Eclipse:为什么性能如此重要
- Eclipse Labs
- 发布于 2025-03-21 08:48
- 阅读 2285
Eclipse:为什么性能如此重要
在 Eclipse,我们致力于构建性能最高、成本最低的基于 SVM 的链。这与我们 GigaCompute 的概念一致——这是我们计划在 Eclipse 上提供的大幅增加的计算能力的术语。
这是关于性能的一系列博文中的第一篇。在接下来的部分和未来的博文中,我们将探讨 SVM 技术的所有方面。我们主要集中于介绍 GigaCompute——这是我们在 路线图 中首次提出的一个概念——并解释我们如何利用它构建 GSVM(GigaCompute SVM),这是我们的更快、更高效的 Solana 客户端,专门为 L2 环境设计。
平台级的性能提升创造了一个强大的创新和采用循环。开发者能够构建更复杂和计算密集的应用,这在之前是不可行的,而用户则享受到更好的体验、更快的响应时间和更低的交易费用。
例如,对于链上 AI 代理和复杂计算任务的日益增长的需求,对区块链计算能力的要求急剧增加,推动了链上处理能力的边界。能够在线上进行其计算(例如无信任模型的训练或再训练)的 AI 代理,加上交易在线上所带来的自主性,形成了一种有效的组合。你之所以看不到区块链执行服务器端游戏逻辑或大量存储玩家数据的原因之一是,即使是低 gas 的链,这也太昂贵,或者延迟太高。
