先发可证明断言 - Layer 2
- 以太坊中文
- 发布于 2025-07-18 17:19
- 阅读 1215
本文提出了一种扩展 Rollup 灵活性的机制,允许 L2 用户和合约依赖对未来状态的任意断言,只要他们的交易以这些断言最终被证明为条件。文章探讨了 Rollup 通信的背景知识,介绍了 Anchor blocks,Same-slot message passing,以及实现实时 L1 读取、相互依赖的 L2 交易和跨 Rollup 断言的机制,并提供了一个建议的实现框架和示例。
感谢 Gustavo Gonzalez (Taiko),Jason Vranek (Fabric) 和 Lin Oshitani (Nethermind) 的审核和反馈。
概述
我想描述一种扩展 Rollup 灵活性的机制。我通过 Taiko 的锚定交易机制和 Nethermind 的 Same Slot L1->L2 Message Passing 设计了解到了核心观点,并且我想把它概括为以下陈述:
L2 用户和合约可以依赖关于未来状态的任意断言,只要他们的交易以这些断言最终被证明为条件。
本文将拆解该陈述,并提供一些用例示例。我们将涵盖:
- 关于 Rollup 通信的背景信息,重点关注时间安排。
- 用于读取 L1 状态的锚定区块。
- 同槽消息传递。
- 一种用于实时 L1 读取的机制。
- 一种用于相互依赖的 L2 交易的机制。
- 用于跨 Rollup 断言的机制。
- 一个建议的实现框架。
- 一个示例演练。
为了避免可能的误解,值得强调的是,我倾向于协议严格定义和执行简单、安全和灵活的抽象。为了方便(或作为谢林点),开发团队可能会支持某些特定用例,但它们应该始终在更高的层面上实现。因此,本文试图在两个方向上提高灵活性:
- 该机制(如下所述)被推广以允许任意复杂的断言。
- 示例实现 将“断言”原语暴露给用户、开发人员和排序器,允许他们构建他们选择的任何系统,并承担他们接受的任何风险。协议的工作是提供框架并确保风险得到控制,因此它们只会影响选择加入的参与者。
背景
以太坊每 12 秒选择一个 L1 提议者,该提议者可以将新的 L1 交易聚合到一个区块中,并将其添加到链中。
 \
provable_assertion_images.03098×441 6.2 KB
\
provable_assertion_images.03098×441 6.2 KB
L2 交易来自在 L1 交易中发布的数据。通常,它们以较短的区块时间聚合到 L2 区块中,因此每个 L1 区块有多个 L2 区块。
 \
provable_assertion_images.13098×654 12.4 KB
\
provable_assertion_images.13098×654 12.4 KB
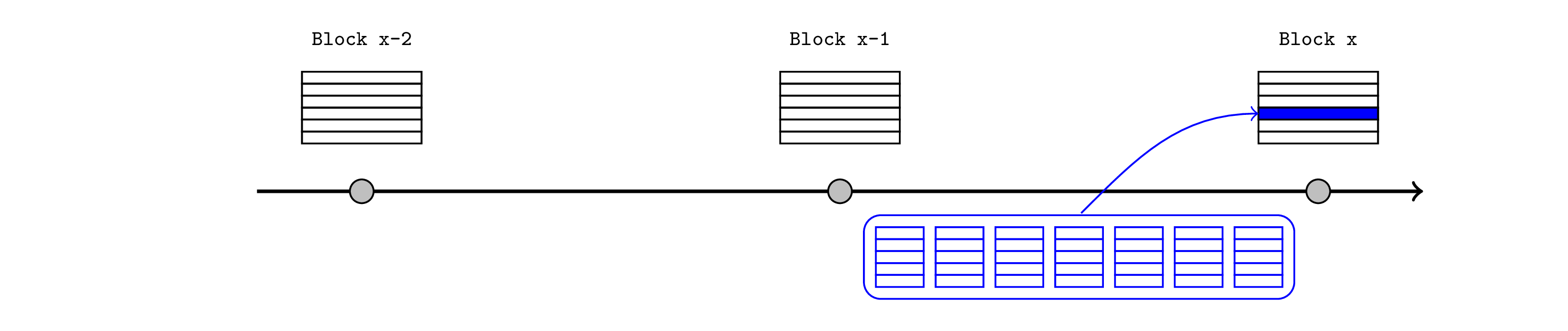
我们专注于 L2 排序器在特定槽位之前可以提供的潜在功能,通常跨越几个 L1 区块(尽管此处仅描述了两个)。
 \
provable_assertion_images.23098×654 13.3 KB
\
provable_assertion_images.23098×654 13.3 KB
这样的排序器在几个槽位上重组 L2 交易的灵活性将受到部分限制,因为他们可能会向用户提供预确认或活跃性保证。每当我们讨论在实际发布到 L1 之前发生在 L2 上的交易时,我们实际上只是意味着它可以影响以后的交易,并且排序器不太可能删除或延迟它。为简单起见,本文将默认描述 L2 区块,就好像它们是连续创建并在实时中最终确定的一样。
锚定区块
我们需要一种将消息从 L1 发送到 L2 的机制,以便 L2 用户和合约可以对 L1 活动做出反应。我将描述 Taiko 的标准架构,尽管这些概念广泛适用于所有 Rollup。
L2 排序器需要以锚定交易开始每个区块,并传入最近的 L1 区块号和状态根作为参数。然后,任何用户都可以证明特定的存储值与最新的状态根一致,并且链的其余部分可以继续了解此信息。
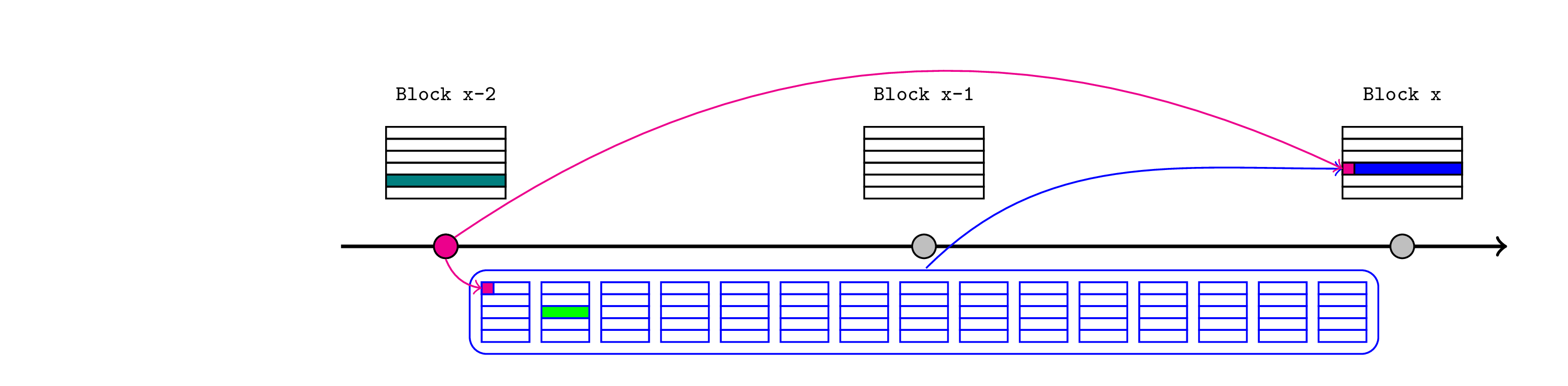
例如,考虑一个跨链 Token 存款和几个后续 L2 区块的场景:
- L1 桥合约接收 Token,并在 L1 存储中记录这一事实(下图中的深绿色交易)。
- L2 排序器将最新的 L1 状态根(粉色)传递到 L2 区块开始时的锚定交易。
- Token 接收者(或任何其他人)向 L2 桥合约提供 Merkle 证明,证明存款已保存在 L1 状态根中的相关存储根下。这说服了 L2 桥,存款发生在 L1 上,因此它释放或铸造 L2 Token(浅绿色)。
- 现在可以立即使用这些 Token 在未来的交易和区块中与 L2 生态系统的其余部分进行交互。
 \
provable_assertion_images.33026×646 8.78 KB
\
provable_assertion_images.33026×646 8.78 KB
请注意,此时排序器直接断言了 L1 状态,而没有提供理由。虽然它是公共信息(因为任何人都可以从 L1 节点检索该值),但这无法从 L2 EVM 内部验证,因此 L2 合约必须简单地相信它是正确的。传递无效状态根的排序器可以捏造一个看似合理的替代历史,该历史从 L2 EVM 内部来看是自洽的。当捆绑包发布到 L1 Inbox 合约时,最终会解决此问题,该合约查询相关的区块哈希,以便将其与注入的状态根进行比较。
