一篇文章整理主流共识算法
- Rayer
- 发布于 2024-06-17 18:23
- 阅读 6245
本文整理了主流的共识算法相关概述,有助于扫盲共识算法和相关概念。
本文章只对各个算法做描述性的文字介绍,概括大意,不介绍各个算法的实施细节。
当前常见的工作量算法
- Pow: 工作量证明,主要在 Bitcoin, Ethereum(1.0), Litecoin, Conflux, Dogecoin 等项目中使用。
- dPow: 延迟工作量证明,主要在 Komodo 项目中使用
- Pos:权益证明,主要在Ethereum(2.0), Peercoin 等项目中使用。
- Poa:权威证明,主要在 Ethereum Kovan Testnet, xDai, VeChain 等项目中使用
- Poh:历史证明,Solana 共识算法
- Dpos:委托权益证明,主要在 BitShares, Steemit, EOS , Lisk 和 Ark 等项目中使用
- Paxos: Paxos 算法,ZooKeeper 使用,ZooKeeper 用于联盟链场景
- Raft:Raft 算法,在联盟链中用得比较多
- PBFT:拜占庭容错算法,在 HyperLedger Fabric(<1.0 版本), Stellar, Ripple 和 Dispatch 等项目中使用
- dPBFT:授权拜占庭容错,NEO 项目中使用
- rBPFT:轮流拜占庭容错
- Tendermint-BFT:Tendermint-BFT 算法,使用 cosmos sdk 的很多项目都使用该共识算法
- Avalanche-BFT:Avalanche-BFT 算法,主要在 Avalanche 中使用
- HotStuff-BFT:HotStuff-BFT 算法,Aptos-BFT 算法基于 HotStuff
- Aptos-BFT:Aptos-BFT 算法,主要在 Aptos 项目中使用
PoW 工作量证明
工作量证明(PoW)被比特币和其他众多加密货币均使用工作量证明机制来保护自身区块链网络和数据的安全。
PoW要求矿工(创建区块的用户)投入电力和算力等资源,对候选区块的数据进行hash运算,直至找到破解难题的方案。
换言之,矿工必须验证和收集待处理的交易,并将这些交易整理成一个候选区块,并将该区块的数据带入哈希函数生成有效的哈希值。矿工成功找到候选区块的有效哈希值后就会发布到网络中,将该区块添加到区块链中,然后获得挖矿奖励。
优点
可以防止双花攻击,安全性高。
缺点
这种共识算法花费了大量的电力资源,造成了资源一定程度上的浪费。
dPoW 延迟工作证明
延迟工作证明 (dPoW) 是一种混合共识方法,允许一个区块链利用通过辅助区块链的哈希能力提供的安全性。这是通过一组公证节点将数据从第一个区块链添加到第二个区块链来实现。
DPoW 共识机制不识别最长链规则来解决网络中的冲突,而是寻找之前插入到所选PoW区块链中的备份。
将 Komodo 交易备份插入安全 PoW 的过程就是“公证”。公证由当选的公证节点执行。大约每十分钟,公证节点就会执行在Komodo区块链上挖掘的特殊区块哈希,并记录Komodo区块链的整体“高度”。公证节点处理该特定块,以便它们的签名以加密方式包含在公证数据的内容中。
通过权益加权投票选出 64 个“公证节点”,其中 KMD 的所有权代表选举中的权益。他们是一种特殊类型的区块链矿工,其底层代码具有某些功能,使他们能够维护有效且具有成本效益的区块链,并且他们定期获得以“简单难度”开采区块的特权。
优点
高效节能,提升安全性
缺点
仅限于使用PoW和PoS的区块链中
PoS 股权证明
股权证明(PoS)机制使用一种算法来工作,该算法选择具有最高股权的参与者作为验证者,假设最高的利益相关者受到激励以确保交易得到处理。这个想法是,那些拥有最多流通代币的人损失最大,因此他们的定位是为了网络的利益而工作。网络可能需要的代币数量会发生变化,就像 PoW 的难度一样。
