去中心化存储那些事(下)
- web3探索者
- 发布于 2022-03-07 10:06
- 阅读 5371
本文介绍了去中心化存储的另外1种解决方案Arweave的实现。文中还对比了filecoin和Arweave的优劣,目前来看Arweave落地的更好一些。最后我们通过Arweave的smartweave引出了一种基于存储的共识范式。
上篇文章我们讨论了去中心化存储ipfs和filecoin。文末提到filecoin虽然提供了去中心化存储,但系统并未提供数据冗余的能力,也就意味着机制上并不保证存储在filecoin中的数据不会丢失,本文我们将讨论提供了冗余机制的去中心化存储解决方案-Arweave。
Arweave
Arweave实现了什么
Arweave 实现了数据的永久存储。即一次进行付费存储,数据将会永久存储在Arweave网络中。
Arweave如何实现
适度冗余
与 filecoin 链下存储的思路不同,Arweave 采用链上存储。在常规的区块链如以太坊中,每个全节点都会下载所有区块。这样来看链上存储可以解决之前提到 filecoin 没有冗余性的设计问题。但如果采用这种方式做去中心化存储也带来大部分节点存储不够的问题,因为每个节点将存储所有的数据,换句话说这样冗余度太高了,我们需要适度冗余即可。
每个节点存储部分区块
如何实现适度冗余呢?Arweave 为了解决这一问题设计了不同的区块链数据结构以及证明方式。每个节点只存储一部分区块。
Arweave使用2张表解决了节点必须存储所有区块的问题
- 区块哈希列表
- 钱包列表
有了块哈希列表,我们不需要下载所有区块进行逐个验证,而是在区块生成过程中持续验证。
有了钱包表,Arweave可以在当前区块即可查到任何一个账户的状态。其原因和以太坊中为何状态树不和交易树一样只存储当前区块涉及到的账户一样。即假设要给1个没有发生过交易的账户转账,则需要遍历到初始块中。以太坊的设计是为了提高效率,而Arweave则是为了实现只存储部分区块的目标。
冗余实现-POA和blockwave
如果只是这样Arweave解决了每个节点只存储部分区块,但无法保证区块的冗余性,因为极限情况下Arweave永远只需要存储最近的一个区块即可。Arwave采用POA服务证明来解决这一问题。
POA访问证明
Arweave中采用POW+POA的方式确定出块权,POW我们之前的文章多次提过不再重复,POA是为了实现每个区块在不同节点的冗余性,其要求是节点出新块的时候需要证明存储了之前随机的某个区块-recall-blockk。
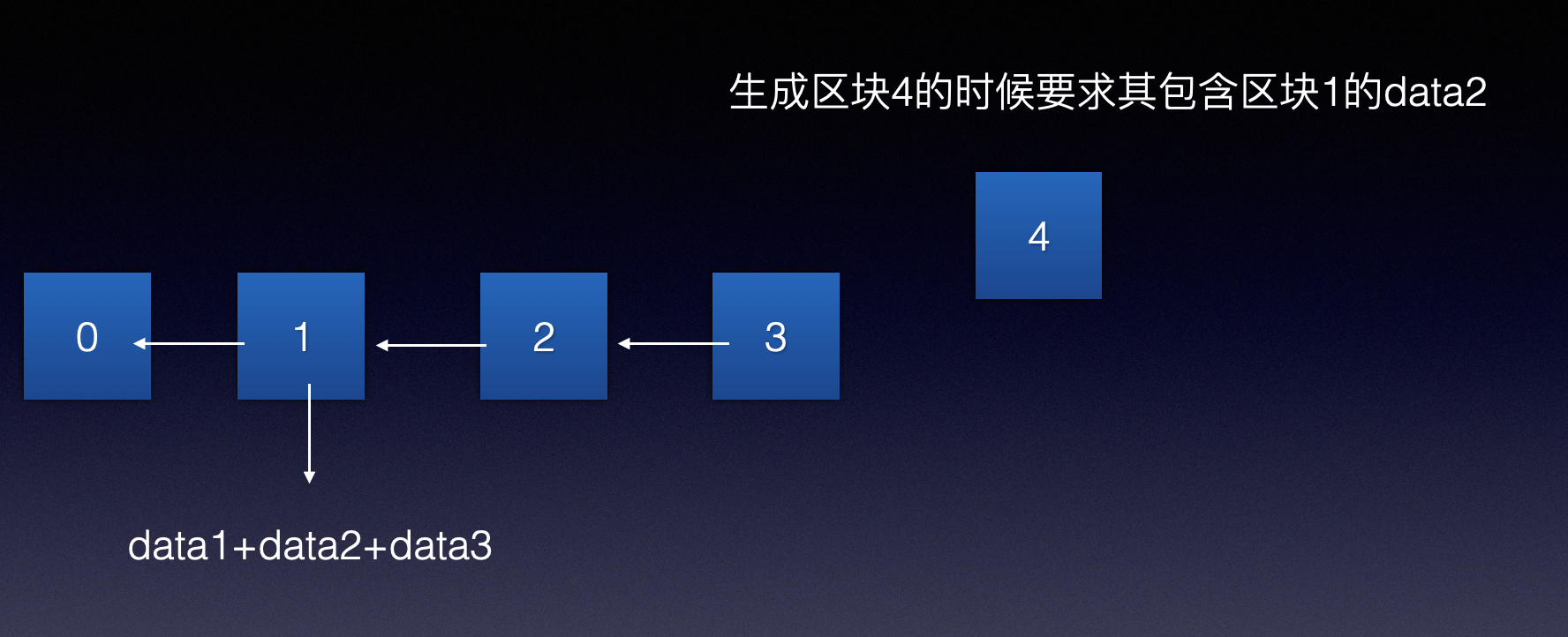
如上图所示,区块4生成的时候要求包含之前链上区块1的部分数据data2。这使得区块4需要存储区块1才可以参与后续挖矿。
blockweave
由于上面POA的方式,Arweave的区块链结构变成了图,当前区块不仅与前一区块连接并且和历史某个随机区块相连接。如图所示
