隐私感知机器学习:同态加密与联邦学习
- billatnapier
- 发布于 2025-05-17 10:15
- 阅读 2629
本文探讨了在保护用户隐私的前提下改进机器学习应用的方法,重点介绍了同态加密和联邦学习在欺诈检测中的应用。文章讨论了使用同态加密对数据进行加密处理,然后在加密状态下进行机器学习模型训练和推理,以及利用联邦学习在不共享原始数据的情况下,通过多个参与方协作训练模型。

隐私感知机器学习:同态加密和联邦学习
在 Lasting Asset 中,我们正在使用同态加密技术研究新的欺诈检测模型。所以让我们快速了解一下该领域的一些最新工作。这些方法通常使用 CCKS 同态方法,该方法对浮点数值进行运算。通过这种方法,我们使用公钥来加密数据,然后我们可以处理这些加密的数据。对于加密的结果,我们可以使用相关的私钥进行解密(图 1)。
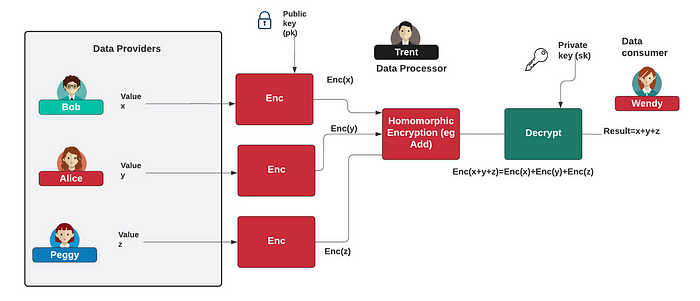
图 1 [ 这里]
同态加密与 ML
Nugent 等人[1] 使用两种模型,即 XGBoost 和前馈分类器神经网络,通过同态加密实现了欺诈检测。XGBoost 的延迟为 6 毫秒,而神经网络方法的延迟为 296 毫秒。不过,作者认为神经网络可能最适合安全性和部署。总体而言,TenSEAL [ 这里] 用于执行机器学习元素,并且构建在 SEAL [2] 之上。XGBoost (eXtreme Gradient Boosting) 推理 [3] 使用 OPE(Order Preserving Encryption,顺序保持加密)[ 这里] 来实现同态加密元素。
图 3 概述了设置,其中同态公钥被发送到客户端,以便它可以加密数据,以便在云中使用 AWS SageMaker 运行机器学习模型和 Amazon EC2 进行处理。XGBoost 的训练方法 [ 这里] 在图 4 中进行了概述。
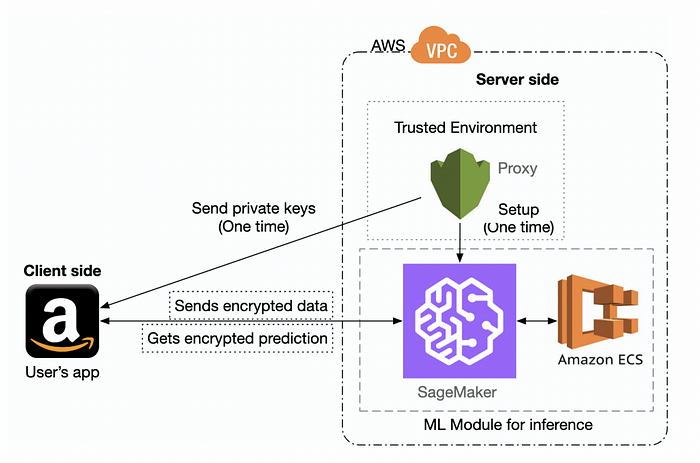
图 2[1]
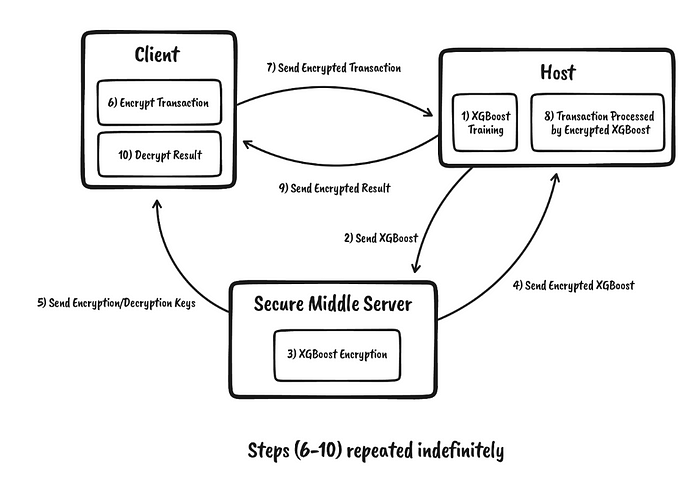
图 3[1]
图 4 概述了 CKKS 前馈神经网络模型的使用,图 5 概述了训练神经网络的方法。
使用的数据集是 Vesta 6 和 ULB 7 数据集。对于 ULB 数据集 [ 这里],我们有 284,807 笔交易,其中 492 笔被定义为欺诈交易 (0.172%)。然后有 28 个数值特征 (V1-V28) 和交易的相对时间。PCA 用于准备匿名化的数据。
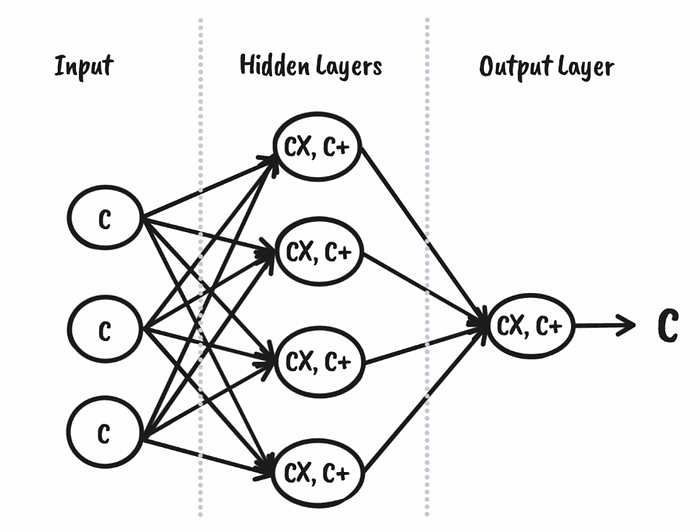
图 4[1]
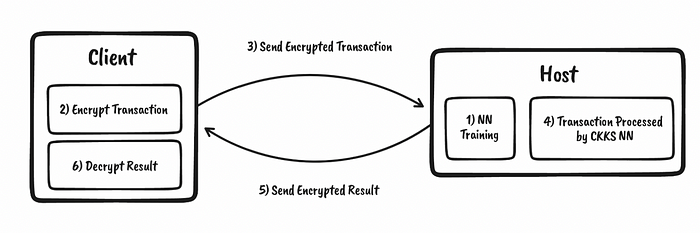
图 5[1]