这些新兴用例和增强的能力自然吸引了更广泛的用户群体进入生态系统,进而为开发者提供了更强的激励,促使他们继续创新和扩展区块链技术的技术边界,这代表了我们在 Eclipse 确定的最重要的机遇之一。
对我们来说,这一良性循环最终体现在 GSVM 的开发上,这是一个更复杂、适应性强、普遍可接入的区块链基础设施,专门设计用于支持和促成日益复杂和计算密集的用例。
首个 Memecoin 事件
美国第 47 任总统的就职标志着 Solana 区块链生态系统的几项前所未有的发展。特朗普利用其广泛的社交媒体存在和对数字参与的理解,做出了铸造自己 meme 代币的显著决定。该加密货币是专门在 Solana 区块链平台上创建的,利用复杂的 Meteora DLMM (动态流动性市场制造者)协议进行首次分发和交易机制。
如图 1 所示,该代币的推出引发了一系列显著的市场波动,表现出极端的波动性。多个因素导致了价格的异常飙升,随后出现了戏剧性和急剧的下降——该代币的价值经历了惊人的过山车蜕变,从几乎达到 80 美元暴跌至大约 32 美元,仅仅几分钟的时间。围绕这一事件的交易狂潮使 Moonshot,即主要促成 TRUMP 代币购买的平台,达到了前所未有的受欢迎程度。
该平台经历了大量新用户的涌入,有 400,000 人为了参与这一交易现象而专门加入。如此强烈的兴趣使 Moonshot 达到一个了不起的里程碑,暂时成为苹果 App Store 上下载量最高的金融应用。
