以太坊漫游指南:读懂以太坊发展路线图
以太坊的研究有很多值得关注的地方,但所有的一切最终都编织成一个总体目标——在不牺牲去中心化验证的情况下扩展计算。通过简单的去中心化验证,以太坊维持者非常高的安全性,而 Rollups 继承了以太坊 L1 的安全性。以太坊还提供结算和数据可用性,允许 Rollups 实现扩容。这里的所有研究最终都是为了优化这两个角色,同时使得验证这条链变得比以往任何时候都更容易。

撰文:Jon Charbonneau,Delphi Digital 分析师
来源:DeFi 之道
关键要点
- 以太坊是唯一建立可扩展的统一结算和数据可用层的主要协议;
- Rollups 在利用以太坊安全性的同时扩展计算;
- 所有道路都通向中心化的区块生产、去中心化&无须信任的区块验证和抗审查的终局;
- 诸如区块提议者-构建者分离 (PBS) 和弱无状态性 (weak statelessness) 等创新开启了这种权力 (构建和验证) 的分离,以在不牺牲安全性或去中心化的情况下实现可扩展性;
- MEV 现在处于核心重要位置,以太坊计划了许多设计来减轻 MEV 的危害,防止 MEV 的中心化化倾向;
- Danksharding 结合了多个前沿研究途径,从而为以太坊以 Rollup 为中心的路线图提供可扩展的基础层;
- 我预计 danksharding 将在我们有生之年实现。
引言
自从以太坊联合创始人 Vitalik Buterin 表示今天出生的人有 50% -75% 的几率能活到 3000 年,他希望能长生不老,我就一直对合并的时间持怀疑态度。但无论如何,让我们看看展望一下以太坊雄心勃勃的路线图吧。

这不是一篇速成文章。如果你想对以太坊雄心勃勃的路线图有一个广泛而细致的理解——请给我一个小时的时间,我将为你节省几个月的工作。
以太坊的研究有很多值得关注的地方,但所有的一切最终都编织成一个总体目标—— 在不牺牲去中心化验证的情况下扩展计算 。
通过简单的去中心化验证,以太坊维持者非常高的安全性,而 Rollups 继承了以太坊 L1 的安全性。以太坊还提供结算和数据可用性,允许 Rollups 实现扩容 。这里的所有研究最终都是为了优化这两个角色,同时使得验证这条链变得比以往任何时候都更容易。
以下是一些缩略语,这些术语会在本文中出现 N 次:
- DA – 数据可用性 (Data Availability)
- DAS – 数据可用性抽样 (Data Availability Sampling)
- PBS – 提议者-构建者分离 (Proposer-builder Separation)
- PDS – Proto-danksharding
- DS – Danksharding
- PoW – 工作量证明 (Proof of Work)
- PoS – 权益证明 (Proof of Stake)
第 I 部分:通往 Danksharding 之路
希望你现在已经知晓了以太坊已经转向了 以 Rollup 为中心的路线图 。以太坊将不会再有执行分片 (execution shards) ,而是将针对需要大量数据的 Rollups 进行优化。这是通过数据分片 (data sharding) 来实现的。
以太坊共识层不会解释分片数据,它的任务是 确保数据是可用的 。
在文本中,我将假设你熟悉一些基本概念,比如 Rollups、欺诈证明和 ZK 证明,以及DA(数据可用性) 的重要性。
1)最初的数据分片设计:单独的分片区块提议者
这个小节描述的设计 已经废弃了 ,但它对于我们了解背景信息是有价值的。为了简单起见,我将这种设计称为“分片1.0”。
以太坊 64 个分片的每个分片区块都有单独的区块提议者和委员会,他们通过随机的方式从验证者集中选出来被分配至各个分片链中。他们分别验证自己所在的分片的数据的可用性。起初这不会是 DAS (数据可用性抽样),而是依赖于每个分片的诚实大多数验证者来完全下载该数据。
这种设计带来了不必要的复杂性、更糟糕的用户体验和攻击向量。在分片之间洗牌 (打乱) 验证者是很棘手的。
如果不引入非常紧密的同步假设,就很难保证投票将在单个 slot 内完成。信标区块的提议者需要收集所有独立委员会的投票,而这可能会有延迟。
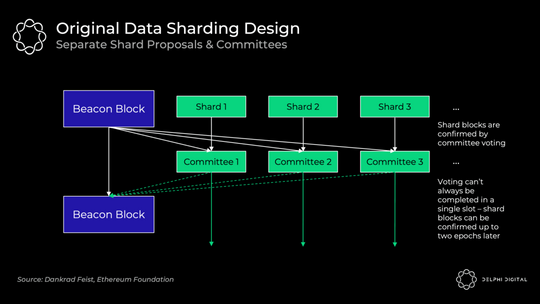
Danksharding (简称 DS) 则完全不同。验证者执行 DAS (数据可用性抽样) 以确认所有数据都是可用的 ( 不会再有单独的分片委员会 )。专门的区块构建者 (builder) 会负责创建一个 大区块 ,该区块会对信标区块和所有的分片数据一起进行确认。因此,Proto-danksharding (简称 PDS) 对于 DS 保持去中心化是很有必要的 (因为构建这样的大区块是资源密集型的)。

2)数据可用性抽样 (DAS)
Rollups 会发布大量的数据,但是我们不希望给节点带来下载所有这些数据的负担,因为这将意味着需要很高的资源,从而损害网络节点的去中心化。
相反, DAS 允许节点 (甚至轻客户端) 能够 在无须下载所有这些数据的情况下 ,轻松、安全地验证这些数据的可用性 。
- 简单的解决方案:只是检查每个区块的一些随机数据块。如果检查合格,节点就对该区块进行签名。但如果节点没有检查到那笔有关你将 ETH 发送给 Sifu 的交易,那么资金就不再安全了。
- 聪明的解决方案:首先对数据进行纠删码。使用 Reed-Solomon 代码扩展该数据。这意味着数据被插值为一个多项式,然后我们在许多额外的地方对该多项式进行求值。这很难懂,所以让我们来分析一下。
对那些忘记数学课的人来说,这是一堂快速的课。(我保证这不会是非常可怕的数学——我不得不看一些 Khan Academy 的视频来写这些部分,但我现在都弄懂了)。
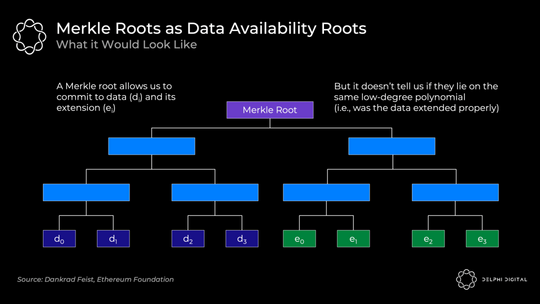
多项式 (Polynomial) 是对任何有限数量的单项式进行求和的表达式。多项式的“次数”(degree) 是指多项式中次数最高的单项式的次数。例如,2ab+b-1 是一个由 2ab、b 和 -1 这三个单项式组成的多项式 ,我们把这三个单项式叫做该多项式的“项”,因此这个多项式就是一个“三项式”;且由于 2ab 这个单项式的次数最高 (次数为 2),故这个三项式是“二次三项式”。你可以从位于该多项式上的任何 d+1 坐标重建任何 d 次多项式。
现在举一个具体的例子。下面我们有四个数据组块(d0 到 d3)。这些数据组块可以映射到给定点的多项式 f (X) 的求值。例如,f (0) = d0。现在你找到了贯穿这些求值的最小次数多项式。由于这是四个组块,我们可以找到三次多项式。然后,我们可以扩展此数据以添加四个沿同一多项式的求值(e0 到 e3)。

