Sig 工程 - 第 8 部分 - Sig 的 SVM 与运行时
- syndica
- 发布于 2025-12-03 07:46
- 阅读 983
本文介绍了Sig团队完成的Solana runtime的实现,包括runtime的重要性、Sig runtime的架构设计以及如何通过client diversity来提高Solana网络的健壮性。
我们很高兴地宣布,我们已经完成了 Sig 验证器的 SVM 和运行时的实现。这篇文章将解释什么是运行时,为什么它重要,以及我们的运行时是如何工作的。这篇文章是我们定期发布的博客系列的第 8 部分,旨在分享 Sig 的工程更新。你可以在(这里) 找到其他 Sig 工程文章。
每个 Solana 验证器都有一个听起来简单的任务:执行交易并更新账户。但实际上执行这项工作的软件——运行时——却绝非简单。每一次转账、投票、DeFi 交易和 NFT 铸造都由这个组件执行。它必须模拟一台图灵完备的计算机,并完美地重现 Agave 的输出。Solana 没有正式的规范。正确性的定义是“Agave 就是这样做的”。即使是微小的偏差也可能破坏共识。构建 Solana 运行时意味着逆向工程数千个实现细节,使用大量的模糊测试和一致性测试来验证它们,并仔细权衡设计清晰性和完美一致性之间的权衡。
如果它如此困难,为什么要构建另一个呢?因为 Solana 需要 客户端多样性 才能生存。只有两个运行时(Agave 和 Firedancer),其中任何一个中的错误都可能通过阻止超多数共识来使网络瘫痪。第三个实现确保了即使其中一个失败,也能保持活性。Sig 消除了这个单点故障,并增强了 Solana 的容错能力。
我们不仅仅用 Zig 重写了 Agave。我们构建了一个运行时,其结构更容易理解,每个组件之间都有简单且明确的边界。我们使并发变得显而易见,将状态与执行分离,并使账户访问变得明确,而不是临时出现。在此过程中,我们最终得到了一个更快的 sBPF 解释器。
这篇文章将从外到内地介绍运行时。我们将从 replay(重放) 开始,因为那是运行时的主要调用者——它将来自账本的区块提供给运行时。在运行时内部,我们将从 区块处理器 开始,并行化发生的地方,以及 交易处理器,在那里必须正确处理许多 Solana 特定的细节。最后,我们将描述 指令处理器 和 sBPF 虚拟机 的底层细节,Solana 程序在那里执行。
ℹ️
注意:术语 SVM 和 Solana Virtual Machine(Solana 虚拟机) 被不同的人用来指代运行时的不同方面(例如,sBPF VM、交易处理器或整个运行时)。在这篇文章中,我们将避免使用这个含糊不清的术语,而是选择使用这里定义的更精确的术语。
下图说明了 Solana 验证器的架构,分为三层:网络、存储和核心验证器。重放和区块生产是核心验证器逻辑的驱动因素,使用运行时来执行区块,并使用共识来对它们进行投票。
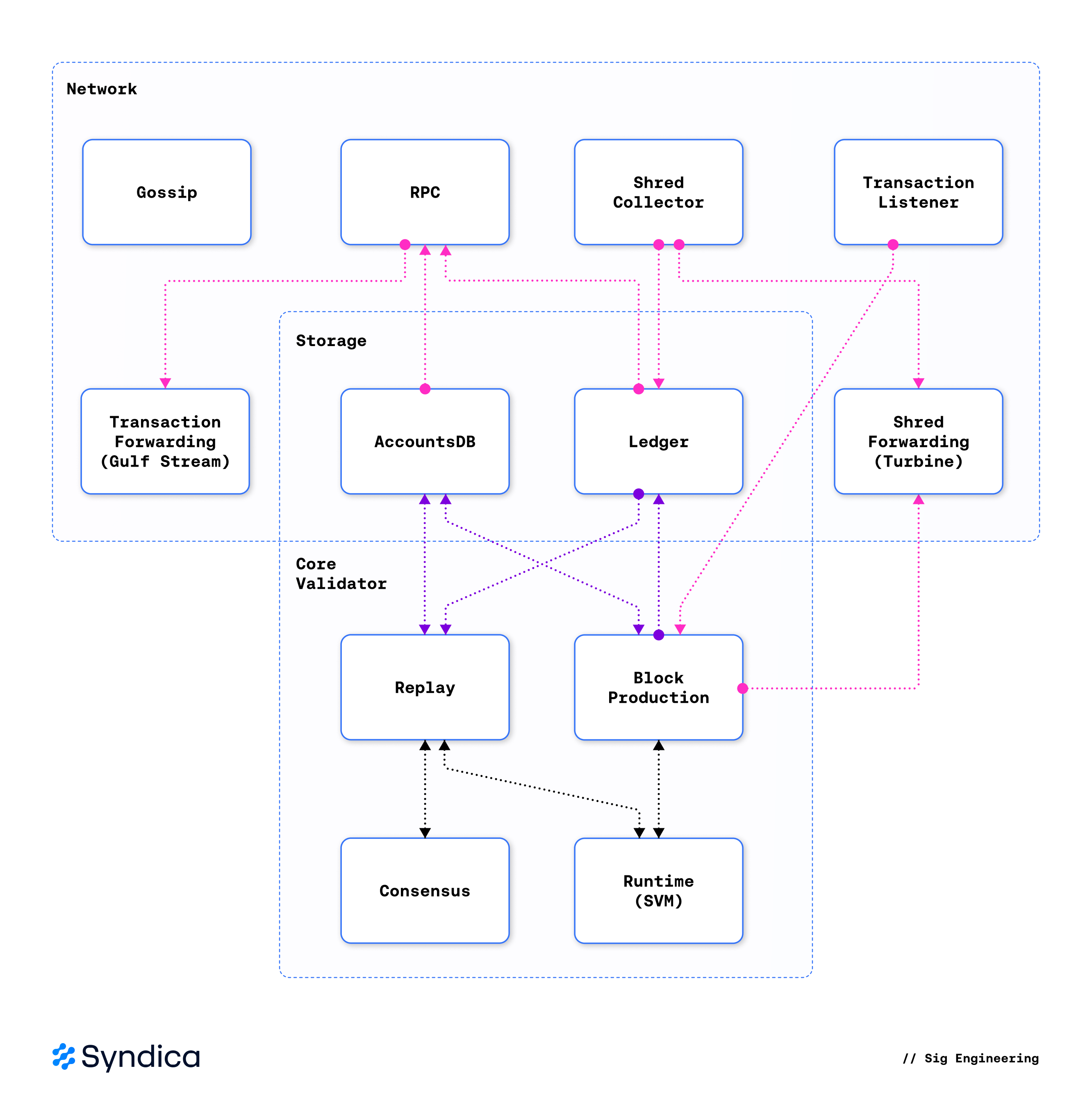 🔍 点击图片放大
🔍 点击图片放大
Replay(重放)
Replay(重放)是 Solana 验证器的主要循环,它驱动运行时来验证区块。它连接了 Solana 验证器的每个主要子系统:账本、运行时、AccountsDB 和共识。它的工作是不断地获取新的区块,执行它们,并报告结果。
重放不断地循环执行一系列步骤:
- 扫描账本,查找从领导者收到的交易。
- 从 AccountsDB 加载 这些交易所需要的账户。
- 使用 运行时的区块处理器 执行 交易。
- 将更新后的账户提交 回 AccountsDB。
- 向共识报告 区块结果,共识决定是否对区块进行投票。
因为 Solana 领导者在仍在生成区块时实时地流式传输交易,所以验证器不需要在开始执行交易之前接收整个区块。重放通过对交易而不是区块进行操作来利用这一点:一旦它检测到新的交易,就立即开始执行。这最大限度地减少了延迟,缩短了区块时间,并使验证器彼此紧密同步。
Sig 还支持并发插槽执行。多个分支可以同时前进,每个重放任务都维护自己的执行上下文。这种并行性允许 Sig 最大限度地利用硬件,而不会影响执行顺序的正确性。
Runtime(运行时)
运行时是负责执行区块的引擎。它以交易和账户作为输入,并生成新更新的账户作为输出。
运行时的结构反映了 Solana 账本的结构:区块包含交易,交易包含指令。它可以根据它们操作的范围大致分为三层:
- 区块处理器: 协调区块执行,通过将交易调度到单独的线程上来管理并行化,强制执行账户锁,调用交易处理器,提交结果,并冻结插槽。
- 交易处理器: 验证交易,加载其账户,在指令处理器中运行每个指令,并输出交易的影响。
- 指令处理器: 调用原生程序或解释 sBPF 字节码以执行链上程序。
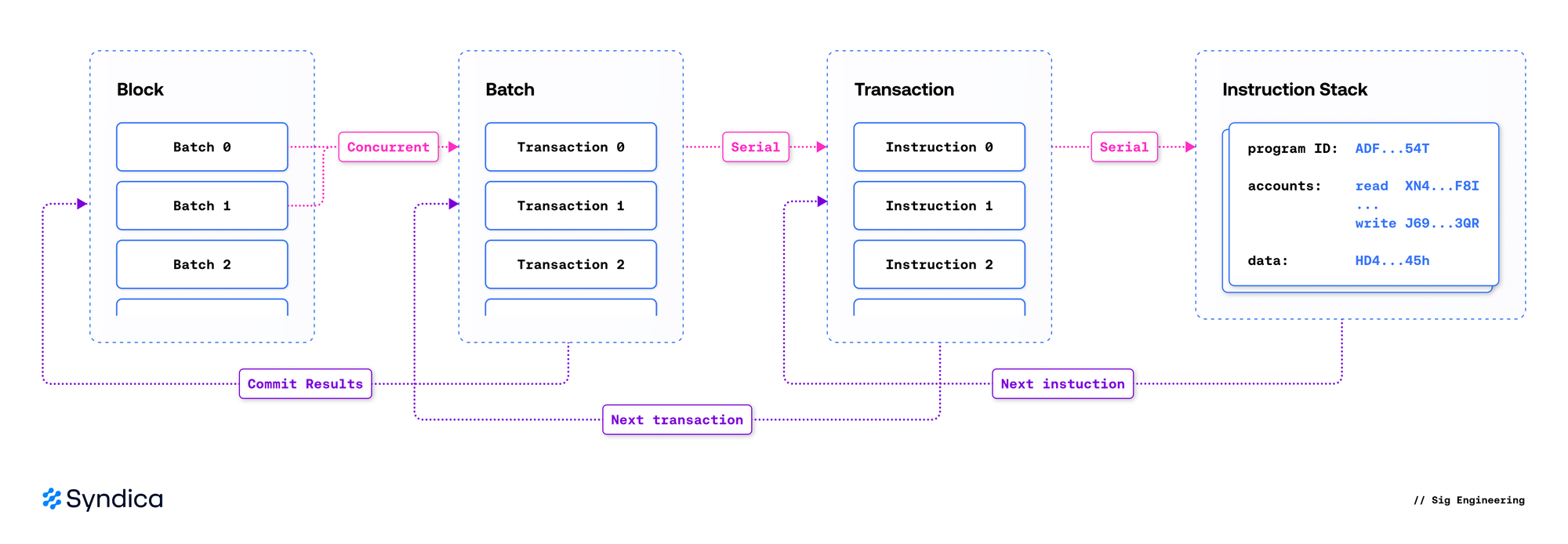 🔍 点击图片放大
🔍 点击图片放大
Block Processor(区块处理器)
区块处理器是运行时的入口点。重放从区块中读取一系列交易,区块处理器输出执行这些交易的结果。通过函数 replaySlotAsync 调用区块处理器,该函数启动以下事件序列:
