理解零知识证明算法之 Zk-stark
- juneocean
- 发布于 2019-12-18 09:42
- 阅读 9716
谈到ZKP算法,大伙可能听过一些,比如zk-snark,zk-stark, bulletproof, aztec, plonk等等。今天,咱就给大伙聊聊这一对“表面兄弟”,zk-stark和zk-snark算法的异同之处。
Concept:zk-stark vs zk-snark
谈到ZKP算法,大伙可能听过一些,比如zk-snark,zk-stark, bulletproof, aztec, plonk等等。今天,咱就给大伙聊聊这一对“表面兄弟”,zk-stark和zk-snark算法的异同之处。
不如,先让我们从名称说起? 毕竟,两个看起来都很厉害的亚子^_^ !
如下图所示,我们将名称zk-stark 和 zk-snark根据功能特点分别分成四个部分,然后逐个比较分析。
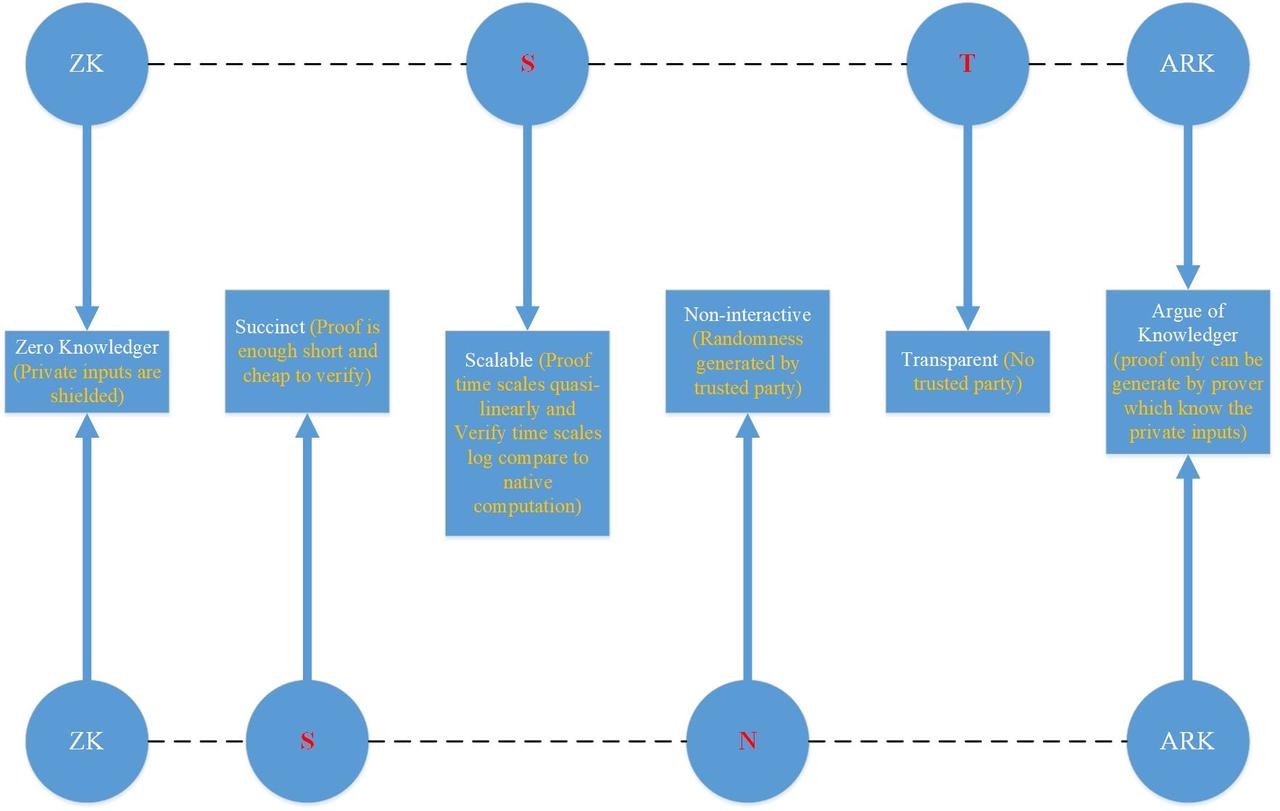
Zk-stark => zk - s t ark
zk:零知识,表明隐私的输入将会被隐藏,除了证明者,其他任何人不会看见; s:可扩展的,和Replay Computation的验证耗时相比,zk-stark的证明和验证耗时分别与之呈拟线性关系和对数关系; t:透明的,zk-stark算法没有CRS setup by Trusted party; arg:知识论证,只有知道private input的prover,才能生成有效的proof;
Zk-snark => zk - s n ark
zk:零知识,表明隐私的输入将会被隐藏,除了证明者,其他任何人不会看见; s:简洁的,指的是生成的proof足够小和验证时间足够短; n:非交互式的,Prover生成证明的过程中和verifier没有交互; arg:知识论证,只有知道private input的prover,才能生成有效的proof;
Compare
相同点
- 都实现了将隐私的输入可靠隐藏;