记住多项式的关键属性:我们可以从任意四个点重构它,而不仅仅是最初的四个数据块。
回到我们的 DAS。现在我们只需要确保任意 50% (4/8) 纠删码数据是可用的。由此,我们可以重构整个区块。
因此, 攻击者必须隐藏区块的 >50% 数据,才能成功地欺骗 DAS 节点,以使节点认为数据是可用的(但实际上是不可用的)。
在许多成功的随机抽样之后,<50% 的数据是可用的概率非常小。如果我们成功地对纠删码数据采样 30 次,那么 <50% 可用的概率是 2-30。
3)KZG 承诺
好的,所以我们做了一堆随机样本,它们都是可用的。但我们还有另一个问题——数据擦除编码是否正确?否则,可能区块生产者在扩展区块时只是添加了 50% 的垃圾,而我们对废话进行了采样。在这种情况下,我们实际上将无法重建数据。
通常我们只是通过使用 Merkle 根来提交大量数据。这对于证明集合中包含某些数据是有效的。
但是,我们还需要知道所有原始数据和扩展数据都位于同一个低次多项式上。Merkle 根并不能证明这一点。所以如果你使用这个方案,你还需要欺诈证明,以防万一做错了。
好的,所以我们做了一堆随机样本,它们都是可用的。但我们还有另一个问题 —— 数据擦除编码是否正确?否则,可能区块生产者在扩展区块时只是添加了 50% 的垃圾,而我们对废话进行了采样。在这种情况下,我们实际上将无法重建数据。
通常我们只是通过使用 Merkle 根来提交大量数据。这对于证明集合中包含某些数据是有效的。
但是,我们还需要知道所有原始数据和扩展数据都位于同一个低次多项式上。Merkle 根并不能证明这一点。所以如果你使用这个方案,你还需要欺诈证明,以防万一做错了。

回到 KZG 承诺 —— 这是一种多项式承诺方案。
承诺方案只是一种可证明承诺某些值的加密方式。最好的比喻是把一封信放在一个锁着的盒子里,然后交给别人。这封信一旦进去就无法更改,但可以用钥匙打开并证明。你提交的新就是承诺,钥匙就是证明。
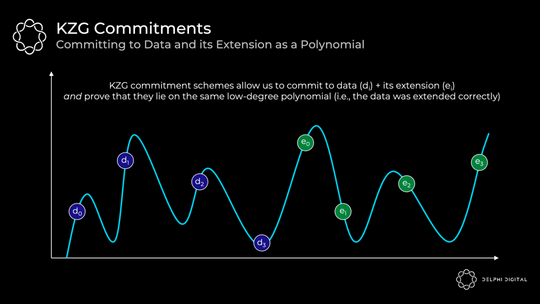
在我们的例子中,我们将所有原始数据和扩展数据映射到 X,Y 网格上,然后找到穿过它们的最小次数多项式(这个过程称为拉格朗日插值)。这个多项式就是证明者将承诺的:
以下是关键点:
-
我们有一个「多项式」f(X)
-
证明者对多项式做出「承诺」C (f)
- 这依赖于具有可信设置的椭圆曲线密码学。有关其工作原理的更多详细信息,请参阅 Bartek 的一个很棒的帖子
-
对于该多项式的任何「评估」y = f(z),证明者可以计算「证明」π(f,z)
-
给定承诺 C(f)、证明 π(f,z)、任何位置 z 以及多项式在 z 处的评估 y,验证者可以确认确实 f (z) = y
-
解释:证明者将这些片段提供给任何验证者,然后验证者可以确认某个点的评估(其中评估代表基础数据)正确地位于承诺的多项式上
-
这证明原始数据被正确扩展,因为所有评估都位于相同的多项式上
-
请注意,验证者不需要多项式 f (X)
-
重要属性 - 这具有 O(1) 承诺大小、O(1) 证明大小和 O(1) 验证时间。即使对于证明者,承诺和证明生成也仅在 O(d) 上进行扩展,其中 d 是多项式的次数
-
解释:即使 n(X 中的值的数量)增加(即,随着数据集随着更大的分片 blob 而增加)- 承诺和证明保持不变的大小,并且验证需要持续的努力
-
承诺 C(f) 和证明 π(f,z) 都只是配对友好曲线上的一个椭圆曲线元素(这将使用 BL12-381)。在这种情况下,它们每个只有 48 个字节(非常小)
-
因此,证明者提交大量原始数据和扩展数据(表示多项式的多次评估)仍然只有 48 个字节,证明也只有 48 个字节
-
TLDR–这是高度可扩展的
然后,KZG 根(多项式承诺)类似于 Merkle 根(这是一个向量承诺):
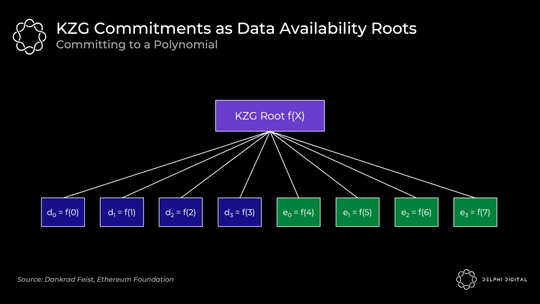
原始数据是在 f (0) 到 f(3) 位置处计算的多项式 f (X),然后我们通过计算 f (4) 到 f(7) 处的多项式来扩展它。所有点 f(0) 到 f(7) 都保证在同一个多项式上。
底线:DAS 允许我们检查纠删码数据是否可用。KZG 的承诺向我们证明了原始数据得到了适当的扩展并承诺了所有这些。

干得好,这就是今天的代数知识。
4) KZG 承诺与欺诈证明
既然我们了解了 KZG 的工作原理,请退后一步比较这两种方法。
KZG 的缺点 —— 它不是后量子安全的,它需要一个可信的设置。这些并不令人担忧。STARK 提供了一种后量子替代方案,而可信设置(开放参与)只需要一个诚实的参与者。
KZG 的优势 - 比欺诈证明设置的延迟更低(尽管如前所述,GASPER 无论如何都不会具有快速确定性),并且它确保了正确的擦除编码,而不会引入欺诈证明中固有的同步和诚实的少数假设。
然而,考虑到以太坊仍然会重新引入这些假设来进行区块重建,所以你实际上并没有删除它们。DA 层总是需要为最初提供块的场景进行规划,但随后节点需要相互通信以将其重新组合在一起。这种重建需要两个假设:
- 您有足够的节点(轻节点或全节点)对数据进行采样,这样它们就足以将它们重新组合在一起。这是一个相当弱且不可避免的诚实少数假设,因此不是一个大问题。
- 重新引入同步假设 —— 节点需要能够在一段时间内进行通信才能将其重新组合在一起。
以太坊验证器在 PDS 中完全下载分片 blob,并且使用 DS,他们将只执行 DAS(下载分配的行和列)。Celestia 将要求验证者下载整个区块。
请注意,无论哪种情况,我们都需要同步假设来进行重建。如果该区块仅部分可用,则完整节点必须与其他节点通信以将其重新组合在一起。
如果 Celestia 想要从要求验证者下载全部数据转变为只执行 DAS(尽管目前尚未计划这种转变),那么 KZG 的延迟优势就会显现出来。然后,他们还需要实施 KZG 承诺 —— 等待欺诈证明将意味着显着增加区块间隔,并且验证者投票支持错误编码区块的风险会非常高。
我推荐以下内容以更深入地探索 KZG 承诺的工作方式:
- 椭圆曲线密码学(相对容易理解)入门
- 探索椭圆曲线配对–Vitalik
- KZG 多项式承诺–Dankrad
- 受信任的设置如何工作?–Vitalik
5) 协议内提议者 - 构建者分离
今天的共识节点(矿工)和合并后的(验证者)扮演两个角色。他们构建实际的区块,然后将其提议给其他验证它的共识节点。矿工通过在前一个区块的基础上进行「投票」,在合并之后,验证者将直接对区块的有效或无效进行投票。
PBS 将它们分开 —— 它明确地创建了一个新的协议内构建者角色。专业的构建者将把区块放在一起并竞标提议者(验证者)来选择他们的区块。这与 MEV 的中心化力量作斗争。
回想一下 Vitalik 的《终局之战》一文 —— 所有道路都通向中心化区块生产,具有去信任和去中心化的验证。PBS 对此进行了编纂。我们需要一个诚实的构建者来为网络提供服务以提高活跃度和抗审查能力(需要两个来实现有效的市场),但验证者集需要诚实的多数。PBS 使提议者角色尽可能简单地支持验证者去中心化。
构建者收到优先费用小费以及他们可以提取的任何 MEV。在一个有效的市场中,有竞争力的构建者将竞标到他们可以从区块中提取的全部价值(减去他们的摊销成本,如强大的硬件等)。所有价值都渗透到去中心化的验证器集 —— 正是我们想要的。
确切的 PBS 实现仍在讨论中,但 two-slot PBS 可能如下所示:
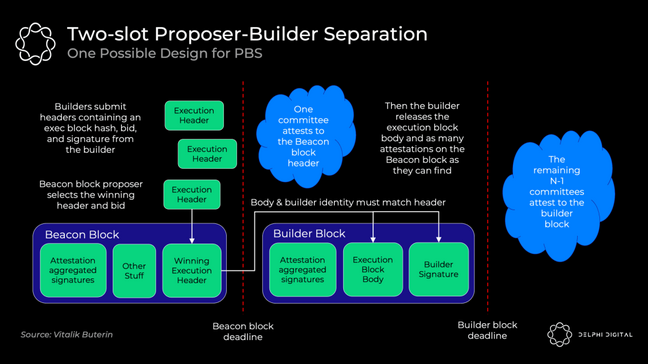
- 构建者使用他们的出价承诺区块头
- 信标区块提议者选择获胜的区块头和出价。即使构建者未能生产出 body,投标人也将无条件获得中标
- 证明人委员会确认获胜标头
- 构建者公布获胜的 body
- 独立的证明人委员会选举获胜的机构(如果获胜的构建者不同意,则投票决定它缺席)
提议者是使用标准 RANDAO 机制从验证者集中选择的。然后我们使用承诺 - 显示(commit-reveal)方案,在委员会确认区块头之前,不会显示完整的区块 body。
commit-reveal 更有效(发送大约数百个完整的区块 body 可能会压倒 p2 p 层的带宽),并且它还可以防止 MEV 窃取。如果构建者要提交他们的完整区块,另一个构建者可以看到它,找出那个策略,合并它,并快速发布一个更好的区块。此外,成熟的提议者可以检测使用的 MEV 策略并复制它,而无需补偿构建者。如果这种 MEV 窃取成为平衡,它将激励合并构建者和提议者,因此我们使用 commit-reveal 来避免这种情况。
在提议者选出获胜区块头后,委员会确认并固定在分叉选择规则中。然后,获胜的建造者发布他们获胜的完整「构建者区块」body。如果及时发布,下届委员会将作证。如果他们未能及时发布,他们仍然向提议者支付全部出价(并失去所有 MEV 和费用)。这种无条件的支付消除了提议者信任构建者的需要。
这种「双时隙(two-slot)」设计的缺点是延迟。合并后的区块将是固定的 12 秒,所以如果我们不想引入任何新的假设,这里我们需要 24 秒来获得完整的区块时间(两个 12 秒的时隙)。每个时隙 8 秒(16 秒的出块时间)似乎是一个安全的折衷方案,尽管研究正在进行中。
6) 抗审查名单 (crList)
不幸的是,PBS 赋予了构建者更高的审查交易能力。也许构建者只是不喜欢你,所以他们忽略了你的交易。也许他们的工作非常出色,以至于所有其他构建者都放弃了,或者他们只是因为他们真的不喜欢你而对区块出价过高。

