深入理解EVM - Part 4 - Geth中存储区的实现
- Alvan
- 发布于 2022-06-25 12:40
- 阅读 6162
以Geth代码为基础,从区块结构讲到账户状态/合约存储,最后是SSTORE和SLOAD两个操作码的具体实现
原文链接:https://noxx.substack.com/p/evm-deep-dives-the-path-to-shadowy-5a5?s=r
这是“深入理解EVM”系列的第四期。在第三期中我们了解了合约存储相关的知识,这期会说明以太链的“世界状态”是怎么容纳单个合约的存储区的。为此我们需要审视以太链的体系结构和数据结构,一探Geth客户端深处的秘密。
我们从以太区块的数据开始,反推回特定合约存储区。再用Geth如何实现SSTORE与SLOAD收尾。需要了解的知识有很多,我们会介绍Geth代码库,讲讲以太坊的世界状态,让你对EVM有一个更深的了解。
以太坊体系结构
我们从下图开始,不要有恐惧心理,在文章的结尾你会对它有一个全面的认识,这里画出了以太坊的体系结构和以太链的数据。
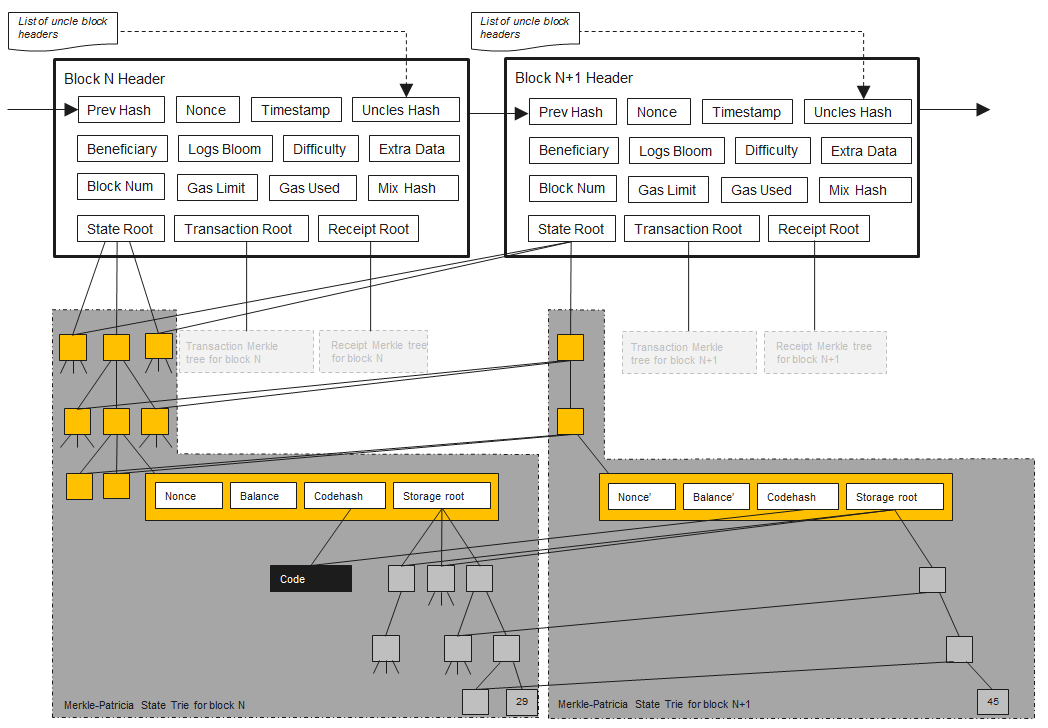 以太坊体系结构 - 来源: Zanzu
以太坊体系结构 - 来源: Zanzu
相比看整个的图,我们不如一块一块看。现在我们看一下第N块的区块头和它包含的字段。
区块头
区块头包含以太区块的关键信息,下边的第N块区块头就划分出了这些信息。看看以太坊第14698834块 是否有下图的字段吧。
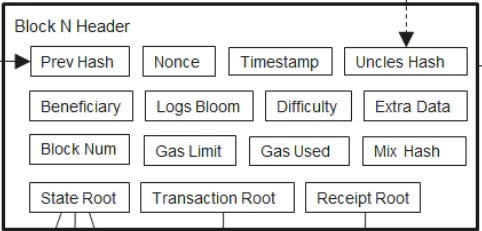
区块头包含以下字段:
- Prev Hash - 父区块的Keccak 哈希