反对权益证明的常见论点是“无利害关系”问题。令人担忧的是,与 PoW 不同,验证者几乎不需要花费任何计算能力来支持分叉,因此验证者可以为每个发生的分叉的双方进行投票。 PoS 中的分叉可能比 PoW 中更为常见,一些人担心这可能会损害货币的可信度。
币龄
为了区分刚刚获得代币的用户和已经持有代币一段时间的用户,权益证明算法使用了币龄的概念。
币龄用于计算质押权重和质押奖励。质押奖励由代币的年利率决定。其效果是,无论输入大小或合理的停机时间如何,所有质押钱包都会获得稳定、一致的兴趣。
用户持有币的时间越长,赢得创建网络区块链区块并获得奖励的权利的变化就越大。
激励保持联系
为了保持大部分用户的活跃度,如果离线用户过多,则创建区块的奖励会增加,因此上线有更多好处。
惩罚离线用户
大多数PoS 算法都会惩罚那些长时间离线的持有者。他们可以通过重新连接来获得控制权,可以通过大量持有Stake来锁定自己的投票权。
如果不惩罚的话就对相当于放任他们空占区块的权益。
伪匿名用户
PoS 网络中的验证者是匿名用户,只能通过钱包地址来识别。对于那些可以在网络上积累大量财富的不良行为者来说,这不会比 PoW 提供额外的责任。
安全
安全模型是一种经济模型,基于“博弈论”假设,即获取成为区块生产者所需的代币的成本超过攻击者愿意承担的成本,它将网络的安全性与其价值结合起来。代币,即:代币的价值越高,网络就越安全。
无利害关系攻击
如果不对攻击者进行经济处罚,该链可能会遭受无利害关系攻击,其中质押者会被激励验证所有提议的分叉以最大化其回报。
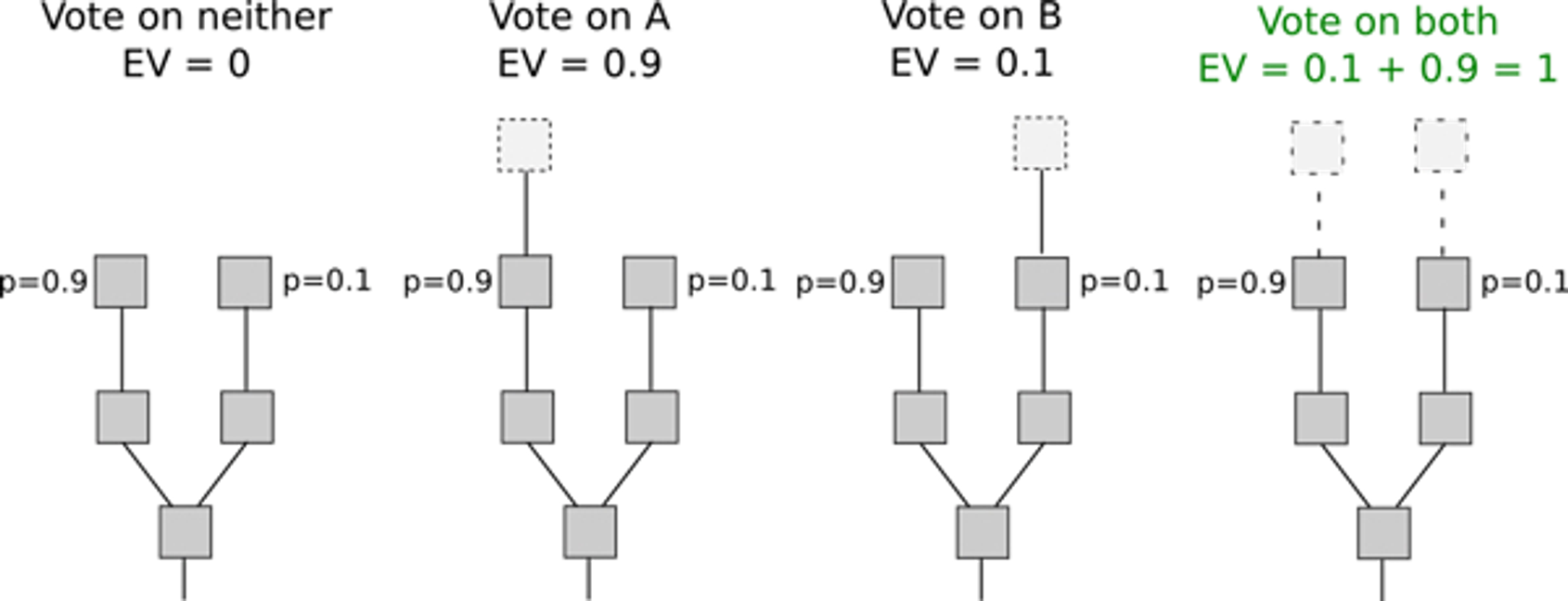
算法
- 验证者必须锁定一些代币作为权益。
- 之后,他们将开始验证这些块。这意味着,当他们发现一个他们认为可以添加到链中的区块时,他们将通过下注来验证它。
- 如果该块被附加,那么验证者将获得与其下注成比例的奖励。
优点
- 使用网络并拥有代币的人越多,网络就越安全。
- 成本效益:速度、能源、硬件上都有提效
- 更加去中心化
缺点
- 经济不平等,富者愈富
- 攻击者可以根据谁拥有多少币来计算赢得创建区块链奖励的概率。
- 无利害关系攻击
PoA 权威证明
在基于 PoA 的网络中,交易和区块由经过批准的帐户(称为Validator)进行验证。验证者运行的软件允许他们将交易放入区块中。该过程是自动化的,不需要Validator持续监控他们的计算机。然而,它确实需要维护计算机(the authority node)不受损害。通过 PoA,个人获得了成为Validator的权利,因此有动力保留他们已经获得的职位。通过将声誉附加到身份上,Validator就会受到激励来维护交易过程,因为他们不希望自己的身份附加到负面声誉上。
该共识算法被用于POA网络、Ethereum Kovan、testnet Rinkeby。
PoA被认为比PoS更稳健,因为:
- 在PoS中,虽然双方的股份可能相等,但它没有考虑每一方的总持股量,这意味着激励可能不平衡。
- PoW使用大量的计算能力,这本身就降低了激励。
建立Authority
建立validator必须满足的三个主要条件:
- 身份必须在链上进行正式验证,并且可以在公开领域中交叉检查信息。
- 资格必须难以获得,有权验证所获得和估价的区块。例如,潜在的验证者需要获得公证员执照。
- 建立权威机构的检查和程序必须完全统一。
优点
- 高吞吐量,可扩展性
- 没有挖矿机制,PoA使用身份作为权威的唯一验证
- PoA适用于专用网络和公共网络
- PoA只允许一个Validator进行非连续的区块批准,这意味着风险最小化
缺点
- 这是一个比较中心化的系统。
PoH
历史证明可以证明事务发生在事件之前和之后的某个时间,而不是信任事务上的时间戳。历史证明是一种高频可验证延迟函数。可验证延迟函数需要特定数量的连续步骤来进行评估,但会产生可以有效且公开验证的独特输出。
