" 这样的表达式来证明其合理性。
这里的不直观和繁琐是尽管机器可验证证明存在已有近 60 年,但该领域仍然小众的很大一部分原因。但另一方面,由于 AI 的快速进步,许多以前不可能的事情现在正在迅速成为可能。
验证计算机程序
到目前为止,你可能在想:好吧,所以我们可以让计算机验证关于数学定理的证明,这样我们终于可以确定哪些关于素数或其他的疯狂新结果是正确的,哪些只是隐藏在数百页 PDF 论文中的错误。也许我们甚至能弄清楚 Shinichi Mochizuki 关于 ABC 猜想是否正确!但除了好奇心价值之外,那又怎样呢?
有许多可能的答案。但有一个对我非常重要的答案,就是验证计算机程序的正确性,特别是那些处理加密或安全相关任务的程序。毕竟,计算机程序是一个数学对象,因此证明一个计算机程序以某种方式运行是一个数学定理。
例如,假设你想证明像 Signal 这样的加密信使是否实际上是安全的。你可以写下在这种情况下“安全”在数学上意味着什么。在高级层面上,你是在证明,假设某些加密假设成立,只有拥有私钥的人才能了解消息内容的任何信息。实际上,有许多不同的安全属性很重要。
嗯,事实证明,有一个团队正在尝试确切地弄清楚这一点!下面就是他们的一个安全定理的样子:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-1)theorem passive_secrecy_le_ddh
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-2) (g : G)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-3) (adv : PassiveAdversary G SK) :
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-4) passiveSecrecyAdvantage (F := F) g adv ≤
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-5) ProbComp.boolDistAdvantage
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-6) (DiffieHellman.ddhExpReal (F := F) g (ddhReduction adv))
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb2-7) (DiffieHellman.ddhExpRand (F := F) g (ddhReduction adv))
而 Leanstral 是这样总结其含义的:
passive_secrecy_le_ddh定理是一个紧的归约,表明 X3DH 的被动消息保密性至少与随机预言模型下的 DDH 假设一样困难。如果一个敌手能够攻破 X3DH 的被动消息保密性,那么他们也可以攻破 DDH。由于 DDH 被认为是困难的,因此 X3DH 对于被动攻击也是安全的。
这个定理证明,如果一个敌手能够被动地观察 Signal 的密钥交换消息,那么他们无法以优于可忽略的概率将产生的会话密钥与随机密钥区分开来。
如果你将其与 AES 加密实现正确的证明结合起来,你就得到了 Signal 协议加密对被动攻击者安全的证明。
类似的验证项目存在,它们证明了 TLS 和其他浏览器内加密组件的安全实现。
如果你进行了端到端的形式化验证,那么你不仅仅是在证明某个协议描述在理论上是安全的,而是在证明用户运行的特定代码段在实践中是安全的。从用户的角度来看,这极大地提高了去信任化程度:为了完全信任代码,你不需要检查整个代码,你只需检查关于它所证明的声明。
现在,这里有一些重要的注意事项需要牢记,特别是关于那个至关重要的词“安全”实际上意味着什么。很容易忘记证明那些实际重要的声明。很容易发现某些情况,其中需要证明的声明没有比代码本身更简单的描述。很容易在证明中偷偷加入最终不成立的假设。也很容易决定只有系统的一部分真正需要被形式化证明,但随后仍然被其他部分(甚至是硬件)的关键错误击中。即使是 Lean 实现本身也可能有 bug。但在我们讨论所有这些烦人的细微差别之前,让我们先更深入地探讨一下,理想且正确地完成形式化验证可能带来的那种乌托邦。
用于安全性的形式化验证
计算机代码中的错误是可怕的。
当你把加密货币放入不可变的链上智能合约时,计算机代码中的错误变得更加可怕,如果代码中有 bug,朝鲜可以自动耗尽你所有的资金而你无法追索。
