HotStuff 工程设计与实现
- xufeisofly
- 发布于 2024-07-03 17:32
- 阅读 7741
文章从原生 HotStuff 出发,重点讨论 Chained HotStuff 的方案设计和工程实现。
本文内容源于 Shardora对 HotStuff 的工程实现。Shardora 是一条基于多分片扩容、多交易池并发共识的高性能区块链,使用 PoCE + HotStuff 来保证共识的性能与安全性。
原文:https://xufeisofly.github.io/blog/shardora-hotstuff
1 共识算法概述
共识算法用于实现各个副本之间的状态机复制(SMR)协议,是去中心化系统(如区块链)的核心部分,它保证了节点对当前系统状态能够达成统一的认知。
1.1 中本聪共识
比特币使用的工作量证明(PoW)和以太坊使用的权益证明(PoS)等共识算法,其核心逻辑是通过满足一个高难度的条件(比如挖矿耗费一定时间计算一个难题),成功后获得一个 Commit Proof。所有节点会对携带该证明的提案进行验证,若认可则无条件执行提交操作。这类“基于计算”的共识被称为中本聪共识(Nakamoto Consensus)。
中本聪共识的一个优势在于它对节点状态的容忍度较高,即使某些节点在提案广播时处于异常状态,或是节点本身存在恶意,也不会影响此次系统状态机的变更。另外,由于条件满足难度很大,中本聪共识具有极高的安全性,但代价是性能的牺牲,并且 Commit Proof 的计算不能过快,以避免频繁分叉影响系统状态的正确性。
1.2 拜占庭容错共识
另一类共识算法称为拜占庭容错共识(Byzantine fault tolerance 简称 BFT)。BFT 共识的核心思想是通过投票而非计算来达成共识。一个领导者(Leader)发起提案,所有副本(Replica)对该提案进行投票,当提案收到的同意票数达到某个阈值时,即可生成 Commit Proof。通常,一个提案需要多轮投票才能达成最终共识。
BFT 共识有一个前提,即拜占庭假设:拜占庭节点(如恶意或宕机)节点的数量必须少于总节点数的三分之一(即少于总节点数的 2/3+1)。由于投票行为容易作恶且成本低,而 PoW 这种「基于计算」的共识作恶成本很高(作恶者需要先完成计算),因此在同等条件下,BFT 共识的安全性低于主流的中本聪共识,尤其在节点数量较少时。一般认为,参与BFT共识的节点数量需要大于 600 才能保证安全。相比中本聪共识,BFT共识在性能上却具有绝对优势,通常出块时间可以达到百毫秒级别。然而,投票过程对带宽的占用很大,例如 PBFT(通信复杂度为O(n^2)),在节点数量超过 100 后,由于过高的带宽占用,系统吞吐量大幅降低。以下为中本聪共识和拜占庭容错共识对比。
| 中本聪共识 | 拜占庭类共识 | |
|---|---|---|
| 原理 | 基于计算 | 基于投票 |
| 安全性 | 高 | 较高,需要满足拜占庭假设 |
| 吞吐量 | 低 | 高 |
| 主要资源占用 | 计算资源 | 带宽资源 |
| 其他 | 易分叉 | 不分叉 |
2019 年提出的 HotStuff 将通信复杂度降低到O(n)级别,使得大规模节点通过投票进行共识成为可能。即便如此,为保证吞吐量,节点数量往往也不会过多。此类区块链(如 Facebook 的 Diem)通常是定期通过中本聪共识选举出一个共识委员会(节点个数存在上限),再在此委员会中使用 BFT 共识实现系统的高可扩展性,本文涉及的 Shardora 也是如此。HotStuff 是一种三阶段投票的共识协议,在工程实现中,通常使用它的链式版本 Chained HotStuff,并通过一系列工程优化来提高系统性能,降低代码复杂性。
文章从原生 HotStuff 出发,重点讨论 Chained HotStuff 的方案设计和工程实现。阅读本文无需对协议有深入研究。文章第一部分对 Basic HotStuff 协议进行基本介绍,以便于理解 Chained HotStuff,第二部分介绍 Chained HotStuff 设计方案,第三部分探讨在工程实现过程中遇到的部分问题以及相关优化措施。希望能对想要了解和实现 HotStuff 的读者有所帮助。
2 Basic HotStuff 介绍
HotStuff 是一种拜占庭容错共识协议,其最大的特点是将 BFT 协议过高的通讯复杂度降低到了 O(n) 级别,即使在异常情况下,仍能以O(n)的线性(Linearity)通讯复杂度进行视图切换,同时不牺牲系统即时响应的能力(Responsiveness)。
2.1 拜占庭假设
在一个去中心化系统中,恶意节点称为拜占庭节点,除此之外为诚实节点。以投票权重计算,系统总的投票权重为 N,拜占庭节点的投票权重为 f,那么只有系统满足 N > 3f 时才能保证共识的正确,此即为拜占庭假设。比如一个节点一票的情况下,需要至少2/3+1 的节点是诚实的。
拜占庭假设是 BFT 共识算法的前提条件,使得系统不会因为少数节点的恶意行为导致系统丧失安全性。
2.2 基本概念
HotStuff 共识算法中涉及一些基本概念:
- 视图(View):视图是共识流程的基本单位,发起一个视图即针对某个内容发起共识。视图也可称为共识高度,视图号 View 是单调递增的(但不一定严格单调)。
- 视图块(ViewBlock):对某个视图发起的共识内容进行打包,称为视图块。视图块即可作为区块链中的区块或是区块的载体。
- 视图链(ViewBlockChain):视图块通过哈希值连接父块,形成视图链。视图链就是一条区块链。
- 提案(Proposal): 主节点打包一个视图块并广播给所有副本节点,尝试达成共识。这个新打包的视图块称为提案。
- 群体证明(Quorum Certificate, 简称 QC):当某一个提案收到
2/3+1的签名投票后,即可产生一个群体证明 QC。QC 意味着有足够多的节点对该提案达成了共识,可作为该提案的合法性证明。 - 主节点(Leader)和从节点(Replica):HotStuff 节点分为主节点(Leader)和从节点(Replica)。正常情况下,Leader 有且仅有一个,其余为 Replica。Leader 同时也是一个 Replica。
在对一个视图进行共识时,Leader 会打包一个新提案并广播给 Replicas。Replica 验证通过后签名并返回投票,当收到2f+1的投票后,可以产生群体证明 QC。这就是 HotStuff 的基本通讯逻辑。
2.3 三阶段提交
在 HotStuff 共识算法中,一个提案从发起到最终提交需要经历三次投票。因此,原生 HotStuff 是一个三阶段的 BFT 协议(目前有研究将 HotStuff 改为两阶段,但会在某些特性上做出牺牲,这里只描述原生的三阶段 HotStuff)。下图展示了 Basic HotStuff 的各个阶段及其主要职责。
