Web3系列教程之进阶篇---7. IPFS
- 李留白
- 发布于 2022-08-19 17:16
- 阅读 6516
了解以太坊生态系统,这样你就不会每次都重新发明轮子。使用Chainlink, ENS, The Graph, IPFS, Ceramic, Polygon, NEAR等开发吧!
IPFS 代表星际文件系统。它是一个分布式的点对点网络,用于存储和共享文件、网站、应用程序等。它最初于 2015 年发布,由Protocol Labs 开发。
要了解 IPFS 的作用以及它为何如此重要,我们需要一些关于当今如何在 Internet 上存储和检索文件的历史课程。
数据识别和检索
想象一下,你想买一本关于以太坊的书。你问你的朋友,Alice和Bob,他们已经在这个领域工作了几年,你在哪里可以找到一本关于以太坊的好书。
他们给你以下答案:
Alice: 去滑铁卢大学附近滑铁卢大学大道上的小书店,上到三楼,到科技区,在第4个书架上找到第3本书。
Bob: 查看《掌握以太坊》。它的 ISBN 号为 9784873118963
如果您的目标是获得这本书的副本,那么按照这里的每条说明,您觉得自己得到了想要的东西有多大信心?
感谢ProtoSchool对这个例子的启发。
位置与内容寻址
我们可以通过两种方法来识别数据。第一个是基于位置的寻址,第二个是基于内容的寻址。
位置寻址
在上面的例子中,Alice对你问题的回答是一个基于位置的寻址的例子。它将我们指向数据被某个实体存储的位置(物理或数字)。Alice知道书店在那个特定的位置有那本书,并希望他们不要把它拿下来或移到另一个地方。
基于位置的寻址是我们在中心化 Web 上识别 Web2 中数据的方式。例如,我知道过去比特币白皮书存储在https://bitcoin.org/bitcoin.pdf. 如果我把你指向那个位置,那是基于一种信念,即他们没有把那份白皮书转移到其他地方,并继续在同一地点提供服务。虽然,它很可能在那个位置托管以太坊白皮书,尽管托管它的机构是bitcoin.org,而且文件名bitcoin.pdf暗示了与比特币有关的东西。
归根结底,托管在中心化网络上的文件内容与它们基于位置的地址没有关系。给定某条数据,我们没有办法猜测它在互联网上的存储位置。我们无法知道它被托管在哪个域名上,谁在托管它,或者它被存储为哪个文件名。
位置寻址的缺点
在中心化网络中,由于我们无法验证哪些内容存在于什么位置,因此我们依赖于中央机构来标记和存储信息的真实情况。正因为如此,我们很容易被坏演员欺骗。您是否下载过被证明是病毒的视频或游戏?
此外,位置寻址意味着相同的数据可以以不同的文件名存储在不同的位置数千或数百万次,这几乎是无用的。
你有没有在你的电脑上保存过download.pdf和download(1).pdf?
由于内容不直接与位置挂钩,中心化的网络是非常混乱的,这些数据在不同的URL上以不同的名字被重复保存多次,而且没有办法分辨哪些项目是相同的。
内容寻址 - 深入探讨
在去中心化的网络上,我们可以停止依赖中央机构来标记信息,并希望我们下载的数据不是恶意的。
事实上,我们都可以使用比基于位置的寻址更安全的不同类型的寻址(特别是内容寻址)来托管彼此的数据。
散列
内容寻址所需的最重要技术是加密哈希。我们将稍微介绍一下哈希函数的属性,但如果您想更深入地了解它们的工作原理以及它们背后的数学原理,您可以阅读上述链接。
散列是一个过程,在该过程中,称为散列函数的函数接受任意输入并生成唯一表示输入的单个、固定大小的“散列”。
我们可以用数学方法将其表示如下:
H(a) = b其中H是散列函数,a是输入,b是输出散列。
有一些重要的属性使哈希函数变得非常重要:
- 对于一个给定的哈希函数,无论输入的a有多小或多大,b的输出大小总是相同的。
- 输出哈希值总是唯一的。如果输入有一个比特的变化,输出哈希值将完全改变。为了检查两个输入是否相同,你可以比较它们的哈希值。如果哈希值匹配,则输入一定匹配。
注意:这就是密码在数据库中的存储方式。需要登录的 Web 应用程序不会将您的密码直接存储在数据库中。它们存储数据库的哈希值。当有人尝试登录时,他们的密码使用相同的散列函数进行散列,并且散列与存储在数据库中的散列相匹配。