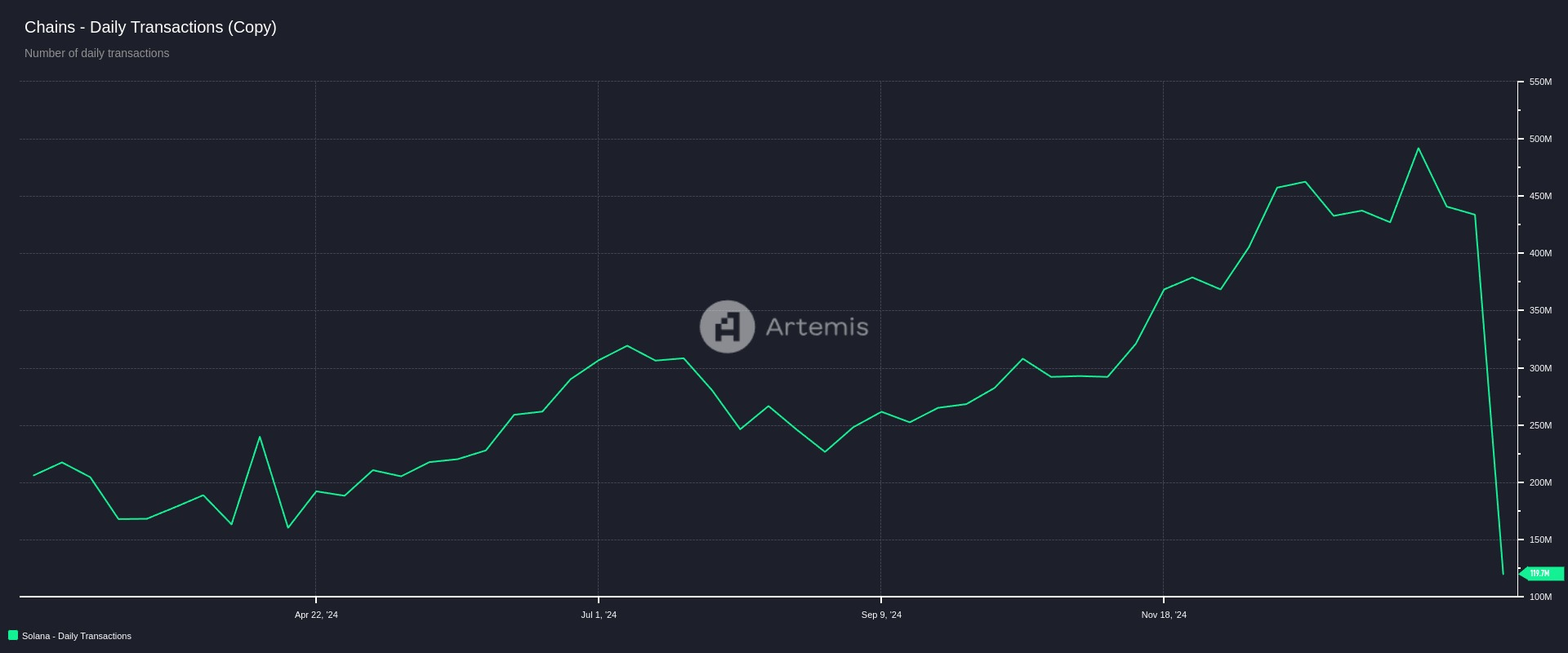
图 1:自 2024 年 4 月以来 7 天内汇总的每日交易。峰值对应于 1 月 23 日。来源:Artemis terminal
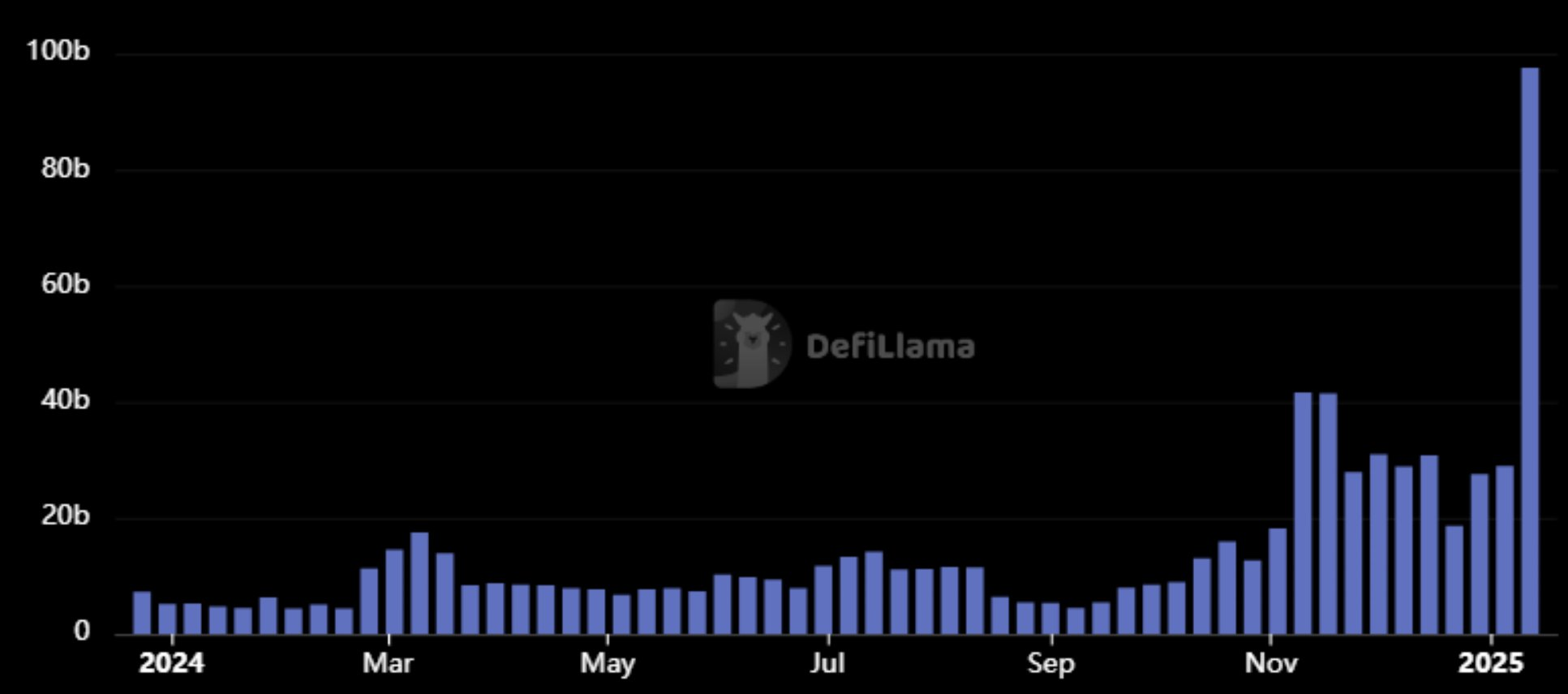
图 2:每日 DEX 交易量。峰值日的 Solana 交易量超过了此前所有链的每日最高交易量总和。来源:DefiLlama
这一 memecoin 的推出及其后续交易活动创造了一系列记录:
- Solana 的真实经济价值(REV)达到了迄今为止的最高值。
- Solana 上活跃和回归用户的数量显著增长(图 2)。
- 稳定币流动性,即与稳定币相关联的真实货币量以迄今为止的最高速度增长(图 3)。
然而,这一事件却带来了严重的缺陷。随着 TRUMP 和 MELANIA 代币在 Solana 上的知名度上升,SOL 价格下跌,触发了套利机器人淹没主网络的交易,导致了有效的级联故障。
由此产生的网络拥堵产生了严重的后果。中位优先费用飙升 5000 倍,非投票交易计数下降 66%,每个区块的计算单位减少 50%。矛盾的是,网络没有随需求规模扩大,反而以正常生产力的一半运作。
这当然给大约五十万新 Solana 用户留下了差劲的第一印象。然而,类似事件 在 Solana 和其他链上与铭文相关的激增期间也发生过。
所有并行处理去哪里了?