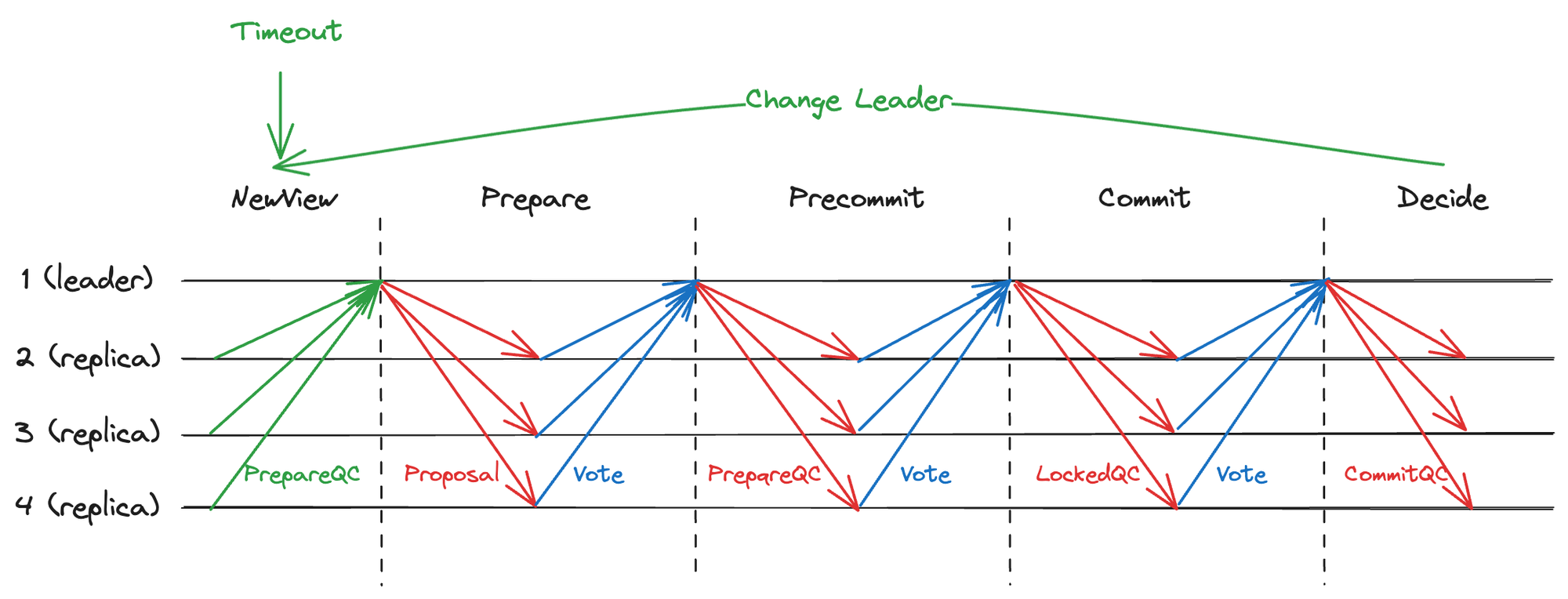 图 2.1 三阶段提交
图 2.1 三阶段提交
图中展示了五个阶段,所谓的三阶段指的是从节点有三次投票。
-
Prepare 阶段:
当一个区块要发起共识时,Leader 会打包提案 Proposal 并广播,Replicas 收到后需要完成一系列校验,校验通过后签名并返回投票。Leader 收到
2/3+1的投票后,即可产生一个群体证明 QC,此 QC 是该 Proposal 的第一个 QC,称为 PrepareQC。PrepareQC 表示有足够多的节点认可该提案。因此,拥有 PrepareQC 的节点会无条件认可该提案的合法性。
-
Precommit 阶段:
Leader 产生 PrepareQC 后,需要将 PrepareQC 同步给所有的 Replicas(虽然 Leader 知道提案是合法的,但其他节点还不知道),因此广播 PrepareQC。Replicas 收到后再次签名投票告知 Leader。Leader 收到超过
2/3+1的回执后,生成一个新的 QC,称为 PrecommitQC。PrecommitQC 表示大部分节点已经得知该提案的合法,该提案可以被随时提交。因此,拥有 PrecommitQC 的节点会认为该提案一定会被自己提交,PrecommitQC 也称为 LockedQC。
-
Commit 阶段:
Leader 产生 LockedQC 后,需要将其同步给其他节点,拥有 LockedQC 的节点认为该提案一定会被自己提交,但却不知道其他节点是否也一定会提交,贸然提交可能会导致状态不一致,因此再次签名返回投票。Leader 收到
2/3+1投票后生成一个 QC,称为 CommitQC。CommitQC 表示大部分节点都认为该提案会被自己提交。因此,拥有 CommitQC 的节点可以立刻执行提案,不用担心其他节点不提交提案造成状态不一致。
-
Decide 阶段:
Leader 广播 CommitQC(即 Commit Proof)给所有节点,收到命令的节点立刻提交该提案。需要说明的是,即使因为网络原因部分节点没有收到 CommitQC,之后也可以随时补发 CommitQC,保证最终一致性。
-
NewView 阶段:
NewView 是一个特殊阶段,用于开启一个新的共识。当一个视图 View 完成共识或因异常放弃共识时触发。此阶段的主要功能是切换大部分节点到新视图,并通过收集最后的共识信息,保证新视图的合法性。比如,原生 HotStuff 在此阶段会收集最新的 PrepareQC 以生成新视图,一些改进的 HotStuff 协议会对当前 View 进行签名投票,生成超时证明(Timeout Certificate),用于生成新视图并广播提案。
说明:工程实现中为提高安全性,每一个视图会进行 Leader 轮换。另外,Prepare 阶段可以同时承担上一个视图 Decide 阶段的功能,在新提案中打包上一个视图的 CommitQC,用来提高系统 TPS。
2.4 超时机制
超时策略是 HotStuff 乃至 BFT 类共识算法的核心部分,这一策略能够维持协议的活性,确保无论在什么情况下协议都不会卡死,并能通过某种方式恢复状态,继续出块。因此,超时的处理策略就是要找到最后的系统状态断点,并从该断点开始继续共识。这涉及到新 Leader 收集「共识状态断点」信息的问题。
为了便于理解,我们对所谓的共识状态简化为以下三个主要的部分:
- 新提案打包的交易(Transactions)
- 旧提案的群体证明(QC)
- 当前视图号(CurView)
一旦大部分节点对这三个内容达成新的共识,就会产生一个新的群体证明 QC,QC 的不断产生代表了系统状态机的不断演进。因此,通过收集最新的 QC,就能明确当前大部分节点最终达成共识的状态,「共识状态断点」信息的收集就变成了新 Leader 对于系统最新 QC 的收集。
其实,Basic HotStuff 和 Chained HotStuff 的视图和 QC 的对应关系是不同的。
- Basic HotStuff 中,一个视图拥有三个 QC(PrepareQC、LockedQC、CommitQC),它们是对同一个视图不同阶段的共识。
- Chained HotStuff 中,一个视图拥有一个 QC,此 QC 是对该视图内容的共识。
当超时而导致视图切换时,Basic HotStuff 通过收集最新的 PrepareQC 来恢复断点,而 Chained HotStuff 通过收集最新的 QC(即 HighQC)恢复断点。虽然对于「断点」信息的收集策略不同,但原理却是相通的,本节仅讨论 Basic HotStuff 的视图切换策略,而 Chained HotStuff 的视图切换策略将在后文中讨论。
2.4.1 主要超时方案对比
为了理解 HotStuff 超时方案的设计思路,我们需要了解一些主要 BFT 共识算法所用的方案。
一般来说,BFT 共识至少拥有两个阶段,Lock 阶段和 Commit 阶段。
- Lock 阶段:将验证通过的提案标记为 Locked,节点认为 Locked 提案一定会被自己执行(仅被该节点认为,并非系统共识),因此新提案不能与自己的 Locked 提案冲突。
- Commit 阶段:提交 Locked 提案。
当一个新提案到来时,节点需要检查新提案是否与本地最新的 Locked 提案冲突,若验证通过的节点数量超过 2f+1 ,即可 Lock 该提案,当新提案被超过 2f+1个节点 Lock 后,即可触发各个节点对提案的 Commit。
接下来我们假设一个超时场景,如下图:1 是主节点,2、3、4 为从节点,其中 4 为有恶意的拜占庭节点,系统满足拜占庭假设。在 LockedQC 广播时,2、3 接收 LockedQC 失败。之后因超时发生视图切换。
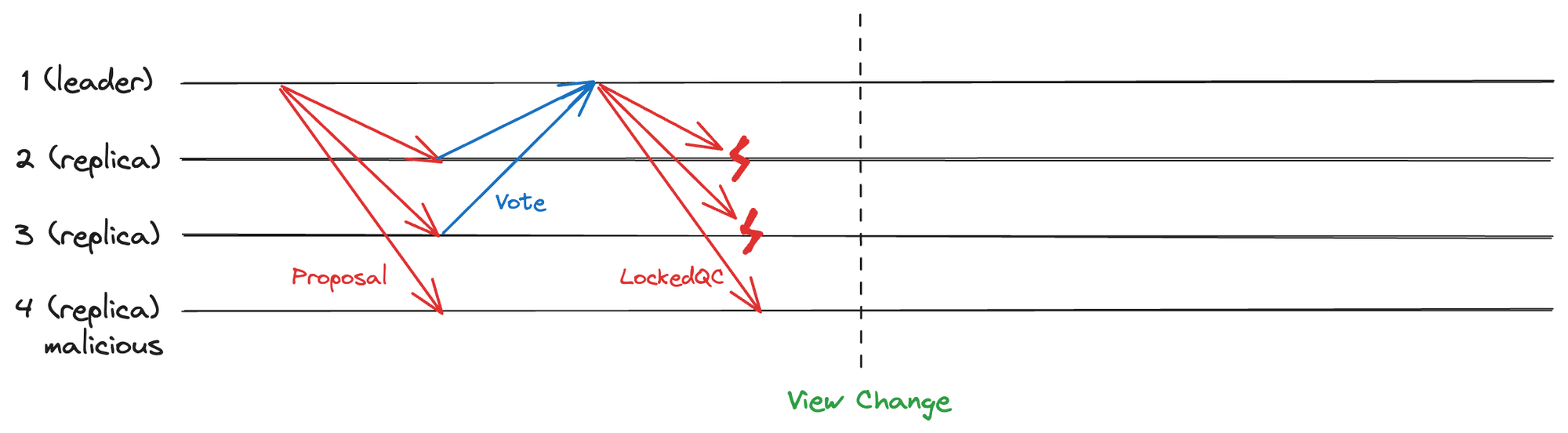 图 2.2 LockedQC 同步时超时
图 2.2 LockedQC 同步时超时
针对上述场景,我们简单对比 PBFT、Tendermint 和 HotStuff 的超时视图切换方案。
- PBFT 方案:使用
2f+1节点生成对 Lock 提案的状态证明
新 Leader 通过超时节点广播的方式收集 2f+1 对当前视图状态的投票,广播起到了状态同步的作用,保证了超过 2f+1 的节点此时拥有相同的 LockedQC。当收到 2f+1 投票后,新 Leader 会生成一个状态证明。之后新 Leader 将该证明广播,证明大部分节点已经拥有相同的 LockedQC,可以顺利推进共识。通讯复杂度为 O(n^2)。