- Nonce - 用于PoW计算,检验区块是否被成功挖出
- Timestamp - UNIX时间戳
- Uncles Hash - 叔叔节点的Keccak 哈希
- Beneficiary - 收款人地址,矿工费接收者
- LogsBloom - 布隆过滤器,提取自receipt,用于查找交易回执中的智能合约事件信息。
- Difficulty - 表示当前区块的挖出难度
- Extra Data - 最长32字节的自定义信息,由矿工自定义
- Block Num - 区块高度
- Gas Limit - 每个区块允许的最大gas量
- Gas Used - 该区块实际消耗的gas量
- Mix Hash - PoW验证时使用,代表区块不含nonce时的哈希值
- State Root - 执行完此区块中的所有交易后以太坊中,所有账户状态的默克尔树根哈希值
- Transaction Root - 交易生成的梅克尔树的根节点哈希值。
- Receipt Root - 交易回执生成的梅克尔树的根节点哈希值。
让我们看看这些和Geth代码的对应关系,block.go里定义的“Header”结构体就代表一个区块头。
 代码地址: go-ethereum/core/types/block.go
代码地址: go-ethereum/core/types/block.go
我们可以看到代码里声明的变量是和上边的概念图匹配的,我们的目标是从从区块头一路找到合约存储区。为此我们要关注被标红的“State Root”字段
状态根
“状态根(State Root)”是一个梅克尔根,它取决于其下所有的数据块,任何一块数据的变动都会改变它。这个状态树的数据结构是MPT,叶子结点存储这网络上每一个以太坊账户的数据。该数据为k-v结构,key是地址,value是账户信息。
