对ZK应用程序的审计示例:Tornado Cash
本文通过对基于零知识证明的项目 Tornado Cash 的分析,探讨了 ZK 审计的思维方式和关键点。作者详细说明了 Tornado 的智能合约逻辑,尤其是与 ZK 证明相关的关键部分,包括存款和取款的流程,以及潜在的攻击向量和安全措施。此外,文章还涉及到 Merkle 树和 Pedersen 哈希的实现及其在安全性中的重要性,强调了对 ZK 项目分析的复杂性及其快速发展的领域特性。
作者:Sergey Boogerwooger
MixBytes 的安全研究员

引言
以下是分析一个基于 ZKP 项目的示例,采用的是现实生活中的例子:Tornado Cash。这并不是一个全面的安全审计,而是一个 ZK 审计员思维方式的展示。我们的意图是指出代码中的关键点,并展示一些特定于 ZK 审计的问题。真正的审计需要更为彻底的分析,研究所有底层算法和证明系统本身,但即使不用深入研究底层的加密构造,也可以提到一些有趣的问题,主要是在 ZK 证明与外部代码交汇的地方。
我们将分析协议的不同部分,并尽力展示审计员的目光应停止的地方以及哪些部分是安全关键的。选择 Tornado Cash 作为示例,是因为它的代码库已成为许多其他使用 "集合成员资格" 证明的项目的基础,并且它已在现实世界的 ZK 应用中得到了充分验证。而且,Tornado 并不太大,因此可以在本文中观察,同时也不太小,使用了多个重要的 SNARK 友好原语。
合约逻辑审计
Tornado 将其部分逻辑放置在智能合约中,这当然也必须被审计,但在本文中,我们不会查看 Tornado 的整个 Solidity 代码范围,而只关注与 ZK 证明直接相关的部分。同时,我们无法完全避免 Solidity 部分的逻辑,因为它定义了 ZK 证明是如何使用的,以及如何利用它们来攻击协议,因此,至少需要对合约进行一次高级别的审查。主合约 Tornado.sol 在 这里。简而言之:用户生成并保存两个秘密随机值:secret 和 nullifier,生成两个哈希值:commitment(由这两个值组成)和 nullifierHash(仅由 nullifier 生成)。在 "deposit()" 阶段,用户在 Tornado 的合约中添加用固定数量的 ETH 弄成的 Merkle 树。随后,在 "withdraw()" 阶段,用户使用他的 secret、nullifier 和公共 Merkle 树生成证明确实知道这样一个 commitment(由相同的 secret 和 nullifier 生成),且属于这个 Merkle 树(而且不透露确切的叶节点),并且该 nullifier 对应于正确的 nullifierHash。合约同时保存已使用的 nullifierHash,以避免二次 "支出" 已用叶节点。
另一个重要的事情是使用 nullifierHash 而不是 "纯" nullifier。这样做是为了减轻提款者的悲剧,当攻击者看到用户的 nullifier 时,抢先提款,创建与用户相同 nullifier 的存款,然后提款,因此,拒绝原用户的提款。
你可以在许多现有的文章中阅读整个算法,我们不需要深入其中,我们的目标是集中在与 ZK 相关的部分。
分析 ZK 相关项目结构
ZK 证明的使用
所有 ZKP 应用都包括证明生成,因此最重要的攻击向量是那些允许绕过基于以前提出的证明进行验证,或通过攻击者使用已知值伪造这些证明。此外,审计员还应该考虑当证明被抢先或从服务中盗取(这些服务正在迅速发展)时的情况,这些情况下,用户的证明被计算。
需要考虑的主要潜在攻击向量有:
-
伪造不正确的证明
在这种情况下,攻击者可以使用一些 "错误" 值(即超出允许范围的值,或为零的值)生成有效的证明。这些值在协议验证后可以使用。
-
重用现有证明
在这种情况下,攻击者可以获取一个先前提交的证明,修改作为公有输入传递的值以保持该证明的有效性,并重新提交带有已更改值的证明。
-
零知识滥用
