AI与Obsidian自动化第二大脑系统
- nickspisak_
- 发布于 3天前
- 阅读 24
本文介绍了如何利用 AI 编程助手(如 Claude Code)与 Obsidian 构建自动化的“第二大脑”系统。作者主张为不同领域建立独立的知识库而非单一杂乱的数据库,并详细讲解了通过命令行工具实现知识摄取、查询和定期维护的完整自动化流程。
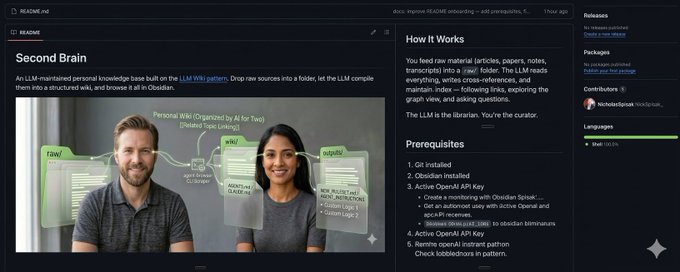
Part 1 展示了文件夹结构,而 Part 2 将为你提供完整的系统实现。
在第一部分中,我们介绍了三个核心文件夹。虽然有 1.2 万人收藏了那篇文章,但最初的版本只是创建了一个知识库,将所有内容堆砌其中,导致它看起来像个杂物篮。
问题不在于模式本身,这种模式非常出色。问题在于,一个通用的“第二大脑”试图包揽一切,结果却样样稀松。相反,针对特定领域的专用第二大脑可以独立复利。这就是我们今天要讨论的系统。
在 Part 1 之后,我构建了自动化整个设置过程的开源工具。过去需要一个周末才能完成的工作,现在只需几分钟。以下是完整的指南,涵盖了每一个依赖项、步骤和操作。
在接下来的 7 分钟内,你将学习到:
- 从零到运行第二大脑的完整设置链(详解每个依赖项)。
- 为什么特定领域的 Vault(库)优于庞大的通用知识库。
- 保持每个第二大脑持续运行和复利的 4 种操作。
- 你今天就可以构建的 5 种特定领域的第二大脑。
- 只需一条命令即可在 60 秒内搭建好一切。
1. 完整设置指南(按依赖顺序)
这里列出了你需要的每一个组件及其作用。
安装 Obsidian(免费)
访问 obsidian.md 下载应用。Obsidian 是一个 Markdown 编辑器,它将文件夹中的文本文件视为维基(Wiki),支持页面间的反向链接、展示连接关系的视觉图谱以及快速搜索。你不需要在里面写作,而是阅读 AI 编写的内容,它充当了你的图书管理员。
选择你的 AI 编程助手
你需要一个能够读取和写入计算机文件的 AI。以下任何一种都可以:
- Claude Code (我日常使用的工具)
- OpenAI Codex
- Cursor
- Gemini CLI
AI 扮演着图书管理员的角色。你通过配置文件给它指令,它负责维护你的整个维基。你永远不需要手动组织任何一个页面。
安装 Node.js
访问 nodejs.org 下载 LTS 版本。下一步的安装命令需要它。如果你已经安装了 Node,请跳过此步。
安装第二大脑技能
打开终端并运行安装命令。这会为你的 AI 助手安装四项技能:
/second-brain:搭建新库(引导式向导)。/second-brain-ingest:将原始素材处理成维基页面。/second-brain-query:针对你的维基进行提问。/second-brain-lint:对维基进行健康检查,修复错误。
一次安装即可在 Claude Code、Codex、Cursor 和 Gemini CLI 中通用。
安装 Obsidian Web Clipper
在 Chrome 网上应用店搜索并安装 “Obsidian Web Clipper”。这个浏览器扩展可以将任何网页文章保存为干净的 Markdown 文件,直接存入你库中的 raw/ 文件夹。
这是你喂养第二大脑的方式。看到值得保留的文章?点击一下,它就在 raw/ 文件夹里了,无需复制粘贴或重新格式化。
运行向导
在你的 AI 助手中输入 /second-brain。它会询问五个问题:库的名称、创建位置、涵盖的领域、你想要为哪些助手生成配置文件,以及需要安装哪些可选工具。
几分钟后,你就拥有了一个完整搭建的知识库。在 Obsidian 中打开该文件夹即可使用。底部的配置文件 CLAUDE.md 是系统的核心,它告诉 AI 如何履行图书管理员的职责。
2. 四大核心操作
每个第二大脑都基于四种操作运行。向导处理第一个,你则定期使用其余三个。
入职 (Onboarding)
一次性设置。创建文件夹结构,生成配置文件,引导索引和日志。
摄取 (Ingest)
这是系统强大的源泉。将素材放入 raw/ 文件夹,运行 /second-brain-ingest。AI 会阅读素材,与你讨论核心要点,然后:
- 编写摘要页面。
- 创建或更新实体页面(提及的人物、工具、公司)。