 \
provable_assertion_images.43098×763 19 KB
\
provable_assertion_images.43098×763 19 KB
安全架构
让我们回顾一下此机制隐含的安全架构。对 L2 排序器的约束可以分为以下两种:
- Rollup 的规则,由 L2 节点和有效性证明强制执行。
- 其他承诺(例如预确认),由经济 Stake 和声誉强制执行。
锚定区块要求(以及本文中描述的其他断言)属于第一类。这意味着所有相关信息都需要在 L1 上可用,并且在使用 ZK 或 TEE 证明时,还需要可以从 L1 EVM 内部进行验证。这可以通过以下某种组合来实现:
- 在发布时在 L1 Inbox 合约中执行相关的验证。
- 在发布时保存可用信息的哈希值,以便可以用来约束链下证明的输入。
在这种情况下,完整的程序是:
- 排序器从其节点读取最新的 L1 状态和区块号。
- 排序器将这些值传递给锚定交易,这会将它们保存在 L2 状态中。
- 在 Taiko 的情况下,每个 L2 区块都有一个锚定交易,但只有更新最新 L1 状态的交易才与本文相关。
- 排序器继续构建 L2 区块,并可能预先确认它们。
- 最终,排序器将整个捆绑包提交给 L1 Inbox 合约。
- Inbox 合约调用
blockhash(anchorBlockNumber)并将其(哈希值)与发布一起保存。 - Rollup 的状态转换函数(由 Rollup 节点实现)验证整个捆绑包的一致性,其中包括确认(除其他事项外):
- 锚定交易在每个区块的开头被完全调用一次。
- 区块号和状态根参数与 L1 Inbox 查询的区块哈希一致。
这样,断言错误状态根的排序器将使整个发布无效,就像他们违反任何其他状态转换规则(例如超过区块 Gas 限制)一样。任何对无效根做出反应的 L2 交易(例如,铸造没有匹配的 L1 存款的 Token)都将包含在无效的发布中,因此不会包含在最终的交易历史中。
正如我们所见,排序器在构建锚定交易时的主张并非严格意义上的“这是最新 L1 区块的状态根”,而是“此状态根与将在发布区块中检索的区块哈希一致”。这描述了一种通用模式,我们可以在以下情况下使用它:
- 排序器知道他们想在 L2 EVM 内部断言的内容,以便 L2 用户和合约可以基于它进行构建。
- 证明该主张所需的任何 L1 信息最终将在发布时在 L1 EVM 中可用。请注意,这并不意味着该主张本身需要在 L1 上进行验证,只是最终的发布可以包含排序器提供的数据和 L1 验证的数据的混合。
- Rollup 的状态转换函数要求证明该主张才能使发布有效。
我推荐的断言机制只是通用地实例化了这种模式。
同槽消息传递
这个想法是由 Nethermind 提出的,正如该帖子中所解释的那样,它可以与他们的快速提款机制结合使用,以执行同槽往返操作。在这里,我将只关注 L1 到 L2 消息的断言和证明结构。
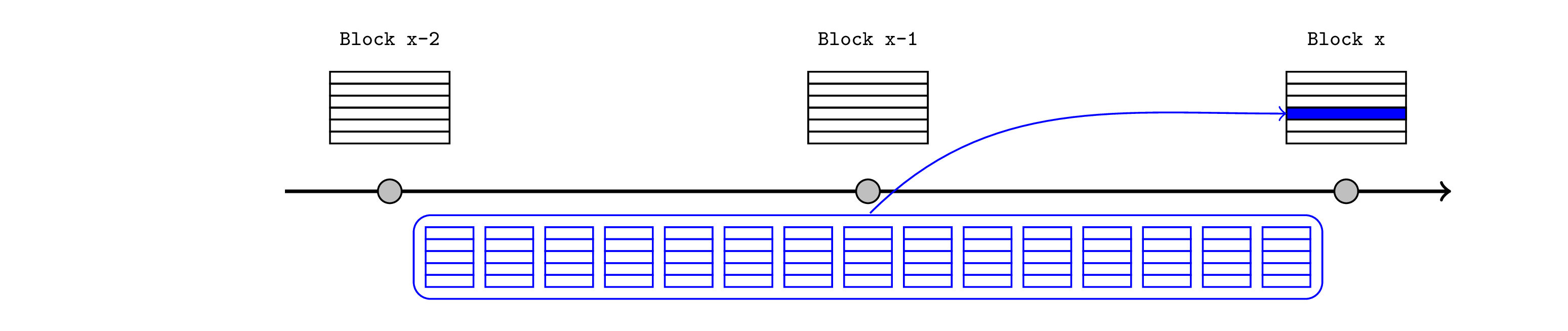
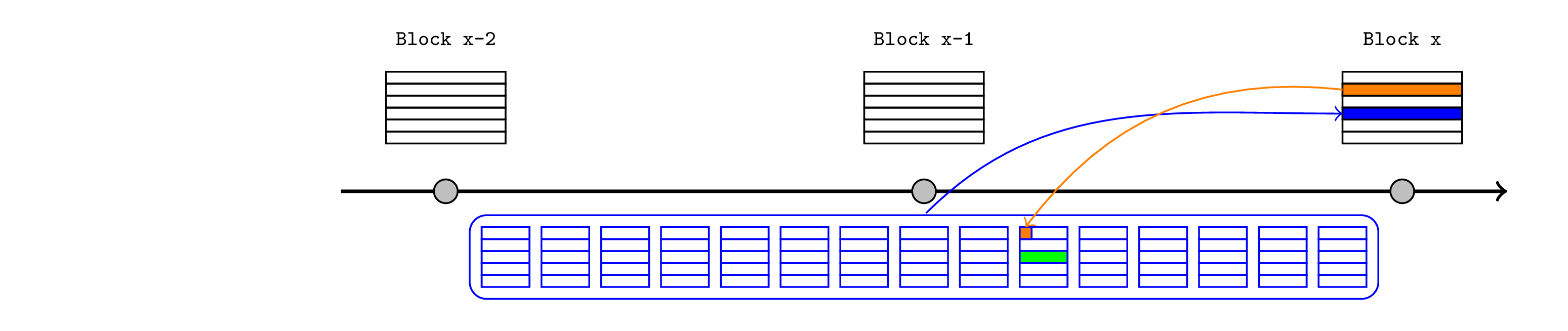
如前所述,锚定区块机制要求 Inbox 合约查询相关 L1 区块的区块哈希,这意味着它不支持对当前 L1 区块中包含的交易做出反应。但是,如果 L2 排序器可以预测特定的 L1 交易将包含在发布区块中(在本例中为橙色),则可以立即在 L2 中断言该主张。
 \
provable_assertion_images.53098×654 16 KB
\
provable_assertion_images.53098×654 16 KB
对于同槽存款,程序将是:
- 用户签署一项交易,该交易存入 L1 桥合约。
- L2 排序器认为此交易将在其自己的发布交易之前包含,并且会成功。
- 通常,这意味着 L2 排序器也是 L1 排序器(即,它是Based Rollup 的),但也可以通过 L1 预确认来实现。
- 排序器构建相应的“信号”(存款详细信息的哈希值)并将其传递给锚定交易,这会将它保存在 L2 状态中。这应解释为排序器断言存款将发生在 L1 上。
- 这说服了 L2 桥,因此它释放或铸造 L2 Token。
- 排序器继续构建 L2 区块,并可能预先确认它们。
- 最终,排序器将整个捆绑包提交给 L1 Inbox 合约。
- Inbox 合约执行“存在性查询”以确认信号已记录在 L1 存储中。它还将信号的(哈希值)与发布一起保存。
- Rollup 的状态转换函数(由 Rollup 节点实现)验证整个捆绑包的一致性,其中包括确认(除其他事项外)锚定交易中注入的信号与 Inbox 合约验证的信号匹配。
与之前一样,这可以确保排序器的断言在发布时得到确认,否则整个捆绑包无效。
泛化预览
这种结构允许一些非常直接的泛化。特别是,Taiko Inbox 合约实际上根本没有与同槽 L1 交易进行交互,而只是确认了它将在专用 SignalService 合约中产生的信号的存在。Inbox 还可以查找任何其他 L1 交易(例如,预言机更新、空投、DAO 投票等)的证据,这些交易在可公开访问的 L1 存储中留下残余物。只要排序器知道以下内容,该机制就可以直接工作:
