设计高性能 zkVM
本文深入探讨了 RISC Zero 的 zkVM 证明系统设计,重点介绍了 RISC-V zkVM 的架构及其优化策略。

本文深入探讨了 zkVM 的证明系统设计,分为两部分。
在第一部分中,我们将对 RISC Zero 的 zkVM 背后的证明系统进行高层次的概述,以及我们为提高 zkVM 性能所做的展望。
在第二部分中,我们将更仔细地研究证明系统的每一层,涉及在折叠方案、JOLT、Binius 和 Circle STARK 等创新方面的设计考虑。
第一部分:zkVM 设计的鸟瞰
一年前,业界对 RISC-V zkVM 的实用性仍不确定。RISC Zero 的 zkVM 是唯一能让你证明像 Rust 这样的高级语言的选项,构建者们对放弃使用像 Circom 和 Noir 这样的电路语言持怀疑态度。当时,大多数 ZK 行业都专注于为构建 zkEVM 而手工编写自定义电路的问题。
.png?table=block&id=5aeb1325-0fa7-4865-930a-9a2592330e41&cache=v2)
RISC Zero 的 早期假设 是,让构建者可以使用像 Rust 这样成熟的语言,而不是手工编写电路,将促进可验证软件应用程序上市的可行性方面的从零到一的差异。我们发布的 Zeth 是我们对这一价值主张的首次重大展示。Zeth 是第一个完全兼容以太坊的 zkEVM,它的简洁性使得 zkVM 的价值主张变得清晰。当其他团队为 zkEVM 的开发筹集数亿美元时,RISC Zero 随意发布了第一个完全兼容以太坊的 zkEVM,它由 3 名工程师在大约 2 周内构建完成。从那时起,我们已经看到像 Taiko 这样的团队通过放弃他们的 zkEVM 电路开发项目而转用 Zeth,从而大大加快了他们的上市时间。
最终,快速开发 zkEVM 的关键是在 zkVM 内部运行现有的 EVM 实现。简而言之,Zeth 是通过在 zkVM 内部运行 reth 实现的。类似地,我们通过在 zkVM 中使用 OIDC crate 来解锁 Bonsai Pay,并通过在 guest 中运行 Doom crate 来解锁 zkDoom。构建者无需每个项目都从头开始构建原语,只需导入相关的 Rust crate 即可继续。这使得构建者能够快速构建他们的项目,并将维护负担降低到接近于零。为了使 Zeth 与以太坊的最新更新保持一致,我们只需更新到最新版本的 reth。作为对 Zeth 中使用的方法的稳健性的进一步证明,以太坊基金会最近宣布了一项通过这种 EVM-inside-zkVM 设计来正式 验证 zkEVM 的重大举措。
如今,关于 zkVM 是构建和部署可验证软件应用程序的正确方式的观点,以及关于 RISC-V 是构建 zkVM 的正确基础的观点,正趋于一致。我们很高兴看到我们关于 RISC-V zkVM 的假设已被整个行业验证,并且我们很高兴看到在过去的几个月中出现了一些有趣的新项目。
我们经常被问及我们对这些较新的 zkVM 和较新的证明系统的看法,以及我们是否计划采用这些技术。当涉及到证明系统和相关技术时,答案通常是一样的——我们一直在关注生态系统中的所有主要项目和研究,以便为我们的设计和优先事项提供信息。我们通常认为在工程层面比在证明系统设计层面更容易获得和更有影响力的性能改进,并且我们正在相应地确定优先事项。
用于改进证明系统的唾手可得的果实
既然我们已经通过发布 zkVM 1.0 在我们的 API 设计中达到了成熟,并且在 许多链 上部署了验证器,并构建了一个高效的 证明服务,那么我们改进 zkVM 的主要目标是最大限度地降低证明生成的成本,特别是对于我们看到最需要的用例——包括为 EVM rollup、OP rollup、Eigenlayer 部分提款和来自各种证明系统的证明的聚合。使用老式的阿姆达尔定律,我们已经在今年上半年看到了 10 倍的成本改进 ——即,识别瓶颈并加以解决。我们很自豪能够提供 市场上最便宜的 zkVM,并且我们期待在未来几个月内实现进一步的成本降低。