crLists 对这种能力进行了检查。确切的实现又是一个开放的设计空间,但「混合 PBS」似乎是最受欢迎的。提议者指定他们在内存池中看到的所有合格交易的列表,构建者将被强制包含它们(除非区块已满):
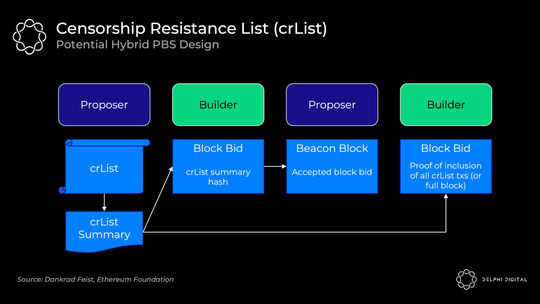
- 提议者发布一个 crList 和 crList 摘要,其中包括所有符合条件的交易
- 构建者创建一个提议的区块 body,然后提交一个竞标,其中包括 crList 摘要的哈希,证明他们已经看到它
- 提议者接受中标构建者的出价和区块头(他们还没有看到 body)
- 构建者发布他们的区块并包含他们已包含来自 crList 的所有交易或该区块已满的证明。否则分叉选择规则不会接受该块
- 证明者检查已发布的 body 的有效性
这里仍有重要问题需要解决。例如,这里的主导经济策略是让提议者提交一个空列表。只要出价最高,即使是审查构建者也能赢得拍卖。有一些想法可以解决这个问题和其他问题,但只是强调这里的设计并不是一成不变的。
7) 二维 KZG 方案
我们看到了 KZG 承诺如何让我们承诺数据并证明它被正确扩展。但是,我简化了以太坊的实际操作。它不会在单个 KZG 承诺中承诺所有数据 —— 单个区块将使用许多 KZG 承诺。
我们已经有一个专门的构建者,那么为什么不让他们创造一个巨大的 KZG 承诺呢?问题是这需要一个强大的超级节点来重建。我们可以接受初始构建的超级节点要求,但我们需要避免这里的重建假设。我们需要资源较少的实体来处理重建,并将其拆分为许多 KZG 承诺使这变得可行。考虑到手头的数据量,重建甚至可能相当普遍,或者是本设计中的基本情况假设。
为了使重建更容易,每个区块将包含在 m 个 KZG 承诺中编码的 m 个分片 blob。天真地这样做会导致大量的采样 —— 你会在每个分片 blob 上执行 DAS 以知道它都是可用的(m*k 个样本,其中 k 是每个 blob 的样本数)。
相反,以太坊将使用 2 D KZG 方案。我们再次使用 Reed-Solomon 代码将 m 承诺扩展到 2 m 承诺:
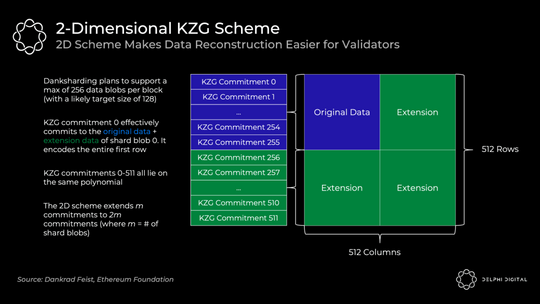
我们通过扩展与 0-255 位于相同多项式上的额外 KZG 承诺(此处为 256-511)使其成为 2 D 方案。现在我们只需对上表进行 DAS,以确保所有分片的数据可用性。
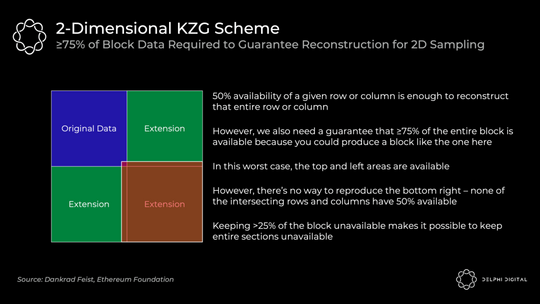
≥75% 的数据可用的 2 D 采样要求(与之前的 50% 相比)意味着我们做的固定样本数量要多一些。在我提到简单一维方案中 DAS 的 30 个样本之前,但这将需要 75 个样本来确保重建可用区块的相同概率几率。
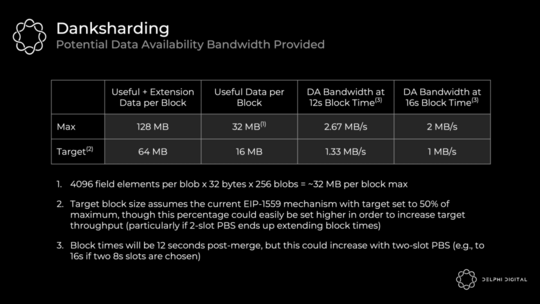
分片 1.0(具有一维 KZG 承诺方案)只需要 30 个样本,但如果您想检查 1920 个样本的完整 DA,则需要对 64 个分片进行采样。每个样本为 512 B,因此这需要:
(512 B x 64 分片 x 30 个样本)/16 秒 = 60 KB/s 带宽
实际上,验证者只是在没有单独检查所有分片的情况下被洗牌。
现在,使用 2 D KZG 承诺方案的组合区块使得检查完整 DA 变得微不足道。它只需要单个统一区块的 75 个样本:
(512 B x 1 块 x 75 个样本)/16 秒 = 2.5 KB/s 带宽
8) Danksharding
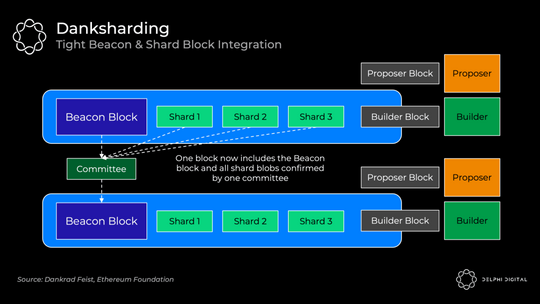
PBS 最初的设计目的是削弱 MEV 在验证器集上的集中力。然而,Dankrad 最近利用了这种设计,意识到它解锁了一个更好的分片结构 ——DS。
DS 利用专门的构建者来创建信标链执行区块和分片的更紧密集成。我们现在有一个构建者一起创建整个区块,一个提议者和一个委员会。如果没有 PBS,DS 将是不可行的 —— 常规验证者无法处理充满 Rollup 数据 blob 的区块的巨大带宽:
分片 1.0 包括 64 个独立的委员会和提议者,因此每个分片都可能单独不可用。这里更紧密的集成使我们能够一次性确保 DA。数据仍然在幕后「分片」,但从实际的角度来看,danksharding 开始感觉更像是大区块,这很棒。
9) Danksharding–诚实的多数验证
验证者证明数据可用如下:
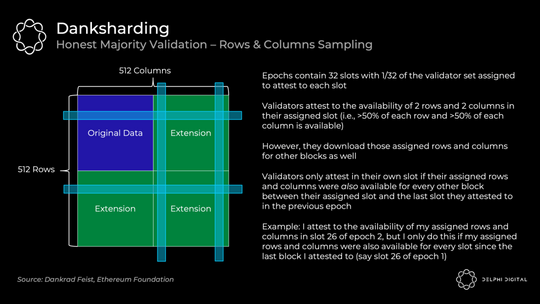
这依赖于诚实的大多数验证者 —— 作为一个单独的验证者,我的列和行可用并不足以让我在统计上确信整个区块可用。这取决于诚实的大多数人说它是。去中心化验证很重要。
请注意,这与我们之前讨论的 75 个随机样本不同。私人随机抽样是资源匮乏的个人能够轻松检查可用性的方式(例如,我可以运行 DAS 轻节点并知道该区块可用)。但是,验证者将继续使用行和列方法来检查可用性和引导区块重建。
10) Danksharding -- 重构
只要单个行或列的 50% 可用,那么采样验证器就可以轻松地对其进行完全重建。当他们重建行 / 列中丢失的任何区块时,他们将这些区块重新分配到正交线。这有助于其他验证器根据需要从相交的行和列中重建任何丢失的区块。
这里重建可用区块的安全假设是:
- 足够多的节点来执行样本请求,以便它们共同拥有足够的数据来重建区块
- 广播各自区块的节点之间的同步假设
那么,多少节点就足够了?粗略估计大约有 64,000 个个体实例(到目前为止,目前已超过 380,000 个)。这也是一个非常悲观的计算,它假设由同一验证器运行的节点中没有交叉(这与节点被限制为 32 个 ETH 实例的情况相去甚远)。
如果您对超过 2 行和列进行采样,则由于交叉,您可以集体检索它们的几率会增加。这开始以二次方的方式扩展 —— 如果验证者运行 10 或 100 个验证者,则 64,000 个可能会减少几个数量级。
如果在线验证器的数量开始变得异常低,可以设置 DS 以自动减少分片数据 blob 计数。因此,安全假设将降低到安全水平。
11) Danksharding–私人随机抽样的恶意多数安全
我们看到 DS 验证依赖于诚实的多数来证明区块。作为个人,我无法通过仅下载几行和几列来向自己证明一个区块可用。但是,私人随机抽样可以在不信任任何人的情况下给我这种保证。如前所述,这是节点查验这 75 个随机样本的地方。