- L1 交易将在其自己的发布之前包含,并且
- 在此期间不会发生任何可能使其失效的事情。在大多数情况下,这需要先前发布的 L1 区块。
也可以直接从 L1 Inbox 进行目标 L1 调用,这消除了更新存储的需要,但提议者需要承担 Gas 成本。
更有趣的是,Inbox 可以保存任意一组查询恰好返回的任何内容(的哈希值),而不是简单地坚持信号存在。这样,Inbox 将负责采取 L1 操作并检索 L1 状态,但不需要了解 L2 断言或评估它们是否已确认。这可以推迟到更复杂的 L2 逻辑。例如,排序器可以断言交易将不会在 L1 上发生,或者在知道确切的投票数之前,它可以断言 DAO 提案在发布时将至少有 X 票。
当我们讨论我建议的实现时,这应该会更清楚。
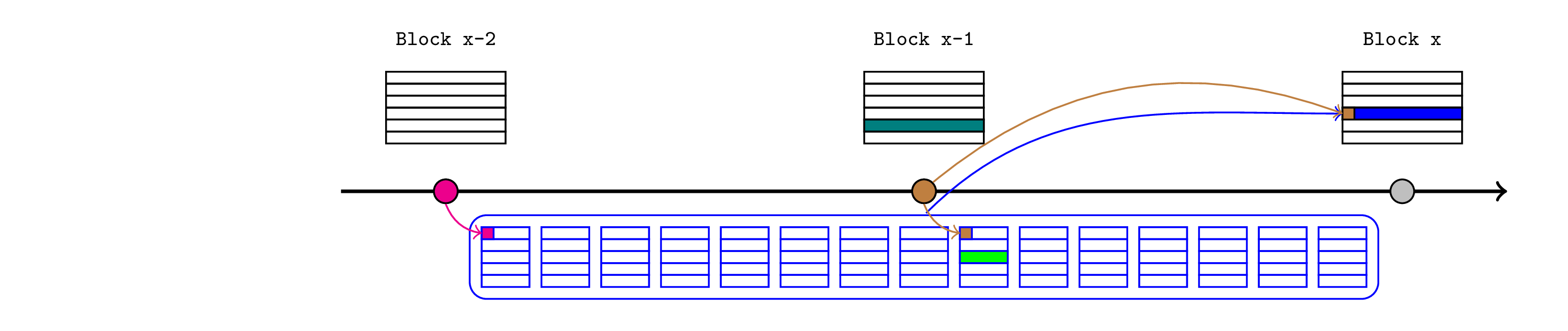
实时 L1 读取
当 L2 发布跨越多个 L1 槽位时,如果每个中间 L1 状态根在已知时立即在 L2 状态中进行断言,这将非常有用,这将允许 L2 合约在 L1 更新发生时立即对其做出响应。例如,深绿色交易可能是对 ENS 解析器的更新,或者价格 Feed 中的新价格。浅绿色交易可能是立即响应此更改的 DeFi 协议(一旦声明了状态),即使它发生在发布期间。这可以通过将锚定机制直接应用于每个区块来实现。
从表面上看,这似乎需要 Inbox 为每个中间区块进行不同的 blockhash 调用,但作为一种优化,排序器可以在证明断言时在 L2 上重现整个 L1 区块头链(从上次验证的区块头开始)。如果在 L1 上验证了上一个区块哈希,则会隐式验证整个链。
 \
provable_assertion_images.63098×654 36.6 KB
\
provable_assertion_images.63098×654 36.6 KB
值得注意的是,此机制允许排序器提供实时更新,但它不会强制他们这样做。可以将 Rollup 设计为强制执行诸如“必须在时间戳较晚的任何 L2 交易之前断言 L1 区块哈希”之类的规则,但这只是关于记录的最终顺序的陈述(这在排序器的控制之下),而不是它在现实世界中发生的时间。我们仍然依赖于预确认或其他外部机制来约束排序器延迟提供最新区块头的时间。
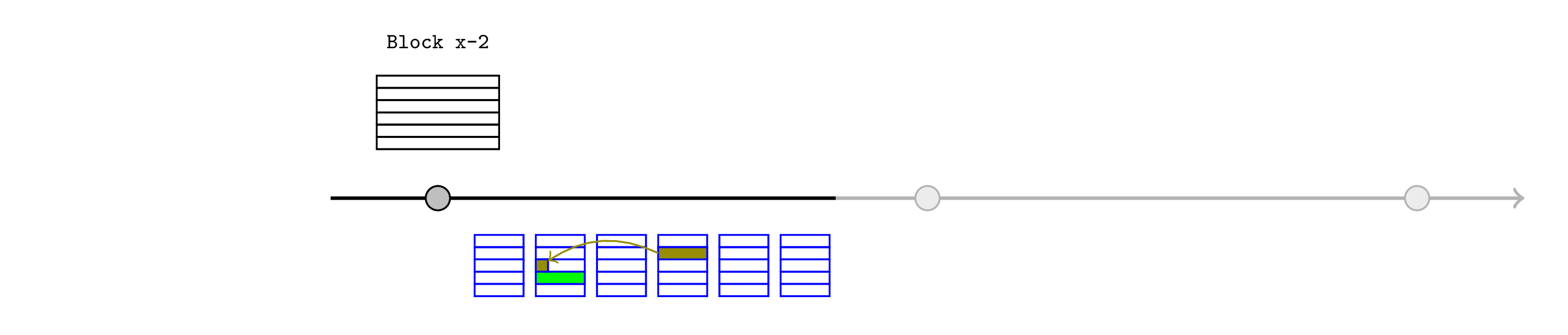
相互依赖的 L2 交易
排序器可以预测的一类状态是他们正在构建的发布中的 L2 状态。在决定遵守关于未来状态的某些约束之后,他们可以立即断言该声明,以便 L2 合约可以依赖它。
 \
provable_assertion_images.73026×646 9.19 KB
\
provable_assertion_images.73026×646 9.19 KB
这可以简化相互依赖的交易。例如,考虑一个字面意义上的囚徒困境合约。
contract PrisonersDilemma is IPrisonersDilemma {
const uint256 COOPERATE = 1;
const uint256 DEFECT = 2;
mapping(address participant => uint256 choice) public choices;
function choose(uint256 choice) public {
require(choices[msg.sender] == 0);
choices[msg.sender] = choice;
}
function payout() public {
// 根据囚徒困境支付表分配奖励
}
}
此示例通常用于解释博弈论,但在区块链的上下文中,这只是一个协调和时间安排问题。面临的挑战是,第二个选择的人可以自由选择 DEFECT,而无需担心报复,这意味着没有参与者会先选择。理想情况下,双方参与者都会发布一项交易,声明“如果我的伙伴选择 COOPERATE,那么我也选择 COOPERATE”。这是通用多方同时交易的代表(例如,“如果你给我发送一个 NFT,我将向你发送 ETH” 或 “如果你向这家慈善机构捐款,我将给予你正面评价”)。
解决此问题的标准方法是让双方参与者将其投票权委托给外部协调合约。请注意,7702 增强型 EOA 是不够的,因为它不具有约束力:委托给选择 COOPERATE 的代码不会说服你的伙伴,因为你始终可以在以后更改代码。这增加了复杂性,因为双方参与者都需要验证协调合约中是否存在漏洞,并增加了时间安排开销,以考虑委托权利并从无响应伙伴的可能性中恢复。
使用断言,每个参与者都可以通过执行以下代码段(通过合约或 7702 增强型 EOA)单方面声明其有条件的选择:
// 检索我的伙伴在下一个区块中记录的选择
// 我们可以使用相同的区块,但使用下一个区块有助于强调这个概念
partnerChoice = getAssertedFutureState(
block.number + 1,
prisonersDilemma,
abi.encodeCall(IPrisonersDilemma.choices, partner)
)
require(partnerChoice == COOPERATE);
// 现在我确信我的伙伴会选择 COOPERATE,我也可以。
prisonersDilemma.choose(COOPERATE);
