批量编译智能合约过程记录
- oacia
- 发布于 2023-03-20 23:27
- 阅读 3908
这两天的区块链研究我的任务是要把大约五万个智能合约的源码编译成字节码的形式,并且提取智能合约中所用到的公开库,过程中遇到了一些困难,当然也是有收获的,所以在这个任务做完之后,写了这篇文章记录一下
这两天的区块链研究我的任务是要把大约五万个智能合约的源码编译成字节码的形式,并且提取智能合约中所用到的公开库,过程中遇到了一些困难,当然也是有收获的,所以在这个任务做完之后,写了这篇文章记录一下
0x01 初步分析
我们需要批量编译的智能合约所在的文件夹结构如下
├─0x01ea1afecdab69ab00212e6f9ed0209c0bf75ac9
│ code.abi
│ code.sol
│ contract_creation_code
│ info
│
├─0x01eacc3ae59ee7fbbc191d63e8e1ccfdac11628c
│ code.abi
│ code.sol
│ contract_creation_code
│ info子文件分析
-
0x01ea1afecdab69ab00212e6f9ed0209c0bf75ac9合约地址 -
code.abi智能合约的ABI文件 -
code.sol智能合约的源码 -
contract_creation_code这是一个空文件,暂未发现该文件的其他内容 -
info储存了合约编译过程中所需要的变量名info文件的内容如下GasToken2//GasToken2为智能合约的合约名称,由于在code.sol文件中不止有一个contract,所以这个名称是十分重要的 v0.4.16+commit.d7661dd9//编译器的版本 0 200
0x02 提取公开库与编译智能合约的实现方式思考
如何提取智能合约中所用到的公开库?
通过对code.sol进行分析,我们发现只有极少的公开库使用了import这一公开库的调用方式,例如以下形式:import "./SafeMath.sol";
而绝大多数的智能合约源代码调用公开库的方式都是通过将公开库的代码直接复制到智能合约源代码内,然后在同一个.sol中进行调用,示例如下
pragma solidity ^0.4.25;
/**
* @title SafeMath
* @dev Math operations with safety checks that throw on error
*/
library SafeMath {
//...公开库代码
}
contract AuctionPotato {
using SafeMath for uint256; //调用公开库
//...智能合约的源代码
}而公开库前的类型定义符共有三种,分别是library,contract和interface
所以我们便可以顺理成章的使用正则表达式提取所有上述关键词后库的名称
然而我们提取到这些库的名称之后,要怎么知道这些库是公开库呢?要知道定义主合约例如上述示例中的AuctionPotato前面的关键字也是contract呀
这时我想到openzeppelin-contracts不是保存了绝大多数智能合约的公开库吗?那我判断提取到的合约名称是否在公开库名称的列表中,不就可以知道这个是不是公开库了嘛
实现如下
import os
import re
def ReadLibraryName():
LibraryPath = r"E:\solidity\智能合约Library的识别和相似度分析\openzeppelin-contracts-master\contracts"
L = []
for dirpath, dirnames, filenames in os.walk(LibraryPath):
for file in filenames:
if os.path.splitext(file)[1] == '.sol':
L.append(os.path.join(os.path.splitext(file)[0]))
return L
LibratyName = ReadLibraryName()# 读取公开库名称
try:
with open(f"{DataDir}\\{ContractAddress}\\code.sol", 'r') as f:
src = f.readlines()
except Exception as e:
# print(f"error during read file!{str(e)}, at {ContractAddress}")
continue
if len(src[0]) > 100:
continue
# print(ContractAddress)
# print(src[0])
openSource = []
for line in src:
matchLib = re.search(r"^library\s+(\w+)\s*", line)# 定义为library类型的库
if matchLib:
T = matchLib.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")
matchContract = re.search(r"^contract\s+(\w+)\s*", line)# 定义为contract类型的库
if matchContract:
T = matchContract.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")
matchInterface = re.search(r"^interface\s+(\w+)\s*", line)# 定义为interface类型的库
if matchInterface:
T = matchInterface.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")如何批量编译智能合约并生成字节码?
