Dune SQL 和以太坊数据分析基础指南
编者导语:你知道以太坊 EVM 数据是如何映射到 Dune 表格的么?在 Dune 查询时需要使用到哪些基本 SQL 用法, 本文一一揭晓。
如果你已经知道基本 SQL 以及如何在 Dune 表中浏览链上数据,那么你应该阅读高级指南。
本篇是你在 Dune 中进行基本分析时需要了解的所有概念,这是数据分析的第一步!很快就会推出更高级的优化技巧指南。
EVM 的数据是如何转化为 Dune 数据表
你可以阅读 关系数据库的基础知识。如果你不知道 "表 "是什么意思,可以把每笔交易看成是 excel 表中的一行。Dune 中的表都有共享的(各表相同)和相关列,最常见的是合约/钱包地址或交易哈希值。EVM指的是 "以太坊虚拟机",以太坊、Gnosis、Avalanche、Arbitrum、Optimism、Polygon和币安等链都是EVM 链,因此原始数据输出都是大致相同的。
Dune有很多表。如果你查看过查询界面中的资源管理器,那么我相信你已经被淹没了。我在下面展示了各表格的层次结构,这样你就能理解你所看到的图标以及它们所对应的表格类型:
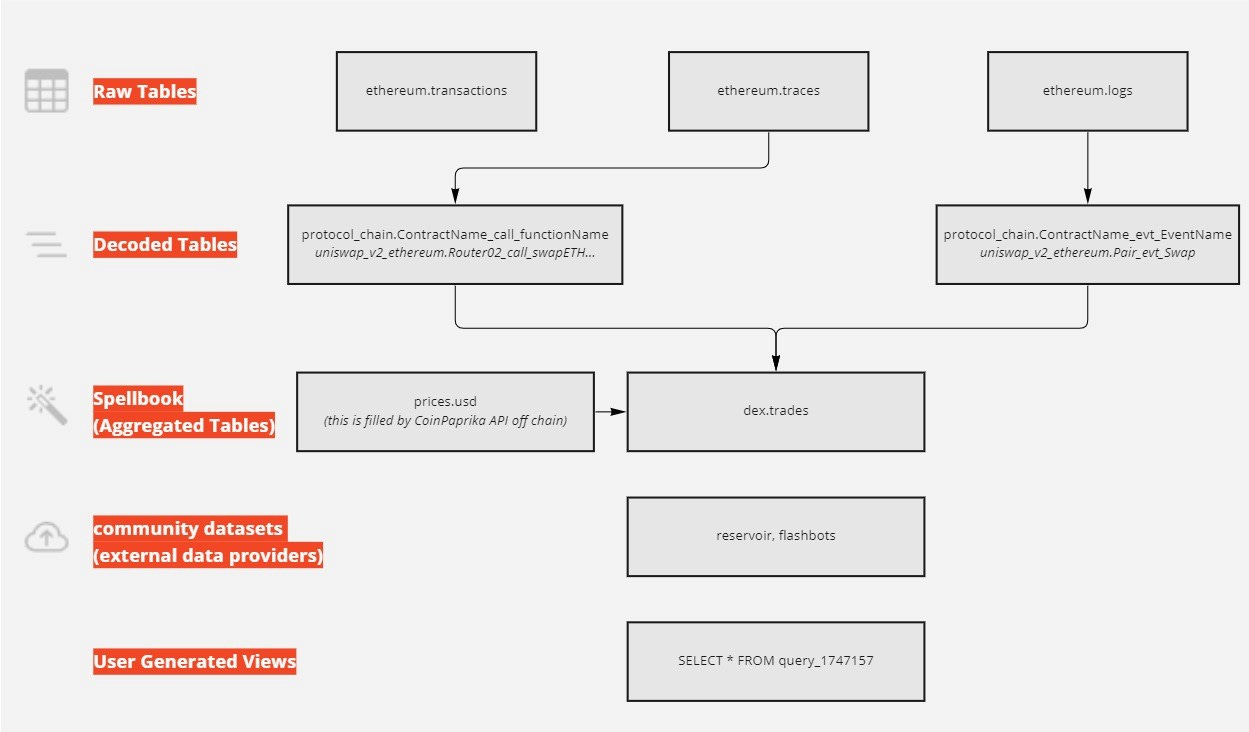
最简单的表是 "交易"表(transactions),其中表内字段 "from" 是签署交易的钱包,"to "是被交互的地址,"input"是调用函数时传递的数据。当你进入更复杂的表,如跟踪(traces)/日志(logs)或解码表(Decoded Tables)时,需要更多的 EVM 知识来浏览这些关系。交易哈希("hash "或 "tx_hash")在交易表中是唯一的,而在其他表中,根据交易的执行方式可能会有重复。
所有这些表都以某种方式相互关联。所有日志(logs)和跟踪(traces)都与交易相关,所有交易都与区块相关。你需要专注于理解数据创建的顺序(链上),以及该顺序如何影响下面表格的填充。
?每条链都有自己独立的原始表(Raw Tables)和解码表(Decoded Tables);有些链会共享法术书表。你可以交叉查询任何表格,无论数据来自哪条链。
钱包地址(EOA)可以跨链连接,但根据交易哈希值或区块编号连接以太坊到 Optimism 数据是毫无意义的。
-
原始表(Raw Tables): 这些表是 "交易表(transactions)"、"跟踪表(traces)"、"日志(ogs) "和 "块(bloks)"表,以最原始的形式保存代表区块链数据:主要是字节数组。你可以在Dune 文档中找到这些表的列描述符。数据是这样在它们之间流动的:
-
你提交一个交易(调用合约,向某人发送 ETH)。每笔交易都发生在特定的区块中。交易有一个索引,表示交易在块中执行的顺序(在交易表该列称为 tx_index)。
-
该交易将触发跟踪(traces), 跟踪是如:合约调用其他合约、部署合约、向某地址发送 ETH 等。所有跟踪都有一个 trace_address 地址(此处参见 traceAddress)。你可以根据 trace_address 列的cardinality为每笔交易排序。
-
这些函数调用在执行过程中会发出事件(存储在 logs 中)。日志是根据索引在整个块中排序的(在日志表之外,列称为 evt_index)。事件无法在交易之外发生!