假设双方参与者(我们称他们为 Alice 和 Bob)创建并发布了这样的交易。排序器可以识别出两项交易可以一起成功。然后,他们可以按顺序排列以下记录:
- 使用以下代码段断言下一个区块中的
choices调用将为双方参与者返回COOPERATE:
assertFutureState(
block.number + 1,
prisonersDilemma,
abi.encodeCall(IPrisonersDilemma.choices, alice), COOPERATE
)
assertFutureState(
block.number + 1,
prisonersDilemma,
abi.encodeCall(IPrisonersDilemma.choices, bob), COOPERATE
)
- 将 Alice 的交易包含在当前区块中,以将其选择设置为
COOPERATE。回想一下,如果排序器尚未断言 Bob 将选择COOPERATE,则这将恢复。 - 包含 Bob 的交易以将其选择也设置为
COOPERATE。 - 此时,游戏已完成,但排序器仍需要证明两个未完成的断言(如下所述)。
这种机制允许用户简单地声明他们期望的结果,从而将协调和复杂性分流给区块构建者。如果参与者使用以下代码段自行进行断言(可能使用下面描述的 pauser 机制),则可以进一步简化它:
// 直接断言我的伙伴会合作。如果排序器不同意,则不会按顺序排列此交易。
assertFutureState(
block.number + 1,
prisonersDilemma,
abi.encodeCall(IPrisonersDilemma.choices, partner), COOPERATE
)
// 现在我确信我的伙伴会选择 COOPERATE,我也可以。
prisonersDilemma.choose(COOPERATE);
这允许 Alice 直接为她想要的断言付费,而不是独立地补偿排序器,并消除了她为恢复交易付费的可能性(如果她的交易是单独按顺序排列的)。
该机制还允许复杂的交易随着时间的推移逐步解决。例如,考虑一个用户,他提出从他们的 DeFi 投资中提取资金,并向任何人提供无担保贷款,只要这些资金以一些最低利息返还,并且可能与构建者共享,以证明其努力的合理性。这就像提供闪电贷,因为不需要抵押,并且必须偿还贷款,否则就不会发生,但它可以跨越多个 L1 槽位(只要它仍在排序器的发布窗口内)。
在排序器知道它可以满足条件之前(即,存在另一项交易接受贷款并偿还全部金额并支付利息),要约交易将位于 L2 内存池中。此时,排序器可以断言将偿还贷款并预先确认要约交易。生态系统的其余部分可以通过发出事件或抢先支付股息(从非贷款资金)来建立在贷款将得到偿还这一认知之上。
但是,排序器不必确认证明断言合理的特定交易。相反,他们可以等待查看生态系统的其余部分如何发展,以防有更有利可图的交易序列。这可能涉及 L1 存款或可以在 L2 中断言的预言机更新,或者可能只是 L2 内存池中的新交易。一旦选择了特定的贷款序列,排序器就可以包含(并可能预先确认)这些交易,然后证明该断言已实现。
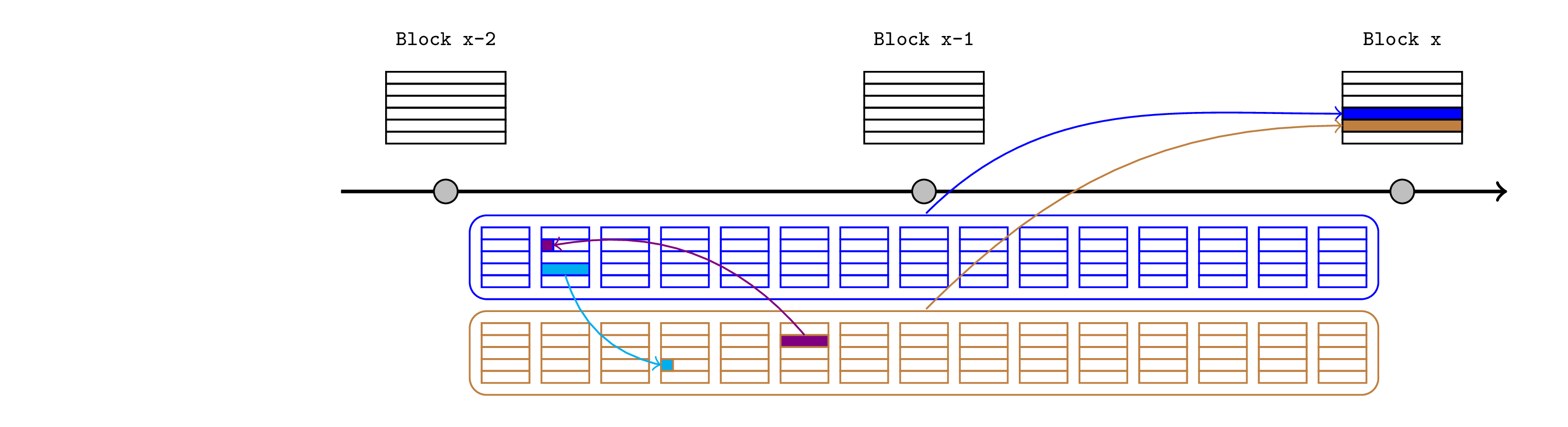
跨 Rollup 断言
可以将相同的模式扩展为提供跨 Rollup 原子性,但需要一些额外的依赖项或假设。考虑一个交换,其中 Alice 在 Rollup A 上向 Bob 发送 10 ETH(浅蓝色),以换取 Bob 在 Rollup B 上向 Alice 发送 10 ETH(紫色)。目标是确保没有一项交易可以在没有另一项交易的情况下包含,这是通过要求排序器在两个 Rollup 中断言另一项交易的存在来实现的。如果尚未进行相关的断言,则每个交易都将恢复。
 \
provable_assertion_images.83098×843 50.6 KB
\
provable_assertion_images.83098×843 50.6 KB
特定机制和相应的安全属性取决于底层假设,因此让我们探索一些选项。
设置
在本文中,我们假设跨 Rollup 机制由一个实体实现,该实体对所有相关 Rollup 具有临时的垄断排序权,直到给定的 L1 槽位。这在处理Based Rollup 时是一种自然的情况,在这种情况下,每个排序器都可以选择加入他们选择支持的任何 Rollup。但是,我们不假设 Rollup 之间有任何协议来保证共享排序。我们预计会有一个动态过程,不同的排序器可以自由选择加入或退出不同的 Rollup,或者可能因某些 Rollup(但不是所有 Rollup)而被禁止或没有足够的 Stake。
需要明确的是,这两种方法并非相互排斥。主要的 Rollup 仍然可以在共享排序器(如 AggLayer)上进行协调,以获得所有的可组合性和流动性优势,而 Rollup 用户 可以利用此处描述的机制与较小的 Rollup 和应用程序链进行跨域通信。但是,机会主义环境提出了一个非常强的要求,这使可组合性变得复杂:Rollup 的状态必须完全从 L1 上可用的信息中在 Rollup 的节点中推导出来,即使它取决于发生在另一个 Rollup 上的活动。
要理解这一要求,请考虑如何包含我们想要的原子交易(为了简单起见,只关注一侧,但另一侧是对称的):
- 当一个特定实体可以按顺序排列 Rollup A 和 Rollup B 的交易时,就会出现机会。