 我们将上面这样的结构称之为blockweave。
我们将上面这样的结构称之为blockweave。
生成新块
我们来描述Arweave生成1个新的区块的具体流程
- 当面末尾区块是区块5,节点A存储了区块2和3
- 生成区块6的需要携带区块2的数据,节点A进行POW
- 通过比拼节点A POW竞争中胜出,获得记账权
- 节点A打包事务并按照要求存入区块2的部分数据,整体打包生成新的区块
- 节点A将新的区块和recall block广播给其他节点
- 其他节点验证新的区块是否有效,有效包含区块的随机数符合POW以及区块中是否包含recall block的部分数据。
上面的过程,为什么要将recall block也一并广播给其他节点呢?Arweave每个节点只存储部分区块,所以很多节点并没有该recall block,但很多都包含recall block的hash值,这样我们可以确认传输过来的recall block的正确性,并用该recall block去验证新的区块中包含的数据是否正确。
Arweave通过POA的方式可以实现均匀的将块分布在不同节点上,每次新块需要的recall block是随机的,一旦某个区块有较少节点存储那么拥有这个区块的节点获得记账权的概率就会变大,从而其他节点也来存储该区块。而如果按照均匀分布计算,某个区块丢失的概率为 (1-平均每个节点存储的区块数/网络中所有区块)^网络中节点数,由于网络中节点数不断增加,区块丢失概率非常之低。
由此可见,Arweave的永久存储还是比较靠谱的,真正从机制上实现了存储冗余。
分发机制
存储的问题基本解释清楚了,之前说过存储系统有2个事情需要解决1个是存数据 1个是分发数据,我们简单看看Areave的数据分发如何
数据访问 Arweave使用了wildfire系统来保障数据更快分发,wildfire是一个排名系统,每个节点都会维护起对等点的排名,排名根据对等点的请求响应耗时来决定,会根据排名顺序来进行顺序交互,这样性能不佳的节点由于在每个节点排名都较差,最终没有节点与之交互从而被踢出网络。
Arweave vs filecoin
同样作为去中心和的存储方案,我们来看看Arweave和filecoin有什么区别,这里不再对比ipfs,之前文章已经论述过ipfs是更侧重数据分发的协议而非存储方案,并且filecoin就是基于ipfs搭建的。
| Arweave | filecoin | |
|---|---|---|
| 目标 | Arweave的目标是实现永久存储 | filecoin的目标是充分利用存储提供商的存储空间以降低存储价格 |
| 冗余性 | Arweave由blockweave结构和POA激励保证数据的冗余性以达到数据冗余 | filecoin本身未支持冗余性,需要存储者主动向不同存储提供商存储多次以达到冗余。 |
| 有效期 | Arweave是一次付费永久存储 | filecoin需要和存储提供商商议存储时长 |