这五万多个智能合约,每个合约所需的编译版本都不相同,所以直接用solc命令去编译毫无疑问是会报错的
这时,我发现python中的solcx可以切换solc版本并进行相应的编译
solcx安装
pip install py-solc-x然后在项目中使用import solcx就可以直接使用了
想要批量编译智能合约,我们需要知道的信息有
- 编译器的版本
- 所编译的智能合约名称
很幸运,我们需要的这两个信息在info文件中都含有了,所以我们只要读取info中的信息即可
with open(f"{src_folder}\\info", 'r') as f:
str = f.readlines()
# print(str)
contract_name = str[0].strip()
match = re.search(r'v(\d+\.\d+\.\d+)', str[1])
if match:
version = match.group(1)
# print(version)如果说没有info内文件的信息的话,我们也可以直接在code.sol文件中提取出编译版本
示例如下
import re
for line in src:
matchVersion = re.search(r"^pragma solidity.*(\d+\.\d+\.\d+)", line)
if matchVersion:
Version = matchVersion.group(1)故批量编译智能合约并生成字节码的代码如下
def bytecodeMaker(ContractAddress):
src_folder = f".\\etherscan\\{ContractAddress}"
dst_folder = f".\\output\\{ContractAddress}"
with open(f"{src_folder}\\info", 'r') as f:
str = f.readlines()
# print(str)
contract_name = str[0].strip()
match = re.search(r'v(\d+\.\d+\.\d+)', str[1])