DS 最初不会包含私有随机抽样,因为这在网络方面是一个非常难以解决的问题(PSA:也许他们实际上可以在这里使用你的帮助!)。
请注意,「私有」很重要,因为如果攻击者对您进行了去匿名化,他们就能够欺骗少量的采样节点。他们可以只返回您请求的确切区块并保留其余部分。因此,您不会仅从自己的抽样中知道所有数据都是可用的。
12) Danksharding–关键要点
除了是一个甜美的名字,DS 也非常令人兴奋。它最终实现了以太坊统一结算和 DA 层的愿景。Beacon 区块和分片的这种紧密耦合本质上是假装没有被分片。
事实上,让我们定义为什么它甚至被认为是「分片」。「分片」的唯一残余就是验证者不负责下载所有数据。而已。
所以如果你现在质疑这是否真的仍然是分片,你并没有疯。这种区别就是为什么 PDS(我们将很快介绍)不被视为「分片」的原因(即使它的名称中有「分片」,是的,我知道这很令人困惑)。PDS 要求每个验证者完全下载所有分片 blob,以证明它们的可用性。然后 DS 引入了抽样,因此各个验证者只下载其中的一部分。

幸运的是,最小分片意味着比分片 1.0 更简单的设计(交付速度如此之快,对吧?)。简化来讲,包括:
- 与分片 1.0 规范相比,DS 规范中的代码可能少了数百行(客户端少了数千行)
- 没有分片委员会基础设施,委员会只需要在主链上投票
- 没有跟踪单独的分片 blob 确认,现在它们都在主链中得到确认,或者它们没有
这样做的一个很好的结果是数据的合并收费市场。由不同的提议者制作的具有不同区块的分片 1.0 会分散这一点。
分片委员会的取消也加强了反贿赂。DS 验证人每个 epoch 对整个区块进行一次投票,因此数据立即得到整个验证人集的 1/32 的确认(每个 epoch 32 个 slot)。分片 1.0 验证者也在每个 epoch 投票一次,但每个分片都有自己的委员会被改组。因此,每个分片仅由验证器集的 1/2048 确认(1/32 分为 64 个分片)。
如前所述,与 2D KZG 承诺方案的组合区块也使 DAS 更加高效。分片 1.0 需要 60 KB/s 的带宽来检查所有分片的完整 DA。DS 只需要 2.5 KB/s。
DS 还存在另一个令人兴奋的可能性 ——ZK-rollups 和 L1 以太坊执行之间的同步调用。来自分片 blob 的事务可以立即确认并写入 L1,因为一切都在同一个信标链区块中生成。由于单独的分片确认,分片 1.0 将消除这种可能性。这允许一个令人兴奋的设计空间,这对于共享流动性(例如 dAMM)之类的东西可能非常有价值。
模块化基础层可以优雅地扩展 —— 更多的去中心化会带来更多的扩展。这与我们今天看到的根本不同。向 DA 层添加更多节点可以让您安全地增加数据吞吐量(即,有更多的空间让 rollup 存在于顶部)。
区块链的可扩展性仍然存在限制,但我们可以将数量级提高到比我们今天看到的任何东西都要高。安全且可扩展的基础层允许执行在它们之上激增。随着时间的推移,数据存储和带宽的改进也将允许更高的数据吞吐量。
超越此处设想的 DA 吞吐量肯定是有可能的,但很难说这个最大值最终会在哪里。没有明确的红线,而是一些假设会开始让人感到不舒服的区域:
- 数据存储 —— 这与 DA 与数据可检索性有关。共识层的作用不是无限期地保证数据的可检索性。它的作用是让它在足够长的时间内可用,以便任何关心下载它的人都可以,满足我们的安全假设。然后它会被转储到任何地方 —— 这很舒服,因为历史是 N 信任假设中的 1,而且我们实际上并没有在宏伟的计划中谈论那么多数据。随着吞吐量增加几个数量级,这可能会在几年后进入令人不安的领域。
- 验证者 ——DAS 需要足够多的节点来共同重建区块。否则,攻击者可能会等待,只响应他们收到的查询。如果提供的这些查询不足以重建区块,那么攻击者可以保留其余的,我们就不走运了。为了安全地增加吞吐量,我们需要添加更多的 DAS 节点或增加它们的数据带宽需求。这不是这里讨论的吞吐量的问题。但是,如果吞吐量比这种设计进一步增加几个数量级,这可能会让人感到不舒服。
请注意,构建者不是瓶颈。您需要为 32 MB 的数据快速生成 KZG 证明,因此需要 GPU 或相当强大的 CPU 以及至少 2.5 GBit/s 的带宽。无论如何,这是一个专门的角色,对他们来说这是一个可以忽略不计的业务成本。