实际上key是地址的哈希值而value是账户信息的RLP编码,但是我们可以暂时忽略这件事
以太坊体系结构图的这一部分正是代表了状态根的MRT。
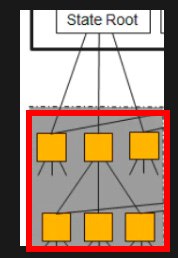
MPT是一种复杂的数据结构,我们这篇文章不做深究。如果你对MPT感兴趣的话建议看这篇文章。接下来我们重点看看以太坊的账户信息是如何映射到地址的。
以太坊账户
以太坊账户由以下四项构成:
- Nonce - 账户的交易数
- Balance - 账户余额
- Code Hash - 合约账户的所执行的代码,一旦被初始化就是只读的。
- Storage Root - 存储根,该值随着合约的存储区的增加、删除、改动而不断变更
(译者注:后两项是合约账户拥有的数据段,普通账户并没有)
我们在之前以太坊体系结构图的这一段可以看到:

现在我们去看看Geth的代码,找到对应的 state_account.go ,这个StateAccount结构体就是“以太坊账户”。
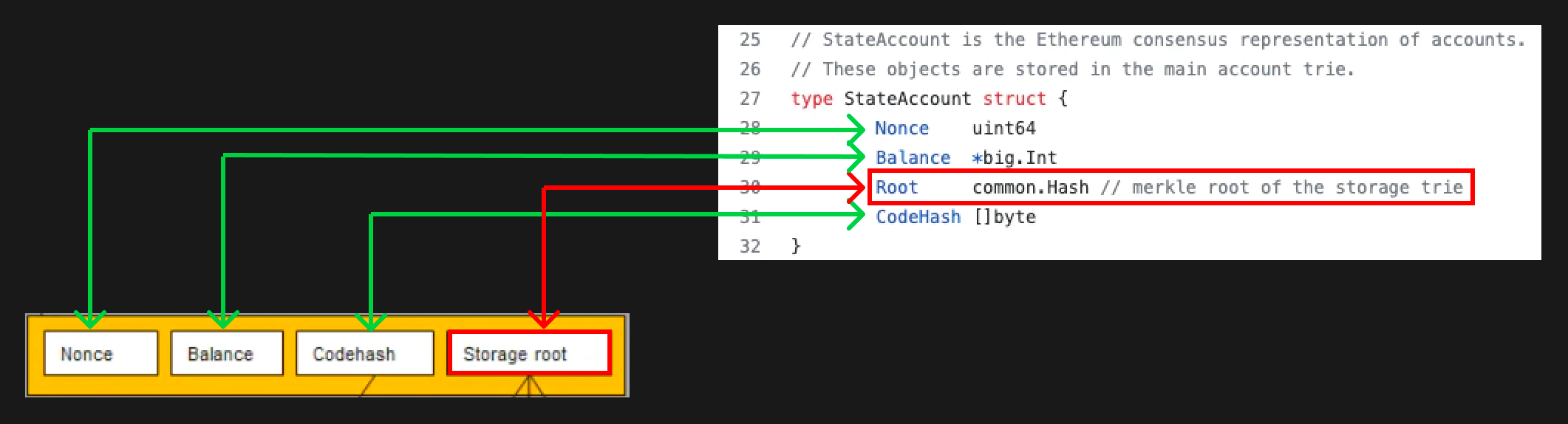 代码地址: go-ethereum/core/types/state_account.go
代码地址: go-ethereum/core/types/state_account.go
可以看到代码里声明的变量与概念图对应上了。接下来我们需要探讨以太坊账户的存储根。
存储根
存储根(storage root)很像状态根,在它的下面是另一棵MPT。区别就是这次的key是存储插槽,而value是插槽里的数据。
