ethrex 如何在 Snap Sync 期间愈合状态
- lambdaclass
- 发布于 2026-03-14 08:09
- 阅读 338
文章详细介绍了以太坊节点同步的现代方法——Snap Sync。它通过先下载状态叶子节点并在本地重建Merkle Patricia Trie,然后引入“状态愈合”机制来纠正由不同时间点数据导致的偏差,从而显著提升了节点同步速度。文中还深入探讨了ethrex客户端中Snap Sync和状态愈合的具体实现细节,包括其并发模型和遇到的工程挑战。
以太坊节点是做什么的?
以太坊节点的核心功能是执行区块。一个区块是一批交易,每笔交易都是一个状态转换函数:它接收世界(账户余额、合约存储、字节码)的当前状态,并生成一个新状态。
EVM (Ethereum Virtual Machine) 是处理这些转换的状态机。给定状态 S 和一个交易块 [tx1, tx2, ..., txN],EVM 会生成状态 S':
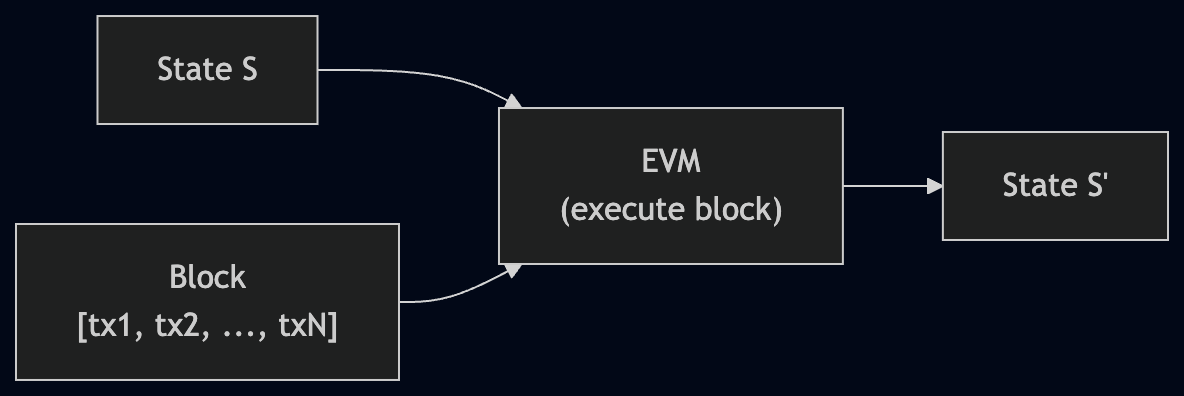
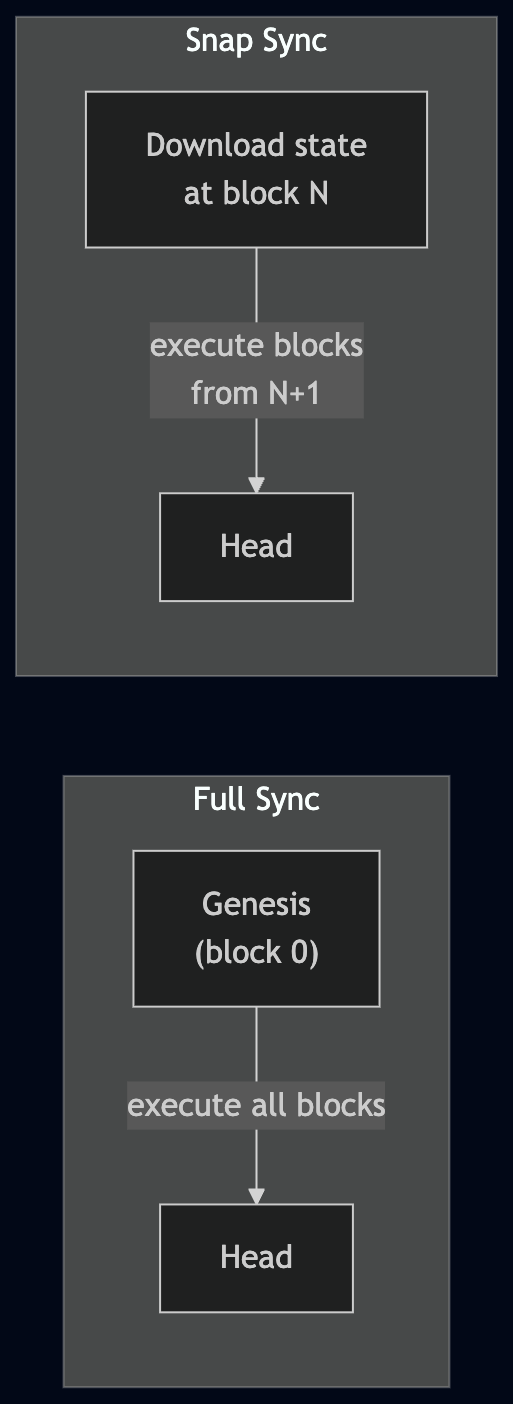
这意味着,要开始运行,一个节点需要一个初始状态。对于运行全同步的节点,该状态就是 genesis —— 区块 0 处的硬编码状态。然后,节点会重新执行所有已生成的区块以达到当前状态。
但还有另一种选择:从以太坊历史中的某个点下载一个状态快照,并从该点开始向前执行区块。这会大大加快速度——你跳过了多年的区块执行,只需要从快照赶上当前头部即可。
挑战在于:如何下载一个拥有数亿个账户的状态?
