【深度知识】区块链数据库LevelDB从入门到原理详解
本文介绍LevelDB的介绍,性能,框架,核心构件原理,基本操作接口样例。

1.摘要
本文介绍LevelDB的介绍,性能,框架,核心构件原理,基本操作接口样例。
2. LevelDB概述
LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。LevelDB应用了LSM (Log Structured Merge) 策略,lsm_tree对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销。
2.1 特点
1、key和value都是任意长度的字节数组; 2、entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数; 3、提供的基本操作接口:Put()、Delete()、Get()、Batch(); 4、支持批量操作以原子操作进行; 5、可以创建数据全景的snapshot(快照),并允许在快照中查找数据; 6、可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot); 7、自动使用Snappy压缩数据; 8、可移植性;
2.2 限制
1、非关系型数据模型(NoSQL),不支持sql语句,也不支持索引; 2、一次只允许一个进程访问一个特定的数据库; 3、没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;
2.3 性能
LevelDB 是单进程的服务,性能非常之高,在一台4核Q6600的CPU机器上,每秒钟写数据超过40w,而随机读的性能每秒钟超过10w。
下面的性能测试报告基于db_bench程序,结果存在一定干扰,但做为性能评估是足够的。
1.3.1 验证场景
我们使用一个数百万记录的数据库,每条记录的key大小为16字节,value大小为100字节。基准测试的Value大小压缩为原始大小的一半。
LevelDB: version 1.1
Date: Sun May 1 12:11:26 2011
CPU: 4 x Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz
CPUCache: 4096 KB
Keys: 16 bytes each
Values: 100 bytes each (50 bytes after compression)
Entries: 1000000
Raw Size: 110.6 MB (estimated)
File Size: 62.9 MB (estimated)
1.3.2 写性能
“填充”基准测试以顺序或随机顺序创建一个全新的数据库。 每次操作后,“fillsync”基准将数据从操作系统刷新到磁盘(顺序操作); 其他写入操作则利用操作系统缓冲区高速缓存中一段时间。 “覆盖”基准做随机写入,更新数据库中的现有key值记录。
fillseq : 1.765 micros/op; 62.7 MB/s; 56.6W+ OP/S
fillsync : 268.409 micros/op; 0.4 MB/s (10000 ops); 0.37W OP/S
fillrandom : 2.460 micros/op; 45.0 MB/s; 40W+ OP/S
overwrite : 2.380 micros/op; 46.5 MB/s; 42W+ OP/S
"op"是指一次写入一个key/value对。随机写性能大约在40W op/s,“fillsync”操作时间(0.3 millisecond)甚至少于磁盘seek时间(典型时间为10millisecond)。我们怀疑这可能是因为硬盘自身存在缓存(memory),并在数据真正落盘前进行响应。这样做是否安全取决于出现电力故障时,是否来得及将缓存中的数据写入磁盘。
1.3.3 读性能
我们列出了正向和反向方向上顺序读取的性能,以及随机查找的性能。 请注意,基准数据库创建的数据库相当小, 报告中的leveldb性能数据基本是基于内存操作的。 读取操作系统高速缓冲区中不存在的数据时,将额外执行1-2次磁盘查找动作。 写性能基本不受数据是否在内存中的影响。
readrandom : 16.677 micros/op; (approximately 60,000 reads per second)
readseq : 0.476 micros/op; 232.3 MB/s; 210W+ op/s
readreverse : 0.724 micros/op; 152.9 MB/s; 138W+ op/s
LevelDB在后台压缩其底层存储数据,以提高读取性能。 上面列出的结果是在大量随机写作之后立即进行的。 压缩后的结果(通常自动触发)更好。
readrandom : 11.602 micros/op; (approximately 85,000 reads per second)
readseq : 0.423 micros/op; 261.8 MB/s; 236W+ op/s
readreverse : 0.663 micros/op; 166.9 MB/s; 150W+ op/s
其中,某些读操作由于重复读取磁盘并解压缩以致耗时较长。我们为leveldb提供足够的缓存,以便可以将未压缩的块保存在内存中,则读取性能再次提高:
