保护隐私的机器学习:同态加密和联邦学习
- asecuritysite
- 发布于 2025-05-20 21:37
- 阅读 2456
本文探讨了两种保护隐私的机器学习方法:同态加密和联邦学习,并将其应用于欺诈检测。同态加密允许在加密数据上进行计算,而无需解密;联邦学习则允许多方在不共享原始数据的情况下协同训练模型。文章介绍了使用这两种技术进行信用卡欺诈检测的实践案例,包括使用OpenFHE库和联邦学习系统Starlit。

隐私感知机器学习:同态加密和联邦学习
在 LastingAsset Limited,我们正在使用同态加密技术研究新的欺诈检测模型。所以让我们快速看一下该领域的一些当前工作,特别是在我们如何与隐私感知机器学习集成方面。这方面的大部分工作都使用了 CCKS 同态方法,该方法对浮点数值进行运算。通过这种方法,我们使用公钥来加密数据,然后我们可以以保护隐私的方式处理这些加密数据。有了加密的结果,我们就可以用相关的私钥来解密(图 1)。
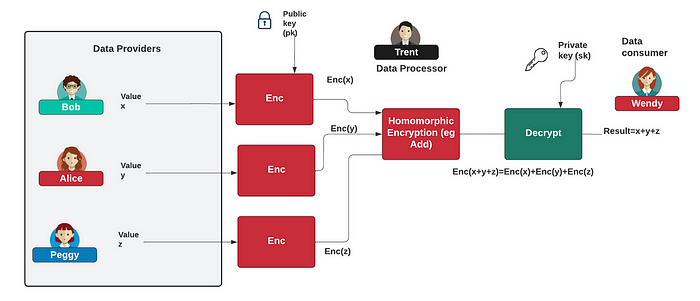
图 1 [ 这里 ]
我们可以很容易地扩展这个模型,这样我们就可以实现机器学习模型,Bob、Alice 和 Peggy 可以以一种保护隐私的方式提供他们的数据,数据处理者无法看到他们数据的具体内容:

同态加密和 ML
Nugent 等人 [1] 使用两种模型:XGBoost 和前馈分类器神经网络,实现了基于同态加密的欺诈检测。XGBoost 的延迟为 6 毫秒,神经网络方法的延迟为 296 毫秒。不过,作者认为神经网络可能最适合安全性和部署。总的来说,TenSEAL [ 这里 ] 用于执行机器学习元素,并且构建在 SEAL [2] 之上。XGBoost (eXtreme Gradient Boosting) 推理 [3] 使用 OPE (Order Preserving Encryption,保序加密) [ 这里 ] 来实现同态加密元素。
图 3 概述了该设置,同态公钥被发送到客户端,以便它可以加密数据,然后在云中使用 AWS SageMaker 运行机器学习模型,并使用 Amazon EC2 进行处理。XGBoost 的训练方法 [ 这里 ] 在图 4 中进行了概述。
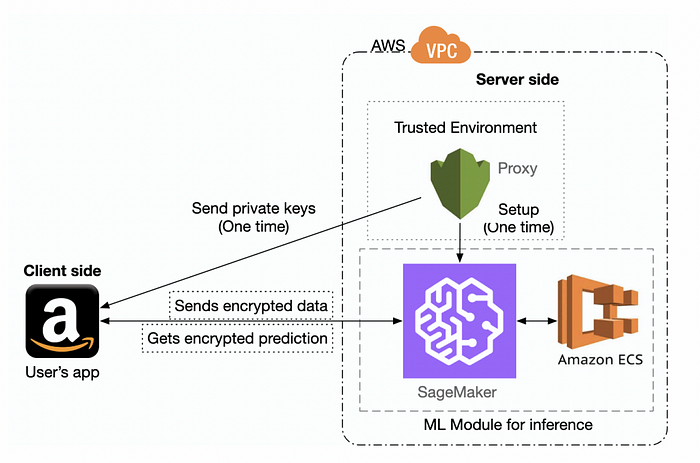
图 2[1]