什么是 snap sync
Snap sync 是下载以太坊状态的现代方法。它从早期的方法 fast sync 演变而来,理解这种演变是理解愈合(healing)存在原因的关键。
初始方法:fast sync
以太坊将其状态存储在一个 Merkle Patricia Trie 中——这是一种树状结构,其中 leaves 存储账户数据,根是一个密码哈希,它对整个状态进行承诺。每个区块头都包含此状态根,因此任何人都可以验证状态是否正确。
Fast sync 自上而下地下载此 trie。你向对等节点请求根节点,然后是其子节点,再是子节点的子节点,直到你到达每个 leaf:
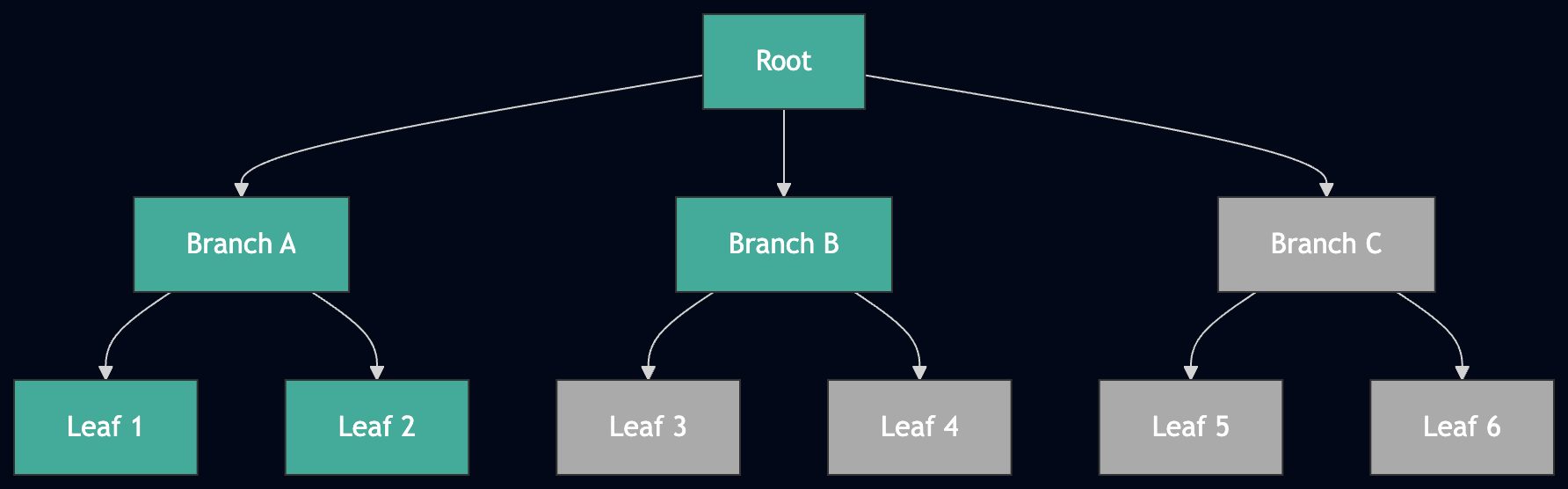
Fast sync 正在进行中:绿色节点已下载,灰色节点仍在待处理。Trie 自上而下遍历,逐层进行。
问题有两方面:
-
对等节点停止提供旧数据。 当你请求一个 trie 节点时,你会指定一个状态根。如果该根超过 128 个区块旧(约 25 分钟),对等节点就会拒绝响应。下载数亿个节点无法在 25 分钟内完成,因此你需要定期切换到更新的状态根(一个新的“pivot”)并从那里继续。
-
扫描缺失节点成本高昂。 切换 pivot 后,你需要遍历整个 trie 以找到你仍然缺失的节点。在已经下载了数百万个节点的情况下,这种扫描会占据大部分同步时间。
snap sync 背后的思想
Snap sync 颠覆了这种方法。它不是自上而下地下载 trie(根 -> 分支 -> leaves),而是只从对等节点下载 leaves —— 即账户状态和存储槽本身。然后它根据这些已排序的 leaves 在本地重建中间 trie 节点。计算 trie 节点比通过网络下载它们要快得多。
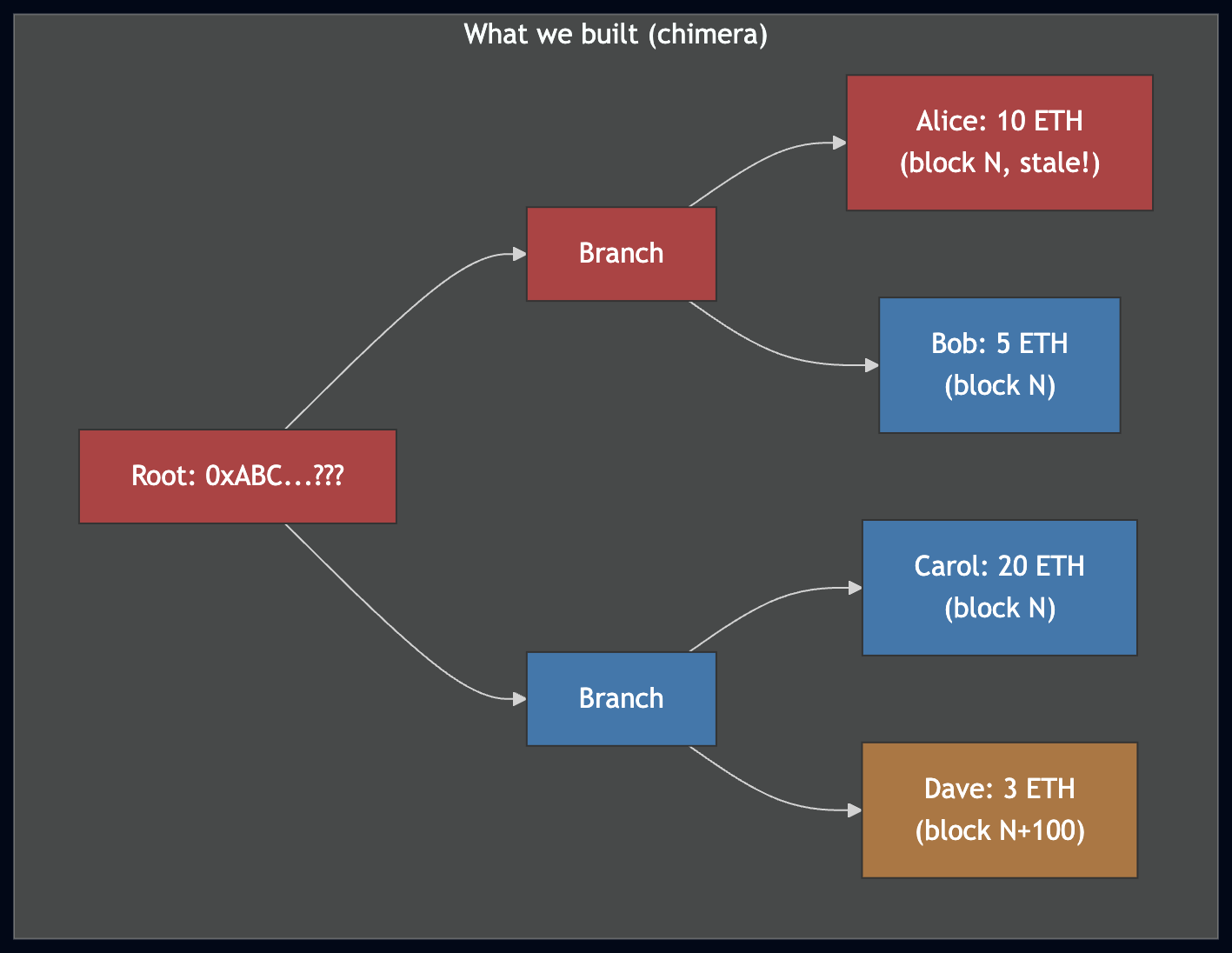
但有一个问题:下载所有 leaves 也需要超过 25 分钟。pivot 会过期,我们切换到一个新的 pivot,并继续下载。由此产生的 leaves 集合是由不同区块的碎片组合而成的——一个不匹配任何真实链上状态的嵌合体:

从两个不同的枢轴点下载的 Leaves。蓝色 leaves 来自区块 N,橙色来自区块 N+100。这些区块之间某些账户可能已发生变化,因此合并后的集合不代表任何真实状态。
这就是愈合(healing)发挥作用的地方。
snap sync 的阶段
Snap sync 按以下步骤进行:
-