if match:
version = match.group(1)
# print(version)
with open(f"{src_folder}\\code.sol", "r") as file:
code = file.read()
# 编译合约
install_solc(version)# 选择编译器版本
compiled_sol = compile_standard(
{
"language": "Solidity",
"sources": {"code.sol": {"content": code}},
"settings": {
"outputSelection": {
"*": {"*": ["abi", "metadata", "evm.bytecode", "evm.sourceMap"]}
}
},
},
solc_version=version,
)
bytecode = compiled_sol["contracts"]["code.sol"][contract_name]["evm"]["bytecode"]["object"]
# print(bytecode)
# with open(f"{dst_folder}\\bytecode", 'w') as f:
# f.write(bytecode)
return bytecode0x03 执行过程中的问题
当我的代码写好之后,我发现在处理八千多份合约左右的时候,程序将会报错并无法正常的进行后续的处理,报错内容为[Errno24] Too many open files
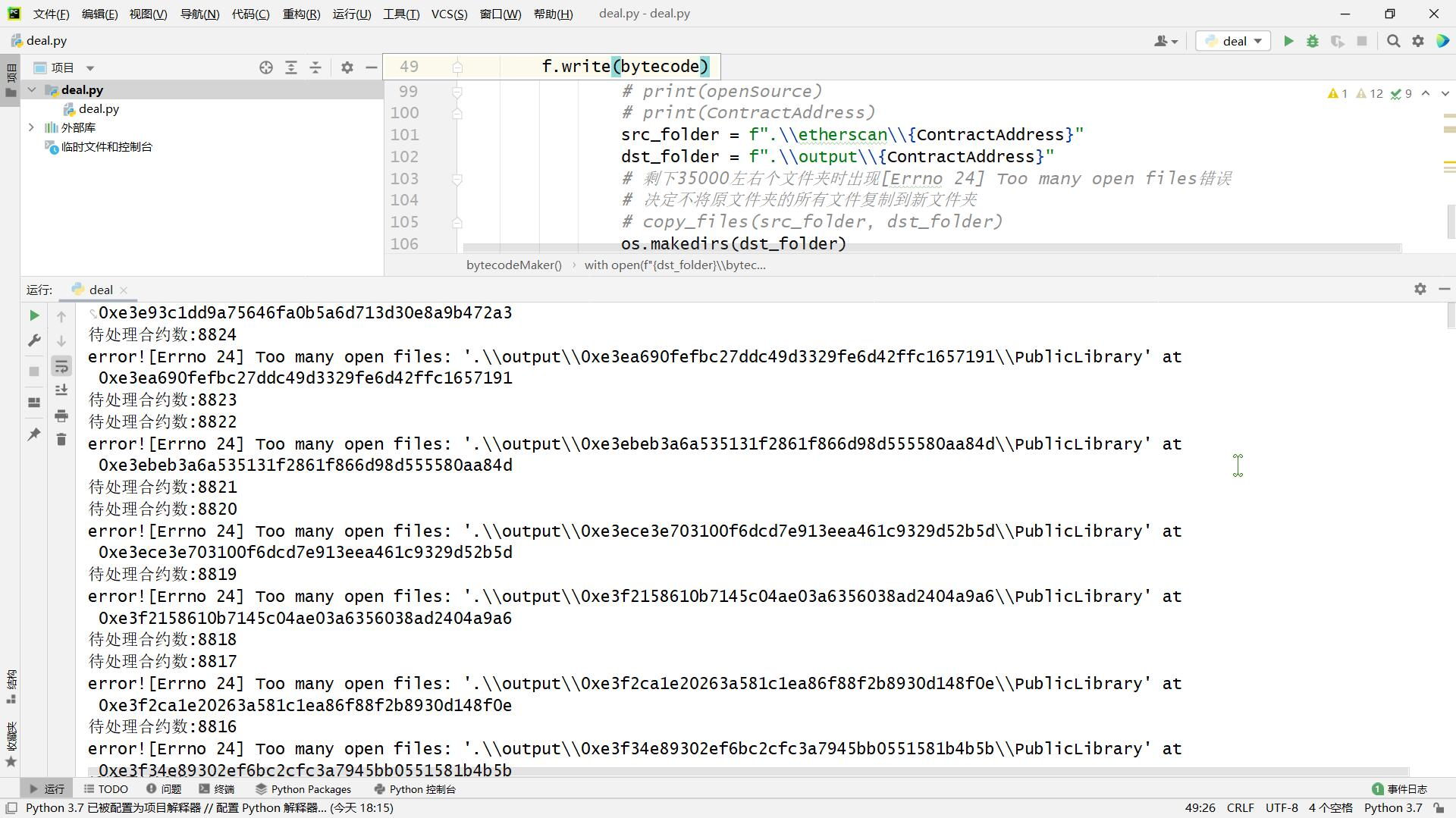 在网上查阅了很多资料,但是都大相径庭的表示是打开文件后没有正常的关闭,但是我反复研究代码,发现自己打开文件的操作用的都是
在网上查阅了很多资料,但是都大相径庭的表示是打开文件后没有正常的关闭,但是我反复研究代码,发现自己打开文件的操作用的都是with open,根本不可能出现这种情况
最终通过打印进程打开的所有文件才明白是solc的问题
def printProess():
# 获取当前进程的ID
pid = psutil.Process().pid