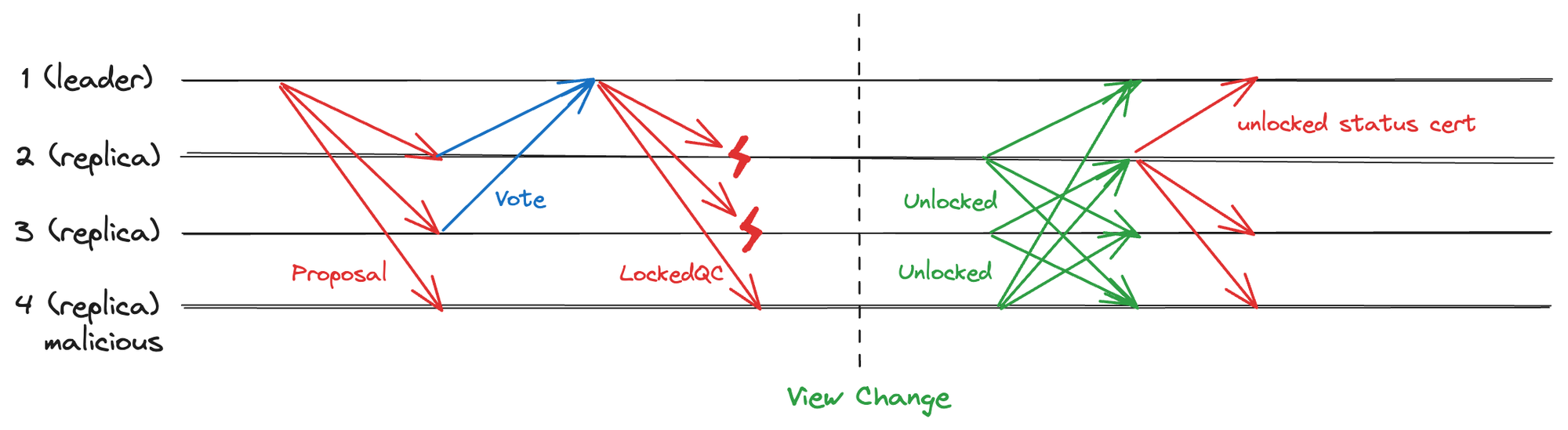 图 2.3 PBFT 生成 Locked 状态证明
图 2.3 PBFT 生成 Locked 状态证明
- Tendermint 方案:在 Δ 内收集全部诚实节点的 Lock 状态
无需广播,但需要设置一个 Δ 超时时间,以保证在该时段内收集到全部诚实节点的 Lock 状态,从而获取到真正的 Highest LockedQC。由于无需投票生成证明,可以达到线性通讯复杂度为。但由于依赖固定时间 Δ,系统丧失了即时响应能力(Responsiveness)。
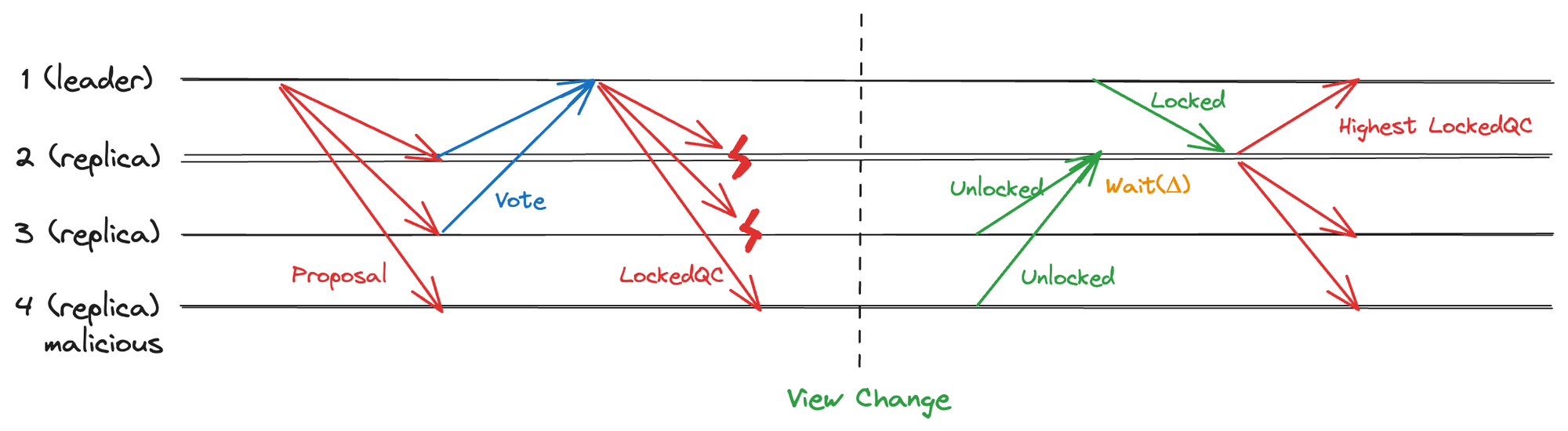 图 2.4 Tendermint 等待 Δ 收集最高 Locked 信息
图 2.4 Tendermint 等待 Δ 收集最高 Locked 信息
2.4.2 HotStuff 超时方案
- HotStuff 方案:增加 Key 阶段
HotStuff 在生成 LockedQC 阶段前增加一个 Key 阶段,收集投票后生成 KeyQC。当有 LockedQC 生成后,即说明一定有超过 2f+1 的节点拥有 KeyQC。那么视图切换时如果收集 2f+1 的 KeyQC,其中必有最高的 KeyQC。
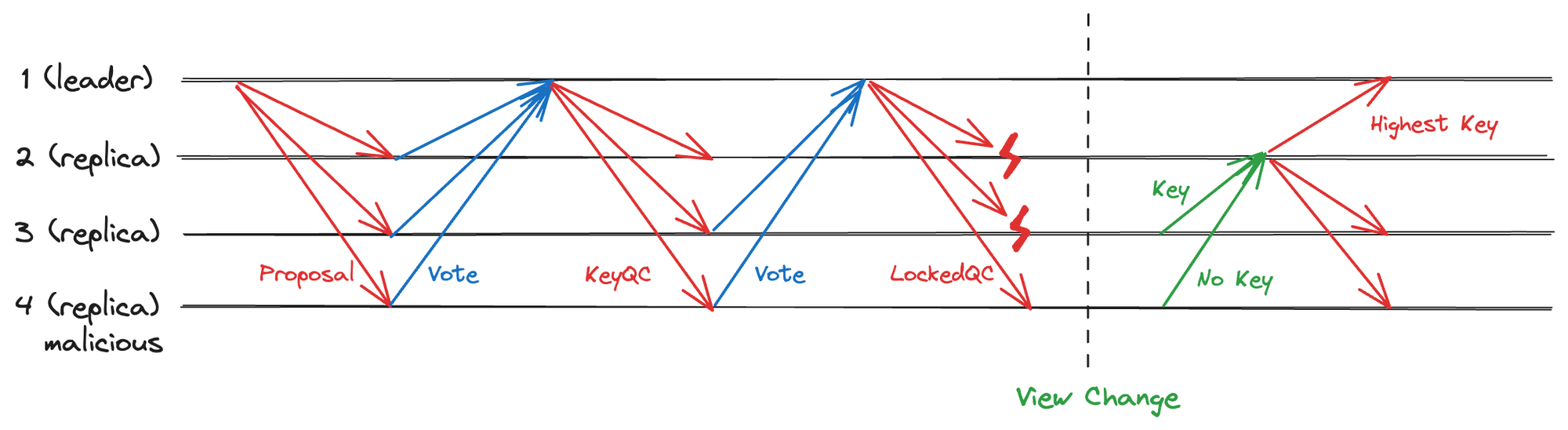 图 2.5 HotStuff 收集 KeyQC 进行视图切换
图 2.5 HotStuff 收集 KeyQC 进行视图切换
KeyQC.view 代表了新提案不能冲突的视图,使用 KeyQC 就能恢复最新的 Locked 状态。因此,HotStuff 在不牺牲系统 Reponsiveness 的同时实现了线性通讯复杂度的视图切换,代价是多了一个 Key 阶段。不难看出,此 Key 阶段即为 HotStuff 中的 Prepare 阶段,如下图。
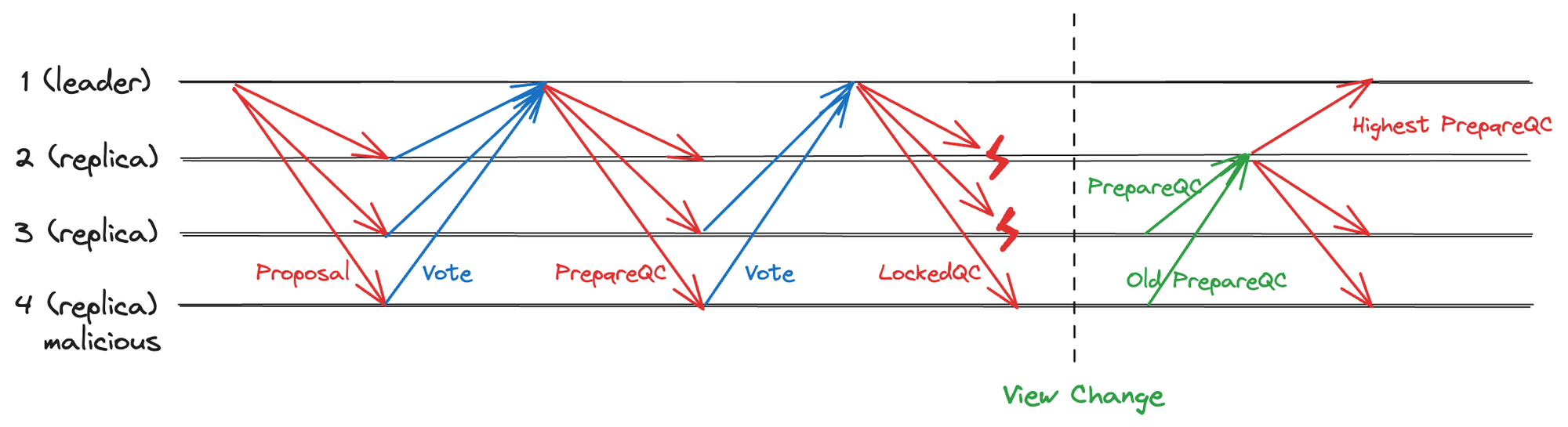 图 2.6 HotStuff 收集 PrepareQC 进行视图切换
图 2.6 HotStuff 收集 PrepareQC 进行视图切换
总之,HotStuff 通过增加一个阶段的方式,收集最新的 PrepareQC,就能恢复「共识断点」。另外,由于 QC 本身就是大多数节点共识投票的结果,因此在发送 PrepareQC 时无需签名验签,从而也降低 CPU 负担。
2.4.3 Timeout Certificate(TC)
虽然原生 HotStuff 超时策略可以保证线性的复杂度,但很多工程实现中都使用了生成 TC(Timeout Certificate)的方案,类似 PBFT,理论上通讯复杂度为 O(n^2) ,但增强系统在不确定和恶劣网络条件下的可靠性和稳定性。
当某一个视图发生超时,需要放弃原视图并开启一个新视图发起提案。此时,超时节点对当前视图号CurView 签名并打包超时消息 TimeoutMsg 发送给新 Leader。新 Leader 在收到 2/3+1 的 TimeoutMsg 后产生针对 CurView 的群体共识,生成新的视图号并切换到新视图。这个针对 CurView 的共识叫做 Timeout Certificate(简称 TC)。我们可以这么理解:
- QC 是大多数节点对 ViewBlock 的认可(其中包括视图号 View)。
- TC 是大多数节点对视图号 View 的认可。
无论是 QC 还是 TC,都是状态一致性的证明,都可以推动系统切换到一个新的视图。
有了 TC 的概念之后,即使在新提案发生超时导致选举退化的情况下,视图号仍然可以递进,而且严格单调递增。大多数节点虽然无法对新提案的交易(Transactions)和上一个块的 QC 达成共识,但仍然可以对 CurView 达成共识。相比 Basic HotStuff 的方案,这样可以避免分叉,提高共识效率。下图是使用 TC 和不使用 TC 作为视图切换方案的分叉情况对比,使用 TC 可以避免重复视图号的出现。
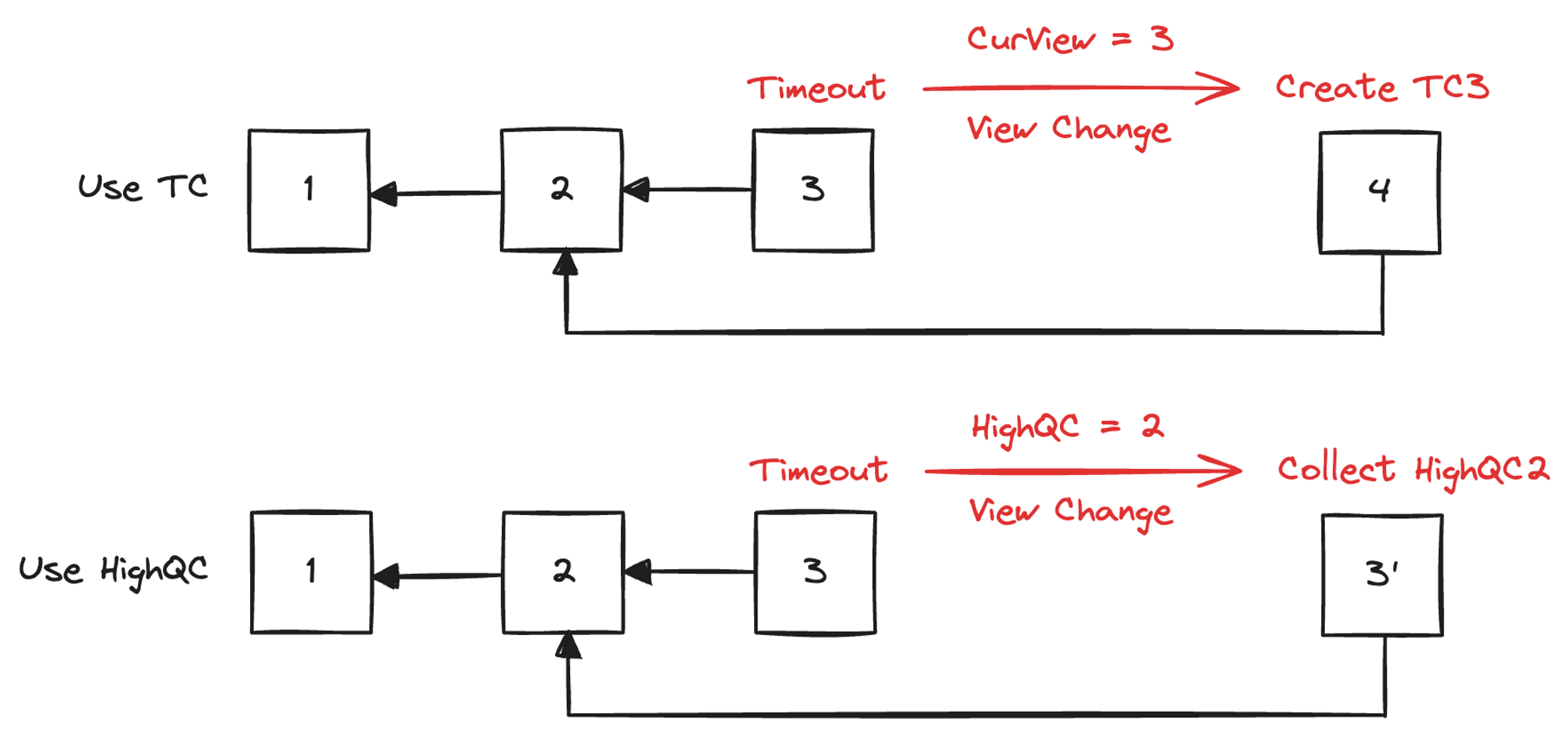 图 2.7 使用 TC 不会造成视图号重复
图 2.7 使用 TC 不会造成视图号重复
3 Chained HotStuff 实现
3.1 基本原理
在 Basic HotStuff 中,一个提案的共识需要经过三个阶段,分别产生三个 QC 才能完成。然而,如果每个消息不仅携带当前视图的信息,同时还包含前三个视图的不同阶段的信息,就能实现并行处理,提高效率,如图 3.1 所示。
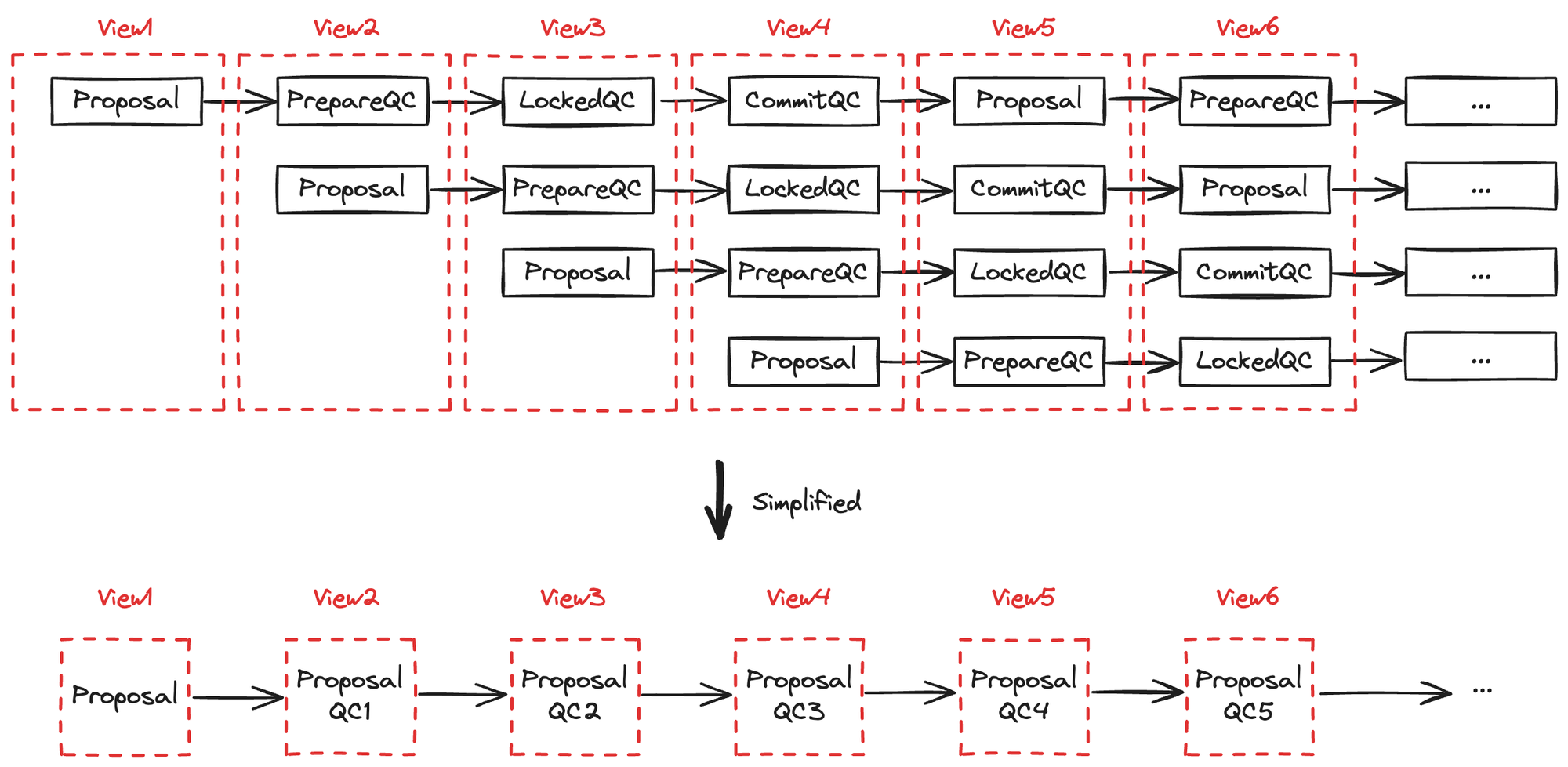 图 3.1 并行对多个提案进行共识
图 3.1 并行对多个提案进行共识
图中,每个视图 View 的共识内容不仅包含当前 View 的提案 Proposal,还包含 View-1 的 PrepareQC,View-2 的 LockedQC 和 View-3 的 CommitQC。实际上在代码实现中, 只需要将一个 QC 打包到 ViewBlock 中,不需要打包三个,图中对这些 QC 的解释如下:
- QC1:对 View1 的 Proposal 的共识(即 View1 的 PrepareQC)
- QC2:对 View2 的 Proposal + QC1 的共识(即 View2 的 PrepareQC + View1 的 LockedQC)
- QC3: 对 View3 的 Proposal + QC2 的共识(即 View3 的 PrepareQC + View2 的 LockedQC + View1 的 CommitQC)
所以,当一个 ViewBlock 后面连续出现三个 QC 时,该 ViewBlock 就可以执行 Commit,这是因为第三个 QC 就等同于 CommitQC;而出现两个 QC 时,该 ViewBlock 就可以执行 Lock,因为第二个 QC 等同于 LockedQC。这样一个视图不必再判断处于什么阶段,直接数后面有几个 QC 即可,大大简化了工程实现。
因此 Chained HotStuff 拥有以下优势。
- 并行处理:通过链式的方式,每个 ViewBlock 都包含了前几个 ViewBlock 的状态信息,使得节点可以并行处理多个提案,提高了整体效率。
- 状态传递:每个 QC 都包含了前一个 QC 的信息,这样新节点加入或者节点出现故障时,只需要同步最新的 QC 就能获取到最新的系统状态,减少了同步时间。
- 简化状态判断:节点只需要根据 ViewBlock 后面 QC 的数量来判断当前的状态,无需复杂的状态判断逻辑。
3.2 数据结构
3.2.1 本地变量