当这一切都被包装在零知识证明中时,计算机代码中的错误变得更加可怕,因为如果有人设法攻破了零知识证明系统,他们可以提取所有资金,而我们却不知道出了什么问题——或者更糟,不知道何时出了问题。
当我们拥有强大的 AI 模型时,比如 Claude Mythos,但再经过两年改进后,它们可以自动化发现漏洞,计算机代码中的错误变得极其可怕。

有些人正在通过倡导放弃智能合约的基本理念来应对这一现实,甚至认为网络领域可以成为防御者相对于攻击者拥有不对称优势的领域。
一些引文:
要强化一个系统,你需要花费比攻击者利用漏洞更多的 Token 来发现漏洞
以及:
我们的职业是围绕确定性代码建立的。编写它,测试它,发布它,知道它能用——但根据我的经验,这个契约正在破裂。在真正的 AI 原生公司中,最顶尖的少数运营者内部,代码库已经开始变成你相信它能工作,但概率是你无法再精确说明的东西。
这对网络安全来说将是一个暗淡的未来。对于那些关心互联网去中心化和自由的人来说,这尤其是一个极其暗淡的未来。整个密码朋克精神从根本上基于这样一个理念:在互联网上,防御者具有优势:建造一个数字“城堡”(无论是加密、签名还是证明)比摧毁一个要容易得多。如果我们失去这一点,那么互联网安全就只能来自规模经济,来自走遍世界各地追捕可能的攻击者,更普遍地说,来自支配与毁灭之间的二元选择。
我不同意,我对网络安全的未来有一个更乐观的愿景。
我认为由强大的 AI 漏洞发现带来的挑战是一个严峻的挑战,但它是一个过渡性的挑战。一旦尘埃落定,我们进入新的平衡,我们将得到比以往更有利于防御的东西。
Mozilla 同意我的观点。引用他们的话:
你可能需要重新优先考虑其他所有事情,以便将无情而专注的精力集中在这项任务上,但隧道尽头是光明的。我们为我们的团队如何迎接这一挑战感到非常自豪,其他人也会如此。我们的工作还没有完成,但我们已经转过弯,可以瞥见一个比仅仅跟上步伐好得多的未来。防御者终于有机会决定性地获胜。
...
缺陷是有限的,我们正在进入一个最终可以将它们全部找到的世界。
现在,如果你在 Mozilla 的帖子中搜索“形式化”和“验证”这两个词,你会发现两者都没有出现。网络安全的积极未来并不严格依赖于形式化验证,或者任何其他单一技术。
它依赖于什么?基本上,是这个图表:
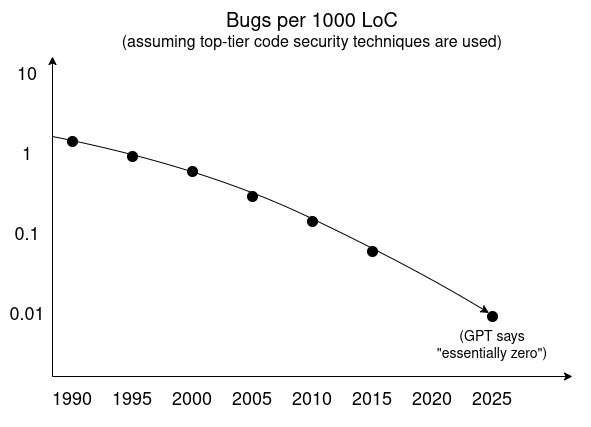
几十年来,有许多技术促成了数字的下降:
- 类型系统
- 内存安全语言
- 软件架构的改进(包括沙箱、权限,以及更普遍地明确考虑“可信计算基”与“其他代码”)
- 更好的测试方法
- 关于安全和危险编码模式的不断增长的知识体系
- 预先编写和审计的软件库的不断增长
由 AI 辅助的形式化验证,不应被视为一个全新的范式,而应被视为一种强大的加速器,加速了已经向前发展的趋势和范式。
形式化验证不是万能药。但它确实特别适用于目标比实现简单得多的情况。这在一些我们需要在以太坊的下一个主要迭代中部署的最棘手的技术中尤其如此:抗量子签名、STARK、共识算法和 ZK-EVM。
STARK 是一个非常复杂的软件。但它实现的核心安全属性很容易理解和形式化:如果你看到一个指向程序 P、输入 x 和输出 y 的哈希 H 的证明,那么要么 (i) STARK 中使用的哈希算法被攻破,要么 (ii) P(x) = y。所以我们有 Arklib 项目,它正试图创建一个完全形式化验证的 STARK 实现(另见 VCV-io,它提供了基础的预言机计算基础设施,可用于形式化验证各种其他加密协议,其中许多是 STARK 的依赖项)。它正在形式化验证各种其他加密算法,其中许多是 STARK 的依赖项。
更雄心勃勃的是 evm-asm:一个构建整个形式化验证的 EVM 实现的项目。在这里,安全属性不那么简洁:基本上,目标是证明与一个用 Lean 编写的不同 EVM 实现等价——尽管该实现可以被编写为最大化直观性和可读性,而无需考虑具体效率。有可能我们将拥有十个 EVM 实现,所有都相互可证明等价,所有都具有相同的致命缺陷,使得攻击者能够从一个他们没有权限的地址中耗尽所有 ETH。但这比今天一个 EVM 实现具有那种缺陷的可能性小得多。而另一个安全属性——其重要性我们只有在经历了痛苦之后才理解——DoS 抵抗性,是很容易指定的。
拜占庭容错共识是另一个这样的领域。在这里,形式化指定所需的安全属性也很困难,但我们曾有过人工编写的证明未能提前捕获 bug 的情况,因此现在我们有了形式化指定和证明关于 Lean 共识的属性的努力。
增值的很大一部分在于证明是真正端到端的。通常,最棘手的 bug 是交互 bug,它们位于被认为是独立的两个子系统的边界。对人类来说,很难对整个系统进行端到端的推理。但是自动化的规则检查系统可以做到。
用于效率的形式化验证
让我们再看一下 evm-asm。这是一个 EVM 实现。但这是一个直接用 RISC-V 汇编编写的 EVM 实现。