13) Proto-danksharding (EIP-4844)
DS 很棒,但我们必须要有耐心。PDS 旨在帮助我们渡过难关 —— 它在加快的时间线(针对上海硬分叉)上对 DS 实施必要的前向兼容步骤,以在此期间提供数量级的扩展。但是,它实际上还没有实现数据分片(即验证者需要单独下载所有数据)。
今天的 Rollups 使用 L1「calldata」进行存储,它永远存在于链上。然而,Rollup 只需要一段合理的时间段内的 DA,这样任何有兴趣的人都有足够的时间下载它。
EIP-4844 引入了新的支持 blob 的事务格式,Rollup 将用于未来的数据存储。Blob 携带大量数据(~125 KB),它们比类似数量的 calldata 便宜得多。然后在一个月后从节点中删除数据 blob,这会降低存储需求。这是足够的时间来满足我们的 DA 安全假设。

当前的以太坊区块通常平均约为 90 KB(调用数据约为其中的 10 KB)。PDS 为 blob 解锁了更多的 DA 带宽(目标~1 MB 和最大~2 MB),因为它们会在一个月后被修剪。它们不会成为节点上的永久拖累。
一个 blob 是一个由 4096 个字段元素组成的向量,每个字段元素为 32 个字节。PDS 允许每个区块最多 16 个,而 DS 将增加到 256 个。
PDS DA 带宽 = 4096 x 32 x 16 = 每区块 2 MiB,目标为 1 MiB
DS DA 带宽 = 4096 x 32 x 256 = 每区块 32 MiB,目标为 16 MiB
每一步都有数量级的扩展。PDS 仍然需要共识节点来完全下载数据,所以比较保守。DS 在验证器之间分配存储和传播数据的负载。
以下是 EIP-4844 在通往 DS 的道路上引入的一些好东西:
- 携带数据 blob 的事务格式
- KZG 对 blob 的承诺
- DS 所需的所有执行层逻辑
- DS 所需的所有执行 / 共识交叉验证逻辑
- BeaconBlock 验证和 DAS blob 之间的层分离
- DS 所需的大部分 BeaconBlock 逻辑
- blob 的自调整独立 gas 价格(具有指数定价规则的多维 EIP-1559)
然后 DS 会进一步添加:
- PBS
- 数据采集系统
- 2 D KZG 方案
- 每个验证者的托管证明或类似的协议内要求,以验证每个区块中分片数据的特定部分的可用性(可能大约一个月)
- 请注意,这些数据 blob 是作为执行链上的一种新事务类型引入的,但它们不会给执行端带来额外的要求。EVM 仅查看附加到 blob 的承诺。使用 EIP-4844 进行的执行层更改也与 DS 向前兼容,并且在这方面不需要更多的更改。然后从 PDS 升级到 DS 只需要更改共识层。
数据 blob 由 PDS 中的共识客户端完全下载。现在,在 Beacon 区块体中引用了 blob,但未完全编码。不是将全部内容嵌入正文中,而是单独传播 blob 的内容,作为「sidecar」。每个区块有一个 blob sidecar,在 PDS 中完全下载,然后使用 DS 验证器将在其上执行 DAS。
我们之前讨论了如何使用 KZG 多项式承诺来提交 blob。然而,EIP-4844 并没有直接使用 KZG,而是实现了我们实际使用的东西 —— 它的版本化哈希。这是一个 0 x01 字节(代表这个版本),后跟 KZG 的 SHA256 哈希的最后 31 个字节。
我们这样做是为了更容易实现 EVM 兼容性和前向兼容性:
- EVM 兼容性–KZG 承诺是 48 字节,而 EVM 更自然地使用 32 字节值
- 前向兼容性 —— 如果我们从 KZG 切换到其他东西(STARKs 可用于抗量子),这些承诺可以继续为 32 字节
PDS 最终创建了一个定制的数据层 —— 数据 blob 将拥有自己独特的费用市场,具有单独的浮动 gas 价格和限制。因此,即使某个 NFT 项目在 L1 上出售一堆猴子土地,您的 Rollup 数据成本也不会上升(尽管证明结算成本会上升)。这承认今天任何 Rollup 的主要成本是将他们的数据发布到 L1(而不是证明)。
gas 费市场保持不变,数据 blob 被添加为新市场:
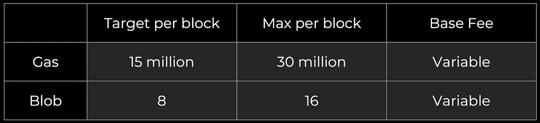
blob 费用以 gas 收取,但它是基于其自己的 EIP-1559 机制的可变金额调整。每个区块的长期平均 blob 数应等于目标。
您实际上有两个并行运行的拍卖 —— 一个用于计算,一个用于 DA。这是有效资源定价的巨大飞跃。
这里有一些有趣的设计。例如,将当前的 gas 和 blob 定价机制从线性 EIP-1559 更改为一种新的指数 EIP-1559 机制可能是有意义的。当前的实现在实践中并没有平均到我们的目标区块大小。今天,基本费用(basefee)没有完全稳定,导致观察到的每个区块使用的平均 gas 平均超过目标约 3%。
第 II 部分:历史 & 状态管理
在这里快速回顾一些基础知识:
- 历史 —— 链上发生的一切。您可以将其粘贴在硬盘上,因为它不需要快速访问。从长远来看,1 of N 诚实假设。
- 状态 —— 所有当前账户余额、智能合约等的快照。完整节点(当前)都需要这个来验证交易。它对于 RAM 来说太大了,而硬盘驱动器又太慢了 —— 它放在你的 SSD 里。高吞吐量区块链膨胀了它们的状态,远远超出了我们普通人在笔记本电脑上所能保存的范围。如果日常用户不能持有状态,他们就无法完全验证,那么告别去中心化。
TLDR—— 这些东西变得非常大,所以如果你让节点存储 它们,就很难运行一个节点。如果运行一个节点太难,我们普通人不会这样做。这很糟糕,所以我们需要确保不会发生这种情况。
1) Calldata Gas 成本降低与总 Calldata 限制 (EIP-4488)
PDS 是通向 DS 的重要垫脚石,它检查了许多最终要求。在合理的时间跨度内实施 PDS 可以提前 DS 上的时间线。
更容易实现创可贴的是 EIP-4488。它不是那么优雅,但它仍然解决了费用紧急情况。不幸的是,它没有在实现 DS 的过程中实施步骤,因此以后仍然需要进行所有不可避免的更改。如果它开始感觉 PDS 会比我们想要的慢一点,那么快速通过 EIP-4488(它只是几行代码更改)然后大约 6 个月之后实现 PDS 可能是有意义的。具体的时间表仍未确定。
EIP-4488 有两个主要组成部分:
- 将 calldata 成本从每字节 16 gas 降低到每字节 3 gas
- 添加每个区块 1 MB 调用数据的限制以及每个事务额外 300 字节(理论最大值约为 1.4 MB)
需要添加限制以防止出现最坏的情况 —— 一个充满 calldata 的区块将达到 18 MB,这远远超出了以太坊的处理能力。EIP-4488 增加了以太坊的平均数据容量,但由于这个 calldata 限制(3000 万 gas / 每 calldata 字节 16 gas = 1.875 MB),它的突发数据容量实际上会略有下降。

EIP-4488 的持续负载远高于 PDS,因为这仍然是 calldata 与 blob,一个月后可以修剪的数据。EIP-4488 将显着加速历史增长,使其成为运行节点的瓶颈。即使 EIP-4444 与 EIP-4488 一起实施,这也只会在一年后删除执行负载历史。PDS 较低的持续负载显然是可取的。