在 Chained HotStuff 中,每个节点本地都维护三个重要变量:
- HighQC:目前已知最高的 QC,所谓最高指的是 QC.view 最高。HighQC 代表了大部分节点认为的系统最新状态,可用于超时时进行视图切换。同时,Leader 在打包新提案时,一般会选择在 HighQC 对应的 ViewBlock 之后继续打包,以提高共识效率,如同 PoW 中永远从最长链向后挖矿。
- HighTC:目前已知最高的 TC,TC 是对 CurView 的群体证明。用于在超时时确定新的视图号。
- CurView:当前视图号,等于
max(HighQC.view, HighTC.view) + 1。新的 QC 和 TC 都可以促使 CurView 变更,由于 QC 和 TC 本身就是多数节点签名后形成的共识,因此可以保证 CurView 的一致性。
3.2.2 Propose & Vote 消息
在 Chained HotStuff 中,三个阶段变成了三次 Propose & Vote 消息。每一次都会进行如下步骤:
- Leader 同步父视图的 QC 给 Replicas,Replica 收到后切换视图。
- Leader 发起新提案并由 Replicas 验证,Replica 验证通过后签名投票,发送给新 Leader。
- 新 Leader 收到足够投票,产生本轮提案的 QC,切换到新视图。
以此往复,每一步也都会重新打包交易,而不是只有 Prepare 阶段打包交易,如图 3.2。注意,Leader 也是一个 Replica,Propose 消息自己也需要处理。
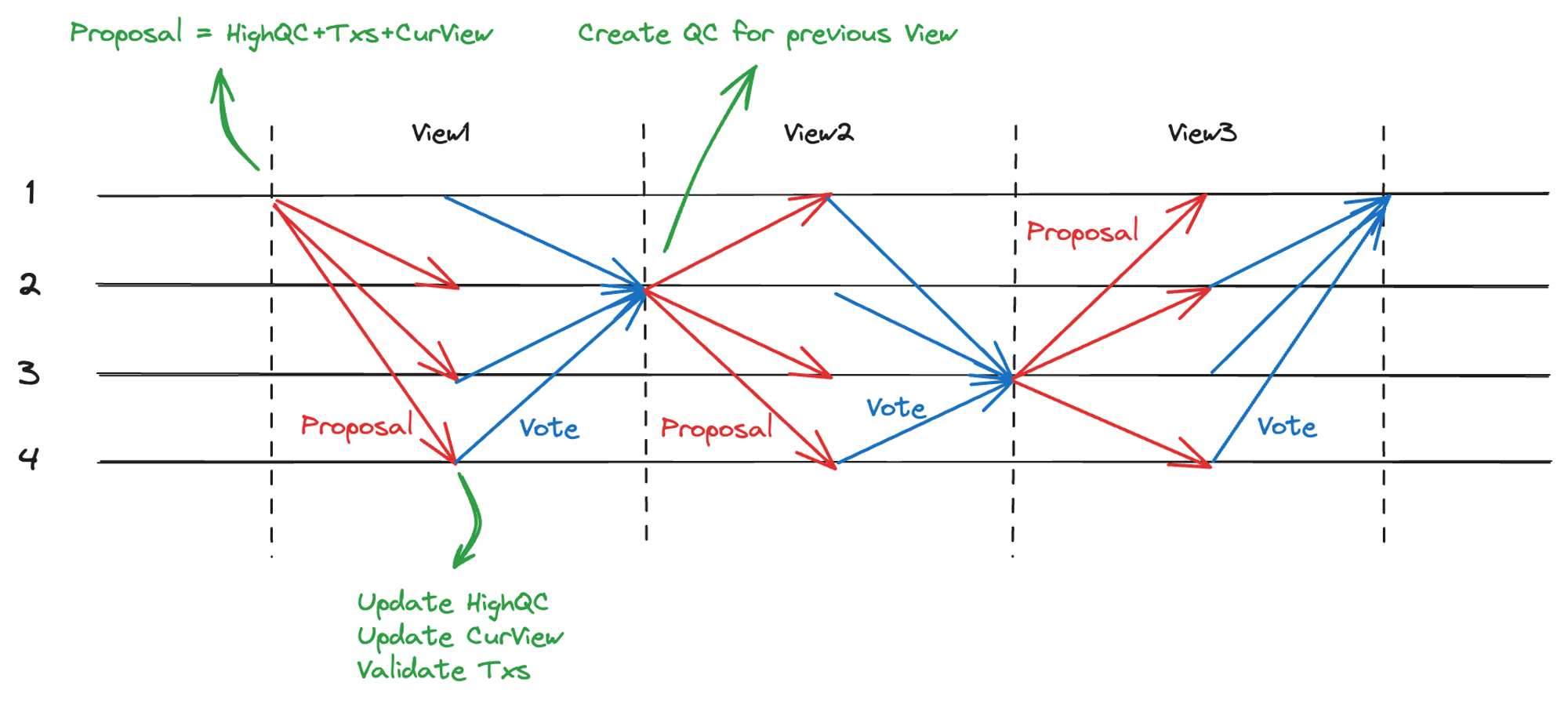 图 3.2 链式共识流程
图 3.2 链式共识流程
- Propose 消息:对新提案进行打包,内容包括 HighQC、交易、CurView。
- Vote 消息:对新提案进行投票,新 Leader 收到
2/3+1的投票后生成新 QC,新 QC 代表了对于新提案(交易、父视图 QC、以及 CurView)的认可。
3.2.3 ViewBlock 和 QC
ViewBlock 和 QC 是 HotStuff 中两个最重要的数据结构。多个 ViewBlock 根据 Hash 指针和 QC 指针组成 ViewBlockChain,示意图如下:
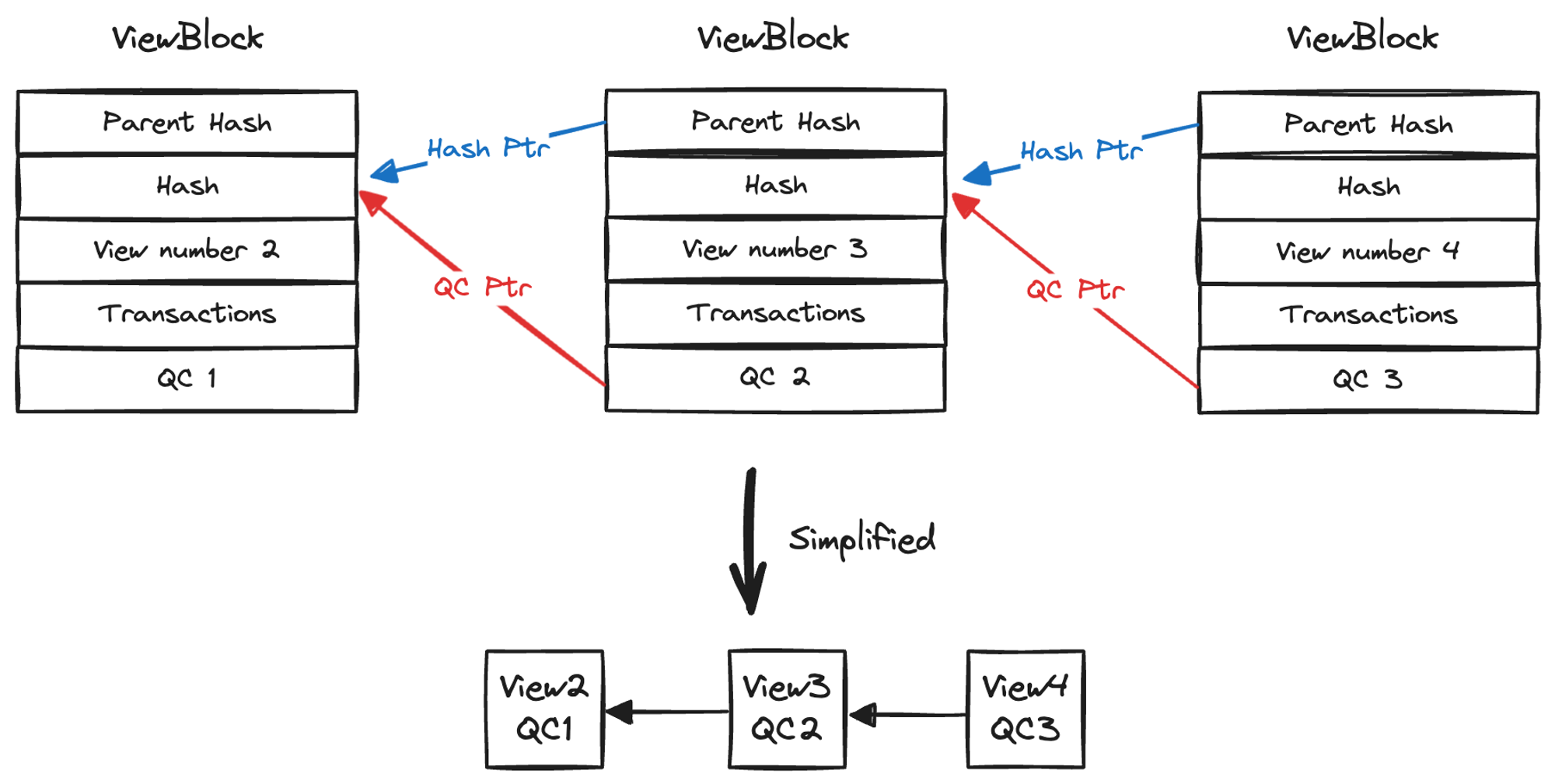 图 3.3 ViewBlockChain 结构,图中的 QC2 指代针对 View2 生成的 QC
图 3.3 ViewBlockChain 结构,图中的 QC2 指代针对 View2 生成的 QC
其中:
- Hash 指针与 QC 指针一致
- 视图号
ViewNumber = max(HighQC.View, HighTC.View) + 1 - 诚实 Leader 应打包 HighQC,提高共识效率,避免恶意回滚。
ViewBlock 的基本结构如下:
struct ViewBlock {
// 当前视图号
View view;
// Hash
Hash hash;
// 父视图块 hash
Hash parent_hash;
// Leader 节点
Node* leader;
// 打包的交易
[]Tx txs;
// QC
QC qc;
// 打包时间
Time* created_time;
}根据是否拥有 LockedQC 和 CommitQC,将每个 ViewBlock 划分为 New Proposal、Locked、Committed 三种状态,就形成了一条不断提交的 ViewBlockChain 区块链。ViewBlockChain 本质上是一个包含了未提交状态的区块链,每一个块是对 HotStuff 中具体阶段的一次共识,而不仅仅是对该提案是否应该提交的共识。我们平时说的区块链多是指其中已经提交的块,这部分不会分叉,而尚未提交的块是会分叉的,如图 3.4。
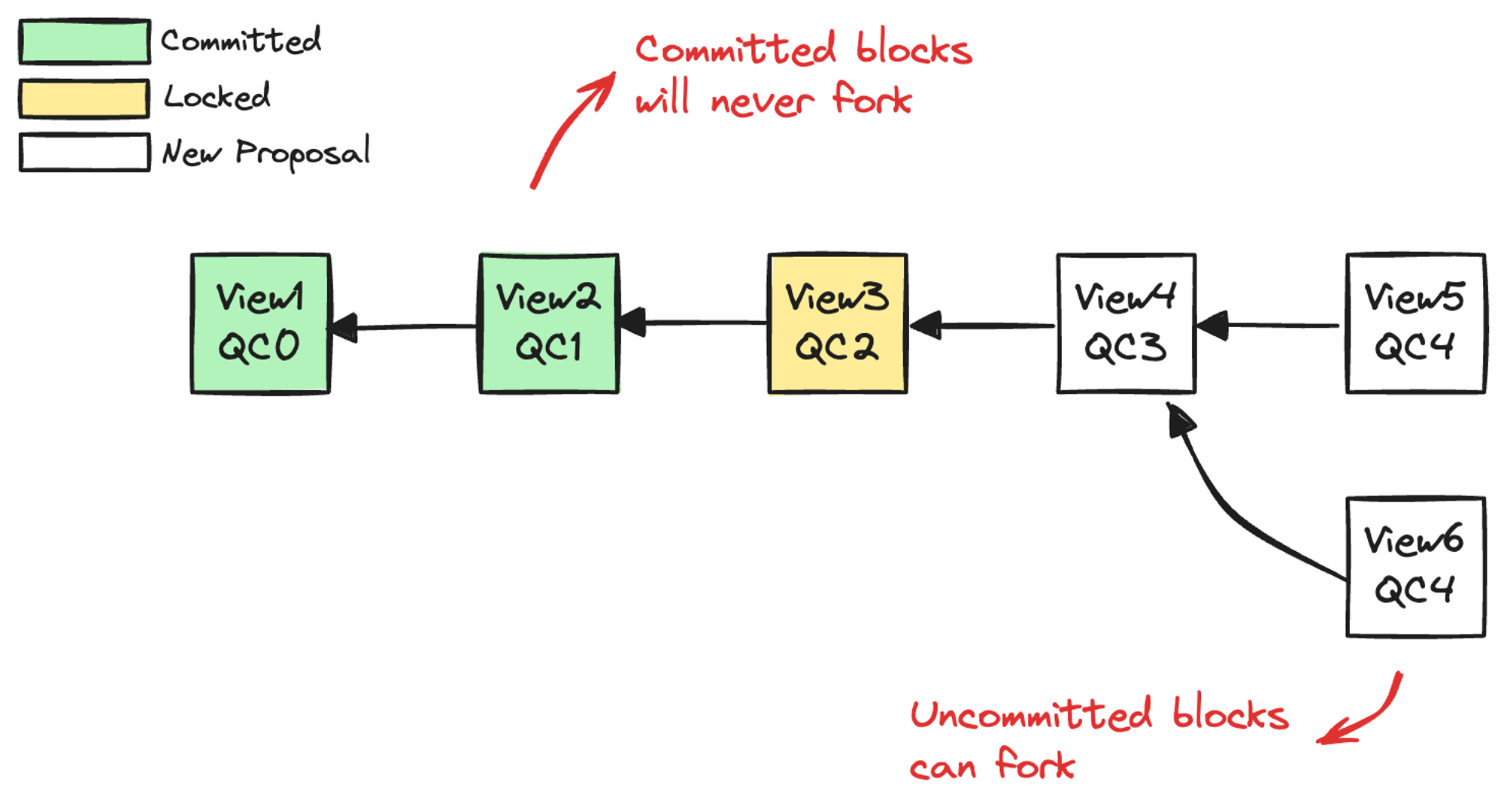 图 3.4 视图链分叉
图 3.4 视图链分叉
系统对新提案不断进行共识,当某个提案连续获得两个 QC,该节点状态即为 Locked;连续获得三个 QC,可提交为 Committed 状态,如下图,这与 Basic HotStuff 的三阶段提交是一致的。
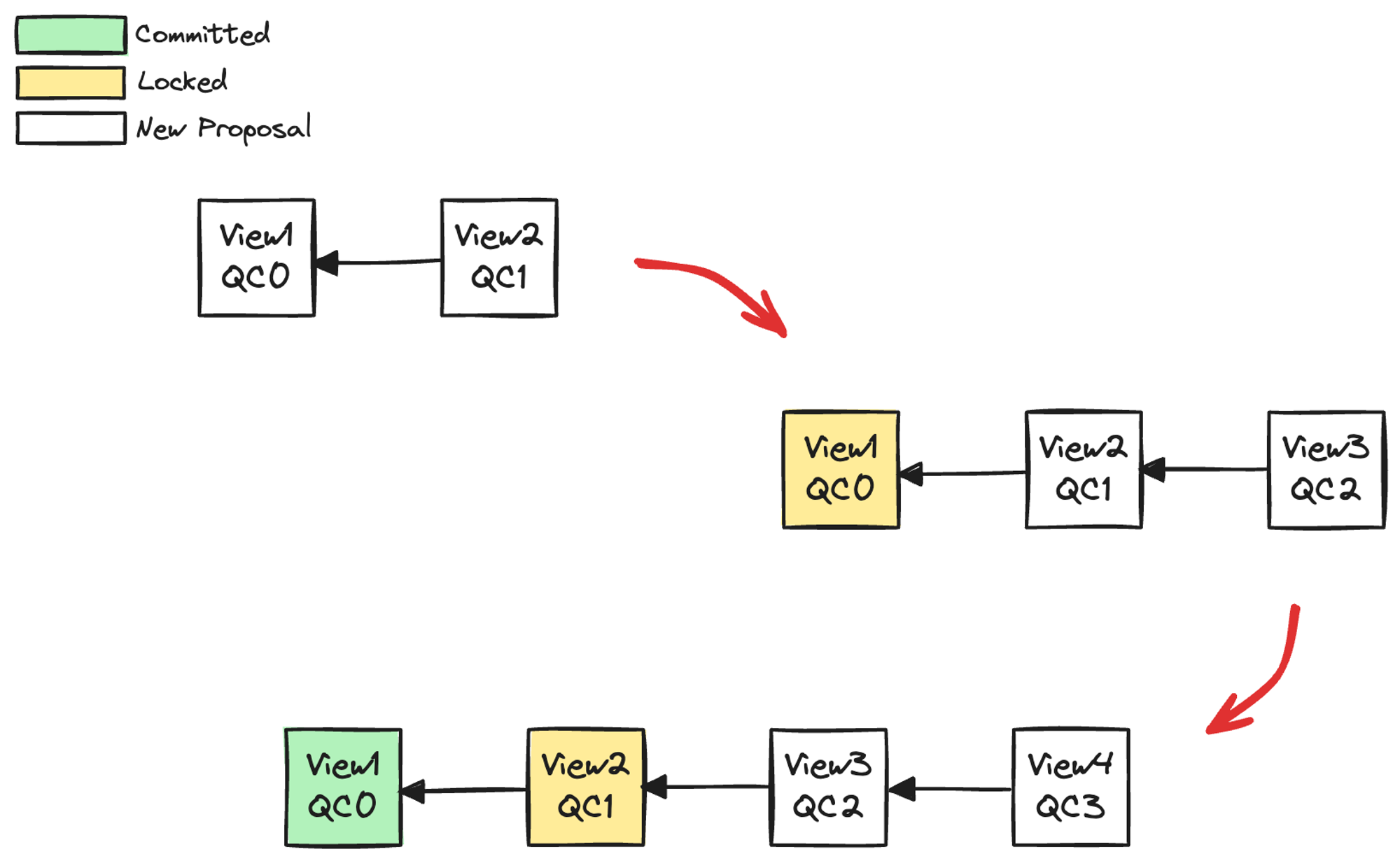 图 3.5 视图块状态变更
图 3.5 视图块状态变更
QC 是对一个 ViewBlock 的群体共识,包括 ViewBlock 的哈希以及重建后的阈值签名(如 BLS)。除了包含对应 ViewBlock 的 Hash 指针以外,QC 中还包含了应该提交的 ViewBlock 的 Hash 指针,用于同步已提交区块时提供 Commit Proof,这在后文「同步模块」中会进行介绍。QC 的基本结构如下:
struct QC {
// 阈值签名
ThresholdSign agg_sign;
// 视图号
View view;
// 对应的 ViewBlock,QC 是其 PrepareQC
Hash view_block_hash;
// Commit ViewBlock, QC 是其 CommitQC
Hash commit_view_block_hash;
// Leader leader
Node* leader
}3.3 提案打包与验证
3.3.1 打包提案
新提案就是一个 ViewBlock,包括以下内容:
- 待执行交易
- 当前视图号 CurView
- HighQC
- HighTC(超时后打包)
对于提案中的 QC 来说,诚实 Leader 会打包 HighQC,即从最新 ViewBlock 之后继续出块,但由于 Leader 有恶意可能,打包什么 QC,从哪个 ViewBlock 之后分叉,只能由 Replicas 做合法性验证。
其实在 HotStuff 协议中,Leader 不打包 HighQC 也可以满足验证条件。但为了避免恶意节点故意打包旧的 QC 而造成其他视图回滚,同时提高共识效率,我们要求诚实节点 Leader 必须打包 HighQC。如图 3.6,如果 Leader 产生了 QC3,却故意打包了 QC2,会造成 View3 被恶意回滚。
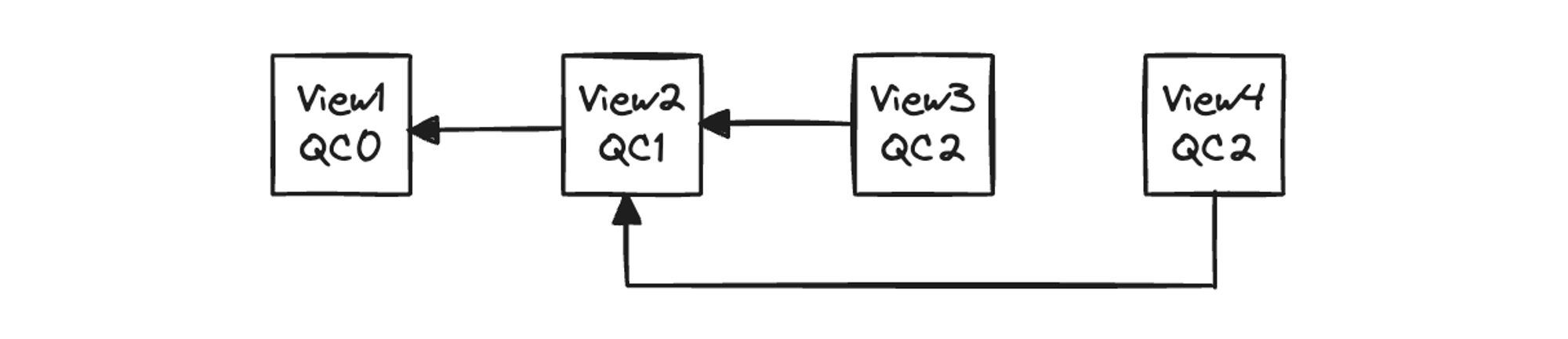 图 3.6 Leader 打包旧 QC 造成恶意回滚
图 3.6 Leader 打包旧 QC 造成恶意回滚
3.3.2 验证提案
HotStuff 论文中,Replica 对于新提案的验证是为了保证 HotStuff 的安全性(Safety)和活性(Liveness)。HotStuff 将 Safety 和 Liveness 解耦,Safety 由 HotStuff 协议本身实现,Liveness 由业务实现。