- 此排序器在其发布中包含两个相互依赖的交易。只有当 Bob 在 Rollup B 上成功进行交易时,Alice 在 Rollup A 上的交易才应成功。
- 一旦发布了捆绑包,任何运行两个 Rollup 节点的实体都可以重建两个 Rollup 的状态,并且可以确认两项交易都成功了。
- 但是,下一个 Rollup A 排序器可能没有运行 Rollup B 节点,或者对 Rollup B 状态一无所知。如果他们无法确定 Bob 在 Rollup B 上是否成功进行了交易,他们就不知道 Alice 在 Rollup A 上的交易是否应该成功。Rollup B 状态最终将在 L1 上得到证明,但在那之前,Rollup A 排序器无法确定 Rollup A 的当前状态,因此他们无法在其之上进行构建,并且 Rollup 将停止。即使 Rollup B 提供预确认,我们也无法强制 Rollup A 排序器依赖它们。
- 因此,关于 Bob 的交易是否成功的消息必须以某种方式在下一个排序器开始构建时(即,一旦发布 Rollup A 捆绑包)在 L1 上可用。
实时证明
当我们进行实时证明时,可以轻松解决此问题。任何创建跨 Rollup 断言的排序器都必须在发布时包含对发布正确性的证明。这样,经过验证的 Rollup B 的最终状态(在 L1 上可用)可用于证明 Rollup A 中的跨 Rollup 断言,就像本文中在发布时可证明的所有其他断言一样。
不幸的是,实时证明目前仅适用于具有简单状态转换功能的简单应用程序链。
Staked Claim
一种中间机制是要求所有排序器在每次发布时都发布最终 Rollup 状态。这将是 Rollup 规范的一部分,因此不正确的状态根将使整个发布无效。默认情况下,排序器将受到激励发布正确的值,以确保他们收到发布费用,保留任何 Stake 存款,并继续留在 Rollup 的排序器集中。
请注意,这在共享排序器(例如,AggLayer)方法中也很有用,因为发布的状态将像强预确认一样起作用。它将比常规预确认更强大,因为它将 Rollup 限制为只有两种可能的状态(发布的状态有效或状态未更改),并且当最终解决证明时,将自动执行任何处罚。
在我们的例子中,可以针对声明的状态证明跨 Rollup 断言,无论它最终是否被证明是正确的。使用跨链交换示例(为了简单起见,只关注一侧,但另一侧是对称的):
- 排序器将决定包含两个相互依赖的交易。
- 在 Rollup A 上,他们断言 Bob 将在 Rollup B 上向 Alice 发送 10 ETH。
- Alice 在 Rollup A 上的交易确认了断言,然后执行转移。
- 排序器继续在两个 Rollup 上构建 L2 区块,并可能预先确认它们。
- 最终,两个捆绑包都将提交到各自的 Inbox 合约,以及声明的状态根。
- Rollup A Inbox 合约将声明的 Rollup B 状态根与 Rollup A 发布一起保存。
- Rollup A 的状态转换函数验证整个捆绑包的一致性,其中包括确认(除其他事项外)Bob 的交易记录在声明的 Rollup B 状态根中(因此证明了断言)。
请注意,存在一个额外的间接级别,这会带来新的风险。本文中的所有断言都视为整个捆绑包的有效性条件,因此 L2 合约可以基于它们进行构建,并且盲目地假设它们是正确的。如果未证明它们,则无论如何都会丢弃(或恢复)任何依赖交易。但是,在本例中,断言只是 Bob 的交易记录在声明的 Rollup B 状态根中。即使最终证明声明的状态根是不正确的,此断言也可能是正确的。在这种情况下:
- Alice 的交易将包含在 Rollup A 中,但整个 Rollup B 发布将被丢弃(因此 Alice 最终将发送单边转账)。
- 排序器将失去与丢弃的 Rollup B 发布相关的所有交易费用,以及任何已存入的 Stake。
如果用户认为对排序器的成本足够大以阻止以这种方式违约,或者 Stakes 足够低,则应仅考虑此机制。它也可以在用户只想确保另一个 Rollup 上没有交易的任何情况下使用(因为要么声明的状态是正确的,要么另一个 Rollup 的状态未更改)。但是,Rollup 协议本身不应依赖 Staked Claim 进行已内置的操作(例如本机桥),因为这会将风险传播给未选择加入的用户。
Sub-publication 证明
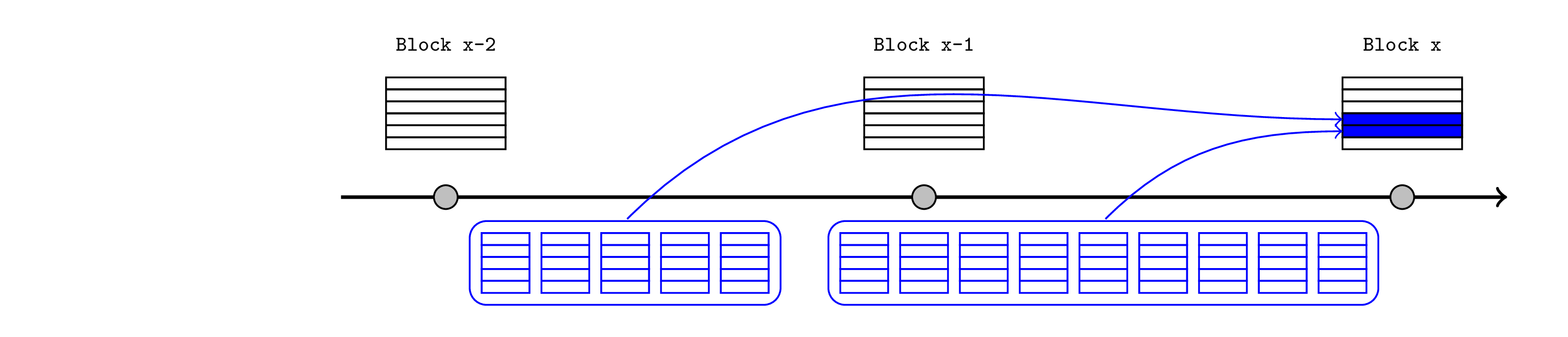
既然已经证明了子槽证明,我们应该考虑排序器提供子发布证明的设计。我们可以想象将发布分为带有发布时间证明的区块以及尚未证明的区块。为了简单起见,我们可以将这视为两个不同的发布交易(尽管它们不需要是)。
 \
provable_assertion_images.93098×665 16.7 KB
\
provable_assertion_images.93098×665 16.7 KB
值得注意的是,证明发布中的任何区块都意味着确保整个先前的发布已经得到证明。在这种情况下,我们可以使用实时证明机制,只要排序器仅对其知道能够及时证明的 L2 区块中的交易进行跨链断言即可。当然,在发布之后仍然可以证明使用或建立在断言之上的区块。
实现框架
