指南:用 Anchor 构建 Solana 程序
- 翻译小组
- 发布于 2024-02-07 18:00
- 阅读 14404
用 Anchor 构建 Solana 程序
感谢 Noah、Mike、Jonas、Ryan、Prames 和bl0ckpain对本文的审阅。
本文内容
Rust 通常被作为 Solana 程序开发的通用语言。更准确地说,大多数 Rust 开发使用的是 Anchor 框架。Anchor 是一个功能强大的框架,旨在快速构建安全的 Solana 程序。它通过减少诸如账户(反)序列化和指令数据等领域的样板文件、进行必要的安全检查、自动生成客户端库以及提供广泛的测试环境来简化开发流程。
本文探讨了如何开发 Anchor 程序。它涵盖了安装 Anchor、使用 Solana Playground 以及创建、构建和部署简单的 Hello, World!程序。然后,我们将深入探讨 Anchor 如何通过检查接口定义语言(IDL)、宏、Anchor 程序的结构、账户类型和约束以及错误处理来简化开发流程。我们还将简要介绍跨程序调用和程序派生地址(PDA)。本文将为你提供开始使用 Anchor 所需的一切。
预备知识
本文假定读者了解 Solana 的编程模型。如果你是 Solana 的新手,我建议阅读我之前的博客文章 Solana 编程模型:Solana 开发入门。
如果你对 Rust 不熟悉,也不用担心——开始 Anchor 开发并不需要高级知识。Anchor 文档指出,开发人员只需要熟悉 Rust 的基础知识(即 Rust Book 的前九章)。我建议观看 Rust 生存指南,这是对基本的 Rust 编程概念进行了很好的解释。同时,了解 Rust 的内存、所有权和借用规则也非常重要。
为了降低学习曲线,我建议对低级编程语言不熟悉的开发人员复习一些系统编程特定概念,这些概念通常被 Rust 资源忽略。例如,我建议了解诸如变量大小 、指针和内存泄漏等主题。我还推荐阅读 Rust 示例和我在 Rust 中编写的各种数据结构和算法的存储库 。
本文专注于 Anchor 开发,仅限Anchor 开发。我们不会涉及如何开发原生 Rust 程序,本文也不假设读者了解该方面的知识。此外,本文也不涉及使用 Anchor 进行客户端开发——我们将在以后的文章中介绍如何通过 TypeScript 测试和与 Anchor 程序交互。
让我们开始 Anchor 之旅吧。
安装 Anchor
设置 Anchor 涉及几个简单的步骤,以安装必要的工具和软件包。本节涵盖了安装这些工具和软件包(即 Rust、Solana 工具套件、Yarn 和 Anchor 版本管理器)。
安装 Rust
Rust 可以从官方 Rust 网站安装,也可以通过命令行安装:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh安装 Solana 工具套件
Anchor 还需要 Solana 工具套件。可以使用以下命令在 macOS 和 Linux 上安装最新版本(1.17.16 - 撰写本文时):
sh -c "$(curl -sSfL https://release.solana.com/v1.17.16/install)"对于 Windows 用户,可以使用以下命令安装 Solana 工具套件:
cmd /c "curl https://release.solana.com/v1.17.16/solana-install-init-x86_64-pc-windows-msvc.exe --output C:\solana-install-tmp\solana-install-init.exe --create-dirs"但强烈建议你使用 Windows 子系统来安装 Solana 工具套件。这将允许你在 Windows 机器上运行 Linux 环境,而无需双重启动或启动单独的虚拟机。通过这种方式安装后,可以参考 Linux 的安装说明(即 curl 命令)。
开发人员还可以将v1.17.16替换为他们希望下载的版本的发布标签。或者,使用stable、beta或edge通道名称。安装完成后,运行solana –version确认所需版本的solana已安装。
安装 Yarn
Anchor 还需要 Yarn。可以使用 npm 软件包管理器 安装 Yarn,命令如下:npm install –global yarn。
使用 AVM 安装 Anchor
Anchor 文档建议使用 Anchor 版本管理器(AVM)安装 Anchor。AVM 简化了管理和选择多个anchor-cli二进制文件的安装。这可能需要生成可验证的构建 ,或者在不同程序之间使用不同版本。可以使用 Cargo 安装 AVM,命令如下:cargo install --git https://github.com/coral-xyz/anchor avm --locked --force。然后,安装并使用最新版本:
avm install latest
avm use latest
# Verify the installation
avm --version使用avm list命令查看anchor-cli的可用版本。开发人员可以使用avm use <version>来使用特定版本。此版本将保持使用,直到更改为止。开发人员可以使用avm uninstall <version>命令卸载特定版本。
使用二进制文件安装 Anchor 并从源代码构建
在 Linux 上,可以通过 npm 软件包 @coral-xyz/anchor-cli 获取 Anchor 二进制文件。目前,仅支持x86_64 Linux。因此,对于其他操作系统,开发人员必须从源代码构建。开发人员可以使用 Cargo 直接安装 CLI。例如:
cargo install --git https://github.com/coral-xyz/anchor --tag v0.29.0 anchor-cli --locked修改–tag参数以安装其他所需的 Anchor 版本。如果 Cargo 安装失败,可能需要安装其他依赖项。例如,在 Ubuntu 上:
sudo apt-get update && sudo apt-get upgrade && sudo apt-get install -y pkg-config build-essential libudev-dev然后,开发人员可以使用anchor –version命令验证 Anchor 的安装。
Solana Playground
 或者,开发人员可以使用 Solana Playground (Solpg) 开始使用 Anchor。Solana Playground 是一个基于浏览器的集成开发环境,可促进 Solana 程序的快速开发、测试和部署。
或者,开发人员可以使用 Solana Playground (Solpg) 开始使用 Anchor。Solana Playground 是一个基于浏览器的集成开发环境,可促进 Solana 程序的快速开发、测试和部署。
开发人员首次使用 Solana Playground 时,必须创建一个 Playground 钱包。单击屏幕左下角标有Not connected的红色状态指示器。将弹出以下模态框:
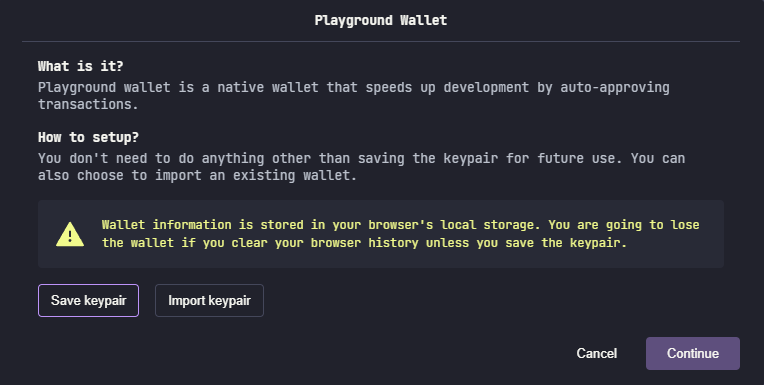
建议在单击Continue之前将钱包的密钥对文件保存为备份。这是因为 Playground 钱包保存在浏览器的本地存储中。清除浏览器缓存将删除钱包。

单击Continue以创建一个准备在 IDE 中使用的 devnet 钱包。
要为钱包充值,开发人员可以在 Playground 终端中运行以下命令solana airdrop <amount>,其中<amount>替换为所需的 devnet SOL 金额。或者,访问此 faucet 获取 devnet SOL。我建议查看以下有关如何获取 devnet SOL 的指南 。
请注意,你可能会遇到以下错误:
Error: unable to confirm transaction. This can happen in situations such as transaction expiration and insufficient fee-payer funds这往往是由于 devnet faucet 被耗尽和/或请求的 SOL 过多所致。当前限额为 5 SOL,这已经足够部署此程序。因此,建议从 faucet 请求 5 SOL 或执行命令solana airdrop 5。逐步请求较小的金额可能会导致速率限制。
Hello, World
Hello, World!程序被视为介绍新框架或编程语言的绝佳入门。这是因为它们的简单性,所有技能水平的开发人员都能理解。这些程序还阐明了新编程模型的基本结构和语法,而不引入复杂的逻辑或函数。它已经迅速成为编码中一个标准的初学者程序,因此我们用 Anchor 编写一个Hello World 是理所当然的。本节将介绍如何使用本地 Anchor 设置以及 Solana Playground 构建和部署 Hello, World! 程序。
使用本地 Anchor 设置创建新项目
安装了 Anchor 后,创建一个新项目就像这样简单:
anchor init hello-world
cd hello-world这些命令将初始化一个名为hello-world的新 Anchor 项目,并导航到其目录。在该目录中,导航到hello-world/programs/hello-world/src/lib.rs。此文件包含以下起始代码:
use anchor_lang::prelude::*;
declare_id!("HZfVb1ohL1TejhZNkgFSKqGsyTznYtrwLV6GpA8BwV5Q");
#[program]
pub mod hello-world {
use super::*;
pub fn initialize(ctx: Context) -> Result<()> {
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize {}
Anchor 已经为我们准备了许多文件和目录,如:
- 用于程序客户端的空app
- 将容纳所有 Solana 程序的programs文件夹
- 用于 JavaScript 测试的tests文件夹。它自动生成了一个用于起始代码的测试文件
- Anchor.toml配置文件。如果你是 Rust 的新手,TOML 文件是一种由于其语义而易于阅读的最小配置文件格式。Anchor.toml文件用于配置 Anchor 与程序的交互方式。例如,程序应该部署到哪个集群。
使用 Solana Playground 创建新项目
在 Solana Playground 上创建新项目非常简单。导航到左上角,单击Create a New Project:
将弹出以下模态框:
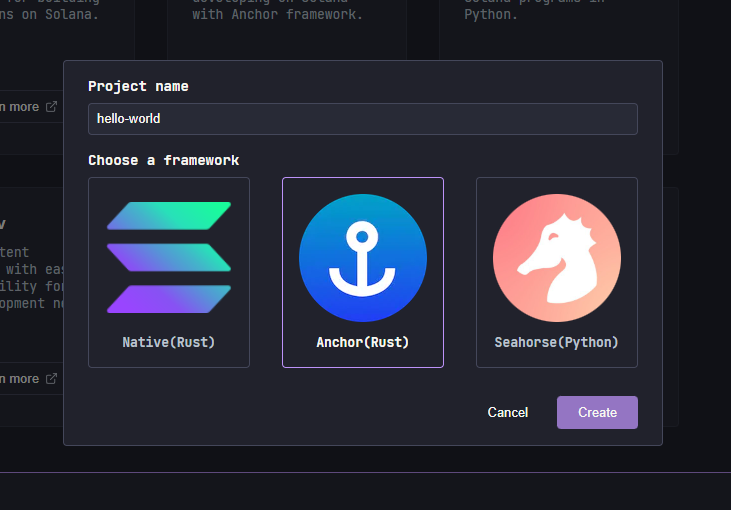
命名你的程序,选择Anchor(Rust),然后单击Create。这将直接在你的浏览器中创建一个新的 Anchor 项目。在左侧的Program部分下,你将看到一个src目录。它包含lib.rs,其中包含以下起始代码:
use anchor_lang::prelude::*;
// 这是 program 的公钥,在 build 的时候会自动更新
declare_id!("11111111111111111111111111111111");
#[program]
mod hello_anchor {
use super::*;
pub fn initialize(ctx: Context, data: u64) -> Result<()> {
ctx.accounts.new_account.data = data;
msg!("Changed data to: {}!", data); // 在交易日志里显示
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize<’info> {
// 为了初始化帐户,必须指定空间。
// 前8个字节是默认的帐户标识符, 接下来的8个字节来自 NewAccount。
// data 的类型为 u64.