| 存储位置 | Arweave将数据存储在链上 | filecoin将数据存储在链下。通过复制证明和时空证明不断验证。 |
| 存储容量 | 较大,但存在数据冗余限制 | 由于filecoin本身没有数据冗余,理论上存储容量要大于Arweave |
| 分发 | filecoin本身的查询检索非常缓慢并且要收费,上篇文章我们说过通常都需要和ipfs搭配使用。而ipfs和网络中各个节点有关,理论上是可以达到比http更好的体验,但就目前看还有不小差距。 | arweave的分发是基于http并增加了wildfire系统能够有较为稳定的体验。 |
这两种方式整体上看目前Arweave要相对更实用一些。filecoin核心问题在于其分发机制一直被诟病,基本上无法单独满足用户体验。
至此,我们对去中心化的存储讨论告一段落,但文中既然提到了Arweave,我们就来继续看看Arweave为区块链运行机制提出的另外一种思路-链下计算。
Arweave不只于存储
SmartWeave
SmartWeave是Arweave的智能合约平台,其机制是在链下执行合约调用,然后将状态存储在Arweave中。是不是似曾相识,我们之前介绍过Layer2的Rollup也是这种机制。SmartWeave规定合约的执行是由调用者完成。

在之前Layer2一文中我们了解过,受限于不可能三角,为了提升L1的TPS将执行过程放在单独一层L2,而L1只进行状态的存储,但就L2的方案需要解决的1个核心问题就是如何证明L2向L1发布的状态是正确的,L2的实现方案之前一文已经讨论过,这里不再赘述。我们看到SmartWeave也是将Arweave只作为存储,而交易执行(状态转移过程)放在链下。那在SmartWeave中是否需要证明发布到Arweave的状态的正确性呢?
SmartWeave并不需要发布者证明其发布的状态正确性,而是采用惰性评估,即每次合约调用者在调用合约的时候,需要将合约相关的交易全部执行一次进行状态转移。相当于将状态的正确性交由下一次合约的调用者来验证。这种方式极大地释放了链上计算量,使得SmartWeave TPS (吞吐量)大幅优于其他L1链。
理论美好,但实际落地遇到了很多问题,目前看SmartWeave并未对发布错误状态的用户做任何惩罚机制。这势必会导致大量用户可以发起很多无效调用来增加后续每次合约调用者的耗时,也就是DDOS攻击。
就目前而言,Arweave还是以永久存储为主要作用,而SmartWeave这种机制还有不少问题有待解决。
结尾
本文介绍了去中心化存储的另外1种解决方案Arweave的实现,通过钱包列表和哈希列表实现了每个节点只存储部分区块,通过POA和blockweave结构实现了数据冗余,从而达成永久存储的目标。文中还对比了filecoin和Arweave的优劣,目前来看Arweave落地的更好一些。最后我们通过Arweave的smartweave引出了一种基于存储的共识范式。
- 学分: 4
- 分类: Arweave/AO
- 标签: 去中心化存储 Arweave 共识