跟状态根一样,key其实是哈希值而value是RLP编码
以太坊体系结构图的这一部分正是代表了存储根的MRT。
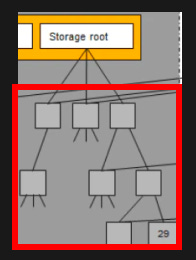
存储根是一个梅克尔根,任何合约存储区的数据的改变都会改变存储根的值,从而影响区块头的值。现在我们知道怎么从区块找到合约存储区了。下一步我们继续研究Geth的代码,看看存储区是怎么初始化的,以及调用SSTORE和SLOAD是会发生什么。这会帮助你找到底层opcode和solidity代码之间的联系。
StateDB → stateObject → StateAccount
我们需要一个全新的合约,全新的合约意味着StateAccount也是全新的。
开始之前我们看三个结构:
- StateAccount
- StateAccount 是以太坊账户的一致化表达
- stateObject
- stateObject 代表着尚未被修改的以太坊账户
- StateDB
- StateDB 存储梅克尔树的所有数据,用于检索合约和以太坊账户的查询接口
我们看看这三个结构的内在关系:
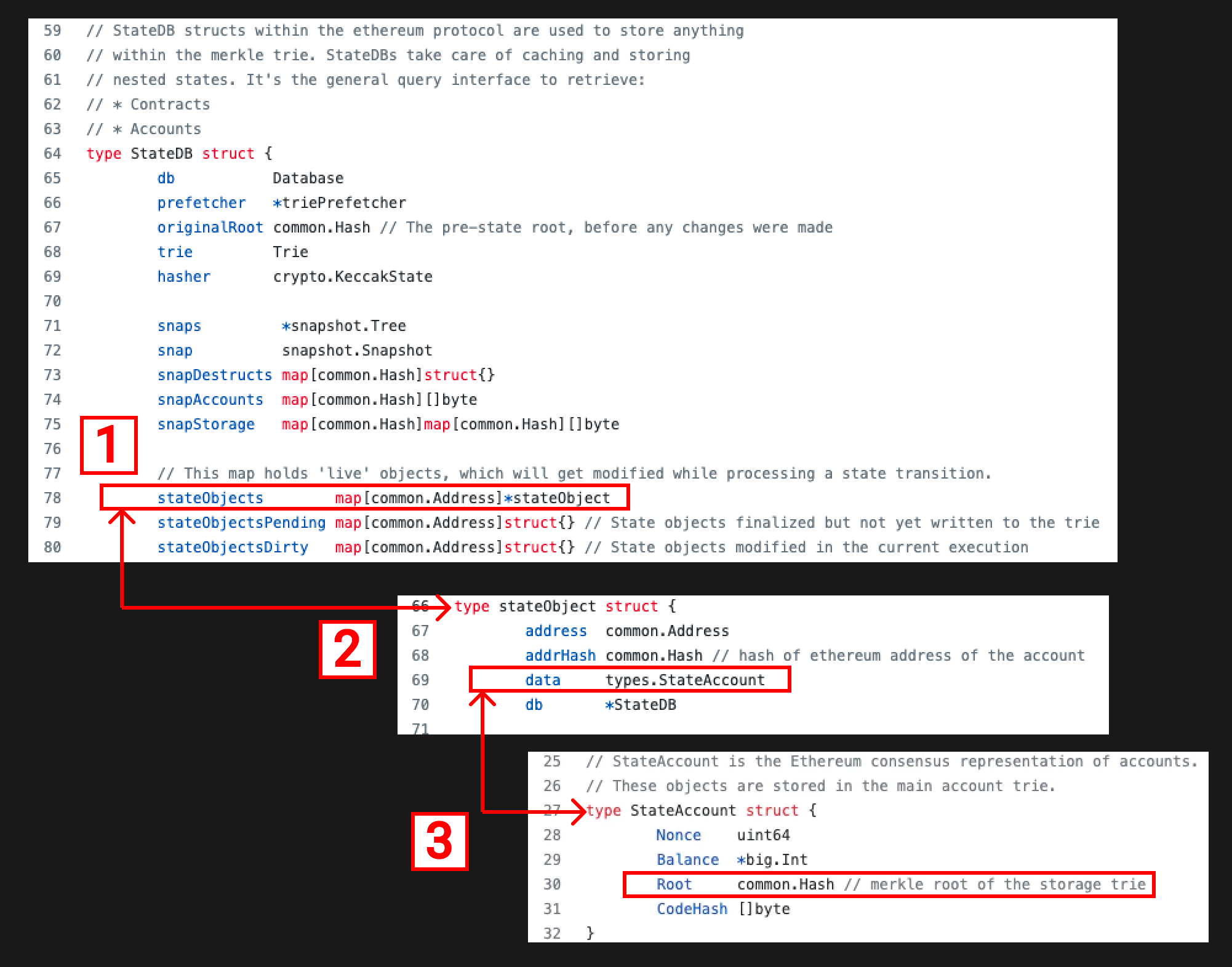 StateDB → stateObject → StateAccount
StateDB → stateObject → StateAccount
- StateDB struct, 我们可以看到它有一个stateObjects字段,是地址到stateObject的映射集(牢记状态根的MPT是地址到以太坊账户的映射,而stateObject是尚未修改的以太坊账户)。
