规模不经济:反相关惩罚 (EIP-7716) - 权益证明
- 以太坊中文
- 发布于 2024-07-24 21:16
- 阅读 828
本文探讨了以太坊PoS机制中存在的中心化风险,指出大型验证者可以通过规模经济获得更多利益,从而威胁网络的去中心化。为了解决这个问题,文章提出了EIP-7716提案,旨在引入反相关惩罚机制,对同质化程度高的验证者进行惩罚,鼓励验证者多样化其设置,从而提高网络的鲁棒性和去中心化程度。
规模不经济:反相关惩罚 (EIP-7716)
特别感谢 DappLion 和 Vitalik 在整体概念上的合作,以及 Anders 和 Julian 对本文的宝贵反馈!
以太坊依赖于一组去中心化的验证者来确保可信中立和抗审查等特性。验证者质押一定数量的 ETH 参与以太坊的共识并保护网络。作为回报,验证者直接从协议中获得奖励(#issuance),以及在提议区块时获得的执行层奖励,其中包括交易费用和来自他们提议区块的 MEV(#mevboost)。时至今日,成千上万(如果不是数万)的小型实体都在自家运行验证器,尽管存在一些不利因素。这些不利因素包括运营和维护节点的风险和责任、与设置和维护相关的技术负担、潜在的停机时间,以及缺乏流动性质押代币(否则会提供灵活性和流动性)。
随着以太坊 PoS 的不断成熟,我们遇到了当前协议固有的各种 中心化力量:
- EL 奖励差异:虽然证明奖励的分配相当均匀,但提议区块的奖励可能会有很大差异。这种差异的出现是因为 MEV 非常不稳定,导致少数异常区块的提议者利润超过 10 ETH。运行大量验证器的大型运营商更有可能捕获这些“诱人”的区块。尽管多年来,单个验证器的收益应该平均化,但未来仍不确定。假设有 100 万个验证器和每年 2,628,000 个 slot,被选为提议者的概率约为 0.0001%。平均而言,一个验证器可以预期每年提议 \frac{1,000,000}{365.25 \times 7200} = 2.6281,000,000365.25×7200=2.628 个区块(每天有 7200 个 slot)。从 2023 年 4 月到 2024 年 4 月,超过 10 ETH 的区块百分比为 0.004041%。从统计上看,单个验证器最终会提议一个 MEV 超过 10 ETH 的区块,但不知道这会在今年还是十年后发生,到那时,MEV 问题可能会得到解决。当 solo staker 实际上是在参与抽奖时,大型运营商可以平均他们的利润,并以更大的确定性规划未来。
在 1 年的时间里,一个随机验证器获得至少一个利润 >10 ETH 的区块的概率是 0.1%:
P(\text{at least one 10} \, \text{ETH} \, \text{block}) = 1 - (1 - 0.0004041)^n = 1 - (1 - 0.0004041)^{2.628}
P(至少一个 10ETHblock)=1−(1−0.0004041)n=1−(1−0.0004041)2.628
如果你控制了所有验证器的 1%(约 1 万个验证器),那么在一年内获得至少一个 MEV 超过 10 ETH 的区块的概率会攀升到大约 99.99%。
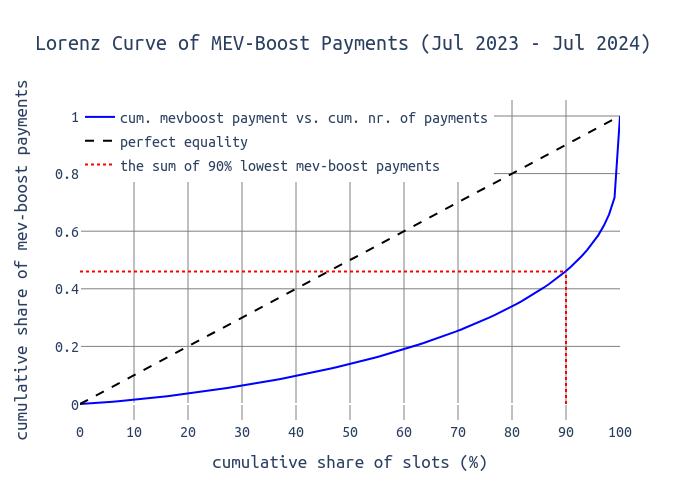
下图显示了 y 轴上的 MEV-Boost 付款的累计总和 和 x 轴上的 MEV-Boost 付款的累计数量。我们可以看到,90% 的区块分配了大约 44% 的总价值,剩下 56% 分配给幸运的 10% 的提议者。
 \
Bk31ssG_R.png700×500 33.6 KB
\
Bk31ssG_R.png700×500 33.6 KB
-