2) 在执行客户端中绑定历史数据 (EIP-4444)
EIP-4444 允许客户端选择在本地修剪超过一年的历史数据(标题、正文和收据)。它要求客户端停止在 p2 p 层上提供这些修剪过的历史数据。修剪历史允许客户减少用户的磁盘存储需求(目前数百 GB 并且还在增长)。
这已经很重要了,但如果 EIP-4488 被实施(因为它显着增长了历史),这将基本上是强制性的。无论如何,希望这能在相对近期内完成。最终将需要某种形式的历史到期,所以这是处理它的好时机。
链的完全同步需要历史记录,但验证新区块不需要它(这只需要状态)。因此,一旦客户端同步到链的顶端,只有在通过 JSON-RPC 明确请求或对等方尝试同步链时,才会检索历史数据。随着 EIP-4444 的实施,我们需要为这些找到替代解决方案。
客户端将无法像现在一样使用 devp2p 进行「完全同步」—— 他们将取而代之的是从弱主观性检查点「检查点同步」,他们将其视为创世区块。
请注意,弱主观性不会是一个额外的假设 —— 无论如何,它是向 PoS 转变所固有的。由于远程攻击的可能性,这需要使用有效的弱主观性检查点进行同步。这里的假设是客户端不会从无效或旧的弱主观性检查点同步。该检查点必须在我们开始修剪历史数据的时期内(即此处为一年内),否则 p2 p 层将无法提供所需的数据。
随着越来越多的客户端采用轻量级同步策略,这也将减少网络上的带宽使用。
3) 找回历史数据
EIP-4444 在一年后修剪历史数据听起来不错,而 PDS 修剪 blob 的速度更快(大约一个月后)。我们绝对需要这些,因为我们不能要求节点存储所有这些并保持去中心化:
- EIP-4488–长期可能包括每个时隙(slot)约 1 MB 每年增加约 2.5 TB 存储
- PDS–目标为每个时隙约 1 MB,每年增加约 2.5 TB 存储
- DS–目标为每个时隙约 16 MB,每年增加约 40 TB 存储
但是这些数据去哪儿了?我们不再需要了吗?是的,但请注意,丢失历史数据对协议没有风险 —— 仅对单个应用程序而言。那么,以太坊核心协议的工作不应该是永久维护所有达成共识的数据。
那么,谁来存储呢?以下是一些潜在的贡献者:
- 个人和机构志愿者
- 区块浏览器(例如 etherscan.io)、API 提供者和其他数据服务
- 像 TheGraph 这样的第三方索引协议可以创建激励市场,客户可以在其中向服务器支付历史数据以及 Merkle 证明
- Portal Network 中的客户端(目前正在开发中)可以存储链历史的随机部分,Portal Network 会自动将数据请求定向到拥有它的节点
- BitTorrent,例如。每天自动生成和分发一个 7 GB 的文件,其中包含来自区块的 blob 数据
- 特定于应用程序的协议(例如 Rollup)可以要求其节点存储与其应用程序相关的历史记录部分
长期数据存储问题是一个相对简单的问题,因为它是我们之前讨论过的 1 of N 信任假设。我们距离成为区块链可扩展性的最终限制还有很多年。
4) 弱无状态
好的,所以我们已经很好地处理了历史记录管理,但是如何处理状态呢?状态问题实际上是目前提高以太坊 TPS 的主要瓶颈。
全节点获取前状态根,执行区块中的所有事务,并检查后状态根是否与它们在区块中提供的内容相匹配。要知道这些交易是否有效,他们目前需要手头的状态 —— 验证是有状态的。
进入无状态时代 —— 我们将不需要状态来发挥作用。以太坊正在争取「弱无状态」,这意味着验证区块不需要状态,但构建区块需要状态。验证变成了一个纯函数 —— 给我一个完全隔离的区块,我可以告诉你它是否有效。基本上是这样的:

由于 PBS,构建者仍然需要状态是可以接受的 —— 无论如何,它们将是更加中心化的高资源实体。专注于去中心化验证者。弱无状态给构建者带来了更多的工作,而验证者的工作要少得多。这是一个伟大的权衡。
您通过见证(witness)实现了这种神奇的无状态执行。这些是构建者将开始包含在每个区块中的正确状态访问的证明。
验证一个区块实际上并不需要整个状态 —— 您只需要该区块中的交易读取或影响的状态。构建者将开始在给定区块中包含受交易影响的状态片段,并且他们将证明他们通过见证(witness)正确访问了该状态。
让我们举个例子。Alice 想向 Bob 发送 1 个 ETH。要使用此交易验证区块,我需要知道:
- 交易前 ——Alice 有 1 ETH
- Alice 的公钥 —— 所以我可以知道签名是正确的
- Alice 的随机数 —— 所以我可以知道交易是按正确的顺序发送的
- 执行交易后 ——Bob 多了 1 ETH,Alice 少了 1 ETH
在弱无状态世界中,构建者将上述见证数据添加到区块中并证明其准确性。验证者接收区块,执行它,并决定它是否有效。仅此而已!
以下是从验证者的角度来看的含义:
- 用于持有状态的巨大 SSD 需求消失了 —— 这是当今扩展的关键瓶颈。
- 由于您现在还要下载见证数据和证明,因此带宽要求会有所增加。这是 Merkle-Patricia 树的瓶颈,但它是温和的,而不是 Verkle 尝试的瓶颈。
- 您仍然执行事务以完全验证。无状态承认这不是目前扩展以太坊的瓶颈。
弱无状态还允许以太坊放松对其执行吞吐量的自我限制,状态膨胀不再是一个紧迫的问题。将 gas 限制提高约 3 倍可能是合理的。
无论如何,大多数用户执行都将在 L2 上进行,但更高的 L1 吞吐量即使对他们来说仍然是有益的。Rollups 依靠以太坊进行 DA(发布到分片)和结算(需要 L1 执行)。随着以太坊扩展其 DA 层,发布证明的摊销成本可能会成为 Rollup 成本的更大份额(尤其是对于 ZK-rollups)。
5) Verkle Tries
我们掩盖了这些见证的实际工作方式。以太坊目前使用 Merkle-Patricia 树来表示状态,但所需的 Merkle 证明对于这些见证来说太大而无法实现。
以太坊将转向 Verkle 尝试进行状态存储。Verkle 证明的效率要高得多,因此它们可以作为可行的见证来实现弱无状态。
首先让我们回顾一下 Merkle 树的样子。每笔交易都经过哈希处理 —— 底部的这些哈希被称为「叶子」。所有的哈希都称为「节点」,它们是它们下面的两个「子」节点的哈希。生成的最终哈希是「Merkle 根」。
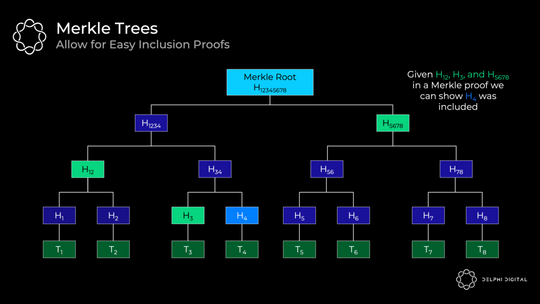
这是一个有用的数据结构,用于证明包含事务,而无需下载整个树。例如,如果您想验证交易 H4 是否包含在内,则只需要 Merkle 证明中的 H12、H3 和 H5678。我们有来自区块头的 H12345678。因此,轻客户端可以向完整节点询问这些哈希,然后根据树中的路由将它们哈希在一起。如果结果是 H12345678,那么我们已经成功证明 H4 在树中。
但是,树越深,到达底部的路径就越长,因此您需要更多的项目来证明。因此,浅而宽的树似乎有利于进行有效的证明。
问题是,如果你想通过在每个节点下添加更多子节点来使 Merkle 树更宽,那将是非常低效的。您需要将所有兄弟姐妹哈希在一起才能爬上树,因此您需要接收更多兄弟姐妹哈希以用于 Merkle 证明。这将使证明大小变得庞大。
这就是高效向量承诺的用武之地。请注意,Merkle 树中使用的哈希实际上是向量承诺 —— 它们只是有效地只对两个元素进行承诺。所以我们想要向量承诺,我们不需要接收所有的兄弟姐妹来验证它。一旦我们有了它,我们就可以使树更宽并减少它们的深度。这就是我们获得有效证明大小的方式 —— 减少需要提供的信息量。
Verkle trie 类似于 Merkle 树,但它使用有效的向量承诺(因此名称为「Verkle」)而不是简单的哈希来向其子节点承诺。所以基本思想是每个节点可以有很多孩子,但我不需要所有的孩子来验证证明。无论宽度如何,它都是恒定尺寸的证明。
实际上,我们之前已经介绍了其中一种可能性的一个很好的例子 ——KZG 承诺也可以用作向量承诺。事实上,这就是以太坊开发者最初计划在这里使用的东西。此后,他们转向 Pedersen 承诺履行类似的职责。这些将基于椭圆曲线(在本例中为 Bandersnatch),并且它们将分别提交 256 个值(比两个好得多!)。
那么为什么不拥有尽可能宽的深度树呢?这对于现在拥有超级紧凑证明的验证者来说非常有用。但是有一个实际的权衡是证明者需要能够计算这个证明,而且它越宽就越难。因此,这些 Verkle 尝试将位于 256 个值宽的极端之间。
6) 状态到期
弱无状态消除了验证者的状态膨胀约束,但状态不会神奇地消失。交易成本是有限的,但它们通过增加状态对网络造成永久性税收。状态增长仍然是网络的永久拖累。需要做一些事情来解决根本问题。
这就是状态到期的地方。长时间处于非活动状态(比如一两年)的状态甚至会从区块构建者需要携带的东西中剔除。活跃用户不会注意到任何事情,并且不再需要的无用状态可以被丢弃。
如果您需要恢复过期状态,您只需要显示一个证明并重新激活它。这又回到了这里的 1 of N 存储假设。只要有人仍然拥有完整的历史记录(区块浏览器等),你就可以从他们那里得到你需要的东西。
弱无状态会削弱基础层对状态到期的即时需求,但从长远来看,特别是随着 L1 吞吐量的增加,这是一件好事。对于高吞吐量汇总来说,这将是一个更有用的工具。L2 状态将以更高数量级的速度增长,甚至会拖累高性能构建者。
第 III 部分--MEV
PBS 是安全实施 DS 所必需的,但请回想一下,它最初实际上是为了对抗 MEV 的中心化力量而设计的。你会注意到今天以太坊研究的一个反复出现的趋势 ——MEV 现在是加密经济学的前沿和中心。