正如已经解释的那样,我认为 Rollup 设计应该支持进行断言的通用模式,但不应该对哪些特定断言有效或应该如何解决它们持有任何意见。相反,各个排序器应该决定他们支持哪些断言(如果有),并且 L2 用户和合约应该决定依赖哪些断言。这意味着 L2 用户有责任确保排序器选择的证明机制能够可靠地确认断言。
基本结构是一个(在 L2 合约中)未证明断言的映射,该映射在每次发布的开始和结束时都必须为空。assertionId 是描述断言类型以及创建它的 msg.sender 所需的任何内容的哈希值,并且只能由同一地址清除。value 将是任何特定于实例的数据(或可能是一个哈希值)。
mapping(bytes32 assertionId => bytes32 value) public assertions;
创建未证明的断言
举例来说,任何人都可以部署一个 RealtimeL1State 合约,该合约断言诸如 “在 L1 区块 B 状态为 S” 之类的声明,并且该断言会将 keccak256(abi.encode(address(realtimeL1State), B)) 映射到 S。排序器可以在他们想要更新关于最新 L1 状态的 L2 时调用该合约,从而创建一个未经证明的断言序列。rollup 将强制执行(如下所述)这些断言在发布结束时被清除。
此时,L2 用户或合约可以看到映射中的断言,并且如果他们确信 RealtimeL1State 合约只有在证明与 L1 历史一致时才会清除该断言,则可以依赖它们。他们可以使用断言的状态来说服其他合约(信任 RealtimeL1State 合约)特定的 L1 合约在存储中具有特定的值。
类似地,任何人都可以部署一个 FutureL2Call 合约,该合约断言诸如 “在 L2 区块 B 的某个时刻,由该合约在目标 D 上调用的 calldata C 将成功并返回值 V” 之类的声明,并且该断言会将 keccak256(abi.encode(address(futureL2Call), B, C, D)) 映射到 keccak256(V)。排序器可以调用该合约以保证他们将尊重此条件,并且 L2 用户或合约可以在此假设下进行。
最后,任何人都可以部署一个 PublicationTimeCall 合约,该合约断言诸如 “Inbox 合约在发布时在目标 D 上调用的 calldata C 将成功并返回值 V”。他们可能希望允许对返回值进行通用条件设置,以涵盖排序器知道 V 的相关属性但并不完全知道它的情况。有趣的是,这可能包括排序器保证关于他们自己发布的声明的情况,例如 “如果 L1 DAO 投票支持,则此 L2 交易将被包含”。为了允许这种灵活性,可以将断言概括为 “Inbox 合约在发布时在目标 D 上调用的 calldata C 将成功并返回一个值,该值可以传递给 L2 函数 F(也在发布时)以返回值 V”。该断言会将 keccak256(abi.encode(address(publicationTimeCall), C, D, F)) 映射到 keccak256(V)。这里的直觉是 Inbox 需要执行 L1 调用并保存(结果的哈希值),但是用户定义的 L2 合约可以描述断言并评估是否已证明。请注意,此机制可用于涵盖对公开可用状态的查询(例如,桥中的先前存款、预言机更新、DAO 投票总数)、实际的 L1 状态更改操作(例如,在桥中存款、更新预言机、在 DAO 中投票)或描述其他 Rollup 的值(例如,最新的已证明状态或排序器声明的状态)。
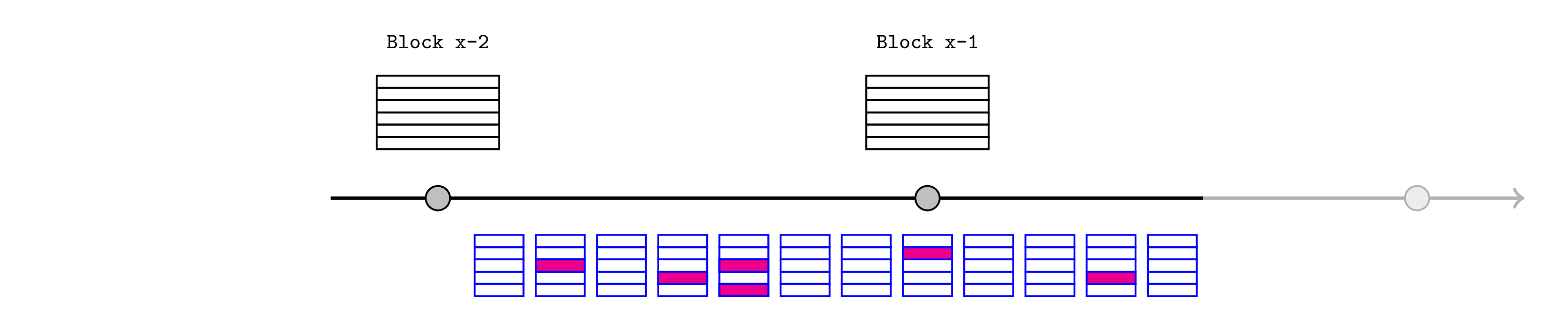
当构建发布时,它将包含越来越多的需要证明的断言集合。
 \
provable_assertion_images.103026×646 8.56 KB
\
provable_assertion_images.103026×646 8.56 KB
证明断言
仅依赖 L2 状态的断言可以在发布中解决。例如,FutureL2State 断言(即 “在 L2 区块 B 的某个时刻,此合约在目标 D 上调用的 calldata C 将成功并返回值 V”)可以通过进行调用并确保它返回正确的值来在区块 B 中清除。排序器必须确保包含这样的交易才能使发布有效。
那些需要 L1 状态的断言将需要 rollup 状态转换函数(由 rollup 节点实现)的帮助。例如,如果 RealtimeL1State 合约获得了 L1 区块 X 的区块哈希:
- 任何人都可以提供整个 L1 头部,以证明它具有预期的哈希值。
- 由于头部包含状态根和前一个区块哈希,因此这两个值都将被证明。
- 可以使用区块 X-1 的哈希来重复此操作,以找到区块 X-1 的状态根和区块 X-2 的哈希。
- 可以重复此操作以覆盖发布期间发生的所有 L1 状态根。
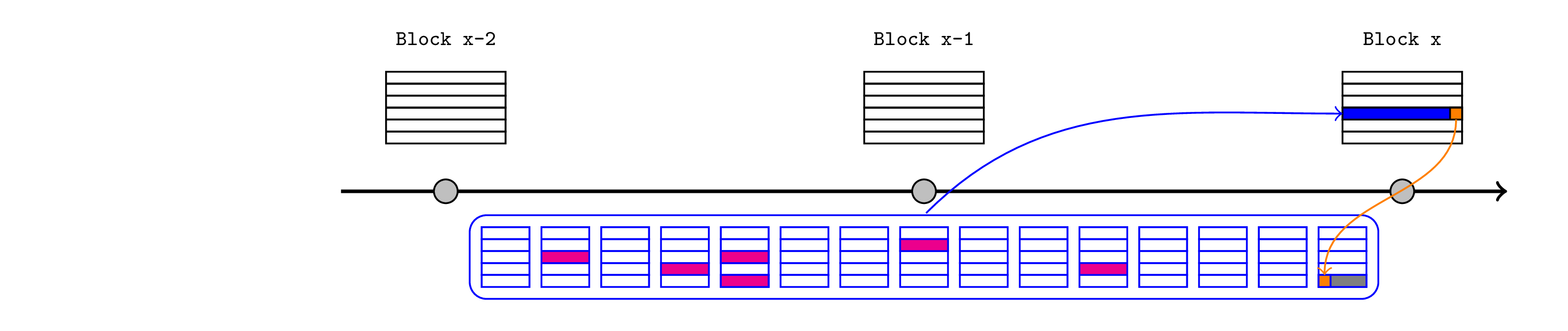
现在的问题是如何确保为区块 X 提供的哈希是准确的。我的建议是在 Inbox 合约中收集所有相关的 L1 数据,该合约应涵盖最新的 L1 区块哈希和排序器指定的所有调用的结果。此数据的哈希(我们称之为 一致性哈希)将作为发布的一部分包含在内。然后,每个发布都应包含一个发布结束交易,该交易:
- 接受一致性哈希
- 将其(和任何相关信息)传递给断言合约,断言合约可以在验证它们已满足后清除断言。
- 如果有任何未经验证的断言,则还原。
状态转换函数将保证:
- 这是发布中的最后一笔交易。
- 输入哈希与在 L1 上计算的值匹配。