-
?
creation_traces是只跟踪合约部署的跟踪(traces)子集。
-
解码表(Decoded Tables): 根据提交的合约 ABI到合约表(即
ethereum.contracts),函数和事件被转换为字节签名(ethereum.signatures),然后与traces和logs进行匹配,从而生成解码表,例如uniswap_v2_ethereum.Pair_evt_Swap,该表存储了由UniswapV2工厂创建的所有交易对合约的所有兑换事件, 你可以通过查看事件的contract_address表过滤特定的一个事件。- 每个函数和事件都有自己的表。 读取的函数会显示出来,但无法查询(例如,对于类似
balanceOf这样的函数,表是空的) - 所有解码后的表都会以
call或evt为前缀,主要记录交易元数据列,如 tx_hash、block_time 和 block_number。
- 每个函数和事件都有自己的表。 读取的函数会显示出来,但无法查询(例如,对于类似
-
魔法咒语表(Spellbook Tables): 这些表是在原始表、解码表或种子文件表的基础上使用 SQL创建的。并在调度程序上运行,因此与原始/解码表相比有数据延迟。
-
像 ERC20 或 NFT 代币名称和小数位这样的东西是 "种子文件",基本上是把 CSV 数据集上传到 Dune。tokens.erc20 和 "tokens.nft "都是非常有用的表格,几乎适用于任何查询。
-
像代币转移这样非常常见的事件也有自己的咒语表,例如
erc20_ethereum.evt_Transfer保存了所有 ERC20 代币的所有转移事件,无论我们的代币时候在代币表中,erc721 及 erc1155 也有类似的表。 -
prices.usd也属于这一类,它提供几乎所有 ERC20 代币的价格。dex.prices是一个类似的表格,它根据 DEX 汇率而不是链外 API 计算价格。
-
?对于任何基于代币的表,由于唯一性约束,你应该始终通过地址而不是代币符号进行连接。
-
社区数据集(community datasets): 这些是我们从其他提供者获取的数据集。Flashbots MEV 数据集和 Reservoir NFT 交易数据集都属于这一类。
- 这些数据集仍可以通过交易哈希值和地址很好地连接 Dune 数据集。
-
用户生成的视图: DuneSQL把每个公共查询都变成了一个 "视图"。可以使用
query_<id>语法查询其中任何一个,它将以CTE的形式插入到引用的查询文本。
此功能目前不适用于查询中的参数。
另外⚠️ 查询必须是使用 DuneSQL 引擎创建的,才能在另一个查询中引用。
数据流程示例
比方说,Uniswap 中的代币兑换发生在一次交易中:
- 会有一笔交易添加到
ethereum.transactions表中。 - 由于发生了 Swap() 事件,兑换将在
ethereum.logs中有记录,相应的解码表uniswap_v2_ethereum.Pair_evt_Swap也将有记录填入。
