解读Cysic:硬件加速与ZK矿业的崛起前夜
- 仙壤
- 发布于 2024-07-26 22:07
- 阅读 4477
硬件加速领域中,Cysic可能是最受关注的劲旅之一
作者:Nickqiao & 雾月,极客web3
今年4月,Vitalik造访香港区块链峰会,发表了题为《Reaching the Limits of Protocol Design》的演讲,其中再次提到ZK-SNARKs在以太坊Danksharding路线图中彰显出的潜力,并展望了ASIC芯片对ZK加速的巨大帮助。
此前Scroll联创张烨也曾指出, ZK在传统领域的应用空间可能比在Web3内的还大, 可信计算、数据库、可验证性硬件、内容防伪及zkML等领域都有对ZK的巨大需求,如果ZK证明实时生成可以落地,Web3和传统行业都有望迎来范式级的变革,但从效率和经济成本角度看,目前要让ZK投入大规模采用还尚且遥远。
其实,早在2022年,顶级风投机构a16z和Paradigm就公开发表报告,明确表达了对ZK硬件加速的重视, Paradigm甚至断言:未来ZK矿工的收入可能比肩比特币或以太坊矿工,基于GPU和FPGA、ASIC的硬件加速方案将具备巨大的市场空间。 此后,随着Scroll和Starknet等主流ZK Rollup的火热,硬件加速一度成为市场追捧的热点概念,这种热度随着 Cysic 等项目的临近上线而变得愈发浓重。

我们有理由认为,基于ZK的巨大需求空间,ZK矿池及实时ZKP生成的SaaS模式可以开辟出崭新的产业链,在这片颇具潜力的新大陆中,有实力支撑且具备先发优势的ZK硬件厂商完全可能成为下一代的比特大陆,雄踞硬件加速的沃土。
而在硬件加速领域中,Cysic可能是最受关注的劲旅之一,该团队曾获得知名ZKP技术竞赛平台ZPrize的重要奖项,并在2023年开始作为ZPrize的导师;其路线图中囊括的ToB端ZK矿池与ToC ZK-Depin硬件更是吸引了Polychain、ABCDE、OKX Ventures和Hashkey等顶级VC的垂青,完成了总计近2000万美元的大额融资。
随着7月底Cysic测试网即将上线,以及其ZK矿池的开放在即,各大社区中关于Cysic的讨论渐趋热烈,本文旨在让更多人了解Cysic的产品原理与业务模式,并对ZK硬件加速原理进行简单科普。在下文中, 我们将对Cysic的相关知识进行简要概括,帮助更多人降低理解门槛。