历史证明是一系列计算,可以提供一种以加密方式验证两个事件之间时间流逝的方法。
- 它使用编写的加密安全函数,因此无法从输入预测输出,并且必须完全执行才能生成输出。
- 该函数在单核上按顺序运行,其先前的输出作为当前输入,定期记录当前输出以及被调用的次数。
- 然后,外部计算机可以通过检查单独核心上的每个序列段来并行重新计算和验证输出。
- 通过将数据(或某些数据的散列)附加到函数的状态中,可以将数据打上时间戳到该序列中。
- 状态、索引和数据在附加到序列中时的记录提供了时间戳,可以保证数据是在序列中生成下一个哈希之前的某个时间创建的。
- 该设计还支持水平扩展,因为多个生成器可以通过将它们的状态混合到彼此的序列中来相互同步。
该算法在solana中使用。
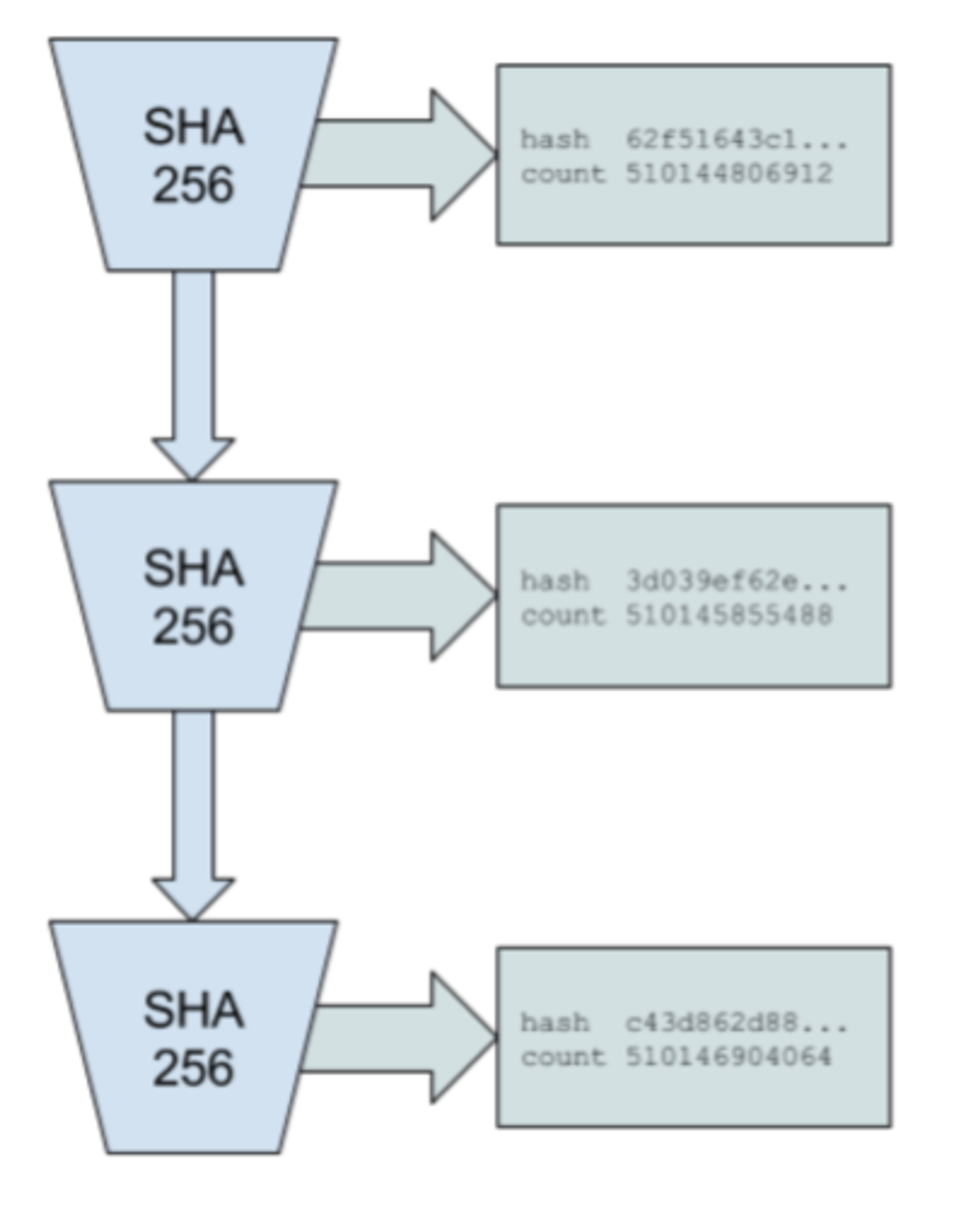
描述
该系统的设计原理如下。从某个随机起始值运行sha256哈希函数并获取其输出,并将其输出作为输入再传递给同一个函数。记录该函数的被调用次数以及每次调用的输出。选择的起始随机值可以是任何字符串。
只要所选择的哈希函数是抗冲突的,这组哈希值就只能由单个计算机线程按顺序计算。这是因为,如果不从起始值实际运行算法 300 次,就无法预测索引 300 处的哈希值将是什么。因此我们可以从数据结构推断出实时已经在索引 0 和索引 300 之间经过。
DPoS(Delegated Proof of Stake)
DPoS 是权益证明共识的一种变形,它依赖一组代表代表网络中的所有节点验证区块。
- 使用生成区块的Witnesses进行工作。
- Witnesses由每个Witness一股一票选出
然而,使用PoA时,权威的任命是自动的,这意味着不会因为不平等的stake而导致任何偏见或不公正的过程。
币龄是无关紧要的。所有成熟的代币都会添加相同的枝桠权重。
仅让活跃且少量投入的账户获取稳定且一致的收益。长时间离线活着过大的投入都会影响你的收益。
从好的方面说,不考虑币龄的设计会使钱币的流动性增加,因为失去币龄的成本较低。
在DPoS区块链共识协议中,代币持有者可以使用他们的代币余额来选举代表,称为Witnesses。这些Witnesses有机会质押新交易的区块,并将其添加到区块链中。投票权由网络财富决定。那些拥有更多代币的人将会获得更大的影响力。
DPoS和PoS有很大的不同:
- DPoS中,代币持有者不会对区块本身的有效性进行投票,而是投票选举代表,代表他们进行验证。
- DPoS通常有21-100名代表,代表会定期进行洗牌,会收到交付其区块的命令。
- 代表数较少可以让他们有效地组织起来,为每个代表创建制定的时间段来发布他们的区块。
- 如果代表不断错过他们的区块或发布无效交易,利益相关者就会投票淘汰他们,并用更好的代表取代他们。
- 在 DPoS 中,矿工可以合作出块,而不是像 PoW 和 PoS 那样竞争。通过部分集中化区块的创建,DPoS 的运行速度比大多数其他共识算法快几个数量级。
优点
- 便宜的交易
- 可扩展
- 高效节能
- 币龄无影响,代币权重相同
- 仅对活跃且少量投入的钱包才产生稳定一致的收益
- 停机时间和大量投入欧蕙影响收益
缺点
- 没有任何利害关系
- 部分中心化
Paxos算法
Paxos是1990年提出的一种基于消息传递且具有高度容错特性的共识算法。
解决的问题
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。基于消息传递通信模型的分布式系统,不可避免的会发生以下错误:进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复。在最普通的 Paxos 场景中,先不考虑可能出现“消息篡改”。
Paxos算法解决的问题是一个可能发生前述异常(即排除消息篡改之外的其他任何异常)的分布式系统中,如何对某个值的看法相同,保证无论发生以上任何异常,都不会破坏决议的共识机制。
算法