在此情况下,来自公共值或证明的信息可以用来恢复私有值并泄露,或者对此内容做出一些建议。
考虑到这些向量,我们需要确定作为输入和输出使用的值并分析它们的向量。更具体地,对于每个输入值和证明,我们需要检查:
-
伪造
该值可以被恶意攻击者生成,从而允许生成有效的证明。
-
重放
相同的值或证明可以被再次重用,导致执行关键操作。
-
零知识滥用
可以重建私有值或使用公共数据推测其某些关键属性。
综上所述,让我们转向更高层次的流程分析。
分析高层次流程
用户与 Tornado 合约的主要交互流程包括两个主要阶段:deposit()和 withdraw()。
Deposit()接受单个 bytes32 _commitment 值。这个承诺被添加到 Merkle 树中,其值储存在发出的 Deposit 事件中,并且这个承诺也存储在合约中,以避免重复使用相同的承诺。在调用时接受固定数量的 ETH,并加到合约余额中。
事件中的承诺值由用户用于重建包含他们承诺的 Merkle 树。让我们记住这一点,因为这些值在某种程度上被攻击者控制(任何用户都可以向树中添加任何承诺)。
Withdraw() 是使用 ZK 证明的逻辑最关键的部分,作为唯一将 ETH 转移到外部的代码部分,它是潜在攻击的主要切入点。我们看到输入参数:
function withdraw(
bytes calldata _proof,
bytes32 _root,
bytes32 _nullifierHash,
address payable _recipient,
address payable _relayer,
uint256 _fee,
uint256 _refund
) external payable nonReentrant {
最后四个参数:_recipient、_relayer、_fee、_refund 是整个逻辑所必需的,但在我们的 ZK 审计的情况下,我们可以简单提到,必须由合法发送者严格执行这些参数的任何更改。任何外部用户不被允许进行改变,同时保持相同的证明。
前三个参数则是最重要的:_proof、_root、_nullifierHash——这是 ZK 证明,证明用户知道一个与 nullifier 拼接并哈希后的秘密值,该值成为 Merkle 树的一个叶子。
该 _proof 允许验证该秘密叶子是否属于我们的 Merkle 树,但不仅是这个事实。这个证明不应与其他提款参数重用,因为例如在 _recipient 未包含在证明中时(证明对于不同的 _recipient 值都是有效的),攻击者可以窃取证明并使用它们自己的 _recipient 地址。让我们记住这一点。
现在,三个 Solidity 检查 在这里:
require(_fee <= denomination, "Fee exceeds transfer value");
require(!nullifierHashes[_nullifierHash], "The note has been already spent");
require(isKnownRoot(_root), "Cannot find your merkle root"); // 确保使用的是最新的根
第一个是 _fee 检查。其底层的逻辑在 _processWithdraw() 中不是很有趣(需要在完整的 Solidity 审计中检查),但我们注意到 _fee 应该包含在 ZK 证明中,以避免使用其他 _fee 值的证明重用。
另外一个值得提到的事情是算术溢出在 EVM 和电路中的处理方式不同(因为值是在不同的字段中处理的),一些值在 EVM 中不导致溢出,但在电路内发生溢出(或者反之亦然)。因此,这里 _fee 参数的范围检查不仅为了保护 Solidity 逻辑。
第二个是 _nullifierHash 检查,用于避免相同承诺的二次使用。让我回忆一下 nullifier 的使用方式:用户将 secret 和 nullifier 拼接在一起,用 Pedersen 哈希进行哈希,获得承诺。来自测试中的代码在 这里:
function generateDeposit() {
let deposit = {
secret: rbigint(31),
nullifier: rbigint(31),
}
const preimage = Buffer.concat([deposit.nullifier.leInt2Buff(31), deposit.secret.leInt2Buff(31)])
deposit.commitment = pedersenHash(preimage)
return deposit
}
因此,这段代码中的潜在攻击向量是生成新的 _nullifierHash 时能够绕过 require(!nullifierHashes[_nullifierHash] 检查,保持证明有效。让我们记住这一点,并在电路部分回归。
最后的 require(isKnownRoot(_root) 检查与 Tornado 的逻辑有关,合约中保持多个 Merkle 根,每添加一个叶子就会创建一个新的 Merkle 根,并在设有 ROOT_HISTORY_SIZE 大小的列表中跟踪这些根。这允许用户为 _"最近的 ROOT_HISTORY_SIZE 根之一"_创建证明。
在这里我们看到一个低严重性的问题:攻击者能够不断创建新的 Merkle 根,其速度使得用户无法使用 "新鲜的" Merkle 根,因为它们都已经过时,阻止用户提款(这对攻击者是昂贵的,并且不会妨碍用户生成新的证明,因此这是一个小问题)。
另一个值得提到的点是任意用户添加新 Merkle 根并控制它的能力。在这个阶段没有想法,但也许它在未来可以被利用,我们就此记住。
接下来的重要 部分 代码:
verifier.verifyProof(
_proof,
[
uint256(_root),
uint256(_nullifierHash),
uint256(_recipient),
uint256(_relayer),
_fee,
_refund
]
)
在进行审计时,一个重要的步骤是确保可验证函数确实与给定电路相关,并且没有被否定。为此,你需要用相同的设置自行生成一个验证合约,并比较验证函数。
在参数中,我们看到所有用户提供的值,因此对于所有值:_root、_nullifierHash、_recipient、_relayer、_fee、_refund,我们需要回忆 ZKP 攻击的主要向量:伪造、重放和零知识滥用。为实现这一点,我们需要转到电路分析。
接下来的 Solidity 部分函数不在我们的审计范围内,保存已使用的 _nullifierHash —— 这个检查是重要的。提款逻辑和其他 Solidity 部分可以由你自行检查。让我们转向 ZKP 部分。
分析 ZKP 部分
电路约束
从主要 Circom 电路 模板,我们收到一整套输入:
signal input root;
signal input nullifierHash;
signal input recipient; // 不参与任何计算
signal input relayer; // 不参与任何计算
signal input fee; // 不参与任何计算
signal input refund; // 不参与任何计算
signal private input nullifier;
signal private input secret;
signal private input pathElements[levels];
signal private input pathIndices[levels];
首先,让我们检查 ZK 证明的输入:确保所有输入都参与了证明生成并且正确约束。这意味着在 Circom 电路中,必须使用这些值生成约束:
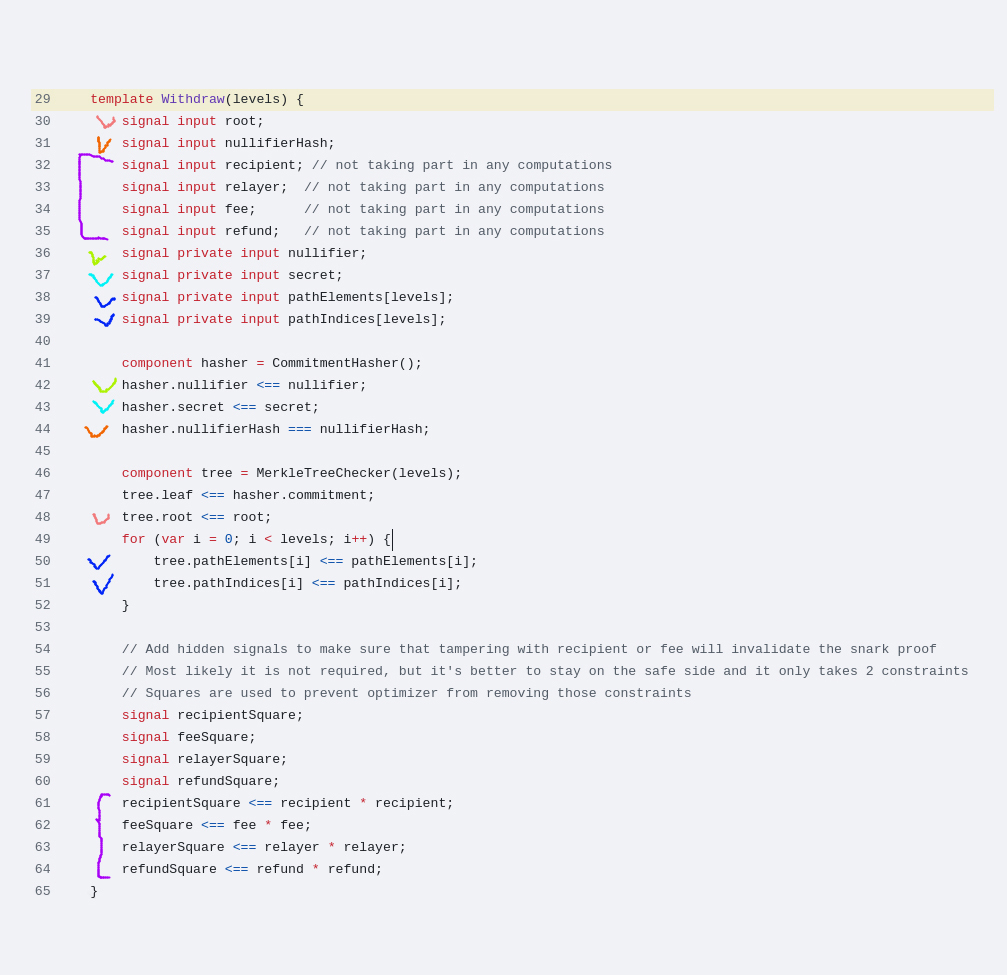