设计具有 MEV 的区块链对于保持安全性和去中心化至关重要。基本的协议级方法是:
- 尽可能减少有害的 MEV(例如,单个 slot 确定性、单一秘密领导者选举)
- 使其余部分民主化(例如,MEV-Boost、PBS、MEV 平滑)
其余的必须很容易被捕获并在验证者之间传播。否则,由于无法与复杂的搜索者竞争,它将集中验证器集。合并后 MEV 将在验证者奖励中所占份额更高(质押发行远低于给予矿工的通胀率)这一事实加剧了这种情况。不容忽视。
1) 当今的 MEV 供应链
今天的事件顺序如下所示:
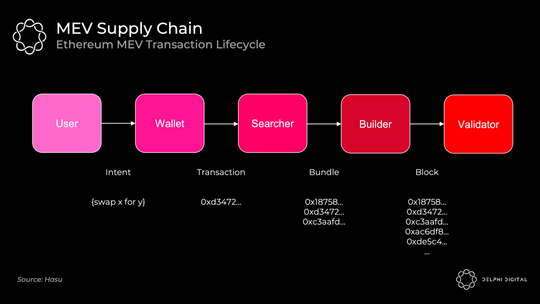
矿池在这里扮演了建设者的角色。MEV 搜索者通过 Flashbot 将交易包(及其各自的出价)中继到矿池。矿池运营商聚合一个完整的区块并将区块头传递给各个矿工。矿工通过 PoW 在分叉选择规则中赋予其权重来证明这一点。
Flashbots 的出现是为了防止整个堆栈的垂直整合 —— 这将为审查制度和其他令人讨厌的外部性打开大门。当 Flashbots 出现时,矿池已经开始与交易公司达成独家交易以提取 MEV。相反,Flashbots 为他们提供了一种简单的方法来汇总 MEV 出价并避免垂直整合(通过实施 MEV-geth)。
以太坊合并后,矿池将消失。我们希望为在家中能够合理运行的验证者节点打开大门。这需要找人担任专门的构建角色。您的家庭验证者节点在捕获 MEV 方面可能不如拥有量化工资的对冲基金那么好。如果不加以控制,如果普通人无法竞争,这将集中验证者集。如果结构合理,该协议可以将 MEV 收入重定向到日常验证者的质押收益。

2) MEV-Boost
不幸的是,协议内的 PBS 根本无法在合并时准备好。Flashbots 再次提供了一个垫脚石解决方案 - MEV-Boost。
合并后的验证者将默认将公共内存池交易直接接收到其执行客户端中。他们可以将这些打包,交给共识客户端,然后广播到网络。(如果您需要了解以太坊的共识和执行客户端如何协同工作,我将在第四部分中介绍)。
但正如我们所讨论的,您的验证者不知道如何提取 MEV,因此 Flashbots 提供了另一种选择。MEV-boost 将插入您的共识客户端,允许您外包专门的区块构建。重要的是,您仍然可以选择使用自己的执行客户端作为后备。
MEV 搜索者将继续发挥他们今天的作用。他们将运行特定的策略(统计套利、原子套利、三明治等)并竞标他们的捆绑交易包。然后,构建者将他们看到的所有捆绑包以及任何私人订单流(例如,来自 Flashbots Protect)聚合到最佳完整区块中。构建者仅通过运行到 MEV-Boost 的中继将区块头传递给验证者。Flashbots 打算运行中继器和构建者,并计划随着时间的推移去中心化,但将其他构建者列入白名单可能会很慢。
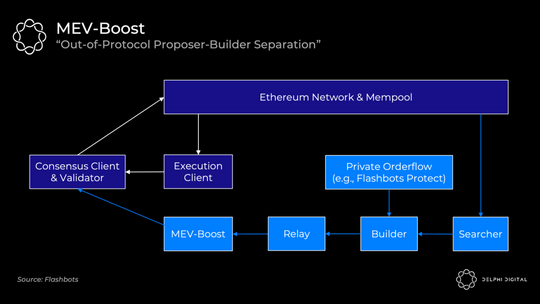
MEV-Boost 要求验证者信任中继者 —— 共识客户端收到区块头,对其进行签名,然后才显示区块 body。中继者的目的是向提议者证明 body 是有效且存在的,这样验证者就不必直接信任构建者。
当协议内 PBS 准备就绪时,它会在此期间编入 MEV-Boost 提供的内容。PBS 提供相同的权力分离,允许更容易的构建者去中心化,并消除了提议者信任任何人的需要。