a. 由于必须有一个代币转入和一个代币转出,我们还会在 ethereum.logs 表和 erc20_ethereum.evt_Transfer 咒语表中发现两个转移事件。
-
每次兑换都会在
ethereum.traces中记录一行。解码函数表uniswap_v2_ethereum.Pair_call_swap也会被填充。a. 代币转移会给
ethereum.traces表增加两行,因为代币合约上一定调用两次转移函数。注意转移函数是没有咒语表的。 -
每次兑换最后都会添加到 "dex.trades"表中。
-
如果是 MEV 兑换,我们也可以在社区数据集
flashbots.mev_summary表中找到它。
正如你所看到的,这些表包含同一交易的不同部分,可以通过不同方式加以利用!如果你还感到困惑,请尝试链接的查询 以探索原始表、解码表和咒语表中的 "兑换 "函数/事件是如何显示的。
如果你想学习如何处理来自交易的原始字节数据,可以在此学习
基础 SQL 概念
一般来说,需要你记住下面的语句结构(其中括号"[ ]"表示可选语句,也就是说,即使没有这些语句,查询也可运行)。括号的顺序非常重要,例如,不能将 WHERE 语句放在 JOIN 语句之前或 GROUP BY 语句之后,否则查询会出错。
[ WITH subquery as (...) ]
SELECT [ ALL | DISTINCT ] some_columns
[ FROM some_table ]
[ [LEFT...] JOIN some_table ON conditional_logic ]
[ WHERE conditional_logic ]
[ GROUP BY [, ...some_columns] ]
[ HAVING conditional_logic ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select other_query]
[ ORDER BY some_column [ ASC | DESC ] [, ...] ]
[ OFFSET some_number_rows ]
[ LIMIT some_number_rows ]
⚠️为便于阅读,以上内容经过了简化,完整的技术版本在这里。还有一些我在本指南中省略的函数在Dune SQL中是支持的;您可以在这里找到基本的Trino SQL。
我们可以点击查询链接,通过 "分叉(forking)"的方式在Dune中使用任何查询。
选择查询
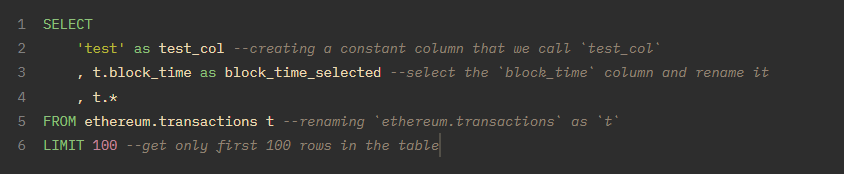
*= 表示 "所有 "列- columns(列) = 查询的列
- constants(常量) = 可以选择一个常量,它将作为一列添加到所有行中。
- as = 任何列和表都可以重命名为其他名称(节省输入次数)
- LIMIT = 返回前 X 行
让我们把这些概念整合到一个查询中:
<p align='center'>https://dune.com/queries/1780448?d=11</p>
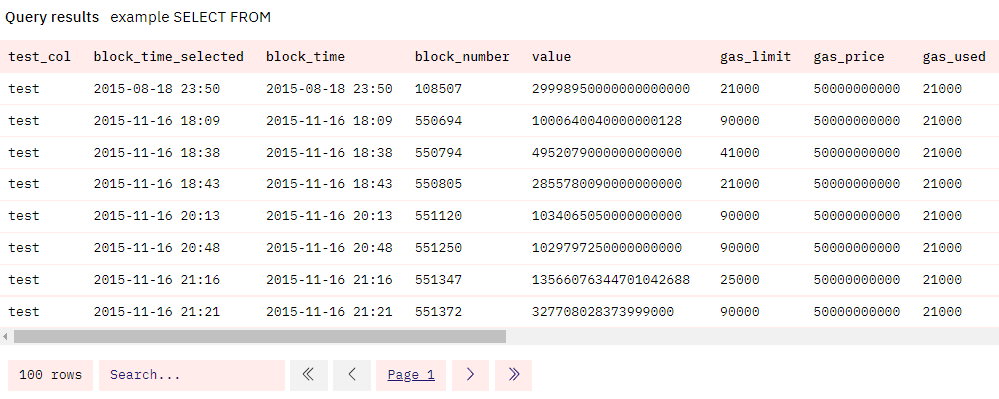
DISTINCT = 返回选择的列组合唯一的行。
- 这通常用于帮助查找唯一地址或交易哈希值。下面,我们通过跟踪存款发出的
Supply事件,用它来获取 Optimism 链上 Aave v3 借贷Pool合约中的所有排重的提供者。他们提供资金池,别人才能借到代币,并支付年利率。希望你能在这里看到所有解码表都一致的模式namespace_chain.ContractName_evt_EventName。

<p align='center'>https://dune.com/queries/1780452</p>
CTE = 允许将子查询存储为变量,并在查询的稍后部分像引用表格一样引用它。这些查询可以嵌套。
译者注: Common Table Expressions,通用表达式, 是一个命名的临时结果集

<p align='center'>https://dune.com/queries/1780452</p>
类型和类型转换
下面是你需要了解的一些主要类型:
-
varchar = 也称为字符串。大多数列默认为这种类型。
-
double = 基本上任何数值都应该使用这种类型。
-
hex/bytea = 大多数原始数据的基本类型,如 "transactions "表中的 "data "或 "logs "表中的任何主题。任何以 "0x... "开头的都是 bytea 类型。
bytea2numeric()是将 bytea 列转换为数字形式的好帮手。不过,你必须 substring() 将结果转为 32 字节(64 个字符)。
-
timestamp = 如果列的类型不一致,许多日期函数就会表现不佳。转换为时间戳是解决这一问题的最简单方法。
使用 cast() 函数可以更改列类型(如适用)。

排序 ORDER BY
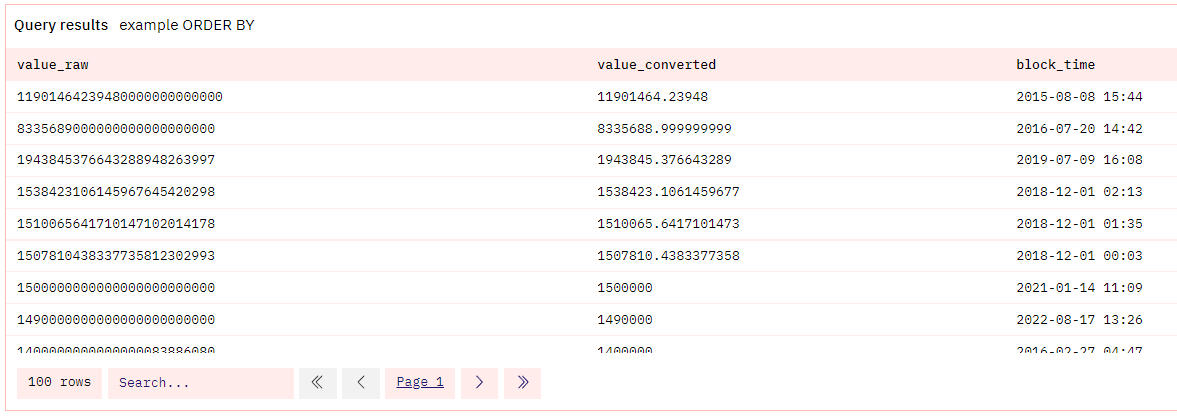
- ASC/DESC = 按某列以升序或降序对所有行排序
- 这对排序很有用,然后使用 LIMIT 可以得到 "前 100 条 "或 "后 100 条"。让我们使用最后一个查询,先进行排序,以获得最大值的前 100 个转移。

-
NULLS FIRST/LAST = 如果存在空值,则首先或最后显示空值
-
我主要将其用于调试目的。先显示空值能让我更快地发现错误。
...order by COLUMN desc nulls first
-
使用条件
有三种主要的运算符类型需要了解:
- is [not] null(如果一行中不存在数据,那么它就是空的, 在左连接中很常见)。
- [not] IN 或 EXISTS(用于检查值列表中是否存在某一行的值)
- !=、=、>、<(这些是对数字和 varchar 类型有效的等式运算符)
下面是最常见的示例--在查看事件表时只过滤一个合约地址:

这样,我们就可以得到在 USDC/WETH Uniswap v2 Piar 地址 上调用所有 swap() 函数。
Uniswap 允许你兑换交易对代币中的任意两个代币,因此在这种情况下,你要么将 USDC 兑换给 WETH,要么将 WETH 兑换给 USDC。假设我们也想查看 WETH/WBTC 的兑换。那么我们可以使用 IN:

现在,假设我们只想知道过去三天内 USDC/WETH 或 WETH/WBTC 货币对的兑换情况。那么我们可以将查询改成这样:

这里的括号位置非常重要,否则,无论先过滤哪个 contract_address,都会得到过去三天内没有发生的兑换。你可以在这里使用 WHERE 查询。
使用时间
现在是介绍使用的三个基本时间函数的好时机。
- date_trunc('minute',some_column)(将其视为向下舍入到最近的时间间隔)
- now()(以 UTC 时区为单位,提供运行查询时的时间戳)
- interval ‘1’ day(可以是分、小时、日、月、年)
- > timestamp '2022-02-01 00:01:00' 使用此格式将字符串转换为时间戳。
由于在接下来的章节中我们会经常使用这些格式,所以我就不在这里举例说明了。
常见数学运算
还有一些基本的数学运算,有些我们已经用过了。你已经得到了所有的 +、-、/、`` 符号。目前你唯一需要的是
- round(some_number, decimal_places) 用于四舍五入小数
- pow(基数, 幂) (或 1e18 格式)主要用于处理代币/值的原始值与实际值之间的转换。
与时间函数一样,我们将在接下来的章节中大量使用这些函数。
分组 GROUP BY
好吧,这里我可能会开始失去一些朋友,但请坚持下去。如果你以前在 excel 中使用过数据透视表,那么 "GROUP BY "就不难理解了。如果没有,就把它看成是对列中的每个唯一 ID 运行选择查询。
你可以应用一些聚合函数来对每个唯一 ID 的所有选定行进行聚合,下面列出了一些聚合函数:
- 计数(count)
- 求和(sum)
- 平均(avg)
- 最小值(min)
- 最大值 (max)
- approx_distinct (与 "count(distinct col) "相同)
- approx_percentile(0.5) (获取中位数或任何你想要的四分位数)
- arbitrary (获取随机值)
我把它们放在 USDC/WETH 最新一天的兑换查询中,语法是这样的:
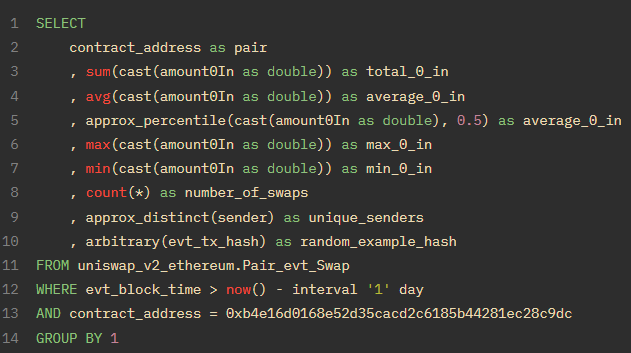
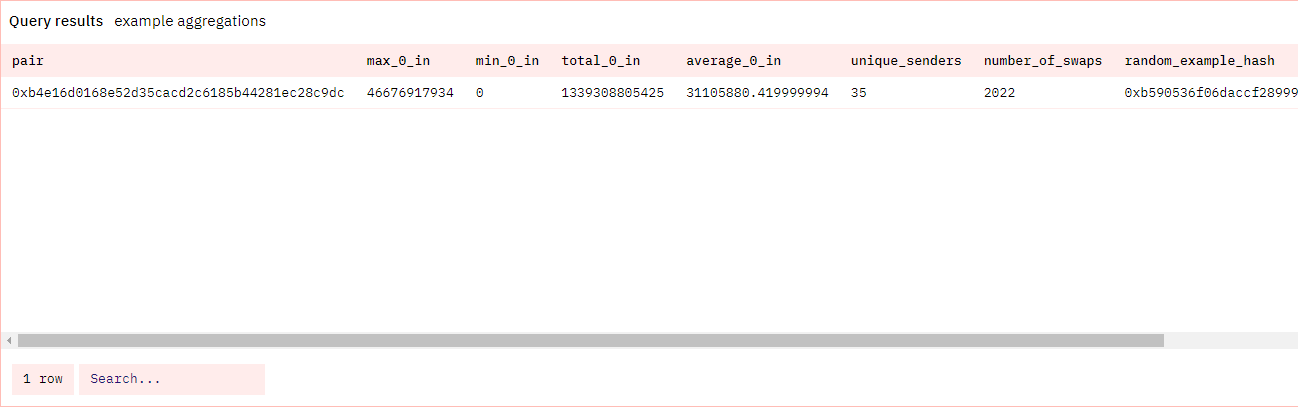
你会注意到,我们现在使用的是 Swap 事件,而不是调用。事件是在调用内部发出的,因此在本例中,Swap() 事件是在 swap() 函数结束时发出的。
谁用分组条件 HAVING
这与 WHERE 类似,但只用在 GROUP BY 之后。比方说,你想要查询某些发起兑换者的总金额,但只保留那些在过去 10 天内兑换了价值 100 ETH 以上代币的兑换者。