- stateObject struct, 我们可以看到它包含一个StateAccount字段,这是一个代码实现里的中间态。
- StateAccount struct, 现在我们终于看到这个代表以太坊账户的结构了,它的Root字段就是我们之前讨论的存储根。
现在一些令人疑惑的东西逐渐明晰了起来,我们看一看新的以太坊账户,或者说StateAccount是怎么初始化的。
初始化一个以太坊账户
我们需要操作statedb.go以及它的StateDB结构体去创建新的StateAccount。StateDB有一个名为createObject的函数,它会创建一个新的stateObject然后放进去一个空的StateAccount。
下图是代码细节:
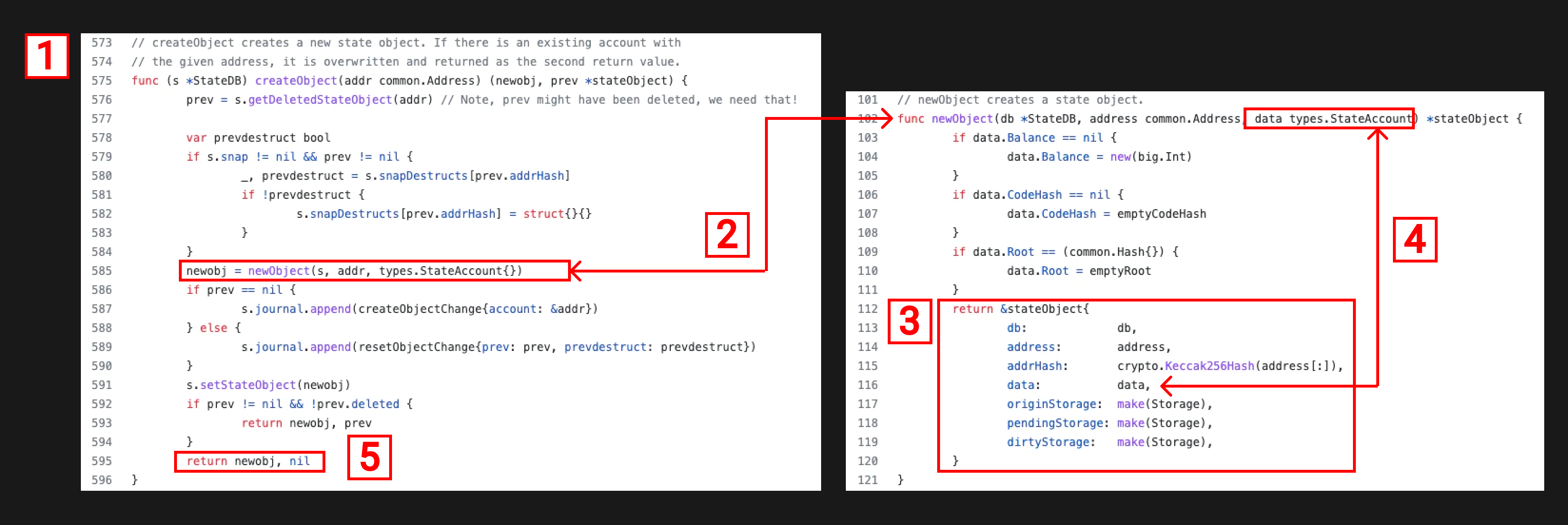
- StateDB有一个 createObject 函数 ,传入一个地址返回一个stateObject。(重申stateObject是一个未修改的以太坊账户)。
- 这个createObject函数调用newObject 函数 ,它传入stateDB,地址和一个空的StateAccount,返回一个stateObject。
- 在newObject函数的返回语句中,我们可以看到有许多字段与stateObject, address, data, dirtyStorage等相关
- tateObject的data映射到空的StateAccount,可以在103-111行看到从nil值转变为初始化空值的过程。
- stateObject被成功创建并带着已经初始化完成的StateAccount(也就是data字段)返回了。
现在我们有了一个空stateAccount,下一步我们存些数据吧,用SSTORE。