readrandom : 9.775 micros/op; (approximately 100,000 reads per second before compaction)
readrandom : 5.215 micros/op; (approximately 190,000 reads per second after compaction)
对于典型的数据库操作,基本为随机读、写,整理下上述关键性能数据:
fillrandom : 2.460 micros/op; 45.0 MB/s; 40W+ OP/S
readrandom : 9.775 micros/op; (approximately 100,000 reads per second before compaction)
readrandom : 5.215 micros/op; (approximately 190,000 reads per second after compaction)
随机写的性能大致为40W+ op/s,读在数据压缩完成后性能最佳为19W+ op/s,运行时的实时读性能大约为10W+ op/s。
3. LevelDB框架
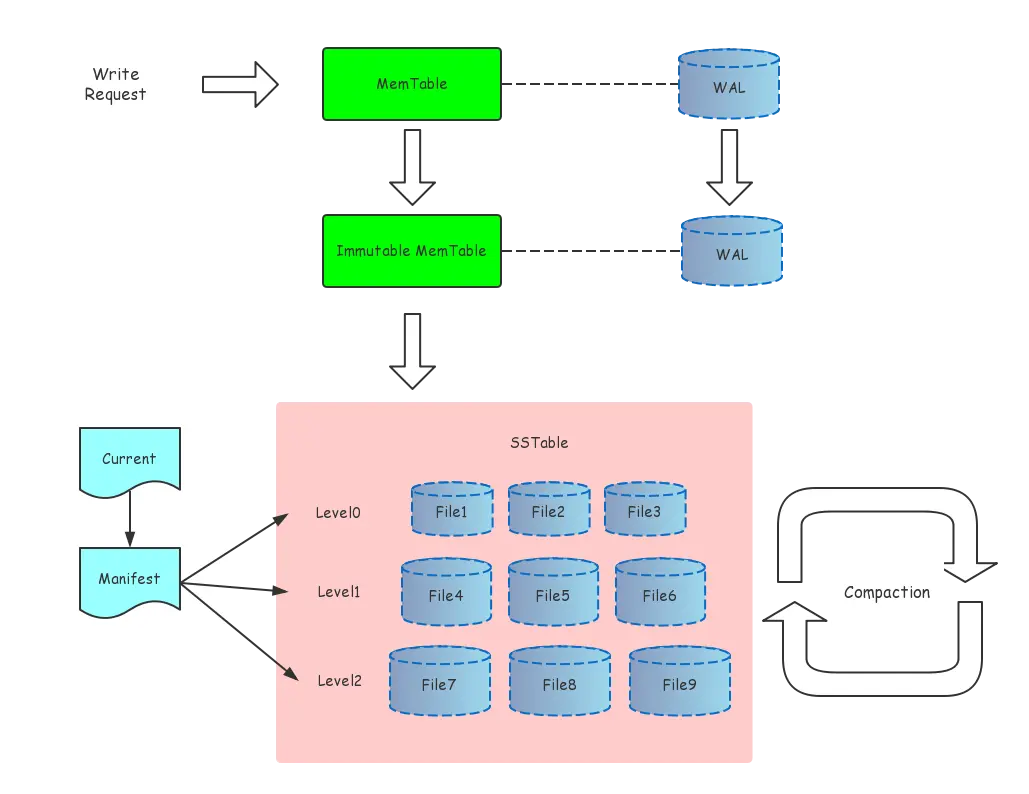
上图简单展示了 LevelDB 的整体架构。LevelDB 的静态结构主要由六个部分组成: MemTable(wTable):内存数据结构,具体实现是 SkipList。 接受用户的读写请求,新的数据修改会首先在这里写入。 Immutable MemTable(rTable):当 MemTable 的大小达到设定的阈值时,会变成 Immutable MemTable,只接受读操作,不再接受写操作,后续由后台线程 Flush 到磁盘上。 SST Files:Sorted String Table Files,磁盘数据存储文件。分为 Level0 到 LevelN 多层,每一层包含多个 SST 文件,文件内数据有序。Level0 直接由 Immutable Memtable Flush 得到,其它每一层的数据由上一层进行 Compaction 得到。 Manifest Files:Manifest 文件中记录 SST 文件在不同 Level 的分布,单个 SST 文件的最大、最小 key,以及其他一些 LevelDB 需要的元信息。由于 LevelDB 支持 snapshot,需要维护多版本,因此可能同时存在多个 Manifest 文件。 Current File:由于 Manifest 文件可能存在多个,Current 记录的是当前的 Manifest 文件名。 Log Files (WAL):用于防止 MemTable 丢数据的日志文件。
粗箭头表示写入数据的流动方向: (1) 先写入 MemTable。 (2) MemTable 的大小达到设定阈值的时候,转换成 Immutable MemTable。 (3) Immutable Table 由后台线程异步 Flush 到磁盘上,成为 Level0 上的一个 sst 文件。 (4) 在某些条件下,会触发后台线程对 Level0 ~ LevelN 的文件进行 Compaction。
读操作的流动方向和写操作类似: (1) 读 MemTable,如果存在,返回。 (2) 读 Immutable MemTable,如果存在,返回。 (3) 按顺序读 Level0 ~ Leveln,如果存在,返回。 (4) 返回不存在。
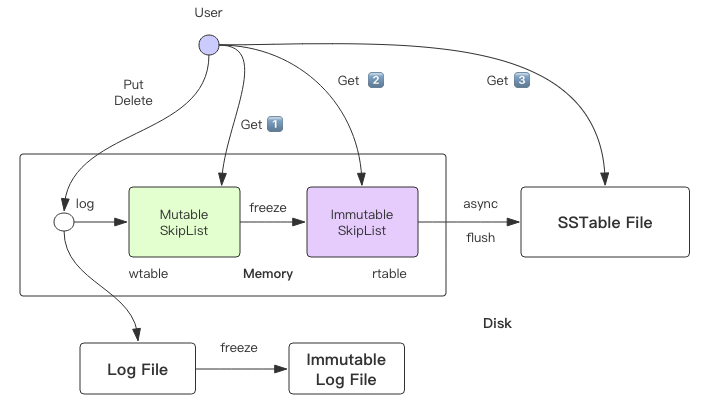
全程的操作流程如下描述: MemTable(wTable)的大小达到一个阈值,LevelDB 将它凝固成只读的Immutable MemTable(rTable),同时生成一个新的 wtable 继续接受写操作。rtable 将会被异步线程刷到磁盘中。Get 操作会优先查询 wtable,如果找不到就去 rtable 中去找,rtable 如果还找不到,再去磁盘文件里去找。
因为 wtable 要支持多线程读写,所以访问它是需要加锁控制。而 rtable 是只读的,它就不需要,但是它的存在时间很短,rtable 一旦生成,很快就会被异步线程序列化到磁盘上,然后就会被置空。但是异步线程序列化也需要耗费一定的时间,如果 wtable 增长过快,很快就被写满了,这时候 rtable 还没有完成序列化,而wtable 急需变身怎么办?这时写线程就会阻塞等待异步线程序列化完成,这是 LevelDB 的卡顿点之一,也是未来 RocksDB 的优化点。
图中还有个日志文件,记录了近期的写操作日志。如果 LevelDB 遇到突发停机事故,没有持久化的 wtable 和 rtable 数据就会丢失。这时就必须通过重放日志文件中的指令数据来恢复丢失的数据。注意到日志文件也是有两份的,它和内存的跳跃列表正好对应起来。当 wtable 要变身时,日志文件也会跟着变身。待 rtable 落盘成功之后,只读日志文件就可以被删除了。
4. LevelDB基础部件
4.1 跳跃表SkipList
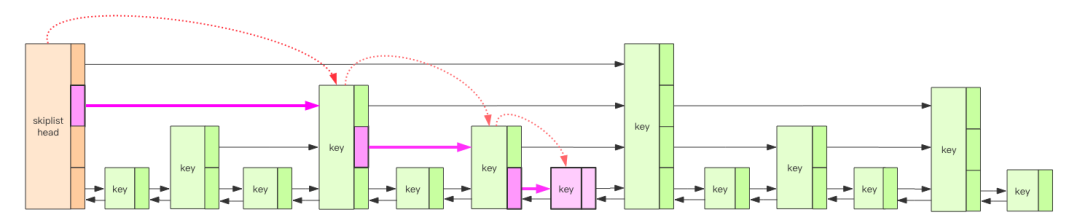