字面意思。
这是 ADD 操作码:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-1)import EvmAsm.Rv64.Program
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-2)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-3)namespace EvmAsm.Evm64
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-4)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-5)open EvmAsm.Rv64
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-6)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-7)/-- 256 位 EVM ADD:二元,弹出 2 个,推入 1 个。
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-8) Limb 0: LD, LD, ADD, SLTU (进位), SD (5 条指令).
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-9) Limbs 1-3: LD, LD, ADD, SLTU (进位1), ADD (进位入), SLTU (进位2), OR (进位出), SD (各 8 条).
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-10) 然后 ADDI sp, sp, 32.
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-11) 寄存器:x12=sp, x7=acc, x6=operand, x5=carry, x11=carry1. -/
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-12)def evm_add : Program :=
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-13) -- Limb 0 (5 条指令)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-14) LD .x7 .x12 0 ;; LD .x6 .x12 32 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-15) ADD .x7 .x7 .x6 ;; SLTU .x5 .x7 .x6 ;; SD .x12 .x7 32 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-16) -- Limb 1 (8 条指令)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-17) LD .x7 .x12 8 ;; LD .x6 .x12 40 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-18) ADD .x7 .x7 .x6 ;; SLTU .x11 .x7 .x6 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-19) ADD .x7 .x7 .x5 ;; SLTU .x6 .x7 .x5 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-20) OR' .x5 .x11 .x6 ;; SD .x12 .x7 40 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-21) -- Limb 2 (8 条指令)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-22) LD .x7 .x12 16 ;; LD .x6 .x12 48 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-23) ADD .x7 .x7 .x6 ;; SLTU .x11 .x7 .x6 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-24) ADD .x7 .x7 .x5 ;; SLTU .x6 .x7 .x5 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-25) OR' .x5 .x11 .x6 ;; SD .x12 .x7 48 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-26) -- Limb 3 (8 条指令)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-27) LD .x7 .x12 24 ;; LD .x6 .x12 56 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-28) ADD .x7 .x7 .x6 ;; SLTU .x11 .x7 .x6 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-29) ADD .x7 .x7 .x5 ;; SLTU .x6 .x7 .x5 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-30) OR' .x5 .x11 .x6 ;; SD .x12 .x7 56 ;;
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-31) -- sp 调整
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-32) ADDI .x12 .x12 32
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-33)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb3-34)end EvmAsm.Evm64
选择 RISC-V 是因为正在构建的 ZK-EVM 证明器通常通过证明 RISC-V 并将以太坊客户端编译到 RISC-V 来工作。因此,如果你有一个直接用 RISC-V 编写的 EVM 实现,这应该是你能得到的最快的实现。RISC-V 也可以在普通计算机中非常高效地模拟(而且存在 RISC-V 笔记本电脑)。当然,要真正做到端到端,你必须形式化验证 RISC-V 实现(或证明器算术化)本身,但别担心——那个也存在了。
直接编写汇编代码是我们五十年前经常做的事情。自那以后,我们已经远离了那种方式,转向使用高级语言编写代码。高级语言在效率上有所损失,但作为交换,编写代码的速度要快得多,而且重要的是,理解他人代码的速度要快得多——这是安全所必需的。
通过结合形式化验证和 AI,我们有机会“回到未来”。具体来说,我们可以让 AI 编写汇编,然后编写一个形式化证明来验证该汇编具有所需的属性。至少,所需的属性可以只是与一个为可读性优化并用某种人性化高级语言编写的实现完全等价。
不再存在一个必须在可读性和效率之间取得平衡的单一代码对象,而是有两个独立的对象:一个(汇编实现)只优化效率,考虑到其执行的具体环境的需求;另一个(安全声明或高级语言实现)只优化可读性,然后我们有一个数学证明来证明两者之间的等价性。用户可以(自动地)验证这个证明一次,然后从那时起,他们只需运行快速版本。
这是强大的,并且 Yoichi Hirai 称之为“软件开发的最终形态”是有原因的。
形式化验证不是万能的
在密码学和计算机科学中,有一个几乎与形式化方法传统本身一样古老的传统:批评形式化方法(或更普遍地依赖“证明”)的传统。这些文献充满了实际例子。让我们从更古老、更简单的密码学时代的手写证明开始,这里由 Menezes 和 Koblitz 在 2004 年批评:
1979 年,Rabin [51] 提出了一种加密函数,它……在某种意义上是“可证明”安全的,即它具有归约主义安全属性。
归约主义安全声明:能够从密文 y 中找到消息 m 的人也必须能够分解 n。...
在 Rabin 提出他的加密方案后不久,Rivest(见 [63])指出,具有讽刺意味的是,正是赋予它额外安全度的特性,在面对一种不同类型的敌手(称为“选择密文”攻击者)时会完全崩溃。也就是说,假设敌手可以以某种方式诱骗 Alice 解密一个由其自行选择的密文。那么敌手就可以按照 Sam 在前一段中使用的相同过程来分解 n。
Menezes 和 Koblitz 接着给出了更多例子。常见的模式:围绕使其更“可证明”来设计加密协议通常会使它们更不“自然”,这使得它们更有可能在设计者甚至没有考虑到的某种情况下崩溃。
