深入vyper: 稀疏、恒定时间跳转表
- vyperlang
- 发布于 2025-05-14 18:49
- 阅读 1364
本文介绍了 Vyper 0.3.10 版本中引入的 O(1) 选择器表(Sparse, Constant Time Jump Tables,SCTJTs)技术,该技术通过两级哈希表结构优化了合约中函数调用的方法 ID 查找过程,可以根据用户的性能约束,选择针对 gas 优化或针对代码大小优化,显著提升了 Vyper 合约的性能,使其在 gas 消耗和代码大小上与手写的 Huff/Assembly/Bytecode 合约具有竞争力。
作者:Charles
在 0.3.10 版本 中,Vyper 发布了 “O(1) selector tables”。它使用了一种新颖的技术来实现稀疏且恒定时间的跳转表,因此得名 “Sparse, Constant Time Jump Tables” (SCTJTs,稀疏、恒定时间跳转表)。 什么是 selector table?它为什么重要?请继续阅读以了解!
Selector Tables
在每种 EVM 语言中,当你调用合约中的函数时,你需要提供其方法 ID 作为 4 字节的签名(“selector”,或 “method id”,我将交替使用这些术语)。
例如,foo() 的 4 字节签名是 0xc2985578。
这是通过计算字符串 "foo()" 的哈希(keccak256)的前 4 个字节得出的。
这在 ABI v2 规范 中定义。
请注意,EVM 对 ABI 一无所知!ABI 本质上是一种约定,所有智能合约都同意遵守它,以便它们可以相互通信。 因此,当你将该 4 字节签名传递给合约时,它必须对其进行解码并找出要跳转到合约的哪个部分。
在 0.3.10 之前,Vyper 通过线性搜索来完成此操作。 也就是说,它做了类似的事情:
method_id = calldata[:4]
if method_id == 0xc2985578:
goto foo__label
if method_id == 0xfebb0f7e: # method id for `bar()`
goto bar__label
...
## 如果没有找到 method id,则转到回退函数
goto fallback__label
然而,这不是很有效。 EVM 中的每个分支都可能花费 22 gas,以及 11 字节的字节码。 这加起来可不少!对于具有 80 个外部方法的大型合约,在最坏的情况下,仅仅为了解析该方法(只是找到代码中的位置!)就需要花费至少 880 字节和 1760 gas。 该系统唯一的可取之处在于,用户可以手动将 “热门” 方法置于文件顶部,以便在 selector table 中更早出现。 但总的来说,该系统非常昂贵。
实际上,我忽略了一些额外的检查。 它们是 calldatasize 检查和 payable 检查。 它们看起来像这样:
if method_id == 0xc2985578:
assert calldatasize >= 4 # 阻止 method id 之间某些奇怪的冲突
assert callvalue == 0 # foo() 是一个 nonpayable 函数
这些可以被认为是 gas 成本的恒定增加,因为它们不会在搜索期间被遍历,但它们确实会在函数入口之前执行 1 次。
它们也增加了一些代码大小。
特别是,CALLDATASIZE PUSH1 4 LT PUSH2 <revert block> JUMPI 花费 8 字节,而 CALLVALUE PUSH2 <revert block> JUMPI 花费 5 字节。
听起来很便宜,但加起来可不少——对于我们假设的具有 80 种方法的大型合约,这可能会花费额外的 1040 字节!