LevelDB 的内存中维护了 2 个跳跃列表,一个是只读的Immutable MemTable(rTable) ,一个是可修改的MemTable(wTable)。简单理解,跳跃列表就是一个 Key 有序的 Set 集合,排序规则由全局的「比较器」决定,默认是字典序。跳跃列表的查找和更新操作时间复杂度都是 Log(n)。
跳跃表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳跃表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳跃表的插入和删除的工作是比较简单的。
(1)跳跃表的核心思想
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。

如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

这基本上就是跳跃表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
(2)跳跃表的数据存储模型 我们定义: 如果一个基点存在k个向前的指针的话,那么该节点是k层的节点。 一个跳跃表的层MaxLevel义为跳跃表中所有节点中最大的层数。 下面给出一个完整的跳跃表的图示:

那么我们该如何将该数据结构使用二进制存储呢?通过上面的跳跃表很容易设计这样的数据结构,定义每个节点类型:
// 这里仅仅是一个指针
typedef struct nodeStructure *node;
typedef struct nodeStructure
{
keyType key; // key值
valueType value; // value值
// 向前指针数组,根据该节点层数的
// 不同指向不同大小的数组
node forward[1];
};
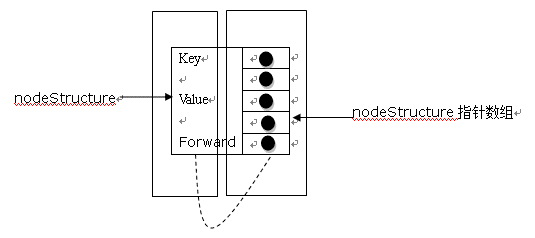
上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的forward将指向一个只含一个元素的数组,以此类推。
// 定义跳跃表数据类型
typedef struct listStructure{
int level; /* Maximum level of the list
(1 more than the number of levels in the list) */
struct nodeStructure * header; /* pointer to header */
} * list;
跳跃表数据类型中包含了维护跳跃表的必要信息,level表明跳跃表的层数,header如下所示:
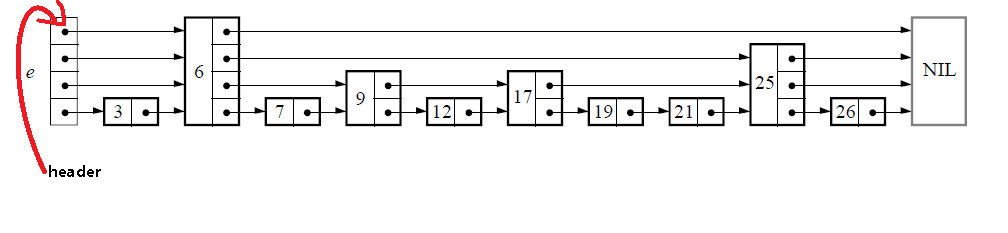
定义辅助变量:
定义上图中的NIL变量:node NIL;
#define MaxNumberOfLevels 16
#define MaxLevel (MaxNumberOfLevels-1)
定义辅助方法:
// newNodeOfLevel生成一个nodeStructure结构体,同时生成l个node *数组指针
#define newNodeOfLevel(l) (node)malloc(sizeof(struct nodeStructure)+(l)*sizeof(node *))
好的基本的数据结构定义已经完成,接下来来分析对于跳跃表的一个操作。
(3)跳跃表初始化
初始化的过程很简单,仅仅是生成下图中红线区域内的部分,也就是跳跃表的基础结构:
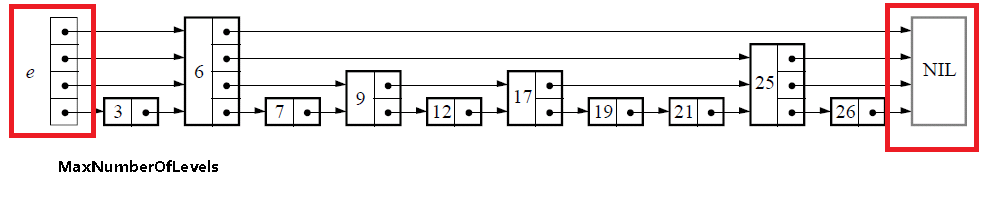
list newList()
{
list l;
int i;
// 申请list类型大小的内存
l = (list)malloc(sizeof(struct listStructure));
// 设置跳跃表的层level,初始的层为0层(数组从0开始)
l->level = 0;
// 生成header部分
l->header = newNodeOfLevel(MaxNumberOfLevels);
// 将header的forward数组清空
for(i=0;i<MaxNumberOfLevels;i++) l->header->forward[i] = NIL;
return(l);
};
(4)插入操作 由于跳跃表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳跃表的level变量。
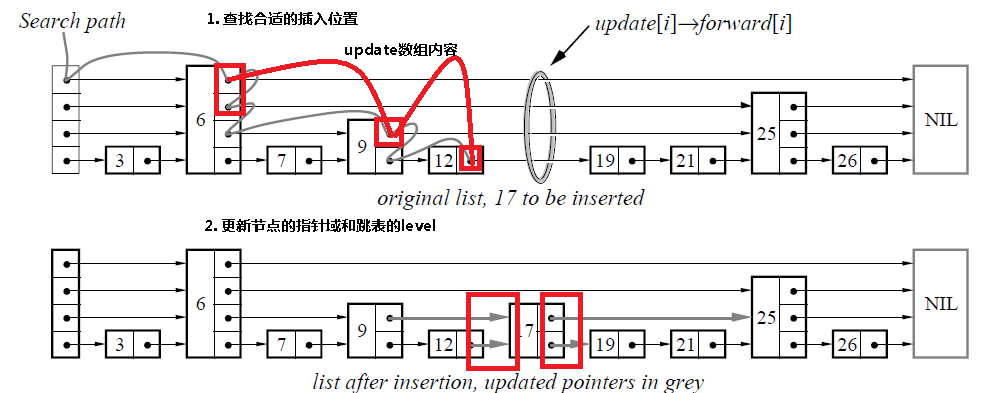
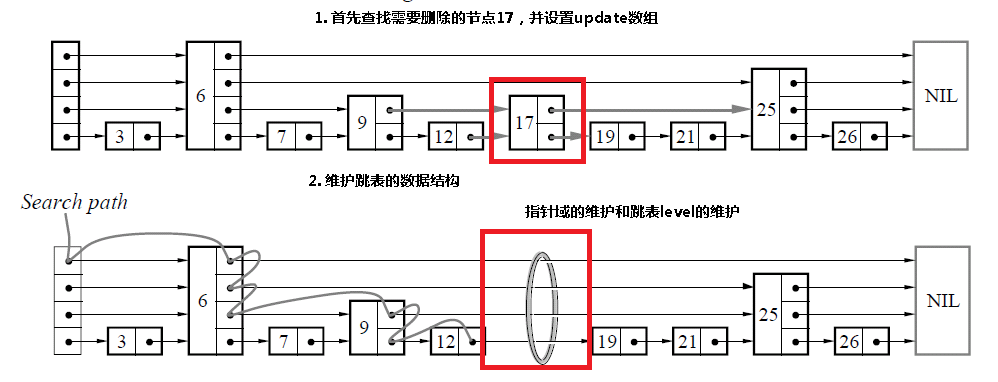
(5)删除某个节点 和插入是相同的,首先查找需要删除的节点,如果找到了该节点的话,那么只需要更新指针域,如果跳跃表的level需要更新的话,进行更新。
4.2 SSTable
LevelDB 的键值对内容都存储在扩展名为 sst 的 SSTable 文件中。
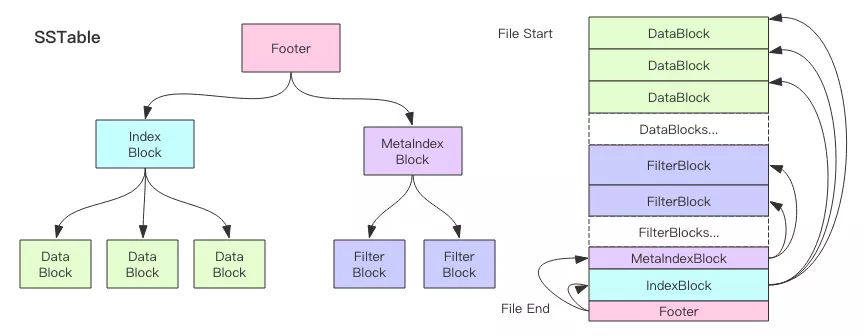