下载区块头 — 从当前头部获取所有区块头到同步目标。范围被分割成块,从对等节点并行请求。
-
下载账户 leaves — 使用
GetAccountRange下载所有账户状态。键空间被分成块,在内存中缓冲(每次 64 MB),并作为 RocksDB SST 文件刷新到磁盘。 -
重建状态 trie — 将 SST 文件摄取到 RocksDB 中,迭代已排序的账户,并使用优化的排序插入算法构建 trie。这会生成一个状态根——几乎肯定与 pivot 的实际根不同,因为 leaves 来自不同的区块。
-
状态愈合 + 存储下载 — 愈合状态 trie,使其根与当前 pivot 匹配。同时,下载所有拥有存储的账户的存储槽 leaves。如果 pivot 过期,则更新并重新开始。
-
构建存储 tries — 将下载的存储槽插入到每个账户的存储 tries 中,同样使用排序插入。
-
存储愈合 — 愈合所有根不与当前状态匹配的存储 tries。
-
下载字节码 — 收集在下载和愈合期间看到的所有代码哈希,然后批量获取合约字节码。
-
切换到全同步 — 存储 pivot 块,运行
forkchoice_update,并切换到向前执行区块。
什么是状态愈合
从多个 pivot 下载 leaves 并在本地重建 trie 后,我们得到了一个其根与任何真实区块都不匹配的 trie。考虑一个简单的例子:
- 我们在区块 N 下载了 3 个账户:Alice (10 ETH),Bob (5 ETH),Carol (20 ETH)。
- pivot 过期;我们切换到区块 N+100。
- 我们在区块 N+100 下载了 1 个新账户:Dave (3 ETH)。
- 在区块 N 和 N+100 之间,Alice 的余额从 10 ETH 变为 7 ETH。
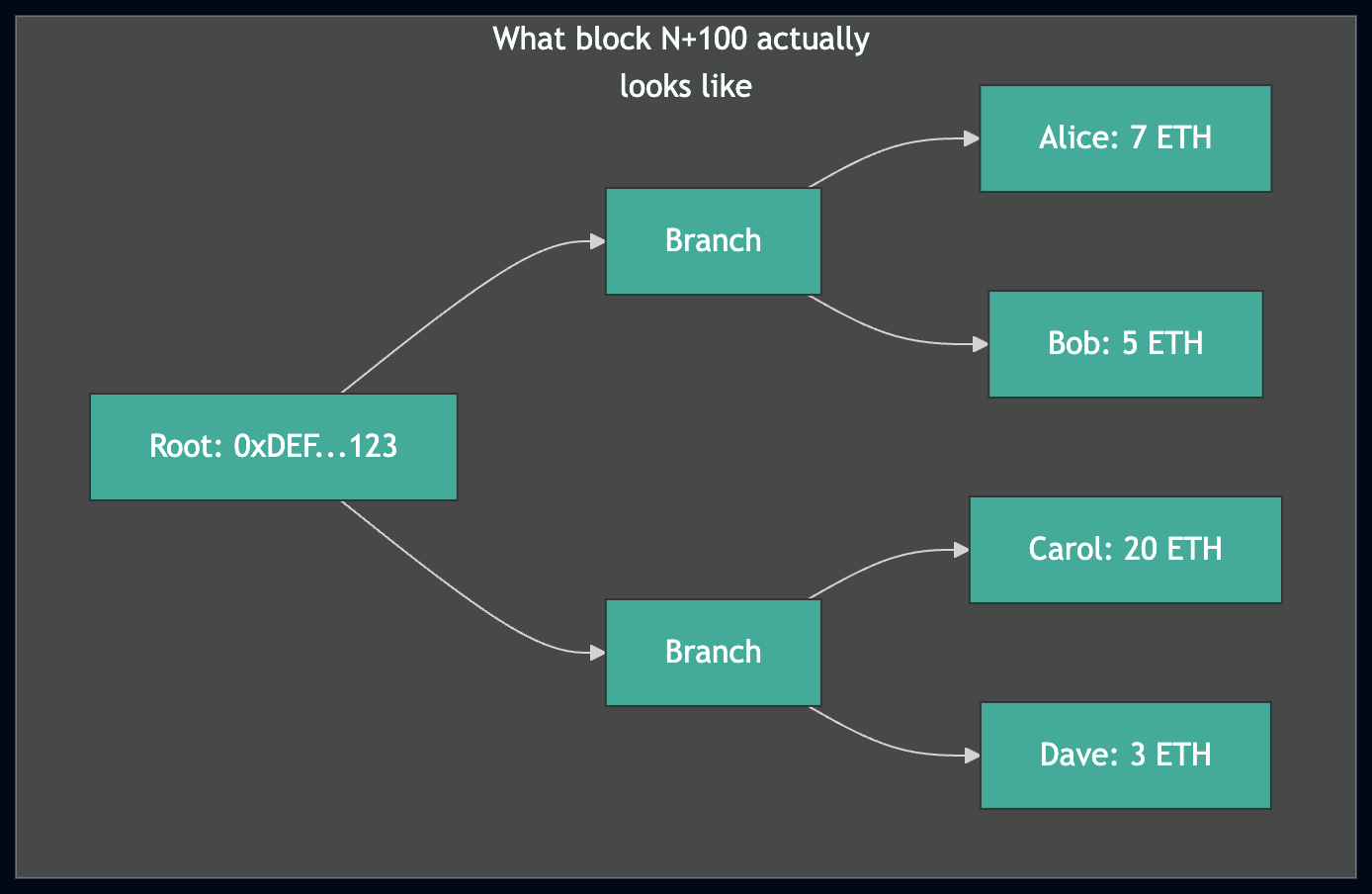
上图:我们构建的 trie 有一个错误的根,因为 Alice 的余额过期了。下图:区块 N+100 处的真实状态。愈合必须修复红色节点,使我们的 trie 匹配。
我们从这 4 个 leaves 构建的 trie 内部是一致的(每个分支都正确连接到其子节点),但它的根是错误的——它不匹配区块 N 也不匹配区块 N+100。
状态愈合解决了这个问题。它本质上是应用于我们嵌合 trie 的 fast sync(自上而下的 trie 遍历)。我们从当前 pivot 的真实状态根开始向下遍历:对于每个节点,我们检查它是否已经存在于我们的 trie 中。如果存在,我们可以跳过整个子树。如果不存在,我们从对等节点下载它并检查其子节点。