// (u64 = 64 位无符号整型 = 8 字节)
#[account(init, payer = signer, space = 8 + 8)]
pub new_account: Account<’info, NewAccount>,
#[account(mut)]
pub signer: Signer<’info>,
pub system_program: Program<’info, System>,
}
#[account]
pub struct NewAccount {
data: u64
}请注意,Solana Playground 只会生成client.ts和anchor.test.ts文件。我建议阅读有关在本地使用 Anchor 创建程序的部分,以了解通常为新 Anchor 项目生成了哪些内容。
编写 Hello, World!
无论你是在本地使用 Anchor 还是通过 Solana Playground,对于一个非常简单的 Hello, World!程序,将起始代码替换为以下内容:
use anchor_lang::prelude::*;
declare_id!("HZfVb1ohL1TejhZNkgFSKqGsyTznYtrwLV6GpA8BwV5Q");
#[program]
mod hello_world {
use super::*;
pub fn hello(_ctx: Context<Hello>) -> Result<()> {
msg!("Hello, World!");
Ok(())
}
#[derive(Accounts)]
pub struct Hello {}
}我们将在后续部分详细介绍每个部分的具体内容。目前,重要的是注意使用宏和 traits 简化了开发过程。declare_id!宏设置了程序的公钥。对于本地开发,使用anchor init命令设置程序将在target/deploy目录中生成一个密钥对,并填充此宏。Solana Playground 也会自动为我们执行此操作。
在我们的主 hello_world 模块中,我们创建了一个打印(日志) Hello, World!的函数。它还返回Ok(())以表示程序执行成功。请注意,我们在控制台中使用下划线前缀ctx以避免未使用变量的警告。Hello 是一个不需要传递任何账户的账户结构,因为该程序只打印一个新消息。
就是这样!不需要传任何账户或进行一些复杂的逻辑。上面呈现的代码创建了一个记录 Hello, World!的程序。
本地构建和部署
本节将重点介绍部署到 Localhost。尽管 Solana Playground 默认为 devnet,但本地开发环境提供了显著改进的开发体验。它不仅更快,而且可以避免在针对 devnet 进行测试时常见的几个问题。例如,交易的 SOL 不足、部署缓慢以及 devnet 不可用时无法进行测试。相比之下,本地开发可以保证每次测试都有一个新的状态。这可以为开发人员提供更受控和高效的开发环境。
配置我们的工具
首先,我们要确保 Solana 工具套件正确配置为本地开发(Local development)。运行solana config set –url localhost命令,确保所有配置指向本地主机 URL。
还要确保你有一个本地密钥对(key pair)以与 Solana 进行交互。你必须拥有一个带有 SOL 余额的 Solana 钱包才能使用 Solana CLI 部署程序。运行solana address命令检查是否已经有本地密钥对。如果遇到错误,请运行solana-keygen new命令。将在默认情况下在~/.config/solana/id.json路径创建一个新的文件系统钱包。它还会提供一个可用于恢复公钥和私钥的恢复短语。建议保存此密钥对,即使它是在本地使用。还要注意,如果你已经在默认位置保存了文件系统钱包,solana-keygen new命令将不覆盖它,除非使用–force命令指定。
配置 Anchor.toml
接下来,我们要确保我们的 Anchor.toml 文件正确指向本地主机。确保它包含以下代码:
...
[programs.localnet]
hello-world = "EJTW6qsbfya86xeLRQpKLM8qhn11cJXmU35QbJwE11R8"
...
[provider]
cluster = "Localnet"
wallet = '~config/solana/id.json'这里,[programs.localnet] 指的是本地网络(即本地主机)上程序 ID。程序 ID 始终是相对于集群指定的。这是因为同一个程序可以部署到不同集群(cluster)上的不同地址。从开发者的角度来看,为部署到不同集群的程序声明新的程序 ID 可能会很烦人。
程序 ID 是公开的。但它的密钥对存储在 target/deploy 文件夹中。它遵循基于程序名称的特定命名约定。例如,如果程序名为 hello_world,Anchor 将在 target/deploy/hello-world-keypair.json 中寻找密钥对。如果在部署过程中找不到该文件,Anchor 将生成一个新的密钥对,这将生成新的程序 ID。因此,在第一次部署后更新程序 ID 至关重要。hello-world-keypair.json 文件用作程序所有权的证明。如果密钥对泄露,恶意行为者可以对程序进行未经授权的更改。
通过 [provider],我们告诉 Anchor 使用 本地主机 和指定的钱包来支付存储和交易费用。
构建、部署和本地运行
使用 anchor build 命令构建程序。要按名称构建特定程序,请使用 anchor build -p <program name> 命令,将 <program name> 替换为程序的名称。由于我们正在本地网络上开发,我们可以使用 Anchor CLI 的本地网络命令来简化开发过程。例如,anchor localnet –skip-build 对于跳过工作区中程序的构建非常有用。这在运行测试时可以节省时间,且程序的代码尚未更改。
如果我们现在尝试运行 anchor deploy 命令,将会收到一个错误。这是因为我们没有在自己的机器上运行 Solana 集群,可以进行测试。我们可以运行本地 ledger 来模拟在我们的机器上运行集群。Solana CLI 自带一个测试验证器 。运行 solana-test-validator 命令 将在你的工作站上启动一个功能齐全的单节点集群。这对许多原因都很有益,例如没有 RPC 速率限制、没有空投限制、直接在链上部署程序、从文件加载账户以及从公共集群克隆账户。测试验证器必须在单独的打开的终端窗口中运行,并保持运行,以使本地主机集群保持在线并可供交互。
现在,我们可以成功运行 anchor deploy 来将程序部署到我们的本地ledger。传输到本地 ledger 的任何数据都将保存在当前工作目录中生成的 test-ledger 文件夹中。建议将此文件夹添加到你的 .gitignore 文件中,以避免将此文件夹提交到你的存储库中。此外,退出本地 ledger(即在终端中按下 Ctrl + C)不会删除发送到集群的任何数据。删除 test-ledger 文件夹或运行 solana-test-validator –reset 将会删除数据。
恭喜!你刚刚将你的第一个 Solana 程序部署到本地主机!