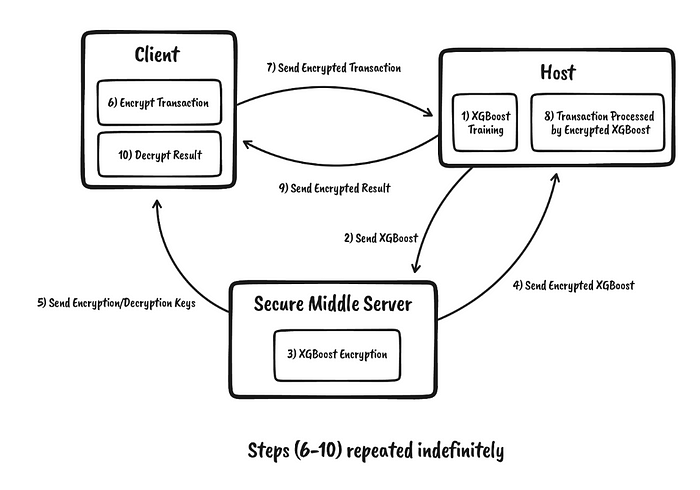
图 3[1]
图 4 概述了 CKKS 前馈神经网络模型的使用,图 5 概述了训练神经网络的方法。
使用的数据集为 Vesta 6 和 ULB 7 数据集。在 ULB 数据集 [ 这里 ] 中,我们有 284,807 笔交易,其中 492 笔被定义为欺诈交易 (0.172%)。然后有 28 个数值特征 (V1-V28) 和交易的相对时间。PCA 用于准备数据,并且数据是匿名的。
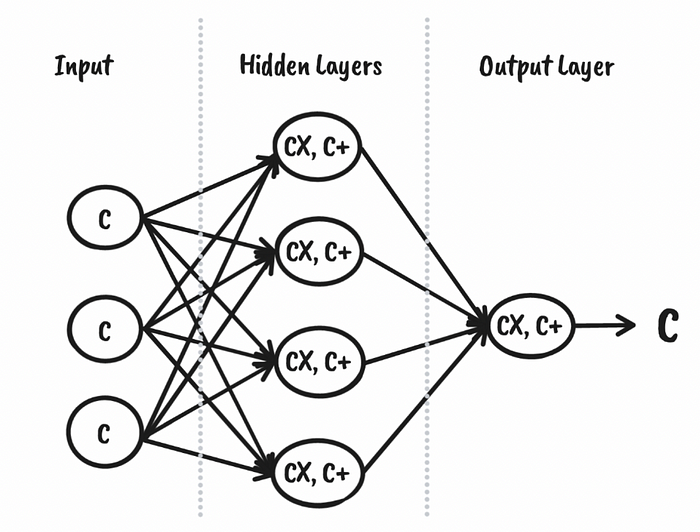
图 4[1]
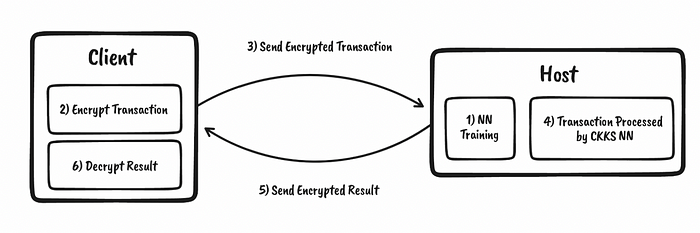
图 5[1]
Vista 数据集 [ 这里 ] 是 IEEE CIS 欺诈检测竞赛的一部分。它包含 590,540 笔交易,其中 20,663 笔是欺诈交易 (3.5%)。每笔交易都有一个时间戳,其中包含 400 个数值特征和 31 个类别特征,以及一个欺诈交易标志。代码可以在 [ 这里 ] 找到。图 6 和图 7 概述了数据集上的结果。
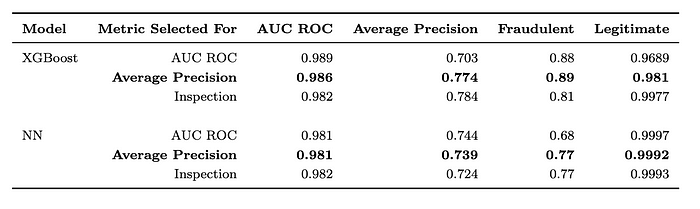
图 6[1]
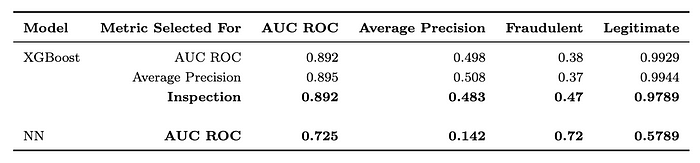
图 7[1]
SVM 和同态加密
Al Badawi 等人 [4] 在加密数据上实现了一种快速同态 SVM 推理方法(图 8)。总的来说,SVM 是一种核方法,可用于监督学习的模式匹配。它使用 CKKS FHE 方案来实现 128 位安全性,并使用比特币交易数据集 [5]。结果表明,使用多核 CPU 平台可以在 1.25 秒内返回 SVM 预测,且不会损失准确性。
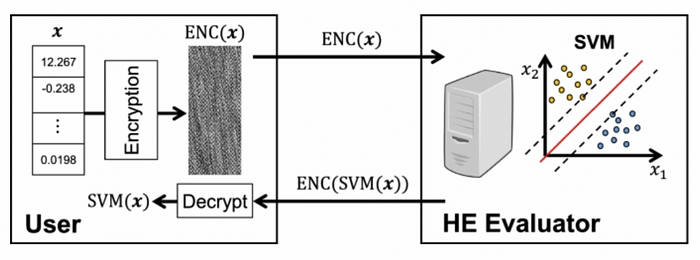
图 8[4]
对于 SVM(SVM)模型,我们有一种监督学习技术。总的来说,它用于创建两个类别(二元)或更多类别(多元),并将尝试将每个训练值分配到一个或多个类别中。基本上,我们有多维空间中的点,并尝试在类别之间创建一个清晰的间隙。然后将新值放置在两个类别之一中。
总的来说,我们将输入数据拆分为训练数据和测试数据,然后使用 sklearn 模型对来自训练数据的未加密值进行训练。模型的输出是权重和截距。接下来,我们可以使用同态公钥加密测试数据,然后将其输入到 SVM 模型中。然后可以通过相关的私钥解密输出值,如图 9 所示。在 [6] 中,作者使用 OpenFHE [7] 来处理数据集。