现在,让我们回到机器可验证的证明和代码。这是 2011 年的一篇论文,在形式化验证的 C 编译器中发现了 bug:
我们发现的第二个 CompCert 问题由两个 bug 说明,它们导致生成了如下代码:
stwu r1, -44432(r1)
这里,正在分配一个大的 PowerPC 栈帧。问题是 16 位位移字段溢出了。CompCert 的 PPC 语义未能指定该立即数宽度的约束,假设汇编器会捕获超出范围的值。
以及一篇 2022 年的论文:
在 CompCert-KVX 中,提交 e2618b31 修复了一个 bug——"nand" 指令会被打印为 "and";"nand" 仅在罕见的 ~(a & b) 模式中被选择。该 bug 是通过编译随机生成的程序发现的。
而今天,在 2026 年,Nadim Kobeissi 描述了 Cryspen 中形式化验证软件中的漏洞:
2025 年 11 月,Filippo Valsorda 独立报告 [50] 称,libcrux-ml-dsa v0.0.3 在给定相同确定性输入的情况下,在不同平台上产生了不同的公钥和签名。该 bug 位于 _vxarq_u64 内联函数包装器(列表 1.1)中,它实现了 SHA-3 的 Keccak-f 置换中使用的 XAR 操作。回退将错误的参数传递给了移位操作,破坏了没有硬件 SHA-3 支持的 ARM64 平台上的 SHA-3 摘要。这是一个 I 类故障:该内建函数被标记为 [1],并且整个 NEON 后端没有完成的运行时正确性或安全性证明。
以及:
libcrux-psq crate [13] 实现了一个后量子预共享密钥协议。
在 decrypt_out 方法中,AES-GCM 128 解密路径调用 .unwrap()
来处理解密结果,而不是传播错误(列表 1.3)。单个格式错误的密文就会导致进程崩溃。
上述四个问题都属于两种类型:
- 只有部分代码被验证的情况(因为验证其余部分太难),结果发现未验证的代码比作者想象的更易出错(并且在更关键的方面)
- 作者忘记指定需要证明的关键属性的情况。
Nadim 的文章包含了对形式化验证故障模式的分类;他还给出了其他类型的故障模式(例如,另一个主要类型是“形式化规范本身是错误的,或者证明包含被构建系统默默接受的虚假声明”的情况)。
最后,我们可以看看软件和硬件边界上的形式化验证失败。一个常见的问题是验证侧信道攻击抵抗力。即使你有完美安全的加密来保护你的消息,如果几米外的人可以拾取电压波动并在几十万次加密后提取你的私钥,你仍然是不安全的。这里有一篇关于“差分功耗分析”的文章,这是一种现在已被充分理解的技术实例。
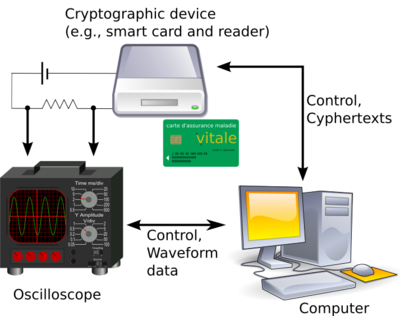
已经有人尝试证明抵御此类攻击者的安全性。然而,任何此类证明都需要某种攻击者的数学模型,你可以针对该模型证明安全性。有时,会使用“d-探测模型”:我们假设攻击者能够查询电路中位置的数量存在一个已知上限。然而,存在该模型无法捕获的泄漏形式。
一个常见的问题,在这篇文章中观察到,是过渡泄漏:如果你能观察到一个信号,该信号不依赖于某个位置上的值,而依赖于该值的变化,那么通常这足以从两个值(旧值和新值)中恢复所需信息,而不是仅仅一个值。这篇文章给出了其他泄漏形式的分类。
几十年来,这些对形式化验证的批评路线帮助形式化验证变得更好。我们现在比过去更擅长留意这些类型的问题。但即使到今天,它也不是完美的。
放大来看,这里有一个共同的线索。形式化验证是强大的。但不管那些让形式化验证听起来像能给你“可证明的正确性”的营销,所谓的“可证明的正确性”从根本上并不证明软件(或硬件)是“正确”的。
正如大多数人类所理解的,“正确”大致意味着:“事物的行为符合用户对开发者意图的理解”。
而“安全”大致意味着:“事物的行为不会以对用户利益不利的方式偏离用户的期望”。
在这两种情况下,正确性和安全性都归结为数学对象与人类意图或期望之间的比较。人类意图和期望在技术上是数学对象——毕竟,人类大脑是宇宙的一部分,遵循物理定律,如果你有足够的计算能力,你可以模拟它们。但它们是极其复杂的数学对象,计算机和我们自己都无法理解甚至阅读。出于所有实际目的,它们是黑盒;我们对自己的意图和期望有所了解,仅仅是因为我们每个人都拥有多年观察自己思想并推断他人思想的经验。
而且,由于我们不能将原始的人类意图塞进计算机,形式化验证无法证明与人类意图的比较。因此,“可证明的正确性”和“可证明的安全性”实际上并不是在证明我们人类所理解的“正确性”和“安全性”——在我们能模拟人类大脑之前,没有任何东西可以做到。
那么形式化验证在做哪些有帮助的事情呢?