Vista 数据集 [ 这里] 是 IEEE CIS 欺诈检测竞赛的一部分。它包含 590,540 笔交易,其中 20,663 笔是欺诈交易 (3.5%)。每笔交易都有一个时间戳,并且有 400 个数值特征和 31 个分类特征,以及一个欺诈交易标志。代码可在 [ 这里] 获得。图 6 和图 7 概述了数据集的结果。
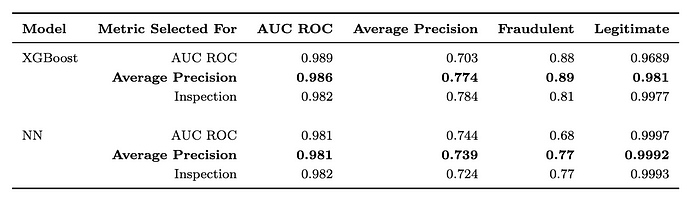
图 6[1]
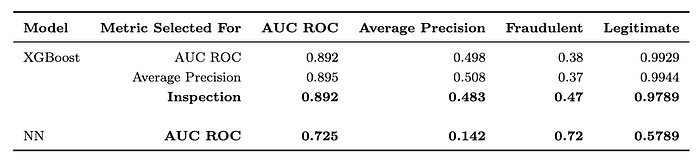
图 7[1]
SVM 与同态加密
Al Badawi 等人 [4] 在加密数据上实现了一种快速的同态 SVM 推理方法(图 8)。总体而言,SVM 是一种核方法,可用于监督学习的模式匹配。它使用 CKKS FHE 方案进行 128 位安全性,并使用比特币交易数据集 [5]。结果表明,使用多核 CPU 平台可以在 1.25 秒内返回 SVM 预测,并且不会损失准确性。
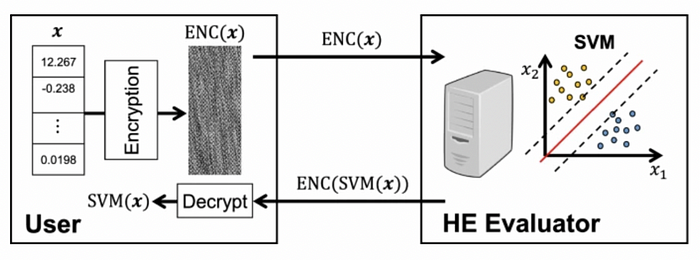
图 8[4]
对于 SVM(SVM)模型,我们有一种监督学习技术。总体而言,它用于创建两个类别(二进制)或更多类别(多重),并将尝试将每个训练值分配到一个或多个类别。基本上,我们在一个多维空间中有点,并尝试在类别之间创建一个清晰的间隙。然后将新值放置在两个类别之一中。
总体而言,我们将输入数据拆分为训练数据和测试数据,然后使用 sklearn 模型以及来自训练数据的未加密值进行训练。模型的输出是权重和截距。接下来,我们可以使用同态公钥加密测试数据,然后将其输入到 SVM 模型中。然后可以通过相关的私钥解密输出值,如图 9 所示。[6] 中,作者使用 OpenFHE [7] 来处理数据集。
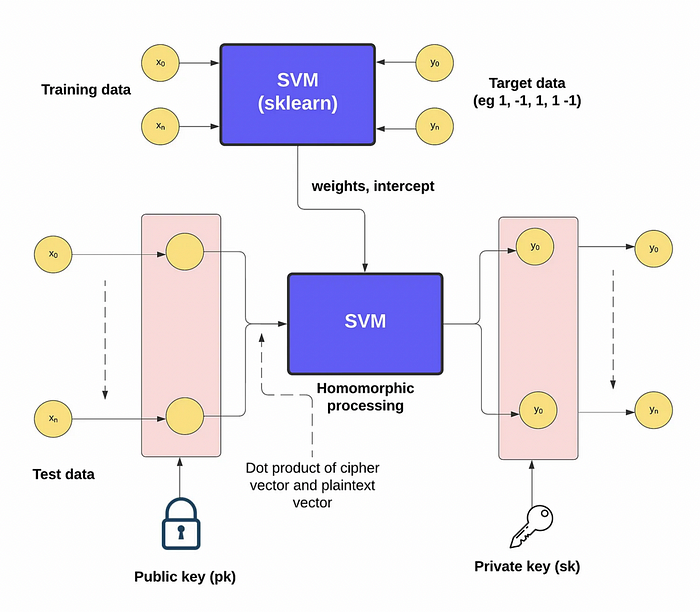图 9[6]
联邦学习与 ML
隐私保护机器学习 (PPML) 中的替代方法是使用联邦学习 (FL) 方法。Starlit 系统 [8] 就是一个例子,其中一系列客户端拥有本地数据,然后构建模型而无需交换信息。对于垂直联邦学习 (VFL),我们有一些用户之间的交集,这些用户在不同的数据集中具有不同的特征,而对于水平联邦学习 (HFL),我们有具有相同特征的客户,但用户具有不同的身份。
Awosika 等人 [9] 概述说,用于训练 AI 系统的欺诈检测数据中的一个特殊问题通常具有比欺诈交易更多的合法交易,并且在共享客户信息的障碍中——这可能会影响机器学习模型的性能。他们开发的系统使用联邦学习 (FL) 和可解释 AI (XAI) 来训练模型,以检测欺诈交易,而无需与其他组织共享客户数据,并且预测可以向人类操作员解释——如图 9 所示。用于模型的数据来自银行帐户欺诈 (BAF) 表格数据集套件 [10][ 这里][ 这里]。它有六个不同的数据集,基本数据集由 [ 这里] 组成。附录 A 概述了数据集的格式。
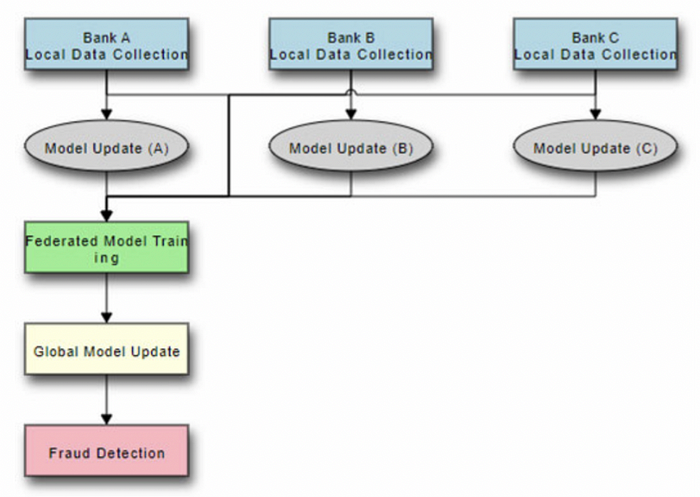