SSTORE
在深入了解SSTORE的Geth实现之前我们先回忆一下SSTORE是干什么的。
SSTORE会从栈上弹出两个值,一个32字节的key,一个32字节的value。key决定了value存在哪个插槽里。
下面就是Geth的SSTORE操作的源码,我们看看他做了什么:
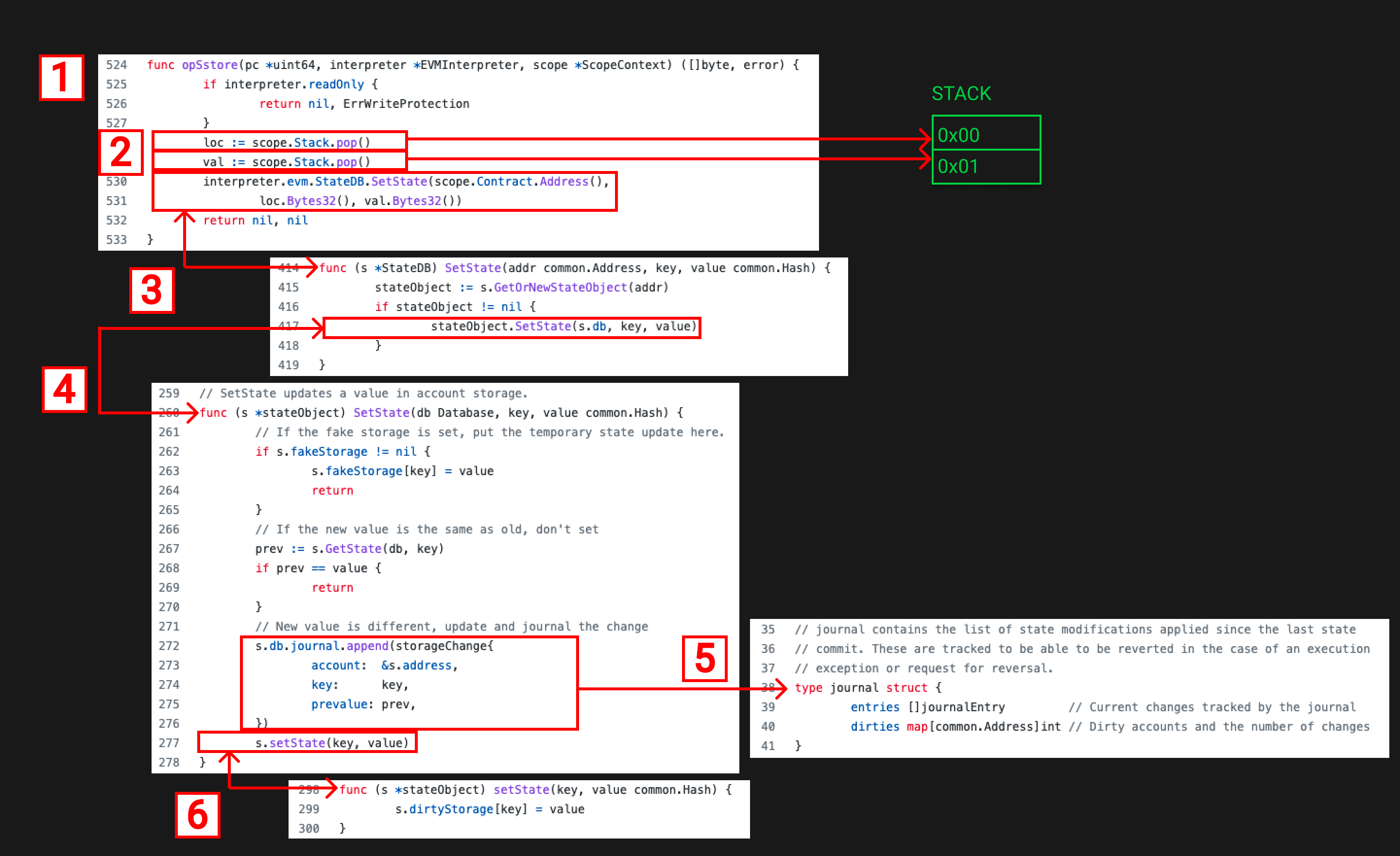
- 我们从 instructions.go开始看,它定义了所有的opcode,在这个文件里我们可以看到opSstore函数。
- 这个函数的入参包括合约上下文信息,例如栈,内存等,我们把两个值弹出栈,标记成loc(location)和val(value)。
- 这两个值被弹出来后作为入参和合约地址一起传进StateDB的SetState 函数,SetState会用合约地址检验合约里是否有stateObject如果没有就创建一个。之后调用stateObject的SetState,传进StateDB,key和value。
- stateObject的SetState 函数对fakeStorage做了检查,看看value是否被改变过,之后运行journal的append函数。
- 如果你阅读journal struct的注释会看到journal是用来跟踪状态的改变(就是保存中间变量),这样它们就可以在执行异常或撤销请求的情况下恢复。
- journal更新之后,调用stateObject的SetState 函数。更新stateObject.dirtyStorage。
现在我们已经更新了stateObject 的 dirtyStorage。而这究竟意味着什么呢?与我们学的东西有什么关系吗?