重要的是要理解,Circom 中的约束仅通过 === 或 <== 运算符生成。有时这些运算符可能会错过,并可能错误地使用 <--- 运算符。如果你发现一个不受约束的 <-- 信号,恶意证明者可以将其设置为任意值。它有时可以用于电路的优化,例如 这里,它允许将一个三元运算符从两个约束减少到一个。无论如何,当你在 Circom 中遇到 <-- 时,你应该知道,恶意提供者可以将任意值放在这里,并且证明仍然有效。只有在接下来的信号正确约束的情况下才可被使用。
如上图所示,每个输入在电路中都有约束,即便是 recipient、relayer、fee、refund 变量组——它们特别使用乘法进行了约束(第61行到第64行),以避免被 Circom 编译器排除在电路之外(其实,现在不再需要,Circom 会自动为输入信号添加约束,但在这里只需要 4 个约束,而数量微乎其微)。现在,证明是从所有输入信号 "推导" 的,任何对其中任何一个的更改都会破坏证明的有效性。
电路处理
电路中的第一个有趣之处是在 这里 使用的 CommitmentHasher()。哈希器模板在 这里:

如我们所见,它接受两个输入信号:nullifier 和 secret,并输出两个哈希值:commitment 和 nullifier。nullifierHash 输入在 这里 与输入 nullifier 哈希结果进行比较,检查其 nullifierHash === nullifierHash。这是一个重要的安全部分,可以减轻外部攻击者传入的 nullifierHash 与私有 nullifier 值不一致的问题。
我们已经检查了所有输入都有约束且每个输入都有相应约束。接下来,我们看到 nullifier 和 secret 被 Num2Bits 电路分拆为 248 位。在这里,我们检查所有输入值的位都被使用,没有遗漏。例如,如果 nullifier 的哈希仅使用 247 位(而不是 248 位),则两个不同的 nullifier 会导致电路中相同的承诺哈希,这可能导致使用其他 nullifier 重复使用证明。有时,开发者希望减少约束的数量,并通过减少某些值的位长度,以使证明(证明生成和大小)更轻量,从而引发安全问题。
下一个检查是 Pedersen 哈希,已知在 这里 描述了某些性质及具有潜在问题的同态特性。让我们检查:
- 来自上述文章的问题 "非唯一的 x 坐标" 在这里存在(结果承诺和 nullifierHash 输出仅使用坐标 "x" 在这里,但这种特定的 Pedersen 实现并不容易受到这一问题的攻击)。
- "可变长度输入" 问题的冲突,涉及不同位长度或部分 bit 长度小于曲线顺序的预像的碰撞。在这里也不适用,因为所有输入都具有固定大小的编码。
需要提到的另一点是 Pedersen 哈希的同态性,这意味着(简化后):H(M1 + M2) = H(M1) * H(M2),因此当你拥有某个秘密值 s 的 "前一个" Pedersen 哈希时,可以计算 H(s + <anything>) 作为 H(s) * H(<anything>),即使不知道 s。在我们的情况中,不能应用,因为 secret 和 nullifier 只会被用一次,但当 Pedersen 哈希被多次使用时,我们始终应该考虑这一点。
电路的另一个部分是 Merkle 证明检查。这里是代码 片段

首先 - 让我们检查一些 Merkle 树的低级细节 - 哈希算法。Tornado 的 Merkle 树实现可以在 这里 找到,它使用的是来自 circomlib 的 MiMC 哈希,下方的行 9 组件 hasher = MiMCSponge(2, 1);(2 输入,1 输出)。在内部,MiMC 可以配置为不同的轮次,较少的轮次可能使这一哈希不安全。如果我们查看 Tornado 中使用的 mimcsponge.circom 文件,同时检查 "../node_modules/circomlib/circuits/mimcsponge.circom",会发现 MiMC 在这里使用了 220 轮。这个轮数完全足够保证哈希的安全性。