# 获取进程句柄信息
process = psutil.Process(pid)
open_files = process.open_files()
# 打印打开的文件句柄信息
print(f"已打开的句柄数量{len(open_files)}")
for file in open_files:
print(file.path)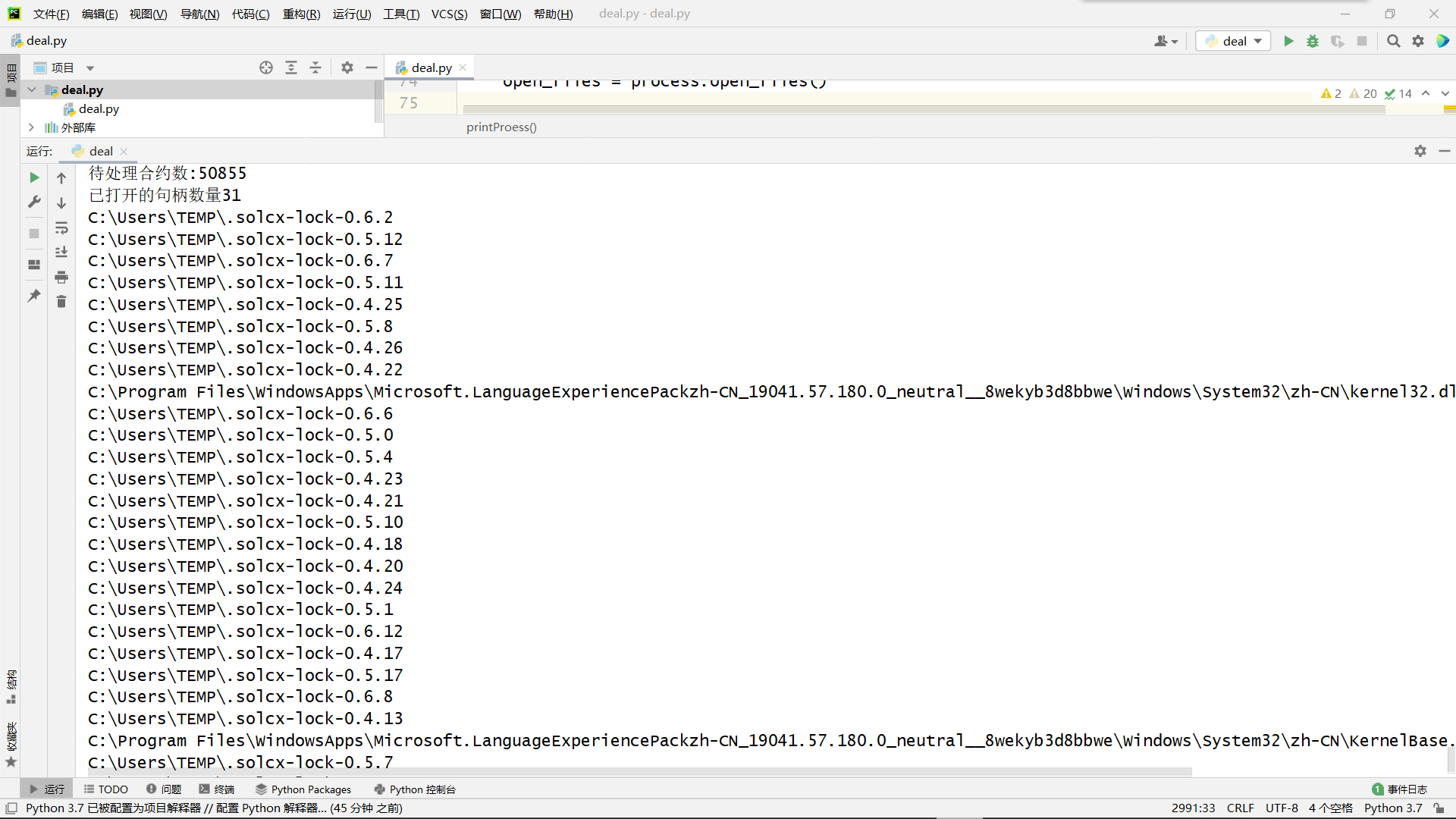 但是我在StackOverflow搜索了很久,都不知道python需要使用什么命令来关闭打开的文件,几乎所有的提问和解答都是关于如何关闭进程的,即使用
但是我在StackOverflow搜索了很久,都不知道python需要使用什么命令来关闭打开的文件,几乎所有的提问和解答都是关于如何关闭进程的,即使用process.kill()来终止进程
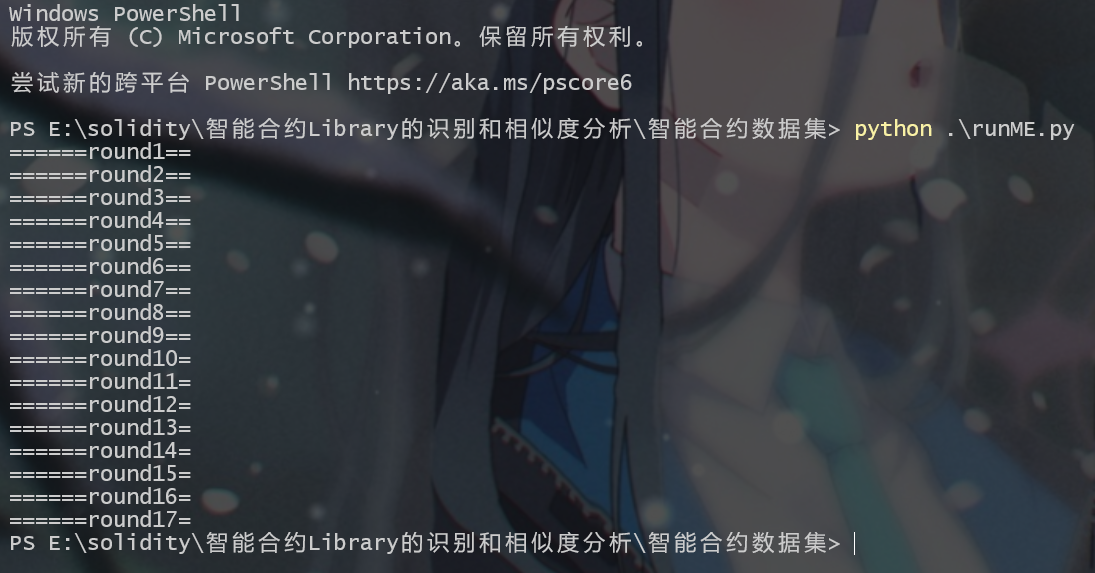
终于,经过下午的研究,我发现可以使用命令行来分批次的编译大量的智能合约
于是很快我写出了主体代码
# runME.py
import os
DataDir = r".\etherscan"
DataDir_sum = len(os.listdir(DataDir))
step = 3000# 一次处理3000个合约
round=0
for startPos in range(0, DataDir_sum, step):
round=round+1
print(f"======round{round}======")
endPos = startPos + step
if endPos < DataDir_sum:
os.system(f"python .\deal.py {startPos} {endPos}")
else:
os.system(f"python .\deal.py {startPos} {DataDir_sum}")
当然也需要在deal.py中增添接受命令行参数的语句
# deal.py
if len(sys.argv) != 3:
print('please enter 2 argv!')