Solana Explorer
开发者还可以将 Solana Explorer 配置为他们的本地ledger。转到 Solana Explorer。在导航栏中,单击当前集群状态的绿色按钮:
这将打开一个侧边栏,允许你选择一个集群。单击 Custom RPC URL。这应该自动填充为 http://localhost:8899 。如果没有,请填写,以便将区块浏览器指向你的机器的 8899 端口:
配置本地区块链浏览器有几个非常重要原因:
- 它允许开发者实时检查本地ledger上的交易,就像他们通常在分析 devnet 或 mainnet 的区块浏览器上所具有的功能
- 更容易可视化账户、代币和程序的状态,就像它们在实时集群上运行一样
- 它提供了有关错误和交易失败的详细信息
- 它提供了一致的开发体验,因为它是一个熟悉的界面
部署到 Devnet
尽管倡导本地主机开发,如果希望专门针对该集群进行测试,开发者也可以部署到 devnet 。该过程通常是相同的,只是不需要运行本地ledger(我们有一个完全成熟的 Solana 集群可以进行交互!)。
运行命令 solana config set –url devnet 来将所选集群更改为 devnet。现在终端中运行的任何 solana 命令都将在 devnet 上执行。然后,在 Anchor.toml 文件中,复制 [programs.localnet] 部分,并将其重命名为 [programs.devnet]。同时,更改 [provider],使其指向 devnet:
...
[programs.localnet]
hello-world = "EJTW6qsbfya86xeLRQpKLM8qhn11cJXmU35QbJwE11R8"
[programs.devnet]
hello-world = "EJTW6qsbfya86xeLRQpKLM8qhn11cJXmU35QbJwE11R8"
...
[provider]
cluster = "Devnet"
wallet = '~config/solana/id.json'开发者必须确保拥有 devnet SOL 以部署程序。使用 solana airdrop <amount> 命令向默认密钥对位置 ~/.config/solana/id.json 进行空投。也可以使用 solana aidrop <amount> <wallet address> 指定钱包地址。或者,访问此水龙头获取 devnet SOL。我建议查看以下获取 devnet SOL 的指南 。
请注意,你可能会遇到以下错误:
Error: unable to confirm transaction. This can happen in situations such as transaction expiration and insufficient fee-payer funds这往往是由于 devnet 水龙头被耗尽和/或一次请求太多 SOL 导致的。当前限制为 5 SOL,这已经足够部署此程序。因此建议从水龙头请求 5 SOL 或执行命令 solana airdrop 5。逐步请求较小的金额可能会导致速率限制。
现在,使用以下命令构建和部署程序:
anchor build
anchor deploy恭喜!你刚刚将你的第一个 Solana 程序部署到本地的 devnet!
在 Solana Playground 上构建和部署
在 Solana Playground 上,转到左侧边栏上的 Tools 图标。单击 Build。在控制台中,你应该看到以下内容:
Building...
Build successful. Completed in 2.20s..注意 declare_id! 宏中的 ID 已被覆盖。这个新地址就是我们将要部署程序的地方。现在,单击 Deploy。你应该在控制台中看到类似于以下内容:
Deploying... This could take a while depending on the program size and network conditions.
Warning: 41 transactions not confirmed, retrying...
Deployment successful. Completed in 17s.恭喜!你刚刚通过 Solana Playground 将你的第一个 Solana 程序部署到 devnet!
有效的抽象:接口定义语言和宏
Anchor 通过有效的抽象简化了程序开发。也就是说,Anchor 简化了复杂的区块链编程概念,使其更易于访问和操作。例如,Anchor 使用接口定义语言(IDL) 来定义程序的接口。在构建程序时,Anchor 将生成代表程序 IDL 的 JSON 文件。基本上,这种结构可以在客户端上使用,定义如何与程序的函数和数据结构进行交互。Anchor 还提供了更高级的抽象来处理状态管理。Anchor 允许开发人员使用 Rust 结构体(struct)来定义其程序的状态,这可能比使用原始字节数组或手动序列化更直观。因此,开发人员可以像使用任何典型的 Rust 数据结构一样定义状态,然后 Anchor 处理底层的序列化和存储到账户中。
在链上发布 IDL 也非常简单。开发人员可以使用以下命令发布 IDL:
anchor idl init --filepath --provider.cluster --provider.wallet 确保提供的钱包是程序的授权方(authority),并且具有足够的 SOL 进行交易。开发人员现在可以在区块浏览器(例如 XRAY 或Solana Explorer)上查看他们的 IDL。
Anchor 的宏是最重要的抽象之一。在 Rust 中, 宏是一段生成另一段代码的代码。这是一种元编程形式。 声明宏是 Rust 中最常用的宏形式。它们允许开发人员通过macro_rules!构造编写类似于match表达式的内容。 过程宏更像是一个函数,接受一些代码作为输入,对该代码进行操作,并产生一些输出。例如,在 Anchor 中,#[account] 宏定义并强制 Solana 账户的约束。这有助于减少围绕账户管理的复杂性和潜在错误。涉及 Anchor 的宏必然需要讨论 Anchor 的程序结构。
Anchor 程序结构

Anchor 的程序结构旨在利用宏和traits的组合来生成样板代码并强制执行程序逻辑。这种设计理念在简化开发流程、确保程序行为的一致性和可靠性方面起着重要作用。
use 声明位于文件顶部。请注意,它们是 Rust 语言的通用语义,与 Anchor 无关。这些声明创建一个或多个本地名称绑定,与其他路径同义 - use 声明缩短了引用模块项所需的路径。它们可以出现在模块或块中。此外,self 关键字可以将具有共同前缀和共同父模块的路径绑定到一个列表。例如,以下都是有效的 use 声明:
use anchor_lang::prelude::*;
use std::collections::hash_map::{self, HashMap};
use a::b::{c, d, e::f, g::h::i};
use a::b::{self, c, d::e};开发人员将遇到的第一个 Anchor 宏是 declare_id!。它用于声明程序的地址(程序 ID),确保所有交互都正确地路由到程序。当开发人员首次构建 Anchor 程序时,Anchor 将生成一个新的密钥对(key pair)。这是部署程序时使用的密钥对,除非另有说明。应将密钥对的公钥作为 declare_id! 宏的程序 ID 提供:
declare_id!("HZfVb1ohL1TejhZNkgFSKqGsyTznYtrwLV6GpA8BwV5Q");#[program] 属性宏表示程序的指令逻辑模块。它充当入口点,定义程序如何解释和执行传入的指令。此宏简化了这些指令路由到程序内适当函数的过程,使程序的代码更有组织性和可管理性。该模块内的每个函数都被视为一个单独的指令。每个函数将以 Context 类型的上下文参数(ctx)作为其第一个参数。开发人员可以访问执行程序的账户、程序 ID 和剩余账户。
Context 类型定义如下:
pub struct Context<'a, 'b, 'c, 'info, T: Bumps> {
pub program_id: &'a Pubkey,
pub accounts: &'b mut T,
pub remaining_accounts: &'c [AccountInfo<’info>],
pub bumps: T::Bumps,
}这有助于为给定程序提供非参数输入。program_id 字段的类型为 Pubkey,表示当前执行的程序 ID。accounts 指的是序列化的账户,而 remaining_accounts 指的是给定但未被反序列化或验证的剩余账户 - 在直接使用时要非常小心。bumps 字段的类型为 Bumps ,由 #[derive(Accounts)] 生成。它表示约束验证期间发现的增量种子。我们将在后面的部分介绍账户约束。目前,重要的是要知道这是为了方便处理程序,使处理程序不必重新计算增量种子或将其作为参数传递。
请注意,Context 是一个通用类型。在 Rust 中, 通用允许开发人员编写灵活、可重用的代码,适用于任何数据类型。它们允许为结构、枚举、函数和方法定义类型,而无需指定它们将使用的确切类型。而是使用占位符来表示这些类型,通常表示为 T。通用帮助减少重复的代码并增加清晰度。例如,可以定义一个枚举来保存通用数据类型:
enum Option<T> {
Some(T),
None,
}上面的代码片段展示了 Option<T> 枚举。它是一个标准的 Rust 枚举,可以封装任何类型的值(即 Some(T))或没有类型(None)。
对于我们的目的,Context 是一个具有 T 指定指令所需账户的通用类型(即开发人员想要创建以存储数据的任何类型)。
当使用 Context 时,开发人员可以将 T 定义为实现 Accounts traits 的结构。例如,Context<SetData>。
开发人员可以使用点符号访问 Context 类型中的字段。例如,ctx.accounts 访问 Context 结构的 accounts 字段。
如前所述,#[account] 宏定义了自定义账户类型。在接下来的部分中,我们将使用 #[account(...)] 探讨账户类型和约束。目前,重要的是要注意 Accounts 结构体(struct)是开发人员定义指令应该期望的账户以及这些账户应该遵循的约束的地方。
账户类型
当指令想要访问账户的反序列化数据时,将使用 Account 类型。Account 结构体是关于 T 的通用结构,定义如下:
pub struct Account<’info, T: AccountSerialize + AccountDeserialize + Clone> { /* private fields */ }这是 AccountInfo 的包装器,用于验证程序所有权并将底层数据反序列化为 Rust 类型。它检查程序所有权,以便 Account.info.owner == T::owner()。也就是说,它检查数据所有者是否与使用 #[account] 的 crate 的 ID(之前使用 declare_id! 创建的 ID)相同。这意味着 Account 包装的数据类型(=T)必须实现 Owner trait。#[account] 属性使用同一程序中由 declare_id! 声明的 crate::ID 为结构体实现该 trait。大多数情况下,开发人员可以简单地使用 #[account] 属性来添加所需的 traits 和实现到他们的数据中。#[account] 属性为以下 traits 生成实现:
在为账户序列化实现 traits 时,会为唯一账户鉴别器(unique account discriminator )分配初始 8 个字节。该鉴别器由账户的 Rust 标识符的 SHA256 哈希的前 8 个字节确定。任何对 AccountDeserialize 的 try_deserialize 的调用都将检查此鉴别器,如果提供了无效账户,则会以错误退出账户反序列化。
开发人员将需要与非 Anchor 程序交互的情况。在这种情况下,开发人员可以创建自己的自定义包装器类型,而不是使用 #[account]。以下代码片段是一个示例:
use anchor_lang::prelude::*;
use anchor_spl::token::TokenAccount;
// Rest of the program
#[derive(Accounts)]
pub struct SetData<'info> {
#[account(mut)]
pub my_account: Account<'info, MyAccount>,
#[account(
constraint = my_account.mint == token_account.mint,
has_one = owner
)]
pub token_account: Account<'info, TokenAccount>,
pub owner: Signer<'info>
}大多数账户验证是通过账户约束完成的,我们将在下一节中介绍。但现在,看看 TokenAccount 类型如何确保传入的账户由代币程序拥有。TokenAccount 包装了代币程序的 Account 结构,并添加了必要的函数。这确保了 Anchor 可以反序列化账户,并且开发人员可以在账户约束和指令函数中使用其字段。
还要注意上面的代码片段中,derive 宏封装了整个结构。这在 SetData 上实现了一个 Accounts 反序列化器,并用于验证传入的账户。
账户验证结构中可以使用多种 Account 类型,包括:
- Account<’info, T>:一个账户容器,用于在反序列化时检查所有权
- AccountInfo<’info>:一个未经检查的账户,可以用作类型。但是,应该使用 UncheckedAccount,因为 AccountInfo 可能会在将来的版本中消失
- AccountLoader<’info, T>:一种类型,用于按需零拷贝反序列化 。这与开发人员使用 Account 不同,因为开发人员必须在初始化账户后调用 load_init,在账户不可变时调用 load,在账户可变时调用 load_mut
- Box<Account<’info, T>> 或 Box<InterfaceAccount<’info, T>>:一种盒子类型,用于保存堆栈空间,因为有时账户对于堆栈来说太大,可能导致堆栈违规 - 对账户进行盒装可以帮助解决这个问题
- Interface<’info, T>:一种类型,用于在 Program 上包装,用于验证账户是否是给定程序集中的一个。它检查预期程序是否包含账户的密钥,以及账户是否可执行
- InterfaceAccount<’info, T>:一个账户容器,用于检查程序所有权并将底层数据反序列化为 Rust 类型
- Option<Account<'info, T>>:用于可选账户的选项类型
- Program<’info, T>:一种类型,用于验证账户是否是给定程序
- Signer<’info>:一种类型,用于验证账户是否签署了交易
- SystemAccount<’info>:一种类型,用于验证账户是否由系统程序拥有
- Sysvar<’info, T>:一种类型,用于验证账户是否是 sysvar,即账户是否是包含有关网络集群、区块链历史和执行交易的动态更新数据的特殊类型。clock、epoch_schedule、instructions 和 rent sysvar 对于程序开发很有用
- UncheckedAccount<’info>:一个账户容器,特别强调对指定账户未执行任何检查
账户约束
账户约束对于开发安全的 Anchor 程序至关重要。在未来的文章中,我们将更深入地介绍 Solana 程序安全和黑客攻击 Anchor 程序。但在这里,重要的是要介绍约束。约束允许开发人员验证某些账户或它们持有的数据是否符合一些预定义的要求。可以使用 #[account(...)] 属性应用几种不同类型的约束,该属性还可以引用其他数据结构。格式如下:
#[account(constraint goes here)]
pub account: AccountType同样重要的是要注意,在 Accounts 宏中,开发人员可以使用 #[instruction(...)] 属性访问指令参数。开发人员需要按照指令中的顺序列出指令参数,但可以省略最后一个需要的参数之后的所有参数。例如,来自 Anchor 文档中的示例:
...
pub fn initialize(ctx: Context, bump: u8, authority: Pubkey, data: u64) -> anchor_lang::Result<()> {
...
Ok(())
}
...
#[derive(Accounts)]
#[instruction(bump: u8)]
pub struct Initialize<'info> {
...
}
账户约束可以分为普通约束和SPL 约束。我们将在本文的其余部分讨论特定的约束。在这些示例中,<expr>表示可能传递的任意表达式,只要它运算出预期类型的值即可。例如,owner = token_program.key() 。
分析程序的约束
我建议查阅 Anchor 关于账户的文档 ,以获取可能约束的更全面列表。循环遍历每个约束,以某种表格格式提供正式定义将会太过繁琐。对于我们的目的,更有益的是分析以下程序,以了解约束在实际中的应用:
use anchor_lang::prelude::*;
#[cfg(not(feature = "no-entrypoint"))]
use {default_env::default_env, solana_security_txt::security_txt};
declare_id!("fanqeMu3fw8R4LwKNbahPtYXJsyLL6NXyfe2BqzhfB6");
pub mod errors;
pub mod instructions;
pub mod state;
pub use instructions::*;
pub use state::*;
#[cfg(not(feature = "no-entrypoint"))]
security_txt! {
name: "Fanout",
project_url: "http://helium.com",
contacts: "email:hello@helium.foundation",
policy: "https://github.com/helium/helium-program-library/tree/master/SECURITY.md",
// Optional Fields
preferred_languages: "en",
source_code: "https://github.com/helium/helium-program-library/tree/master/programs/fanout",
source_revision: default_env!("GITHUB_SHA", ""),
source_release: default_env!("GITHUB_REF_NAME", ""),
auditors: "Sec3"
}
#[program]
pub mod fanout {
use super::*;
pub fn initialize_fanout_v0(
ctx: Context<InitializeFanoutV0>,
args: InitializeFanoutArgsV0,
) -> Result<()> {
instructions::initialize_fanout_v0::handler(ctx, args)
}
pub fn stake_v0(ctx: Context<StakeV0>, args: StakeArgsV0) -> Result<()> {
instructions::stake_v0::handler(ctx, args)
}
pub fn unstake_v0(ctx: Context<UnstakeV0>) -> Result<()> {
instructions::unstake_v0::handler(ctx)
}
pub fn distribute_v0(ctx: Context<DistributeV0>) -> Result<()> {
instructions::distribute_v0::handler(ctx)
}
}这是Helium 的 Fanout 程序。这是一个相当复杂的程序,根据持有的代币比例向代币持有者分发代币。目前,该项目对我们来说似乎并不那么有用,因为没有任何约束。然而,如果我们分析 stake_v0指令的StakeV0结构体,我们将有多个约束可供探索。
mut
该指令中的第一个约束是 mut 账户约束。mut 被定义为#[account(mut)]或#[account(mut @ <custom_error>)],支持使用@符号的自定义错误。此约束检查给定账户是否可变,并使 Anchor 持久化任何状态更改。在 Helium 的程序中,该约束确保payer账户是可变的:
...
pub struct StakeV0<'info> {
#[account(mut)]
pub payer: Signer<'info>,
pub staker: Signer<'info>,
/// CHECK: Just needed to receive nft
pub recipient: AccountInfo<'info>,
...has_one
has_one约束被定义为#[account(has_one = <target_account>)]或#[account(has_one = <target_account> @ <custom_error>)]。它检查target_account字段,以查看账户是否与 Accounts 结构体中的target_account字段的键匹配。通过@注释支持自定义错误。
在StakeV0结构体的上下文中,has_one约束用于检查账户是否具有membership_mint、token_account和membership_collection:
...
#[account(
mut,
has_one = membership_mint,
has_one = token_account,
has_one = membership_collection
)]
pub fanout: Box<Account<'info, FanoutV0>>,
pub membership_mint: Box<Account<'info, Mint>>,
pub token_account: Box<Account<'info, TokenAccount>>,
pub membership_collection: Box<Account<'info, Mint>>,
...
请注意,存在多个has_one约束,并且还在使用mut约束。使用账户约束时,可以同时在账户上使用多个账户约束。
seeds, bump
seeds和bump约束用于检查给定账户是否是从当前执行程序、种子(如果提供的话)以及bump 派生的 PDA:
- #[account(seeds = <seeds>, bump)]
- #[account(seeds = <seeds>, bump, seeds::program = <expr>)]
- #[account(seeds = <seeds>, bump = <expr>)]
- #[account(seeds = <seeds>, bump = <expr>, seeds::program = <expr>)]
如果未提供 bump,Anchor 将使用规范的 bump。seeds::program = <expr>可用于从与当前执行程序不同的程序派生 PDA。
在 Helium 的 fanout 程序中 ,seeds约束检查文本“metadata”、token_metadata_program键、membership_collection键以及文本“edition”是否是用于派生此 PDA 的种子。seeds::program约束确保使用token_metadata_program来派生 PDA,而不是当前程序:
...