Paxos将角色分为proposers、acceptors和learners,允许某个节点身兼数职。
- proposer提出提案, 提案信息包括编号和内容。
- acceptors收到提案可以accept提案,若提案获得多数派的acceptros的接受,则称该提案被批准。
- learners只能“学习”被批准的提案。
划分角色后,定义问题:
- 提案只有在被proposer提出后才能被提准。
- 一次Paxos算法的执行实例中,只能批准(chosen)一个提案。
- learners只能获得被批准提案的值
通过一个决议分为两个阶段:
- prepare阶段:
- proposer选择一个提案编号n并将prepare请求发送给acceptors中的一个多数派;
- acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息(回复消息表示接受accept),则acceptor将自己上次接受的提案回复给proposer,并承诺不再回复小于n的提案;
- 批准阶段:
- 当一个proposer收到了多数acceptors对prepare的回复后,就进入批准阶段。它要向回复prepare请求的acceptors发送accept请求,包括编号n和根据P2c决定的value(如果根据P2c没有已经接受的value,那么它可以自由决定value)。
- 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept请求后即批准这个请求。
这个过程在任何时候中断都可以保证正确性。例如如果一个proposer发现已经有其他proposers提出了编号更高的提案,则有必要中断这个过程。因此为了优化,在上述prepare过程中,如果一个acceptor发现存在一个更高编号的提案,则需要通知proposer,提醒其中断这次提案。
决议的发布
一个显而易见的方法是当acceptors批准一个value时,将这个消息发送给所有learners。但是这个方法会导致消息量过大。
由于假设没有Byzantine failures,learners可以通过别的learners获取已经通过的决议。因此acceptors只需将批准的消息发送给指定的某一个learner,其他learners向它询问已经通过的决议。这个方法降低了消息量,但是指定learner失效将引起系统失效。
因此acceptors需要将accept消息发送给learners的一个子集,然后由这些learners去通知所有learners。
但是由于消息传递的不确定性,可能会没有任何learner获得了决议批准的消息。当learners需要了解决议通过情况时,可以让一个proposer重新进行一次提案。注意一个learner可能兼任proposer。
Progress的保证
根据上述过程当一个proposer发现存在编号更大的提案时将终止提案。这意味着提出一个编号更大的提案会终止之前的提案过程。如果两个proposer在这种情况下都转而提出一个编号更大的提案,就可能陷入活锁,违背了Progress的要求。一般活锁可以通过 随机睡眠-重试 的方法解决。这种情况下的解决方案是选举出一个leader,仅允许leader提出提案。但是由于消息传递的不确定性,可能有多个proposer自认为自己已经成为leader。
Multi-Paxos算法
原始的Paxos算法(Basic Paxos)只能对一个值形成决议,决议的形成至少需要两次网络来回,在高并发情况下可能需要更多的网络来回,极端情况下甚至可能形成活锁。
- 针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
- 在所有Proposers中选举一个Leader,由Leader唯一地提交Proposal给Acceptors进行表决。这样没有Proposer竞争,解决了活锁问题。在系统中仅有一个Leader进行Value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