- 交易成功。
这确保了每个断言都按照创建它的合约的标准进行验证,可能会使用发布时的 L1 数据。
 \
provable_assertion_images.113098×654 16.5 KB
\
provable_assertion_images.113098×654 16.5 KB
请注意,由于一致性哈希(图中的橙色)包含在发布结束交易中,因此该机制假设排序器能够在发布捆绑包之前预测其值,这意味着以下情况之一:
- 这是一个基于 L1 的 rollup
- 在排序器创建发布结束交易与 L1 中确认发布之间,查询的结果无法更改(这将是最常见的情况)。
- 排序器已收到相关的 L1 预确认。
此机制为 stake 的跨 rollup 断言选项带来了一个小小的复杂性。在这种情况下,排序器需要在发布后发布 rollup 的声明状态。但是,rollup B 的声明状态将成为 rollup A 的一致性哈希的一部分,这意味着它将影响 rollup A 的最终状态。使用此机制的双向跨 rollup 断言将引入循环依赖关系。这可以通过注意到发布结束交易对最终状态具有非常 specific 且可预测的影响(它会清除未经验证的断言)来解决,但为了简单起见并避免与 gas 成本相关的复杂性,可以更改该机制以要求排序器在发布结束交易之前立即提供状态。
分配角色
一个值得考虑的有趣问题是谁有权力和动机来进行和证明断言。如所述,允许排序器包含发布其捆绑包时要进行的任意 L1 调用列表。rollup 节点仅强制执行最近的 L1 区块哈希(由排序器选择)和这些调用的结果将忠实地传递给发布结束的 L2 交易,并且该交易成功。其余逻辑包含在常规 L2 合约中,必须使用支付 L2 gas 的常规 L2 交易来调用。
由于排序器正在为用户提供额外的服务,因此他们可能会收取以下费用:
- 他们产生的任何增加的 L1 gas 成本(例如,支付 Inbox 中其他查询的费用)
- 他们产生的任何 L2 gas 成本(例如,进行或证明断言)
- 他们在构建发布时因限制其选项而可能损失的任何机会。
- 验证他们是否能够证明用户想要的任何断言所需的任何努力(例如,确保 L1 查询在发布时具有可预测的结果)。
为方便起见,我建议断言合约由 pauser 地址启用和禁用,pauser 地址由任何人在为零时设置,并在发布结束交易中重置为零,这允许排序器在发布开始时设置受信任的 pauser 地址。这并非绝对必要,因为排序器也可以拒绝包含进行未经认可断言的交易,但它提供了一种机制,让排序器与用户协调并推迟成本。特别是,pauser 地址可以是一个仅允许来自白名单集的断言的合约,并且可能要求用户提供足够的预先证据并支付足够的费用。例如:
- 声称 L1 区块 B 的区块哈希为 H 的用户可以提供证明所需的 L1 头部,以及足够的资金来支付 L1 上的
blockhash查询。 - 想要断言某些属性在 L2 区块 X 中为真的用户也可以签署需要在区块 X 中排序的证明交易。
排序器仍然负责确保所有断言都得到证明(因此他们应该只包含进行有效可证明断言的交易),但此机制将部分分析和成本推迟给用户。它还允许用户在同一交易中创建断言并对该断言做出反应,因此他们消除了签署如果事先未进行断言可能会还原的交易的风险。从某种意义上说,这使得用户可以在交易上创建交易记录级别(而不是 EVM 级别)的条件,以便这些交易只能在其他交易存在的情况下包含在内。
示例演练
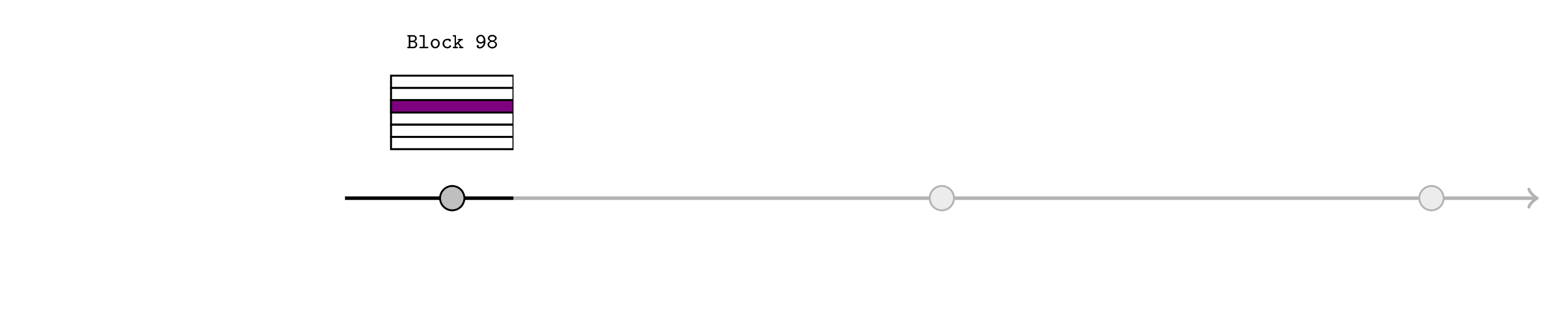
让我们使用部署在 L2 上的示例 PreemptiveAssertions 和 RealtimeL1State 合约详细演练一个可能的 price-feed 示例。如果发布只有几个 L1 区块长,这可能有点过头(因为我们只保存了几个 L1 blockhash 调用),但此示例足够详细,可以阐明该机制。
上下文
假设在 L1 区块 100 之前存在一个垄断排序器,并且 price-feed 刚刚在区块 98 中更新(紫色)。当然,可以自然地扩展此机制以覆盖几个 L1 区块。
 \
provable_assertion_images.123026×646 6.94 KB
\
provable_assertion_images.123026×646 6.94 KB
步骤 1
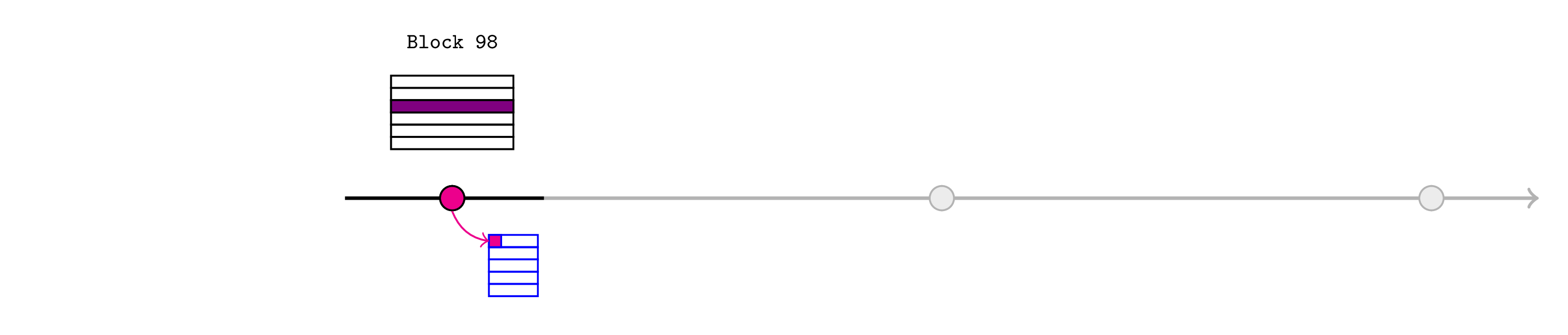
Alice 想要将该新价格通知 L2 预言机,因此她检索 L1 区块 98 的区块头并调用
realtimeL1State.assertL1Header(98, header);
排序器只有在它对应于真实头部时才应包含此交易。他们还可以确保 Alice 支付费用以支付 L1 上最终的 blockhash(99) 调用(可能使用 pauser 机制)。
这将创建三个断言:
- L1 区块 98 的区块哈希是提供的
header的哈希 - L1 区块 98 的父哈希是
header.parentHash字段(本例中未使用) - 区块 98 的状态根是
header.stateRoot(图中的粉色)
 \
provable_assertion_images.133026×646 8.16 KB
\
provable_assertion_images.133026×646 8.16 KB
步骤 2