#[account(
mut,
seeds = ["metadata".as_bytes(), token_metadata_program.key().as_ref(), membership_collection.key().as_ref()],
seeds::program = token_metadata_program.key(),
bump,
)]
pub collection_metadata: UncheckedAccount<'info>,
...token::mint, token::authority
token::mint和token::authority约束定义如下:
- #[account(token::mint = <target account>, token::authority = <target account>)]
- #[account(token::mint = <target account>, token::authority = <target account>, token::token_program = <target account>)]
mint和authority代币约束用于验证TokenAccount的铸造地址和权限。这些约束可以用作检查,或者与init约束一起使用,以使用给定的铸造地址和权限创建代币账户。在用作检查时,可能只指定约束的子集。
在 Helium 的程序上下文中,这些约束用于检查associated_token的铸造地址是否等于membership_mint,以及代币的权限是否设置为staker:
...
#[account(
mut,
associated_token::mint = membership_mint,
associated_token::authority = staker,
)]
pub from_account: Box<Account<'info, TokenAccount>>,
...
Copyinit, payer, space
此时,跳到代码中稍后的部分,分析init、payer和space约束是有意义的。init约束被定义为[#account(init, payer = <target_account>, space = <num_bytes>)]。此约束通过 CPI 创建账户到 System Program,并通过设置其账户鉴别器来初始化它。这将标记账户为可变,并且与mut互斥。对于大于 10Kibibytes 的账户,请使用#[account(zero)]。
init约束必须与一些额外的约束一起使用。它需要payer约束,指定将支付账户创建费用的账户。还需要 System Program 存在于结构体中,并被称为system_program。还必须定义space约束。在账户空间部分,我们将更深入地探讨此约束和空间要求。
关于 Helium 的 fanout 程序,init命令创建一个新账户。payer设置为之前在结构体中定义的payer,即pub payer: Signer<'info>。账户的空间设置为FanoutVoucherV0的大小,再加上 8 个字节用于鉴别器,以及额外的 61 个字节的空间:
...
#[account(
init,
payer = payer,
space = 60 + 8 + std::mem::size_of::<FanoutVoucherV0>() + 1,
seeds = ["fanout_voucher".as_bytes(), mint.key().as_ref()],
bump,
)]
pub voucher: Box<Account<'info, FanoutVoucherV0>>,
...
Copyinit_if_needed
init_if_needed约束被定义为#[account(init_if_nedded, payer = <target_Account>)]或#[account(init)if_needed, payer = <target_account>, space = <num_bytes>)]。此约束与init具有完全相同的功能。但是,仅当账户尚不存在时才运行。如果账户存在,init_if_needed仍然验证所有初始化约束是否满足,例如账户已分配正确数量的空间或在 PDA 的情况下具有正确的种子。
init_if_needed 应谨慎使用,因为它受到功能标志的限制,可能存在潜在风险。要启用它,请使用 init-if-needed cargo 功能导入 anchor-lang。在使用 init_if_needed 时,至关重要的是防范重新初始化攻击。开发人员必须确保他们的代码包含检查,以防止账户在初始化后被重置为其初始状态,除非这种行为是有意的。将指令执行路径保持简单以减轻这些攻击是最佳实践。考虑将指令分为一个用于初始化和另一个用于后续操作。
Helium 的 Fanout 程序使用 init_if_needed 约束 来初始化 recipient_account,如果该账户尚不存在:
...
#[account(
init_if_needed,
payer = payer,
associated_token::mint = mint,
associated_token::authority = recipient,
)]
pub receipt_account: Box<Account<'info, TokenAccount>>,
...
constraint
constraint 约束被定义为 #[account(constraint = <expr>)] 或 #[account(constraint = <expr> @ <custom_error>)]。它检查提供的表达式是否为真。当没有其他约束符合预期用例时,这非常有用。它还支持通过 @ 注释自定义错误。
Fanout 程序使用 constraint 来检查铸币的供应是否设置为零:
...
#[account(
mut,
constraint = mint.supply == 0,
mint::decimals = 0,
mint::authority = voucher,
mint::freeze_authority = voucher,
)]
pub mint: Box<Account<'info, Mint>>,
...
mint::authority, mint::decimals, mint::freeze_authority
在上述代码片段中,mint::decimals、mint::authority 和 mint::freeze_authority 约束被用于检查铸币的小数是否设置为零,voucher 是否具有权限和冻结权限。
为了更好理解,mint::authority、mint::decimals 和 mint::freeze_authority 约束被定义为:
- #[account(mint::authority = <target account>, mint::decimals = <expr>)]
- #[account(mint::authority = <target account>, mint::decimals = <expr>, mint::freeze_authority = <target account>)]
这些约束是不言自明的 - 即它们分别检查代币的权限、decimals 和冻结权限。它们可以用作检查或与 init 一起使用,以创建具有给定铸币小数和铸币权限的铸币账户。与 init 一起使用时,冻结权限是完全可选的。在用作检查时,可以只指定这些约束的子集。
账户空间
Solana 上程序使用的每个账户都必须显式分配其存储空间。这种分配对于有效的资源管理至关重要,确保链上仅存储必要的数据。这也有助于可预测的交易成本,并增强了交易执行的效率 - 交易可以在无需动态分配或调整账户存储空间的情况下进行处理。此外,预先分配数据可保证账户具有足够的空间来存储其所有必需数据,减少了交易失败或潜在安全漏洞的风险。
变量大小
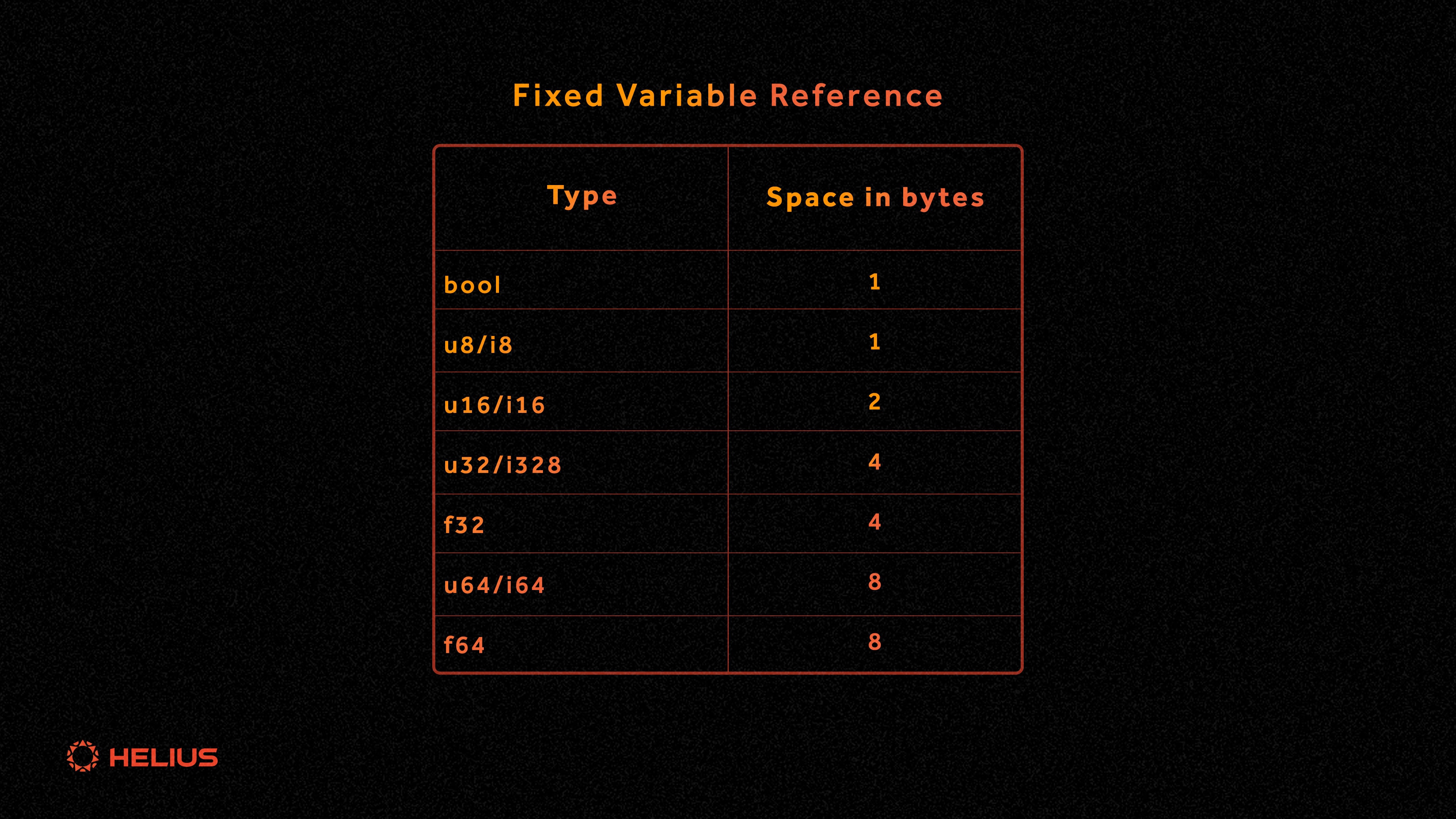
不同的数据类型具有不同的空间要求。以下是一个简化的指南,以帮助估算空间要求:
- 基本类型:像 bool、u8、i8、u16、i16、u32、i32、u64、i64、u128 和 i128 这样的简单数据类型都有固定的大小。从 bool(尽管它只使用 1 位)到 u128 / i128 的 16 字节不等