从工作流程理解ZK证明系统
ZK证明系统其实是很复杂的,但如果要对其大体构造有个简单理解,可以从职能和工作流程角度进行分解。对于一个把普通计算ZK化的系统而言,其核心流程概括如下:
首先我们要通过前端与ZK系统交互,向其提交待证明的内容,前端会将这些内容进行格式转换,便于被ZK证明系统处理。之后,系统会通过特定的证明系统或框架(如Halo2、Plonk等)生成ZK Proof。这个过程可以细分为以下几步:
1. 问题设置: 首先我们要确定待证明的内容是什么。比如,证明者Prover声明自己掌握/知道某样数据,“我知道方程式F(x)=w的一个解N”,但他又不想让人看到N的数值。
2.算术化与CSP: 证明者提交待证明的内容后,系统会建立专门的数学模型/程序,等价的表达出待证明内容,然后进行格式转换,便于被证明系统处理。具体而言,前述声明“我知道方程F(x)=w的一个解N”将从原始的数学等式,转化为逻辑门电路和多项式的形态。
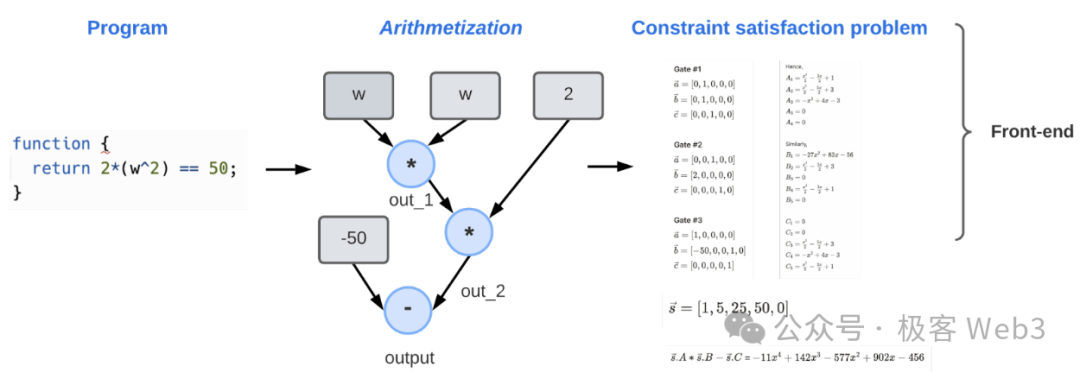
- 之后,系统将选择合适的证明系统如Halo、Plonk等,将前面几步生成的内容编译为可用的ZKP程序。证明者使用该ZKP程序生成证明,交由验证者做验证。
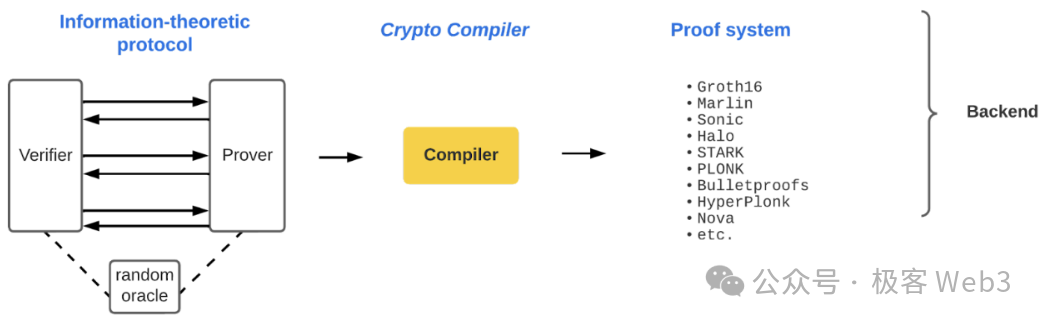
像zkEVM等频繁在以太坊二层当中被采用的ZK系统,本质是先将智能合约编译为EVM的底层操作码,然后对每个操作码进行格式转换,转化为逻辑门电路/多项式约束的形式,再交由后端的ZK证明系统做进一步处理。
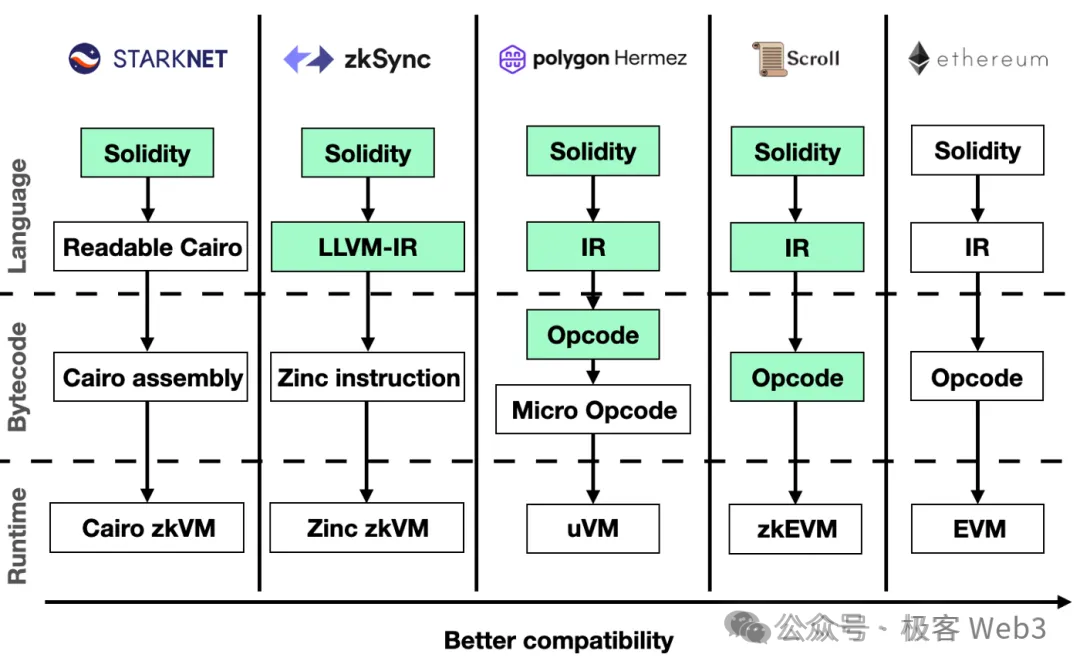
值得一提的是,目前在区块链中被广泛使用的ZKP技术方案主要是zk-SNARK(零知识简洁非交互式知识论证),而 ZK Rollup大多数利用了SNARK的简洁性而非零知识性。 简洁性意味着ZKP占用的空间很小,可以把大量的内容压缩到几百个字节,验证成本非常低。
这样一来,Prover和Verifier之间的工作量是不对称的,Prover生成ZKP的成本很高,Verifier的验证成本却很低,只要利用好这种不对称性,在“单一Prover,多个Verifier”的场景下采用ZK,可以将整体的成本集中在Prover侧,极大程度降低Verifier的成本,这种模式对去中心化验证极其有利,以太坊二层的思路便是如此。