- 都是基于知识论证,不知道private input的prover生成不了有效的proof;
- 都可以实现交互式与非交互式式的算法,只是取决于randomness是由谁来生成的; 不同点
- zk-stark具有可扩展性,即证明和验证的耗时与原始计算的耗时分别呈拟线性关系(且线性因子为常量)和对数关系,这意味这,如果原始输入的数据集增大1000000倍,zk-stark的证明耗时增加线性倍数的时间,但验证时间仅仅增加21*log1000000 =~ 420倍。证明耗时呈线性关系基本满足所有的ZKP算法,但是验证时间呈对数关系,仅此一家,因此在扩展性上,zk-stark要胜一筹。
- zk-stark同样具有简洁性,但是是验证简洁性。所谓简洁性,通常是指即使验证程序很大,生成的proof size也不会很大,同时又能很快的完成验证(比native computation快很多)。相比对zk-snark,zk-stark的proof size要大的多,因此在简洁性上,zk-snark要胜一筹。
ALG compare
前面从概念上对zk-stark 和 zk-snark算法做了比较,其异同点可以笼统的概括为:
- 都是基于知识论证的ZKP算法;
- zk-stark不需要zk-snark的Trusted party 设置CRS,因此是Transparent;
- zk-stark的验证耗时与native computation 耗时呈对数关系,因此是Scalable;
下面,我们将从算法层面,去做相对更深入一些的比较分析:
zk-snark ALG
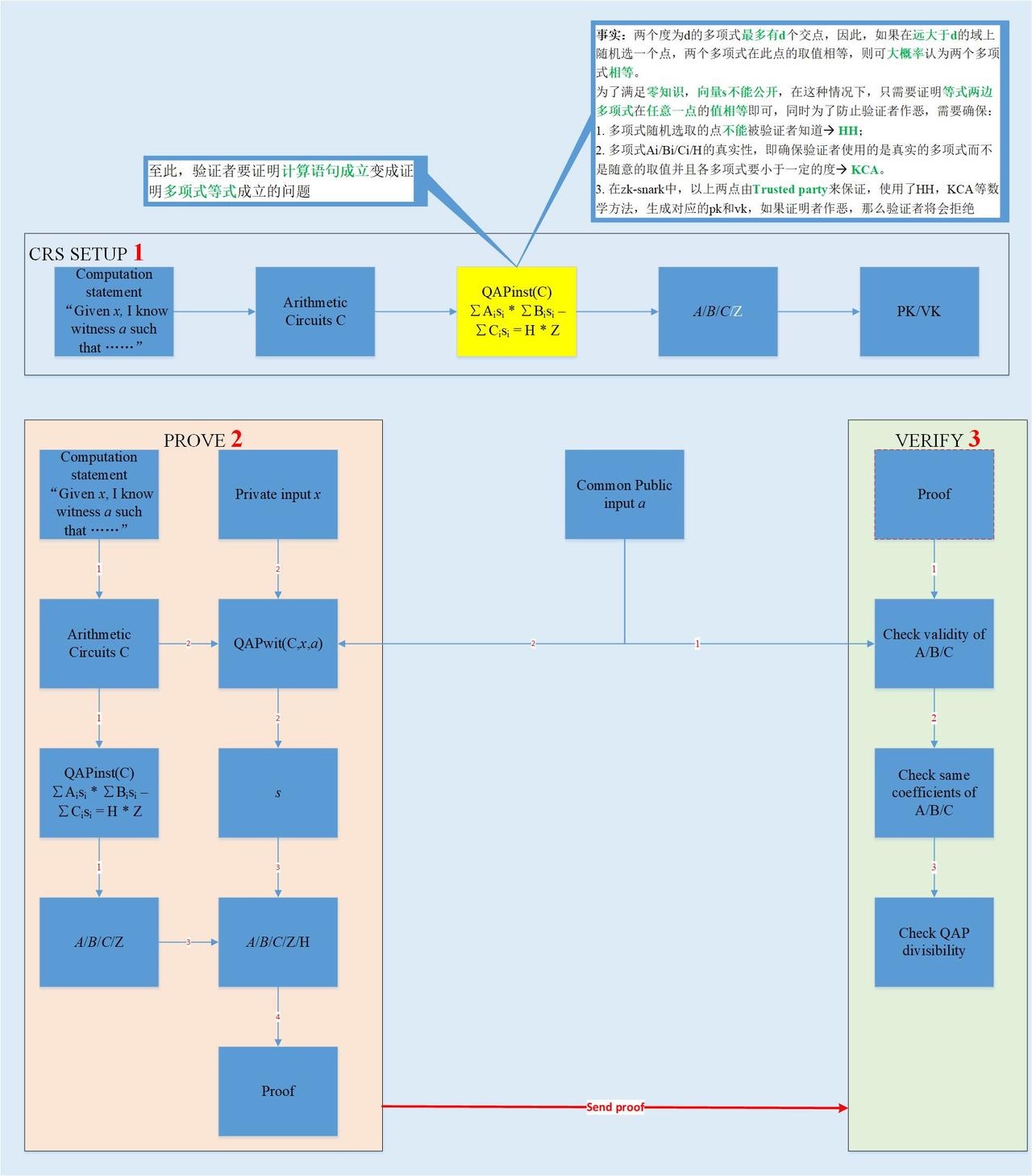
- 算法思想:将证明CI statement成立问题转换成证明多项式等式成立问题,转换过程用到了算术环路和QAP方法;