- 一个散列函数不可能逆转。这意味着,鉴于散列函数H和输出的散列值b,你无法找出a是什么。但是,如果你有a,你可以很容易地检查它输出b。
起初,这似乎有点不直观。如果输出哈希值总是一个固定的大小,但输入可以是任意大的,我们怎么能保证输出的唯一性?将此作为研究散列函数安全性的一个练习,并深入挖掘它。
我们现在不会深入研究散列,但我会说散列是一种概率保证。并不是 100% 保证每个散列都是唯一的,但是找到两个输出相同散列的单独输入的概率非常低。
事实上,如果您能够在 SHA-2 等现代散列函数上找到两个给出相同输出散列的输入,那么恭喜!您破坏了该哈希函数的安全性。如果您可以研究这些输入并提出一个通用公式来重复执行此操作,您将获得世界上最大的漏洞赏金!整个比特币网络都是你的 :)
回到内容寻址和散列。
由于散列给出了唯一的、固定大小的输出,无论输入数据的大小如何,我们实际上都可以使用输出散列作为数据本身的唯一标识符。因此,我们有一种方法可以通过一个唯一的 ID 来引用任意数据,该 ID 可以通过一个散列函数从数据本身派生而来。
信任影响
如前所述,在集中式网络上,我们已经开始信任某些中央机构来托管我们的大部分数据。但是,恶意行为者有时可以通过欺骗位置来欺骗我们了解文件的内容。
在去中心化的网络上,我们可以消除对中央机构的信任,每个人都可以托管彼此的文件。由于通过散列进行内容寻址,如果我们根据散列查找和识别文件,没有人可以欺骗任何人了解文件的内容。如果恶意行为者在任何文件中更改了一个位,它的哈希值就会改变,我们不会在寻找那个文件。
点对点
但是我们实际上从哪里获取数据呢?如果您曾经使用过 Torrent,这听起来很熟悉,但从某种意义上说,您也可以将其与以太坊的数据共享方法联系起来。
假设您正在寻找一个特定的文件,并且您拥有它的内容哈希。我们不是要求一个权威机构给我们那个文件,而是要求整个网络!
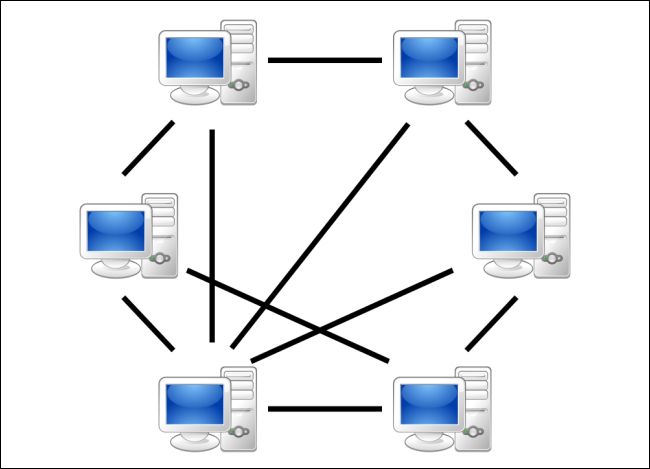
您的请求将通过您直接连接的节点、它们连接的其他节点等共享 - 直到您找到拥有您正在寻找的内容的人。
您将知道它正是您要查找的文件,因为它具有匹配的哈希值。此外,如果该节点在处理请求时脱机,您仍然可以从另一个也具有该内容的节点获取该文件的副本。
IPFS
现在我们了解了内容寻址,让我们再看看 IPFS。
IPFS 是一个分散的节点网络,用于存储和共享文件。IPFS 上的文件是内容寻址的,每个文件都是根据其内容哈希来识别的。此内容散列称为CID -a Content ID。使用 IPFS 时,您经常会听到“IPFS CID”一词。
任何人都可以运行 IPFS 节点并将文件上传到该节点。该节点将对这些文件进行哈希处理,并将其 CID 公开给网络的其余部分。如果其他人对该内容感兴趣,他们可以请求该 CID 的内容,最终该请求将到达您的节点,然后您可以为他们的请求提供服务。
此外,对于重要数据,任何人都可以在自己的 IPFS 节点上存储某些数据的副本,以在某些节点脱机的情况下改进复制。因此,IPFS 上的数据可以通过复制实现高可用性。
最后要注意的一件重要事情是 IPFS 上的数据是不可变的,这意味着它无法更新。由于文件由其 CID 表示,因此这些文件在上传后无法修改。您可以上传新的修改版本,但由于散列函数的唯一性,该版本的 CID 与原始版本不同。
IPFS 提供者
运行您自己的 IPFS 节点可能看起来很费力。类似于不是很多 dApp 构建者运行自己的以太坊节点,而是使用 Infura、Alchemy 或 Quiknode 的节点来构建他们的应用程序,您也可以使用 IPFS 的节点提供程序。
Pinata和Textile是一些流行的 IPFS 节点提供商。与以太坊节点提供商类似,您可以在这些平台上创建一个帐户来访问 IPFS 节点,以存储和检索存储在网络上的数据。
IPFS 网关
IPFS 节点还可以选择公开一个公共网关,允许 web2 用户访问存储在 IPFS 上的文件。
Protocol Labs 团队与 Cloudflare 等其他组织一起运行公共 IPFS 网关。
协议实验室 IPFS 网关位于https://ipfs.io/.