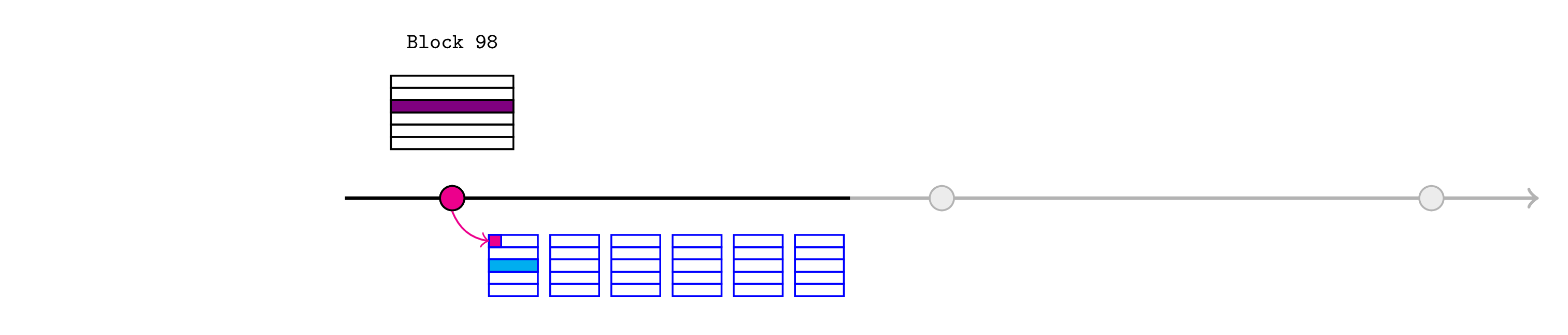
我们假设 L2 预言机信任 realtimeL1State 合约所做的断言(实际上,这意味着 L2 预言机的开发人员相信 RealtimeL1State 代码可以正确验证它所做的断言)。它应该被设计为在调用时检索最新的 L1 状态根断言。
Alice 可以针对断言状态根提供到相关存储位置的 Merkle 证明,以证明 L1 区块 98 末尾的最新价格(浅蓝色)。
L2 生态系统的其余部分可以使用此价格继续。
 \
provable_assertion_images.143026×646 8.71 KB
\
provable_assertion_images.143026×646 8.71 KB
步骤 3
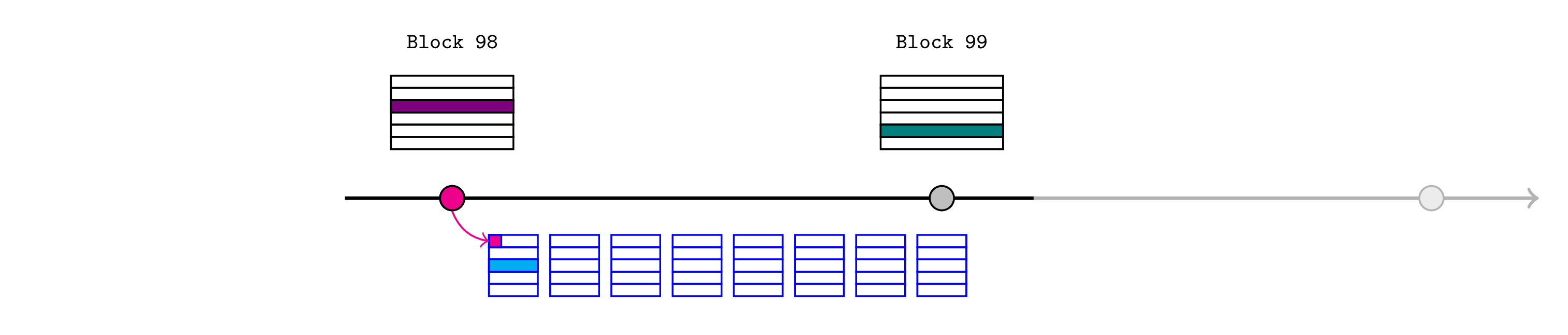
price-feed 在区块 99 中更新(深绿色)。
 \
provable_assertion_images.153026×646 9.39 KB
\
provable_assertion_images.153026×646 9.39 KB
步骤 4
Bob 想要将该新价格通知 L2 预言机,因此他检索 L1 区块 99 的区块头并调用
realtimeL1State.assertL1Header(99, header);
与之前一样,排序器只有在它对应于真实头部时才应包含此交易(并且 Bob 已支付所需的费用)。
这将创建另外三个断言:
- L1 区块 99 的区块哈希是提供的
header的哈希 - L1 区块 99 的父哈希是
header.parentHash字段 - 区块 99 的状态根是
header.stateRoot(图中的棕色)
 \
provable_assertion_images.163026×646 10.3 KB
\
provable_assertion_images.163026×646 10.3 KB
步骤 5
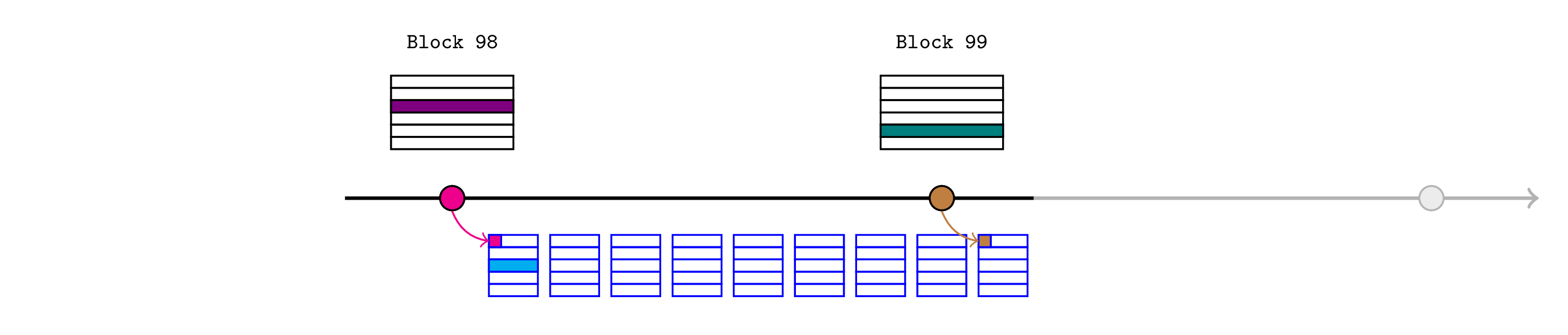
与之前一样,任何人都可以使用断言的状态根来证明 L1 区块 99 末尾的最新价格,并且 L2 生态系统的其余部分将使用此价格继续。
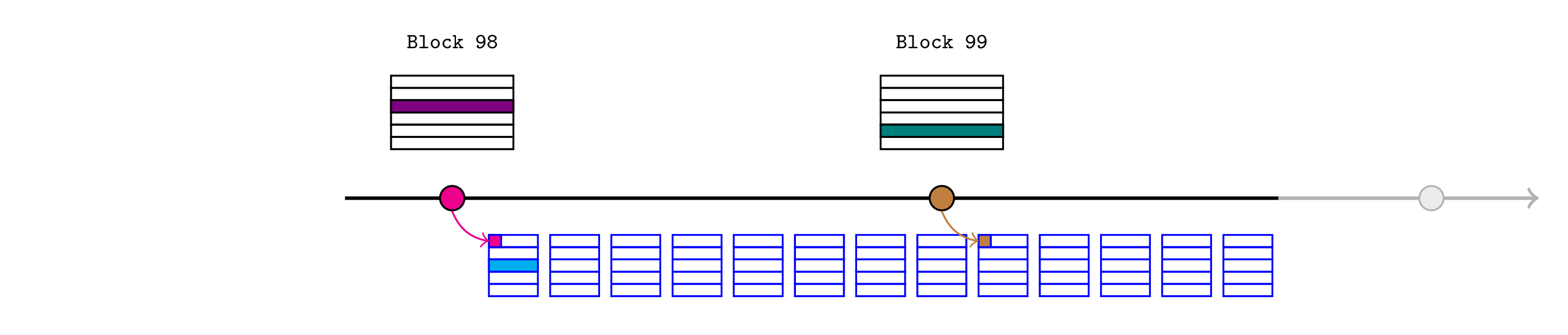 \
provable_assertion_images.173026×646 10.4 KB
\
provable_assertion_images.173026×646 10.4 KB
步骤 6
一旦断言了区块 99 头部,区块 98 断言就不再必要了。此时,任何人都可以使用以下调用删除它们
realtimeL1State.resolveUsingNextAssertion(98)
排序器可以设计他们的 pauser 合约在步骤 4 结束时调用此方法(因此由 Bob 支付)。或者,他们可以要求 Alice 在步骤 1 中签署此交易(但现在只对其进行排序),因此她支付添加和删除断言的费用。
在任何一种情况下,此调用都将
- 确认 L1 区块 98 的断言区块哈希与区块 99 的断言父哈希匹配(这保证了区块 98 断言由区块 99 断言隐含)
- 删除所有三个区块 98 断言。
步骤 7
发布结束交易接受一致性哈希(橙色),该哈希从(除其他事项外)在发布时(区块 100)在 Inbox 合约中执行的 blockhash(99) 的结果派生而来。排序器可以预测该值并将其传递给发布结束交易,同时最终确定发布。
排序器还将指定 realtimeL1State 合约具有未经验证的断言,因此发布结束交易将使用一致性哈希(以及排序器提供的 L1 区块 99 的区块哈希)在该合约上调用 resolve。此函数将:
- 确认传递的区块哈希对应于一致性哈希(因此它与将在 L1 上检索的值匹配)。
- 确认这与为区块 99 断言的区块哈希匹配(在步骤 4 中)。
- 删除所有三个区块 99 断言。
发布结束交易将确认没有剩余的未经验证的断言。
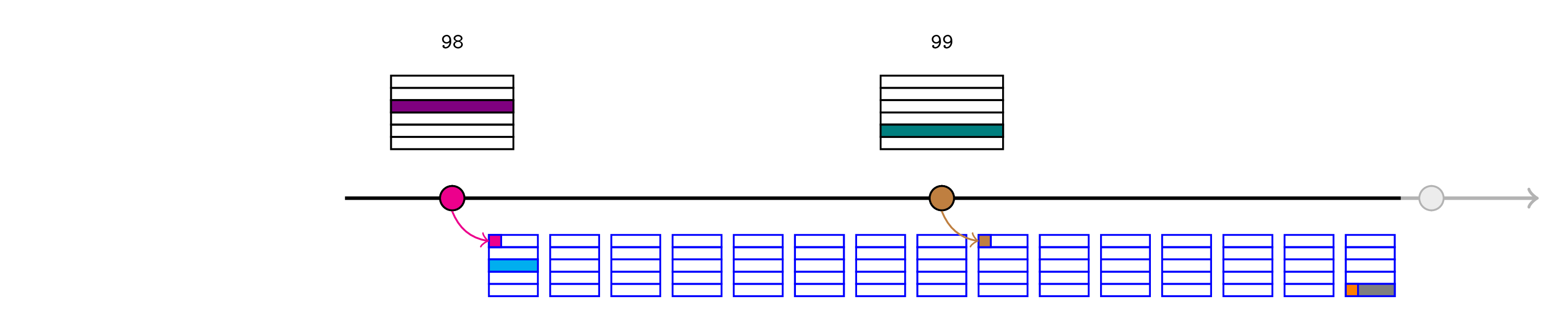 \
provable_assertion_images.183026×646 9.87 KB
\
provable_assertion_images.183026×646 9.87 KB
步骤 8
最后,排序器最终确定发布并将其发布到区块 100 中。该状态转换函数(由 rollup 节点强制执行)将保证 Inbox 中计算的一致性哈希与传递给发布结束交易的一致性哈希匹配,并且它没有恢复(以确保所有断言都已证明)。
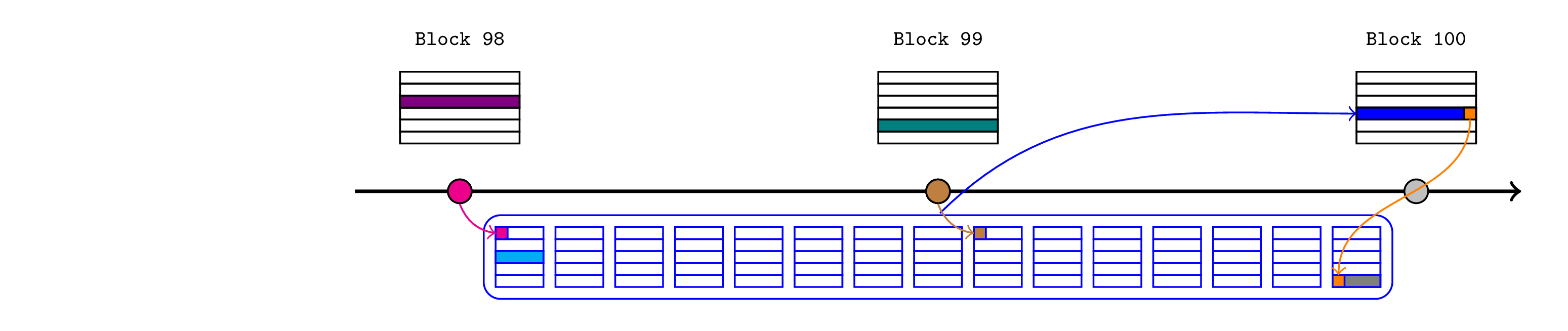 \
provable_assertion_images.193098×654 36.1 KB
\
provable_assertion_images.193098×654 36.1 KB
- 原文链接: ethresear.ch/t/preemptiv...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 20
- 分类: 以太坊
- 标签: Rollup L2 L1 Anchor blocks Same-slot message passing 跨链原子性