图 9 [9]
结论
我们需要改进我们对机器学习的使用,并着眼于保护所用数据的隐私。同态加密和联邦学习方法提供了一个很好的解决方案。
附录
用于模型的数据来自银行帐户欺诈 (BAF) 表格数据集套件 [10][ 这里][ 这里]。它有六个不同的数据集,基本数据集由 [ 这里] 组成。数据集的格式为:
- income (numeric)。申请人的年收入(以十分位数形式)。范围在 [0.1, 0.9] 之间。
- name\_email\_similarity (numeric)。电子邮件和申请人姓名之间的相似性指标。值越高表示相似性越高。范围在 [0, 1] 之间。
- prev\_address\_months\_count (numeric)。申请人先前注册地址的月数,即申请人的先前住所(如果适用)。范围在 [−1, 380] 个月之间(-1 是缺失值)。
- current\_address\_months\_count (numeric)。申请人当前注册地址的月数。范围在 [−1, 429] 个月之间(-1 是缺失值)。
- customer\_age (numeric)。申请人的年龄(以年为单位),四舍五入到十年。范围在 [10, 90] 岁之间。
- days\_since\_request (numeric)。自申请完成以来经过的天数。范围在 [0, 79] 天之间。
- intended\_balcon\_amount (numeric)。申请的初始转账金额。范围在 [−16, 114] 之间(负数是缺失值)。
- payment\_type (categorical) & 信用卡支付计划类型。5 种可能(匿名)值。
- zip\_count\_4w (numeric) & 过去 4 周内同一邮政编码内的申请数量。范围在 [1, 6830] 之间。
- velocity\_6h (numeric) & 过去 6 小时内提出的总申请速度,即过去 6 小时内每小时的平均申请数量。范围在 [−175, 16818] 之间。
- velocity\_24h (numeric) & 过去 24 小时内提出的总申请速度,即过去 24 小时内每小时的平均申请数量。范围在 [1297, 9586] 之间
- velocity\_4w (numeric) & 过去 4 周内提出的总申请速度,即过去 4 周内每小时的平均申请数量。范围在 [2825, 7020] 之间。
- bank\_branch\_count\_8w (numeric) & 过去 8 周内在选定银行分行的总申请数量。范围在 [0, 2404] 之间。
- date\_of\_birth\_distinct\_emails\_4w (numeric) & 在过去 4 周内具有相同出生日期的申请人的电子邮件数量。范围在 [0, 39] 之间。