- 验证 历史证明哈希对区块是否有效。
- 规划
- 解析 交易所需的账户。
- 调度 交易以进行安全高效的并行执行。
- 执行
- 在线程池中并发地执行 交易。
- 提交 由这些交易生成的状态更改。
- 区块完成后 冻结 插槽,并生成其状态的哈希。
Planning(规划)
在规划阶段,区块处理器检查区块中的交易,并根据它们将使用的账户来确定何时以及如何执行它们。
Theory: Account Locks(理论:账户锁)
Solana 的运行时与以太坊等传统区块链的不同之处在于,它从一开始就被设计为使用并行执行来最大化性能。大多数区块链一次只执行一个交易,因为它们的交易被授予对整个状态空间的访问权。如果两个交易试图同时使用同一个账户,它们可能会相互干扰并损坏该账户中的数据。
Solana 采取了一种更谨慎的方法,每个交易都会提前指定它需要什么数据。这允许运行时同时执行任意数量的交易,从而使 Solana 具有极高的可扩展性。
为此,每个交易都会列出它将读取哪些账户以及它将修改哪些账户。运行时采用了一种简单而有效的账户锁定规则:如果任何交易修改了一个账户,则不允许任何其他读取或修改该账户的交易同时执行。这是一个读写锁,它确保不会发生数据争用。
- 写是 排他的 ——不允许同时发生其他读取或写入。
- 读是 共享的 ——它们可以相互重叠,但不能与写操作重叠。
Implementation: Resolve Account Addresses(实现:解析账户地址)
为了规划区块执行,运行时首先需要确定哪些账户将被交易使用。许多账户直接在交易本身中列出,这使得这个过程很容易。但是,在某些情况下,交易指定了地址查找表,这些是链上账户,其中包含交易将使用的其他账户的列表。这需要一个多步骤的过程来识别交易将使用的账户。
交易 Message 的结构包含六个字段:
pub const Message = struct {
signature_count: u8,
readonly_unsigned_count: u8,
account_keys: []const Pubkey,
recent_blockhash: Hash,
instructions: []const Instruction,
address_lookups: []const AddressLookup = &.{},
};account_keys 字段是立即知道交易所需的账户列表。address_lookups 字段指定了交易所需的其他账户,但必须查找才能识别。
pub const AddressLookup = struct {
/// Address of the lookup table
table_address: Pubkey,
/// List of indexes used to load writable account ids
writable_indexes: []const u8,
/// List of indexes used to load readonly account ids
readonly_indexes: []const u8,
};AddressLookup 数据类型(在 transaction 中找到)指示哪个地址对应于其他地址的列表。这些索引是整数,用于指定执行交易需要该列表中的哪些项。
为了获得交易所需账户的完整列表,运行时使用 resolveTransaction 函数来查找它们,步骤如下:
- 在 AccountsDB 中查找地址查找表的
table_address。
如果找不到有效的查找表,则交易无效。将此交易包含在区块中是非法的。这将停止区块的执行。具有此失败的提案区块必须被拒绝。
- 将账户解析为地址列表。
- 遍历列表,并提取由
AddressLookup结构中的writable_indexes和readonly_indexes指向的每个地址。 - 对消息中指定的每个地址查找重复此过程。
- 为交易所需的所有账户创建一个新的账户地址列表,包括来自交易消息的
account_keys和我们刚刚在 AccountsDB 中找到的所有其他地址。
Implementation: Schedule Transactions(实现:调度交易)
现在我们知道每个交易使用哪些账户,运行时有足够的信息来安全地调度它们以进行并发执行。
TransactionScheduler 将交易分配到工作线程上并行运行。它首先检查区块中的完整交易列表,以确定它们的依赖关系。如果一个交易必须在另一个交易完成后才能执行,则该交易依赖于另一个交易。这些关系形成一个有向无环图 (DAG)。
如果交易 T1 在区块中出现在交易 T2 之前,并且它们不共享任何账户,则账户锁定规则允许它们并行运行——没有依赖关系。但是,如果任一交易写入另一个交易使用的账户,则它们可能无法并发执行。由于 T1 出现在区块中更早,因此 T2 依赖于 T1。
if (writable) {
// if we write, we depend on last writer, or the readers who depend on it.