这一切的发生有一个看似简单的解释。Anza,这一 Solana 基金会的精神继承者,已经发现令人尴尬的并行 agave 验证者实际上并不够并行。正如下图所示,非投票交易处理线程,即实际执行交易的线程,几乎处于闲置状态,这显然不是我们希望发生的情况。
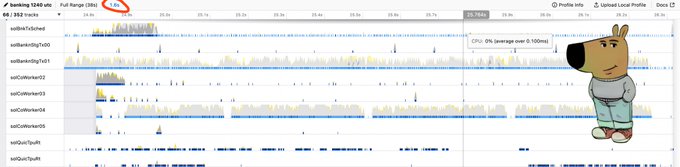
图 3:对 agave 运行 perf 的结果。来源:Alessandro Decina
我们自己小规模的内部关于并行性的调查证实了这些发现,并揭示了新的 DAG 调度程序在充分利用工作线程方面存在困难。尽管 Solana 仍然是一个令人印象深刻的工程,但在并行性方面,它的潜力仍未被充分利用。
我们正在继续进行这一分析:我们已经确定了 Solana 上最具争议的程序,并在很大程度上分析了它们的并发逻辑。我们的初步结果(我们打算进行精炼和公布)表明,问题在于潜在争议状态和实际上不能从不同线程写入的状态之间的差距。解决这个问题并不简单,实际上我们不确定它是否能在足够通用的情况下解决,同时保持与主流 Solana 的向后兼容性。
一种可能性是修复应用本身; 例如,可以将 DLMM 程序重写为多线程,采用细粒度的状态锁定。虽然风险很大,但如果做对了,这将消除争用。
为什么选择 GigaCompute?
标准指标——TPS、延迟和 gas——仍然至关重要,但它们只讲述了部分故事。对用户而言,一致且可预测的延迟往往比原始吞吐量更重要——这是将预确认作为许多 Rollup 设计的一部分的原因之一。传统指标的不足之处在于:gas 成本并未反映交易池中的等待时间,而 TPS 数据在忽视交易复杂性或现实网络条件时可能会产生误导。性能指标必须更直接地反映用户体验。
TPS?
仅讨论 TPS 可能会产生误导。因此,一定应该讨论稳定状态 TPS 和负载下的百分位数。我们并没有做到。我们还忽略了在这样的背景下的延迟。现实是,在 TRUMP memecoin 事件期间,平均 和 第 99 百分位 的延迟讲述了两个非常不同的故事。更重要的是,虽然交易的延迟表明平均情况下处理所需的时间更长,但并未反映出被包含所需支付的代价的巨大规模。一个好的指标应该反映这一事实。
这暗示了另一个问题。TRUMP 事件的问题并不完全与软件性能有关。如果 SOL 没有下跌,套利机器人就不会发起交易,而交易量将减少 50,000-100,000 笔每秒。最终,用户所看到的只是一个正常运行的系统,不管其稳定性是聪明代码还是巧妙设计的结果。
我们并不孤单于此思考。Optimism 和 Monad,都认为 TPS 不是度量验证者性能的最佳指标。我们倡导一种整体方法,即将压力下的性能与稳定状态吞吐量分开衡量。每个阶段都有最优指标。
链上计算
让我们考虑一下实际上在链上执行的计算量。目前,它实际上是惊人地少。在链上运行游戏逻辑相对不常见;大多数 Web 3 游戏使用区块链记录玩家信息:他们拥有什么类型的 NFT,他们取得了什么进展以及他们取得了什么成就。但据我们所知,尚无项目,甚至 Multisynq,使用 Solana 进行更雄心勃勃的事情。
一个关键原因是大多数区块链每个区块提供的有用计算量微乎其微。
确实,目前每个 Solana 区块限制为 4800 万 CU。待定 SIMD 0207,可能会有一些提升,但即使这样,考虑到这一数字的规模。Solana 在那么短的时间内可以处理多达 100,000 笔交易,并会产生五个区块,因此每笔交易的整体预算为每笔交易 2400 CU。这不足以将你的账户地址转换为人类可读的形式,即 base58。如果你保留中间计算,大约需要五秒钟才能完成一次。在此背景下,当你在 iPhone 上打开 SolScan 时,该操作在不到 16 毫秒内完成,因此区块链的速度大约是你的 iPhone 的 32,000 倍慢。
// 11962 CU !!