但这种将验证成本转嫁到ZK生成端的模式并不是银弹,对于ZK Rollup项目方而言,生成ZKP付出的高昂成本最终必然会再度转嫁到UX和手续费上,这并不利于ZK Rollup的长期发展。
纵使ZK在去信任和去中心化验证的场景下有很大的用武之地,但 受限于生成时间上的瓶颈,无论是zkEVM还是zkVM或是ZK Rollup和ZK桥,目前都不具备大规模采用的经济基础。
对此,以Cysic、Ingonyama、Irreducible等为代表的ZK加速项目应运而生,分别从不同的方向尝试降低ZKP的生成成本。下文中,我们将从技术角度简要介绍ZKP生成的主要开销与加速方式,以及为何Cysic在ZK加速赛道具备巨大的潜力。
运算开销:MSM和NTT
很多人都知道,ZKP的Prover生成证明的时间开销非常的大。在ZK-SNARK协议中经常会出现这样一种情况:Verifier只需要一秒就可以验证证明,但是证明的生成可能需要花费Prover半天甚至一天的时间。 为了高效的使用ZKP证明计算,有必要要将计算格式从经典程序转换为ZK友好。
目前有两种方法可以做到这一点:一种是使用一些证明系统框架编写电路,例如Halo2;另一种是使用领域特定语言 (DSL),如Cairo或Circom,将计算转换为中间表达形式,以便后续提交给证明系统。证明系统会根据编写的电路或DSL编译的中间表达形式来生成ZK证明。
程序操作越复杂,生成证明所需的时间就越长。另外,某些操作在本质上对ZK不友好,实现它们需要额外的工作。例如,SHA或Keccak哈希函数是ZKP不友好的,使用这些函数将导致证明生成时间延长。而即便在经典计算机上执行成本很低的操作,也可能是ZKP不友好的。

而抛开ZK不友好的计算任务不说,虽然ZK证明生成过程可能因选用的证明系统而异,但其瓶颈本质上都是相似的。 在ZK证明的生成中,有两种计算任务最消耗计算资源:MSM(Multi-Scalar Multiplication)和NTT(Number Theoretic Transform)。这两种计算任务可以占到证明生成时间的 80-95%, 具体取决于 ZKP 的承诺方案和具体实现。