它之所以快——snap sync 比纯 fast sync 快 4-5 倍的原因——是因为 trie 的大部分已经正确。我们下载的 leaves 和重建的 trie 为愈合提供了巨大的先发优势。在 Hoodi 测试网上,纯 fast sync 大约需要 45 分钟;带愈合功能的 snap sync 大约需要 10 分钟。
为什么愈合是必要的
如果没有愈合,我们就会有一个我们在本地构建的 trie,但其根不匹配任何区块。我们无法使用它来验证新区块,因为以太坊的共识要求每个区块头中的状态根与你在执行该区块交易后计算出的 trie 根相匹配。愈合弥合了“大部分状态是正确的”与“状态是完全正确的”之间的鸿沟。
ethrex 如何实现 snap sync
Snap sync 的实现位于 ethrex-p2p crate 中,主要在:
sync/snap_sync.rs— 主协调器sync/healing/state.rs— 状态 trie 愈合sync/healing/storage.rs— 存储 trie 愈合sync/healing/types.rs— 共享类型(愈合队列条目)
pivot 和过期
Pivot 块是我们尝试下载其状态的目标。由于对等节点停止提供早于 128 个区块的根数据,ethrex 需要检测过期并更新 pivot。
我们使用基于时钟的过期检测而不是依赖对等节点响应。这是一个有意为之的选择:根据规范,对等节点对过期根返回空响应,但拜占庭节点可能随时返回空响应。所以我们只需检查:
stale = current_unix_time() > block_timestamp + 128 * 12当 pivot 过期时,我们估计一个新的区块号:
new_number = old_number + (elapsed_seconds / 12) * 0.80.8 的系数解释了约 20% 的槽位丢失(没有生成区块)。
子树不变量
整个愈合算法中最重要的不变量是:
如果一个节点存在于数据库中,那么该节点及其所有子节点都存在且正确。
这个不变量是愈合高效的原因。当自上而下遍历 trie 时,如果遇到一个已在数据库中的节点,我们可以跳过整个子树——我们知道它下面的所有内容都已存在。

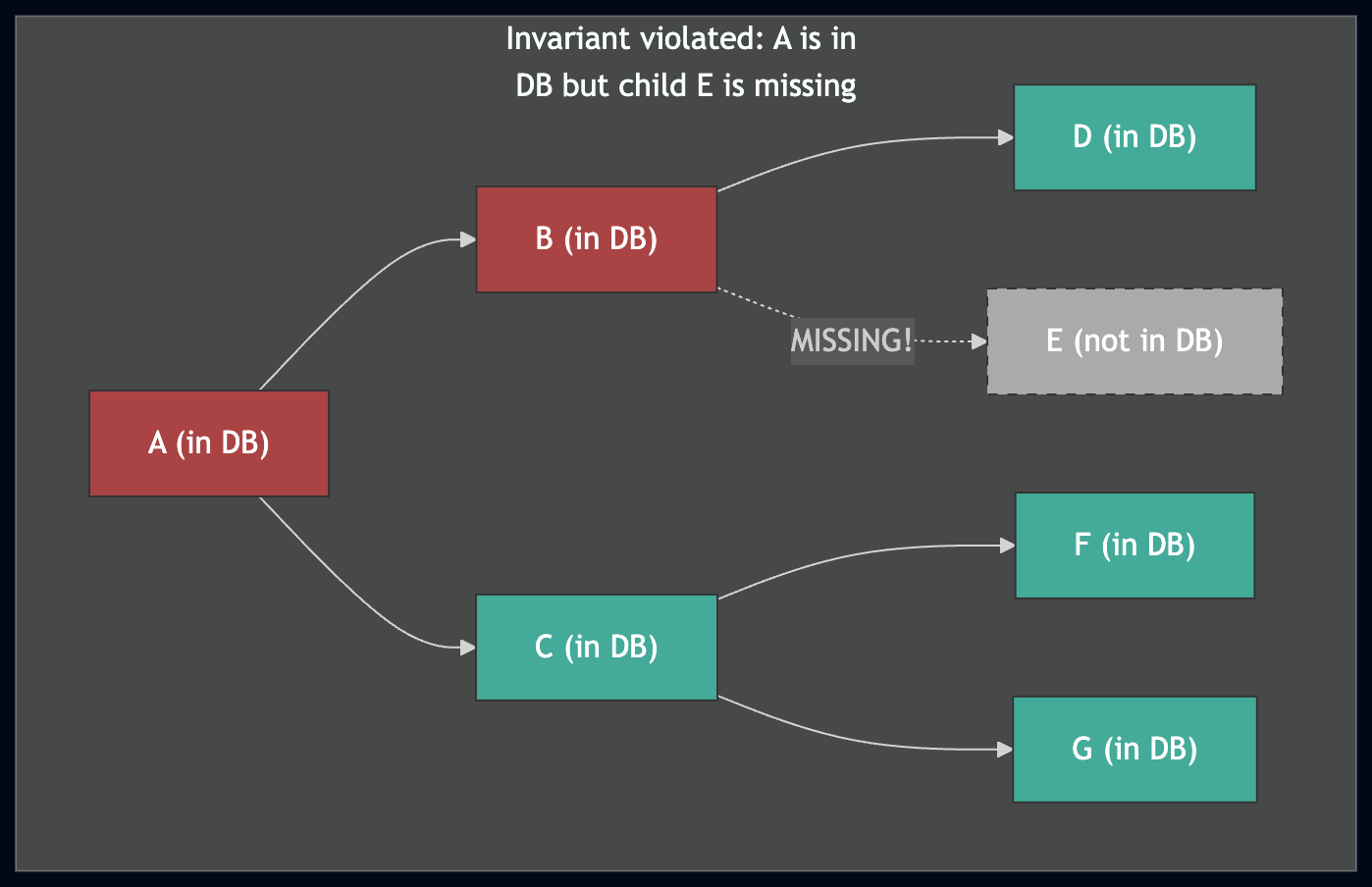
上图:不变量成立——如果愈合器在数据库中找到 A,它可以安全地跳过整个子树。下图:如果不变量被违反(E 缺失),愈合器将跳过 A 的子树,永远不会发现间隙,从而导致损坏的 trie。