- Safety:共识的正确性,比如不会出现状态不一致等。
- Liveness:活性,保证无论在什么情况下,系统不会卡住,能够持续产生共识。
论文中的验证逻辑如下:
node extends from lockedQC.node:新的视图块需要和最新的 lockedQC 在同一分支。正常情况下 HotStuff 协议都能保证新的提案在 lockedQC 的分支上,可以保证 Safety。qc.viewNumber > lockedQC.viewNumber:保证 Liveness。
这两个条件是「或」的关系,此外还有一些是 HotStuff 在工程实现过程中要依次加以限制的:
- 基本验证
Block.ParentBlockHash = Block.QC.BlockHash:QC 指针与哈希指针相同。leader.ID == LeaderRotation.GetLeader():Leader 的正确性。Block.View() > CurView:只接受高度更高的块。
2.验证 QC & TC
VerifyQC(Block.QC):QC 验证。TC == null || VerifyTC(Block.TC):TC 验证(父视图超时后会打包 TC)。
3.验证交易
VerifyCommand(Block.Cmd):验证交易。
4.Safety & Liveness 保证
blockChain.Extends(Block, GetBlock(Block.QC.BlockHash))blockChain.Extends(Block, LockedBlock) || Block.QC.View > LockedBlock.View
5.尝试 Commit
Commit(FindBlockToCommit()):尝试提交有 3 个 QC 的块。
以上所有验证进行完毕后,Replica 才会对提案进行投票。这些验证分别保证了新视图中的交易、QC 以及当前视图号的正确性。
3.4 Commit 提交
一个 ViewBlock 只要获得三个连续的 QC 就可以被提交,这三个 QC 分别对应 Basic HotStuff 中的 PrepareQC、LockedQC、CommitQC。其实在 HotStuff 论文中,CommitQC 所在视图并不需要和前面视图连续,但这样会导致频繁分叉,影响系统性能和稳定性,这里参考了 LibraBFT 以及 Fast HotStuff 在此方面做出的改进。
当一个 Replica 收到一个新的提案,除了验证这个提案之外,还要尝试找出可以提交 的ViewBlock。如图 3.7 中,当 Replica 收到了 View7{QC6} 提案时,提交流程如下:
- 验证新提案:
- Replica 首先验证收到的新提案的有效性,包括基本验证、QC 验证、TC 验证和交易验证等步骤。
- 寻找可提交的 ViewBlock:
- 当收到一个新的 QC(例如
View7{QC6}),Replica 不仅要验证当前 QC 对应的 View7,还需要尝试找到可以提交的 ViewBlock。这意味着需要查找连续获得三个 QC 的块,图中找到 View4。
- 当收到一个新的 QC(例如
- 提交 ViewBlock:
- 找到可提交的 ViewBlock 后(例如 View4),进行提交。
- 提交意味着将 ViewBlock 和其对应的 CommitQC 持久化到数据库中,确保其他节点可以同步到这个状态。
- 处理提交后的视图状态:
- 提交后,Replica 需要将之前的视图分支「剪掉」,并将其中的交易归还给交易池,等待下一次打包。
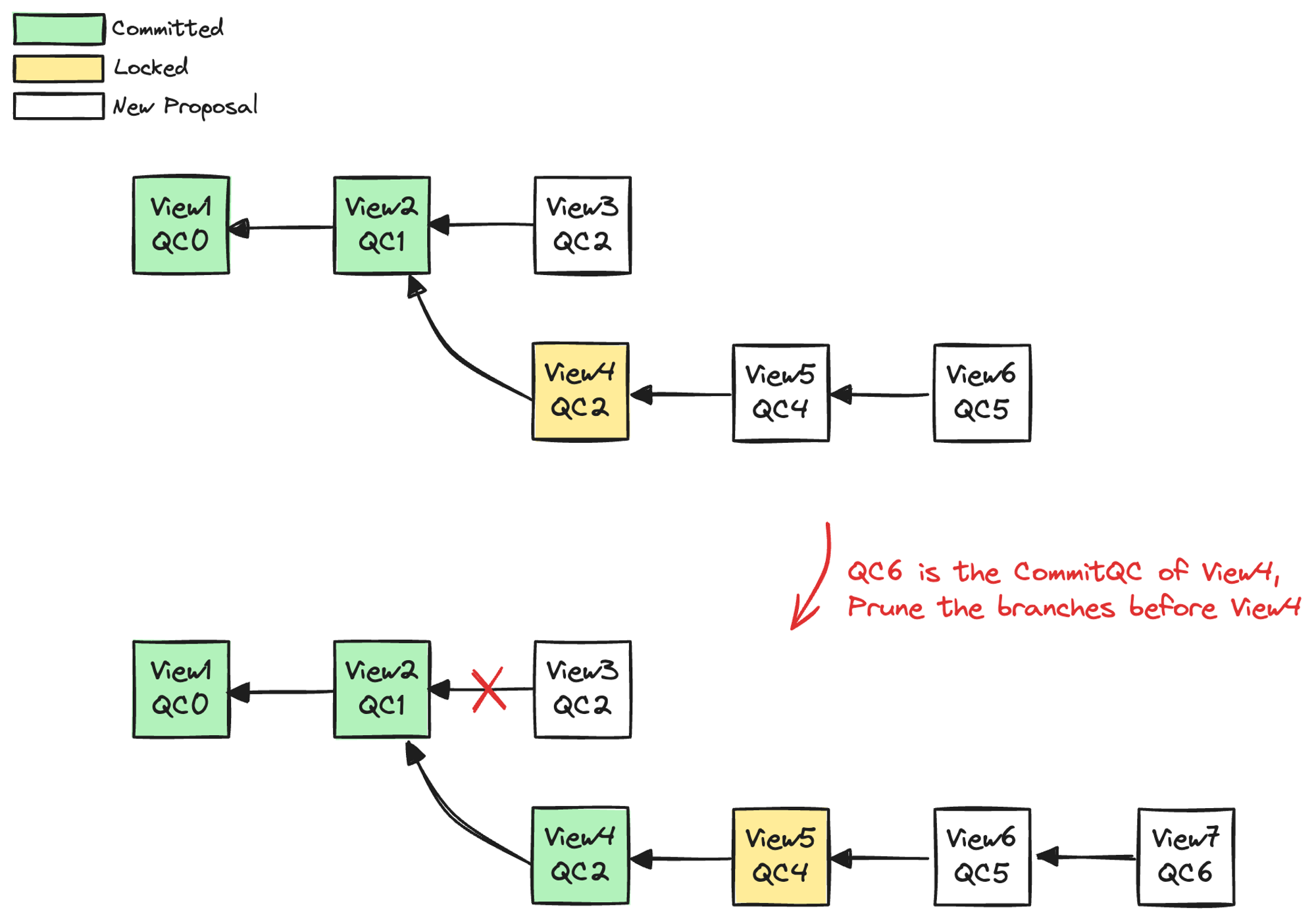 图 3.7 视图块提交触发剪枝
图 3.7 视图块提交触发剪枝
注意:
- 促成提交的是 QC 而非 ViewBlock,即使某个 ViewBlock 没有通过验证,只要其中的 QC 是合法的,Replica 仍然应该尝试寻找可以提交的块进行提交。
- 提交后的操作包括持久化到数据库并更新系统状态,确保所有节点可以达到一致的共识状态。
3.5 投票
一个提案被验证通过后 Replica 即可发送投票,并对该提案进行部分阈值签名。Leader 收到 2/3+1 的投票后恢复完整的阈值签名、生成新的 QC、开启新的视图并广播新提案。
3.6 视图切换
Pacemaker 模块是 HotStuff 协议中用于保证活性的重要模块,负责视图切换、超时机制。顾名思义,它保证了在正常或异常情况下,系统地共识轮次能够正确稳定地向前演进,不会卡死而丧失活性。
此处的视图切换是狭义概念,根据系统当前的 HighQC 和 HighTC 变更当前视图号 CurView。切换的时机主要包括以下情况:
- 新 Leader 创建新的 QC 或 TC:
- 当新 Leader 在当前视图下创建了一个新的 QC 或 TC 后,系统尝试进行视图切换,更新 CurView。
- Replica 收到 Leader 发来的 QC 或 TC:
- 当其他节点的 Leader 向当前节点发送了一个新的 QC 或 TC 时,当前节点尝试进行视图切换。
- Replica 收到其他节点同步来的 QC 或 TC:
- 当节点从其他节点同步到了一个新的 QC 或 TC 时,系统也会尝试进行视图切换。
3.7 超时机制
3.7.1 动态超时时间
视图超时时间的预设通常根据旧视图处理时间来进行动态调整,例如,可以使用过去平均处理时间的 95% 置信区间上限作为阈值。一旦视图超时,系统会根据当前超时时间乘以一个系数来调整后续视图的超时时间选择策略。
3.7.2 TC 生成方案
Replica 对当前视图号 CurView 进行签名并发送给 Leader,Leader 收到 2/3+1 超时消息后生成 TC,作为系统对于新视图的共识,完成视图切换。
CurView 值由 HighQC 和 HighTC 共同决定,因此在收集 CurView 签名消息之前,需要保证2/3+1 节点的 HighQC 是一致的。举例来说,发生超时时,如果一半的节点收到了最新的提案并更新了 HighQC,而另一半节点没有收到,由于 HighQC 不一致,系统无法对同一个 CurView 签名并发送消息导致共识卡死,如图 3.8。
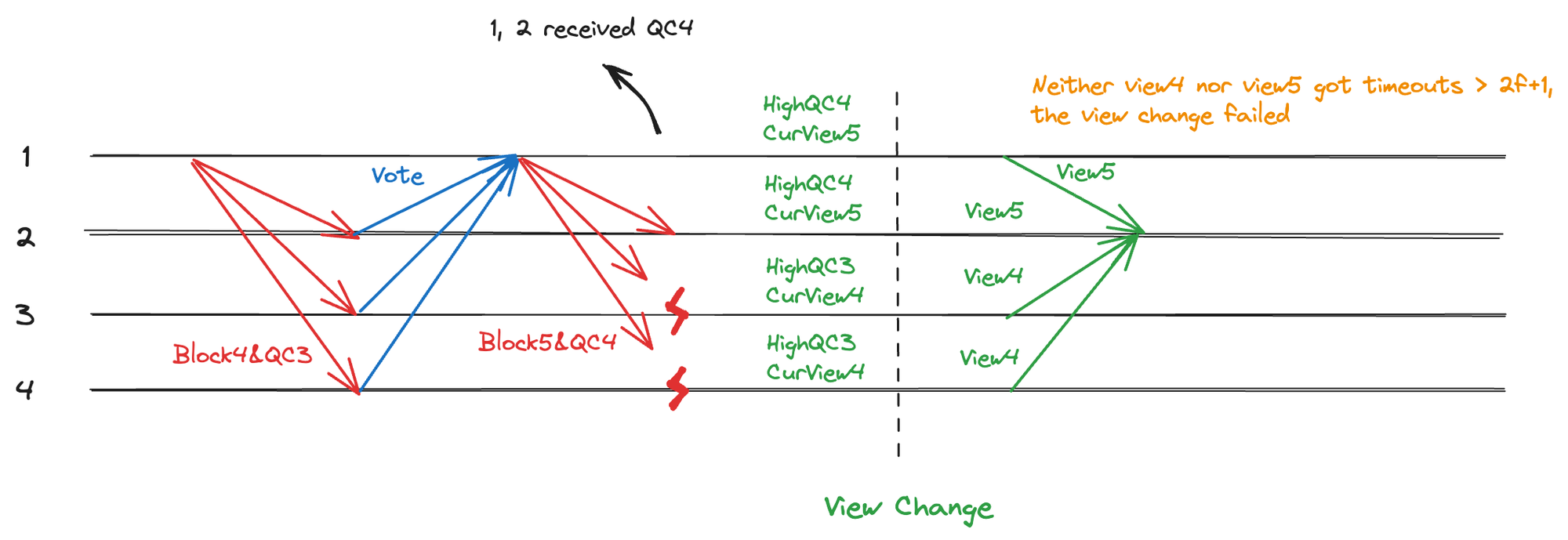 图 3.8 超时不广播且无同步情况下视图切换卡死
图 3.8 超时不广播且无同步情况下视图切换卡死