- employment\_status (categorical) & 申请人的就业状况。7 种可能(匿名)值。
- credit\_risk\_score (numeric) & 申请风险的内部评分。范围在 [−191, 389] 之间。
- email\_is\_free (binary) & 申请电子邮件的域(免费或付费)。
- housing\_status (categorical) & 申请人当前的居住状况。7 种可能(匿名)值。
- phone\_home\_valid (binary) & 提供的家庭电话的有效性。
- phone\_mobile\_valid (binary) & 提供的手机的有效性。
- bank\_months\_count (numeric) & 之前帐户(如果持有)的月数。范围在 [−1, 32] 个月之间(-1 是缺失值)
- has\_other\_cards (binary) & 申请人是否拥有来自同一银行公司的其他卡。
- proposed\_credit\_limit (numeric) & 申请人提议的信用额度。范围在 [200, 2000] 之间。
- foreign\_request (binary) & 请求的来源国家/地区是否与银行的国家/地区不同。
- source (categorical) & 申请的在线来源。浏览器 (INTERNET) 或应用 (TELEAPP)。
- session\_length\_in\_minutes (numeric) & 用户在银行网站上的会话长度(以分钟为单位)。范围在 [−1, 107] 分钟之间(-1 是缺失值)。
- device\_os (categorical) & 提出请求的设备的操作OS。可能的值:Windows、macOS、Linux、X11 或其他。
- keep\_alive\_session (binary) & 用户在会话注销时的选项。
- device\_distinct\_emails (numeric) & 过去 8 周内来自所用设备的银行网站中的不同电子邮件的数量。范围在 [−1, 2] 封电子邮件之间(-1 是缺失值)。
- device\_fraud\_count (numeric) & 使用过的设备的欺诈申请数量。范围在 [0, 1] 之间。
- month (numeric) & 提出申请的月份。范围在 [0, 7] 之间。
- fraud\_bool (binary) & 申请是否具有欺诈性。
参考文献
[1] D. Nugent,“使用同态加密的隐私保护信用卡欺诈检测”,arXiv 预印本 arXiv:2211.06675, 2022。
[2] M. S. Team,“Microsoft seal (simple encrypted arithmetic library)”,2022,可在 https://www.microsoft.com/en-us/research/project/microsoft-seal/ 获得。