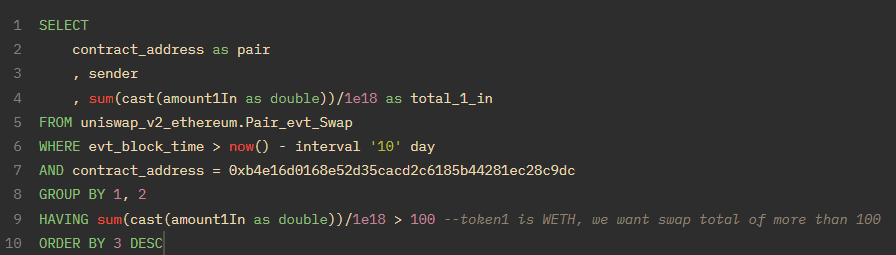
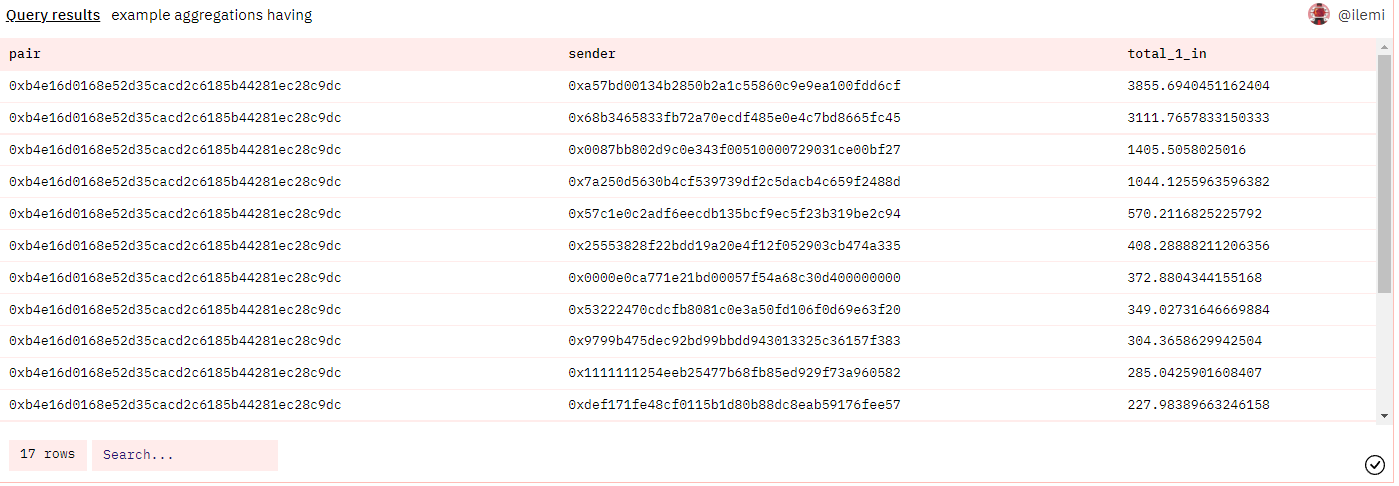
在我运行此查询时(12/19/22),只有 17 个兑换者在过去十天内兑换了超过 100 个 ETH。
使用 union (all), intersect, except
在使用 JOIN 之前,我们先来了解一下按行组合选择(子查询)。这些函数要求在组合前必须有一致的列,否则会出错。一个超级简单的示例是使用此查询。
对于 UNION ALL,我的主要用途是合并,这样我就可以有一套完整的数据来开始工作。例如,Uniswap v2 的兑换路由有 8 种不同的兑换函数,具体取决于期望的输入和输出Token及数量。因此,要获得所有兑换信息,我需要联合所有兑换函数:
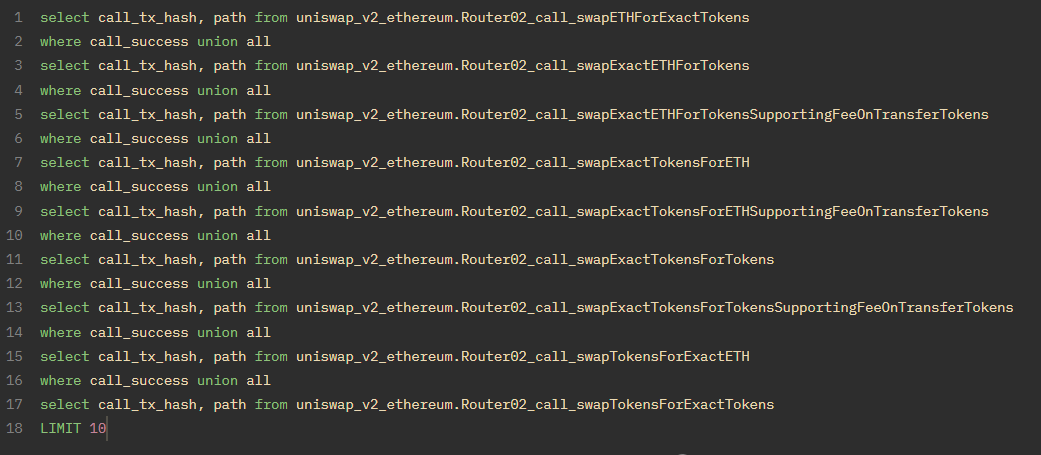
如果我只使用UNION,那么就相当于使用UNION ALL,然后对所有列进行SELECT DISTINCT。**INTERSECT(交集)和EXCEPT(排除)**分别给出两个选择之间的相同项或去除相同项。我通常不会使用这些功能,因为当我需要这些功能时,我通常需要条件逻辑,所以我会使用某种 JOIN 来代替。
JOINS
好了--到目前为止,你跟上我的进度做得很好!如果你是 SQL 的新手,可以多玩玩上面的内容,如果你已经开始在脑海中想象表格的操作,那么消化这部分内容就会容易得多。
连接允许你按列**组合两个选择(子查询、CTE、表)。**如果连接条件只从每个表中产生一条匹配记录,你应该只得到额外的列,而没有额外的行。
这里有一个最佳图表,可以帮助你了解连接后要添加或删除哪些数据:
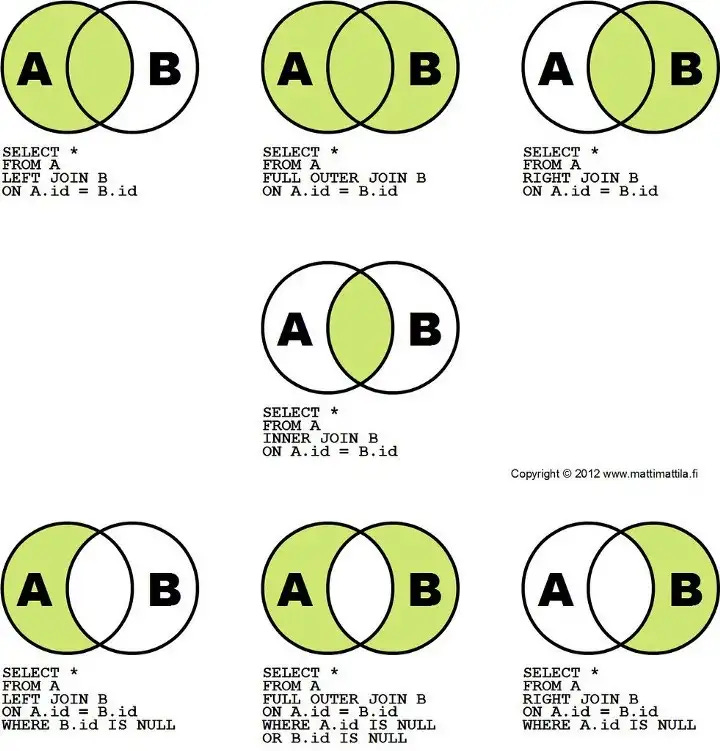
来自:https://live.staticflickr.com/8346/8190148857_78d0f88cef_b.jpg
你需要的最常用的工具有:
- JOIN(表示 INNER,因此只保留重合的记录)
- **LEFT JOIN **(保留所有原始行,并连接任何匹配行)
- FULL OUTER JOIN(保留所有内容)
让我们从一个简单的例子开始。通常情况下,事件表和函数表不包含交易/跟踪的 "from "或 "to "列。因此,我们可以通过 JOIN 来获取这些地址。在这种情况下,LEFT JOIN 和 JOIN 会得到相同的结果,因为每个事件和函数都有一个交易哈希值,而每个哈希值在交易/跟踪表中都有一行。
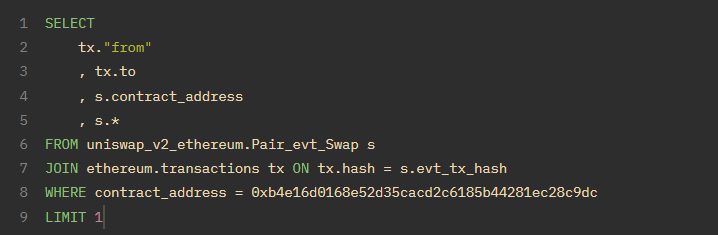
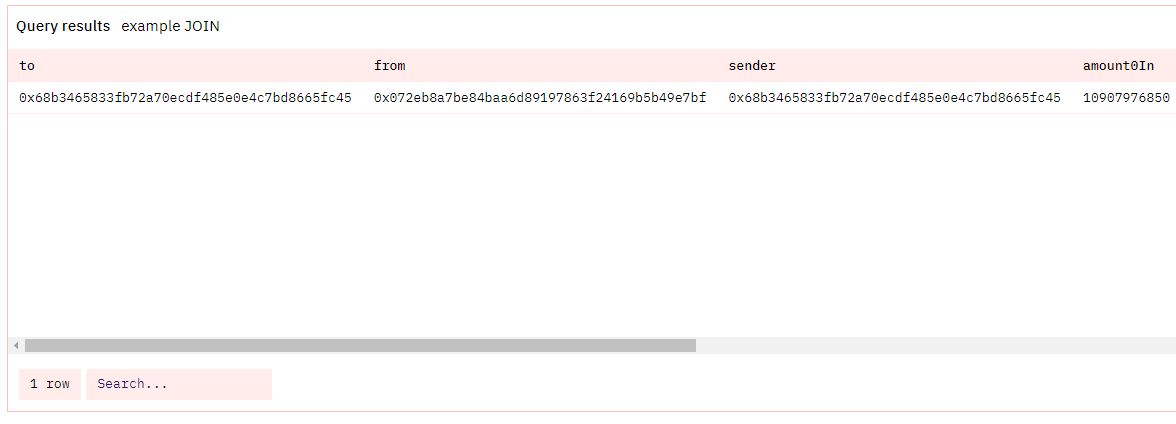
你会发现结果的 sender 与from不同, to 也不等于 USDC/WETH 的池地址。因此,即使名称听起来相似,也不要盲目相信事件/函数列是真相的来源! ?