让我们看看定义dirtyStorage的代码
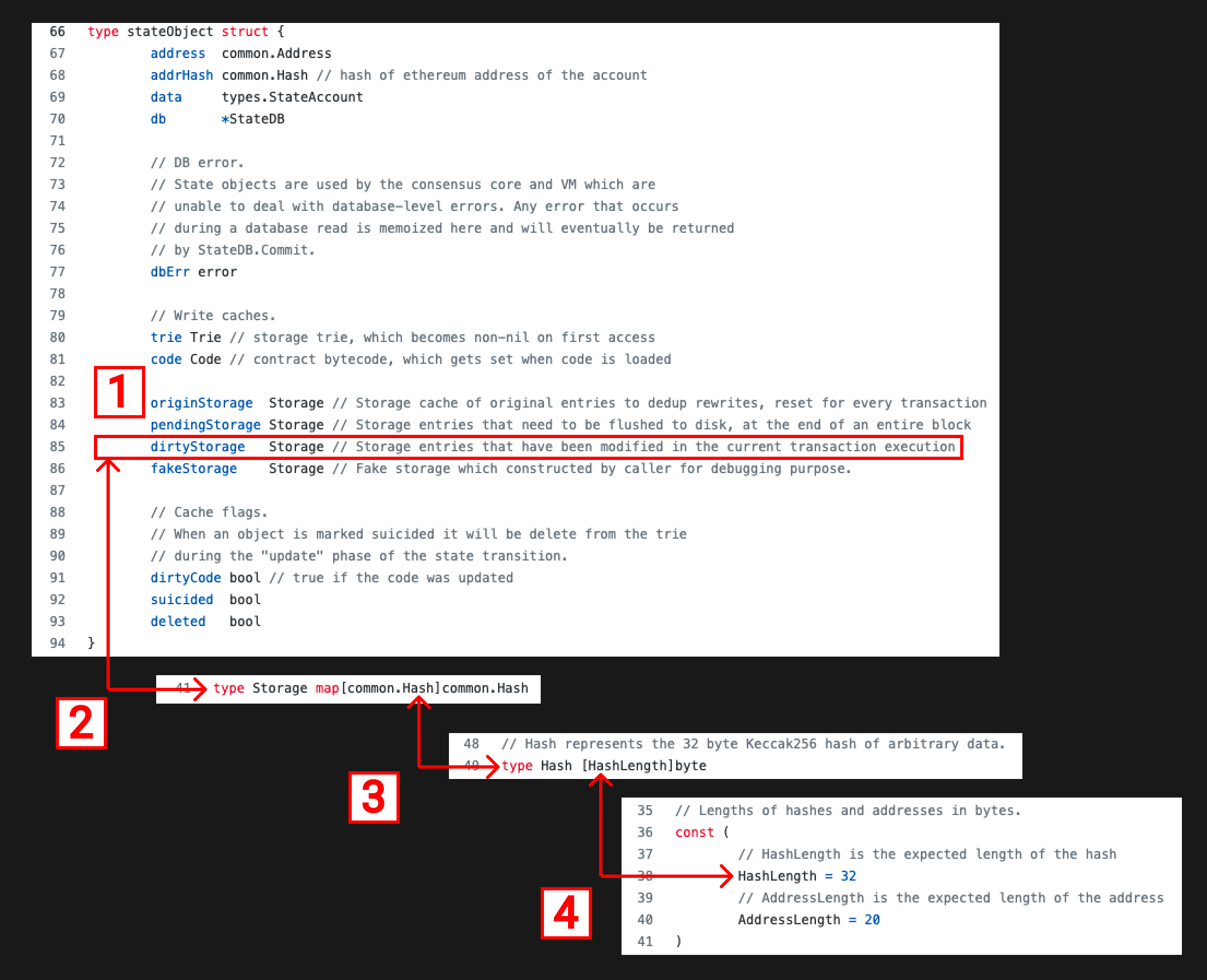 dirtyStorage → Storage → Hash → 32-byte
dirtyStorage → Storage → Hash → 32-byte
- dirtyStorage是在stateObject里定义的,被描述为"在当前事务执行中被修改的存储项"。
- dirtyStorage的类型Storage type是一种从common.Hash到common.Hash的映射。
- Hash type 就是一个长度为HashLength的字节数组
- HashLength是常量,值是32。
32字节key到32字节value的映射对你来说应该很熟悉,这完全就是第三篇我们提到过的合约存储区的概念。你现在可能注意到dirtyStorage字段上边的pendingStorage和originStorage了。他们是有相关性的,dirtyStorage在确定写入的过程中,会复制到pendingStorage,然后在MPT更新时复制到originStorage。MPT更新了之后,StateDB的commit过程中StateAccount的状态根也会更新。会将新的状态写进MPT的底层数据库。
下面轮到最后一个难点,SLOAD。
SLOAD
我们快速回忆一下SLOAD是干什么的:它会把一个32字节的key从栈里弹出来,然后返回key对应的插槽里的值。下面看一下Geth实现SLOAD的代码:
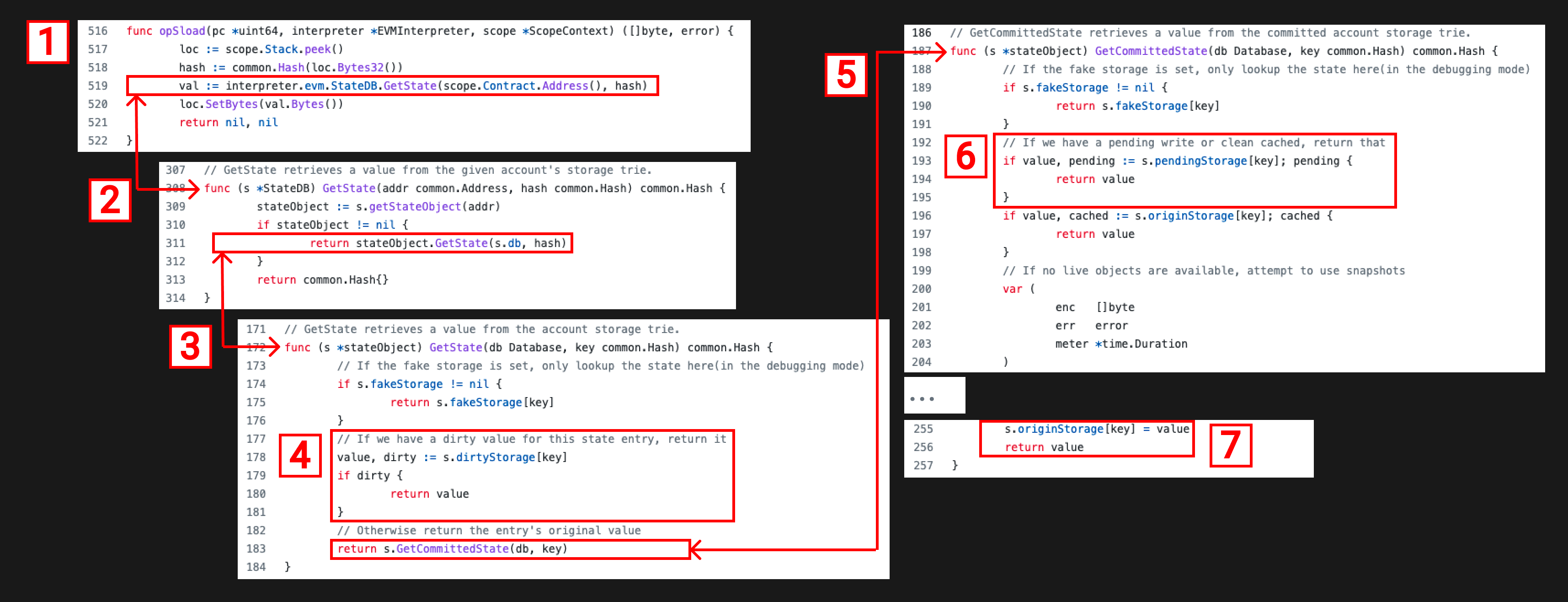
- 我们依然从instructions.go file 开始,找到opSload函数,我们从栈顶获取到了存储插槽。也就是临时变量loc。