然后,让我们考察一些与 Merkle 树相关的高层次问题。第一要点是使用零叶——一个简单的向量,可能容易被遗忘。ZK 项目通常使用稀疏 Merkle 树,其中大部分叶节点为零,因此构建零叶的 Merkle 证明是可行的。在这里不适用(我们无法表示 pedersen(nullifier + secret) == 0,同时又展示已知的 pedersen(nullifier))。此外,Tornado 中的 Merkle 树实现使用了非零值作为 "零" 叶节点(检查 这里)。
另一个与 Merkle 树相关的问题是 "第二预成像攻击"(在 这里 描述)。当用于哈希的叶子数据与 Merkle 树节点的大小相等时有效,并且中间节点可以用作叶子,从而正确 Merkle 证明到达相同根。要检验这一点,我们需要确保我们的叶子(nullifier + secret)的大小与 Merkle 树哈希不相等,或使用不同的哈希计算第一个叶子哈希(根据 这个)。Tornado 使用 Pedersen 进行承诺哈希,并将其与 nullifierNash 相比 在这里,因此用一个中间节点作为叶子不生效。
在 Tornado 的实现中,使用 "仅追加" 的 Merkle 树,每新增一个叶子都是从左到右的。因此,涉及叶子包含/排除的不同场景在这里不可行(例如,重复插入/删除/插入/删除的场景),但在使用更复杂逻辑时与 Merkle 树时应该记住检查它们。
检查的另一个重点是树的大小,这里是 20 层(这里),这是足够的,因为在溢出情况下,新叶将无法添加(这里 检查),且同样逻辑的新合约可以轻松部署。
输入的可伪造性、重用和零知识滥用
下一部分是分析每个输入及其伪造、重用和滥用零知识特性的可能性:
-
root
这是电路中实现的树的 Merkle 根。根据 这里 的 require(isKnownRoot(_root), "Cannot find your merkle root"); 检查,我们无法伪造这个根。重用相同根仅在使用另一个 nullifier 时才有意义,因此这里没有问题。根是公共的,因此我们在这里没有 ZK 问题。通过。
-
nullifierHash
这是 nullifier + secret 的 Pedersen 哈希。我们已经在前面的讨论中讨论了 Pedersen 哈希,并且由于 nullifierHash 和 secret nullifier 及 secret 输入是绑定在一起并被电路检查的,因此我们可以说它安全,抵抗 nullifierHash 的伪造。重播问题通过 require(!nullifierHashes[_nullifierHash],"..."); 检查在合约 这里 解决了。零知识特性在这里有点棘手,因为 Pedersen 哈希不会生成完全伪随机的值,在某些情况下可以对其原像产生一些建议,但在我们的情况下,安全生成 secret 和 nullifier 减轻了这个问题。通过。
-
recipient、relayer、fee、refund
这些值是主要通过合约使用的外部参数。我们已经检查它们包含在证明中,因此无法在使用相同证明的情况下被更换为其他值。它们的重播理应是设计的一部分,且是公共的,因此不存在零知识妥协。通过。
-
nullifier + secret
伪造这些参数允许相同的存款被重复使用两次或更多,代表对 Tornado 的主要攻击向量。这里攻击者的目标是提交从单一存款派生出的次级 nullifierHash(一个 secret 和 nullifier 的单一对)。如果合约中检查了 Pedersen 哈希,使用非 Circom 中使用的其他 Pedersen 实现,可能出现问题,即相同值在两个实现中导向不同哈希,但这里承诺哈希在电路中得到检查,使此攻击向量不适用。另一个伪造/重放攻击理应在 secret + nullifier 编码某种方式使用不同位长度的情况下发生,使情况如 (secre[t] + nullifier) == (secre + [t]nullifier),但在这里这种情况也不适用。由于使用了具有充足安全位和合适的安全椭圆曲线的 Pedersen 哈希,因此零知识滥用在这里也无法利用。通过。