if (lock.readers.items.len > 0) {
for (lock.readers.items) |reader_id|
try txn_deps.put(allocator, reader_id, {});
lock.readers.clearRetainingCapacity();
} else if (lock.last_writer) |writer_id| {
try txn_deps.put(allocator, writer_id, {});
}
// We also become the writer for others later.
lock.last_writer = id;
} else {
// if we read, we depend on last writer & becomes readers for next writer
try lock.readers.append(allocator, id);
if (lock.last_writer) |writer_id| {
try txn_deps.put(allocator, writer_id, {});
}
}执行从立即将每个没有依赖项的交易(我们的示例中的 T1)排队开始。当 T1 完成时,调度程序沿着 DAG 中其传出的边移动到其依赖项 T2,并递减 T2 的依赖项计数。一旦交易的依赖项计数为零,调度程序就会将其排队以进行执行。这会一直持续到每个交易都已执行完毕。
// Try to schedule the other workers waiting for us
for (self.waiters.items) |id| {
const waiter = &self.scheduler.workers.items[id];
if (waiter.ref_count.fetchSub(1, .acq_rel) - 1 == 0) {
task_batch.push(.from(&waiter.task));
}
}这种方法是最佳的,因为它最大限度地提高了并行性:调度程序始终保持尽可能多的交易运行,如账户锁定规则允许的那样。
Execution(执行)
一旦交易被调度到一个线程,该线程就会运行 replayBatch 以处理其分配的交易。该函数通过将每个交易和账户传递到 executeTransaction 来委托给交易处理器,该函数输出执行交易的结果。
每个交易将具有三个结果之一:成功、失败或验证失败。如果它验证失败,则区块本身无效,因此必须停止区块的执行并报告为失败。否则,交易结果将使用 Committer 提交,该提交程序将结果保存到 SlotState 中。
在执行完区块中的所有交易后,使用 freezeSlot 冻结该插槽。这涉及执行一些区块结束状态更改,例如将交易费用分配给领导者。然后,我们计算 AccountsDB 中所有账户以及区块元数据的组合哈希。这是 插槽哈希(有时在 Agave 中称为 银行哈希)。预计每个验证器都会为该插槽计算相同的哈希;否则,他们必须执行不同的区块。共识将验证一致的插槽哈希,以确定是否对该区块进行投票。
Architecture(架构)
代码可读性是我们 Sig 的主要目标之一。为了实现这一点,我们的区块处理器的设计受到以下原则的指导:
- 使依赖项显式且清晰。
- 以清晰的步骤序列在高级别上呈现关键操作。
为了使依赖项显式且清晰,每段代码仅请求它实际需要的输入,而不是依赖于一揽子结构或全局状态。我们避免将重量级依赖项隐藏在抽象后面,而是直接将它们作为高级参数传递。这使读者清楚地了解是什么驱动了一个组件,甚至让他们无需阅读实现即可预测其行为。一个具体的例子是 ReplaySlotParams,它定义了区块处理器需要的确切的依赖项集合。我们没有在整个代码库中隐式地访问全局状态,而是定义了一个函数 prepareSlot,其唯一的工作是收集这些依赖项。
/// Inputs required to replay a single slot.
pub const ReplaySlotParams = struct {
entries: []const Entry,
batches: []const ResolvedBatch,
last_entry: Hash,
svm_gateway: SvmGateway,
committer: Committer,
verify_ticks_params: VerifyTicksParams,
account_store: AccountStore,
};为了在高级别上呈现关键操作,我们确定了执行区块所需的步骤,并将它们逐一列出:
- 验证区块中的 ticks 是否有效。
- 验证历史证明链。
- 重放批处理中的交易。
// 1. Verify the ticks within a block are valid.
if (verifyTicks(logger, params.entries, params.verify_ticks_params)) |block_error| {
return .{ .invalid_block = block_error };
}
// 2. Validate the PoH chain
if (!try verifyPoh(params.entries, allocator, params.last_entry, .{})) {
return .{ .invalid_block = .InvalidEntryHash };
}
// 3. Replay the transactions in a batch
var svm_gateway = params.svm_gateway;
for (params.batches) |batch| {
var exit = Atomic(bool).init(false);
switch (try replayBatch(
allocator,
&svm_gateway,
params.committer,
batch.transactions,
&exit,
)) {
.success => {},
.failure => |err| return .{ .invalid_transaction = err },
.exit => unreachable,
}
}同样,重放交易批处理也在 replayBatch 中使用清晰的步骤序列进行描述:
- 预处理每个交易以验证签名并计算预算。
- 使用交易处理器执行每个交易。
- 使用提交程序提交交易结果。
// 1. Pre-process each transaction to verify the signature and compute budget.
const hash, const compute_budget_details =
switch (preprocessTransaction(transaction.transaction, .run_sig_verify)) {
.ok => |res| res,
.err => |err| return .{ .failure = err },
};
const runtime_transaction = transaction.toRuntimeTransaction(hash, compute_budget_details);
// 2. Execute each transaction with the Transaction Processor.
switch (try executeTransaction(allocator, svm_gateway, &runtime_transaction)) {
.ok => |result| {
results[i] = .{ hash, result };
populated_count += 1;
},
.err => |err| return .{ .failure = err },
}
// 3. Commit the transaction results with the Committer.