我喜欢将测试套件、类型系统和形式化验证都视为实现编程语言安全性的同一种基本方法的不同实现——可能也是唯一有意义的方法。它们都关乎以不同方式冗余指定我们的意图,然后自动检查这些不同的规范是否彼此兼容。
以这段 Python 代码为例:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-1)def fib(n: int) -> int:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-2) if n < 0:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-3) raise Exception("不支持负数")
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-4) elif 0 <= n < 2:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-5) return n
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-6) else:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-7) return fib(n-1) + fib(n-2)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-8)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-9)if __name__ == '__main__':
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-10) assert [fib(i) for i in range(10)] == [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb4-11) assert fib(15) == 610
在这里,你以三种不同的方式表达了你的意图:
- 明确地,通过在代码中实现斐波那契公式
- 间接地,通过类型系统(指定输入、输出和递归中间步骤是整数)
- 通过“示例包”方法:测试用例
运行文件会根据示例检查公式。类型检查器可以验证类型是否兼容:将两个整数相加是合法的,并产生另一个整数。类型系统通常是检查物理工作中工作的好方法:如果你计算加速度,得到的结果单位是 ms 而不是 ms²,你就知道出了错。而一个“示例包”式的“定义”(测试用例是其一个实例)通常是人类处理概念更自然的方式,相比于直接明确的定义。
你指定意图的方式越多、越不同,理想情况下需要你用不同的思维方式来处理问题,那么如果所有这些表达方式都证明彼此兼容,你实际上表达了想要的东西的可能性就越大。
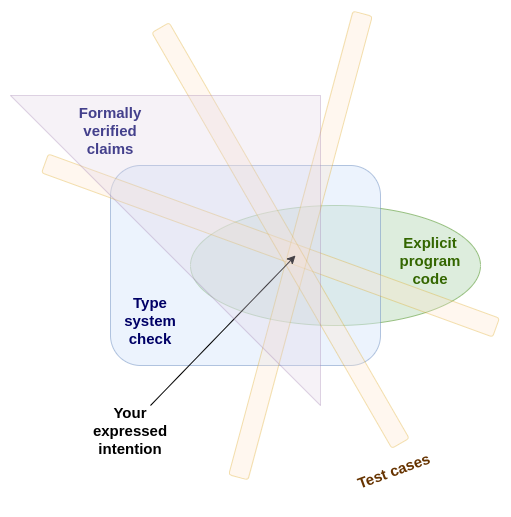
形式化验证让你可以进一步扩展这种方法。通过形式化验证,你可以以几乎任意数量的不同冗余方式来指定你的意图,程序只有在它们全部兼容时才验证通过。你可以指定一个优化的实现和一个非常低效但人类可读的实现,并验证它们是否匹配。你可以让你的十个朋友提供你的程序应该具有的数学属性列表,然后检查它是否通过了所有这些属性——如果没有,就弄清楚是程序错了还是数学属性错了。而且你可以使用 AI 极其高效地完成以上所有工作。
那么我该如何开始?
实际上,你不会自己编写证明。形式化方法没有流行起来的整个原因是大多数人无法理解如何编写这些该死的东西。你能告诉我下面的代码是什么意思吗?
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-1) /-- 辅助:带有累加器的 foldl 层面的逐点 ≤。 -/
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-2)private theorem foldl_acc_le (ds1 ds2 : List Nat) (w : Nat) (a b : Nat) (hAcc : a ≤ b)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-3) (hLE : Forall₂ (· ≤ ·) ds1 ds2) :