第一次尝试 – 魔法
我第一次遇到这个问题是在大约 4 年前的 2021 年 7 月。
我一直在进行 Vyper 的代码大小优化,并意识到 selector table 特别昂贵。
我熟悉 switch 语句的常用跳转表实现,但这些实现通常适用于输入值密集的情况(例如,在 1 到 20 的范围内)。
在我们的例子中,方法 id 或多或少随机分布在 32 位空间中,因此简单的跳转表需要 2**32 数量级的代码大小!不可行。
我想要的是一个可以在恒定的 O(1) 时间内解析的跳转表,但允许输入在输入空间中稀疏分布。
我在这里的第一个想法是找到一些魔法哈希函数,将这些 4 字节的方法 id 映射到 0-N 的密集集合(其中 N 是选择器的数量)。 这些通常被称为完美哈希函数,并且理论上可以在给定静态已知的数字集的情况下计算它们。 我很快编写了一个脚本来查找给定一组选择器的这个魔法数字。 它看起来像这样:
##!/usr/bin/env python
from vyper.utils import method_id_int
seed = 1
method_ids = [f"foo{seed + i}()" for i in range(10)]
def HASH(method_id, magic, n):
return (method_id * magic) % n
magic = 0
while True:
method_ids = [method_id_int for sig in signatures]
mapped_method_ids = [HASH(method_id, magic, len(method_ids)) for method_id in method_ids]
if len(set(mapped_method_ids)) == len(method_ids):
print("FOUND MAGIC:", magic)
break
magic += 1
对于 5 个选择器,它有效!我增加了选择器的数量。 到 15 个选择器时,性能急剧下降——我让我的笔记本电脑运行了几个小时,但它找不到解决方案。 这似乎是指数级的。 对于稍微大一点的数字,找到解决方案可能比宇宙的热寂还要长。 我尝试了不同的哈希函数——sha256 代替 mulmod,用于魔法数字的 “聪明” 起始点等等,但没有任何改进算法性能。
那么常规哈希表呢?它们似乎不太有效。 为了最大限度地减少冲突,你需要低负载,而且空间在这里非常宝贵。 即使你解析到一个 bucket,解析 bucket 内的冲突(经典实现为链表遍历)在已经资源匮乏的 EVM 上也不够有效。 我做了一些粗略的估计并得出结论——如果我们需要循环,我们就已经输了!
我把问题搁置了一段时间。
第二次尝试:哈希表
我在 2023 年 5 月再次提出了这个问题。 来自 Curve 的 bout3fiddy 在代码大小方面遇到了一些问题,因此我对 selector table 进行了一些小的 “优化”——其中一些优化最终效果不佳。 我感到沮丧,再次开始考虑 O(1) selector table。我查看了我之前查看过的一些资源,包括关于完美哈希和 cuckoo 哈希 的研究。
但这一次,我更仔细地阅读了这些资源并深入研究了参考文献。
完美哈希构造和 cuckoo 哈希都使用两级技术。我已经拒绝了 cuckoo 哈希,因为它每个项目占用两个槽,这不会带来足够的代码大小节省。
然而,两级技术让我开始思考。为什么我们不在这里使用混合的两级技术呢?我们可以做一些看起来像常规哈希表的事情。但是在进入 bucket 之后,我们不需要循环来解决冲突。我们可以使用以前的魔法数字技术!即使我们无法为大于 ~12 的集合计算魔法数字,我们也可以只针对大小为 10-12 的 bucket。因此,我们只需要两级指针间接寻址即可从 selector 解析到我们需要跳转到的代码目标!
我很兴奋,我很快编写了一些脚本来证明,实际上,我们可以解决大于 10 的集合的这个 “完美哈希”。 我开始在几百毫秒内求解 N > 100 的集合,并且感到满意。 最终,这些脚本演变为调整基准,这些基准今天仍然存在于 Vyper 代码库中。
此时,我确信该技术会奏效。 但是,我必须消除所有细节。 即使该技术是 O(1),如果常数很高,它仍然可能比其他技术更昂贵。 作为参考,selector table 中具有单个 method id 的 selector table(遍历它需要单个分支)的实现成本可能在 56-90 gas 之间。 因此,如果哈希表遍历不能与此相提并论,那么它将不是一个廉价的实现,用户会想要使用更便宜的替代方案。 换句话说,即使使用我们超酷的 O(1) 技术,它仍然必须经过超优化才能具有竞争力!
此时,我去旅行了(我无法摆脱,因为它已经事先安排好了),并且被迫暂停键盘一段时间,置身于大自然中思考。 事实证明,这有助于消除细节。
细节,以及权衡
首先要做的是实际确定哈希函数。
哈希函数必须非常便宜——请记住,即使是最简单的算术运算在 EVM 上也至少花费 9 gas(例如,DUP1 PUSH1 24 SHR)。
鉴于我们的目标是 56 gas,我们在算术运算方面没有太多预算!
