zkVM 安全性:哪里可能出错?- ZKSECURITY
- zksecurity
- 发布于 2024-11-22 19:31
- 阅读 922
本文深入探讨了零知识虚拟机(zkVM)的工作原理、潜在的安全漏洞以及构建安全零知识应用的必要性。文章详细介绍了zkVM的编译、执行、证明和验证流程,并分析了每个阶段可能出现的安全风险,例如编译器漏洞、执行不确定性、电路约束不足以及验证过程中的输入混淆等问题。
一个 zkVM (零知识虚拟机) 使用零知识证明来证明和验证在特定 ISA (指令集架构) 中运行的计算。现有的 zkVM (例如, risc0, sp1, jolt, valida, zkm) 允许开发者使用 Rust 或 C++ 等高级语言编写程序,而无需担心 ZKP 的复杂性。它抽象了底层密码学细节,使开发者能够专注于他们的应用程序逻辑并更快地交付。一旦 zkVM 是安全的,它就可以为在其上运行的任何程序提供“开箱即用”的 ZKP 功能,使开发者无需额外努力就能获得零知识证明的好处。
然而,尽管 zkVM 简化了开发,但它们仍然是复杂的系统,集成了许多技术组件——从编译器到证明系统和链上验证。这些组件中任何一个的单个 bug 都可能导致灾难性的安全故障。理解 zkVM 背后的技术堆栈对于构建者创建安全系统以及用户评估他们所依赖的应用程序的可靠性和安全性至关重要。
在这篇博文中,我们将逐步介绍典型的 zkVM 工作流程,高亮显示每个阶段的常见漏洞,并探讨这些领域中的 bug 如何损害零知识应用程序的安全性。通过更深入地了解所涉及的技术,我们可以更好地防范潜在风险,并构建更强大的由 zk 驱动的应用程序。
zkVM 是如何工作的
下图说明了 zkVM 的一般工作流程,我们将逐步介绍。
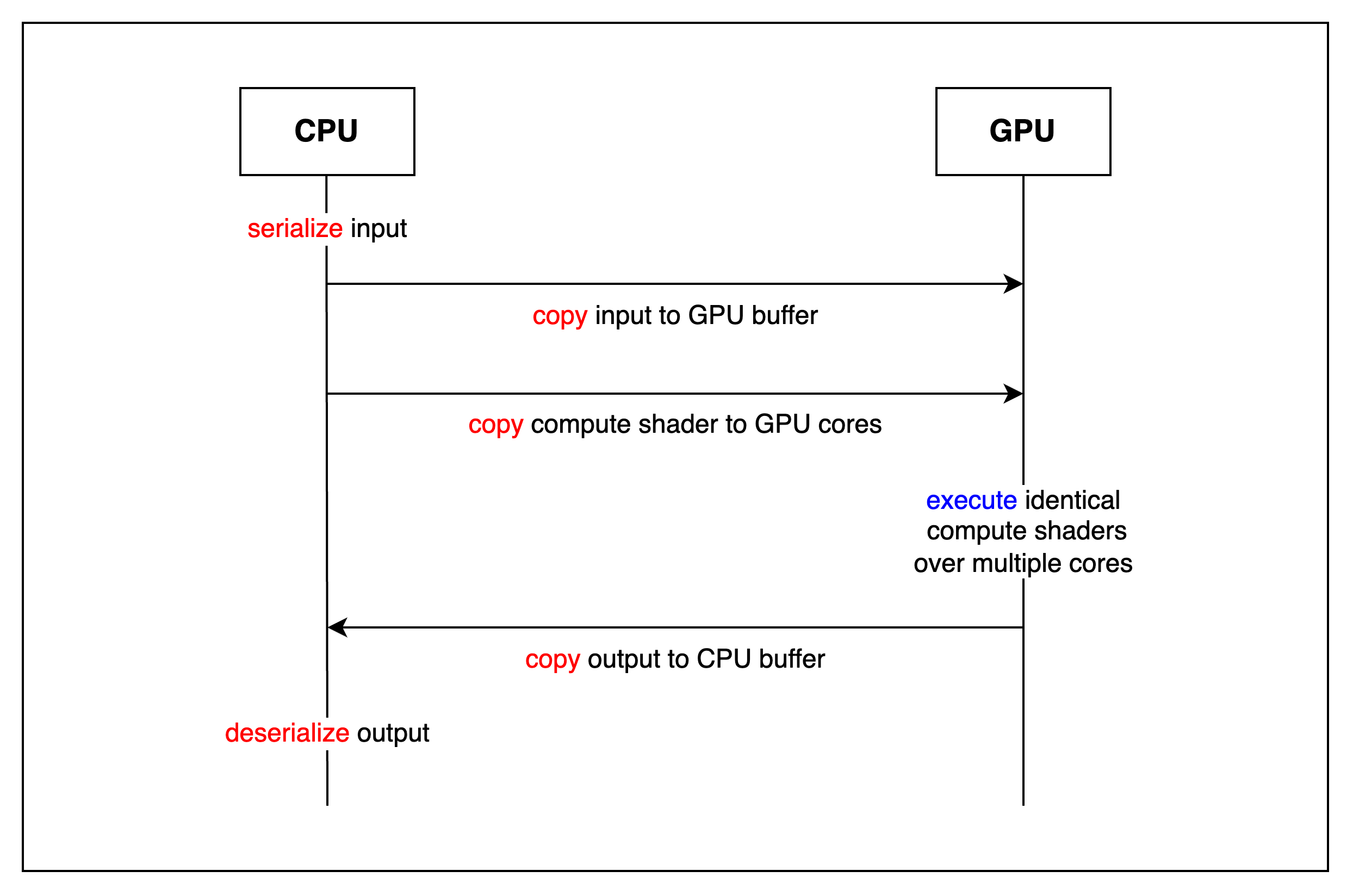
编译 (Compilation)。 zkVM 用户使用高级语言(例如,Rust、C、C++)编写程序,并将其编译为 zkVM 构建所用的特定 ISA(指令集架构)的汇编代码。例如,risc0、sp1 和 Jolt 使用 RISC-V,而 zkm 使用 MIPS。由于这些 ISA 已经获得了广泛使用,因此编译可以重用现有的编译器工具链的大部分。
从用户的角度来看,该过程变化不大,因为他们仍然可以使用熟悉的工具和工作流程,例如标准编译器。但是,许多库在 zkVM 中无法直接使用。这种限制类似于为裸机设备编写程序而没有操作系统的支持,因为许多库依赖于 I/O 操作等在 zkVM 环境中不受支持的功能。
执行 (Execute)。 给定汇编代码和输入,VM 执行程序以生成执行轨迹。执行本质上涉及解释指令,直到程序终止或崩溃。轨迹是执行步骤的序列,其中每个步骤表示一个带有操作数以及对寄存器和内存的读/写操作的指令。
VM 约束和证明 (VM Constraint and Prove)。 zkVM 的核心是证明执行的有效性。这意味着“给定汇编程序和输入,我知道一个有效的执行轨迹,可以生成此输出。” 为了验证轨迹,必须验证提取-解码-执行周期的每个步骤。这主要涉及证明以下三点:
- 指令执行:指令执行正确。例如,如果运行
add 1 2,则结果应为3。 - 内存一致性:内存和寄存器中的读/写操作是一致的。例如,如果将
1写入ra寄存器,则下次从该寄存器读取时应产生1。 - 控制流:例如,在执行当前指令后,应正确提取下一条指令。
为了提高证明者的速度,一些 zkVM 将轨迹分成更小的段,并行地证明每个段,然后将它们组合起来以形成一个完整的证明。
验证 (Verify)。 验证者接收证明,其中包括对轨迹的承诺以及程序输入/输出数据。它本质上检查上述三点,并确认执行是否按预期终止或崩溃。
为了降低验证者的成本,通常使用递归。例如,risc0 使用 STARK-to-SNARK 电路 来验证 Groth16 验证器中的 STARK 证明,从而显著减少了在以太坊上进行验证所需的 gas。
zkVM 中可能出现什么问题
在这里,我们将介绍 zkVM 中每个工作流程阶段(从编译到验证)的潜在漏洞。
编译
以现有的 ISA 为目标,使 zkVM 能够受益于成熟的编译器工具链,但编译器 bug 仍然是不可忽略的风险。如果编译后的汇编代码不能反映预期的源代码逻辑,则可能导致灾难性的安全问题。根据最近的估计,“每个月,应该至少有十几个新的已知漏洞可能导致形式化验证的 RISC-V ZKVM 中的漏洞利用。” 这凸显了依赖编译器正确性可能存在的固有问题。
也就是说,这种风险并非 zkVM 独有——编译器 bug 可能会影响所有类型的应用程序。此外,针对这些问题导致专门针对 zkVM 系统的漏洞利用的频率如何,目前还没有充分的研究。虽然在许多情况下风险仍然是理论上的,但确保编译器可靠性对于构建安全的 zkVM 仍然至关重要。
除了标准编译之外,zkVM 通常涉及自定义预处理,例如专门的库和预编译,以优化性能:
-
指令替换 (Instruction Replacement): 例如,Jolt 使用一系列更适合查找操作的虚拟指令替换
DIV等指令。 -
预编译 (Precompiles): 预编译是一种自定义电路,用于加速特定操作。像 risc0 和 sp1 这样的 zkVM 支持用于加密中一些常用函数的预编译,例如 sha256,以提高性能。
-
自定义库 (Custom Libraries): 一些 zkVM 为高级语言提供优化的自定义库。例如,sp1 实现了
memcpy和memset的 自定义版本 以提高效率。
这些对于 zkVM 功能至关重要的预处理步骤引入了复杂性。至关重要的是,每个步骤都是安全的,并且准确地保留了原始程序逻辑,以避免引入漏洞。
执行
zkVM 的执行阶段应严格遵守底层 VM 的规范,以确保行为的一致性。给定相同的汇编代码和输入,证明者和验证者的执行轨迹和输出必须相同。某些程序可能依赖于操作系统提供的随机性,例如哈希映射,哈希映射通常是随机化的以防止 DoS 攻击。但是,程序中使用的任何形式的随机性都需要以预定的、确定性的方式处理,以确保一致性。例如,在 sp1 中,sys_rand 用于生成 确定性随机性,以防止证明者和验证者之间出现任何差异。