SSTable 文件的内容分为 5 个部分,Footer、IndexBlock、MetaIndexBlock、FilterBlock 和 DataBlock。其中存储了键值对内容的就是 DataBlock,存储了布隆过滤器二进制数据的是 FilterBlock,DataBlock 有多个,FilterBlock 也可以有多个,但是通常最多只有 1 个,之所以设计成多个是考虑到扩展性,也许未来会支持其它类型的过滤器。另外 3 个部分为管理块,其中 IndexBlock 记录了 DataBlock 相关的元信息,MetaIndexBlock 记录了过滤器相关的元信息,而 Footer 则指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部。
4.2.1 Footer 结构
它的占用空间很小只有 48 字节,内部只存了几个字段。下面我们用伪代码来描述一下它的结构
// 定义了数据块的位置和大小
struct BlockHandler {
varint offset;
varint size;
}
struct Footer {
BlockHandler metaIndexHandler; // MetaIndexBlock的文件偏移量和长度
BlockHandler indexHandler; // IndexBlock的文件偏移量和长度
byte[n] padding; // 内存垫片
int32 magicHighBits; // 魔数后32位
int32 magicLowBits; // 魔数前32位
}
Footer 结构的中间部分增加了内存垫片,其作用就是将 Footer 的空间撑到 48 字节。结构的尾部还有一个 64位的魔术数字 0xdb4775248b80fb57,如果文件尾部的 8 字节不是这个数字说明文件已经损坏。这个魔术数字的来源很有意思,它是下面返回的字符串的前64bit。
$ echo http://code.google.com/p/leveldb/ | sha1sumdb4775248b80fb57d0ce0768d85bcee39c230b61
IndexBlock 和 MetaIndexBlock 都只有唯一的一个,所以分别使用一个 BlockHandler 结构来存储偏移量和长度。
4.2.2 Block 结构
除了 Footer 之外,其它部分都是 Block 结构,在名称上也都是以 Block 结尾。所谓的 Block 结构是指除了内部的有效数据外,还会有额外的压缩类型字段和校验码字段。
struct Block { byte[] data; int8 compressType; int32 crcValue;}
每一个 Block 尾部都会有压缩类型和循环冗余校验码(crcValue),这会要占去 5 字节。如果是压缩类型,块内的数据 data 会被压缩。校验码会针对压缩和的数据和压缩类型字段一起计算循环冗余校验和。压缩算法默认是 snappy ,校验算法是 crc32。
crcValue = crc32(data, compressType)
在下面介绍的所有 Block 结构中,我们不再提及压缩和校验码。
4.2.3 DataBlock 结构
DataBlock 的大小默认是 4K 字节(压缩前),里面存储了一系列键值对。前面提到 sst 文件里面的 Key 是有序的,这意味着相邻的 Key 会有很大的概率有共同的前缀部分。正是考虑到这一点,DataBlock 在结构上做了优化,这个优化可以显著减少存储空间。
Key = sharedKey + unsharedKey
Key 会划分为两个部分,一个是 sharedKey,一个是 unsharedKey。前者表示相对基准 Key 的共同前缀内容,后者表示相对基准 Key 的不同后缀部分。
比如基准 Key 是 helloworld,那么 hellouniverse 这个 Key 相对于基准 Key 来说,它的 sharedKey 就是 hello,unsharedKey 就是 universe。
DataBlock 中存储的是连续的一系列键值对,它会每隔若干个 Key 设置一个基准 Key。基准 Key 的特点就是它的 sharedKey 部分是空串。基准 Key 的位置,也就是它在块中的偏移量我们称之为「重启点」RestartPoint,在 DataBlock 中会记录所有「重启点」位置。第一个「重启点」的位置是零,也就是 DataBlock 中的第一个 Key。
struct Entry {
varint sharedKeyLength;
varint unsharedKeyLength;
varint valueLength;
byte[] unsharedKeyContent;
byte[] valueContent;
}
struct DataBlock {
Entry[] entries;
int32 [] restartPointOffsets;
int32 restartPointCount;
}
DataBlock 中基准 Key 是默认每隔 16 个 Key 设置一个。从节省空间的角度来说,这并不是一个智能的策略。比如连续 26 个 Key 仅仅是最后一个字母不同,DataBlock 却每隔 16 个 Key 强制「重启」,这明显不是最优的。这同时也意味着 sharedKey 是空串的 Key 未必就是基准 Key。
一个 DataBlock 的默认大小只有 4K 字节,所以里面包含的键值对数量通常只有几十个。如果单个键值对的内容太大一个 DataBlock 装不下咋整?