我最终选择了一个简单的哈希函数,该函数在调整期间表现良好——单个乘法、右移和模运算。
设置好之后,我开始研究哈希表的布局。它将作为数据部分的一部分驻留在代码中。我很快意识到,对于我们这里的目的,CODECOPY 操作实际上非常昂贵,因为它需要 3 个参数。CODECOPY 操作的最低成本是 15 gas——9 gas 用于参数,6 gas 用于复制操作本身。因此,我们希望最大限度地减少需要使用 CODECOPY 的次数。
我最终得到了两个主要部分:bucket 标头和包含方法信息的表。为了获得 bucket,我们只需将输入 MOD 针对 bucket 的数量,并将其用作 bucket 标头部分的偏移量。从 bucket 标头部分,我们将获得该 bucket 的魔法数字(这本质上编码了关于 bucket 的哈希函数的唯一可变信息),然后使用前面步骤中描述的哈希函数来找到给定 bucket 中方法的位置。这总共导致两次 CODECOPY。
但这引入了一个有趣的问题,即每个 bucket 的开销(乘以 bucket 的数量)是否会掩盖字节码节省?我意识到我们可以通过尝试一系列目标 bucket 大小来改善项目的分布。我们希望最大限度地减少 bucket 开销(有趣的是,与 “正常” 哈希表实现相反,通过最大化 bucket 大小)。因此,我们将花费一些编译时间来尝试优化 bucket 大小。通过尝试一系列可能的 bucket 大小,我们可以以非常高的概率避免 “病态” 情况,在这种情况下,bucket 开销会掩盖 selector table 的其余部分。在绝大多数情况下,bucket 开销小于 selector table 的 10%。
布局
因此,让我们回顾一下布局。我最终采用的布局如下(参见 Vyper 源代码):
bucket 魔术数字 <2 字节> | bucket 位置 <2 字节> | bucket 大小 <1 字节>
我们将把整个 bucket 从 BUCKET_OFST + (method_id % num_buckets) * sz_bucket 代码复制到内存中,然后使用位运算 mload 它并解压缩它。然后我们将使用公式 bucket_location + (method_id * bucket_magic_number >> 24) * sz_function_info 找到函数
每个函数的信息如下所示( 链接到源代码)
方法 id <4 字节> | 标签 <2 字节> | 函数信息 <1-3 字节>
函数信息(1-3 字节,已打包),用于:expected calldatasize,is_nonpayable 位
函数信息(1-3 字节数量)所需的字节数由合约中最大的 expected_calldatasize 数量在编译时确定。
即使函数信息只有 1 个字节,我也能够将 is_nonpayable 位打包到函数信息中,因为 expected calldatasize 始终是 32 + 4 的倍数,因此它总是以位序列 0b00100 结尾。
总而言之,函数信息是 7-9 字节(通常为 7),bucket 标头是 5 字节——由于通常每 10 个函数信息有 1 个 bucket 标头,因此每个方法的摊销大小为函数信息 + bucket 标头是 8 字节。这很好!对于那个 80 方法的合约,我们节省了 1.4KB!
但我遇到了这种方法的限制。还记得我说过每个算术运算至少花费 9 gas 吗?好吧,事实证明,我担心的那个常数运行时因子比我想要的要大。
Gas 的麻烦
解码哈希表的每个组件,即使经过了很好的优化,也会加起来。让我们来分解一下。我将使用 “伪” 汇编,因此会考虑这些指令,但为了便于演示,我将对堆栈变量位置和清理工作稍微松散一些。例如,SCHEDULE 表示我们安排 <variable> 位于堆栈中的正确位置,并且不需要真正的(DUP 或 SWAP)指令来获得它。
// 获取方法 ID:11 gas
PUSH0 CALLDATALOAD PUSH1 224 SHR
// 查找 bucket ID:11 gas
DUP1 PUSH <n_buckets> MOD
// 解析到代码位置,复制到内存:26 gas
PUSH1 5 PUSH1 <szbucket> MUL PUSH2 <BUCKETS_OFST> ADD PUSH1 27 CODECOPY
// 解压缩 bucket 标头:39 gas
PUSH0 MLOAD // 将 bucket 信息加载到堆栈
DUP PUSH1 24 SHR // bucket 魔法值
DUP PUSH1 8 SHR PUSH1 0xFFFF AND // bucket 位置
DUP PUSH1 0xFF AND // bucket 大小
// 计算函数信息位置,复制到内存:42 gas
PUSH1 7 // 函数信息大小
SCHEDULE<bucket size>
DUP<method id> SCHEDULE<bucket magic> MUL PUSH1 24 SHR MOD // 我们的哈希函数!