- 数组:对于数组 [T;amount],空间计算为 T 的大小乘以元素的数量(即 amount)。例如,一个包含 16 个 u16 的数组需要 32 字节
- Pubkey:在 Solana 上,公钥始终占用 32 字节
- 动态类型:String 和 Vec<T> 需要仔细考虑。它们都需要 4 个字节来存储它们的长度,再加上实际内容的空间。对于 String,这看起来是 4 个字节加上 String 的长度(以字节为单位)。对于 Vec<T>,这看起来是 4 个字节加上给定类型的空间乘以预期元素的数量(即 4 + space(T) * amount)
- Options和枚举:Option<T> 类型需要 1 个字节加上类型 T 的空间。枚举需要 1 个字节用于枚举鉴别器,再加上最大变体(variant)所需的空间
- 浮点数:诸如 f32 和 f64 的类型分别占用 4 和 8 个字节。要小心 NaN 值,因为它们可能导致序列化失败
以下指南仅适用于不使用 zero-copy 序列化的账户。zero-copy 序列化由 #[zero_copy] 属性表示。它利用 repr(c) 属性的内存布局,从而实现直接指针转换以访问数据。这是一种在没有传统反序列化开销的情况下处理链上数据的高效方式。#[zero_copy] 是应用 #[derive(Copy, Clone)]、#[derive(bytemuck::Zeroable)]、#[derive(bytemuck::Pod) 和 #[repr(C)] 的简写。这些属性确保账户可以安全地被视为字节序列,并且与零拷贝反序列化兼容。零拷贝反序列化对于需要显著大尺寸的账户 是至关重要的 - 这些账户无法在不遇到堆栈限制下使用 Borsh 或 Anchor 的默认序列化机制有效序列化。
Anchor 的内部鉴别器(Internal Discriminator)
开发人员必须为 Anchor 的内部鉴别器添加 8,以满足 space 约束。例如,如果一个账户需要 32 字节,它将需要 40。将 space 约束设置为 space = 8 + <account size> 是一个良好的实践,以表明考虑了内部鉴别器在空间计算中的影响。
另外,鉴别器是用于在运行时区分不同数据类型的唯一标识符。这对于区分 Anchor 程序内不同类型的账户数据结构非常有用。它还用于前缀指令,帮助将这些指令路由到 Anchor 程序内对应的方法。鉴别器是表示数据类型唯一标识符的 8 字节数组。
计算初始空间
计算账户的初始空间需求可能具有挑战性。InitSpace 宏添加了一个 INIT_SPACE 常量,可用于账户的结构。结构体并不需要包含 #[account] 宏来生成该常量。Anchor 文档提供了以下示例:
#[account]
#[derive(InitSpace)]
pub struct ExampleAccount {
pub data: u64,
// max_len represents the length of the structure
#[max_len(50)]
pub string_one: String,
#[max_len(10, 5)]
pub nested: Vec<Vec<u8>>,
}
#[derive(Accounts)]
pub struct Initialize<'info> {
#[account(mut)]
pub payer: Signer<'info>,
pub system_program: Program<'info, System>,
#[account(init, payer = payer, space = 8 + ExampleAccount::INIT_SPACE)]
pub data: Account<'info, ExampleAccount>,
}在此示例中,ExampleAccount::INIT_SPACE 自动计算了 ExampleAccount 所需的空间,并考虑了 Anchor 的内部鉴别器对空间计算的影响。
调整程序空间
realloc 约束用于在指令开始时调整程序账户的空间。它要求账户是可变的(即 mut),并适用于 Account 或 AccountLoader 类型。它被定义为 #[account(realloc = <space>, realloc::payer = <target>, realloc::zero = <bool>)]。当增加账户数据长度时,从 realloc::payer 转移 lamports 到程序账户,以保持租金豁免。如果数据长度减少,则从程序账户将 lamports 移回 realloc::payer。realloc::zero 约束决定新分配的内存是否应该进行零初始化。零初始化确保新内存是干净的,没有任何残留或不需要的数据。
不建议手动使用AccountInfo::realloc,而是使用realloc约束。这是因为缺乏运行时检查,以确保重新分配不超过MAX_PERMITTED_DATA_INCREASE限制,否则可能导致覆盖其他账户中的数据。该约束还会检查并阻止在单个指令中重复重新分配。
例如:
#[derive(Accounts)]
pub struct Data {
#[account(mut)]
pub payer: Signer<'info>,
#[account(
mut,
seeds = [b"data"],
bump,
realloc = 8 + std::mem::size_of::<()>() + 48,
realloc::payer = payer,
realloc::zero = false
)]
pub update_account: Account<'info, NewData>,
system_program: Program<'info, System>,
}
Copy错误
错误处理是程序开发的重要方面。这是一种识别和管理可能导致程序执行中断的错误的机制。处理错误必须是有意识和计划的,以确保代码质量、维护和功能。Anchor 通过强大的错误处理机制简化了这一过程。Anchor 程序中的错误可以分为 AnchorErrors 和非 Anchor 错误。本节将重点介绍AnchorErrors,而非 Anchor 错误涵盖了广泛的 Rust 错误。对于非 Anchor 错误,建议查看 Rust Book 中的错误处理章节和Rust By Example 中的错误处理部分。
以下struct定义了AnchorError:
pub struct AnchorError {
pub error_name: String,
pub error_code_number: u32,
pub error_msg: String,
pub error_origin: Option<ErrorOrigin>,
pub compared_values: Option<ComparedValues>,
}
这些字段相对直观。error_name是一个字符串,表示错误的名称。error_code_number是一个唯一标识符(即占用 32 位空间的唯一无符号整数)用于表示错误。error_msg是解释错误的描述性消息。error_origin是一个可选字段,提供有关错误来源的信息,例如涉及的源文件或账户。compared_values是一个可选字段,详细说明了发生错误时正在比较的值。这对于调试非常有用。
AnchorError实现了 log 方法 。这包括有关错误来源和涉及的值的信息,对于调试和错误解决非常有用。该方法使用error_origin和compared_values提供此信息。
AnchorError可以进一步细分为 Anchor 内部错误和自定义错误。Anchor 有一个很长的列表内部错误代码可以返回。这些内部错误不应该由用户使用。但是,了解代码和原因之间的映射是有用的。通常在违反约束时会抛出这些内部错误。内部错误代码遵循此模式:
- >= 100 是指令错误代码
- >= 1000 是 IDL 错误代码
- >= 2000 是约束错误代码
- >= 3000 是账户错误代码
- >= 4100 是杂项错误代码
- = 5000 是弃用的错误代码。
自定义错误从 ERROR_CODE_OFFSET(即 6000)开始。
开发人员可以使用error_code属性实现自定义错误。此属性用于枚举,并且枚举的变体可以在整个程序中用作错误。可以为每个变体添加消息。如果发生错误,客户端可以显示此消息。例如:
#[error_code]
pub enum HeliusError {
#[msg(“This RPC provider is too good”)]
RPCTooGood
}require!(rpc.speed > 9000, HeliusError::RPCTooGood);需要注意的是,有多个可供选择的require宏 。其中绝大多数宏关注非公钥值。例如,require_gte宏检查第一个非公钥值是否大于或等于第二个非公钥值:
pub fn set_data(ctx: Context<SetData>, data: u64) -> Result<()> {
require_gte!(ctx.accounts.data.data, 1);
ctx.accounts.data.data = data;
Ok(());
}在比较公钥时也有一些注意事项。例如,开发人员应该使用require_keys_eq而不是require_eq,因为后者更昂贵。
所有程序都将返回一个 ProgramError。此错误类型包括一个专门用于自定义错误编号的字段,Anchor 用它来存储其内部和自定义错误代码。但是,这只是一个数字,因此并不是很有用。Anchor 的AnchorError日志记录和解析要比这更有帮助。Anchor 客户端旨在解析这些日志。但是,在某些情况下,这可能会有挑战。例如,关闭预检查的情况下检索已处理事务的日志并不那么直接。同样,Anchor 还为不以标准方式记录AnchorError的非 Anchor 或旧程序采用了回退机制。在这种情况下,Anchor 会检查事务返回的错误编号是否对应于 Anchor 内部错误代码或程序的 IDL 中定义的错误编号。当找到匹配时,Anchor 会丰富错误信息以提供更多上下文。Anchor 还会尝试在可能的情况下解析程序错误堆栈,以追溯到程序错误的原因。ProgramError作为基础错误类型,其实用性通过 Anchor 的日志记录和解析机制得到增强,以提供详细的错误信息。
跨程序调用(CPI)
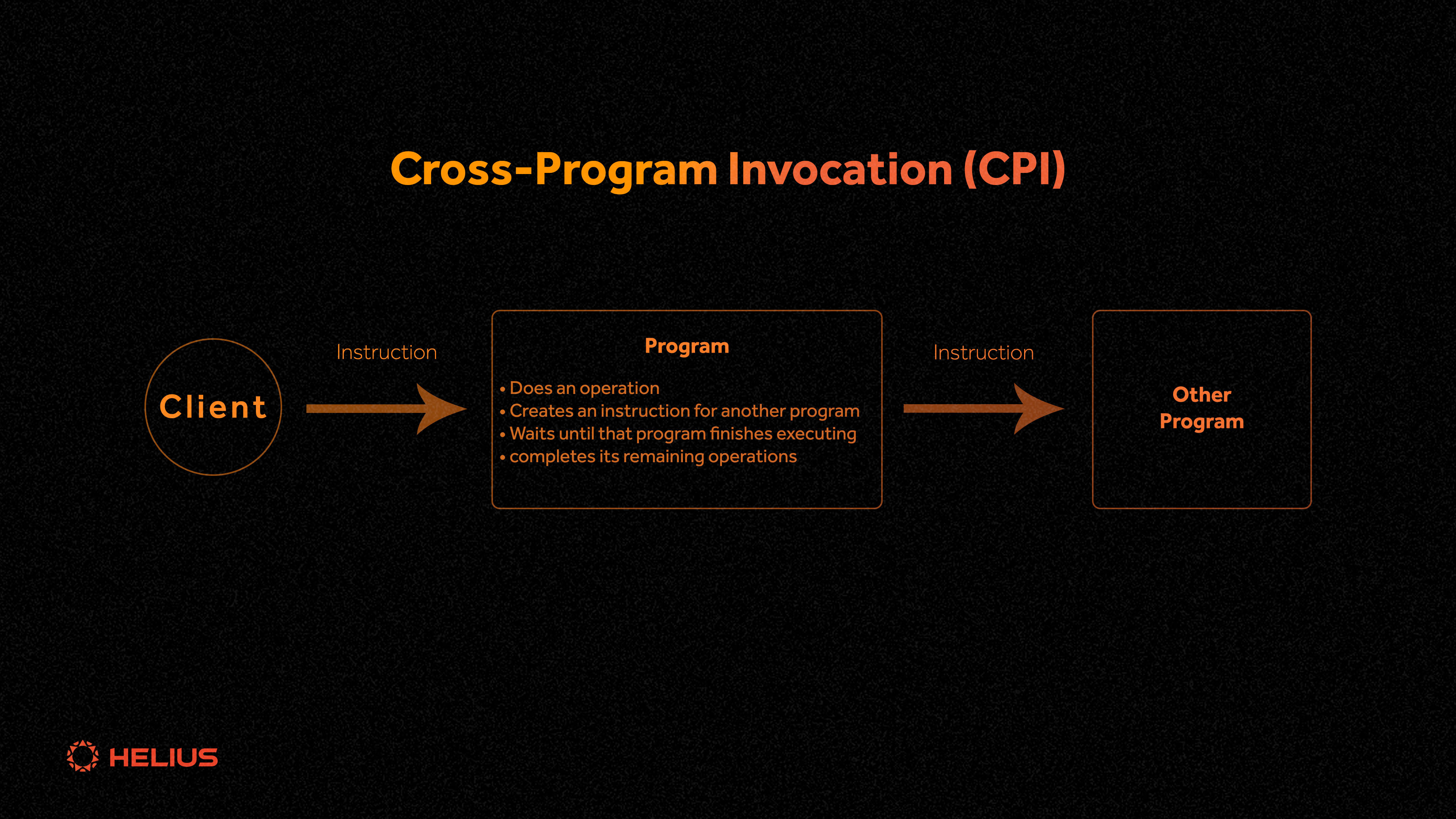
改编自 Solana 的Solana Bytes - 跨程序调用 YouTube 视频
跨程序调用(CPIs)已在本文中多次提到,因此我们有一个专门的部分来介绍它们。CPI 对 Solana 的可组合性至关重要,因为它们使程序能够直接调用其他程序。这将 Solana 生态系统转变为一个庞大的、相互连接的 API(如果想供开发人员使用的话)。为了简洁起见,建议阅读 Anchor 关于 CPI 的文档 ,因为它们提供了 CPI 在使用puppet 和 puppet 主程序中的实际示例。
尽管如此,CPI 可以定义为从一个程序调用另一个程序,目标是调用程序中的特定指令。调用程序将一直悬停,直到被调用程序完成处理指令。
特权提升
CPI 使调用程序能够将其签名者特权扩展到被调用程序。特权扩展很方便,但潜在风险很大。如果 CPI 意外地针对了一个恶意程序,那么该程序将获得与调用者相同的特权。Anchor 通过两个保障来减轻这一风险:
- Program<’info, T>类型确保指定的账户与预期的程序(T)匹配
- 即使没有使用Program类型,自动生成的 CPI 函数也会验证cpi_program参数是否对应于预期的程序
执行 CPI
程序可以使用 solana_program 中的invoke或invoke_signed来执行 CPI。Anchor 还提供了 CpiContext 结构体来指定 CPI 的非参数输入。
invoke
当不需要 PDA 作为签名时,使用invoke函数。在这种情况下,运行时将原始签名从调用程序扩展到被调用程序。该函数定义如下:
pub fn invoke(
instruction: &Instruction,
account_infos: &[AccountInfo<'_>]
) -> ProgramResult
调用另一个程序涉及创建一个包括程序 ID、被调用程序的指令数据以及被调用方将访问的账户列表的Instruction。程序只会在其程序入口点从运行时接收AccountInfo值。被调用程序需要的任何账户都必须包含在调用程序提供的AccountInfo值列表中。例如,如果被调用程序需要修改特定账户,则调用程序必须在AccountInfo值列表中包含该账户。这也适用于被调用方的程序 ID(即,调用方必须明确指定调用的程序,包括被调用方的程序 ID)。
Instruction通常在调用程序中构建,尽管它可以从外部输出进行反序列化。
如果被调用程序遇到错误或中止,整个交易将立即失败。这是因为invoke函数除了成功之外不会返回任何内容。使用set_return_data或get_return_data函数来返回 CPI 的结果数据。请注意,返回的类型必须实现AnchorSerialize和AnchorDeserialize traits。或者,让被调用方写入一个专用账户来存储数据。
虽然程序可以递归调用自身,但是由另一个程序进行的间接递归调用(即递归攻击 )将立即导致交易失败。
例如,如果我们有一个通过 CPI 转移代币的程序,我们将使用invoke如下:
pub fn set_data(ctx: Context<SetData>, data: u64) -> Result<()> {
require_gte!(ctx.accounts.data.data, 1);
ctx.accounts.data.data = data;
Ok(());
}invoke_signed
invoke_signed用于需要 PDA 作为签名者的 CPI。它允许调用程序代表 PDA,提供生成它所需的种子:
pub fn invoke_signed(
instruction: &Instruction,
account_infos: &[AccountInfo<'_>],
signers_seeds: &[&[&[u8]]]
) -> ProgramResultPDA 也可以在 CPI 中充当签名者。运行时将使用提供的种子和调用程序的program_id内部生成 PDA,通过create_program_address验证 PDA 是否与指令中传递的地址(即account_infos)匹配,以确认其为有效签名者。
使用此函数,调用可以代表由调用程序控制的一个或多个 PDA 进行签名。signer_seeds包括用于生成 PDA 的种子切片。在调用过程中,运行时将任何匹配的账户在account_info中视为“已签名”。例如,如果我们有一个为 PDA 创建账户的程序,我们将如下调用invoke_signed:
invoke_signed(
&system_instruction::create_account(
&payer.key,
&vault_pda.key,
lamports,
vault_size,
&program_id,
),
&[
payer.clone(),
vault_pda.clone(),
],
&[
&[
b"vault",
payer.key.as_ref(),
&[vault_bump_seed],
],
]
)?;
CopyCpiContext
Anchor 提供了 CpiContext 作为一种更简化的方式来进行 CPI,而不是使用invoke或invoke_signed。该结构体指定了 CPI 所需的非参数输入,与Context的功能密切相关。它提供了有关指令所需的账户信息、涉及的任何其他账户、被调用的程序 ID 以及如有必要的 PDA 派生种子的信息。对于不需要 PDA 的 CPI,请使用CpiContext::new,对于需要 PDA 签名的 CPI,请使用CpiContext::new_with_signer。
CpiContext定义如下,其中T是一个泛型类型,包括任何实现ToAccountMetas和ToAccountInfos<’info> traits 的对象:
pub struct CpiContext<'a, 'b, 'c, 'info, T>where
T: ToAccountMetas + ToAccountInfos<'info>,{
pub accounts: T,
pub remaining_accounts: Vec>,
pub program: AccountInfo<'info>,