在并发、可中断的下载过程中维护此不变量是状态愈合的核心工程挑战。
ethrex 如何实现愈合
愈合队列:一个依赖跟踪写入缓冲区
核心数据结构是我们称之为“愈合队列”(受 geth 的“membatch”启发)。它解决了一个根本问题:我们自上而下地下载节点(父节点在子节点之前),但我们需要自下而上地持久化它们(子节点在父节点之前)以维护子树不变量。
愈合队列是一个 HashMap,它将 trie 路径映射到条目:
pub struct HealingQueueEntry {
pub node: Node,
pub pending_children_count: usize,
pub parent_path: Nibbles,
}
pub type StateHealingQueue = HashMap<Nibbles, HealingQueueEntry>;当我们下载一个节点时,我们检查有多少其子节点在数据库中缺失。如果所有子节点都存在,我们可以立即写入该节点。如果有些缺失,我们将该节点存储在愈合队列中,并记录缺失子节点的数量,并将这些子节点添加到下载队列中。
当一个子节点最终被下载并提交时,我们递减其父节点的计数器。如果计数器归零,父节点也会被提交,这可能会进一步向上级联:
fn commit_node(
node: Node,
path: &Nibbles,
parent_path: &Nibbles,
healing_queue: &mut StateHealingQueue,
nodes_to_write: &mut Vec<(Nibbles, Node)>,
) -> Result<(), SyncError> {
nodes_to_write.push((path.clone(), node));
if parent_path == path {
return Ok(()); // 我们已经提交了根节点
}
let mut entry = healing_queue.remove(parent_path)?;
entry.pending_children_count -= 1;
if entry.pending_children_count == 0 {
commit_node(entry.node, parent_path, &entry.parent_path,
healing_queue, nodes_to_write)?;
} else {