compute_fn! { "Log a pubkey to account info" =>
msg!("A string {0}", ctx.accounts.counter.to_account_info().key());
}提高 CU 限制、扩大区块规模或缩短区块时间等提议在 Solana 和其他地方都有提出。然而,尽管这些措施可能在一定程度上改善用户体验,但从根本上说,我们在 Eclipse 的目标是提供更多的计算能力。
为性能设计 Eclipse
以下是我们将在 GSVM(Eclipse 的 SVM 区块链客户端)中使用的三条原则,以实现最佳性能。
1. Profile-Guided 的优化
Profile-Guided 的优化是指在编译器设计和性能调优中使用的一组技术,其中优化过程由从分析应用程序运行时行为中收集的数据指导。分析涉及收集有关程序执行的详细信息,例如哪些函数被调用得最频繁、采取哪些分支以及大部分执行时间花费在哪里。
GSVM 的一个特定原则是专门针对频繁出现的模式进行执行,优化热路径。比如,它可用于决定哪些函数 JIT,哪些函数解析。
我们发现新 DAG 中的批处理模式与 Faleiro et al [1] 描述的模式相似。具体而言,我们发现因为应用批次的效果只能在稍后的批次中可见,所以我们可以利用更细粒度锁定的创新,以便实现更早的可见性,从而在每个批次中执行更多操作。
这也意味着我们可以更早地应用简单交易。大约 25% 的交易不需要超过常规的 SPL 代币和少数系统程序。实际上,它们可以在到达操作系统之前就预先应用,利用专门的硬件 [9]。
2. 自我改进的运行时
区块链运行时的一个关键优势是它们的工作负载是容易观察的。这使得构建预测模型以应对即将到来的交易模式并相应调整运行时变得简单。这与强化学习的理念非常契合。我们可以对数月的数据进行预测训练,并随着工作负载的变化对其进行更新。
GSVM 旨在通过分析交易模式并实时调整执行参数,持续适应变化的工作负载。随着系统处理更多工作负载,其记录运行时性能。每次执行后,机器学习模型都会更新,从而创建一个自我改善的运行时系统。这是一种在运行时和虚拟机中被称为反馈驱动优化的具体情况。
这些持续改进的原则适用于缓存、预执行、争用解决和交易重新排序,列举几个优化领域 [2, 3, 8]。
3. 硬件-软件协同设计
在需要去中心化以确保安全和抗审查的 L1 中,通常只规定基础硬件的容量需求,例如 RAM 和磁盘存储的量。对于像 Eclipse 这样的 rollup,情况截然不同——只要我们的“安全措施”,如链衍生和欺诈证明有效,我们就可以构建一个非常专门化的 GSVM 客户端。
以下是软件与硬件协同设计的一些示例,以及它能带来的改进。
- 我们可以使用 GPU 加速 Solana 中的数据库操作 [7],作为 L2,我们可以利用更大的计算能力。
- 现代 FPGA(现场可编程门阵列)可以减少特定计算的延迟,例如签名验证操作 [5, 6]。有关数据包捕获的前景工作也很有希望 [4]。
- 具有硬件支持的专用键值存储,包括定制的内存层次结构和专用近数据处理单元 [9, 10],可以通过最小化数据访问时间和优化存储模式,显著减少账户数据库操作的延迟。
我们的目标是实现软件和硬件能力之间的最佳平衡。然而,在构建 GSVM 时,相较于其他区块链项目,我们对专用硬件采取了更大胆的 approach。
结论
性能改进的作用不仅限于防止诸如最近的 TRUMP 事件等技术问题。虽然防止此类问题是重要的,但真正的长期价值在于扩展链上可能实现的内容。通过实现更快的处理速度和降低使用费用,Eclipse 将为区块链应用解锁全新可能性路径。
这些改进创造了一个良性循环——开发者获得了构建更复杂和资源密集型应用的能力,而用户则获得更流畅的体验和更低的费用。这种增强的能力吸引更多用户进入生态系统,反过来又激励更多开发者进行创新,推进区块链技术能够实现的边界——这是我们在 Eclipse 所拥有的最大解锁之一。最终的结果是一个更强大、灵活且易于接入的区块链基础设施,能够支持日益复杂和要求严格的用例。
我们采取了一种直接的方法:将高效的软件与 L1 无法使用的强大硬件结合起来。虽然 Solana 为我们提供了一个强有力的起点,但成为 L2 使我们能够做更多——通过轮廓驱动优化、自我改进的运行时和硬件-软件协同设计的结合。我们可以利用专用设备并做出 L1 无法做出的设计选择,因为要求专用硬件会显著限制参与。这帮助我们更好地服务于高性能的应用。