exit(-1)
startPos, endPos = sys.argv[1:3]
startPos, endPos = int(startPos), int(endPos)0x04 处理完成
完整代码如下
# deal.py
import os
import re
from solcx import compile_standard, install_solc
import sys
def ReadLibraryName():
LibraryPath = r"E:\solidity\智能合约Library的识别和相似度分析\openzeppelin-contracts-master\contracts"
L = []
for dirpath, dirnames, filenames in os.walk(LibraryPath):
for file in filenames:
if os.path.splitext(file)[1] == '.sol':
L.append(os.path.join(os.path.splitext(file)[0]))
return L
def bytecodeMaker(ContractAddress):
src_folder = f".\\etherscan\\{ContractAddress}"
dst_folder = f".\\output\\{ContractAddress}"
with open(f"{src_folder}\\info", 'r') as f:
str = f.readlines()
# print(str)
contract_name = str[0].strip()
match = re.search(r'v(\d+\.\d+\.\d+)', str[1])
if match:
version = match.group(1)
# print(version)
with open(f"{src_folder}\\code.sol", "r") as file:
code = file.read()
install_solc(version)
compiled_sol = compile_standard(
{
"language": "Solidity",
"sources": {"code.sol": {"content": code}},
"settings": {
"outputSelection": {
"*": {"*": ["abi", "metadata", "evm.bytecode", "evm.sourceMap"]}
}
},
},
solc_version=version,
)
bytecode = compiled_sol["contracts"]["code.sol"][contract_name]["evm"]["bytecode"]["object"]
# print(bytecode)
# with open(f"{dst_folder}\\bytecode", 'w') as f:
# f.write(bytecode)
return bytecode
def copy_files(src_folder, dst_folder):
os.makedirs(dst_folder)
for root, dirs, files in os.walk(src_folder):
for file in files:
src_file = os.path.join(root, file)
dst_file = os.path.join(dst_folder, os.path.relpath(src_file, src_folder))
# print(dst_file)
# print(os.path.dirname(dst_file))
# shutil.copy2(src_file, dst_file)
with open(src_file, 'r') as f:
text = f.read()
with open(dst_file, 'w') as f:
f.write(text)
if len(sys.argv) != 3:
print('please enter 2 argv!')
exit(-1)
startPos, endPos = sys.argv[1:3]
startPos, endPos = int(startPos), int(endPos)
LibratyName = ReadLibraryName()
# print(LibratyName)
DataDir = r".\etherscan"
DataDir_sum = endPos - startPos
# print(DataDir)
for i in range(startPos, endPos):
ContractAddress = os.listdir(DataDir)[i]
print(f"待处理合约数:{DataDir_sum}\x1B[1A\x1B[K")
DataDir_sum = DataDir_sum - 1
try:
with open(f"{DataDir}\\{ContractAddress}\\code.sol", 'r') as f:
src = f.readlines()
except Exception as e:
# print(f"error during read file!{str(e)}, at {ContractAddress}")
continue
if len(src[0]) > 100:
continue
# print(ContractAddress)
# print(src[0])
openSource = []
for line in src:
matchLib = re.search(r"^library\s+(\w+)\s*", line)
if matchLib:
T = matchLib.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")
matchContract = re.search(r"^contract\s+(\w+)\s*", line)
if matchContract:
T = matchContract.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")
matchInterface = re.search(r"^interface\s+(\w+)\s*", line)
if matchInterface:
T = matchInterface.group(1)
if T in LibratyName:
openSource.append(T)
# print(f"{T},{ContractAddress}")
# print(openSource)
if openSource:
# print(openSource)
# print(ContractAddress)
src_folder = f".\\etherscan\\{ContractAddress}"
dst_folder = f".\\output\\{ContractAddress}"
try:
bytecode = bytecodeMaker(ContractAddress)
except Exception as e:
# print(f"error during bytecode!{str(e)}, at {ContractAddress}")
continue
copy_files(src_folder, dst_folder)
with open(f"{dst_folder}\\PublicLibrary", 'w') as ff:
ff.write(str(openSource))
with open(f"{dst_folder}\\bytecode", 'w') as ff:
ff.write(str(bytecode))
处理完成!