此外,还存在一种情况,即少数节点持有最新的 HighQC,而大部分节点的 HighQC 还停留在较旧的状态。如图 3.9,当 View5 发生超时时,只有少量节点收到了 QC4 并更新了 HighQC,而大多数节点仍然停留在 QC3。在这种情况下,如果超时节点直接向新 Leader 发送 TimeoutMsg(通信复杂度为 O(n)),虽然不会影响共识活性,但会导致 QC4 被浪费,降低吞吐量。
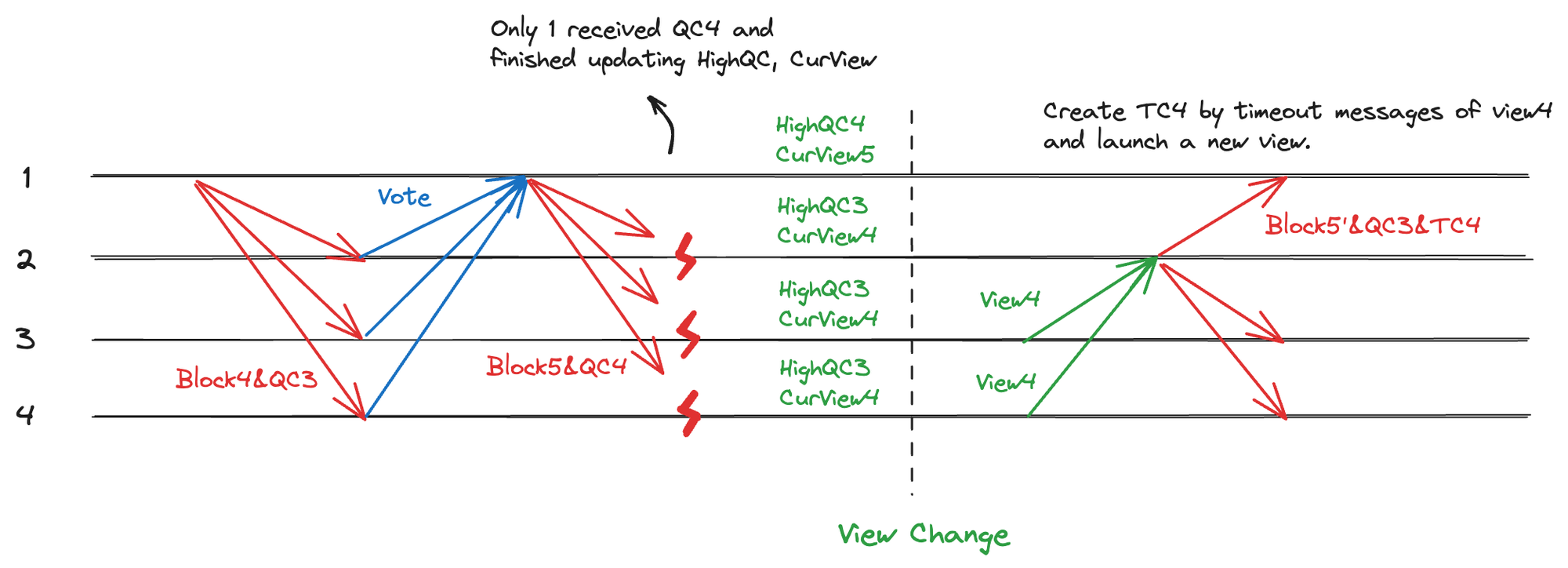 图 3.9 不能收集到最新 HighQC 的情况
图 3.9 不能收集到最新 HighQC 的情况
所以,应当在保证 2/3+1 节点 HighQC 一致的前提下,尽量保证这个 HighQC 是最新的。为了实现这点,HotStuff 通过广播 TimeoutMsg 的方式生成 TC,TimeoutMsg 包括 HighQC 以及签名后的 CurView,广播起到了同步其中 HighQC 作用,以确保 Leader 收到真正的 HighQC,即使只有少数节点持有该信息。具体流程如图 3.9 所示:
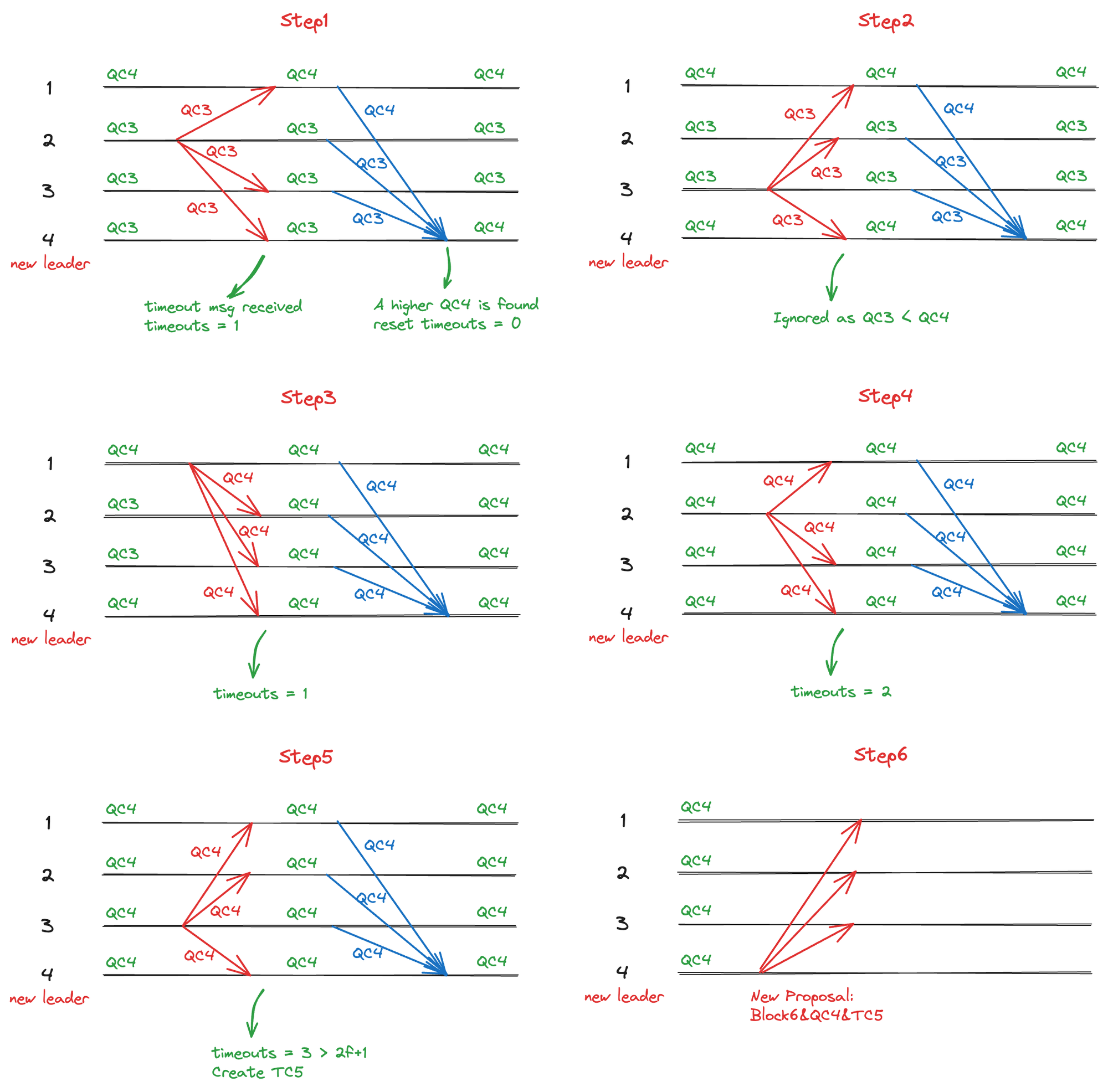 图 3.10 Timeout 消息广播过程
图 3.10 Timeout 消息广播过程
- Step1: 当一个 HighQC = QC3 的节点触发超时时,它会广播 TimeoutMsg,其中包含本节点当前的 HighQC(QC3)。新 Leader 收到此消息后,发现 QC3 ≤ 自身的 HighQC,将该节点加入统计。同时,其他节点也会更新本地的 HighQC(尝试进行视图切换),并将新的 HighQC 发送给 Leader。Leader 接收到 QC4,更新本地 HighQC,并且废弃之前的 QC3 超时统计。
- Step2: 第二个 QC3 节点触发超时并广播 QC3 给 Leader 和其他 Replica。由于新 Leader 已经更新到 QC4,不会接受 QC3 的超时消息。
- Step3: 一个 QC4 的节点触发超时并将 QC4 广播给所有节点。Leader 发现该 QC4 ≤ 自身的 HighQC,因此将其加入超时统计。其他节点收到 QC4 后尝试更新 HighQC。此时所有节点将更新到 QC4。
- Step4 和Step5: 后续的 QC4 节点依次触发超时,并在 Leader 收到足够多的针对 QC4 的超时消息后,创建 TC5,并将 CurView 切换到
max(QC4, TC5) + 1 = 6。 - Step6: 新 Leader 打包新的提案
View6{QC4}并发起共识。
由于对 TimeoutMsg 的广播,此视图切换方案需要 O(n^2) 的通讯复杂度,但提高了系统鲁棒性,是多数工程实践的选择,如 LibraBFT。另外,我们可以使用渐进式的 HighQC 同步策略降低复杂度,具体实现细节将在后面的「同步模块」中详细介绍。
3.7.3 HighQC 收集方案
我们还可以使用原生 HotStuff 方案,即新 Leader 通过收集 2/3+1个节点中 HighQC 的值来恢复「共识断点」,将通讯复杂度降为线性。
收集到的 HighQC 有两个作用:
- 明确新 Leader 发起新视图的视图号 View(即
HighQC.view+1)。 - 保证共识安全性,确保新提案不会从最新 Locked 块之前分叉。
根据上文中对 Basic HotStuff 超时机制的介绍,只要收集 PrepareQC 即可获得系统最新 Locked 状态,所以即使新 Leader 没有收到真正的 HighQC(实际上也无法保证,如图 3.8),也不会影响共识的活性和安全性,只会导致少数节点临时分叉。
这里有个细节,一般验证新提案的时候我们要求提案的视图号不能重复(否则 Leader 可以恶意回滚某个视图),即节点不会对已经投过票的视图投票,但在超时情况下,这将会导致之前收到最新 QC 的少数节点后续无法参与共识。仍然以上文中图 3.9 的例子加以说明,即 View5 仅发送给了少数节点而触发超时,如下图。
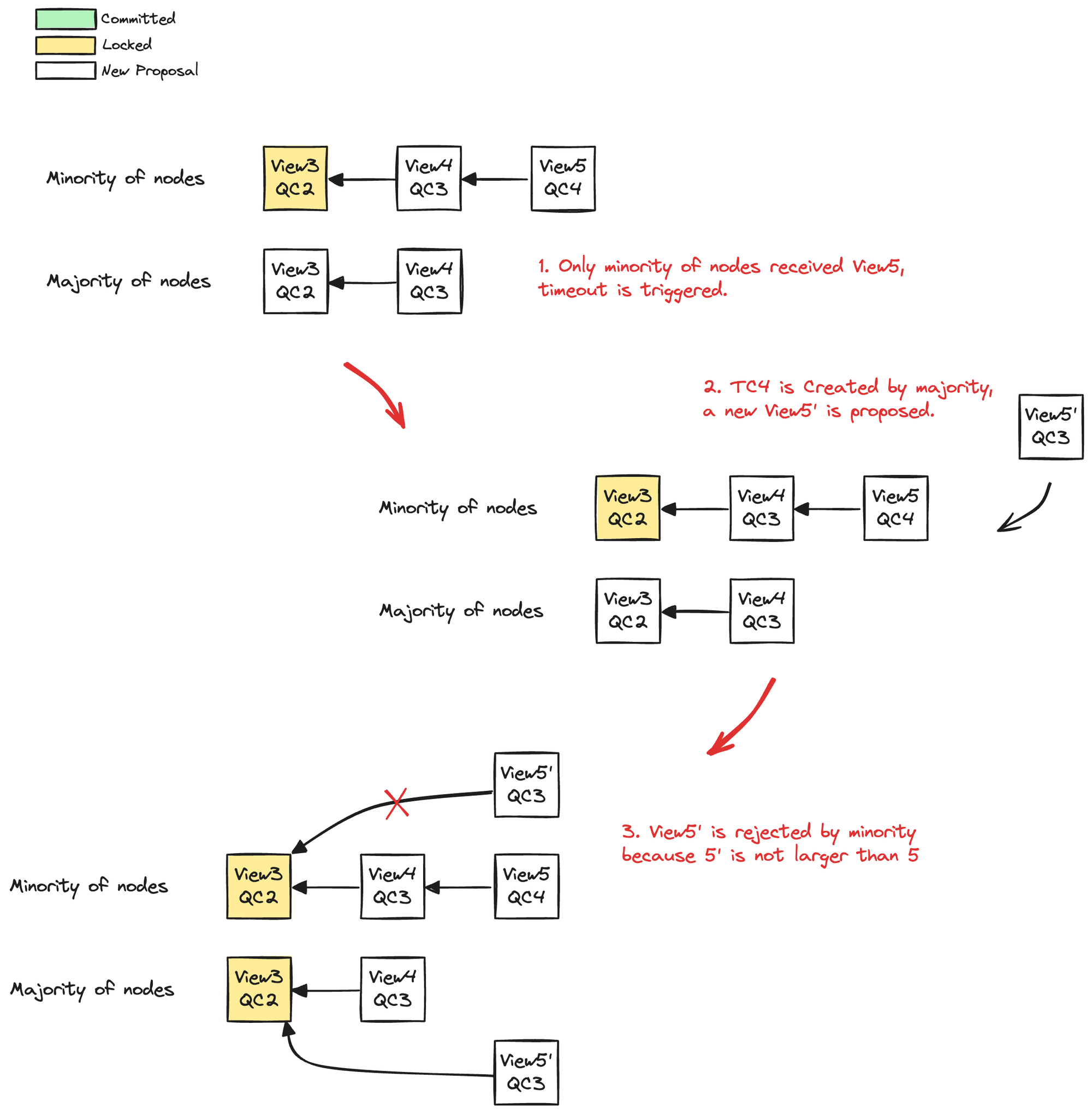 图 3.11 View 号重复性验证会导致少数节点无法参与后续共识
图 3.11 View 号重复性验证会导致少数节点无法参与后续共识
这部分少数节点由于 View5’ ≤ View5 无法接受 View5’,从而无法参与后续共识。因此,在超时造成视图切换之后的第一个视图中,我们需要放开对于视图号必须最新的限制,可以接受重复视图号的提案。比如上面例子中少数节点应该允许接受 View5’ 从而强行回滚 View4(反正大部分节点也没有 QC4,这个回滚是大家投票决定的)。如果选择收集 HighQC 作为超时视图切换的方案,这点是应当注意的,使用 TC 方案则不存在此问题。
综上所述:
- 当最新的 HighQC 只被少于 1/3 的节点持有时,新 Leader 无法确保收到真正的 HighQC。这种情况虽然不会影响共识活性与安全性,但会导致最新的 HighQC 被废弃。
- 对于超时后发起的新视图,我们需要放宽对视图号不重复的限制。
为了提高共识效率,应尽量确保新 Leader 收到真正的 HighQC。因此,开发一个同步模块来保证最新 HighQC 的同步是非常必要的。
3.9 同步模块
节点状态不一致导致共识失败时,系统需要同步策略来保证超过 2/3+1 节点的状态一致性,以继续进行共识。在上文的图 3.8 中,在 View5 提案广播异常的情况下,一半节点收到了新的 QC,而另一半没有收到,这样在没有同步机制的情况下,新 Leader 永远无法获得足够的投票来生成 TC。
通常情况下,HotStuff 通过广播方式在超时后进行状态一致性的修复(见「超时机制」部分),不需要额外的同步模块。但由于 O(n^2) 的通讯复杂度在节点过多时占用过多带宽,我们开发了一个额外的同步模块,以渐进式地同步节点之间的状态。
3.8.1 同步内容
- 未提交 ViewBlock
保证节点不会因缺少父块而无法参与投票。
当节点发现自己缺失 ViewBlock 时,会尝试向邻居节点同步。邻居节点收到请求后,对比请求者与自己 ViewBlockChain 的差异,将请求者缺失的 ViewBlock 及其对应的 QC 发给该节点,只要 QC 验证通过,该 ViewBlock 就会被加入请求者本地的 ViewBlockChain 中,如下图所示。
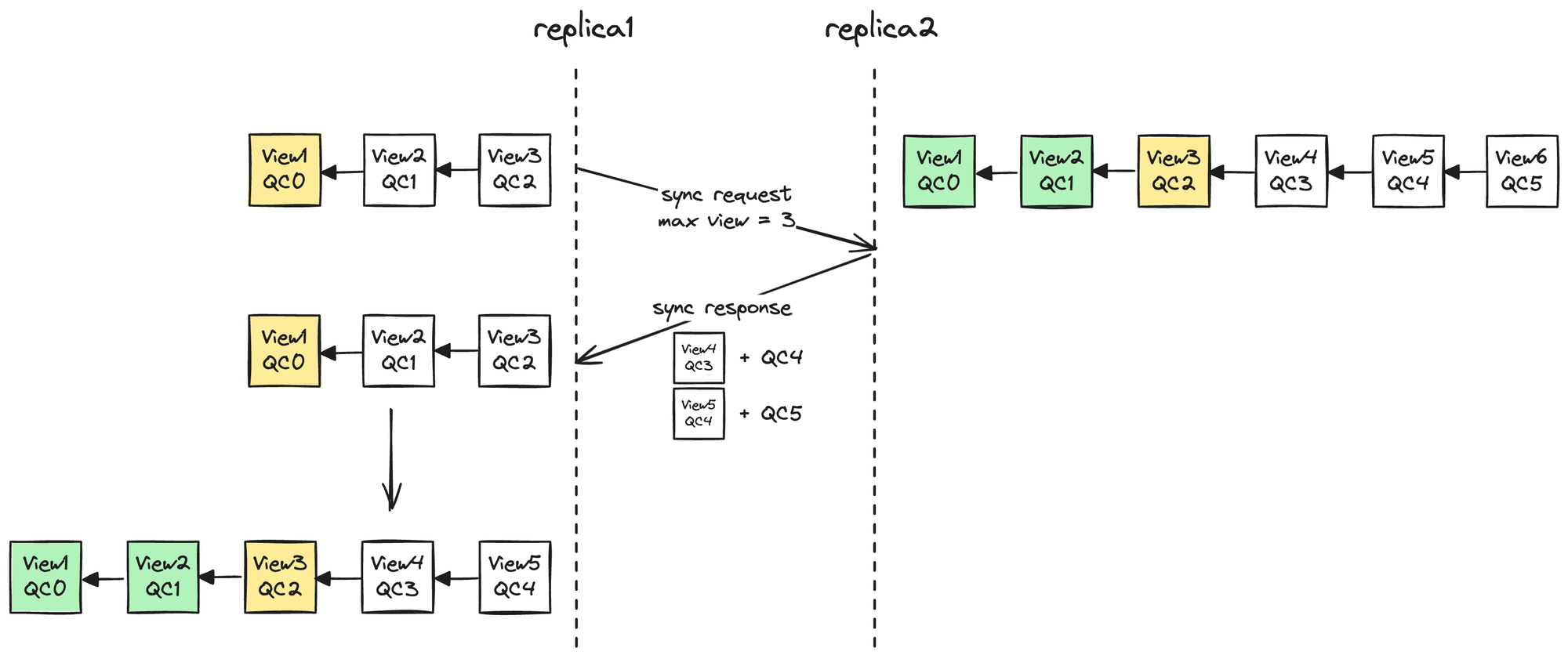 图 3.12 同步未提交 ViewBlocks
图 3.12 同步未提交 ViewBlocks