对于 LEFT JOIN,我最常用的可能是在一组代币地址上连接 tokens.erc20 以获取它们的符号。我将在接下来的 COALESCE() 部分介绍这一点,以及如果没有得到匹配的符号该怎么办。
当涉及到时间序列并需要将它们匹配在一起时,我通常会使用 FULL OUTER JOIN 。你可以在这里找到代币余额的示例。
COALESCE()
在你亲身尝试之前,这个函数并不直观。从本质上讲,它返回你给它的第一个非空值(常量或列)。
SELECT coalesce(null, null, 1); --returns 1
SELECT coalesce(null, 2, null, 32); --returns 2
它可以用来创建一个后备列,或用一些占位常量来填充空值。让我们结合所学知识,看看哪些 ERC20 代币在最近一天的名义价值转移最多。
所有ERC20代币都有一个Transfer事件,因此我们可以将它们放入一个表--erc20_chain.evt_Transfer。我们将获取所有的转账事件,并与 tokens.erc20 表连接,以获得符号和小数。tokens.erc20 表 就像是上传到我们数据库的社区贡献 google 表。
然后,我们对所有唯一的 erc20 代币(通过 contract_address 和符号)进行分组和求和(如果存在连接,则除以小数,默认情况下仅除以 18)。
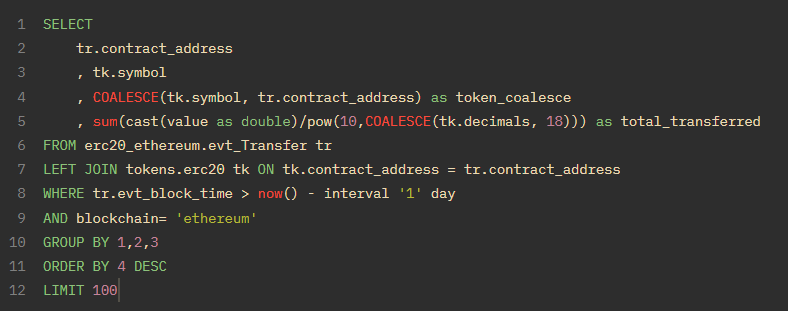
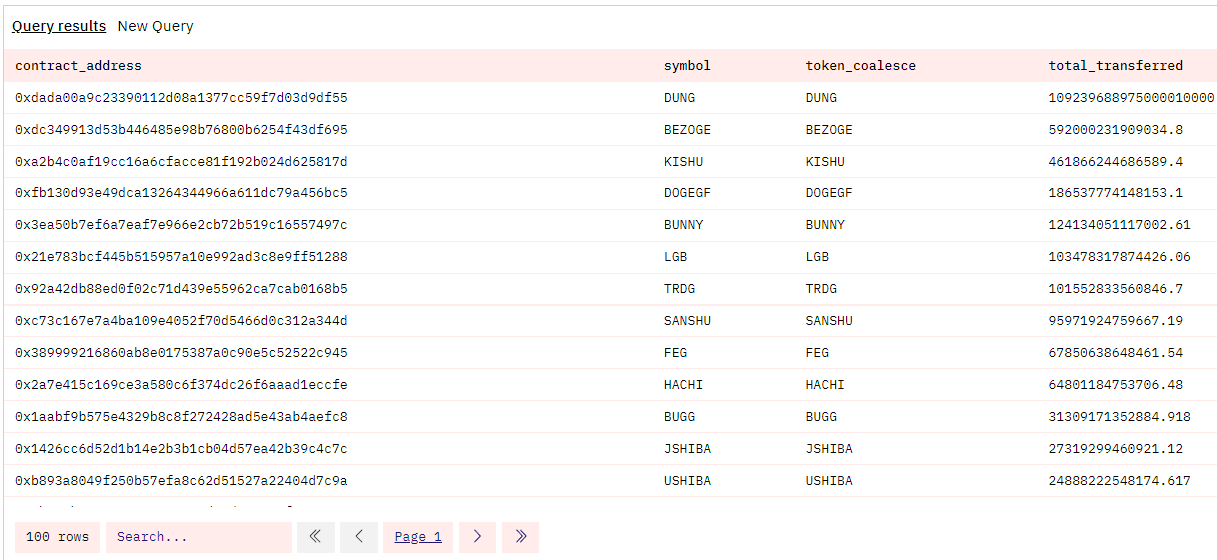
如果这个例子对你有意义,恭喜你做得非常好!如果不明白,请尝试把它分解成几个部分 - 先查询各个表。
try()
try()函数能很好地与数学函数和转换函数搭配使用。如果函数内部的逻辑产生了错误,它将直接返回null。如果运行下面的查询,就会出现错误:
SELECT 1/0 --returns a query error, query will stop running
如果用 try() 运行,结果将是 "空"。