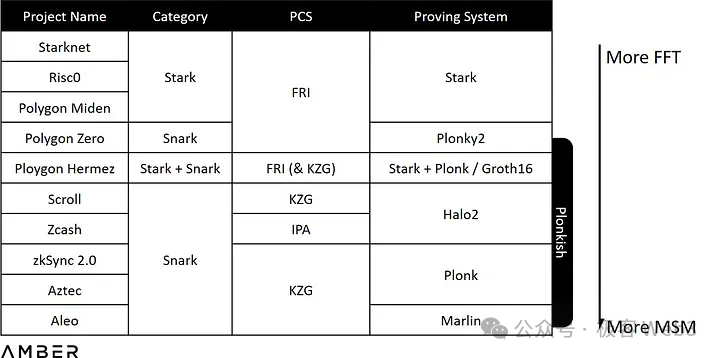
MSM主要处理椭圆曲线上的多标量乘法,而NTT则是在有限域上的FFT(快速傅立叶变换),用于加速处理多项式乘法。使用不同的方案组合将带来不同的FFT/MSM负载比例。
以Stark为示例,其PCS (Polynomial Commitment Scheme,多项式承诺方案)使用的是FRI,一种基于哈希的承诺,而不是像KZG或IPA所使用的椭圆曲线,因此完全没有MSM的计算。表中越靠上意味着需要越多的FFT运算,越靠下则需要越多的MSM运算。
优化方案
由于MSM运算涉及可预测的内存访问,虽可以大量并行化,但需要消耗大量的内存资源。另外,MSM还存在可扩展性挑战,即使并行化的前提下,也可能很慢,因此,虽然MSM有可能在硬件上加速,但它们需要巨大的内存和并行计算资源。
NTT往往涉及随机内存访问,这使得它们对硬件不友好,而且在分布式基础设施上难以处理,这是因为NTT随机访问的特点,其如果在分布式环境下运行,不可避免地要访问其他节点的数据,一旦涉及到网络交互,性能就会大大下降。
因此,存储数据的访问和数据移动成为一个主要的瓶颈,限制了NTT运算并行化的能力,加速 NTT的大部分工作,都集中在管理计算如何与存储器交互上。
其实,解决MSM和NTT效率瓶颈最简单的方法,是彻底消除这些操作。一些新提出的算法,比如Hyperplonk,对Plonk进行了修改,消除了NTT操作。这使得Hyperplonk更易于加速,但引入了新的瓶颈;再如计算成本较高的sumcheck协议。还有STARK算法, 它不需要MSM,但其FRI协议引入了大量哈希计算。
ZK硬件加速与Cysic的终极目标
尽管软件和算法层面的优化非常重要且具有价值,但存在明显的局限性。为了充分优化ZKP的生成效率,必须使用硬件加速,这就像ASIC和GPU最终称霸BTC和ETH挖矿市场。
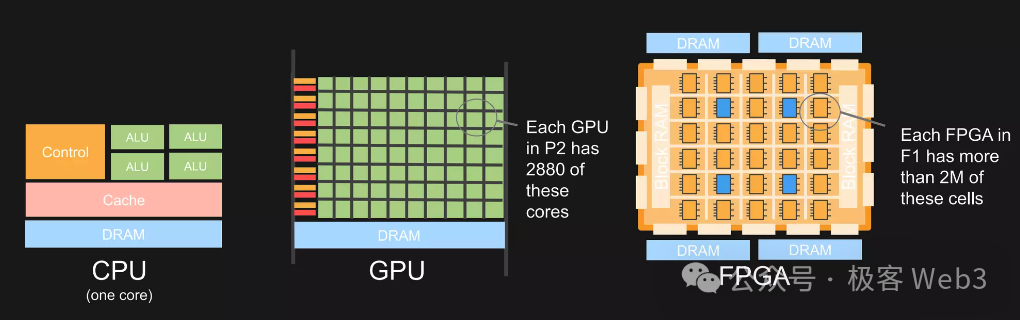
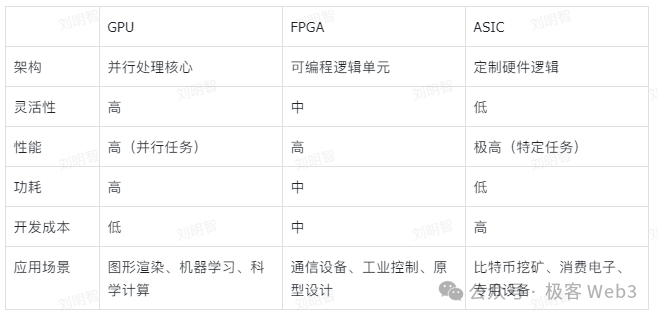
那么问题是:加速ZKP生成的最佳硬件是什么?目前有多种硬件可以实现ZK加速,如GPU、FPGA或ASIC,当然他们各有优劣.
