Merkle树如何增强DynamoDB中的数据一致性
- Yong kang Chia
- 发布于 2024-06-24 14:17
- 阅读 1547
本文介绍了AWS的NoSQL数据库服务DynamoDB如何使用Merkle树来解决数据复制和一致性的问题。通过比较Merkle哈希,DynamoDB可以快速识别不一致之处,并仅更新必要的数据块,从而最大限度地减少所需的复制迭代次数,加速数据迁移过程,并确保目标节点快速达到一致状态。
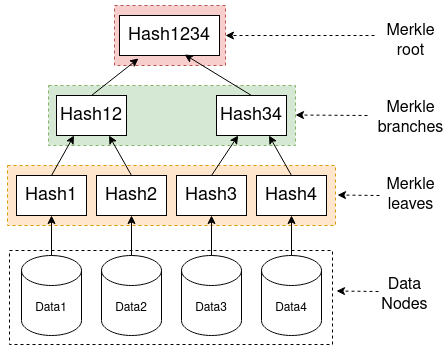
Dynamo DB 使用的 Merkle Tree
DynamoDB 是 AWS 提供的一项完全托管的 NoSQL 数据库服务,专为高可用性和持久性而设计。确保这种可靠性的关键特性之一是以容错方式存储数据,即将其复制到多个节点上。但是,DynamoDB 如何管理数据复制和一致性的复杂性呢?这就是 Merkle Tree 的用武之地。
理解问题
当数据存储在 DynamoDB 中时,会跨不同的节点复制,以确保容错能力。但是,这种复制带来了一些挑战,尤其是在需要将数据从一个节点复制到另一个节点时。
数据复制和一致性
假设你需要将某个数据范围从旧节点复制到新添加的节点。
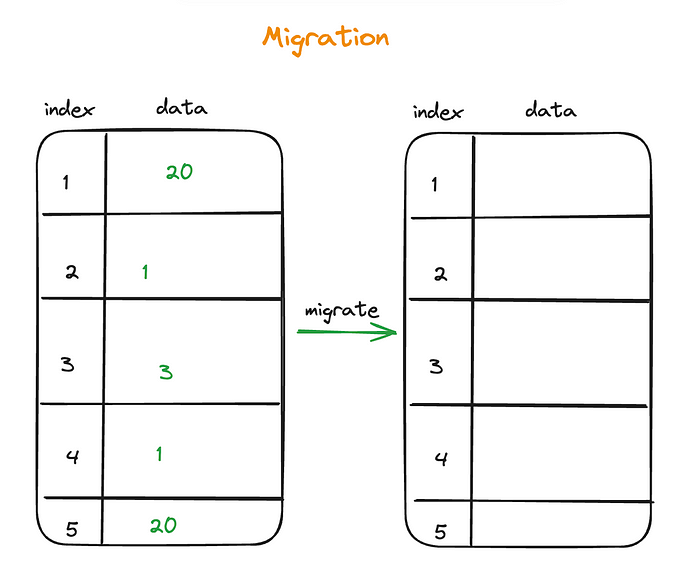
迁移前
迁移后
这听起来很简单,但是旧节点中的数据在不断更新。这些并发更新可能导致不一致,从而导致目标节点中的数据过时。
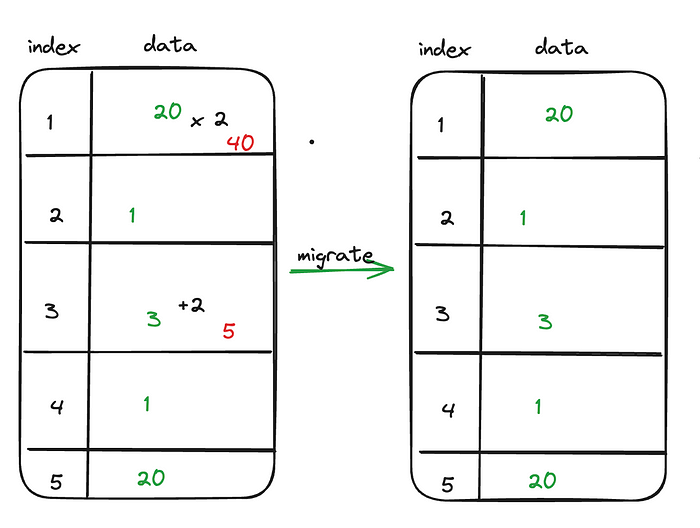
迁移期间节点中的并发更新可能导致不一致
为了解决这个问题,数据范围会被多次复制。当源节点和目标节点之间没有变化时,数据被声明为一致。但是,此过程必须尽可能快,以最大程度地减少服务中断。
挑战
- 确保数据一致性: 尽管有持续的更新,我们仍需要将旧节点中的所有值完全复制到新节点。
- 最大程度地减少复制迭代: 为了加快该过程,我们必须减少实现一致性所需的迭代次数。
Merkle Tree 登场
Merkle Tree 为复制期间的数据一致性问题提供了一种有效的解决方案。以下是具体方法:
Merkle Tree 的工作原理
Merkle Tree 是一种树数据结构,其中每个叶节点包含数据块的哈希值,每个非叶节点包含其子节点的哈希值。这种结构可以对数据完整性进行高效且安全的验证。
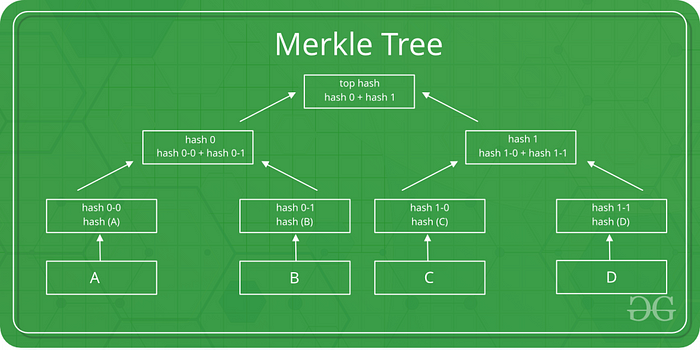
Merkle Tree 基础
Merkle Tree 在 DynamoDB 中的优势