healing_queue.insert(parent_path.clone(), entry);
}
Ok(())
}这创建了一个自下而上的提交波:leaves 首先提交,然后是它们的父节点,向上传播到根节点。
父路径删除
当节点刷新到数据库时,我们以一种特殊方式写入它们:所有祖先路径都写入为空字节(墓碑标记):
for (path, node) in to_write {
for i in 0..path.len() {
encoded_to_write.insert(path.slice(0, i), vec![]);
}
encoded_to_write.insert(path, node.encode_to_vec());
}这在愈合周期中保留了子树不变量。如果愈合因过期 pivot 而中断,墓碑标记确保在下一个周期,愈合算法将重新下载并根据新 pivot 的状态根重新验证祖先节点。只有最深已提交节点包含真实数据。
状态愈合循环
状态愈合算法(state.rs 中的 heal_state_trie)是一个异步事件循环:
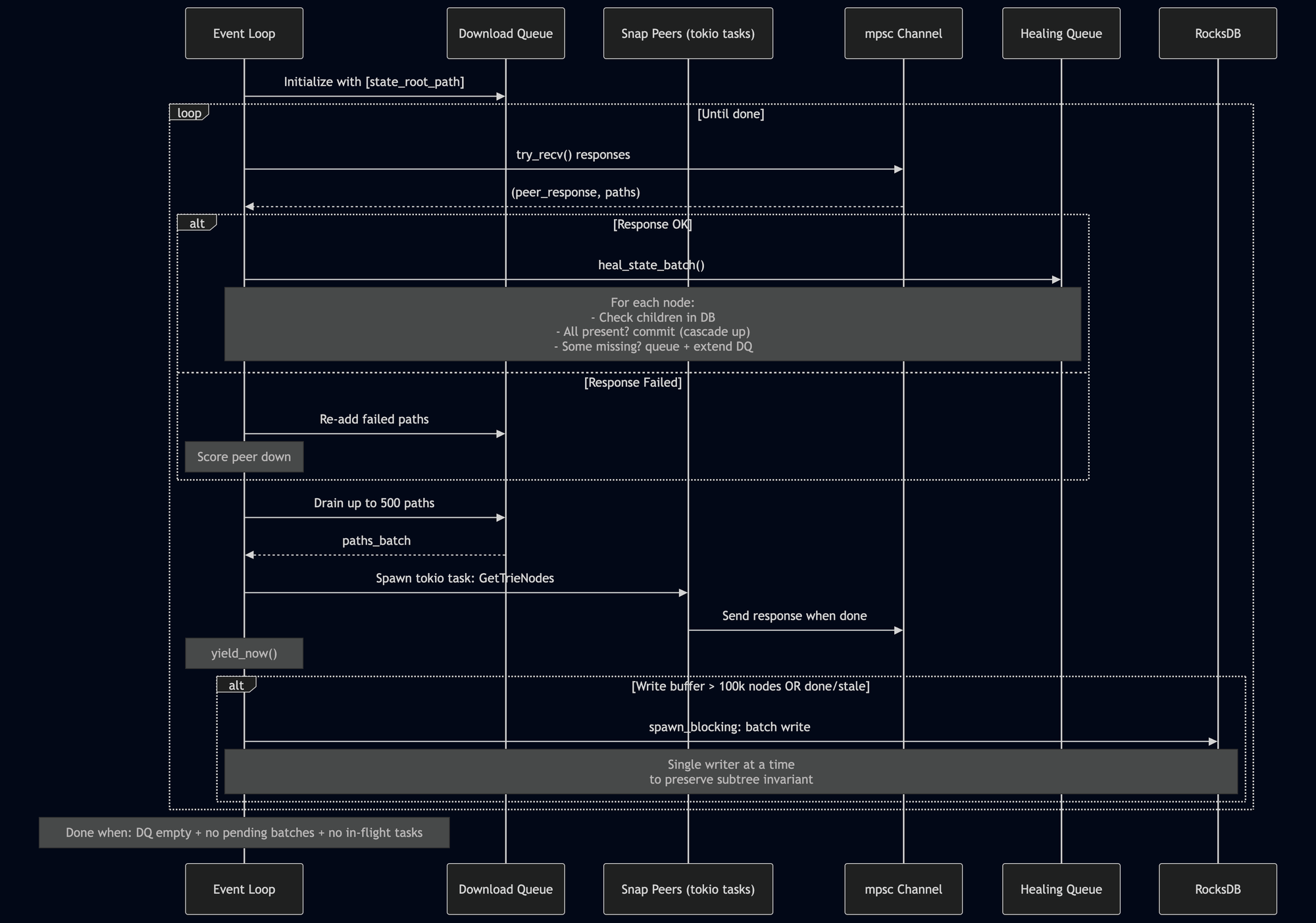
详细说明:
-
初始化:使用单个路径:状态根本身。
-
接收响应:(来自 mpsc 通道的非阻塞
try_recv)。成功的响应排队等待处理;失败的响应将其路径重新添加到下载队列中,并将对等节点评分降低。 -
发送请求:如果未过期。从队列中取出多达 500 个路径,选择最佳可用 snap 对等节点,并生成一个 tokio 任务来发送
GetTrieNodes请求。调用yield_now()以允许其他任务运行。 -
处理批次:通过
heal_state_batch:对于每个下载的节点,检查其在数据库中的子节点。如果全部存在,则提交它(可能级联)。如果有些缺失,则添加到愈合队列中,并用缺失的子节点扩展下载队列。 -
刷新到数据库:当写入缓冲区超过 100,000 个节点,或完成/过期时。一个
spawn_blocking任务处理写入——一次只有一个,以防止乱序写入可能违反子树不变量。 -
终止:当下载队列为空,没有批次待处理,且没有正在进行中的任务时。
在愈合过程中,遇到的每个 leaf 节点也会被检查:如果它有一个非空的代码哈希,该哈希会被收集以供稍后字节码下载。如果账户有存储,则将其标记为存储愈合。
存储愈合
存储愈合遵循与状态愈合相同的概念算法——自上而下遍历、愈合队列、自下而上提交——但由于我们同时愈合成千上万个独立的存储 tries,因此存在关键差异。