Reorgs:“诚实 reorgs”Honest reorgs”发生在 slot n_{1}n1 的提议者孤立了 slot n\{0}n0 的提议者的区块时,因为该区块没有收到至少 40% 的 slot 委员会成员的投票。通过使用 提议者加速 ,下一个提议者可以 reorg 这些“弱”区块(那些少于 40% 证明的区块),以惩罚前一个提议者的不良表现,例如迟到,从而导致一些证明者因其正确的 head 投票而被 rug。Reorgs 可能会产生中心化力量,并且一个实体持有的 stake 越多,它就能越有策略地决定是否要 reorg 某个特定的区块。大型运营商更安全,因为他们可以确保自己的验证器永远不会投票 reorg 自己的区块。从本质上讲,一个实体的所有节点都可以协调一致,始终投票支持当前 slto 的区块,而不是其父区块(如果当前区块来自该实体)。这种协调可能会使大型实体冒险在 slot 中稍后广播其区块,同时仍然具有该区块成为规范链的高概率。分析表明 ,在 slot 的 第 4 秒 时,已经看到了 该 slot 40% 的所有证明 。一个控制着许多验证器并且知道这些验证器永远不会投票重组其区块的大型运营商,可以稍微延迟区块传播,而不会显着增加其风险。当单个实体拥有连续的 slot 时,相同的原理适用。理论上,该实体可以等到 slot 结束(甚至更长时间)后再发布其区块。然后,它可以利用下一个 slot ,通过利用提议者加速将该弱区块固化到链中。
-
提议者时序博弈:提议者时序博弈 (另请参见 [1], [2])是一个术语,它概括了某些区块提议者所采用的一种策略,他们延迟其提议,以便为构建者提供更多时间来提取 MEV。这会导致提议者的利润增加,但 显而易见地 对其他提议者,尤其是证明者,产生负面影响。提议者时序博弈是有风险的,因为延迟的区块被 reorg 的机会增加。一般来说,大型运营商在玩时序博弈时面临的风险低于小型实体。这源于大型运营商平均而言更复杂,并且在 P2P 网络中具有更好的连接性:对于澳大利亚验证器来说可能是延迟的区块(祝 sassal 好运!:crown:) 对于位于美国的 Coinbase 验证器来说可能恰到好处。因此,延迟越低,验证器可以冒险延迟的程度就越大。
\textbf{上述症状都因一件事而加剧,即...}
上述症状都因一件事而加剧,即...
\underline{\mathbf{规模\经济。}}
规模经济。––––––––––––––––––––––––
规模经济 并非新鲜事物,加密货币领域也并非免疫。看看维基百科,它被定义为“企业因其运营规模而获得的成本优势 […]”,这同样适用于以太坊质押:
 \
ryZMFz-_R.png635×570 11.3 KB
\
ryZMFz-_R.png635×570 11.3 KB
像 Coinbase、Kraken 或 Kiln 这样的大型运营商可以利用规模经济来使质押更有利可图。这使得他们即使在扣除费用后,也能提供与 solo staker 具有竞争力的奖励。为了说明这一点,请考虑一个简单的示例(这里的确切数字并不重要):
| 实体 | 一个节点上的验证器 | 硬件成本 | 其他成本 | 总成本 ($) |
|---|---|---|---|---|
| Solo Staker | 1 个验证器 | 1 Intel NUC ($ 1,200) | $ 5,000 | $ 6,200 |
| Coinbase | 1,000 个验证器 | 1 Intel NUC ($ 1,200) | $ 50,000 | $ 51,200 |
对于更真实的数字,请参考 此处 发布的最新 EthStaker 调查。通过为大型运营商分配 10 倍的其他成本,我们考虑了在一台机器上设置多个验证器的复杂性增加。这对于我们在这里提出的观点来说已经足够真实了。
我们可以看到规模经济的影响:Coinbase 使用的机器将产生 solo staker 1,000 倍的利润,而成本仅高出八倍。因此,大规模运营商的投资回报率明显更好。
使用一个硬件设备来运行多个验证器只是其中的一部分。其他包括:
- 云服务提供商
- ISPs
- 地理位置
- 维护责任
- 客户端软件
- 还有更多...