Raft算法
Raft 是一种共识算法,旨在替代 Paxos。它通过逻辑分离的方式比 Paxos 更容易理解,但它也被正式证明是安全的,并提供了一些额外的功能。 Raft 提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意相同系列的状态转换。
Raft不是拜占庭容错算法。需要节点信任当选的领导者。
Raft被用于IPFS私有集群。
描述
raft的过程可以参考可视化网站http://thesecretlivesofdata.com/raft/
在Raft集群中,服务器可能是三种身份的其中一个:Leader,follower,candidate。正常情况只有一个Leader。Leader会负责所有的外部请求,如果是非Leader的机器收到消息,会被转发给Leader。
Leader通常会在固定的时间发送消息,这个过程被记作heartbeat。heartbeat让follower知道领袖还在工作,而每个follower都有timeout机制,当超过一定时间没有收到heartbeat,则会重新选举领袖。
Raft将问题拆成几个子问题:
- 领袖选举 Leader Election
- 记录复写 Log Replication
- 安全性 Safety
领袖选举
在算法起始,或者领袖死机断线时就要选出新的领袖。
选举是由candidate发动的。当heartbeat超时,follower就会把自己的任期编号+1,宣告竞选、投自己一票、并向其他服务器拉票。每个服务器在每个任期都只会头一票,固定投给最早拉票的服务器。
如果候选人收到其他候选人的拉票、而且拉票的任期编号不小于自己的任期编号,就会自认落选,成为追随者,并认定来拉票的候选人为领袖。如果有候选人收到过半的选票就当选为新的领袖。如果超时仍没有选出新领袖,此任期自动终止,开始新的任期并开始下一场选举。
Raft每个服务器的超时期限是随机的,这降低伺服务同时竞选的几率,也降低因两个竞选人得票都不过半而选举失败的几率。
记录复写
记录复写的责任在领袖身上。
整个集群有个复写的状态机(英语:state machine),可执行外来的指令。领袖接收指令,将之写入自己记录中的新指令部分,然后把指令转发给追随者。如果有追随者没反应,领袖会不断重发指令、直到每个追随者都成功将新指令写入记录为止。
当领袖收到过半追随者确认写入的消息,就会把指令视为已存储(英语:committed)。当追随者发现指令状态变成已存储,就会在其状态机上执行该指令。
当领袖死机时,领袖的某些新指令可能还没复写到集群整体,造成集群的记录处于不一致的状态。新领袖会担起重返一致的责任,让每个追随者的记录都和它的一致,做法是:和每个追随者比对记录,找出两者一致的最后一笔指令,删除追随者之后的指令,把自己之后的指令拷贝给追随者。这个机制完成时,每个服务器的记录就会一致。
安全性
Raft的安全性规则
Raft保证以下的安全性:
- 选举安全性:每个任期最多只能选出一个领袖。
- 领袖附加性:领袖只会把新指令附加(英语:append)在记录尾端,不会改写或删除已有指令。
- 记录符合性:如果某个指令在两个记录中的任期和指令序号一样,则保证序号较小的指令也完全一样。
- 领袖完整性:如果某个指令在某个任期中存储成功,则保证存在于领袖该任期之后的记录中。
- 状态机安全性:如果某服务器在其状态机上执行了某个指令,其他服务器保证不会在同个状态上执行不同的指令。
前四项保证的原因详见上述算法,状态机安全性则借由下述选举流程的限制所达到。
追随者死机
当某台追随者死机时,所有给它的转发指令和拉票的消息都会因没有回应而失败,此时发送端会持续重送。当这台追随者开机重新加入集群,就会收到这些消息,追随者会重新回应,如果转发的指令已经写入,不会重复写入。
领袖死机