SELECT try(1/0) --returns null
如果使用 coalesce() 来运行,则可以控制回退值。
SELECT coalesce(try(1/0),10) --returns 10
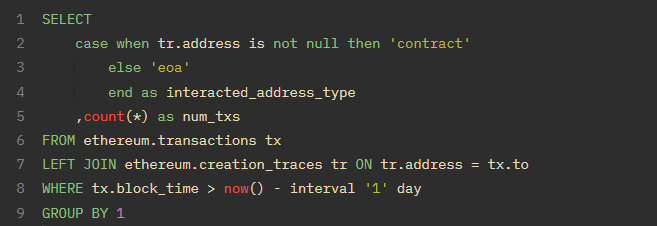
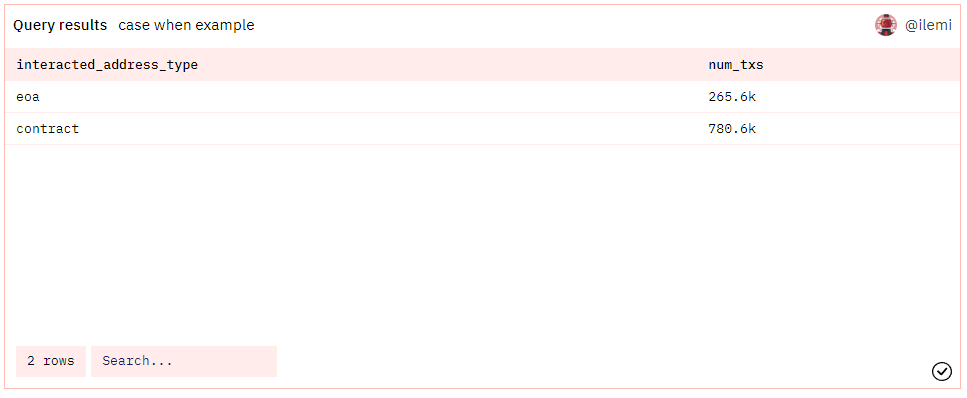
CASE WHEN
一旦你开始对地址类型或交易类型进行分桶或分类,你就会更加依赖 CASE WHEN 操作。我最常做的分类之一是检查地址是合约还是钱包(EOA)。为此,你可以连接 "creation.traces "表并进行 "是否为空 "检查。所有 WHERE 检查在这里都有效。
让我们检查一下在过去一天中有多少交易的to地址是一个合约:
常见字符串操作
今天我将向大家介绍一些常见的字符串运算,这些运算只有在特定情况下才真正有用(但仍然经常出现)。
-
lower()--在对合约名称或确保名称进行字符串比较时非常有用。
-
LIKE '%thing%' - 用于部分字符串匹配。我有时会将其用于Wrap的代币。

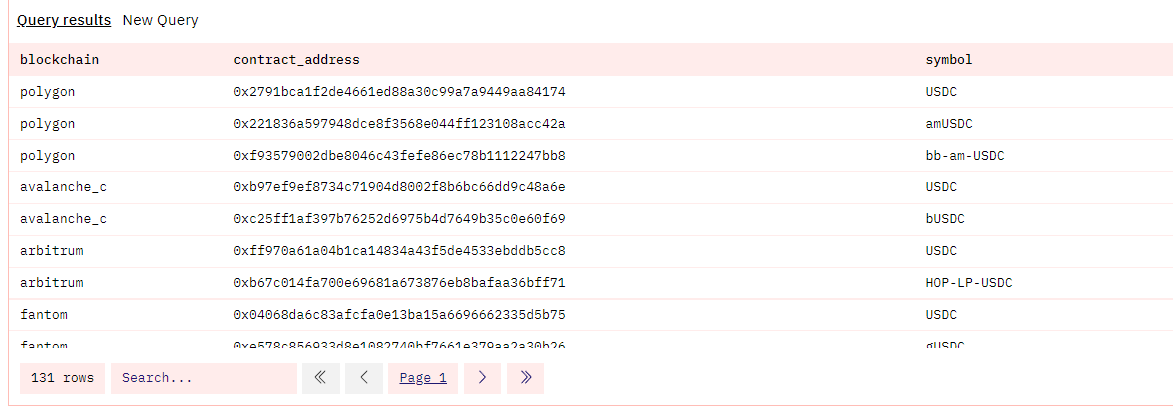
https://dune.com/queries/1781934?d=11
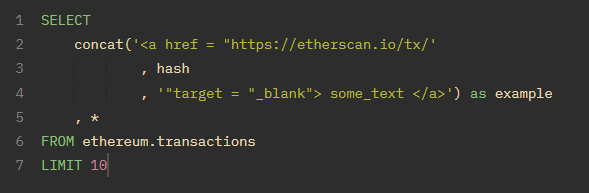
- concat()--该功能可用于创建超链接(可点击的参考文献)或更易读的标记/合约名称。
- substr() - 这对处理原始字节数据很有用。我在一开始的表格示例部分就用它从交易数据中选择函数签名。
小结
在本篇中,我们学习了开始使用Dune 查询所需的所有基本表格导航和 SQL 概念 。
操练起来吧。
本翻译由 DeCert.me 协助支持, 来DeCert码一个未来, 支持每一位开发者构建自己的可信履历。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