在所有这些类别中,目标是最大程度的多样性,以最大程度地减少外部因素降低或损害网络的风险。尽管有这个目标,但经济上理性的参与者可能更喜欢一站式解决方案,例如在位于中欧的 Google/AWS/Hetzner 实例上运行 Lighthouse + Geth 节点,并由专门的专家团队维护。虽然这种设置在效率方面可能表现良好,但以太坊不应创造进一步加剧中心化的激励措施。

但是谁是大型规模,谁不是?
协议本身并不知道哪个验证器由哪个实体运营。从协议的角度来看,Coinbase 验证器看起来与 solo staker 相同。因此,为了防止相关性出现,我们不能简单地根据验证器背后实体的市场份额来缩放奖励和惩罚。有关此主题的更多信息,我推荐 Barnabé 的文章 “像协议一样看待” 。
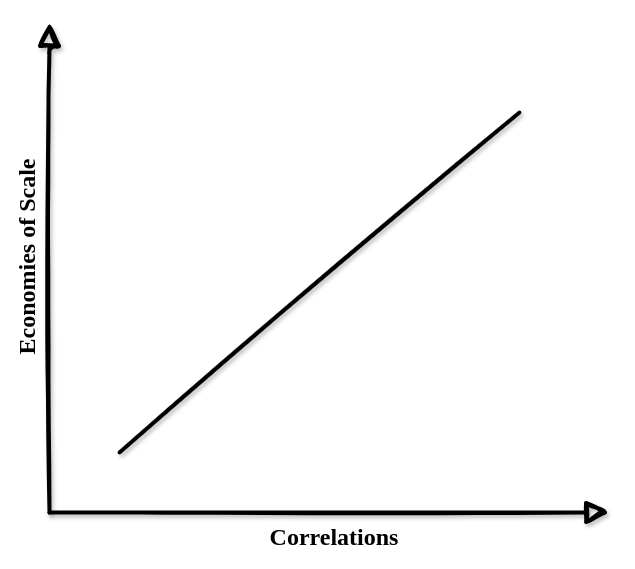
幸运的是,规模经济本质上伴随着相关性,协议可以意识到这一点。利用规模经济可以与相关性线性缩放,因此我们可以实施规则来动态缩放经济激励措施,并引导验证器集朝着多样化的方向发展。
 \
BJbZ1XWuR.png635×569 11.5 KB
\
BJbZ1XWuR.png635×569 11.5 KB
惩罚相关的错误对于以太坊来说并不是什么新鲜事。在当前的 slashing 机制中,“恶意”验证器在被 slashing 时最初会受到其有效余额 1/32 的减少的惩罚。在完成提款期一半后,他们将受到额外的惩罚(相关性惩罚 correlation penalty),该惩罚会随着大约在同一时间被 slashing 的验证器的数量(特别是他们的 stake)而增加(+/- 18 天)。因此,一个 solo staker 意外地投票支持两个不同的 head 区块(这是一种可被 slashing 的行为),其损失将远小于具有 20% 市场份额的一方(假设所有 20% 的人集体失败)。
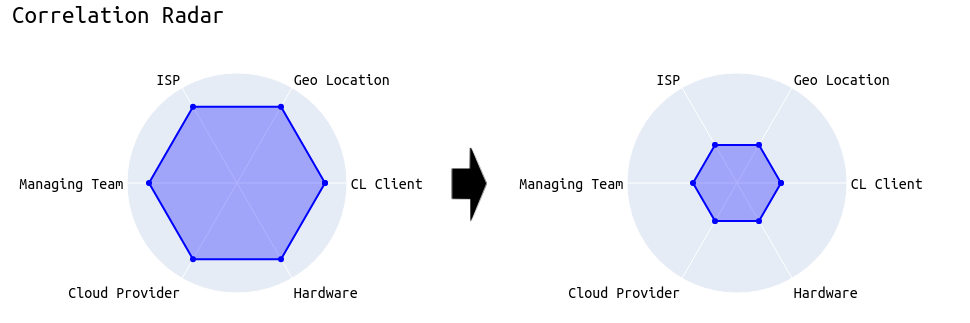
最后,目标必须是激励验证器使其设置多样化。如下例所示,我们希望验证器减少与其他验证器的相关性,从而使整个网络更能抵御外部影响。
 \
ry5bkuMO0.png970×323 21.7 KB
\
ry5bkuMO0.png970×323 21.7 KB
EIP-7716
“EIP-7716:反相关证明惩罚”的目标是让我们更接近规模不经济。一个实体的质押设置越同质化,它受到的惩罚就应该越多,而非相关的设置则会从提议的变更中获利。
通过反相关惩罚,之前的“规模经济与验证器数量”可能更像以下这样:
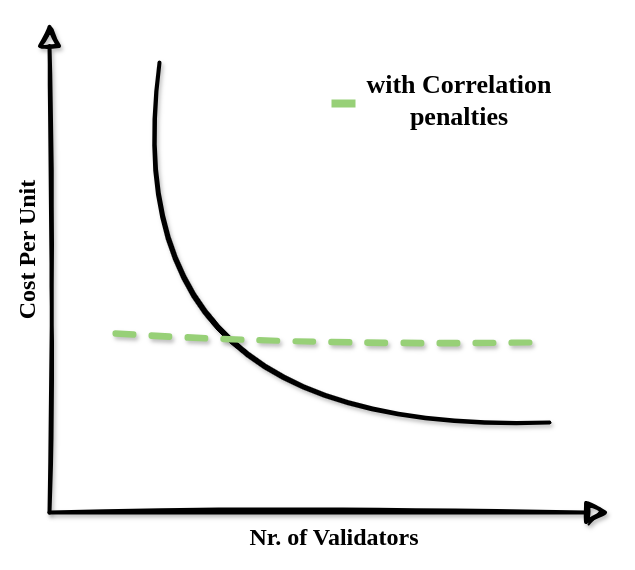 \
S179FsfOA.png635×570 27.3 KB
\
S179FsfOA.png635×570 27.3 KB
Vitalik 在一篇 ethresearch 文章 中首次描述了反相关惩罚。在进行了一些 初步分析 和一个更 具体的提案 之后,该 EIP 现在正处于每个人都被邀请深入了解相关惩罚的内部运作并留下反馈的阶段。