领袖死机或断线时,每个已存储指令必定已经写入到过半的服务器中,此时选举流程会让记录最完整的服务器胜选。其中一个因素是Raft候选人拉票时会揭露自己记录最新一笔的信息,如果服务器自己的记录比较新,就不会投票给候选人。
超时期限和可用性
因为Raft启动选举是基于超时,使得超时期限的选择至为关键。若遵守算法的时限需求
广播时间 << 超时期限 << 平均故障间隔
就能达到稳定性。这三个时间定义如下:
- 广播时间 是单一服务器发送消息给集群中每台服务器并得到回应的平均时间,需要测量得到。
- 超时期限 是发动选举的超时期限,由部署Raft集群的人选定。
- 平均故障间隔 是服务器发生故障之间的平均时间,可以测量或估计得到。
广播时间典型是 0.5ms 到 20ms,平均故障间隔通常是用周或月来计算的,所以可以将超时期限设在 10ms 到 500ms。
PBFT 拜占庭容错算法
PBFT可以在少数节点作恶的情况下达成共识,在一个由(3f+1)个节点构成的系统中,只要有不少于(2f+1)个非恶意节点正常工作,该系统就能达成一致性。
节点类型
- Leader/Primary:共识节点,负责打包称区块和区块共识,每轮共识过程中有且只有一个Leader,为了防止Leader伪造区块,每轮PBFT共识后,均会切换Leader。
- Replica:副本节点。负责区块共识,每轮共识过程中有多个Replica节点,每个Replica节点的处理过程类似;
- Observer:观察者节点,负责从共识节点或者副本节点获取最新区块,执行并验证区块执行结果后,将产生的区块上链。
其中Leader和Replica统称为共识节点。
节点ID && 节点索引
为了防止节点作恶,PBFT共识过程中每个共识节点均对其发送的消息进行签名,对收到的消息包进行验签名,因此每个节点均维护一份公私钥对,私钥用于对发送的消息进行签名,公钥作为节点ID,用于标识和验签。
节点ID : 共识节点签名公钥和共识节点唯一标识, 一般是64字节二进制串,其他节点使用消息包发送者的节点ID对消息包进行验签
考虑到节点ID很长,在共识消息中包含该字段会耗费部分网络带宽,FISCO BCOS引入了节点索引,每个共识节点维护一份公共的共识节点列表,节点索引记录了每个共识节点ID在这个列表中的位置,发送网络消息包时,只需要带上节点索引,其他节点即可以从公共的共识节点列表中索引出节点的ID,进而对消息进行验签:
节点索引 : 每个共识节点ID在这个公共节点ID列表中的位置
视图
PBFT共识算法使用视图view记录每个节点的共识状态,相同视图节点维护相同的Leader和Replicas节点列表。
当Leader出现故障,会发生视图切换,若视图切换成功(至少2f+1个节点达到相同视图),则根据新的视图选出新leader,新leader开始出块,否则继续进行视图切换,直至全网大部分节点(大于等于2f+1)达到一致视图。
当Node3节点为拜占庭节点时,视图切换过程如下:
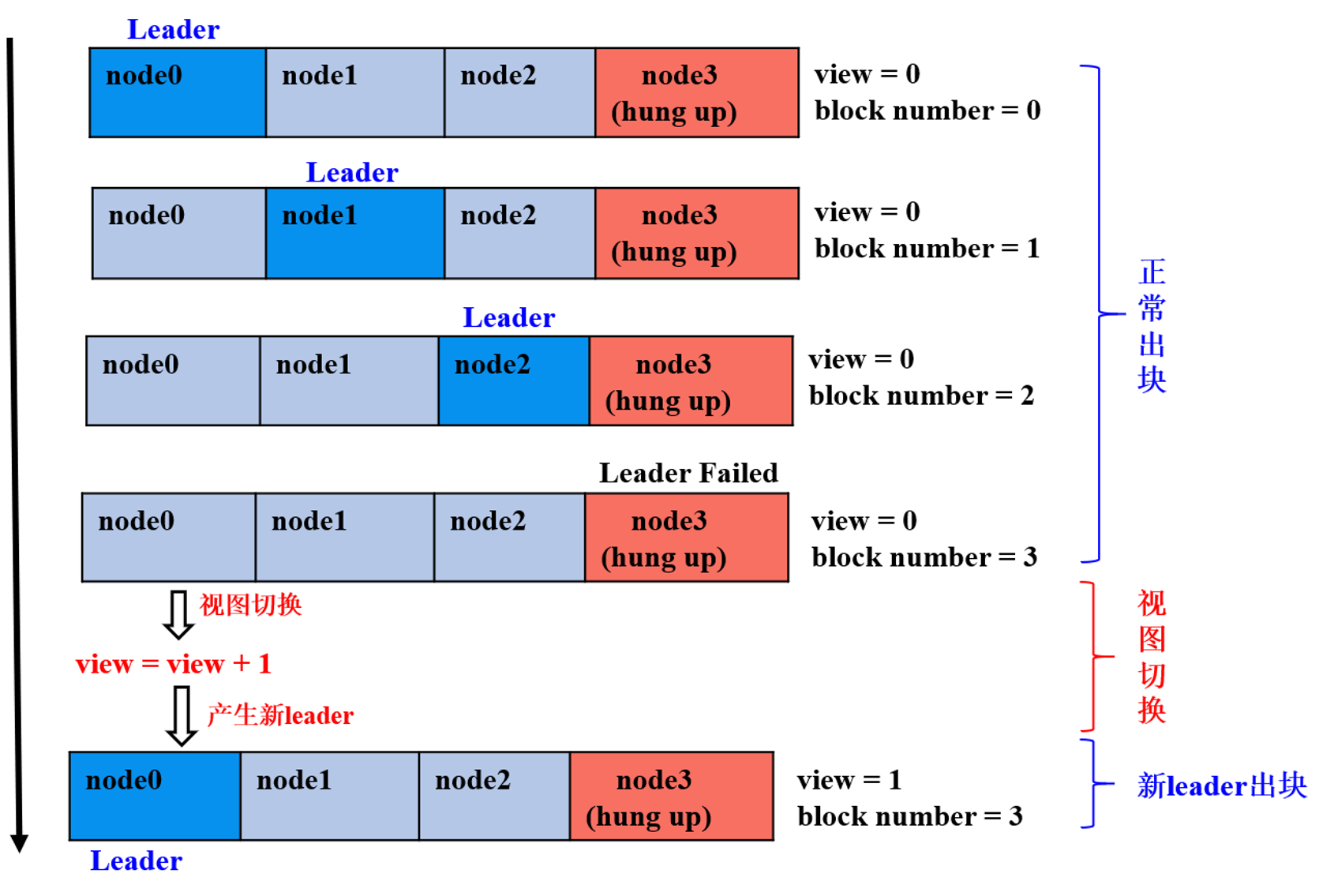
- 前三轮共识: node0、node1、node2为leader,且非恶意节点数目等于
2*f+1,节点正常出块共识; - 第四轮共识:node3为leader,但node3为拜占庭节点,node0-node2在给定时间内未收到node3打包的区块,触发视图切换,试图切换到
view_new=view+1的新视图,并相互间广播viewchange包,节点收集满在视图view_new上的(2*f+1)个viewchange包后,将自己的view切换为view_new,并计算出新leader; - 为第五轮共识:node0为leader,继续打包出块。
核心流程
PBFT共识主要包括Pre-prepare、Prepare和Commit三个阶段:
- Pre-prepare:负责执行区块,产生签名包,并将签名包广播给所有共识节点;
- Prepare:负责收集签名包,某节点收集满