展望未来,我们正在针对的下一个主要成本改进来自特定于应用程序的加速器电路(又名预编译/gadget/芯片)的集成。通过将 RISC-V zkVM 与对集成特定于应用程序的加速器电路的支持相结合,我们可以在不牺牲证明器效率的情况下实现最快的开发时间。应用程序开发人员推荐的开发过程与标准软件开发实践中的过程相似:构建原型,然后测量性能。观察瓶颈,设计解决这些瓶颈的方案,然后重复。为了使这个过程更容易,我们为构建者编写了一份 优化指南。
一旦我们确定了一个重要的瓶颈,我们就可以将一个特定于应用程序的加速器电路集成到 zkVM 中,以便解决该瓶颈。我们正在发布一个 RSA 加速器,随后将推出用于 Keccak、ECDSA、配对和 BLS12-381 的附加电路。这些操作构成了我们今天看到的大多数证明需求的瓶颈。我们将继续识别和解决瓶颈,并且我们很快将发布一些令人兴奋的公告,关于允许用户构建他们自己的加速器电路。
.png?table=block&id=8104becb-52bd-49d4-91bc-3274a13cac52&cache=v2)
在推送这些加速器电路之后,我们很高兴发布 V2 版本的 RISC-V 电路。与 V1 相比,由于更有效的内存参数、更好的编译器技术和各种次要的设计改进,我们预计电路的大小将减少 2 倍。
zkVM 的证明系统架构
技术进步的速度随着空间中参与者的数量而增长,并且很高兴看到在 zkVM 设计和证明系统设计方面有如此多的创新。在这个阶段,RISC Zero、Succinct 和 a16z 各自都有自己的基于 RISC-V 的 zkVM 实现。与此同时,许多其他项目都以其他高级 ISA(如 WASM 和 MIPS)为目标,还有一些项目(STARKware、Valida)以自定义指令集为目标。在 zkVM 设计的下一层,我们在过去 12 个月中看到了许多同样令人兴奋的证明系统设计创新。
让我们概述一下 RISC Zero 的证明系统设计,我在 zkSummit 10 和我们的 开发文档 中对其进行了描述。这种设计不仅是 RISC Zero zkVM 的基础,也是 Polygon 和 zkSync 以及 SP1 构建的 zkEVM 的基础。下图显示了“基本”思想,它可以分为四个部分:执行、RISC-V 证明、聚合证明 和 STARK-to-SNARK 证明。
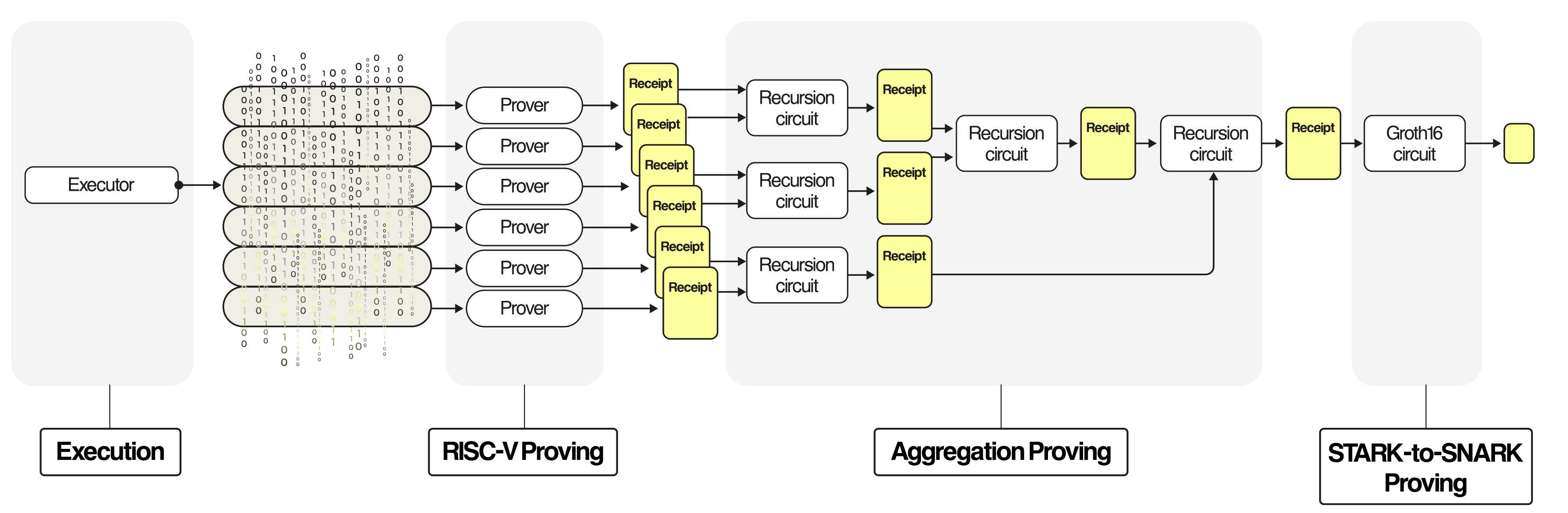
-
执行。程序被执行,生成许多“段”。
-
RISC-V 证明。每个段都使用基于 FRI 的证明器进行证明。
-
聚合证明。所有段证明都使用基于 FRI 的证明器聚合为单个证明。
-
STARK-to-SNARK 证明。为了输出一个足够小的可以在链上验证的证明,证明系统中的最后一步依赖于基于椭圆曲线的证明器。
今天,我们使用 FRI,因为它对于横向可扩展的递归证明非常有效,并且我们使用 Groth16,因为它在链上验证非常便宜。我们一直在寻找对这种高层次设计及其实现的改进,无论是通过小的调整还是重大的改变。在考虑替代方案时,需要考虑系统的许多方面,包括:
-
证明大小
-
证明成本/时间
-
证明者的硬件要求
-
验证者的成本/时间
-
递归证明成本/时间(即,在证明者内部运行验证算法)
-
可并行性
-
可去中心化性
-
安全
-
可审计性
-
隐私
提名:0STARK 协议
为了更容易地讨论我们的证明系统,我们引入了名称 0STARK 来指代我们的 密码学文档 中描述并在我们的 risc0-zkp crate 中实现的 IOP 协议。0STARK 协议在结构上与 plonky2 和 eSTARK 论文中描述的证明系统非常相似——算术化方案是基于 AIR 的,并且承诺方案是基于 FRI 的。0STARK 专为 GPU 上的高效递归而设计,并且据我们所知,它是 GPU 集群上大规模可扩展证明生成的最有效选择。
现在我们已经在我们的语汇中使用了 0STARK 这个名称,我们可以简洁地描述一下我们 zkVM 的基础证明系统:
-
我们使用 延续 将大型计算拆分为 段。
-
我们使用 0STARK 来证明这些段,每个段生成 1 个 STARK。
-