这里就必须纠正一下,DataBlock 的大小是 4K 字节,并不是说它的严格大小,而是在追加完最后一条记录之后发现超出了 4K 字节,这时就会再开启一个 DataBlock。这意味着一个 DataBlock 可以大于 4K 字节,如果 value 值非常大,那么相应的 DataBlock 也会非常大。DataBlock 并不会将同一个 Value 值分块存储。
4.2.4 FilterBlock 结构
如果没有开启布隆过滤器,FilterBlock 这个块就是不存在的。FilterBlock 在一个 SSTable 文件中可以存在多个,每个块存放一个过滤器数据。不过就目前 LevelDB 的实现来说它最多只能有一个过滤器,那就是布隆过滤器。
布隆过滤器用于加快 SSTable 磁盘文件的 Key 定位效率。如果没有布隆过滤器,它需要对 SSTable 进行二分查找,Key 如果不在里面,就需要进行多次 IO 读才能确定,查完了才发现原来是一场空。布隆过滤器的作用就是避免在 Key 不存在的时候浪费 IO 操作。通过查询布隆过滤器可以一次性知道 Key 有没有可能在里面。
单个布隆过滤器中存放的是一个定长的位图数组,该位图数组中存放了若干个 Key 的指纹信息。这若干个 Key 来源于 DataBlock 中连续的一个范围。FilterBlock 块中存在多个连续的布隆过滤器位图数组,每个数组负责指纹化 SSTable 中的一部分数据。
struct FilterEntry {
byte[] rawbits;
}
struct FilterBlock {
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系数
}
其中 baseLg 默认 11,表示每隔 2K 字节(2<<11)的 DataBlock 数据(压缩后),就开启一个布隆过滤器来容纳这一段数据中 Key 值的指纹。如果某个 Value 值过大,以至于超出了 2K 字节,那么相应的布隆过滤器里面就只有 1 个 Key 值的指纹。每个 Key 对应的指纹空间在打开数据库时指定。
// 每个 Key 占用 10bit 存放指纹信息
options.SetFilterPolicy(levigo.NewBloomFilter(10))
这里的 2K 字节的间隔是严格的间隔,这样才可以通过 DataBlock 的偏移量和大小来快速定位到相应的布隆过滤器的位置 FilterOffset,再进一步获得相应的布隆过滤器位图数据。
4.4.5 MetaIndexBlock 结构
MetaIndexBlock 存储了前面一系列 FilterBlock 的元信息,它在结构上和 DataBlock 是一样的,只不过里面 Entry 存储的 Key 是带固定前缀的过滤器名称,Value 是对应的 FilterBlock 在文件中的偏移量和长度。
key = "filter." + filterName// value 定义了数据块的位置和大小
struct BlockHandler { varint offset; varint size;}
就目前的 LevelDB,这里面最多只有一个 Entry,那么它的结构非常简单,如下图所示
4.4.6 IndexBlock 结构
它和 MetaIndexBlock 结构一样,也存储了一系列键值对,每一个键值对存储的是 DataBlock 的元信息,SSTable 中有几个 DataBlock,IndexBlock 中就有几个键值对。键值对的 Key 是对应 DataBlock 内部最大的 Key,Value 是 DataBlock 的偏移量和长度。不考虑 Key 之间的前缀共享,不考虑「重启点」,它的结构如下图所示
4.5 日志文件(LOG)
"LOG文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。"
4.5.1 日志数据结构
日志中的每条记录由Record Header + Record Content组成,其中Header大小为kHeaderSize(7字节),由CRC(4字节) + Size(2字节) + Type(1字节)三部分组成。除此之外才是content的真正内容:

日志文件的基础部件很简单,只需要能够创建文件、追加操作、实时刷新数据即可。为了做到跨平台、解耦,LevelDB还是对此做了封装。Leveldb命名空间下,有一个名为log的子命名空间,其下有Writer、Reader两个实现类。按前几节的命名规则,Writer其实是一个Builder,它对外提供了唯一的AddRecord方法用于追加操作记录。
4.5.2 Writer
在log命名空间中,包含一个Writer用于日志操作,其只有一个Append方法,这和日志的定位相同,定义如下:
class Writer
{
explicit Writer(WritableFile *dest);
Writer(WritableFile *dest, uint64_t dest_length);
...
Status AddRecord(const Slice &slice);
...
};
外部创建一个WritableFile,通过构造函数传递给Writer。AddRecord按上述的结构完善record并添加到日志文件中。
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
do {
//1. 当前块剩余大小
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
//2. 剩余大小不足,占位
if (leftover < kHeaderSize)
{
// Switch to a new block
if (leftover > 0)
{
// Fill the trailer (literal below relies on kHeaderSize being 7)
assert(kHeaderSize == 7);
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
block_offset_ = 0;
}
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
//3. 当前块存储的空间大小
const size_t fragment_length = (left < avail) ? left : avail;
//4. Record Type
RecordType type;
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
}
else if (begin) {
type = kFirstType;
}
else if (end) {
type = kLastType;
}
else {
type = kMiddleType;
}
//5. 写入文件
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}
当前Block剩余大小不足以填充Record Header时,以"\x00\x00\x00\x00\x00\x00"占位。 当Block无法完整记录一条Record时,通过type信息标识该record在当前block中的区块信息,以便读取时可根据type拼接出完整的record。 EmitPhysicalRecord向Block中插入Record数据,每条记录append之后会执行一次flush。
4.5.3 创建日志的时机
在LevelDB中,日志文件和memtable是配对的,在任何数据写入Memtable之前都会先写入日志文件。除此之外,日志文件别无它用。
因此,日志文件的创建时和Memtable的创建时机也必然一致,这点对于我们理解日志文件至关重要。那么,Memtable在何时会创建呢?
4.5.3.1 数据库启动
如果我们创建了一个新数据库,或者数据库上次运行的所有日志都已经归档到Level0状态。此时,需要为本次数据库进程创建新的Memtable以及日志文件,代码逻辑如下:
Status DB::Open(const Options &options, const std::string &dbname,
DB **dbptr)
{
*dbptr = NULL;
//创建新的数据库实例
DBImpl *impl = new DBImpl(options, dbname);
impl->mutex_.Lock();
VersionEdit edit;
//恢复到上一次关闭时的状态
// Recover handles create_if_missing, error_if_exists
bool save_manifest = false;
Status s = impl->Recover(&edit, &save_manifest);
if (s.ok() && impl->mem_ == NULL)
{
//创建新的memtable及日志文件
// Create new log and a corresponding memtable.