3) 委员会驱动的 MEV 平滑
PBS 还为另一个很酷的想法打开了大门 —— 委员会驱动的 MEV 平滑。
我们看到提取 MEV 的能力是验证者集的中心化力量,但分布也是如此。从一个区块到另一个区块的 MEV 奖励的高度可变性促使汇集许多验证者来平滑你的回报(正如我们今天在矿池中看到的那样,尽管在这里的程度较小)。
默认设置是向实际的区块提议者提供构建者的全额付款。MEV 平滑将改为将支付分配给许多验证者。验证者委员会将检查提议的区块并证明这是否确实是出价最高的区块。如果一切顺利,则区块继续进行,奖励将在委员会和提议者之间分配。
这也解决了另一个问题 —— 带外贿赂。例如,可以激励提议者提交次优区块并直接接受带外贿赂以向委托人隐瞒他们的付款。此证明可以检查提议者。
协议内 PBS 是实现 MEV 平滑的先决条件。您需要了解构建者市场和提交的明确投标。这里有几个开放的研究问题,但这是一个令人兴奋的提议,对于确保去中心化的验证者再次至关重要。
4) 单 slot 交易最终性
快速最终性很棒。等待约 15 分钟对于 UX 或跨链通信来说不是最佳选择。更重要的是,这会造成一个 MEV 重组问题。
合并后的以太坊已经提供了比今天更强大的确认 —— 成千上万的验证者证明每个区块与矿工竞争并可能在相同区块高度进行挖矿而无需投票。这将使重组极不可能。然而,这仍然不是真正的交易最终性。如果最后一个区块有一些丰厚的 MEV,你可能只是诱使验证者尝试重组链并为自己窃取它。
单 slot 确定性消除了这种威胁。恢复一个最终确定的区块至少需要三分之一的验证者,并且他们的质押代币会立即被削减(数百万 ETH)。
我不会对这里的潜在机制过于关注。单 slot 最终性在以太坊的路线图中已经发展的很遥远了,它是一个非常开放的设计空间。
在今天的共识协议中(没有 slot 最终确定性),以太坊只需要 1/32 的验证者来证明每个 slot(目前大约 380,000 个中的大约 12,000 个)。将这种投票扩展到在单个 slot 中使用 BLS 签名聚合的完整验证器集需要更多的工作。这会将数十万张选票压缩为一次验证:
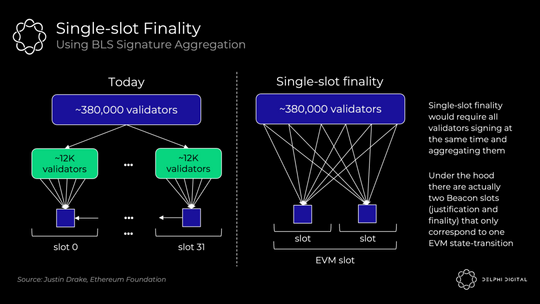
Vitalik 在这里分解了一些有趣的解决方案。
5) 单一秘密领袖选举(SSLE)
SSLE 试图修补合并后我们将面临的另一个 MEV 攻击向量。
信标链验证者列表和即将到来的领导者选择列表是公开的,并且很容易对它们进行去匿名化并映射它们的 IP 地址。您可能可以在这里看到问题。
更复杂的验证者可以使用技巧来更好地隐藏自己,但小型验证者特别容易受到 doxxed 和随后的 DDOSd 的影响。这可以很容易地用于 MEV。
假设你是第 n 区块的提议者,我是第 n+1 区块的提议者。如果我知道你的 IP 地址,我可以廉价地对你进行 DDOS 攻击,这样你就会超时并且无法生成你的区块。我现在可以捕获我们 slot 的 MEV 并加倍我的奖励。EIP-1559 的弹性区块大小(每个区块的最大 gas 是目标大小的两倍)加剧了这种情况,因此我可以将本来应该是两个区块的交易塞进我现在两倍长的单个区块中。
家庭式验证者节点可能会放弃验证,因为他们被持续攻击。SSLE 使得除了提议者之外没有人知道何时轮到他们阻止这种攻击。这不会在合并时生效,但希望它可以在不久之后实施。
Part IV – 合并
好吧,要清楚我之前是在开玩笑。我实际上认为(希望)以太坊合并发生得相对较快。

我们都在谈论这个话题,所以我觉得有义务至少给它一个简短的介绍。
1) 合并后的客户端
今天,你运行一个可以处理所有事情的单体客户端(例如,Go Ethereum、Nethermind 等)。具体来说,全节点同时执行以下操作:
- 执行 —— 执行区块中的每笔交易以确保有效性。获取前状态根,执行所有操作,并检查生成的后状态根是否正确
- 共识 —— 验证你是否在完成工作最多的最重(最高 PoW)链上(即中本聪共识)
它们是不可分割的,因为全节点不仅遵循最重的链,而且遵循最重的有效链。这就是为什么它们是完整节点而不是轻节点。即使发生 51% 攻击,全节点也不会接受无效交易。

信标链目前只运行共识来给 PoS 一个测试运行。不包含执行。最终将决定最终的总难度,此时当前的以太坊执行区块将合并到信标链块中,形成一条链:
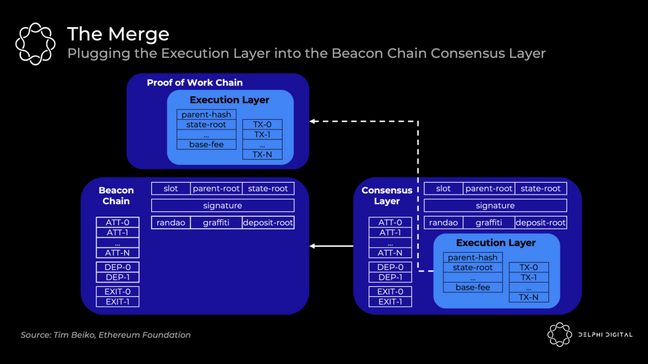
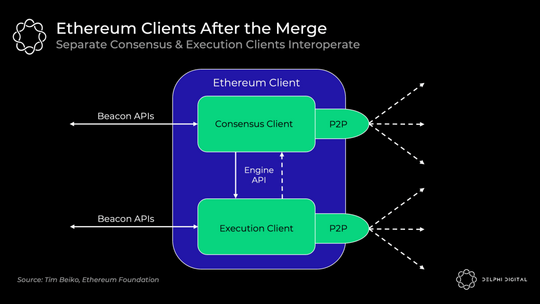
但是,全节点将在后台运行两个独立的客户端,它们可以互操作:
- 执行客户端(又名「Eth1 客户端」)—— 当前的 Eth 1.0 客户端继续处理执行。他们处理区块,维护内存池,管理和同步状态。PoW 部分被撕掉了。
- 共识客户端(又名「Eth2 客户端」)—— 当前信标链客户端继续处理 PoS 共识。他们跟踪链的头部,gossip 并证明区块,并获得验证者奖励。
客户端接收信标链区块,执行客户端运行交易,如果一切顺利,共识客户端将遵循该链。您将能够混合和匹配您选择的执行和共识客户端,所有这些都将是可互操作的。将引入一个新的引擎 API 供客户端相互通信:
或者:
2) 合并后的共识
今天的中本聪共识很简单。矿工创建新区块,并将它们添加到观察到的最重的有效链中。
合并后的以太坊转向 GASPER—— 结合 Casper FFG(最终确定性工具)和 LMD GHOST(分叉选择规则)以达成共识。这里的 TLDR - 这是一种有利于共识的活跃性,而不是有利于安全性。
区别在于,有利于安全的共识算法(例如,Tendermint)在未能获得必要数量的选票(此处设置为验证者的 2/3)时停止。有利于链的活跃性(例如,PoW + 中本聪共识)无论如何都会继续建立一个乐观的分类帐,但如果没有足够的选票,它们就无法达到最终确定性。今天的比特币和以太坊永远不会最终确定 —— 你只是假设在足够数量的区块之后不会发生重组。
然而,以太坊也将通过定期检查点获得足够的票数来实现最终性。每个 32 ETH 实例都是一个单独的验证者,并且已经有超过 380,000 个信标链验证者。Epochs 由 32 个 slot 组成,所有验证者都分开并在给定 epoch 内证明一个 slot(意味着每个 slot 约 12,000 个证明)。分叉选择规则 LMD Ghost 然后根据这些证明确定链的当前头部。每个 slot(12 秒)添加一个新区块,因此 epoch 为 6.4 分钟。通常在两个 epoch(也就是 64 个 slot,尽管最多可能需要 95 个)之后通过必要的投票来实现最终性。
结论
所有道路都通向中心化区块生产、去中心化去信任区块验证和抗审查的终局。以太坊的路线图瞄准了这个愿景。
以太坊的目标是成为最终统一的 DA 和结算层 —— 在底层大规模去中心化和安全,在顶层计算可扩展。这将密码学假设浓缩为一个健壮的层。包含执行的统一模块化基础层还捕获了 L1 设计中的最高价值 —— 实现货币溢价和经济安全,正如我最近介绍的(现在在这里开源)。
我希望你能更清楚地了解以太坊研究是如何相互交织的。我们有这么多动人的文章作品,非常前沿,而且有一个非常大的画面环绕在你的脑海。
从根本上说,这一切都回到了那个单一的愿景。以太坊为实现大规模可扩展性提供了一条引人注目的道路,同时珍视了我们在这个领域非常关心的那些价值观。
特别感谢 Dankrad Feist 的审阅和见解。
本文仅代表原作者观点,不构成任何投资意见或建议。
-END-
本文首发于:https://mp.weixin.qq.com/s/FiiEBhC5dPEUP-LuB-X2Ew
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