参考文献
https://kelvinfichter.com/pages/thoughts/tps-is-dumb/
https://www.monad.xyz/wtf-is-tps
[1] J. M. Faleiro, D. J. Abadi, 和 J. M. Hellerstein, ‘高性能交易通过提前写入可见性’, Proc. VLDB Endow. , vol. 10, no. 5, pp. 613–624, 2017 年 1 月, doi: 10.14778/3055540.3055553。
[2] C. Yan 和 A. Cheung, ‘利用锁争用提高 OLTP 应用性能’, Proc. VLDB Endow. , vol. 9, no. 5, pp. 444–455, 2016 年 1 月, doi: 10.14778/2876473.2876479。
[3] N. Zhou, X. Zhou, X. Zhang, X. Du, 和 S. Wang, ‘重新排序交易执行以促进高频交易应用’, Data Sci. Eng. , vol. 2, no. 4, pp. 301–315, 2017 年 12 月,doi: 10.1007/s41019-017-0054-0。
[4] J. Duchniewicz, ‘FPGA 加速的 eBPF 数据包捕获:使用 SoC FPGA 加速数据包捕获的性能考虑。’ 2022 年。
[5] A. Boutros, E. Nurvitadhi, 和 V. Betz, ‘超越 FPGA 重配置加速设备的架构与应用协同设计’, IEEE Access, vol. 10, pp. 95067–95082, 2022 年,doi: 10.1109/ACCESS.2022.3204664。
[6] H. Yang, Z. Li, J. Wang, S. Yin, S. Wei, 和 L. Liu, ‘HeteroKV:基于异构 CPU-FPGA 平台的可扩展实时关键值存储’, 在 2021 年设计、自动化与欧洲会议和展览 (DATE),法国格勒诺布尔:IEEE,2021 年 2 月,pp. 834–837,doi: 10.23919/DATE51398.2021.9474088。
[7] H. Sharma 和 A. Sharma, ‘GPU 加速数据库的全面概述’, 2024 年 6 月 19 日,arXiv:arXiv:2406.13831,doi: 10.48550/arXiv.2406.13831。
[8] J. He, Y. Liu, J. Chen, S. Peng, Y. Wang, 和 M. Zhang, ‘MoryFabric: 通过实际有效性验证和重新排序降低交易中止’, 在 2023 年 IEEE 第 29 届国际并行与分布式系统会议 (ICPADS),中国海洋花岛:IEEE,2023 年 12 月,pp. 691–698,doi: 10.1109/ICPADS60453.2023.00106。
[9] H. Yang, Z. Li, J. Wang, S. Yin, S. Wei, 和 L. Liu, ‘HeteroKV:基于异构 CPU-FPGA 平台的可扩展实时关键值存储’, 在 2021 年设计、自动化与欧洲会议和展览 (DATE),法国格勒诺布尔:IEEE,2021 年 2 月,pp. 834–837,doi: 10.23919/DATE51398.2021.9474088。
[10] S. Xi et al., ‘Cora:用 SmartNICs 加速有状态网络应用’, 2024 年 10 月 29 日,arXiv:arXiv:2410.22229,doi: 10.48550/arXiv.2410.22229。
- 原文链接:www.eclipselabs.io/blogs...
- 本文链接:learnblockchain.cn/article… 我是 AI 翻译助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