//分配日志文件编号及创建日志文件
uint64_t new_log_number = impl->versions_->NewFileNumber();
WritableFile *lfile;
s = options.env->NewWritableFile(LogFileName(dbname, new_log_number),
&lfile);
if (s.ok())
{
edit.SetLogNumber(new_log_number);
impl->logfile_ = lfile;
impl->logfile_number_ = new_log_number;
//文件交由log::Writer做追加操作
impl->log_ = new log::Writer(lfile);
//创建MemTable
impl->mem_ = new MemTable(impl->internal_comparator_);
impl->mem_->Ref();
}
}
......
}
创建日志文件前,需要先给日志文件起一个名字,此处使用日志编号及数据库名称拼接而成,例如:
数据库名称为AiDb,编号为324时,日志文件名称为AiDb000324.log
4.5.3.2 插入数据
如果插入数据时,当前的memtable容量达到设定的options_.write_buffer_size,此时触发新的memtable创建,并将之前的memtable转为imm,同时构建新的日志文件。
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile *lfile = NULL;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok())
{
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
//创建日志文件
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.Release_Store(imm_);
//创建memtable
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
MaybeScheduleCompaction();
4.5.3.3 数据库恢复
数据库启动时首先完成数据库状态恢复,日志恢复过程中,如果为最后一个日志文件,且配置为日志重用模式(options_.reuse_logs=true)时,创建新的日志文件。但和其他场景不同的是,这里的日志文件是“继承性”的,也就是说部分内容是上次遗留下来的。来看实现:
// See if we should keep reusing the last log file.
if (status.ok() && options_.reuse_logs && last_log && compactions == 0)
{
assert(logfile_ == NULL);
assert(log_ == NULL);
assert(mem_ == NULL);
uint64_t lfile_size;
if (env_->GetFileSize(fname, &lfile_size).ok() &&
env_->NewAppendableFile(fname, &logfile_).ok())
{
Log(options_.info_log, "Reusing old log %s \n", fname.c_str());
log_ = new log::Writer(logfile_, lfile_size);
logfile_number_ = log_number;
if (mem != NULL)
{
mem_ = mem;
mem = NULL;
}
else
{
// mem can be NULL if lognum exists but was empty.
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
}
}
}
4.6 版本控制
LevelDB如何能够知道每一层有哪些SST文件;如何快速的定位某条数据所在的SST文件;重启后又是如何恢复到之前的状态的,等等这些关键的问题都需要依赖元信息管理模块。对其维护的信息及所起的作用简要概括如下:
- 记录Compaction相关信息,使得Compaction过程能在需要的时候被触发;
- 维护SST文件索引信息及层次信息,为整个LevelDB的读、写、Compaction提供数据结构支持;
- 负责元信息数据的持久化,使得整个库可以从进程重启或机器宕机中恢复到正确的状态;
- 记录LogNumber,Sequence,下一个SST文件编号等状态信息; 以版本的方式维护元信息,使得Leveldb内部或外部用户可以以快照的方式使用文件和数据。
LeveDB用Version表示一个版本的元信息,Version中主要包括一个FileMetaData指针的二维数组,分层记录了所有的SST文件信息。FileMetaData数据结构用来维护一个文件的元信息,包括文件大小,文件编号,最大最小值,引用计数等,其中引用计数记录了被不同的Version引用的个数,保证被引用中的文件不会被删除。除此之外,Version中还记录了触发Compaction相关的状态信息,这些信息会在读写请求或Compaction过程中被更新。可以知道在CompactMemTable和BackgroundCompaction过程中会导致新文件的产生和旧文件的删除。每当这个时候都会有一个新的对应的Version生成,并插入VersionSet链表头部。
VersionSet是一个Version构成的双向链表,这些Version按时间顺序先后产生,记录了当时的元信息,链表头指向当前最新的Version,同时维护了每个Version的引用计数,被引用中的Version不会被删除,其对应的SST文件也因此得以保留,通过这种方式,使得LevelDB可以在一个稳定的快照视图上访问文件。VersionSet中除了Version的双向链表外还会记录一些如LogNumber,Sequence,下一个SST文件编号的状态信息。
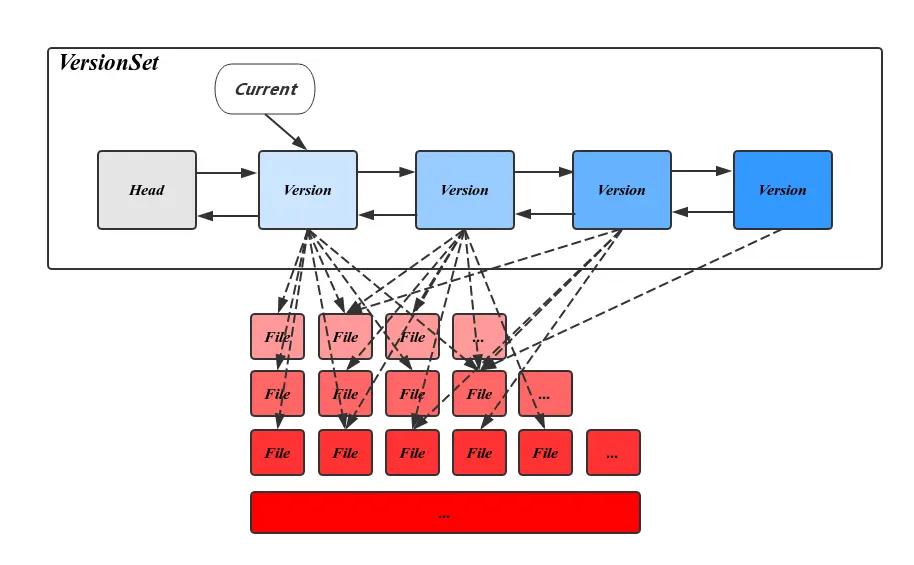
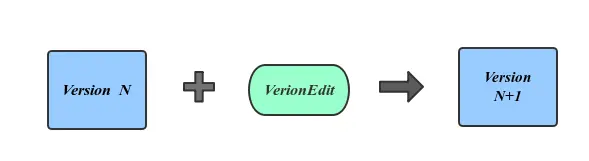