简而言之,EIP 建议将未参与(来源)投票的惩罚乘以一个惩罚因子,该因子范围从 0 到 4,但平均值为 1 (值得注意的是,这一点很重要,不要触及发行政策)。
7716 是如何工作的?
| 变量 | 符号 | 描述 | 值 |
|---|---|---|---|
penalty_factor |
pp | 惩罚缩放因子 | 动态 |
net_excess_penalties |
p_{exc}pexc | 净超额惩罚 | 动态 |
non_participating_balance |
balance_{non\_attesting}balancenon_attesting | 未/错误证明的验证器的总余额 | 动态 |
PENALTY_ADJUSTMENT_FACTOR |
p_{adjustment}padjustment | 惩罚调整因子 | 2**12 |
MAX_PENALTY_FACTOR |
p_{max}pmax | 最大惩罚因子 | 4 |
EXCESS_PENALTY_RECOVERY_RATE |
p_{recovery}precovery | 超额惩罚降低的速率 | 1 |
常量的最终值仍有待确定。
惩罚因子 pp 将 slot 惩罚缩放到最大 MAX_PENALTY_FACTOR 或向下缩放。它的确定方式如下:
p = \min\left(\frac{balance_{non\_attesting}\ \times\ p_{adjustment}}{\max(p_{excess},\ 0.5)\times\ balance_{total}\ +\ 1},\ p_{max} \right)
p=min(balancenon_attesting×padjustmentmax(pexcess,0.5)×balancetotal+1,pmax)
penalty_factor = min(
((total_balance - participating_balance) * PENALTY_ADJUSTMENT_FACTOR) //
(max(self.net_excess_penalties, 0.5) * total_balance + 1),
MAX_PENALTY_FACTOR
)
该公式计算惩罚因子,作为未证明验证器的“惩罚权重”与按所有验证器的余额缩放的净超额惩罚的比率。更高的惩罚调整因子会增加惩罚因子的敏感性。相反,更高的净超额惩罚会导致更低的惩罚因子。
最后,penalty_factor 变量的使用方式如下:
def get_flag_index_deltas(state: BeaconState, flag_index: int) -> Tuple[Sequence[Gwei], Sequence[Gwei]]:
"""
Return the deltas for a given ``flag_index`` by scanning through the participation flags.