这是一些 IPFS 文档,托管在 IPFS 本身上。您可以通过访问此链接从公共网关访问它 - https://ipfs.io/ipfs/QmTkzDwWqPbnAh5YiV5VwcTLnGdwSNsNTn2aDxdXBFca7D/example
是否要公开公共网关取决于节点运行者。打开公共网关确实意味着用户可以使用您的节点从网络中获取和检索任意数据,这会增加运行节点的流量和带宽成本,因此您可以选择不打开它。Pinata 和 Textile 等提供商允许您选择是否要公开公共网关。
IPFS 用例
IPFS 有很多用例。因为它是一个去信任的、去中心化的、冗余的数据存储——它有很多含义。没有审查制度,没有人控制网络。
建立开放的无边界知识库
某些国家、组织或当局禁止或审查来自集中式网络的某些类型的数据。多亏了去中心化的网络,我们可以建立开放和无边界的信息知识库,任何中央机构都无法审查或控制。
这对于生活在高度权威的国家或州的公民特别有用,在这些国家或州,中央网络上无法广泛获取信息。
数据市场
同样来自 Protocol Labs 的 Filecoin 等项目扩展了 IPFS 网络,包括对数据存储者的激励。您只需支付在 AWS 等集中式云提供商中托管数据的一小部分成本,就可以向 Filecoin 网络的矿工支付费用来托管您的数据。为了换取数据可用性的保证,你用 $FIL 代币支付它们,并以比中心化解决方案更便宜的方式获得去中心化且可靠的数据存储网络。
NFT 元数据
最近,IPFS 上的去中心化 NFT 元数据一直是趋势。在 NFT 的早期,NFT 将元数据托管在中央服务器上。事实上,即使在我们的 Sophomore NFT Collection 教程中,我们也要求您构建一个 API 端点来提供 NFT 元数据。
这是有问题的,因为 NFT 项目的开发人员可以替换该元数据,或者他们的服务可能会出现故障,从而基本上搞砸了整个项目。通常用于此的术语是“rugpull”——开发人员从用户下方拉出一块地毯。
在这个空间发生了几次之后,人们开始使用 IPFS 作为元数据存储的替代方案,因为一旦元数据存储在 IPFS 上,任何人都可以创建内容的副本,并且 IPFS 上的数据不能真正删除,除非甚至没有单个节点不再具有该内容的副本。
托管大型数据集
许多组织拥有庞大的数据集。当我说巨大时,我的意思是像 PB 级的数据。想要公开构建的公司可以依靠 IPFS 来分散这些数据的存储,并使数据在世界各地都可以轻松访问。
离线数据共享
由于 IPFS 是对等协议,因此可以将其配置为在各种传输协议上工作。到目前为止,我们一直假设 IPFS 上的数据是通过 HTTP(S) 协议传输的,这需要互联网连接。但是,您可以将 IPFS 配置为通过蓝牙、无线电信号或其他类型的信号工作。这在受灾地区或低连接性地区非常有用,可以在缺乏互联网访问的社区内实现数据共享。
托管去中心化网站
在文章的开头,我们提到 IPFS 可以托管网站。什么是网站?它们只是几个文件的组合——HTML、CSS 和 JavaScript。您可以将它们全部托管在 IPFS 上,并最终获得一个 CID。您可以通过公共 IPFS 网关访问该 CID,并呈现给完全在去中心化互联网上运行的网站。
Random Planet Facts是一个示例网站,由 IPFS 团队创建,完全在 IPFS 网络上运行,而不是托管在 Google 或 AWS 等中央云提供商上。
IPFS 用例还有更多示例。无论如何,这不是一份详尽的清单。
Protocol Lab 的网站上列出了更多用例示例,您可以在此处找到。
结论
随着我们从中心化权威转向去中心化,IPFS 确实是分布式网络的基本组成部分。我们希望这篇文章能对您有所启发,并帮助您了解去中心化数据存储背后的动机。
随着我们的前进,我们将做一个使用 IPFS 在以太坊上存储 NFT 元数据的实际示例。