通过上面的描述可以看出,相邻Version之间的不同仅仅是一些文件被删除另一些文件被删除。也就是说将文件变动应用在旧的Version上可以得到新的Version,这也就是Version产生的方式。LevelDB用VersionEdit来表示这种相邻Version的差值。
为了避免进程崩溃或机器宕机导致的数据丢失,LevelDB需要将元信息数据持久化到磁盘,承担这个任务的就是Manifest文件。可以看出每当有新的Version产生都需要更新Manifest,很自然的发现这个新增数据正好对应于VersionEdit内容,也就是说Manifest文件记录的是一组VersionEdit值,在Manifest中的一次增量内容称作一个Block,其内容如下:
Manifest Block := N * Item
Item := [kComparator] comparator
or [kLogNumber] 64位log_number
or [kPrevLogNumber] 64位pre_log_number
or [kNextFileNumber] 64位next_file_number_
or [kLastSequence] 64位last_sequence_
or [kCompactPointer] 32位level + 变长的key
or [kDeletedFile] 32位level + 64位文件号
or [kNewFile] 32位level + 64位 文件号 + 64位文件长度 + smallest key + largest key
可以看出恢复元信息的过程也变成了依次应用VersionEdit的过程,这个过程中有大量的中间Version产生,但这些并不是我们所需要的。LevelDB引入VersionSet::Builder来避免这种中间变量,方法是先将所有的VersoinEdit内容整理到VersionBuilder中,然后一次应用产生最终的Version,这种实现上的优化如下图所示:
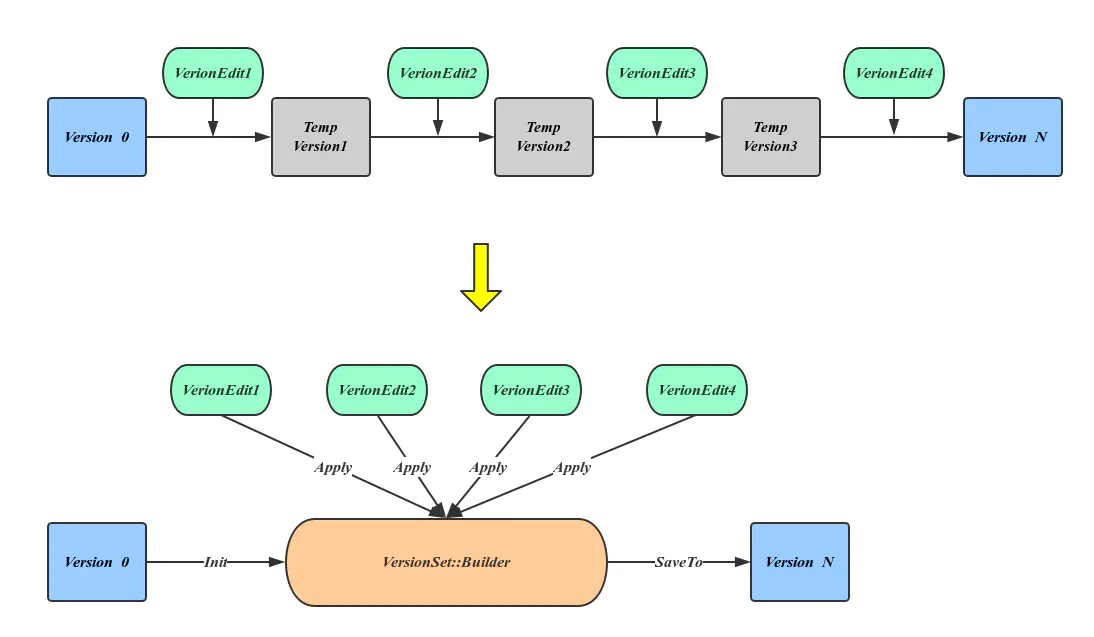
在这一节中,我们依次看到了LevelDB版本控制中比较重要的几个角色:Version、FileMetaData、VersionSet、VersionEdit、Manifest和Version::Builder。
版本信息有什么用?先来简要说明三个类的具体用途: Version:代表了某一时刻的数据库版本信息,版本信息的主要内容是当前各个Level的SSTable数据文件列表。 VersionSet:维护了一份Version列表,包含当前Alive的所有Version信息,列表中第一个代表数据库的当前版本。 VersionEdit:表示Version之间的变化,相当于delta 增量,表示有增加了多少文件,删除了文件。Version0 +VersionEdit-->Version1。VersionEdit会保存到MANIFEST文件中,当做数据恢复时就会从MANIFEST文件中读出来重建数据。那么,何时会触发版本变迁呢?Compaction。
具体而言: Version版本信息记录了运行期一组编号信息,该信息被序列化到Manifest文件中,当数据库再次打开时可恢复至上一次的运行状态。 版本信息记录了SSTable信息,包括每个文件所属的层级、大小、编号(名称等); VersionSet类组提供了查询SSTable信息功能,如每层文件的列表、数量;同时数据库的Get方法中如需通过文件查找key值数据时,也由Version类组完成。最后,SSTable的缓存机制也有Version类组提供。 版本信息提供了Compaction支持。 每个LevelDB有一个Current File,Current File内唯一的信息为:当前数据库的Manifest文件名。Manifest中包含了上次运行后全部的版本信息,LevelDB通过Manifest文件恢复版本信息。
LevelDB的版本信息为富语义功能组,它所包含的信息已经大大超出了版本定义本身。如果将Version类封装为结构体、VersionSet仅仅为Version列表、VersionEdit也是单纯的结构数据,再为上述结构提供多套功能类应该更为合理。目前来看,这应当算作LevelDB实现的一处臭味。
5. LevelDB基本操作接口
5.1 例子
#include <iostream>
#include <cassert>
#include "leveldb/db.h"
#include "leveldb/write_batch.h"
int main()
{
// Open a database.
leveldb::DB* db;
leveldb::Options opts;
opts.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(opts, "./testdb", &db);
assert(status.ok());
// Write data.
status = db->Put(leveldb::WriteOptions(), "name", "jinhelin");
assert(status.ok());
// Read data.
std::string val;
status = db->Get(leveldb::ReadOptions(), "name", &val);
assert(status.ok());
std::cout << val << std::endl;
// Batch atomic write.
leveldb::WriteBatch batch;
batch.Delete("name");
batch.Put("name0", "jinhelin0");
batch.Put("name1", "jinhelin1");
batch.Put("name2", "jinhelin2");
batch.Put("name3", "jinhelin3");
batch.Put("name4", "jinhelin4");
batch.Put("name5", "jinhelin5");
batch.Put("name6", "jinhelin6");
batch.Put("name7", "jinhelin7");
batch.Put("name8", "jinhelin8");
batch.Put("name9", "jinhelin9");
status = db->Write(leveldb::WriteOptions(), &batch);
assert(status.ok());
// Scan database.