注意,只有已经生成 QC 的 ViewBlock 才能被同步,以防恶意节点伪造 ViewBlock。但这也带来一个问题:最新的提案由于还没有投票生成 QC,永远不能被同步过来,导致 Replica 无法参与后续的共识。这是因为验证新提案要求其父块必须存在,由于父块无法同步过来,Replica 永远不能对新提案投票。
此外,Leader 的选举由 QC 决定(QC 会触发 Commit,决定了 Leader,将在下文「Leader 选举中讲述」),尽管 QC 可以通过同步获得,但在高 TPS 场景下,Propose 消息往往比同步消息更先到达,Replica 很难真正「跟上进度」。这会导致 Replica 误认为 Propose 消息中的 Leader 是错的,从而拒绝接受新提案。
总之,一旦节点「掉队」,就无法继续参与共识,直到共识节点数量不足而触发视图超时,才能重新跟上进度。因此,系统参与共识的节点数量随着时间变化呈现如下图所示趋势。
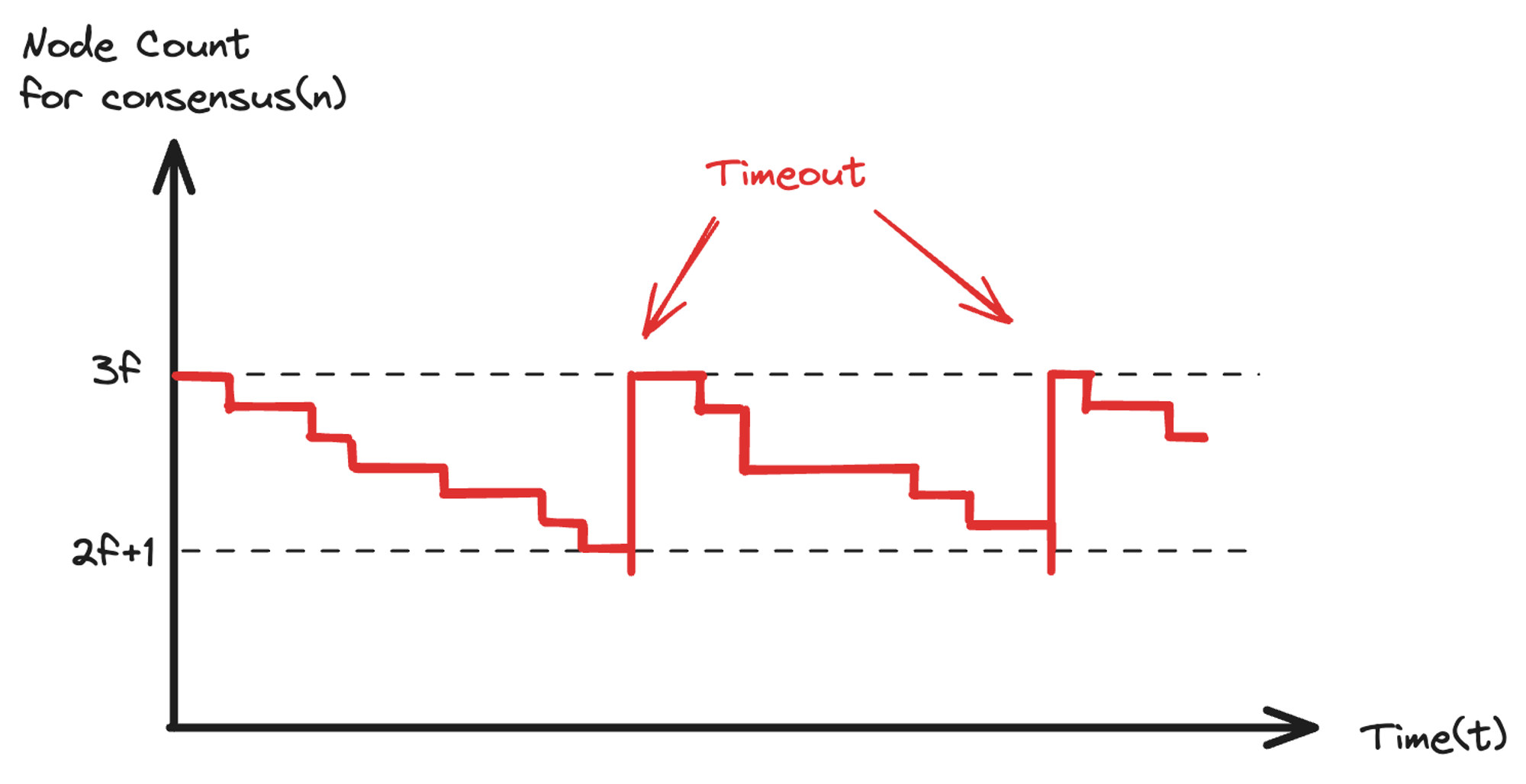 图 3.13 「掉队」节点无法参与共识,直到节点数量不足而触发超时
图 3.13 「掉队」节点无法参与共识,直到节点数量不足而触发超时
为了解决这个问题,我们没有直接拒绝因节点状态滞后而验证失败的提案,而是将其放入等待队列,并记录断点的上下文。这主要针对以下两种提案:
- Leader 一致性验证失败
- 新提案的父块缺失
这两种情况可能是由节点状态不一致造成的,在触发同步之后可以从断点处重新验证并投票。
- 已提交 ViewBlock
用于新节点历史数据的同步,同时保证共识节点账本状态和 Leader 的一致性。
为了验证同步来的已提交 ViewBlock 的合法性,被请求节点需要额外发送该 ViewBlock 对应的 CommitQC。CommitQC 承载了 2/3+1 节点对该 ViewBlock 提交的认可,需要在提案完成提交时存储,作为后续同步已提交 ViewBlock 的合法性证明。这也是为什么 QC 结构中要存有 commit_view_block_hash 字段的原因。
- HighQC 与 HighTC
保证新提案打包的 HighQC 一致,同时和 HighTC 一起保证各个节点的 CurView 一致。
3.8.2 同步方式
为避免 O(n^2) 的通讯复杂度,同步使用 Gossip 协议,每个周期将本节点信息随机同步给 N 个节点。下图是 Gossip N=1 的同步示意,初始仅有一个节点拥有最新状态,每次同步各节点随机选择 1 个节点发送本地数据,经过三次同步后覆盖了全部 5 个节点。
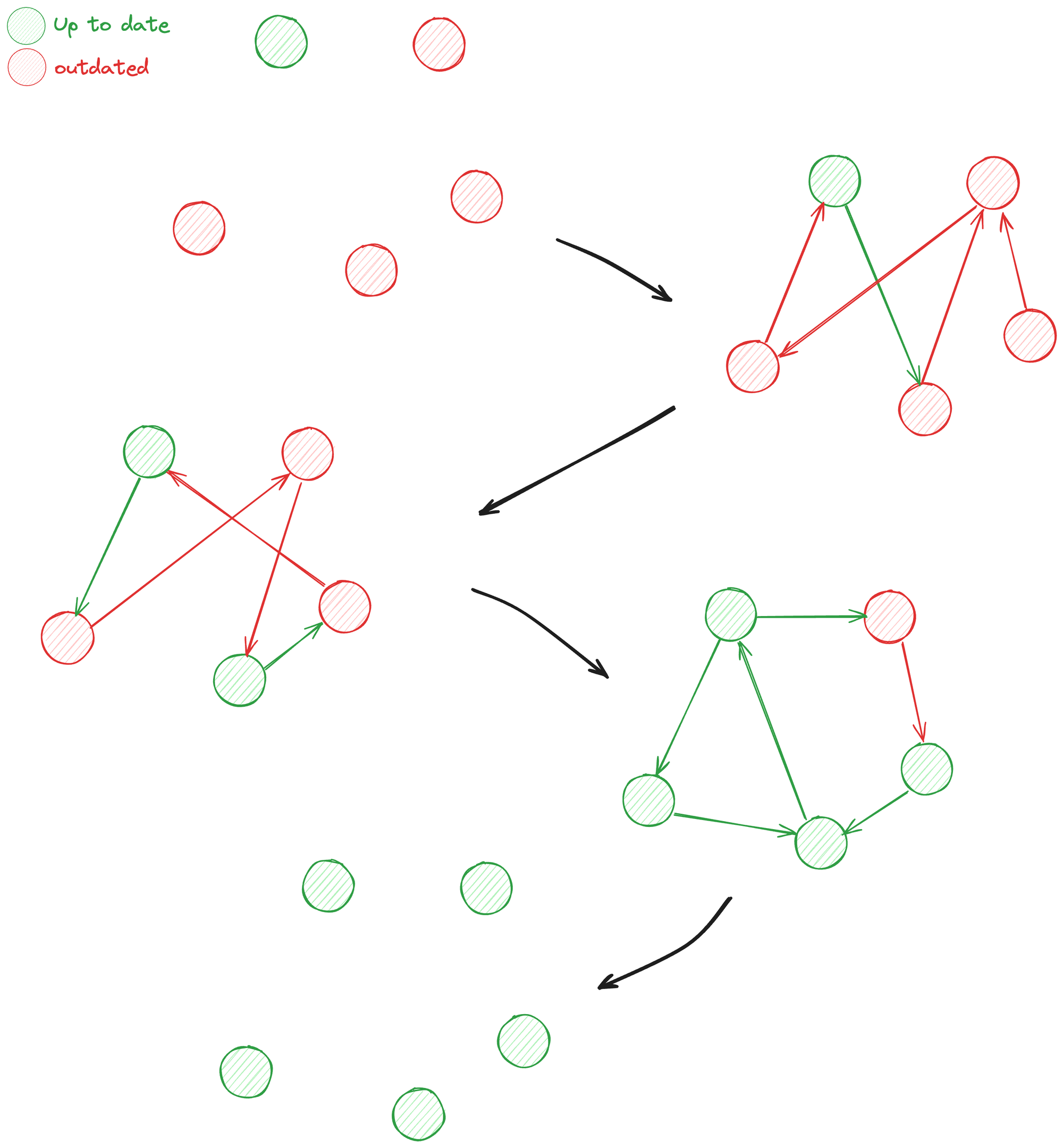 图 3.14 N = 1 时,Gossip 需要多次同步才能保证状态一致
图 3.14 N = 1 时,Gossip 需要多次同步才能保证状态一致
这种同步方式可能需要多次同步才能保证 2/3+1 的节点实现数据一致,但降低了通讯复杂度,可以避免过量带宽的占用。
3.8.3 同步时机
同步触发时机如下:
- 周期性定时同步。
- 节点触发超时时同步。
- 验证提案失败时同步,具体为 Leader 不一致和提案的父块缺失。
3.9 Leader 选举
在 HotStuff 中,Leader 的选举策略并未在协议中严格规定,但需要保证选出的 Leader 具有一致性和有效性。通常的 Leader 选举策略可以考虑以下因素:
- 随机选择:使用随机数生成器选取一个 Leader。例如,可以结合当前的时间戳、最新已提交块、HighTC、CurView 等信息生成随机数,以确保在一定程度上的随机性和公平性。
- 避免连续选举相同 Leader:为了防止连续选举相同的 Leader,可以在随机因子中加入一些额外的信息,如 TC 或 CurView 的信息,以增加随机性和分散概率。如,TC 保证了不会由同一个 Leader 连续处理超时异常。
Shardora 的 Leader 选择考虑了上面两个因素,并结合共识成功次数ConsensusOkNumber动态调整节点选为 Leader 的概率,伪代码如下:
randHash = hash(latestCommittedBlock.qc.String() + nowTime / 30s + HighTC)
leader = GetLeaderByConsensusOkNumber(randHash)- 随机因子:
latestCommittedBlock确保每次成功共识后进行 Leader 轮换。HighTC确保每次共识失败后进行 Leader 轮换。nowTime / 30s提供一个周期性的随机因子,以应对 Leader 宕机或恶意行为未广播 TC 的情况,强制 30s 进行一次轮换。
- 共识成功次数:
- 每个节点维护一个新的本地状态,记录每个节点的共识成功次数
ConsensusOkNumber。 - Replica 收到新的提案时,根据自身的记录计算出新的
ConsensusOkNumber,并将其包含在新的区块中提交给网络。 - 每当某个区块被提交时,同时提交包含 Leader 的
ConsensusOkNumber,更新本地记录。
- 每个节点维护一个新的本地状态,记录每个节点的共识成功次数
根据节点的ConsensusOkNumber动态调整被选为 Leader 的概率。共识成功更多次的节点在随机选取时有更高的概率被选中,以提高系统的整体效率和鲁棒性。
以下是计算共识成功次数的简化代码示例,展示了如何根据最新提交块到最新提案之间的块数计算 Leader 的共识成功次数:
int CalculateConsensusOkNumber(const ViewBlock& v_block) {
int additionalSuccesses = 0;
auto currentBlock = v_block;
// 回溯到最新提交块之前的所有块,计算该 Leader 的共识成功次数
while (currentBlock.view > LatestCommittedBlock().view) {
currentBlock = QcRef(currentBlock);
if (currentBlock.leader == v_block.leader) {
additionalSuccesses++;
}
}
// 加上当前视图块本身,计算新的共识成功次数
return LatestCommittedConsensusOkNumber(v_block.leader) + additionalSuccesses + 1;
}4 工程优化
Shardora 是一条基于多分片扩容、支持多交易池并发的高性能区块链,我们使用改进的 PoS + HotStuff 共识机制保证共识的安全性和性能。本部分介绍在开发过程中针对 Chaine HotStuff 进行的部分工程优化。