try committer.commitTransactions(
allocator,
svm_gateway.params.slot,
transactions,
results,
);Architecture Case Study: Resolving Lookup Tables(架构案例研究:解析查找表)
由于 Solana 缺乏正式规范,我们通过跟踪 Agave 的实现来推导出 Sig 的需求。在 Agave 中,交易批处理从重放到签名验证再到调度,没有显式的查找表步骤。但是,我们注意到,在此过程中,交易批处理被转换为五种不同的数据结构五次。乍一看,这似乎是无害的,好像现有的数据只是被重新格式化为一种更容易被下一步消化的结构。只有在检查每次转换的每个细节后,我们才发现签名验证巧妙地将每个 Transaction 转换为 RuntimeTransaction。此转换访问全局状态以解析查找表。
Agave 的设计具有引人注目的优势——编写新代码非常容易,因为调用 RuntimeTransaction::try_from(transaction, bank) 隐式地从全局状态收集所需的所有数据。无需程序员甚至意识到有必要,即可自动解析查找表。
在设计 Sig 时,我们将 可读性 优先于 可写性。这涉及更高的前期成本,但从长远来看,它通过提高可维护性来获得回报。为了使代码尽可能可读,我们在顶级别上使用清晰的步骤序列呈现关键操作。replayActiveSlots 首先调用 prepareSlot,其唯一的工作是收集该插槽所需的所有数据。通过 resolveBlock,在 prepareSlot 中显式执行查找表解析。
Transaction Processor(交易处理器)
Solana 交易是经过授权的工作单元,它将一个或多个链上操作组合成一个单一的、全有或全无的动作。每个交易都包含要执行的指令列表、它们与之交互的账户,以及授权这些操作所需的签名。
交易处理器负责将交易转换为账户状态更改。虽然描述起来很简单,但实现一个符合 Solana 规范的处理器具有挑战性:必须以绝对的精度重现显式和隐式行为,因为效果上的任何偏差都会破坏共识。在较高级别上,每个交易都经历三个关键阶段:验证、程序和账户加载以及指令执行。
![]() 🔍 点击图片放大
🔍 点击图片放大
验证确保交易格式良好,签名正确,以前没有执行过,并且费用支付者有效且有足够的资金来支付交易成本。在重放期间,如果交易验证失败,则该区块将被标记为无效,因为领导者不应在区块中包含无法收取费用的交易。
程序和账户加载确保交易指令请求的所有程序和账户都可用,并且加载的账户总大小不超过计算预算指定的上限。程序会经过额外的检查,以确保其字节码有效且可以安全执行。由于这是一项计算成本很高的操作,因此已验证的程序存储在缓存中,以防止重复工作。
一旦交易经过验证,并且其程序和账户已成功加载,执行只需为每个指令调用指令处理器即可。如果所有指令都成功,则将提交所有 resulting 的账户状态更改。如果任何指令失败,则交易立即失败,并且唯一 resulting 的状态更改是对费用支付者的收费。
Sig 使用单一的数据类型 TransactionContext 来简化整个指令执行过程中的状态管理。它包含处理每个指令所需的信息,强制执行资源约束,跟踪中间状态,并记录最终结果和元数据。虽然这听起来很多,但它在不到 300 行 代码中指定,并为指令处理器提供了一个干净的 API 用于数据访问和修改。resulting 的指令执行可以在 这里 找到,并且与以下伪代码非常接近。
var transaction_context = TransactionContext.init(...);
var transaction_error = null;
for (transaction.instructions) |instruction| {
executeInstruction(transaction_context, instruction) catch |err| {
transaction_error = TransactionError{ .InstructionError = err };
break;
};
}虽然实现者在内部设计方面具有一定的灵活性,但一致性需要仔细关注错误排序。重新排序容易出错的操作可能会导致交易在不同的点失败并产生不同的错误。虽然这不一定会影响共识,因为账户状态通常保持不变,但它可能会导致 RPC 输出和账本元数据的差异。对于用户和开发人员而言,这意味着跨验证器实现的交易状态和错误报告中存在令人困惑的差异。匹配 Agave 的错误排序增强了对行为等效性的信心,并且与现有的一致性框架使用的方法一致。
Instruction Processor(指令处理器)
Solana 指令只是一个请求,用于调用具有一些输入数据和它可以与之交互的账户列表的程序。指令处理器负责执行此调用。
Solana 对程序的输入数据的形式不做任何假设,从而允许程序选择它代表什么。通常,输入数据指定要执行的目标程序的命令。例如,system program 期望可以反序列化为 system program instruction 的输入数据。
另一方面,指令的账户必须以标准格式指定,指示账户是否可写以及是否已签署交易。这是必要的,因为调用的程序需要知道哪些操作已授权给提供的账户。例如,在执行 transfer 时,系统程序要求发送者既是签名者又是可写的。
pub const Instruction = struct {
program: Pubkey, // Target program address
data: []const u8, // Arbitrary program input
accounts: []const struct { // Accounts with permission metadata
address: Pubkey,
is_signer: bool,