- 调用StateDB的GetState函数传入合约地址和存储位置,GetState获得了合约地址对应的stateObject,如果它不为空,则调用stateObject的GetState函数。
- stateObject的GetState函数对fakeStorage和dirtyStorage做检查。
- 如果dirtyStorage存在,则返回key在dirtyStorage映射里的值(dirtyStorage代表着合约的最新状态,所以要最先返回它)。
- 否则将调用GetCommitedState 函数里查询数据,再次检验fakeStorage。在这个函数里完成下面两步。
- 如果pendingStorage存在,则返回key在pendingStorage映射里的值。
- 如果上边的都没有,就检索originStorage里的值并返回。
你会发现函数最先试图返回dirtyStorage,然后依次是pendingStorage和originStorage。这是合情合理的,在运行的过程中dirtyStorage是最新状态,紧接着是pendingStorage和originStorage。一个交易可能多次改变同一个插槽的数据所以我们必须保证拿到的是最新的值。
让我们设想在同一笔交易里,SLOAD之前在同一个插槽发生了SSTORE操作,在这种情况下dirtyStorage是被SSTORE更新过的,SLOAD返回的正应该是它。
现在您已经了解了Geth是如何实现SSTORE和SLOAD的。它们如何与状态和存储区交互,以及如何更新插槽与世界状态相关的知识。
这篇文章的强度很大但是你坚持下来了,我猜这篇文章会让你的问题比刚开始更多了,但这正是加密世界的乐趣不是吗?
只要功夫深,铁杵磨成针!