- 多项式等式成立意味着什么?(图中黄色部分) 等式两边可以看作两个度相等的多项式,假设为n,其交点最多有n个,假如在一个很大的域范围内随机选一个点,如果的两个多项式在此点的值相等,则证明两个多项式是相等的。 我们可以看到,等式右边的多项式因子Z是目标多项式,它的零点就是右边整体多项式的零点,也就是等式左边整体多项式的零点,而等式左边的多项式在这些零点的取值,就转换成了一个个的算术电路里每个乘法门对应的一阶线性约束等式(R1CS)成立,即原始计算等式成立(注:R1CS由原始计算等式分解得到);
- 算法分为三个步骤,CRS生成;证明者证明;验证者验证;
- 可以看到prover生成证明过程中,没有与验证者交互,因此是non-interative;
- 如何保证prover用于生成证明的A/B/C/H是多项式且是小于某个度数呢?
a. 通过trusted party 来保证,因为它是可信任的,因此它生成pk,vk用到的A/B/C等肯定是多项式并且是小于某个度的;
b. 如果证明者作恶,那么验证者将会很大概率验证失败;
c. 主要用到了同态加密HH和系数知识假设KCA和椭圆曲线双线性配对等数学知识;
zk-stark ALG
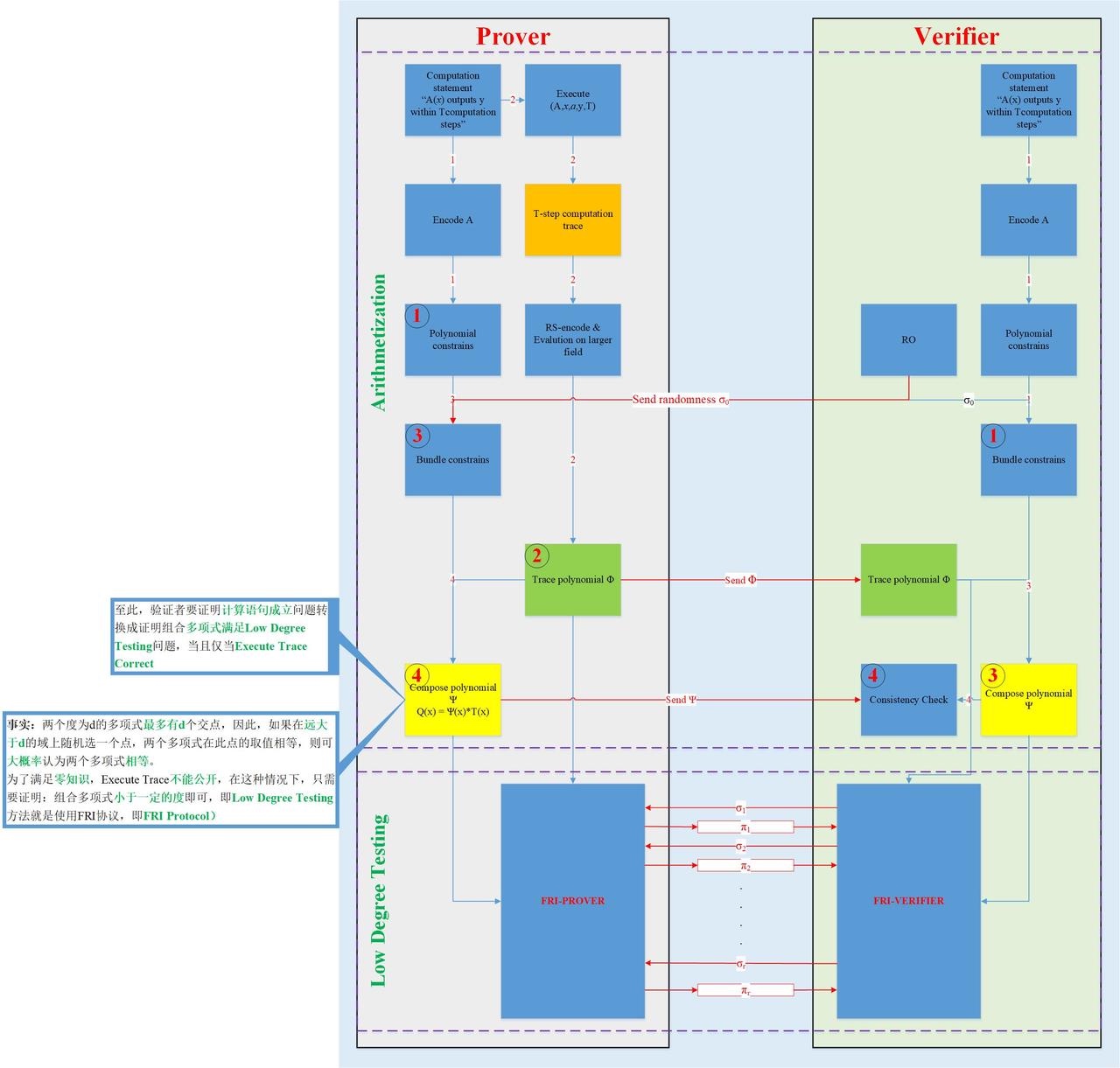
- 算法思想:将证明CI statement成立问题转化成证明多项式小于某个度的问题,转换过程用到了多项式插值方法;
- 多项式等式成立意味着什么?(图中黄色部分) 思想与zk-snark一样,T同样为目标多项式,其零点已知且公开,也是等式左侧多项式Q的零点,多项式Q在每一个零点的取值都对应了一个execute trace的成立(没错,在zk-stark中,原始计算语句转化成了多个execute trace,这类似与zk-snark中的R1CS)。因此多项式相等,意味着execute trace 正确,说明原始CI成立。
- 多项式小于某个度意味着什么? 和zk-snark类似的是,两者都把CI statement转换成了证明多项式等式成立的问题(?可以这么抽象的认为,zk-stark不仅要证明多项式相等,还要证明相应多项式是小于某个度的,这是zk-stark算法的核心,所以才有了第一点的描述)。为了防止验证者作恶,必须要保证多项式是低于某个度的(?