4.1 高 TPS 下的 QC、TC 一致性优化
当 Leader 发起一个新视图的共识时,HighQC 和 HighTC 会跟随 ProposeMsg 一同广播给 Replicas,然而如果打包提案失败,刚刚生成的新 QC 也无法同步给 Replicas,只能等待同步,这会大幅拉低系统吞吐量。因此在新提案打包失败时单独对 QC 进行广播,这比等待同步要快的多,如图所示。
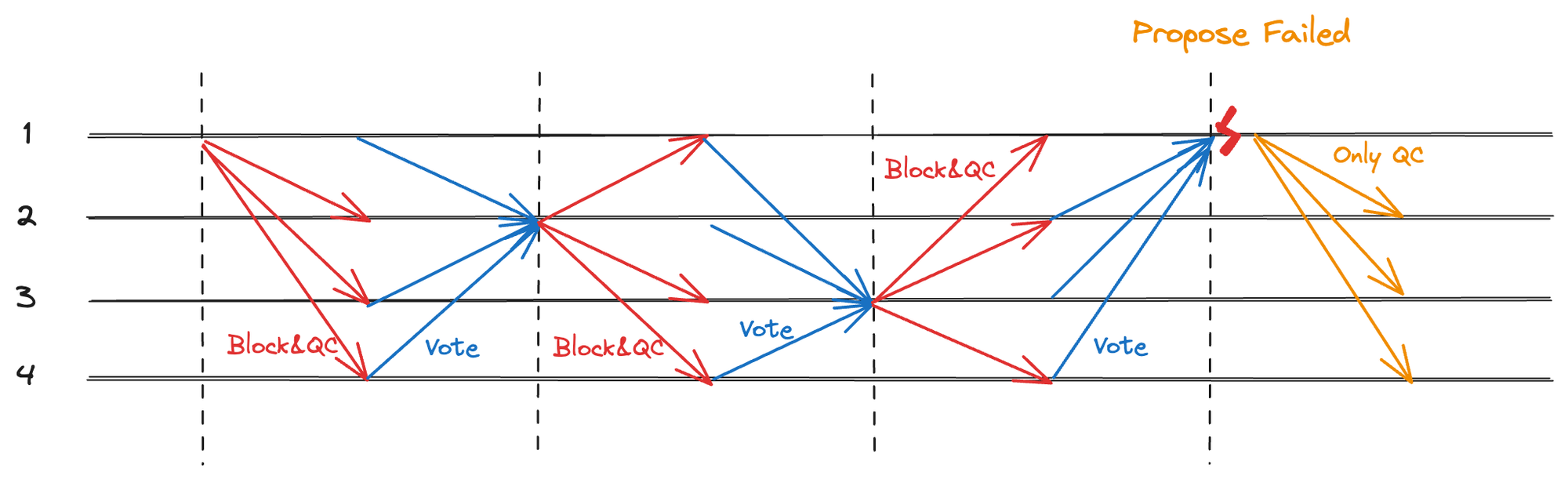 图 4.1 正常情况,提案打包失败,仅广播 QC
图 4.1 正常情况,提案打包失败,仅广播 QC
超时生成的 TC 也是如此,如果因为提案打包失败而导致 TC 无法广播,那么 Replica 就会认为视图切换失败不断申请切换该视图,系统便会丧失活性,因此应该在 Propose 失败时单独广播 TC,确保 Replica 能够切换到新的视图,如图所示。
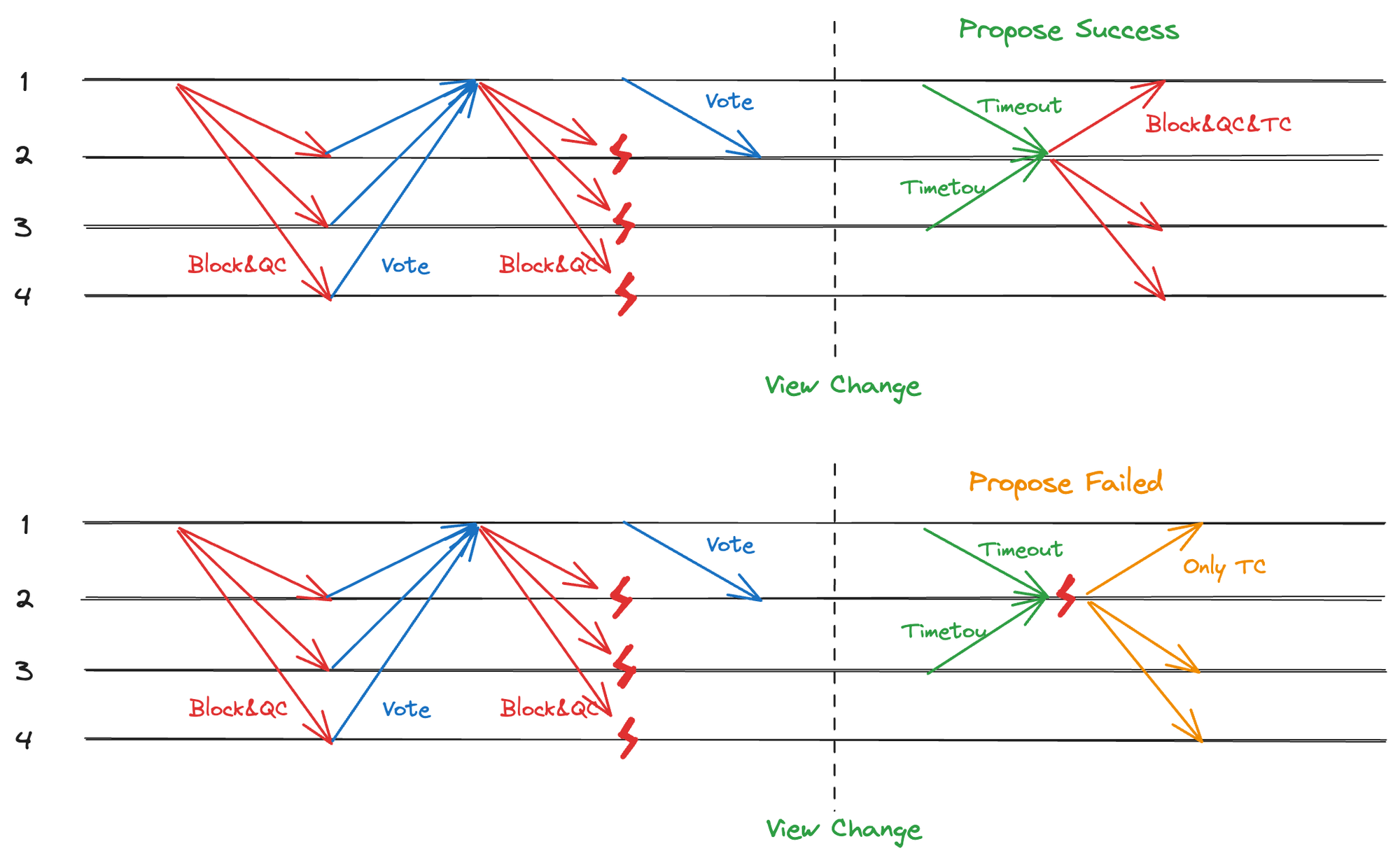 图 4.2 超时情况,提案打包失败,仅广播 TC
图 4.2 超时情况,提案打包失败,仅广播 TC
4.2 高 TPS 下的交易池一致性优化
与使用中本聪共识的区块链不同,BFT 要求投票节点在投票时提案中的交易必须存在。如果每次收到交易后再使用 Gossip 的方式进行扩散,由于交易同步存在延迟,就会出现投票时本地交易池中找不到该交易的情况,造成共识失败而拉低系统性能。
因此,Shardora 的交易并不是以 Gossip 进行扩散的,而是由指定的节点接收,并跟随 Propose & Vote 消息在节点之间进行传递的,原理如下图。
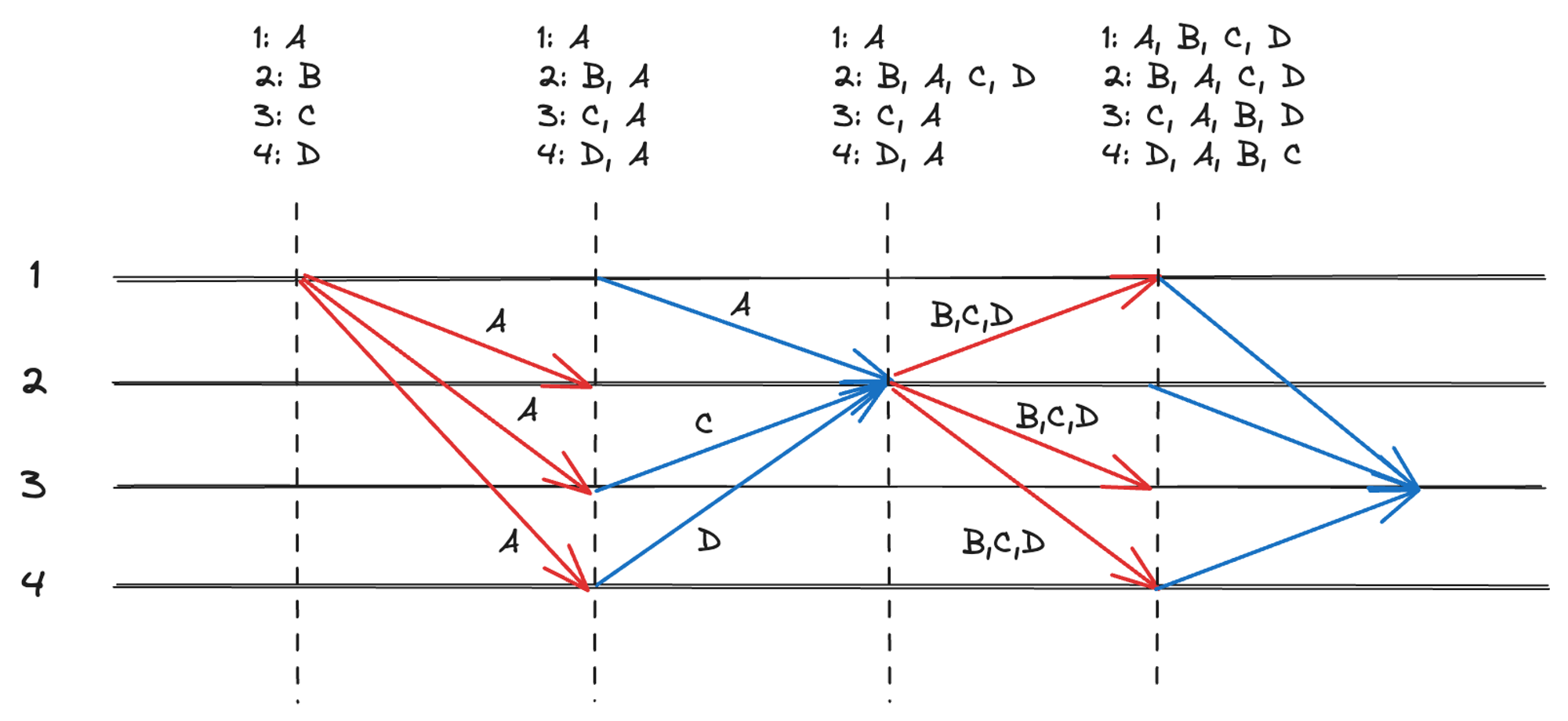 图 4.3 交易通过 Propose & Vote 消息传播
图 4.3 交易通过 Propose & Vote 消息传播
图中,4 个节点(1, 2, 3, 4)初始状态各自拥有不同的交易(A, B, C, D),这些交易会随着 Propose 和 Vote 共识消息进行传播。比如,当一个 Replica 收到一条 Leader 发来的新交易,就会将该交易加入交易池,而在 Replica 发送投票消息给 Leader 时,也会附带本地的一部分交易作为同步。
这种交易同步方式也对应了后文中对于交易延迟的优化,此处仅做简单介绍,具体内容请参考 Shardora 白皮书。
4.3 低 TPS 下的交易延迟优化
低 TPS 场景下,如果交易池长时间没有交易,Leader 不能出块,会持续触发超时,超时导致阈值签名和验签会极大地消耗 CPU 消耗资源。
当然,由于超时时间是根据历史共识情况动态调整的,不断地超时会持续增加超时时间,使得 CPU 占用率逐步降低。然而,Shardora 使用多个交易池并行出块,本身会耗费更多的 CPU,实际测试中超时时间在10s 以上才能令 CPU 占用率降至合理区间。
在长时间无交易场景下,较高的超时时间会造成突发交易的较大延迟,系统需要等待一个超时触发的视图切换后才能出块。为此,Shardora 为节点增加了交易监听功能,如图 4.4 所示。
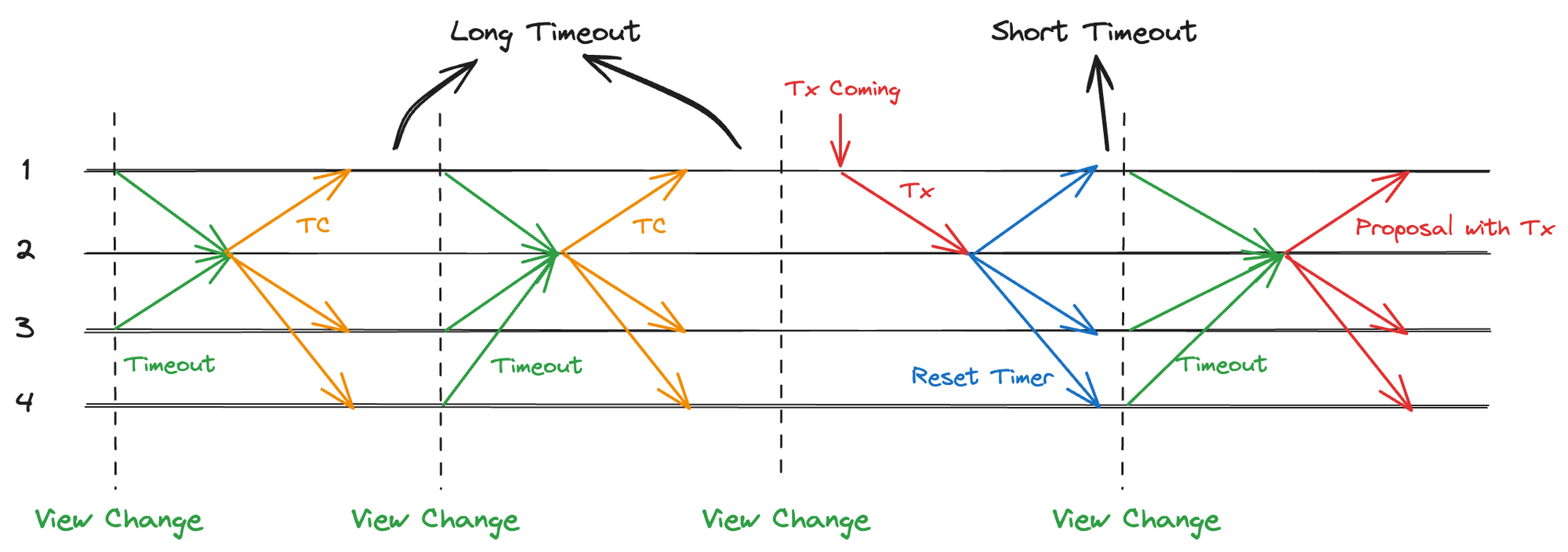 图 4.4 新交易到来重置超时时间
图 4.4 新交易到来重置超时时间
图中,交易池中长时间没有交易,系统不停地触发超时进行视图切换,此时:
- 节点 1 突然收到一条交易,会将该交易同步给 Leader。
- Leader 收到消息后,将其中的交易添加到自己的交易池,并广播
ResetTimerMsg给所有 Replicas - Replica 收到该 Leader 的消息后,会重置超时时间到初始值。
- 超时被快速出发,Leader 打包该交易到提案,尝试共识出块。
超时时间和视图号关系如图。
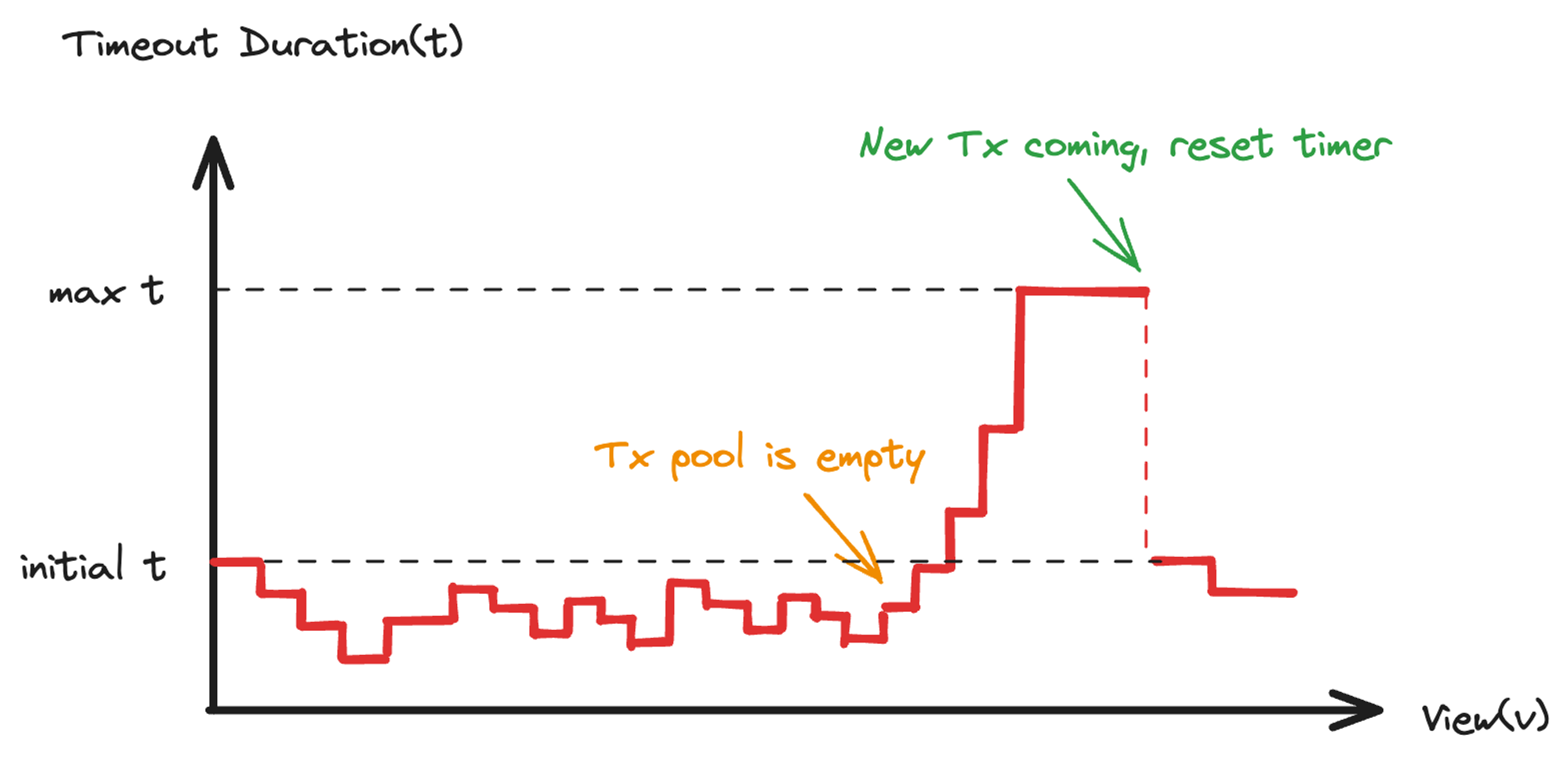 图 4.5 无交易和新交易到来时超时时间变化
图 4.5 无交易和新交易到来时超时时间变化
4.4 低 TPS 下的交易提交优化
在 Basic HotStuff 中,一个新视图开启时前一个视图已经完成提交,而在 Chained HotStuff 中却无法保证这一点。提交一个块需要三个连续的 QC,而 QC 是随提案下发的,如果交易池中没有交易后就无法打包提案,那么最后两个有交易的提案就永远无法提交了。
因此需要允许对无交易提案进行共识,提案中没有交易,只有前一个块的 QC。每个有交易提案之后最多跟随无交易提案,超过数量便不再允许,防止无意义的空块占用资源。下面代码即是否允许打包无交易提案的判断逻辑。
bool IsEmptyBlockAllowed(const ViewBlock& v_block) {
auto v_block1 = QcRef(v_block);
if (!v_block1 || v_block1.tx_list_size() > 0) {
return true;
}
auto v_block2 = QcRef(v_block1);
if (!v_block2 || v_block2.tx_list_size() > 0) {
return true;
}
auto v_block3 = QcRef(v_block2);
if (!v_block3 || v_block3.tx_list_size() > 0) {
return true;
}
return false;
}5 性能测试
Shardora 支持多分片多交易池,每个交易池单独进行共识出块,由于仅测量 HotStuff 共识逻辑,这里仅对单分片单交易池进行压测,实测 300 节点约 1w+ TPS。
Shardora 目前仍处于开发阶段,你可以前往Github 项目地址查看并测试 HotStuff 代码。
6 参考资料
论文: HotStuff: BFT Consensus in the Lens of Blockchain Fast-HotStuff: A Fast and Robust BFT Protocol for Blockchains 文章: State Machine Replication in the Libra Blockchain What is the difference between PBFT, Tendermint, HotStuff, and HotStuff-2? 为什么PBFT需要View Changes https://hyperchain.readthedocs.io/zh-cn/stable/consensus mechanism.html#noxbft 代码: https://github.com/relab/hotstuff