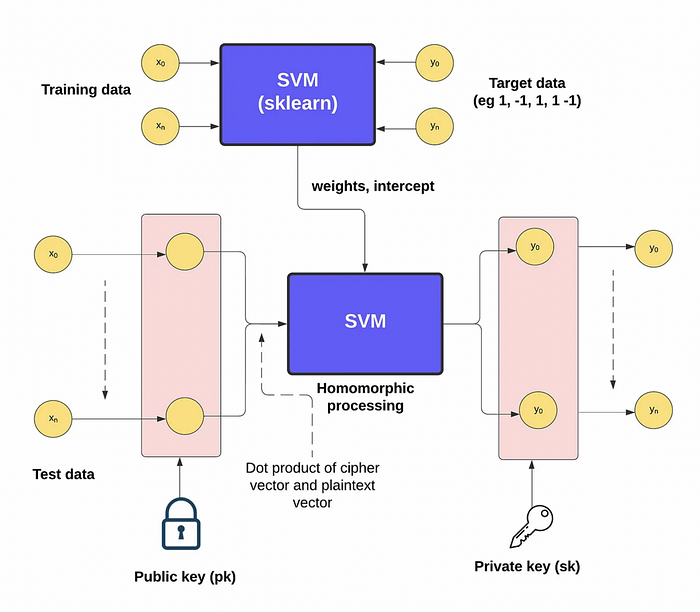
图 9[6]
该演示程序位于 这里。
使用带有 Python 封装器的 OpenFHE 进行信用卡欺诈检测
所以,让我们看一个使用 OpenFHE 开源库和一个简单的信用卡欺诈数据集的简单示例。总的来说,我们可以使用 C++ 进行编码,但可以通过使用封装器将其转换为 Python。代码位于 [ 这里 ]。
要下载信用卡欺诈数据集并将数据集拆分为训练和测试,我们运行 [ 这里 ]:
python get_data.py这将使用 [ 这里 ] 拉取所需的数据集:
credit_approval = fetch_ucirepo(id='Credit Approval')这将从 这里 下载信用卡审批数据集,并创建以下文件 [ 这里 ]:
credit_approval.csv
credit_approval_target_test.csv
credit_approval_target_train.csv
credit_approval_test.csv
credit_approval_train.csvcredit_approval.csv 文件包含信用卡数据集的 16 个特征,其中 credit_approval_train.csv 包含训练数据,credit_approval_test.csv 包含用于测试模型的数据。credit_approval_target_test.csv 和 credit_approval_target_train.csv 文件具有目标训练因子(欺诈与否)。训练数据和测试数据之间的比例为 80%/20%。
在数据集的 16 个特征(其中已匿名化,因此不会泄露任何敏感信息)中,A2、A3、A8、A11、A14 和 A15 具有数值,这些值将用于学习 [ 这里 ]:
A1: b, a.
A2: continuous.
A3: continuous.
A4: u, y, l, t.
A5: g, p, gg.
A6: c, d, cc, i, j, k, m, r, q, w, x, e, aa, ff.
A7: v, h, bb, j, n, z, dd, ff, o.
A8: continuous.
A9: t, f.