跨账户批量处理。 GetTrieNodes 消息允许在单个请求中从多个账户的存储 tries 请求节点。存储愈合按账户路径对请求进行分组:
[[acc_path_1, storage_path_a, storage_path_b, ...],\
[acc_path_2, storage_path_c, ...], ...]这减少了与每个账户一个请求相比的往返次数。
二维队列键。 由于我们同时愈合多个 tries,愈合队列的键由 (account_path, storage_path) 组成,而不仅仅是路径:
type StorageHealingQueueKey = (Nibbles, Nibbles);
pub type StorageHealingQueue = HashMap<StorageHealingQueueKey, StorageHealingQueueEntry>;并行初始化。 在愈合循环开始之前,get_initial_downloads 使用 rayon 的 par_iter 并行读取 trie 中的账户状态,确定哪些账户具有需要愈合的非空存储根。
并发上限。 存储愈合将正在进行中的请求上限设置为 77 (MAX_IN_FLIGHT_REQUESTS),而状态愈合是无限制的(每个发送的批次一个任务)。此上限防止对等节点因太多并发存储 trie 请求而过载。
基于结构体的状态。 存储愈合使用 StorageHealer 结构体来封装所有循环状态(下载队列、请求跟踪、指标),使代码比变量繁多的状态愈合循环更有条理。
并发模式
两种愈合算法共享相同的并发模式:
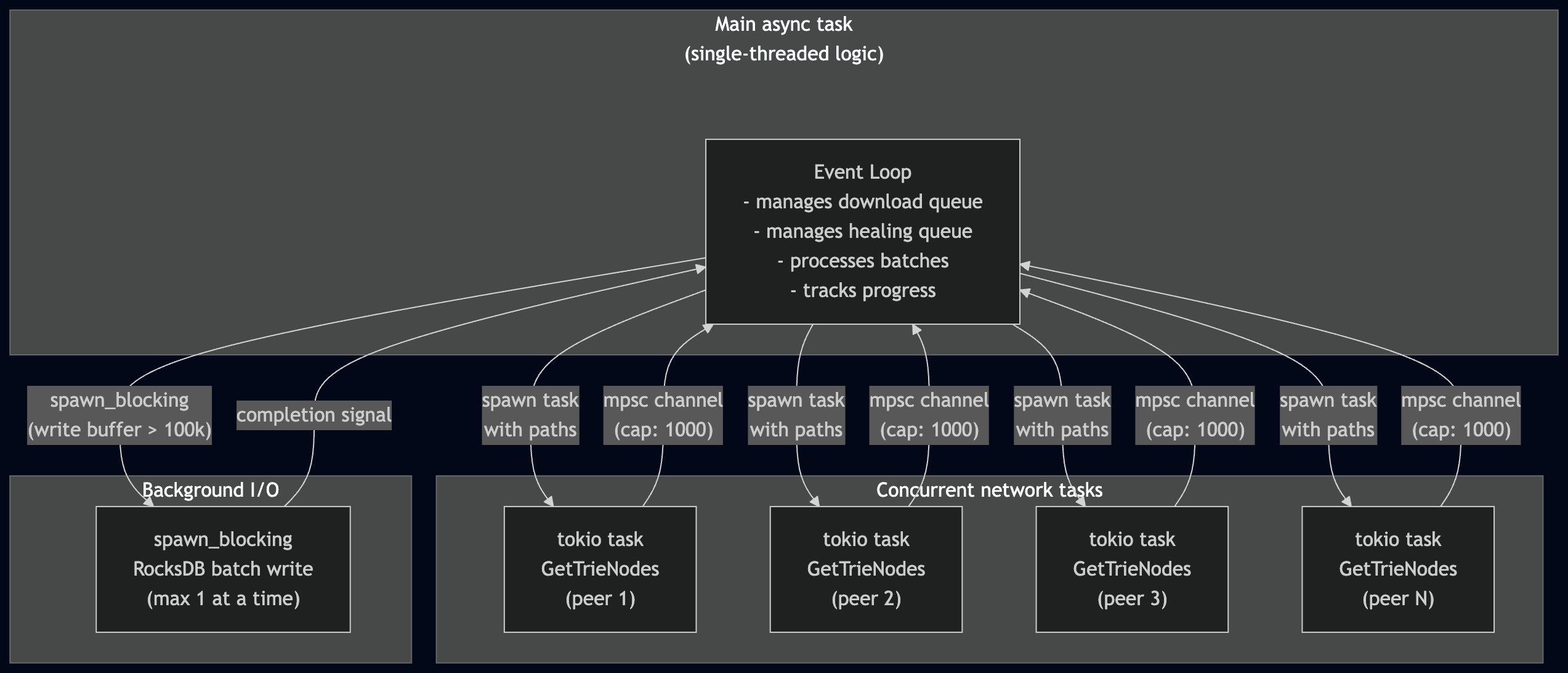
这种设计保持了状态管理的简单性(愈合队列上没有锁),同时通过并发网络请求实现了高吞吐量。事件循环是唯一读写愈合队列和下载队列的东西——tokio 任务只进行网络 I/O 并通过通道将结果发送回去。
如何判断愈合完成
当三个条件同时满足时,状态愈合完成:
- 下载队列为空(没有更多路径可获取)
- 没有批次待处理
- 没有正在进行中的任务
当以下条件满足时,存储愈合完成:
- 请求映射为空(没有正在进行中的请求)
- 下载队列为空
外部 snap sync 循环按顺序运行两个愈合过程。如果其中任何一个返回 false(因过期而中断),循环会更新 pivot 并重新开始。这意味着愈合可以跨越多个同步周期,逐步收敛到正确状态。
进度跟踪
ethrex 通过以下几个指标跟踪愈合进度:
global_state_trie_leafs_healed/global_storage_tries_leafs_healed— 累积 leaf 计数- 对等节点计数、正在进行中的任务、最长路径深度、下载成功率、愈合队列中的待处理节点
进度每 2 秒记录一次。没有明确的预计完成时间(ETA)——trie 愈合的性质使得进度难以预测,因为根附近的一个分支节点可以生成 16 条新的下载路径。记录的指标让操作员对收敛有感觉:当待处理路径和愈合队列正在缩小,愈合就接近完成了。
边缘情况和注意事项
时间旅行问题。 一个账户在 pivot 变化过程中可以从状态 A 变为 B 再变回 A。当它回到状态 A 时,节点已存在于数据库中——因此愈合会跳过它,即使该账户的存储根在状态 B 时可能不同。这是开发过程中一个重要的 bug 来源。在我们当前的基于路径的 trie 设计中,通过愈合覆盖先前状态来缓解了这个问题,但它仍然是我们仔细测试的问题。作为安全网,在存储下载期间经历 2 次过期 pivot 后,ethrex 会回退到愈合所有剩余的存储账户,而不是尝试下载它们。
调试验证。 在调试构建中,愈合完成后,整个状态 trie 和所有存储 tries 通过从头开始重新计算根来完全验证。这非常慢,但能确定性地捕获 bug——验证失败意味着 snap sync 中存在 bug,没有例外。
SKIP_START_SNAP_SYNC 标志。 设置此环境变量会跳过 leaf 下载,直接进入愈合,有效地模拟纯 fast sync。这对于独立测试愈合算法很有用。
接下来
状态愈合在主网上运行稳定。我们正在积极改进的领域包括:
- 在周期之间保留愈合队列,而不是在过期时清除它——这将避免重新下载我们已在内存中的节点。
- 在子节点查找期间检查愈合队列——如果一个子节点已在队列中,我们可以跳过下载。
- 优化存储愈合初始化期间的数据库读取——并行 trie 查找可以更高效地批量处理。
完整的 snap sync 代码是开源的,位于 github.com/lambdaclass/ethrex 的 crates/networking/p2p/sync/ 中。docs/l1/fundamentals/snap_sync.md 中的内部文档更深入地介绍了协议细节,并包含了每个阶段的流程图。
- 原文链接: blog.lambdaclass.com/how...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