VM约束和证明
在 zkVM 中,用户不再编写 ZK 电路。 通过设计,这很好地让开发人员避免了常见的 ZK 电路陷阱:那些因混合电路外和电路内代码以及误解如何正确约束 witnessed/hinted 数据而产生的陷阱。 话虽如此,复杂性和电路仍然存在! 它只是被移到了一个构建精美的抽象中:VM 本身的电路。 这意味着 ZK 电路错误被移动到该层,它们仍然可能存在并且需要被发现。 就像其他零知识证明项目一样,对 zkVM 电路的任何部分进行约束不足都可能导致严重的安全漏洞。
通常,VM 中的每个指令都需要自己的电路。 例如,在 RISC-V 中,必须仔细约束数十条指令以防止出错。 即使缺少一个约束,也可能允许证明者生成不正确的轨迹。 例如,在单个指令中缺少约束允许不正确的轨迹通过验证。 在 Jolt 中,它使用查找表进行指令处理,这可以减少它需要定义的电路数量。
对于具有预编译功能的 zkVM,电路还必须覆盖这些预编译。 像 sha256 这样的操作需要自定义证明电路来确保它们正常运行。 对 RISC Zero 电路的审核表明预编译功能需要额外注意以避免错误。
内存和寄存器访问的一致性也是至关重要的。 每次读取内存地址时,电路都必须检查该值是否与上次写入该地址的值匹配。 缺少此检查,如 此审核 中所示,可以让证明者在内存中使用不正确的值。
最后,电路必须反映 VM 对特定操作的处理。 一个例子是 RISC-V 对除以零的处理,它不会导致 panic,而是根据操作数返回指定的值。 未能正确实施此行为可能会导致轨迹和预期行为之间存在差异。
验证
验证者根据其验证密钥验证证明。 验证密钥是特定于程序的,其中包含对汇编代码和与执行无关的配置数据的承诺。 它收到的证明数据通常包括程序的公共输入、输出和 zkp 证明。 重要的是不要混淆这些元素。 例如,如果验证者直接从证明数据中获取内存布局,如我们报告的 此 Jolt 问题 中所示,则恶意证明者可能会更改内存布局以覆盖输出。
验证者还应确保程序已正确终止。 如果没有此检查,证明者可能会提交部分轨迹并通过验证,从而可能导致 不 正确的输出。 另一个 Jolt 问题 中出现了这种风险的示例,其中恶意证明者可以伪造具有 不 正确输出的截断轨迹的证明。
总结
zkVM 提供了一种有希望的方式,可以为跨各种平台的计算启用安全、零知识证明。 然而,它们的复杂性来自于多个组件的集成,包括编译器、指令集架构、零知识证明和验证器。 确保每个部分的安全对于维护系统的整体完整性至关重要。
随着 zkVM 的不断发展,重要的是不仅要关注性能,还要关注安全性。 必须严格检查每个组件,从编译到验证,以防止漏洞。 随着 zkVM 技术的快速发展,对潜在风险和缺陷保持警惕对于创建强大而安全的零知识应用程序至关重要。 随着空间的发展,我们将继续关注其发展,并确保安全性仍然是重中之重。
- 原文链接: blog.zksecurity.xyz/post...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