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-4) List.foldl (λ acc d => acc * w + d) a ds1 ≤
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-5) List.foldl (λ acc d => acc * w + d) b ds2 := by
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-6) match ds1, ds2, hLE with
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-7) | [], [], .nil => exact hAcc
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-8) | d1::ds1', d2::ds2', .cons hd htl =>
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-9) simp [List.foldl]
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-10) refine foldl_acc_le ds1' ds2' w (a * w + d1) (b * w + d2) ?_ htl
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb5-11) exact Nat.add_le_add (Nat.mul_le_mul hAcc (Nat.le_refl _)) hd
(如果你想知道,这是某个特定安全声明证明中的众多子引理之一,涉及 SPHINCS 签名的一个变体——具体来说,除非存在哈希碰撞,否则一个消息的签名将需要在至少一个哈希梯子上比任何其他消息的签名更高的值——因此需要无法从该其他签名计算出的信息。)
与其手动编写代码和证明,不如让 AI 为你编写程序(要么直接用 Lean 编写,要么如果你需要速度,就用汇编编写),并在此过程中证明任何所需的属性。
这项任务的一个好处是它本质上是自我验证的,因此你不需要监督——你可以让 AI 独自运行数小时。可能发生的最坏情况是它会原地打转而没有进展(或者,就像我的 leanstral 有一次所做的,决定通过替换要求其证明的语句来简化自己的工作)。你最后需要检查的是,被证明的语句是否与你想要的一致。
在 SPHINCS 签名变体中,这是最终的声明:
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-1)theorem wots_fullDigits_incomparable
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-2) {dig1 dig2 : List Nat} {w l1 l2 : Nat}
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-3) (hw : 0 < w)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-4) (hLen1 : dig1.length = l1) (hLen2 : dig2.length = l1)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-5) (hBound1 : ∀ d ∈ dig1, d < w) (hBound2 : ∀ d ∈ dig2, d < w)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-6) (hL2suff : l1 * (w - 1) < w ^ l2)