A10: t, f.
A11: continuous.
A12: t, f.
A13: g, p, s.
A14: continuous.
A15: continuous.
A16: +,- (class attribute)在训练中,我们将使用前四个特征(A2、A3、A8 和 A11)。接下来,我们可以使用以下命令训练模型:
python model_training.py这将在 models 文件夹中构建一个模型 [ 这里 ]:
dual_coef.txt
intercept.txt
intercept_poly.txt
support_vectors.txt
weights.txt最后,我们可以使用加密数据运行模型 [ 这里 ]:
python encrypted_svm_linear.py运行结果如下 [ 这里 ]:
---- Loading Data and Model ----
---- Data Loaded! ----
---- Model Loaded! ----
CKKS is using ring dimension 16384
Input pt_weights: (1.89376, -0.0995155, 1.3739, 0.565907, ... ); Estimated precision: 50 bits
Input pt_bias: (0.161167, ... ); Estimated precision: 50 bits
Linear-SVM inference took 0.051833391189575195 ms
Expected score = -0.8002993455043914
Predicted score (1st element) = (-0.800299, 7.43123e-15, -2.47025e-14, -6.37651e-15, ... ); Estimated precision: 44 bits我们可以看到使用的 CKKS 模数为 16,384。预期分数为 -0.8002993455043914,预测分数为 -0.800299。因此,即使我们使用了加密数据,准确性也几乎是完美的。
联邦学习和 ML
隐私保护机器学习 (PPML) 中的另一种选择是使用联邦学习 (FL) 方法。Starlit 系统 [8] 就是一个例子,其中一系列客户端拥有本地数据,然后构建一个模型,而不需要交换信息。对于垂直联邦学习 (VFL),某些用户在不同的数据集中具有不同的特征,而对于水平联邦学习 (HFL),我们拥有具有相同特征的客户,但用户的身份不同。
Awosika 等人 [9] 指出,用于训练 AI 系统的欺诈检测数据中的一个特殊问题是,合法交易通常比欺诈交易多得多,而且共享客户信息的障碍也会影响机器学习模型的性能。他们开发的系统使用联邦学习 (FL) 和可解释 AI (XAI) 来训练模型,以检测欺诈交易,而不需要与其他组织共享客户数据,并且预测对人工操作员来说是可以解释的,如图 9 所示。该模型使用的数据来自银行账户欺诈 (BAF) 表格数据集套件 [10][ 这里 ][ 这里 ]。它有六个不同的数据集,基本数据集由 [ 这里 ] 组成。附录 A 概述了数据集的格式。
图 9 [9]
结论
我们需要改进机器学习的使用,并着眼于保护所用数据的隐私。同态加密和联邦学习方法提供了一个很好的解决方案。
附录
该模型使用的数据来自银行账户欺诈 (BAF) 表格数据集套件 [10][ 这里 ][ 这里 ]。它有六个不同的数据集,基本数据集由 [ 这里 ] 组成。数据集的格式为:
- income (numeric). 申请人的年收入(以十分位数形式)。范围在 [0.1, 0.9] 之间。
- name_email_similarity (numeric). 电子邮件和申请人姓名之间的相似性指标。值越高表示相似性越高。范围在 [0, 1] 之间。
- prev_address_months_count (numeric). 申请人先前注册地址的月数,即申请人的先前居住地(如果适用)。范围在 [-1, 380] 个月之间(-1 是缺失值)。
- current_address_months_count (numeric). 申请人当前注册地址的月数。范围在 [-1, 429] 个月之间(-1 是缺失值)。
- customer_age (numeric). 申请人的年龄(以年为单位),四舍五入到十年。范围在 [10, 90] 岁之间。
- days_since_request (numeric). 自申请完成以来经过的天数。范围在 [0, 79] 天之间。
- intended_balcon\amount (numeric). 申请的初始转账金额。范围在 [-16, 114] 之间(负数是缺失值)。
- payment_type (categorical). 信用卡支付计划类型。5 个可能的值(已匿名化)。
- zip_count_4w (numeric). 过去 4 周内在同一邮政编码内的申请数量。范围在 [1, 6830] 之间。
- velocity_6h (numeric). 过去 6 小时内所做的总申请的速度,即过去 6 小时内每小时的平均申请数量。范围在 [-175, 16818] 之间。
- velocity_24h (numeric). 过去 24 小时内所做的总申请的速度,即过去 24 小时内每小时的平均申请数量。范围在 [1297, 9586] 之间。
- velocity_4w (numeric). 过去 4 周内所做的总申请的速度,即过去 4 周内每小时的平均申请数量。范围在 [2825, 7020] 之间。
- bank_branch_count_8w (numeric). 过去 8 周内在选定银行分行的总申请数量。范围在 [0, 2404] 之间。
- date_of_birth_distinct_emails_4w (numeric). 过去 4 周内具有相同出生日期的申请人的电子邮件数量。范围在 [0, 39] 之间。
- employment_status (categorical) & 申请人的就业状态。7 个可能的值(已匿名化)。
- credit_risk_score (numeric) & 申请风险的内部评分。范围在 [-191, 389] 之间。
- email_is_free (binary) & 申请电子邮件的域名(免费或付费)。
- housing_status (categorical) & 申请人当前的居住状态。7 个可能的值(已匿名化)。