- 高效的数据比较: Merkle Tree 可以检测到基于数据节点中任何差异的根哈希变化。通过比较 Merkle 哈希,DynamoDB 可以快速识别不一致之处。
- 降低时间复杂度: 遍历 Merkle Tree 以查找不一致数据的对数时间复杂度为 O(log(n)),而检查每个节点的线性时间复杂度为 O(n)。这使得该过程明显更快。
那么它是如何使用的呢?
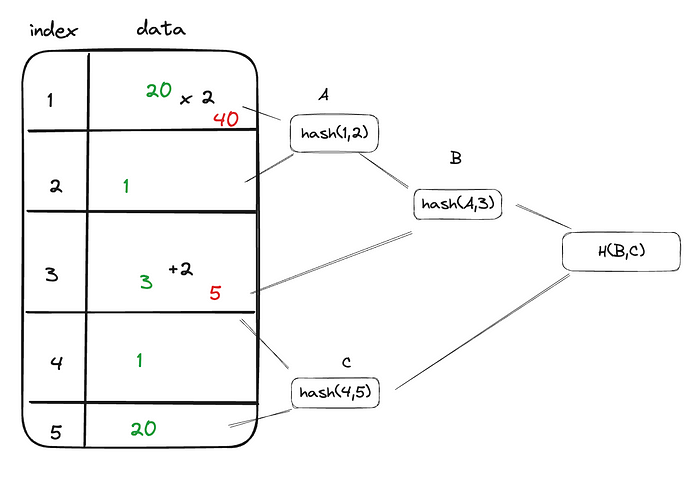
如何使用 Merkle Tree
当将数据复制到新节点时,问题在于复制过程中可能发生的更改。Merkle Tree 使 DynamoDB 能够有效地识别和解决这些不一致之处。通过比较源节点和目标节点的 Merkle 哈希,DynamoDB 可以查明差异并仅更新必要的数据块。
此方法最大程度地减少了所需的复制迭代次数,从而加快了数据迁移过程,并确保目标节点快速达到一致状态。
结论
Merkle Tree 为 DynamoDB 中数据复制和一致性的挑战提供了一种优雅而有效的解决方案。通过利用 Merkle Tree 的独特属性,DynamoDB 可以快速识别和解决节点之间的数据不一致之处,从而确保即使在迁移和更新期间,数据仍保持一致且可用。
在 DynamoDB 中使用 Merkle Tree 的主要优势包括:
- 高效的数据比较: 检测基于数据节点中任何差异的根哈希变化的能力允许快速识别不一致之处。
- 降低时间复杂度: 凭借遍历 Merkle Tree 的对数时间复杂度,DynamoDB 可以比线性方法更快地查明和解决不一致之处。
- 最大程度地减少复制迭代: 需要更少的迭代来实现数据一致性,从而加快了整个数据迁移过程。
从本质上讲,Merkle Tree 通过确保数据完整性同时最大程度地减少对性能的影响来增强 DynamoDB 的容错架构。这使 DynamoDB 能够保持高可用性和可靠性,从而为各种规模的应用程序提供强大且可扩展的数据存储解决方案。
通过理解和实施 Merkle Tree,你可以利用它们的力量来实现高效且有效的数据复制,从而确保你的系统保持弹性,并且你的数据保持一致。
如果你觉得这篇文章很有见地,请鼓掌并与你的网络分享。请随时在下面留下你的评论和问题,让我们继续讨论 DynamoDB 和 Merkle Tree!
- 原文链接: extremelysunnyyk.medium....
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