is_writable: bool
},
};广义上讲,有两种程序类型:原生程序和 sBPF 程序。原生程序 是在验证器中实现的特殊程序,由运行时直接调用,而 sBPF(链上)程序 是用户定义的,由在 sBPF 虚拟机内部运行的任意字节码组成。
重要的是,每个程序(无论是 sBPF 还是原生程序)都有一个关联的链上账户,该账户必须加载并提供给指令处理器。为了调用一个程序,指令处理器首先通过检查程序账户的所有者来确定其类型:原生程序账户由原生加载器拥有,而 sBPF 程序账户由 BPF Loader 程序之一拥有。
当目标是原生程序时,指令处理器直接调用程序的入口点。当目标是 sBPF 程序时,处理器会在 provisioned sBPF 虚拟机中加载并执行目标程序的字节码。
Sig 利用了 Native 程序是在验证器中定义的事实,通过 直接 调用它们,而不是像 Agave 中那样 通过 sBPF VM 调用它们。虽然 Agave 提供了一种统一的程序执行方法,但代价是为每次程序调用设置一个额外的 sBPF VM。根据我们的经验,以不同的方式处理 Native 和 sBPF 程序调用也使程序执行更容易理解。运行时直接执行 Native 程序,而 sBPF VM 仅执行 sBPF 程序。
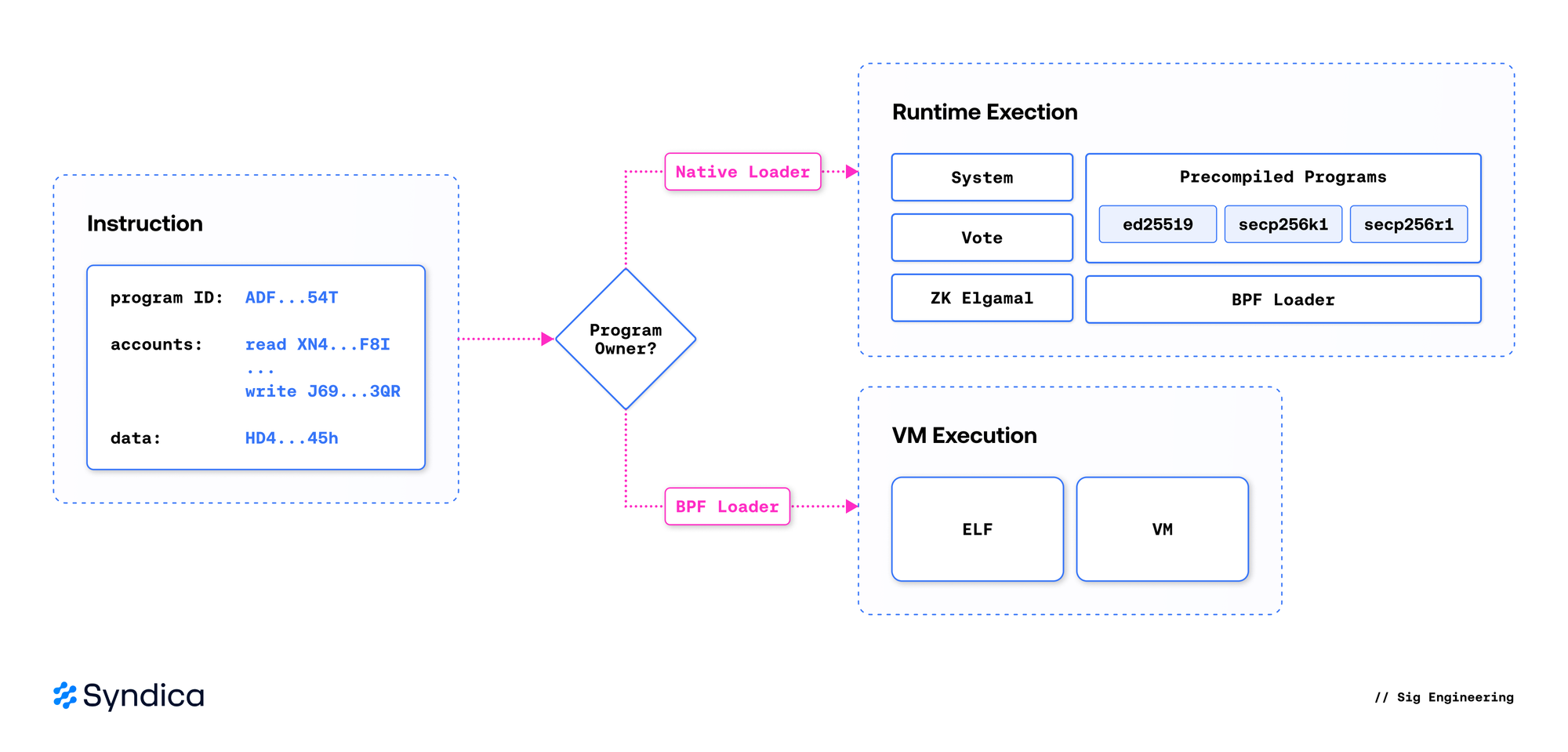 🔍 点击图片放大
🔍 点击图片放大
BPF Loaders
BPF Loaders 在 Solana 中发挥着关键作用,因为它们定义了用户与链上程序交互的机制。BPF Loader 是一种原生程序,负责管理 sBPF 程序。通过调用 BPF Loader,用户可以部署或升级 sBPF 程序。
BPF Loader Versions
随着网络的发展,Solana 引入了新的 BPF Loader 版本,这些版本实现了更新的部署规则。最终,较旧的 BPF Loader 将被弃用和禁用,但它们部署的程序仍然可以调用。
目前,有四个原生 BPF Loader 程序。版本一和版本二已被弃用,仅支持程序调用。版本三——通常称为 BPF 可升级 加载器——目前处于活动状态,而版本四已定义但尚未发布。
BPF Upgradeable Loader
顾名思义,引入 BPF Upgradeable Loader 是为了在链上程序初始部署后对其进行升级。这为开发人员提供了灵活性,可以修复错误或引入新功能,而无需部署单独的程序并将其用户迁移到新程序。由于它是当前活动的加载器,因此我们更仔细地研究其机制。
Upgradeable Loader 支持对链上程序进行许可的创建、部署、修改和关闭。这通过 10 个指令来实现,每个指令都由指定的程序授权方进行保护。
Program Authority
程序 权限 是每个程序元数据账户中指定的地址,用于标识程序的所有者。任何通过 Upgradeable Loader 修改程序的指令都必须包含权限地址及其签名。
权限可以在任何时候使用 Loader 的 set_authority 指令将其所有权转移到另一个地址。这包括分配一个空的权限地址。这种转移是程序最终的改变,因为在没有权限的情况下,没有人可以进行修改,从而有效地冻结程序并使其不可变。
不可变的程序账户仍然可以通过 Solana 指令调用。使权限无效的行为,能向程序的调用者保证,程序在被调用之前不会发生意外更改,这是一个有用的属性,尤其是对于处理余额转移的 SPL Token 而言。
部署
sBPF 程序必须以与任何数据上链相同的方式部署,即将其打包到交易中。Solana 交易限制为 1232 字节,这可能太小,无法包含整个 sBPF 程序。为了解决这个问题,程序的字节码通过可能多次交易写入到链上的 缓冲区账户 中,然后再进行部署。
在通过 initialize_buffer 指令初始化 缓冲区账户 到可升级 Loader。该指令指定了程序权限,限制了谁可以在将来修改 缓冲区账户。然后,使用 write (以及可选的 extend_program)指令填充 缓冲区账户,直到完整的 sBPF 程序被加载到链上。
一旦所有代码都被写入,调用 Loader 的 deploy_with_max_data_len 指令就能使程序可供执行。它获取 缓冲区账户 的数据(现在包含权限和字节码),验证它,并将其复制到所需的程序账户。在下一个插槽,可以通过向程序账户发出指令来执行已部署的程序。
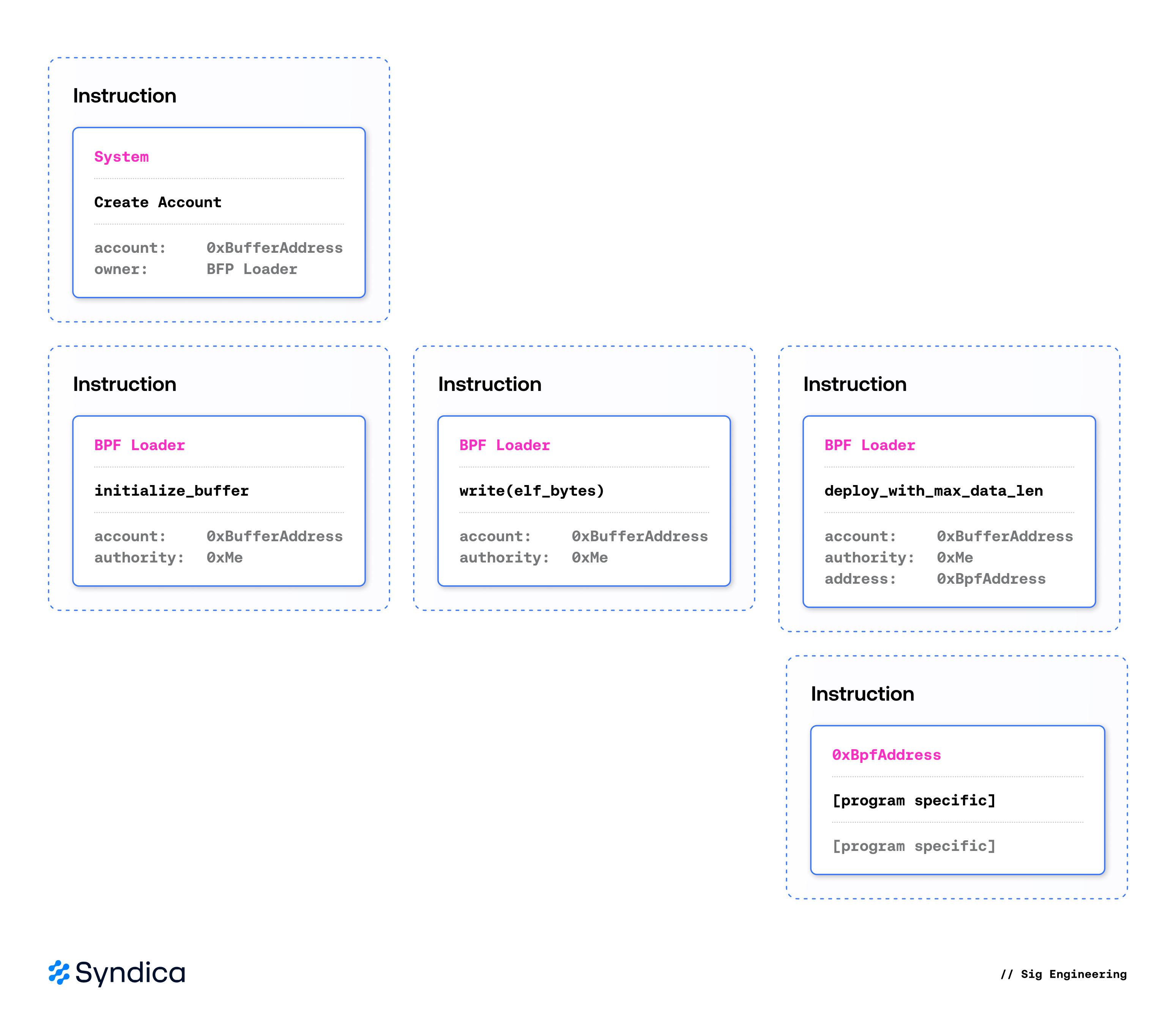 🔍 点击图片可放大
🔍 点击图片可放大
升级
部署后,可以使用 Loader 的 upgrade 指令升级和重新部署程序。此功能使可升级 Loader 得以命名——能够在不以不同地址进行新部署的情况下更改 BPF 程序。升级指令的行为类似于部署指令,接收已加载的 缓冲区账户,然后更新程序的账户以保存新的 sBPF 字节码。
管理
如前所述,如果用户希望阻止将来对已部署程序的升级,则可以将其权限设置为 null。或者,可以使用 close Loader 指令停用该程序,从而阻止从下一个插槽开始执行该程序。将来,某些 BPF 程序可能希望从可升级 Loader 迁移到 V4 Loader。一旦 Loader V4 可用,就可以向可升级 Loader 发出 migrate 指令,以转移现有的程序账户,并在过程中使用新的 loader 重新部署它。
无论 sBPF 程序是通过哪个 Loader 部署的,它们都可以通过 Solana 指令执行。这种执行必须模拟运行 sBPF 字节码的真实机器,它具有自己的内存、I/O 和与运行时交互的能力。这是由 sBPF 虚拟机执行的。
sBPF 虚拟机
sBPF 虚拟机是运行时的一部分,它执行每个链上程序。虚拟机 是模拟整个计算机的软件:它读取程序,解释其指令,并产生结果——就像物理 CPU 一样。每台计算机都支持一个 指令集,这是它可以执行的操作的集合。在 Solana 上,指令集是 sBPF,它是专门为链创建的 eBPF 的变体。