0x05 有趣的小知识
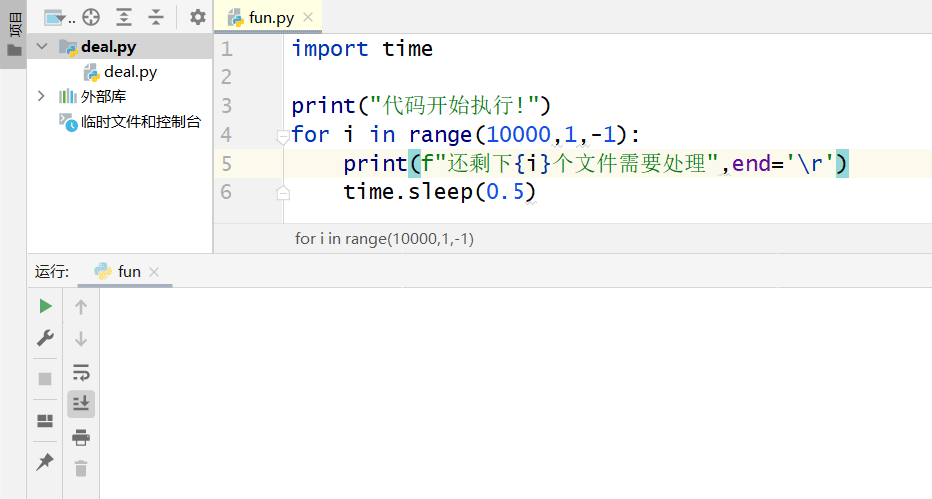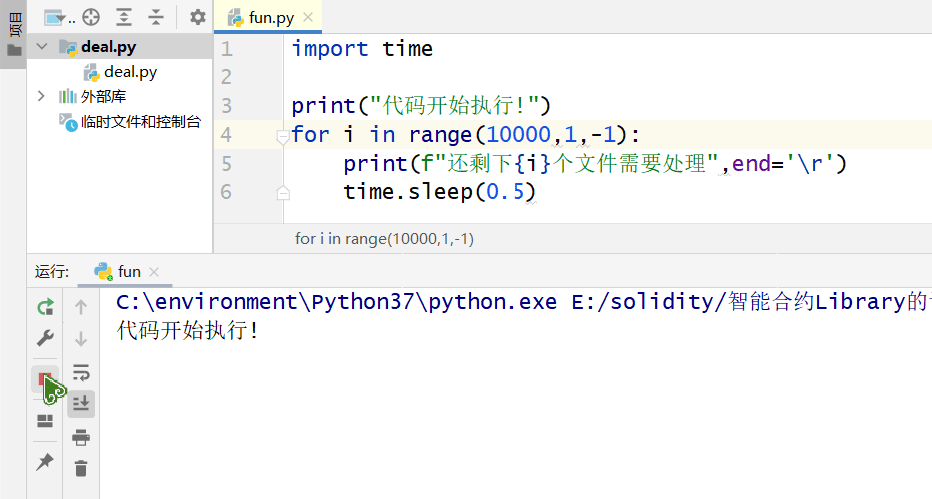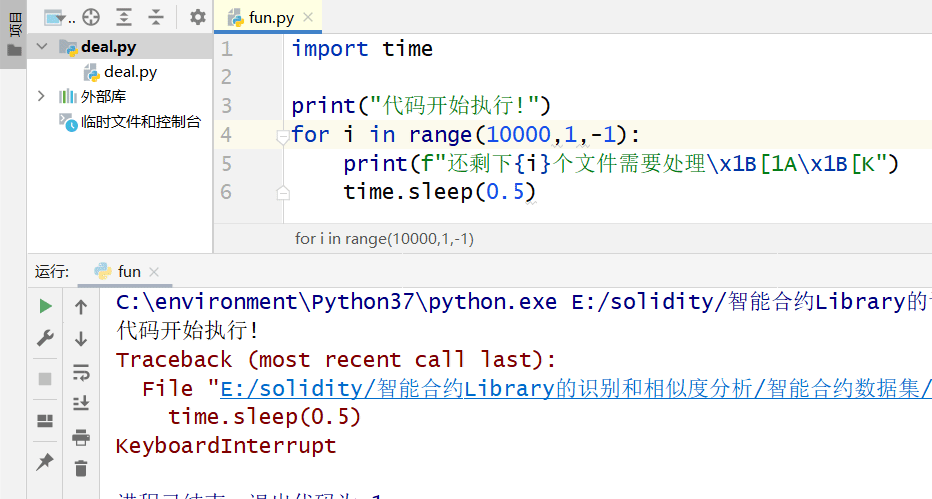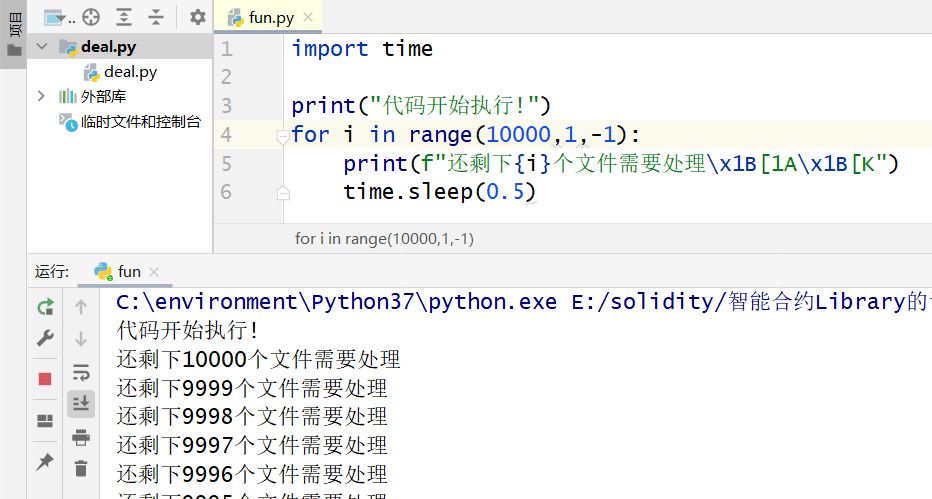
当我想要知道还剩下多少文件需要处理的时候,总是苦于输出的刷屏
比如下面的代码
import time
print("代码开始执行!")