PUSH1 5 MUL SCHEDULE<bucket location> ADD // 函数信息指针
PUSH1 27 CODECOPY
// 解码函数信息:47 gas
PUSH0 MLOAD // 将函数信息加载到堆栈
DUP PUSH1 1 AND // is nonpayable
DUP PUSH1 0xFFFE AND // expected calldatasize
DUP PUSH1 8 SHR PUSH1 0xFFFF AND // function 标签
DUP PUSH1 24 SHR // function 方法 id
// 执行必要的检查:59 gas
PUSH1 3 CALLDATASIZE GT // 以防方法 id 中有尾随 0
DUP<method_id> SCHEDULE<function method id> EQ // 来自 calldata 的方法 id == 方法 id
AND // 应该回退
PUSH2 <join> JUMPI PUSH2<fallback function> JUMP JUMPDEST<join> // 如果应该回退:goto fallback
CALLVALUE SCHEDULE<is nonpayable> MUL // 错误的 callvalue
SCHEDULE<expected calldatasize> CALLDATASIZE LT // 错误的 calldatasize
OR PUSH2<revert block> JUMPI // 如果错误的 calldatasize 或错误的 callvalue:goto fail
// 我们是自由的!跳转到函数:8 gas
SCHEDULE<function label> JUMP
总计:219 gas 1!与我们的基准相比,这很多。如果我们与二分查找实现进行比较,我们从大约 64 种方法开始优于二分查找(在 gas 方面)。我们真的希望尽可能接近基准。
因此,回顾我们的哈希表实现,我们可以看到有一些地方确实削减了我们的 gas 预算。
- 两个哈希函数——第一个 mod 查找 bucket,第二个更复杂的哈希函数——花费了我们预算的 25%。
- 解压缩所有元数据实际上非常昂贵!这花费了我们预算的 40%。
- 我们为 callvalue 和 calldatasize 检查支付了过多的费用。因为它们存储为数据,所以我们无法进行某些优化——例如,当 nonpayable 标志为 false 时,我们无法优化 callvalue 检查,因为我们需要在运行时检查它。
再次失败!虽然看起来我们走在正确的轨道上。看来……我们现在开始面临代码大小与 gas 的权衡。如果我们检查布局,那么大部分成本都在解压缩中。如果我们放弃一些打包,我们可以降低 gas 成本。如果我们尝试将其中一些当前表现为运行时数据的东西移动到常规代码块中,该怎么办?
所以我开始尝试优化 gas,而不是代码大小。
优化 Gas
既然很明显,大部分 gas 成本都是从数据部分复制东西,我稍微改变了一下方向。我们可以使用相同的技术,但略有不同。在第一次 MOD 操作找到 bucket 之后,我们可以使用更传统的哈希表实现,而不是从数据部分复制函数信息。但是遍历数据很昂贵!没关系,因为我们实际上在编译时就知道哈希表的结构。我们可以遍历代码,而不是遍历数据!
该结构实际上与原始线性搜索算法非常相似。但是,我们使用该初始 MOD 操作使我们_非常_接近我们的最终目标,然后再开始线性搜索。这次,我们希望尽可能优化小的 bucket,以最大限度地减少遍历任何特定 bucket 所花费的 gas 2。使用伪 python 代码而不是汇编可以更好地解释这种技术。
calldata_method_id = calldataload(0) >> 224
bucket = calldata_method_id % n_buckets
## 从数据部分抓取 bucket 位置
sz_bucket = 2
codecopy(28, BUCKET_OFST + bucket*sz_bucket, sz_bucket)
bucket_location = mload(0)
goto bucket_location
...
jumpdest <bucket 1 location>
if method_id == 0xabcd:
... # calldatasize 检查
... # callvalue 检查
goto method_0xabcd
if method_id == 0x1234
... # calldatasize 检查
goto method_0x1234
goto fallback # 关闭 bucket
jumpdest <bucket 2 location>
if method_id == 0xbdef
... # calldatasize 检查
... # callvalue 检查
goto method_0xbdef
goto fallback # 关闭 bucket
这很酷!我们减少了哈希表开销。我们实际上可以估计——bucket 跳转前导码看起来花费了大约 60 gas。并且由于数据都编码在代码中,因此我们不需要设计所有那些令人讨厌的代码布局内容。请记住,每个分支花费大约 22 gas,因此根据所需的检查,我们似乎可以在大约 80-100 gas 中进入我们的函数!
但是,这在代码大小方面将严格大于原始线性搜索。你可以看到这一点,因为哈希表结构 kind of 叠加在代码的线性搜索结构之上。因此,虽然这在 gas 方面非常便宜(对于任何 N > 1!,它几乎总是比线性搜索更有效),但它并没有解决改进代码大小的原始问题。而且,尽管我尽了最大的努力,但我找不到一个折衷方案,一个在代码大小和 gas 方面都严格改进的实现。
一个难题 - 鱼与熊掌兼得?