- phone_home_valid (binary). 提供的家庭电话的有效性。
- phone_mobile_valid (binary). 提供的手机的有效性。
- bank_months_count (numeric). 以前的账户(如果持有)的月数。范围在 [-1, 32] 个月之间(-1 是缺失值)。
- has_other_cards (binary). 如果申请人具有来自同一银行公司的其他卡。
- proposed_credit_limit (numeric). 申请人提议的信用额度。范围在 [200, 2000] 之间。
- foreign_request (binary). 如果请求的来源国家/地区与银行的国家/地区不同。
- source (categorical). 申请的在线来源。浏览器 (INTERNET) 或应用程序 (TELEAPP)。
- session_length_in_minutes (numeric). 用户在银行网站上的会话时长(以分钟为单位)。范围在 [-1, 107] 分钟之间(-1 是缺失值)。
- device_os (categorical). 发出请求的设备操作系统。可能的值:Windows、macOS、Linux、X11 或其他。
- keep_alive_session (binary). 用户在会话注销时的选项。
- device_distinct_emails (numeric). 过去 8 周内来自所用设备的银行网站中的不同电子邮件数量。范围在 [-1, 2] 个电子邮件之间(-1 是缺失值)。
- device_fraud_count (numeric). 使用的设备中的欺诈性申请数量。范围在 [0, 1] 之间。
- month (numeric). 提出申请的月份。范围在 [0, 7] 之间。
- fraud_bool (binary). 申请是否具有欺诈性。
参考文献
[1] D. Nugent, “Privacy-preserving credit card fraud detection using homomorphic encryption,” arXiv preprint arXiv:2211.06675, 2022.
[2] M. S. Team, “Microsoft seal (simple encrypted arithmetic library),” 2022, available at https://www.microsoft.com/en-us/research/project/microsoft-seal/.
[3] X. Meng and J. Feigenbaum, “Privacy-preserving xgboost inference,” arXiv preprint arXiv:2011.04789, 2020.
[4] A. Al Badawi, L. Chen, and S. Vig, “Fast homomorphic svm inference on encrypted data,” Neural Computing and Applications, vol. 34, no. 18, pp. 15 555–15 573, 2022.
[5] M. Weber, G. Domeniconi, J. Chen, D. K. I. Weidele, C. Bellei, T. Robinson, and C. E. Leiserson, “Anti-money laundering in bitcoin: Experimenting with graph convolutional networks for financial forensics,” arXiv preprint arXiv:1908.02591, 2019.
[6] W. J. Buchanan and H. Ali, “Evaluation of privacy-aware support vector machine (svm) learning using homomorphic encryption,” arXiv preprint arXiv:2503.04652, 2025.
[7] W. J. Buchanan, “Homomorphic encryption (openfhe),” https://asecuritysite.com/openfhe, Asecuritysite.com, 2025, accessed: February 20, 2025. [Online]. Available: https://asecuritysite.com/openfhe
[8] A. Abadi, B. Doyle, F. Gini, K. Guinamard, S. K. Murakonda, J. Liddell, P. Mellor, S. J. Murdoch, M. Naseri, H. Page et al., “Starlit: Privacy-preserving federated learning to enhance financial fraud detection,” arXiv preprint arXiv:2401.10765, 2024.
[9] T. Awosika, R. M. Shukla, and B. Pranggono, “Transparency and privacy: the role of explainable ai and federated learning in financial fraud detection,” IEEE Access, 2024.
[10] S. Jesus, J. Pombal, D. Alves, A. Cruz, P. Saleiro, R. Ribeiro, J. Gama, and P. Bizarro, “Turning the tables: Biased, imbalanced, dynamic tabular datasets for ml evaluation,” Advances in Neural Information Processing Systems, vol. 35, pp. 33 563–33 575, 2022.
- 原文链接: medium.com/asecuritysite...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