2*f+1的签名包后,表明自身达到可以提交区块的状态,开始广播Commit包; - Commit:负责收集Commit包,某节点收集满
2*f+1的Commit包后,直接将本地缓存的最新区块提交到数据库。
dPBFT
未完待续
rPBFT
节点类型
- 共识委员: 执行PBFT公式流程的节点,有轮流出块权限。
- 验证节点:不执行公式流程,验证公式节点是否合法、区块验证,经过若干轮共识后,会切换共识节点。
核心思想
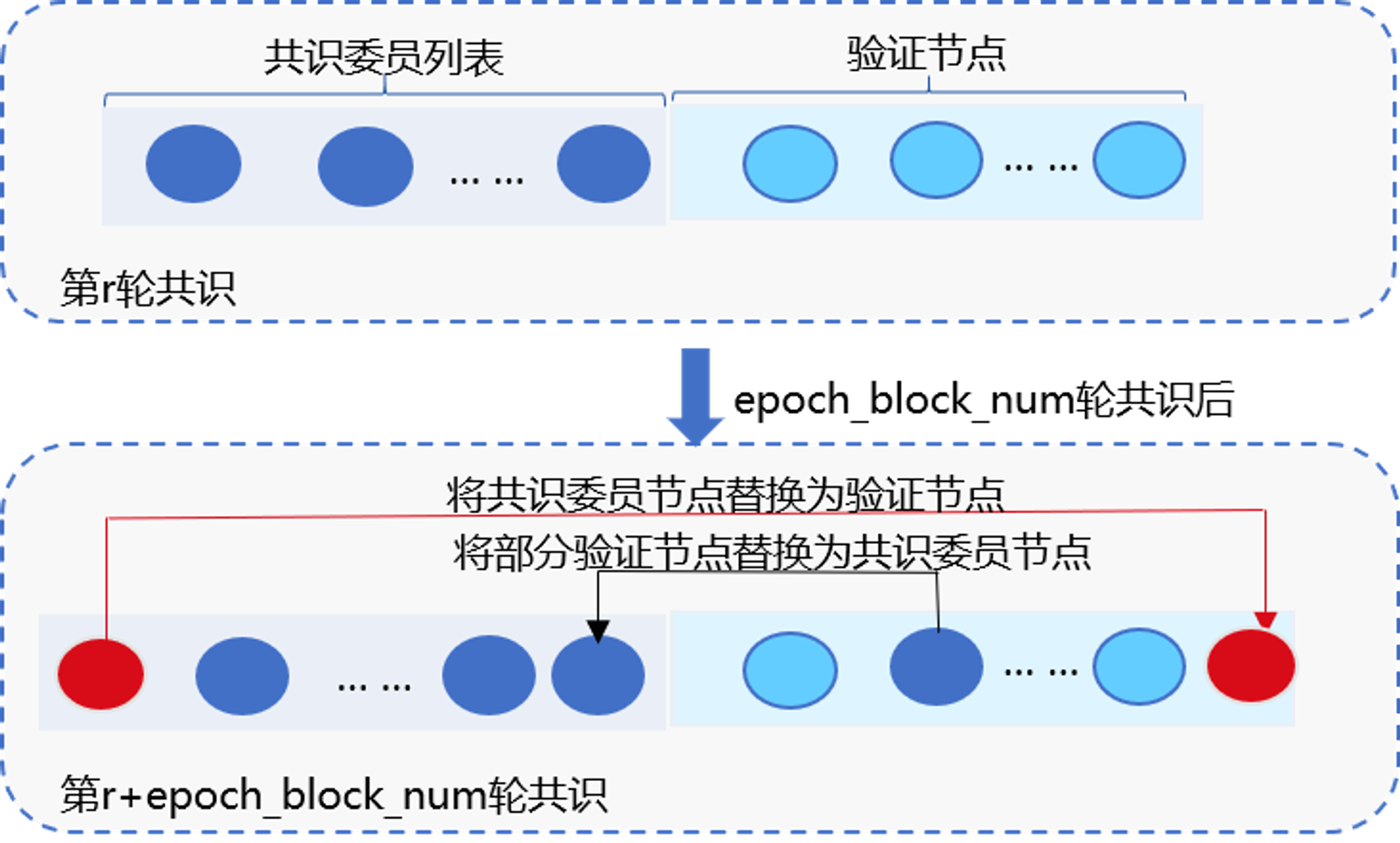
rPBFT算法每轮共识流程仅选取若干个共识节点出块,并根据区块高度周期性地替换共识节点,保障系统安全,主要包括2个系统参数:
epoch_sealer_num:每轮共识过程中参与共识的节点数目,可通过控制台发交易方式动态配置该参数epoch_block_num: 共识节点替换周期,为防止选取的共识节点联合作恶,rPBFT每出epoch_block_num个区块,会替换一个共识节点,可通过控制台发交易的方式动态配置该参数
算法流程
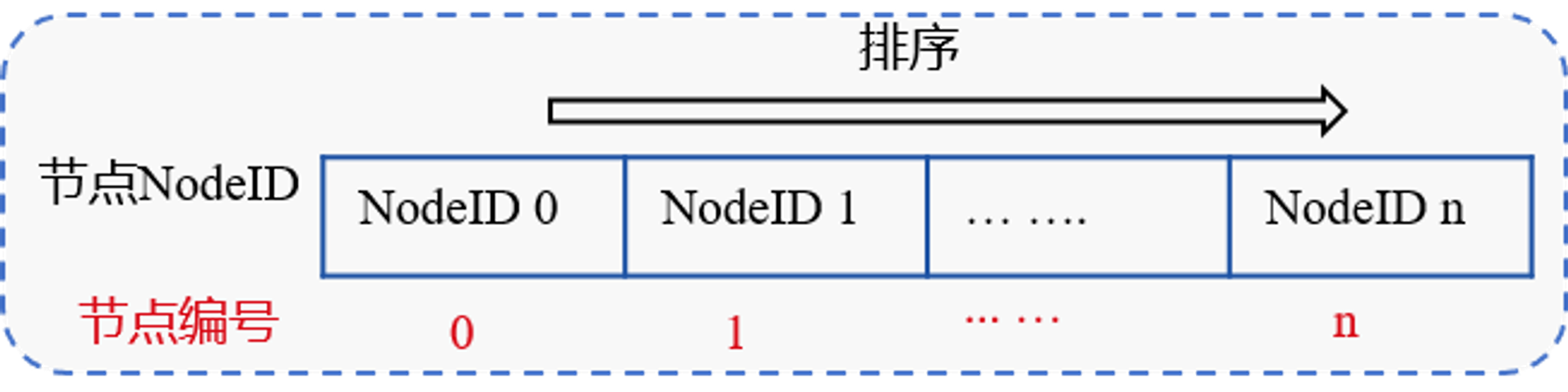
确定各共识节点编号IDX
对所有共识节点的NodeID进行排序,如下图,节点排序后的NodeID索引即为该共识节点编号:
链初始化
链初始化时,rPBFT需要选取epoch_sealer_num个共识节点到共识委员中参与共识,目前初步实现是选取索引为0到epoch_sealer_num-1的节点参与前epoch_block_num个区块共识。
共识委员节点运行PBFT共识算法
选取的epoch_sealer_num个共识委员节点运行PBFT共识算法,验证节点同步并验证这些共识委员节点共识产生的区块,验证节点的验证步骤包括:
- 校验区块签名列表:每个区块必须至少包含三分之二共识委员的签名
- 校验区块执行结果:本地区块执行结果须与共识委员在区块头记录的执行结果一致
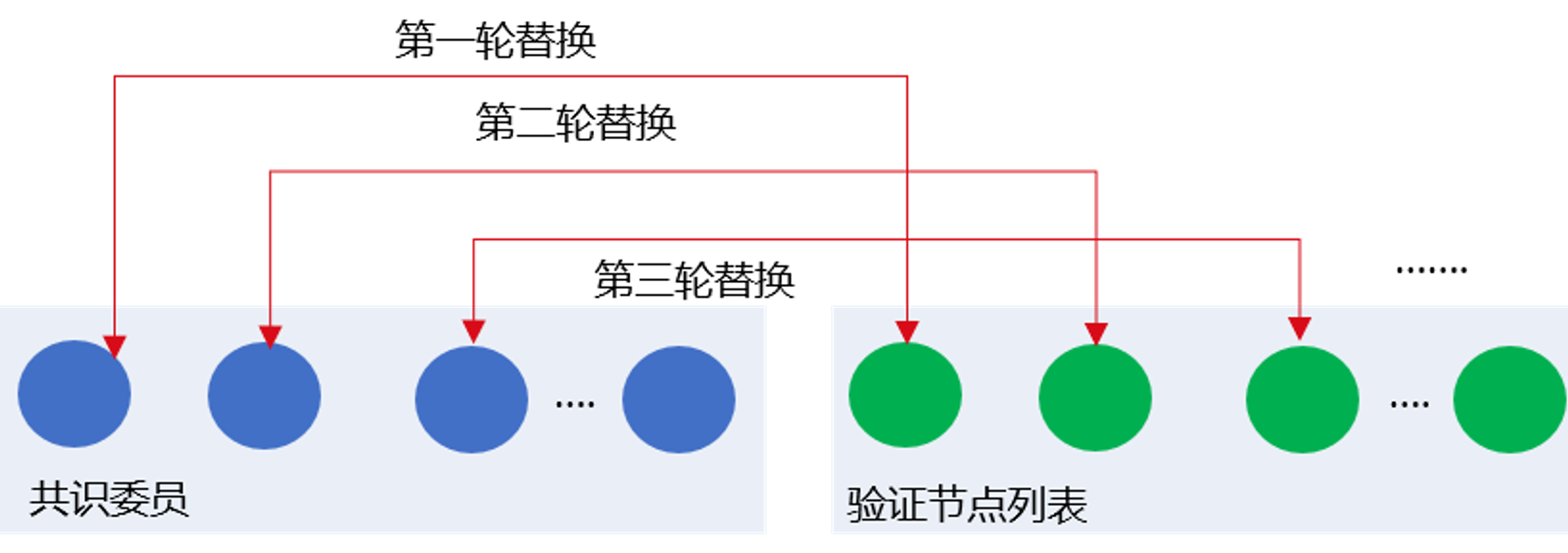
动态替换共识委员列表
为保障系统安全性,rPBFT算法每出epoch_block_num个区块后,会从共识委员列表中剔除一个节点作为验证节点,并加入一个验证节点到共识委员列表中,如下图所示:
节点重启
节点重启后,rPBFT算法需要快速确定共识委员列表,由于epoch_block_num可通过控制台动态更新,需要结合epoch_block_num最新配置生效块高获取共识委员列表,主要步骤如下:
计算共识周期rotatingRound
设当前块高为blockNum,epoch_block_num生效块高为enableNum,则共识周期为: rotatingRound = (blockNumber - enableNum) / epoch_block_num
确定共识委员起始节点索引: N为共识节点总数,索引从(rotatingRound * epoch_block_num) % N到(rotatingRound * epoch_block_num + epoch_sealer_num) % N之间的节点均属于共识委员节点
rPBFT算法分析
- 网络复杂度:O(epoch_sealer_num * epoch_sealer_num),与节点规模无关,可扩展性强于PBFT共识算法
- 性能:可秒级确认,且由于算法复杂度与节点数无关,性能衰减远小于PBFT
- 一致性、可用性要求:需要至少三分之二的共识委员节点正常工作,系统才可正常共识
- 安全性:未来将引入VRF算法,随机、私密地替换共识委员,增强共识算法安全性
Tendermint-BFT
Tendermint 是一致的 PoS BFT(Proof of Stake Bizantine 容错)共识算法,这意味着它可以容忍最多 1/3 的故障节点。
协议中的参与者