我们可以对比一下这几种硬件:
首先我们通过一个简单的例子来说明它们在开发层面的区别。比如,现在我们要实现一个简单的并行乘法:
-
在GPU上,利用CUDA SDK提供的API,我们可以像写原生代码一样开发,从而获得并行计算的能力;
-
在FPGA上,我们需要重新学习硬件描述语言,使用这种语言来控制硬件级别的连接,以实现并行算法;
-
在ASIC上,芯片设计阶段硬件层面便直接固定好晶体管的连接排布,之后无法再进行修改。
这几种方案各有优劣,适用在ZK赛道的不同发展阶段。而Cysic致力于成为ZK硬件加速的终极解决方案,其分步战略为:
-
基于GPU开发SDK为ZK应用提供解决方案,并整合全网GPU资源;
-
利用FPGA的灵活性和各项平衡的特点,快速实现定制化的ZK硬件加速。
-
自主研发基于ASIC的ZK Depin硬件
-
而Cysic Network则将以SAAS平台/矿池的身份,整合ZK Depin与GPU的所有算力,为整个ZK行业提供算力与验证解决方案
下面让我们通过对多个细分赛道展开解读,来充分理解ZK加速方案的细分差异与Cysic的发展思路。
ZK矿池与SaaS平台:Cysic Network
其实,无论是Scroll还是Polygon zkEVM等知名ZK Rollup,都曾在其路线图中明确提出了“去中心化Prover”的概念,而这实际上就是构建ZK矿池。这种市场化的方式可以让ZK Rollup项目方减轻包袱,激励矿工和矿池运营方不断对ZK加速方案进行优化。
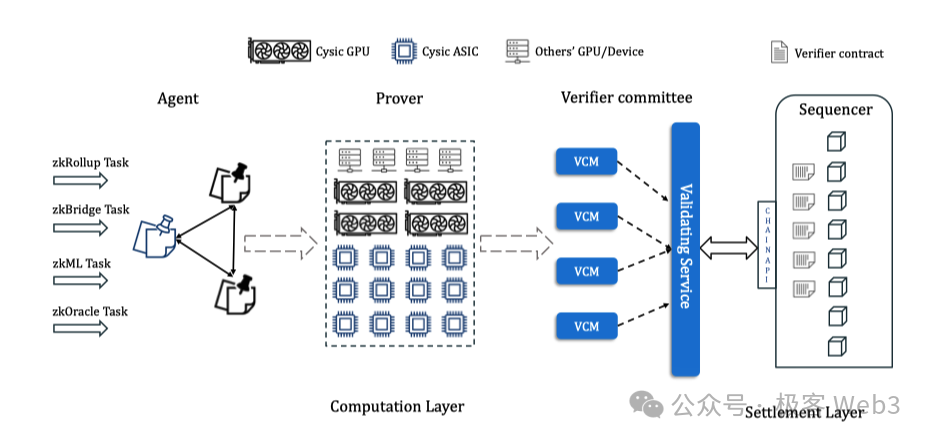
而在Cysic的路线图中,已明确提出名为Cysic Network的ZK矿池与SaaS平台计划。 它不但会集成Cysic自有算力,还将通过挖矿激励的方式吸收第三方算力资源,包括闲散的GPU和普通用户手上的zk DePIN设备。
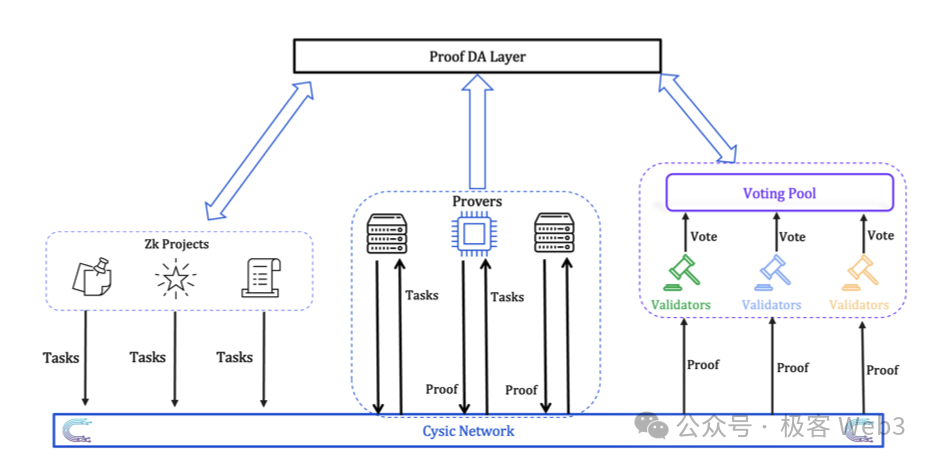
其整个验证工作流示意图如下:
-
zk项目方将证明生成任务提交给代理人(Agent),后者的工作是将证明任务转发至验证网络。这些Agent在一开始将由Cysic官方运行,后续将引入资产质押,让任何人都能成为Agent;
-
Prover接受证明任务,并使用硬件生成ZK证明,证明者需要质押Token来参与证明任务的承包,完成证明任务后将获得奖励;
-
验证者委员会负责检查Prover生成证明的有效性并进行投票,当达到一定的票数后,证明将被认为有效。验证者通过质押Token加入委员会,参与投票并获得奖励,这个过程可以结合EigenLayer的AVS概念,复用现有的Restaking设施。
其详细交互过程如下:
其实上面的流程中有个点,无论是资产质押还是激励分发,以及计算任务的提交等动作都需要依赖于某个专属平台,这就需要有区块链作为专用设施。
为此Cysic Network搭建了一条专属公链,采用了一种独特的共识算法,称为 Proof of Compute (PoC),其基本原理是基于VRF函数和Prover的历史表现,比如设备的可用性、提交证明次数、Proof正确率等等,来选择出块人负责出块(注:它这里的区块应该是用于记录各台设备的信息和分发Token激励)。
当然,在ZK矿池和SaaS平台之外,Cysic基于不同硬件的ZK加速方案上都进行了大量布局。接下来让我们分别了解其在GPU、FPGA和ASIC三条路线上的成果。
GPU、FPGA和ASIC
ZK硬件加速的核心在于将一些关键运算尽可能并行化。 而从硬件的功能特性来看,CPU为了实现最大的灵活和通用,芯片中很大一部分面积都用来提供控制功能和各级缓存,这导致其并行计算能力较弱。
在GPU当中,用作运算的芯片面积比例大大提高,这使其能够支持大规模的并行处理。现在GPU已经非常普及,例如Nvidia Cuda等库可以帮助开发人员利用GPU的并行性,而无需了解底层硬件,通过CUDA SDK可以封装CUDA ZK库加速MSM和NTT运算。
而FPGA则由大量小型处理单元组成的阵列,要对FPGA进行编程,需使用专门的硬件描述语言,再将其编译为晶体管电路组合。所以FPGA实际上是直接用晶体管电路实现特定算法,而不需要经过指令系统的编译。这种定制性和灵活性要远胜GPU。
目前 FPGA价格大约仅是GPU的三分之一,且能效可以比GPU高出十倍以上。 这种显著的能效优势部分原因在于GPU需要连接到主机设备,而主机设备通常消耗大量电力。可以说,FPGA可以在不增加能耗的情况下,增加更多的运算模块来应对MSM和NTT的需求。这使得FPGA特别适合计算密集型、需要高数据吞吐量和低响应时间的ZK证明场景。
然而, FPGA最大的问题是鲜少有开发人员具备编程经验, 对于ZK项目方而言,组织一个既拥有密码学专业知识、同时拥有FPGA工程专业知识的团队极其困难。
而ASIC则相当于完全用硬件来实现某个程序,一旦设计完毕,硬件就无法更改,相应地,ASIC能够执行的程序自然也无法更改,只能用作特定任务。上面讲述的FPGA在MSM和NTT方面的硬件加速优点,ASIC同样也具备。 而由于是专用电路设计,ASIC在所有方案里是效能最高、能耗最小的。
对于目前主流的ZK Circuit, Cysic希望证明时间能实现1 - 5 秒的速度,想要达到这个目标,只有ASIC能够实现。