"""
...
for index in get_eligible_validator_indices(state):
base_reward = get_base_reward(state, index)
if index in unslashed_participating_indices:
if not is_in_inactivity_leak(state):
reward_numerator = base_reward * weight * unslashed_participating_increments
rewards[index] += Gwei(reward_numerator // (active_increments * WEIGHT_DENOMINATOR))
elif flag_index != TIMELY_SOURCE_FLAG_INDEX:
# [New in correlated_penalties]
slot = committee_slot_of_validator(state, index, previous_epoch)
penalty_factor = compute_penalty_factor(state, slot)
penalties[index] += Gwei(penalty_factor * base_reward * weight // WEIGHT_DENOMINATOR)
return rewards, penalties
我们检查是否正在处理 source 投票(第 12 行),推导出验证器应该投票的 slot (第 14 行),计算惩罚因子(第 15 行),并将其乘以基本奖励(第 16 行)。
尽管 source 投票可能是一个好的起点,但该概念同样适用于 head 和 target 投票。
p_{exc}pexc 在每个 slot 结束时使用以下公式更新:
p_{exc} = \max(p_{recovery},\ p_{exc} + p) - p_{recovery}
pexc=max(precovery,pexc+p)−precovery
等于:
net_excess_penalties = max(
EXCESS_PENALTY_RECOVERY_RATE,
net_excess_penalties + penalty_factor
) - EXCESS_PENALTY_RECOVERY_RATE
我们可以观察到以下动态:
- 如果未证明验证器的余额增加,则惩罚因子也会增加。
- 如果未证明验证器的余额保持不变,则惩罚因子接近 1。
- 如果未证明验证器的余额减少,则惩罚因子可以在一段时间内低于 1,然后在之后接近 1。
当 non_participating_balance 连续几个回合持续增加时,penalty_factor 和 net_excess_penalties 也会增加。这种情况一直持续到 non_participating_balance 停止增加。然后,net_excess_penalties 和 penalty_factor 开始一起减少。
通过 net_excess_penalties 跟踪过去 epoch 的超额惩罚,该公式可以自我调节什么是“大量”未参与,什么不是。
该机制确保此 EIP 不会改变惩罚的总和 - 只会改变分配方式。
一些常见问题解答
1. 这对 solo staker 来说不是更糟糕吗?
不是。通常被称为小型运营商或在家运行 1-10 个验证器的个人 solo staker,预计与大型运营商相比,行为方式非常不相关。尽管地理位置和客户端软件等因素会影响相关性,但 solo staker 可能在与 Coinbase 或 Kraken 等大型运营商不同的时间离线。因此,solo staker 收到的惩罚小于当前系统中的惩罚。相反,如果大型运营商的质押设置出现错误,导致其所有验证器都无法证明,则相关性很明显,并且惩罚更高。
这一预期首先在对反相关惩罚的 初步分析 中得到证实,该分析表明,solo staker 和 Rocketpool 运营商的情况会更好,而大型运营商平均会受到更高的惩罚。
2. 这不会阻止人们使用少数客户端吗?
不会。事实上,它鼓励使用少数客户端。使用多数客户端会导致更高的相关性。例如,如果 Lighthouse 客户端出现错误,导致证明者投票支持错误的 source,则相关性很高,并且惩罚会增加。相反,如果所有 Lodestar 证明者都失败了,则被认为是一个小得多的集体错误。相关性惩罚对小众群体的容忍度高于对多数客户端的容忍度。因此,即使预计少数客户端会有更多错误,相关性惩罚也可以引导验证器使用它们。
3. 为什么它有利于去中心化?
反相关惩罚有效地区分了小型和大型运营商,而无需依赖已巩固其 stake 的验证器或其他链下解决方案。通过引入鼓励多样化行为的经济激励措施,我们使已经“反相关”的小型参与者受益,同时鼓励大型参与者减少外部因素的影响,例如单节点设置或云提供商对其质押运营的影响。
4. 这不会导致大型参与者投资于提高容错能力,甚至增加相关性吗?