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-7) (hNeq : dig1 ≠ dig2) :
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-8) ¬ Forall₂ (· ≤ ·) (wotsFullDigits dig1 w l1 l2) (wotsFullDigits dig2 w l1 l2) ∧
[](https://vitalik.eth.limo/general/2026/05/18/fv.html#cb6-9) ¬ Forall₂ (· ≤ ·) (wotsFullDigits dig2 w l1 l2) (wotsFullDigits dig1 w l1 l2)
这实际上已经接近可读性的边缘了:
如果从一个哈希摘要 (dig1) 生成的数字与从另一个哈希摘要 (dig2) 生成的数字不相等
那么以下两条都不成立:
- 对于所有数字,dig1 的数字 <= dig2 的数字
- 对于所有数字,dig2 的数字 <= dig1 的数字
在通过添加校验和 (wotsFullDigits) 生成的“扩展数字”中。也就是说,不可避免地,在有些地方,dig1 扩展后的数字会更高,而在其他地方,dig2 扩展后的数字会更高。
对于使用 LLM 编写证明,我发现 Claude 是够用的,Deepseek 4 Pro 也是够用的。Leanstral,一个专门为编写 Lean 而微调的较小开源权重模型,是一个有前途的替代方案;拥有 119B 参数,每个 Token 6B 活跃,你可以在本地运行它,尽管速度较慢(我在我的笔记本上得到约 15 tok/秒)。根据基准测试,Leanstral 的表现优于大得多的通用模型:
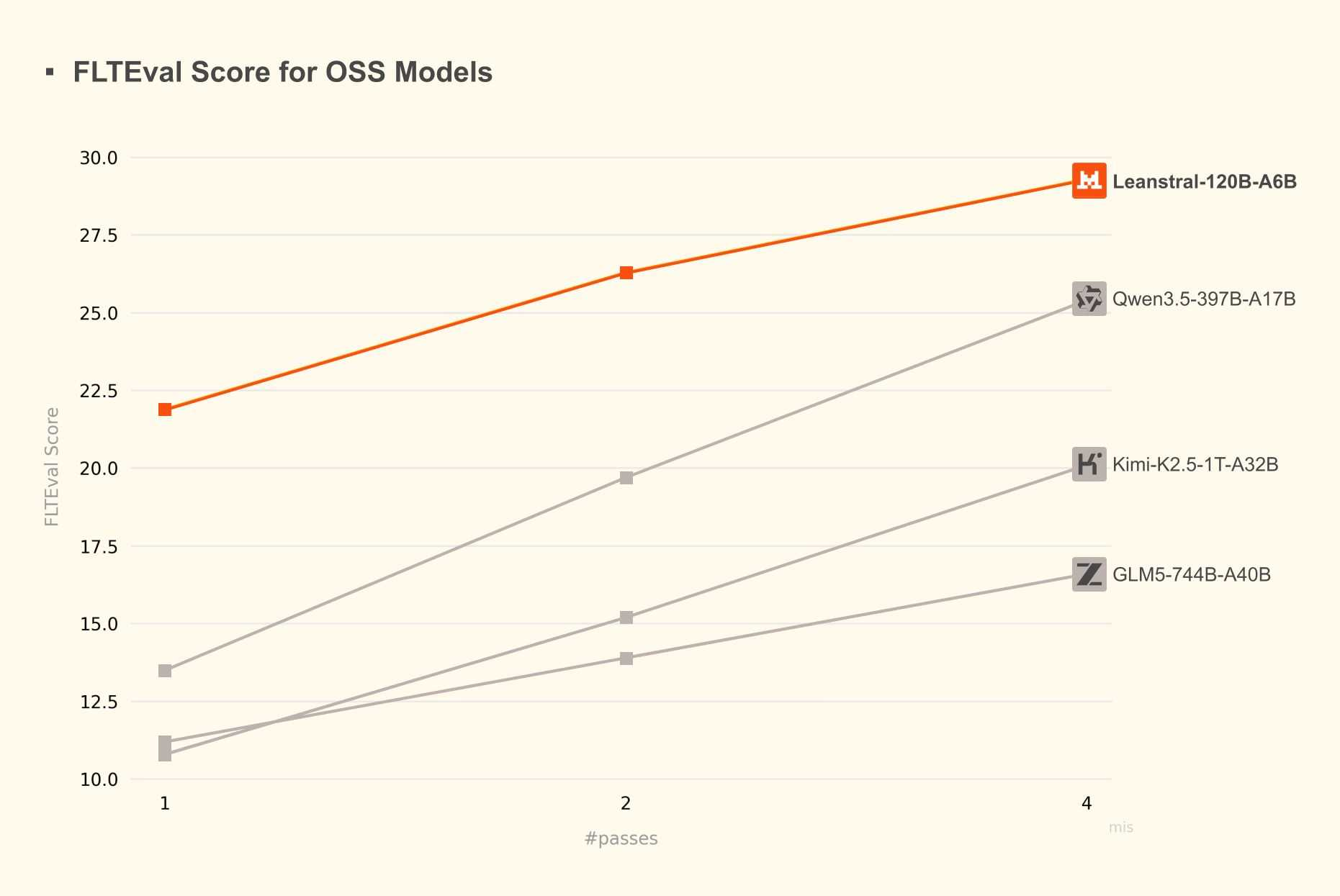
根据我目前的个人经验,它比 Deepseek 4 Pro 稍差,但仍然有效。
形式化验证不会解决我们所有的问题。但如果我们想要一个不基于每个人都信任少数强大组织的互联网安全模型,我们需要能够信任代码——包括在面对强大的 AI 对手时信任代码。AI 辅助的形式化验证让我们在做到这一点上迈出了大步。
就像区块链和 ZK-SNARK 一样,AI 和形式化验证是非常互补的技术。
区块链以牺牲隐私和可扩展性为代价,为你提供公开可验证性和抗审查性,而 ZK-SNARK 为你赢回……隐私和可扩展性(实际上,甚至比之前更多)。
AI 以牺牲准确性为代价,赋予你编写大量代码的能力,而形式化验证为你赢回……准确性(实际上,甚至比之前更多)。
默认情况下,AI 将产生大量非常草率的代码,错误数量将会增加。实际上,在某些情况下,让错误增加是正确的权衡:如果错误是轻微的,即使是有错误的软件也比没有该软件要好。但这里存在一个关于网络安全的乐观未来:软件将(继续)分裂为围绕一个‘安全核心’的‘不安全的边缘部分’。
不安全的边缘部分将在沙箱中运行,并被授予完成其工作所需的最小权限。安全核心将管理一切。如果安全核心崩溃,一切都会崩溃——你的个人数据、你的钱等等。但如果某个不安全的边缘部分崩溃,安全核心会保护你。
当涉及到安全核心时,我们不能让有错误的代码倍增。我们要积极行动,保持安全核心的小尺寸,甚至进一步缩小它。相反,我们将 AI 带来的全部额外能力用于使安全核心更加安全,以便它能够处理我们在高度数字化社会中赋予它的极高信任负担。
你的操作系统内核(或至少部分内核)将是这样一个安全核心。以太坊将是另一个。希望你所使用的硬件,至少对于所有非性能密集型的计算,将是第三个。涉及 IoT 的东西将是第四个。至少在这些安全核心中,旧的格言“错误是不可避免的,你只能努力在攻击者之前找到它们”将不再成立,取而代之的是一个更有希望的世界,在那里你获得真正的安全。但是,如果你想要将你的资产和数据交给编写得很差、可能意外地将它们全部送入黑洞的软件,嗯,你也会有那个自由。
- 原文链接: vitalik.eth.limo/general...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