pub signer_seeds: &'a [&'b [&'c [u8]]],
}
Accounts是一个泛型类型,允许任何实现ToAccountMetas和ToAccountInfos<’info> traits 的对象。这是通过#[derive(Accounts)]属性宏来实现的,以促进代码组织和增强类型安全性。
CpiContext简化了调用 Anchor 和非 Anchor 程序。对于 Anchor 程序,只需在项目的Cargo.toml文件中声明依赖项,并使用 Anchor 生成的cpi模块:
[dependencies]
callee = { path = "../callee", features = ["cpi"]}设置features = [“cpi”]将使程序可以访问callee::cpi模块。Anchor 会自动生成此模块,并将程序的指令公开为 Rust 函数。此函数接受一个CpiContext和任何额外的指令数据,与 Anchor 程序中常规指令函数的格式相似,但CpiContext替换了Context。cpi模块还提供了调用指令所需的必要账户结构。
例如,如果被调用程序有一个名为hello_there的指令,需要在GeneralKenobi结构中定义特定账户,可以如下调用:
// We assume "jedi" is an Anchor program with a published crate
use jedi::cpi::accounts::GeneralKenobi;
use jedi::cpi::hello_there;
use anchor_lang::prelude::*;
#[program]
pub mod fight_on_utapau {
use super::*;
pub fn call_hello_there(ctx: Context<CallGeneralKenobi>, data: GreetingParams) -> Result<()> {
let cpi_accounts = GeneralKenobi {
jedi: ctx.accounts.jedi.to_account_info(),
// Other account infos needed for the GeneralKenobi struct go here
};
let cpi_program = ctx.accounts.jedi_program.to_account_info();
let cpi_ctx = CpiContext::new(cpi_program, cpi_accounts);
hello_there(cpi_ctx, data);
}
#[derive(Accounts)]
pub struct CallGeneralKenobi<'info> {
pub jedi: UncheckedAccount<'info>,
pub jedi_program: Program<'info, Jedi>,
// Other required accounts
}
pub struct GreetingParams {
// Params required for the hello_there function
}
在fight_on_utapau模块中,使用CpiContext执行了一个 CPI。函数call_hello_there旨在与jedi程序交互。它创建了一个包含来自jedi程序的GeneralKenobi账户结构所需的账户信息和jedi程序的账户信息的CpiContext。此上下文调用hello_there,传入由GreetingParams结构指定的任何额外所需参数。CallGeneralKenobi结构定义了此函数所需的账户,简化了整个过程。
最后,当从非 Anchor 程序调用指令时,请检查程序维护者是否已发布了包含用于调用其程序的辅助函数的 crate。如果没有任何程序的指令必须被调用的辅助函数,就回退到使用invoke和invoke_signer来组织和准备 CPI。
程序派生地址(PDA)
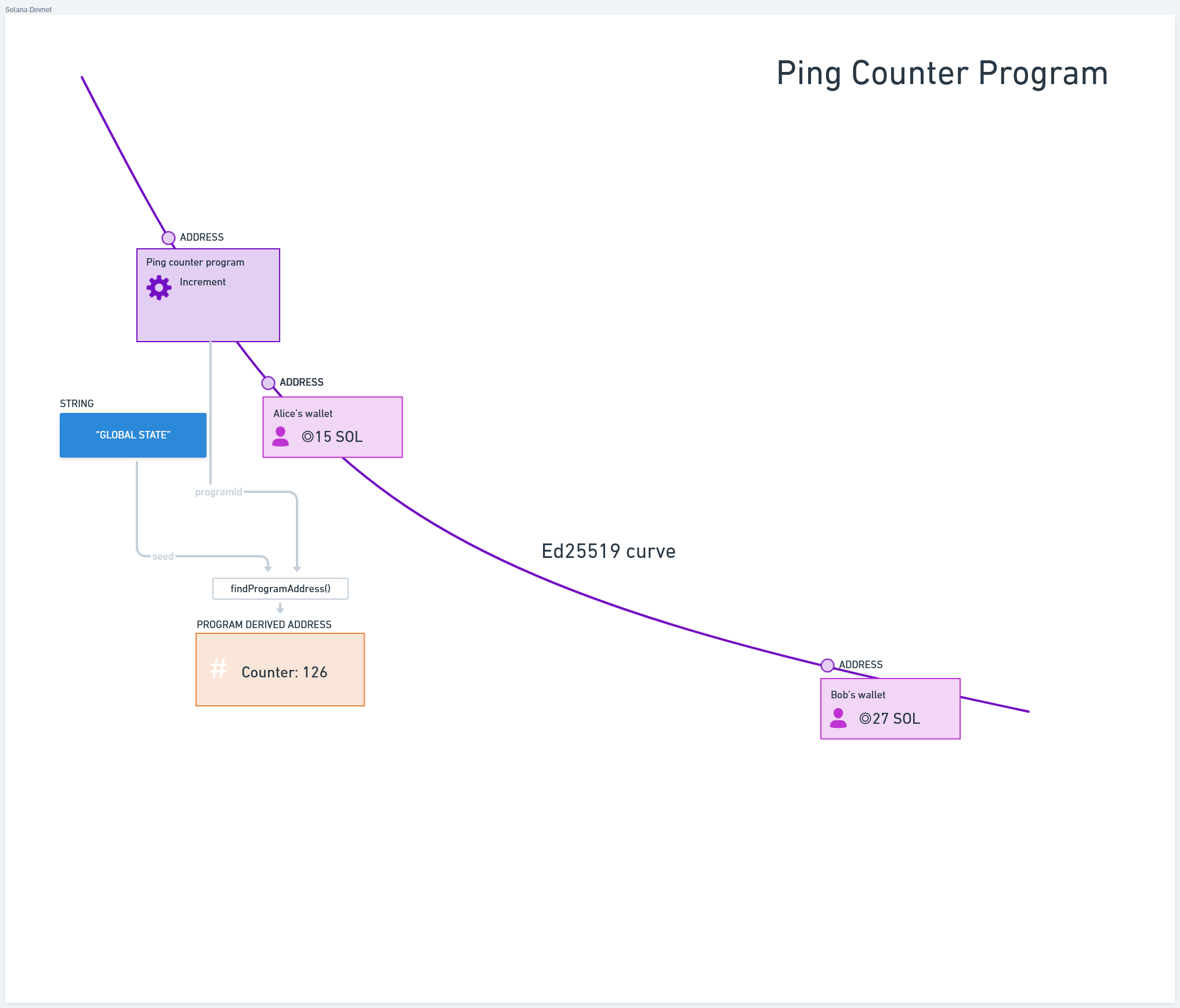
来源: 由Solana Foundation提供的基本 Ping Counter 程序示例
请记住,PDAs 是离散的,没有关联的私钥。它们允许程序签署指令,并允许开发人员在链上构建类似哈希映射的结构。PDA 是使用可选种子列表、bump seed 和程序 ID 派生的。
重申一下,以下约束用于检查给定账户是否是从当前执行程序、种子以及如果提供的话,bump 派生的 PDA:
- #[account(seeds = <seeds>, bump)]
- #[account(seeds = <seeds>, bump, seeds::program = <expr>)]
- #[account(seeds = <seeds>, bump = <expr>)]
- #[account(seeds = <seeds>, bump = <expr>, seeds::program = <expr>)]
如果未提供 bump,则 Anchor 将使用规范的 bump。Seeds::program = <expr> 可用于从不同于当前执行程序的程序派生 PDA。
使用seeds和bump约束可以简化派生过程:
#[derive(Accounts)]
struct ExamplePDA<'info> {
#[account(seeds = [b"example"], bump)]
pub example_pda: Account<'info, AccountType>,
}
在这里,seeds约束用于派生 PDA。Anchor 会自动验证传递到指令的账户是否与从 seeds 派生的 PDA 匹配。当未提供特定值的情况下使用 bump 约束时,Anchor 会默认使用规范的 bump。
Anchor 还允许基于其他账户字段或指令数据动态生成 seeds。这可以通过在结构体内引用其他字段或使用#[instruction(...)]属性宏来包含反序列化的指令数据来实现。例如,在以下结构体中,example_pda受限于使用静态 seed、指令数据和签名者的公钥的组合:
#[derive(Accounts)]
#[instruction(instruction_data: String)]
pub struct ExamplePDA<'info> {
#[account(seeds = [b"example", signor.key().as_ref(), instruction_data.as_bytes()], bump)]
pub example_pda: Account<'info, AccountType>,
#[account(mut)]
pub signoooorrr: Signer<'info>
}结论
称 Anchor 为一个强大的框架实在是轻描淡写。在我们探索 Anchor 使用的各种宏和traits以减少代码的过程中,它简化开发流程的能力是显而易见的。Anchor 得到了完善的文档支持,并拥有相关教程和 crate 的强大生态系统。Anchor 深受 Solana 开发者的喜爱和使用。
本文是一篇非常、非常全面的 Anchor 程序开发指南。它涵盖了安装 Anchor,使用 Solana Playground,以及创建、构建和部署 Hello, World!程序。然后,我们探讨了 Anchor 的有效抽象方法,典型 Anchor 程序的结构以及许多可用的账户类型和约束。它还涵盖了委托账户空间和错误处理的重要性。最后,我们探讨了 CPIs 和 PDAs。这是完整的Anchor 文章 - 它包含了你今天开始在 Solana 上开发程序所需的一切。
如果你读到这里,非常感谢!这样你就不会错过 Solana 的最新动态。准备深入了解吗?加入我们的 Discord 开始开发 Anchor 程序。
附加资源
- Anchor Book
- Anchor 文档
- anchor_lang crate
- Solana Cookbook
- Solana 关于程序间调用的文档
- Solana Playground
- solana_program crate
- Solana 编程模型:Solana 开发入门
本翻译由 DeCert.me 协助支持, 在 DeCert 构建可信履历,为自己码一个未来。