存在这样一种可能,攻击者可以特意生成满足验证等式的一些点,这些点并不是真正的多项式上的点,但是根据这些点生成的证据也能通过验证者验证)。不同的是,zk-snark使用了trusted party机制 和 同态加密等数学方法,而zk-stark使用了低度测试等数学方法。当且仅当多项式真正的小于某个度时,多项式的相等才是真实意义上的相等,说明生成轨迹多项式的execute trace 是正确的,即原始CI成立。
- 算法分为两大步骤,算术化和低度测试; a. 算术化:是把问题转化为多项式形式 b. 低度测试:是证明组合多项式(图中黄色)和轨迹多项式(图中绿色)小于某个固定的度-->FRI算法
- 在生成证明的过程中,有交互(图中红线所示),所以图中描述的是交互式的零知识证明算法;
Summary
以上分别从概念和算法上介绍了zk-snark和zk-stark算法的异同之处,作为引子,后续发文将深入详细价绍zk-stark算法的原理。如有不足,请批评指正,谢谢。
Appendix
V神三部曲,含泪拜读 https://vitalik.ca/general/2017/11/09/starks_part_1.html zk-stark论文 chrome-extension://cdonnmffkdaoajfknoeeecmchibpmkmg/assets/pdf/web/viewer.html?file=https%3A%2F%2Feprint.iacr.org%2F2018%2F046.pdf starkware官方讲解系列 https://medium.com/starkware/stark-math-the-journey-begins-51bd2b063c71 zk-snark论文 chrome-extension://cdonnmffkdaoajfknoeeecmchibpmkmg/assets/pdf/web/viewer.html?file=https%3A%2F%2Feprint.iacr.org%2F2013%2F879.pdf