那么,我该怎么办?我一开始是寻找适用于稀疏值的恒定时间跳转表。现在我有两种了——只是其中一种具有更好的代码大小,而另一种具有更好的 gas 使用率!我应该如何选择哪一个交付给生产环境?在冥想一段时间后,我创建了一个电子表格,比较了各种选项并将其四处展示。
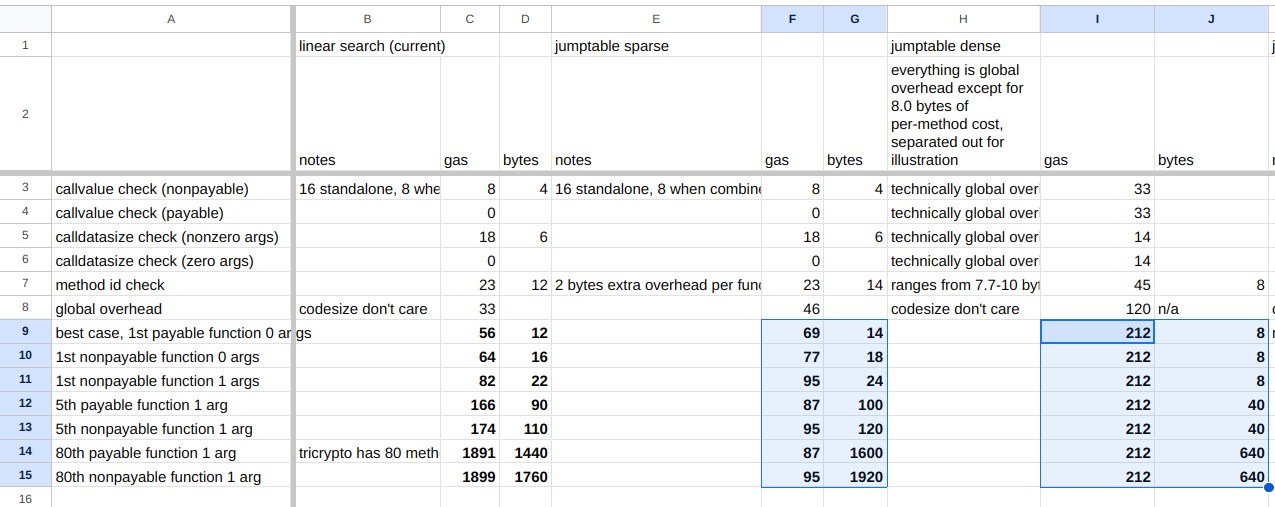
在获得一些反馈后,我发现这两种选择都对用户有用,因为用户应该能够根据他们的性能约束来决定选择哪一个。所以我决定同时实现这两种!并且选择哪个实现由 0.3.10 中引入的一个新的 CLI 标志决定,-Ogas 与 -Ocodesize 3。你可以在 Vyper 代码库的 PR 中看到相关工作和描述 https://github.com/vyperlang/vyper/pull/3496。
结论
事实胜于雄辩。凭借其新的 selector table,Vyper 合约可以与手工制作的 huff / 汇编 / 字节码合约竞争——并且通常比它们更有效 4。这是因为 selector table 从一开始就提供了 gas 优势,甚至在你开始执行任何用户代码之前! (当然,在 huff 或汇编中实现 O(1) selector table 是可能的,但这很复杂,并且各种方法最终都难以维护)。如果你关心 gas 或代码大小,并且一直在犹豫是否尝试 Vyper,那么现在是尝试的好时机!
与往常一样,请随时加入我们的 discord( https://discord.gg/6tw7PTM7C2)或亲自动手并访问我们的 github( https://github.com/vyperlang/vyper))。
下次见!
-
我通过在脑海中进行这些估算(并且,一旦开始出现多个选项,就使用 excel+计算器)来节省了自己进行实现以找出实际成本的工作。我非常惊喜的是,一旦完成了实现,它与我的估算非常吻合:)。置身于大自然中有所帮助! ↩︎
-
我还为此编写了一些 tuning 脚本。它使用了或多或少类似于之前描述的技术,因此我不会详细介绍,但该脚本与之前一样位于 Vyper 代码库中。 ↩︎
-
也可以使用源代码 pragma,例如
#pragma optimize codesize。 ↩︎ -
https://twitter.com/big_tech_sux/status/1679991525172813824 ↩︎
- 原文链接: blog.vyperlang.org/posts...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