for i in range(10000, 1, -1):
print(f"还剩下{i}个文件需要处理")
time.sleep(0.5)
这样输出会导致刷屏看起来十分不舒服
但是我们只要在输出后面加上\x1B[1A\x1B[K
变成下面这种形式
import time
print("代码开始执行!")
for i in range(10000,1,-1):
print(f"还剩下{i}个文件需要处理\x1B[1A\x1B[K")
time.sleep(0.5)这样就没有刷屏的困扰了
 至于原理使用的是 ANSI 终端控制序列
至于原理使用的是 ANSI 终端控制序列
\x1b[nA表示光标上移\x1b[2K表示擦除当前行
所以\x1B[1A\x1B[K组合起来就能把这一行清除啦
或者网上还有方法可以用下面的代码
import time
print("代码开始执行!")
for i in range(10000,1,-1):
print(f"还剩下{i}个文件需要处理", end='\r')
time.sleep(0.5)同样可以实现刷新当前行的操作
但是令我感到奇怪的是,无论是\x1B[1A\x1B[K还是end='\r',都无法在pycharm中刷新当前行
 终于我发现了完美的刷新输出行的方式!
终于我发现了完美的刷新输出行的方式!
就是这种写法
import time
print("代码开始执行!")
for i in range(10000,1,-1):
print(f"\r还剩下{i}个文件需要处理",end='')
time.sleep(0.5)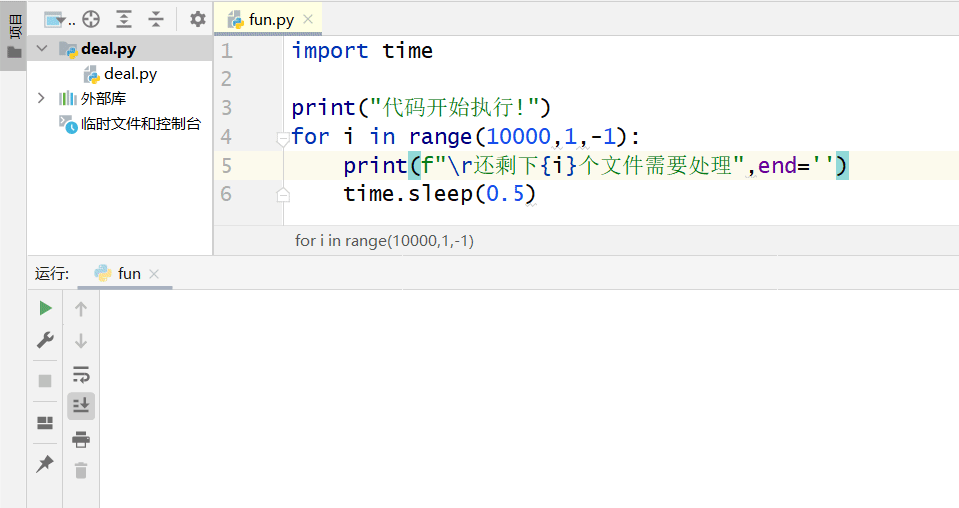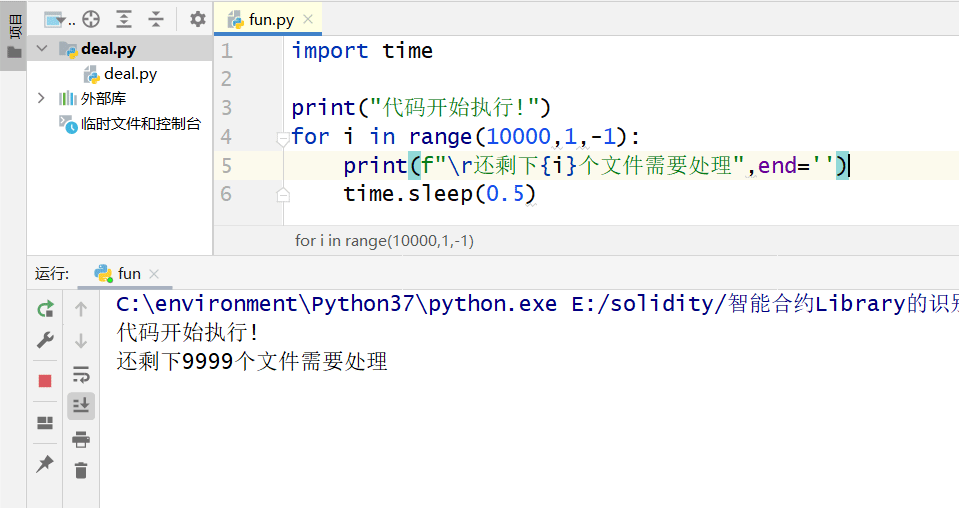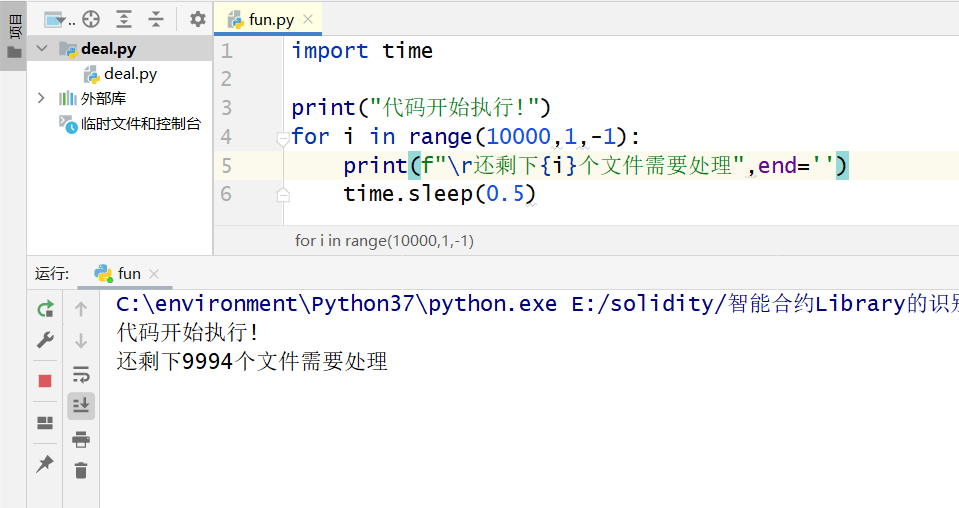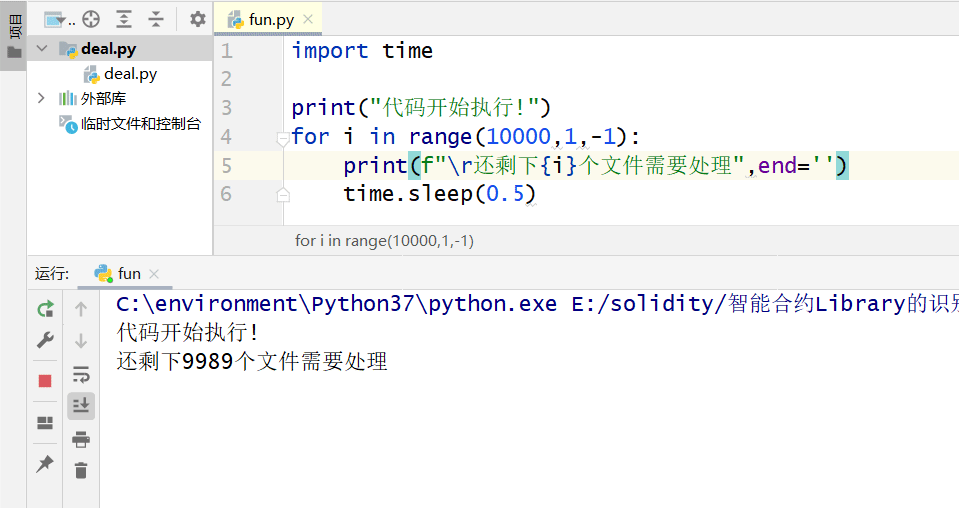 完美在pycharm中输出~
完美在pycharm中输出~