我们从头开始实现了一个 sBPF 虚拟机。它由以下核心组件组成:
- 内存映射:将 sBPF 程序使用的 虚拟 地址转换为 本地 地址。当初始化 sBPF 环境时,它会为堆栈、堆、账户数据和程序内存分配区域。
- 解释器:执行 sBPF 指令的状态机。这些指令的范围从基本算术运算到系统调用和内存访问。
- 系统调用:一组预定义的、可从 sBPF 程序调用的本地函数。诸如哈希、加密原语和批量内存操作之类的昂贵操作被委托给系统调用,以提高性能和正确性。跨程序调用 (CPI) 也是一种系统调用,将在下一章中介绍。
内存映射
内存映射将 sBPF 程序使用的地址转换为主机上分配的内存的真实硬件地址。你可以在 这里 找到实现。在内部,内存映射是一个标记联合,因为内存映射可以是对齐的,也可以是不对齐的:
pub const MemoryMap = union(enum) {
aligned: AlignedMemoryMap,
unaligned: UnalignedMemoryMap,
};在 sBPF 中,某些虚拟地址具有独特的含义。例如,0x200000000 是用于表示堆栈内存的地址,而 0x300000000 表示堆内存的起始地址。这两个地址相隔 4 GiB,并且由于我们不想分配千兆字节的内存来表示相对较小的堆栈和堆部分,因此我们需要将映射拆分为多个块。
内存映射被抽象为 Region,它是主机上映射到虚拟地址空间的内存范围。
pub const Region = struct {
host_memory: HostMemory,
vm_addr_start: u64,
vm_gap_shift: std.math.Log2Int(u64),
vm_addr_end: u64,
};host_memory 表示支持 VM 区域的主机上的内存区域。vm_addr_start 和 vm_addr_end 表示该区域表示的虚拟地址空间的边界。例如,堆栈表示为一个区域,其中 vm_addr_start 为 0x200000000,vm_addr_end 为起始地址加上堆栈的长度。
通常,sBPF 程序的输入数据会被复制到为 VM 创建的内存区域中。但是,sBPF 虚拟机具有一项称为 数据直接映射 的功能,这是一种性能优化,允许 VM 执行的程序直接访问已存在于主机上的账户数据,而无需复制它。这需要为每个账户创建一个单独的区域,以将其数据映射到虚拟地址空间中。这是 aligned 内存映射的一个根本限制成为问题的地方,需要使用非对齐映射。
aligned 内存映射查看地址的最高 32 位,以确定虚拟内存位于哪个内存映射区域中。假设我们有一个虚拟地址 0x2000001234,我们需要确定它属于哪个区域。通过将地址向右移动 32 位 (0x2000001234 >> 32),我们得到 2,它是表示 堆栈 的区域编号。我们可以使用此数字直接索引到我们的区域列表中并获得结果。
对于上下文,第一个区域是数据区域,它存储程序要使用的数据。这种设计的一个固有局限性是,每个 Region 表示的虚拟地址必须相隔 4 GiB。否则,移位后它们将产生相同的索引,我们将无法区分它们。
这就是 unaligned 内存映射发挥作用的地方。它不是仅查看地址的最高 32 位来确定索引,而是将区域存储在排序列表中,并按它们表示的虚拟地址进行排序。然后,当需要查找特定虚拟地址的区域时,内存映射会在此列表中执行二进制搜索。这消除了 aligned 映射施加的间距限制,但是缺点是,对于 n 个区域,查找区域的时间复杂度从 O(1) 增加到 O(log(n))。
内存映射的接口非常简单:
/// Retrieves a value of type `T` from a given virtual address
/// 从给定的虚拟地址检索类型为“T”的值
pub fn load(self: MemoryMap, comptime T: type, vm_addr: u64) !T
/// Writes a value of type `T` to a given virtual address
/// 将类型为“T”的值写入给定的虚拟地址
pub fn store(self: MemoryMap, comptime T: type, vm_addr: u64, value: T) !void这些函数处理转换地址、检查对齐方式和访问权限。
解释器
解释器是一个小型且确定性的状态机。每个步骤都涉及获取下一个指令、解码它并执行其对状态的影响。该实现的核心在于三个函数:
step执行单个指令。run在循环中调用step,直到程序停止或出错。dispatchSyscall处理对本地函数的调用。
step 获取并执行当前程序计数器 (pc) 处的指令。每个 sBPF 指令长 8 字节,并存储在 ELF 二进制文件中的特定偏移量处。程序计数器是一个寄存器,用于跟踪解释器的当前指令。通常,step 在每个指令之后将程序计数器递增 1,以继续执行下一个指令。某些指令(如跳转和分支)会将程序计数器更新为任意值。
指令
sBPF 指令长 8 字节,包含五个字段,Sig 使用 packed struct 表示:
pub const Instruction = packed struct(u64) {
opcode: OpCode,
dst: Register,
src: Register,
off: i16,
imm: u32,
};opcode 确定要执行的操作,dst 和 src 指定要从中获取数据的寄存器,imm 是立即数(硬编码到程序和指令编码中的值,允许直接使用它而不是从寄存器中获取它),off 是跳转和分支指令使用的偏移量,以告诉解释器要跳转多远。
这是一个简化的示例,说明如何在解释器中实现算术指令:
// Retrieve the current program counter.