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
std::cout << it->key().ToString() << ": " <<
it->value().ToString() << std::endl;
}
assert(it->status().ok());
// Range scan, example: [name3, name8)
for (it->Seek("name3");
it->Valid() && it->key().ToString() < "name8";
it->Next()) {
std::cout << it->key().ToString() << ": " <<
it->value().ToString() << std::endl;
}
// Close a database.
delete db;
}
这个例子简单介绍了 LevelDB 的基本用法,包括:
- 打开数据库。
- 写入一条数据。
- 读取一条数据。
- 批量原子操作。
- 范围查找。
- 关闭数据库。
5.2 打开数据库
// Open a database.
leveldb::DB* db;
leveldb::Options opts;
opts.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(opts, "./testdb", &db);
assert(status.ok());
打开 LevelDB 数据库需要三个参数:
-
**leveldb::Options **:控制 DB 行为的一些参数,具体可以参考链接指向的代码。在这里
create_if_missing为true表示如果数据库./testdb存在就直接打开,不存在就创建。 -
** ./testdb** :LevelDB 数据库的根目录。一个 LevelDB 数据库存放在一个目录下。
-
&db :用来返回一个 LevelDB 实例。
-
leveldb::Status :封装了 leveldb 接口返回的详细信息。
5.3 写入一条数据
// Write data.
status = db->Put(leveldb::WriteOptions(), "name", "jinhelin");
assert(status.ok());
Put 接口的三个参数:
- leveldb::WriteOptions :目前里面只有一个
sync成员。表示写完 WAL 后是否需要 flush。 - 另外两个参数分别是本次写入数据的 Key 和 Value。
5.4 读取一条数据
// Read data.
std::string val;
status = db->Get(leveldb::ReadOptions(), "name", &val);
assert(status.ok());
std::cout << val << std::endl;
Get 接口和 Put 接口比较像,除了leveldb::ReadOptions参数是用来控制读操作的,具体见链接指向的代码。
5.5 批量原子修改
// Batch atomic write.
leveldb::WriteBatch batch;
batch.Delete("name");
batch.Put("name0", "jinhelin0");
batch.Put("name1", "jinhelin1");
batch.Put("name2", "jinhelin2");
batch.Put("name3", "jinhelin3");
batch.Put("name4", "jinhelin4");
batch.Put("name5", "jinhelin5");
batch.Put("name6", "jinhelin6");
batch.Put("name7", "jinhelin7");
batch.Put("name8", "jinhelin8");
batch.Put("name9", "jinhelin9");
status = db->Write(leveldb::WriteOptions(), &batch);
assert(status.ok());
LevelDB 的 Write 接口支持原子地修改多条数据,主要参数是leveldb::WriteBatch
5.6 范围查找
// Scan database.
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
std::cout << it->key().ToString() << ": " <<
it->value().ToString() << std::endl;
}
assert(it->status().ok());
// Range scan, example: [name3, name8)
for (it->Seek("name3");
it->Valid() && it->key().ToString() < "name8";
it->Next()) {
std::cout << it->key().ToString() << ": " <<
it->value().ToString() << std::endl;
}
LevelDB 通过提供 leveldb::Iterator 来实现范围查找。
5.7 关闭数据库
...
// Close a database.
delete db;
...
最后,关闭数据库时需要删除掉创建的数据库实例,让其调用析构函数处理一些收尾工作。
5.8 Snapshot
LevelDB 还提供了快照(Snapshot)的功能,让应用可以获得数据库在某一时刻的只读的一致性数据。可以利用 LevelDB 的 Snapshot 功能实现类似 MySQL 的 MVCC。
6. 参考
(1)LevelDB官网 https://github.com/google/leveldb 帮助文档 https://github.com/google/leveldb/blob/master/doc/index.md
(1)既生 Redis 何生 LevelDB ? https://mp.weixin.qq.com/s/j9a0T1DMVmhd7HTxbJJ6Aw
(2)LevelDB 入门 —— 全面了解 LevelDB 的功能特性 https://mp.weixin.qq.com/s/GIVPGs9J90VBPpGcbMp5dw
(2)LevelDB库简介 https://www.cnblogs.com/chenny7/p/4026447.html
(2)LevelDB、TreeDB、SQLite3性能对比测试 https://www.oschina.net/question/12_25944
(2)1. LevelDB源码剖析之关于LevelDB https://www.jianshu.com/p/9b5945cb6e70
(2)LevelDB https://baike.baidu.com/item/LevelDB/6416354?fr=aladdin
(3)鸿篇巨制 —— LevelDB 的整体架构【质量高】 https://mp.weixin.qq.com/s/rN6HX2VzsRi3_EKXYKuJAA (3)LevelDB:整体架构 https://www.jianshu.com/p/6e49aa5182f0
(4)跳表SkipList https://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html
(4)5. LevelDB源码剖析之基础部件-SkipList https://www.jianshu.com/p/6624befde844
(5)深入 LevelDB 数据文件 SSTable 的结构 https://mp.weixin.qq.com/s/npFr16_RnxZVnJdaKpPu8w
(5)8. LevelDB源码剖析之日志文件 https://www.jianshu.com/p/d1bb2e2ceb4c
(6)9. LevelDB源码剖析之Current文件\Manifest文件\版本信息 https://www.jianshu.com/p/27e48eae656d (6)庖丁解LevelDB之版本控制 https://www.jianshu.com/p/9bd10f32e38c
(7)LevelDB 代码撸起来! https://mp.weixin.qq.com/s/HzHxt7PgH2Cwv4PlIaz5WA (7)LevelDB:使用介绍 https://www.jianshu.com/p/573c5706da0a
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