虽然这些优点听起来非常吸引人,但ZK技术正在快速发展,而ASIC的设计和生产周期通常需要1-2年,并且成本高达1000-2000万美元。因此,必须要等到ZK技术足够稳定,才能投入大规模的生产,以避免生产出的芯片很快就过时。
对此,在GPU和FPGA、ASIC这三个领域,Cysic都做了充分布局;
在GPU加速方案层面,随着各种新型ZK证明系统的诞生,Cysic基于自研CUDA加速SDK对它们进行了适配,并通过聚拢社区资源的方式,在Cysic的GPU算力网络中链接了数十万张顶级算力显卡,同时Cysic CUDA SDK比最新的开源框架提速了50%-80%甚至以上。
在FPGA上,Cysic通过自研方案,完成了全球最快的MSM、NTT、Poseidon Merkle tree等模块的实现,覆盖了ZK计算最主要的部分,而且该方案经过了多个顶级ZK项目的原型验证。
Cysic自研的SolarMSM可以在0.195秒内完成2^30规模的MSM计算,而SolarNTT能在0.218秒内完成2^30规模的NTT计算,是目前所有公开的FPGA硬件加速结果中性能最高的。


而在ASIC领域,虽然距离ZK ASIC的大规模应用还有一定距离,但Cysic已经提前布局了这一赛道,并推出了自主研发的ZK DePIN芯片和设备。
为了吸引C端用户,并满足不同ZK项目方对性能和成本的要求, Cysic将推出两款ZK硬件产品:ZK Air和ZK Pro。

ZK Air的大小与充电宝、笔记本电脑电源相近,普通用户可以直接通过Type-C接口将其连接到笔记本、iPad甚至手机上,为特定ZK项目提供算力支持并获得奖励。目前ZK Air算力仍然超越消费级显卡,可以加速小规模的ZK证明生成任务。
ZK Pro则类似于传统矿机,算力达到了多块顶级消费级显卡互联GPU服务器的效果,能够大幅加速ZK证明的生成,适用于大型ZK项目,如ZK-Rollup和ZKML(Zero knowledge machine learning)。
通过这两款设备,Cysic最终将构建一个稳定可靠的ZK-DePIN网络。目前这两款设备还在研发中,预计于2025年上市。
此外,通过Cysic Network,C端用户能够以非常低的门槛加入到zk硬件加速市场,加上ZK项目方对算力的大量需求,这可能使市场再次掀起一波如同比特币挖矿一样的热潮,ZK计算领域的市场规模可能将再次迎来爆发式增长。
reference
https://medium.com/amber-group/need-for-speed-zero-knowledge-1e29d4a82fcd
https://figmentcapital.medium.com/accelerating-zero-knowledge-proofs-cfc806de611b