-
pathElements[levels] + pathIndices[levels]
这些值是承诺包含的 Merkle 证明。前面已讨论过 Merkle 树的主题。级别的数量是电路模板参数,因此无法调整 Merkle 证明的大小和第二预成像攻击的可能性。现在,零知识特性:如果只有一个"树中的第一个"存款并且随之而来完成的提款,我们当然可以确定使用了哪个叶节点并暴露存款者。Tornado 只能在多用户的多次存款情况下工作。因此,无法为自己部署 "我的 Tornado 池",这将面临此问题。匿名性由许多独立的用户提供,而在基于 Tornado 方案开发的解决方案时,总是应考虑到此问题。这是一个很好的例子,说明底层 ZK 协议的安全性如果使用不当可能简直无效。
最终基于清单的分析
附加 "基于清单" 的检查对任何审计至关重要,特别是在 ZK 应用和智能合约审计中。它 "打磨" 先前的结果,再次覆盖所有潜在危险的模式,检查是否有任何重要的内容被遗漏。每个审计公司都应该有这样的检查清单。我们不打算公开我们的清单,但我们会展示一些主题以示范这个过程可以如何进行。让我们开始。
ZK 证明重用与其他参数
已在上文中对所有参数进行了检查,大部分通过 nullifierHash 缓解。这部分也可以通过在见证中连续更改值并检查证明的有效性来自动检查。
不包含在证明中的参数,导致证明重用
在电路部分进行了检查,所有参数均已约束。
发送者通过出示证明被披露
设计上盖章,如果进行了足够独立的存款,一切都很好。
SNARK 友好哈希的非伪随机特性(Pedersen, MiMC)
此处未使用伪随机特性的已用哈希,不适用。
Pedersen 同态特性、位长度、其他特定问题
如上所述,已检查。
MiMC,轮次,足够的安全性
(参见) 如上所述讨论。
椭圆曲线、"无穷处" 和 (0,0) 点的问题
在这里不适用。
Merkle 树、零叶,第二预成像,多重包含/排除问题
如上讨论,已检查。
字段算术、溢出
在这里不适用。
Groth16 问题,例如证明的可变性
(参见),由于 nullifierHash,在这里不可用。
Fiat-Shamir 启发式问题
(参见) 这部分与底层证明系统相关。需要在 unSHARED 推荐的振奋 Circom 中分析 Tintoin 现金电路,且该部分也应该进行证明系统的实现。正常全面审计应在此进行,不仅适用于我们文章的情况。
可信设置过程
如果使用了带有可信设置的证明系统,这是审计的重要部分。审计员还应检查此设置过程(对此过程已有许多文章)。
…
清单中有许多主题,我们不会呈现所有主题,但你绝对应该有自己的清单,保持其更新,因为 ZK 中出现的新安全问题频繁,你不能错过它们。
结论
分析 ZK 项目是一个复杂的过程,许多安全主题不仅与项目自身的逻辑相关,还需要理解底层证明系统的内部机制:曲线、哈希、Fiat-Shamir 启发式、底层数学的具体特性。此外,分析过程中可能会出现许多性能问题,审计员的工作是指出这些问题,因为在 ZK 中,许多决策是基于证明/验证过程的优化,这些决策可能导致安全缺陷。
此外,这一领域正在迅速发展,新的证明系统每几个月就会面世,有时分析结果会比整个分析准备得更快失效——这也是受到了经常缺乏合格官方 ZK 审计报告的原因之一。团队很简单地切换到新算法,改变证明系统,重新考虑其内部逻辑。因此,若想在这一市场中保持竞争力,你应该跟上这一领域的众多话题,这使得该领域为任何希望在现代计算科学和安全前沿工作的高技能专家提供极具吸引力的机会。祝好运!
- MixBytes 是谁?
MixBytes 是一支由区块链审计专家和安全研究员组成的团队,专注于为 EVM 兼容和基于 Substrate 的项目提供全面的智能合约审计和技术顾问服务。关注我们在 X 上,以便及时获取最新行业趋势和洞察。
- 原文链接: mixbytes.io/blog/audit-z...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