[3] X. Meng 和 J. Feigenbaum,“隐私保护 xgboost 推理”,arXiv 预印本 arXiv:2011.04789, 2020。
[4] A. Al Badawi、L. Chen 和 S. Vig,“加密数据上的快速同态 svm 推理”,Neural Computing and Applications, vol. 34, no. 18, pp. 15 555–15 573, 2022。
[5] M. Weber、G. Domeniconi、J. Chen、D. K. I. Weidele、C. Bellei、T. Robinson 和 C. E. Leiserson,“比特币中的反洗钱:使用图Rollup网络进行金融取证的实验”,arXiv 预印本 arXiv:1908.02591, 2019。
[6] W. J. Buchanan 和 H. Ali,“使用同态加密评估隐私感知SVM (svm) 学习”,arXiv 预印本 arXiv:2503.04652, 2025。
[7] W. J. Buchanan,“同态加密 (openfhe)”,https://asecuritysite.com/openfhe, Asecuritysite.com, 2025, accessed: February 20, 2025. [Online]。可从以下网址获得:https://asecuritysite.com/openfhe
[8] A. Abadi、B. Doyle、F. Gini、K. Guinamard、S. K. Murakonda、J. Liddell、P. Mellor、S. J. Murdoch、M. Naseri、H. Page 等人,“Starlit:隐私保护联邦学习,以增强金融欺诈检测”,arXiv 预印本 arXiv:2401.10765, 2024。
[9] T. Awosika、R. M. Shukla 和 B. Pranggono,“透明度和隐私:可解释 ai 和联邦学习在金融欺诈检测中的作用”,IEEE Access, 2024。
[10] S. Jesus、J. Pombal、D. Alves、A. Cruz、P. Saleiro、R. Ribeiro、J. Gama 和 P. Bizarro,“扭转局面:用于 ml 评估的有偏差、不平衡、动态的表格数据集”,Advances in Neural Information Processing Systems, vol. 35, pp. 33 563–33 575, 2022。
- 原文链接: billatnapier.medium.com/...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