协议中的参与者称为Validators,他们轮流提议交易区块并对其进行投票。这些轮次根据验证者的权益总额使用循环调度分配给验证者。
协议中的另一个关键角色是Delegators。委托人是不想运行验证器操作的代币持有者(即投资必要的设备以便能够参与共识协议),顾名思义,他们将其股份代币委托给验证者,验证者收取佣金委托代币获得的相应费用。
共识概述
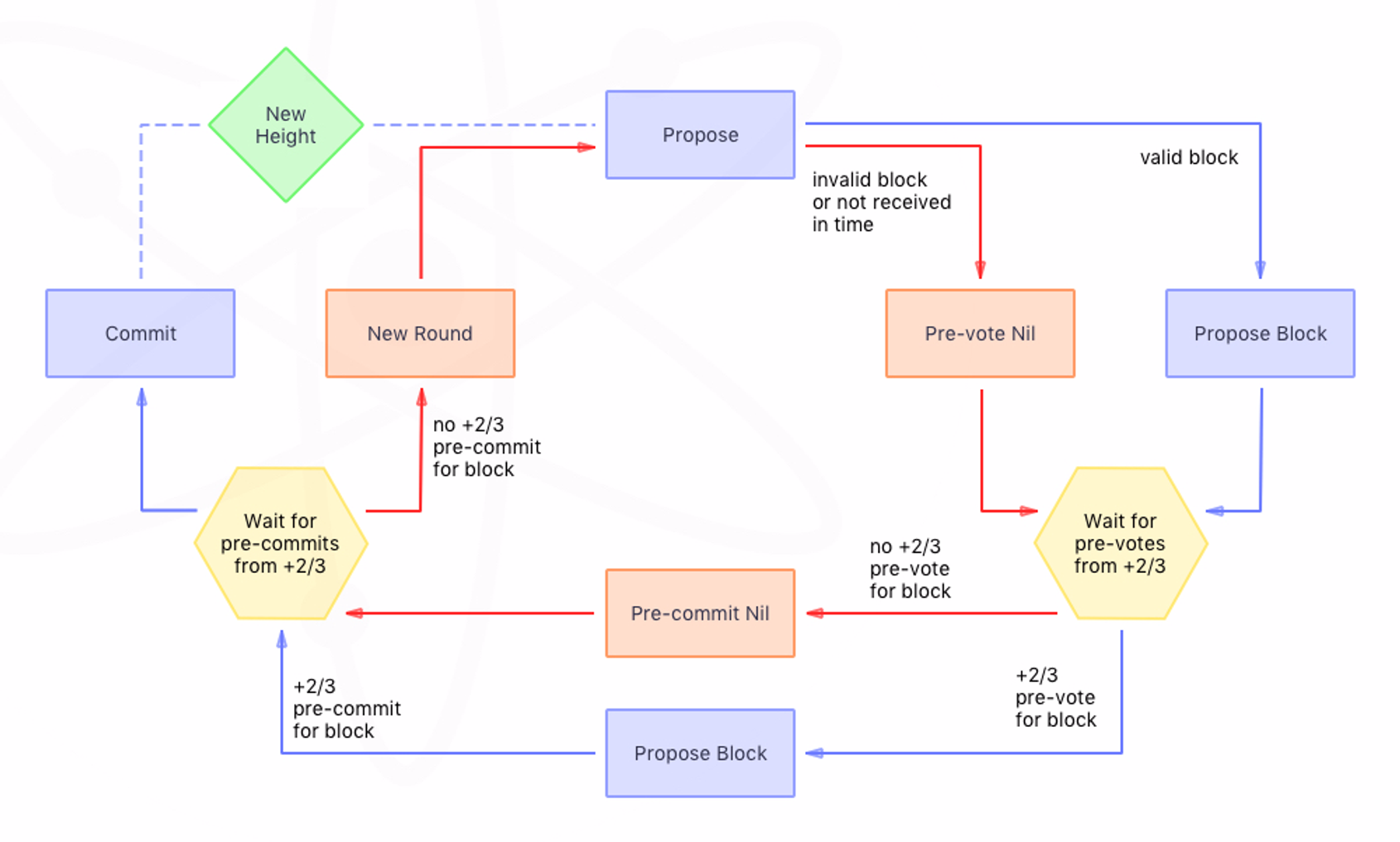
每个高度有一个区块被提交给链。 Tendermint BFT 的工作原理分为三个步骤:提议、预投票和预提交。序列 (Propose -> Pre-vote -> Pre-commit) 称为一轮。
理想的场景是 NewHeight -> (Propose -> Pre-vote -> Pre-commit)+ -> Commit -> NewHeight ->... 并按以下方式工作:
- Propose step
- 从验证者集中选择一个验证者节点作为给定高度的区块提议者。
- 验证者节点收集交易并将它们打包到一个区块中。提议的块被广播到其余节点。
- Pre-vote step
- 每个节点都会进行预投票并进行侦听,直到提交来自验证者节点的 +2/3 预投票。
- 块可以被预投票为预投票(即有效块)或
nil(当它无效或达到超时时)。当超过 2/3 的验证者对同一个区块进行预投票时,我们通常称为 Polka。 - 此外,从验证者的角度来看,如果验证者投票支持 Polka 中引用的区块,那么验证者现在在特定高度和轮次中拥有所谓的锁更改证明或简称 PoLC
(H, R)。
- Pre-commit step
- 一旦达到 Polka,验证者就会提交一个预提交块,否则他们会预提交
nil。广播后,他们等待同行的 +2/3 预提交。 - 最后,当验证者提交超过 +2/3 的预提交(又名提交)并且新选定的区块提议者达到新的区块高度时,提议的区块就会被提交。如果没有,网络将执行新一轮,并且该过程从头开始Propose step。
- 一旦达到 Polka,验证者就会提交一个预提交块,否则他们会预提交
需要考虑的一件重要事情是,这些预投票包含在下一个区块中,作为前一个区块已提交的证据 - 它们不能包含在当前区块中,因为该区块已经创建。
共识投票期间的锁定条件
为什么我们需要锁定条件?
- Pre-Vote step
- 首先,如果验证器从
LastLockRound开始就锁定在一个区块上,但现在在PoLC - Round轮(其中LastLockRound < PoLC - R < R)有一个PoLC来锁定其他东西,然后它解锁。 - 如果验证器仍然锁定在某个块上,它会对该块进行预投票。
- 首先,如果验证器从
- Pre-commit step
- 如果验证器在特定块 B 的
(H, R)处具有PoLC,它会(重新)锁定(或更改锁定)并预提交 B 并设置LastLockRound = R. - 否则,如果验证器在
(H, R)处有nil的PoLC,它会解锁并预提交nil。 - 否则,它保持锁定不变并预提交
nil。 nil的预提交意味着“我没有看到本轮的PoLC,但我确实获得了 +2/3 预投票并等待了一会儿”。
- 如果验证器在特定块 B 的
新一轮
当共识未能提交提议的区块时,需要进行新一轮。以下是可能发生这种情况的一些示例:
- 指定的提案人不在线。
- 指定提议者提议的区块无效。
- 指定提议者提议的区块没有及时传播(即超时)。
- 提议的区块是有效的,但在到达预提交步骤时,没有及时收到足够多的验证节点对提议区块的 +2/3 预投票。尽管需要 +2/3 的预投票才能进入下一步,但至少有一个验证者可能投了零票或恶意投票给其他东西。
- 提议的区块是有效的,并且足够的节点收到了 +2/3 的预投票,但是足够的验证者节点没有收到提议的区块的 +2/3 的预提交。
Avalanche-BFT
未完待续
HotStuff-BFT
未完待续
Aptos-BFT
未完待续