// 检索当前程序计数器。
const pc = registers.get(.pc);
// Fetch the instruction from memory.
// 从内存中获取指令。
const inst = instructions[pc];
// Fetch the data from the registers.
// 从寄存器中获取数据。
const lhs = registers.get(inst.dst);
const rhs = registers.get(inst.src);
// Perform the calculation.
// 执行计算。
const result = switch (inst.opcode) {
.add => lhs +% rhs,
.sub => lhs -% rhs,
.mul => lhs *% rhs,
.div => try divTrunc(lhs, rhs),
...
};
// Store the result back in the registers.
// 将结果存储回寄存器中。
registers.store(inst.dst, result);在实际实现中,该过程有很多怪癖,通常需要特殊处理,但归根结底就是这样。我们从状态的一部分(寄存器)中获取数据,执行计算,然后将数据存回到同一个寄存器中。
请注意,我们从同一个寄存器中检索左侧输入,稍后将在该寄存器中存储结果。这是因为 sBPF 是一种 双地址 指令集架构。这些指令没有空间包含第三个寄存器,因此大多数操作都是通过对已存储在目标寄存器中的值执行计算来完成的。这可以减少指令的大小,但缺点是某些模式需要更多指令来表示,这可能需要更长的时间才能执行。
调度系统调用
在 sBPF 中,系统调用 (syscall) 是实现敏感或计算密集型任务的函数。考虑 SHA-256 哈希或椭圆曲线密码学原语。通过系统调用调用它们可以极大地受益于经过优化以直接在验证器使用的本机硬件上运行,从而可以实现这些操作。
要指示解释器运行特定的系统调用,sBPF 程序使用 syscall 指令。这是一个 opcode 设置为 syscall 的指令。它通过将系统调用名称的 Murmur3 哈希值放置在 immediate 字段中来标识系统调用。然后,我们的解释器在注册表中查找它,该注册表存储这些哈希值与实现系统调用的函数指针之间的映射。
一旦我们找到系统调用的函数指针,我们只需要使用提供的上下文调用它即可。然后,系统调用实现从寄存器中获取数据,执行所需的计算,并通过使用新数据更新这些寄存器将结果返回给程序。
未来改进
我们实现 sBPF VM 时的关注点是正确性而不是性能。当前设计运行良好,因为它编译成一个小的跳转表,这归功于大量共享指令实现,如前面给出的算术示例。
将来,可以通过利用即时 (JIT) 编译来显着提高大型程序的性能。使用此方法,轻量级编译器会在执行之前扫描程序中的指令,并将它们转换为可以在验证器上以更高的速度本机执行的机器代码指令。这样做的折衷是预编译步骤也需要时间,这可能会使整个过程对于较小的程序而言变慢。JIT 编译是一个被广泛研究的领域,有许多有趣的方法和细微差别。将来,Sig 可能会使用复制和修补 JIT 方法。
跨程序调用
如前所述,交易包含描述指令处理器执行的程序调用的指令。Solana 通过允许程序通过称为跨程序调用 (CPI) 的过程来调用其他程序,从而扩展了此模型。这种机制使程序能够相互交互和组合,从而允许从较小的模块化组件中产生复杂的行为。
对于 CPI 至关重要的是指令堆栈——一种跟踪当前正在执行的程序的结构,允许 CPI 调用将结果返回到其调用上下文。在交易中指定的指令通过被推送到一个空堆栈上来开始其执行。之后,指令处理器从堆栈中读取它并调用其目标程序。发生 CPI 时,新指令会被推送到堆栈上;指令处理器识别到这一点并立即开始执行新指令。一旦程序运行完成,其结果将被记录,并且其关联的指令将从堆栈中弹出。
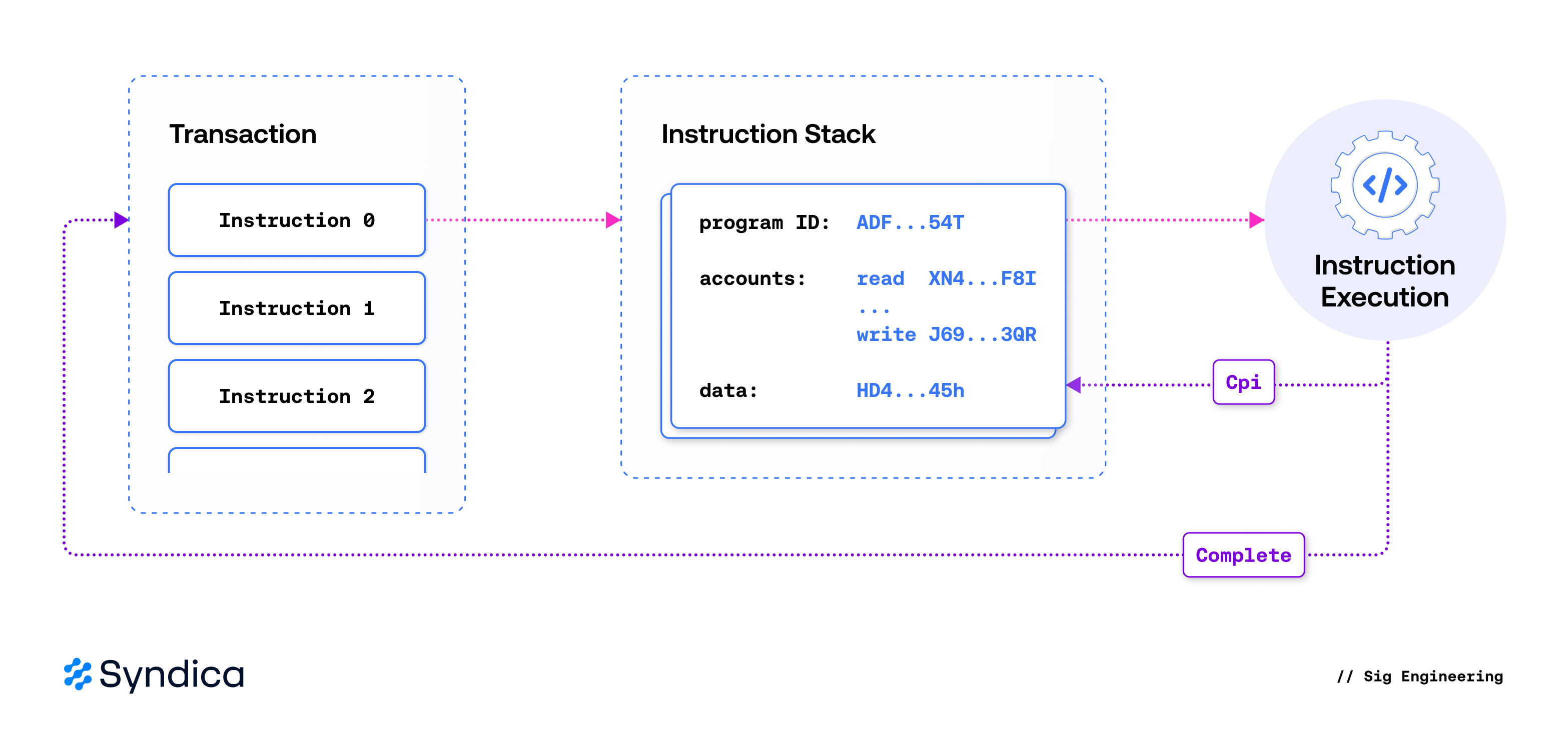 🔍 点击图片可放大
🔍 点击图片可放大
CPI 的一个关键组成部分是账户权限的管理——特别是,防止程序调用之间的权限升级。当新指令被推送到堆栈上时,运行时会验证其关联的账户权限是否与最顶层指令指定的权限兼容。这确保了通过 CPI 调用的程序永远不会执行超出其调用上下文授予的权限的操作。
对于本机程序,此过程很简单,因为它们是直接在验证器运行时中实现的。在 Sig 中,本机程序通过使用所需的指令调用 executeNativeCpiInstruction 来执行 CPI。但是,对于 sBPF 程序,事情变得更加复杂,因为必须在运行时和执行当前程序的虚拟机之间转换指令及其结果。sBPF 程序通过两个系统调用之一触发 CPI——sol_invoke_signed_rust 或 sol_invoke_signed_c——它们使用指令的 VM 表示,将其转换为运行时的内部格式,验证权限,并将其推送到指令堆栈上以供执行。
通常,sBPF 程序在编译为字节码之前用 Rust 编写。但是鉴于 sBPF 是一种标准化的字节码格式,因此任何以它为目标的源语言也适用于编写 BPF 程序。为了适应 Rust 编译程序之外的 ABI,建立了一个单独的系统调用以使用 C ABI,从而为 VM 数据类型提供了通用且稳定的内存布局。
在 Agave 中,有多个转换函数可以从每个 ABI 读取到标准类型;但是,Zig comptime 允许 Sig 编写一次并且 仅泛化数据类型,而不是所有的转换逻辑。这限制了实现不同步的可能性以及未经测试的错误在其中一个实现中显现的可能性。
ZK SDK
zksdk 模块实现了 zk-elgamal-proof 本机程序,该程序验证嵌入在账户数据中的零知识证明。这些是在链上执行的计算量最大的操作之一,某些操作的计算单位成本高达数十万,因此性能至关重要。
我们的实现比 Agave 的快数倍,并且与 Firedancer 的大致相当。性能差距来自三个核心设计差异:
- 大量 SIMD 优化的 Edwards25519 / Ristretto255
- 零堆分配
- 更优化的多标量乘法 (MSM) 排序
大量 SIMD 优化的 Edwards25519 / Ristretto255
我们对 Edwards25519 / Ristretto255 进行了大量优化,以利用任何架构上的 SIMD 操作。我们还手工制作了一个自定义实现,以进一步优化支持 x86-64 AVX512-IFMA 的架构。
可移植 SIMD 实现使用 Zig 的 @Vector 类型,该类型在 x86-64 上编译为最佳 AVX2 指令,在 ARM 上编译为接近最佳的 NEON 指令。此实现的优点在于它是跨平台的,从而使编译器可以发出目标上可用的任何 SIMD 指令。
x86-64 AVX512-IFMA 实现使用 vpmadd52l/vpmadd52h 融合乘加指令。这些指令在 52 位 limbs 上运行,与 Edwards25519 域中元素 (2^255 - 19) 的常用 5x52 位表示匹配。
结果是大大提高了证明验证的速度,特别是对于 RangeProof256 之类的较大批量操作,这需要数百个点乘法。
零堆分配
ZK SDK 中的所有证明在内存使用方面都有已知的、固定的上限。我们的实现仅使用堆栈内存,而没有在运行时进行动态分配。通过 Zig 缺乏隐式堆分配和强大的泛型,可以轻松实现这一点。例如,RangeProof 指令是一个由其编码的整数的位大小参数化的单一实现。
优化的多标量乘法 (MSM) 排序
对于 sigma 证明,我们重新排序了最终 MSM,以便最终输出乘以预期值,从而使我们能够简单地检查输出是否为恒等点。Ristretto 比较(需要一些乘法运算)与批量中的单个摊销乘法运算之间的差异不如其他改进那么有影响力,但可以节省几微秒的验证时间。
基准
以下是比较 Sig、Agave 和 Firedancer 性能的基准。这些测量是在 Zen 5、Ryzen 5 9600X 上进行的,这使其能够利用 IFMA 优化以及 Zen 5 附带的完整通道 AVX512。这些基准可以使用 此脚本 重现。
| Agave | Firedancer | Sig | |
|---|---|---|---|
pubkey_validation |
40 us | 21 us | 17 us |
zero_ciphertext |
70 us | 38 us | 32 us |
percentage_with_cap |
74 us | 48 us | 43 us |
range_proof_u64 |
1.45 ms | 529 us | 436 us |
range_proof_u256 |
4.92 ms | 1.8 ms | 802 us |
一致性
一致性测试在确保多验证器网络中的正确性方面起着至关重要的作用。如前所述,验证器实现之间的账户状态的任何差异都会导致共识的崩溃。随着替代实现获得权益,这种差异会导致网络速度下降——甚至是完全停止。
因此,至关重要的是,新的验证器实现在开始累积大量权益之前,要经过彻底的等效性测试。一种简单的方法是以少量权益运行新的验证器,并确认它们与集群保持一致。虽然这肯定是更广泛的权益采用过程中的一部分,但这是不够的。无法保证过去的交易已有效地探索了完整的状态空间——实际上,这极不可能。
一种更强大的方法是构建和维护一组以验证器的特定区域为目标的输入,并比较通过在不同实现中运行这些输入而产生的输出。通过这种方式分解问题可以更轻松地理解和改进覆盖范围,调试差异,并采取增量方法进行一致性测试——逐步扩展目标区域的范围,直到包含整个运行时。语料库输入可以手动制作,也可以通过旨在生成触发现有语料库尚未覆盖的执行路径的输入的模糊引擎以编程方式生成。
构建和维护这样的测试框架是一项重要的任务。Firedancer 团队在开发和开源 solfuzz-agave、protosol、test-vectors 和 solana-conformance 方面所做的努力为 Sig 的一致性优先开发方法奠定了基础。
solfuzz-agave 实现了 Agave 组件的 API bindings(称为测试工具),protosol 定义了这些工具的输入和输出模式,test-vectors 包含大量的测试用例,最后,solana-conformance 将所有内容整合到一个简单的工具中,用于比较不同验证器实现的行为。
| Harness | Detail | Public Corpus Size |
|---|---|---|
elf_loader |
ELF 解析 | 198 |
vm_interp |
sBPF 程序执行 | 108,811 |
vm_syscalls |
sBPF 系统调用执行 | 4,563 |
instr_execute |
指令执行 | 21,619 |
txn_execute |
交易执行 | 5,624 |
Sig 现在运行 solana-conformance,并将上述工具作为其持续集成 (CI) 管道的一部分,从而确保持续符合 Solana 的参考实现。通过与 Asymmetric Research 合作,我们还将测试范围扩展到 test-vectors 存储库之外。随着新问题的出现,我们会将相应的失败测试用例贡献给公共语料库,从而帮助提高整个生态系统的覆盖率。
结论
Sig 通过添加从头开始构建的第三个完全一致的运行时,使 Solana 变得更具弹性。这就是基线:首先确保正确性。我们感谢社区为一致性测试奠定了基础,我们将继续为公共语料库做出贡献。
既然基础已经到位,我们将把重点转移到性能上。有很多唾手可得的果实:零复制账户读取、无分配执行和 JIT 编译。请在 Twitter 上关注我们,以了解更多信息,因为我们将推出下一轮更新。
Sig 的存在是为了使 Solana 更加清晰、快速和更具弹性——而这仅仅是个开始。如果你对简洁的代码、底层优化或测试假设直到它们崩溃充满热情,请 加入我们。
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