如果大型参与者投资于提高容错能力,这仍然是有益的。增强容错能力既困难又昂贵。在某些时候,投资于反相关比进一步改进容错能力更便宜。虽然大型运营商可能不得不将验证器从流行的云平台转移到不同的环境,但从家中运行节点的 solo staker 可以像以前一样继续运行。任何让大型运营商花钱但对 solo staker 免费的东西(=规模不经济)都有利于去中心化。
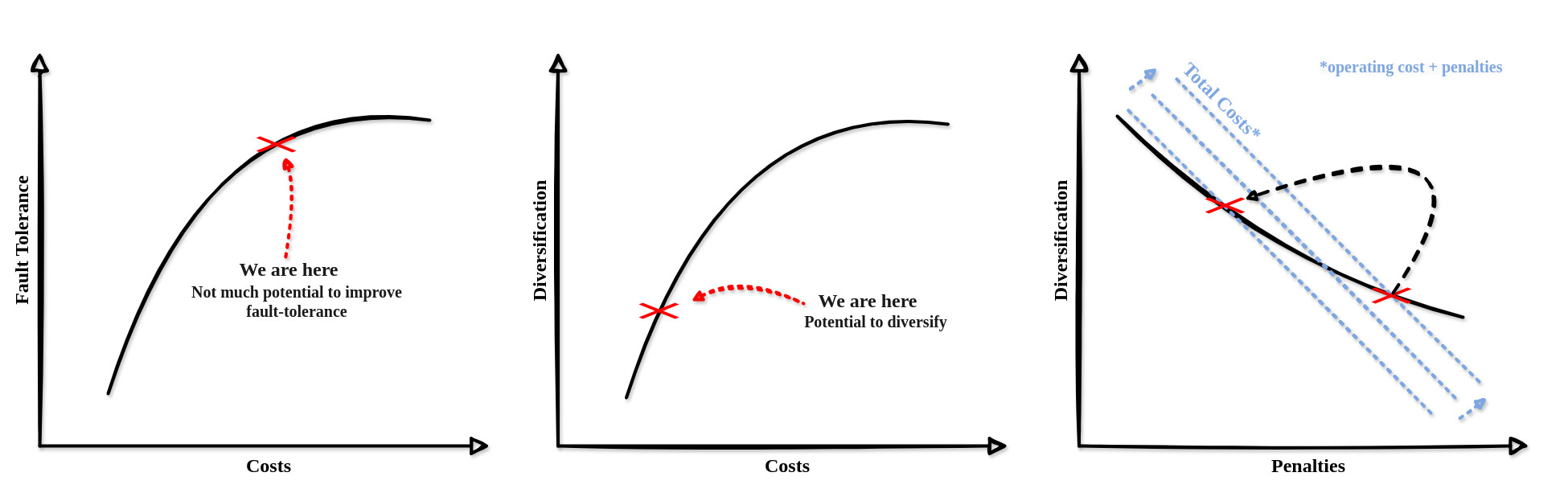 \
HyW84oMdA.jpg1950×613 98.4 KB
\
HyW84oMdA.jpg1950×613 98.4 KB
主要的论点是,无论大型运营商如何反应,无论是选择反相关,还是选择相反的方式,将所有验证器放在一个极其强大的节点上,两者都会花费金钱并降低其 APY。由于容错能力有限制,除了多样化之外,没有其他方法可以摆脱更严厉的惩罚。
 \
BJL374W_0.png429×654 291 KB
\
BJL374W_0.png429×654 291 KB5. 这听起来非常危险,因为仅仅因为错过一个 source 投票,我可能会被罚款 32 ETH。
这是不正确的,因为 penalty_factor 变量的上限为 4(有待分析)。设置上限可确保相关性惩罚永远不会失控。
6. 为什么只关注 source 投票,而不对 head 和 target 投票做同样的事情?
这是一个好问题,由于对该主题的研究仍处于起步阶段,因此尚未决定。反对 head 和 target 投票的一个论点是,它们取决于外部因素:如 之前的分析 所示,head 投票对提议者时序博弈很敏感。因此,如果这些时序博弈变得越来越普遍,那么连接不太好的验证器(通常是 solo staker)可能会变得更糟。但是,此 分析表明情况恰恰相反,从长远来看,小型 staker 将从反相关惩罚中获利。这同样适用于与每个其他 slot 相比,在一个 epoch 的第一个 slot 中更难获得正确的 target 投票。然而,从长远来看,这应该在验证器之间保持平稳,从而使我们能够对证明的所有部分(source 投票、target 投票和 head 投票)进行反相关惩罚。
实用链接:
| 网址 | 描述 |
|---|---|
| EIP-7716:反相关证明惩罚 | EIP-7716(草案) |
| 相关证明者惩罚的具体提案 | 原始提案 |
| EIP-7716:反相关证明惩罚 - EIP - 以太坊魔法师协会 | EthMagicians 文章 |
| GitHub - dapplion/anti-correlation-penalties-faq: 反相关惩罚常见问题解答 | EthBerlin 项目 |
| Impement anti-correlation attestation penalties eip by igorline · Pull Request #1 · igorline/lighthouse · GitHub | Lighthouse 实现 |
| 关于“相关证明惩罚”的分析 | 定量分析 |
- 原文链接: ethresear.ch/t/diseconom...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~






{kind=link}