- 更新概念页面。
- 添加相关主题之间的交叉引用。
- 更新主索引。 一个素材通常会触达 10-15 个维基页面。
查询 (Query)
针对你的维基提问。运行 /second-brain-query 并询问任何问题,例如:“我在理解 X 方面最大的差距是什么?”或者“对比素材 A 和素材 B 的观点,它们的矛盾点在哪里?”AI 会阅读整个维基并综合给出带有引用的答案。关键在于:好的答案会被存回维基作为综合页面,你的提问会让系统变得更聪明。
检查 (Lint)
这是被大多数人忽略的每月健康检查。运行 /second-brain-lint,AI 会审计断开的链接、无连接的孤立页面、文章间的矛盾、被新素材取代的陈旧主张以及缺失的交叉引用。不要跳过这一步,错误的堆积和知识的增长一样快。
3. 为什么专用库优于通用库
这是一个非主流但重要的观点:如果你在 Part 1 之后建立了一个知识库,把健康文章、商业文档和 AI 研究混在一起,那你就错失了重点。
一个跨越 15 个主题、拥有 200 个页面的通用第二大脑,就像一个 AI 每次都必须翻找的档案柜。而一个专注于单一领域、只有 40 个页面的专用第二大脑,则是一个随着每个素材的加入而变得更敏锐的专家。
每个领域都会构建自己的概念图谱、实体网络和交叉引用。当你针对特定内容的库查询“哪些标题模式点击率最高?”时,AI 会从你数月的表现数据中提取信息,而不是从你的烹饪食谱或健身日志中寻找。
4. 五种你可以立即构建的第二大脑
每个库的搭建只需几分钟。以下是放入 raw/ 的内容以及维基产出的成果:
竞争情报 (Competitive Intelligence)
- 素材: 市场报告、竞争对手公告、产品发布页面、定价截图。
- 产出: 维基为每个竞争对手建立实体页面,并跟踪他们的动态。
- 提问: “[竞争对手] 在过去 90 天内发布了什么,与我们的产品相比如何?”
个人健康 (Personal Health)
- 素材: 化验结果、医生就诊记录、补剂研究文章、锻炼日志。
- 产出: 维基将你的血液指标趋势与数月数据中的生活方式变化联系起来。
- 提问: “根据我最近的三次血检,哪些方面在改善,我应该关注什么?”
客户知识 (Client Knowledge)
- 素材: 会议记录、入职调查问卷、项目文档、邮件往来。
- 产出: 每个大客户一个库。维基跟踪每一项决策、每一个待办事项和他们提到的每一个偏好。
- 提问: “我们在过去三次会议中达成了哪些共识,还有哪些问题悬而未决?”
学习与进阶 (Learning and Upskilling)
- 素材: 课程笔记、教程文稿、文档页面、会议演讲。
- 产出: 维基交叉引用来自不同来源的概念,并标记出你理解上的空白。
- 提问: “哪些概念我在 3 个以上的来源中见过,但从未整合进我自己的框架?”
内容管道 (Content Pipeline)
- 素材: 文章草稿、表现数据、受众分析、竞争对手内容拆解。
- 产出: 维基了解哪些主题表现好,哪些格式被收藏,以及哪些Hook (Hooks) 能引发回复。
- 提问: “基于所有行之有效的经验,我接下来的创作重点应该是什么?”
5. 知识复利的秘诀
每个第二大脑通过两种方式变得更聪明。
首先,新素材会优化现有维基。第 50 份竞争情报报告不仅仅是增加了一个页面,它还更新了每个实体,加强了交叉引用,并揭示了你在前 10 份报告中无法看到的模式。
其次,你的提问会形成反馈。当你询问“这 5 个竞争对手的趋势是什么?”且 AI 编写了综合分析时,该分析就成为了永久的维基页面。下一次查询将在此基础上进行。你的好奇心在字面上让系统变得更聪明。
这是 Karpathy 原始模式中被大多数人忽略的洞察:维基不是一个你去填满的终点,而是一个复利机器。第 100 个素材的价值呈指数级高于第一个,因为它拥有 99 个素材的上下文可以连接。
这就是完整的系统:Obsidian 用于查看,AI 助手用于维护,四项技能用于日常操作,以及根据你的需求建立的多个专用第二大脑。
选择你的第一个领域,输入 /second-brain,几分钟后,你的系统就上线了。
- 原文链接: x.com/nickspisak_/status...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