我们使用 0STARK 来聚合这些 STARK。
最后,我们使用 Groth16 来输出一个可以发布并在链上验证的证明。
.png?table=block&id=161612b3-a9e0-4f99-8c14-ae9e54c63382&cache=v2)
第一部分到此结束。在下一部分中,我们将更深入地研究 RISC Zero 的证明架构,并分享我们如何看待各种新技术,包括折叠方案、JOLT、Binius 和 Circle STARK。
第二部分:平衡 zkVM 设计中的权衡
到目前为止,我们已经概述了 RISC Zero zkVM 基础的证明系统设计的高层次设计。简而言之,该系统由 4 层组成:
-
执行
-
RISC-V 证明
-
聚合证明
-
STARK-to-SNARK 证明
.png?table=block&id=be83012c-09d0-4f24-be2d-252502f4707c&cache=v2)
在迭代 zkVM 方面,我们的重点是最大限度地提高效率。现在让我们深入讨论一下我们如何看待摆在桌面上的各种选项。剧透:正如我上面提到的,通过更多地关注工程层面的问题而不是证明系统设计,我们可以以更少的努力获得更大的性能提升。
折叠方案怎么样?
在我于 zkSummit 发表讲话时,我们设计的主要替代方案是基于折叠方案的。Lurk zkVM 正在获得关注,而 Nexus zkVM 正在启动——这两个 zkVM 都以基于折叠方案的 zkVM 设计为目标。当我们评估基于折叠的 zkVM 的选项时,我们的结论是,基于折叠的 zkVM 设计不利于高效的并行化或去中心化。
为了使折叠更具并行性,已经进行了一些令人鼓舞的工作,包括 Paranova 和 Cyclefold,但我们的结论仍然是,基于 FRI 的系统为构建我们正在构建的大规模分布式证明架构提供了更有效的机制。我在 zkSummit 演讲的最后几分钟 中简要地讨论了这一点,并在 Napkin Math Analysis 中进一步阐述了细节。因此,我们不太可能在短期内转向基于折叠的 zkVM。另一方面,最近的一些其他工作对于我们的目的来说看起来更有希望。
当我们展望 zkVM 证明的未来时,执行、段证明、聚合证明、STARK-to-SNARK 证明 的整体结构似乎相当稳定。主要问题是如何最好地处理证明堆栈的每一层。
在我们深入研究每一层之前,让我们对每一层的效率给出一些高层次的视角。正如你在下表中看到的,要清楚地回答 “什么是瓶颈?” 这个问题并不容易。答案取决于你是否专注于最大限度地缩短时间或最大限度地降低成本,以及你是否对证明小计算或证明大计算感兴趣。
.png?table=block&id=416d0fa0-e4a7-42af-a16c-0f7adb9a6aae&cache=v2)
这里一个令人惊讶的观察结果是,用户最大的痛点是流程的最后一步——STARK-to-SNARK 证明。对于像签名验证这样的小型证明,STARK-to-SNARK 证明花费的时间竟然比证明系统的其余部分加起来还要长 5 倍。在当今的 CUDA 上,我们看到 STARK-to-SNARK 的时间约为 15 秒,而输出 STARK 证明的时间约为 2.5 秒。
鉴于 STARK-to-SNARK 层面临的这些挑战,让我们更详细地讨论这个主题,然后我们将把注意力转向执行、RISC-V 证明和聚合证明。
STARK-to-SNARK 证明
虽然证明系统的早期部分针对高效的证明生成进行了优化,但最后阶段针对可以高效地在链上验证的小型证明进行了优化。
当涉及到最大限度地减小证明的大小时,基于椭圆曲线的 SNARK(Groth16、PLONK、FFLONK 等)是明显的赢家。椭圆曲线 SNARK 的证明大小约为 数百字节,而基于哈希的 SNARK(例如,基于 FRI 的系统)的证明大小约为 数百 KB。
正如我们上面提到的,最后一层最终成为我们的 zkVM 和其他 zkVM 的主要瓶颈。我们已经设法将我们的 Groth16 证明时间缩短到 Bonsai 上的约 15 秒,但即使有了这些改进,这仍然是许多应用程序中的时间瓶颈。
我们想要的是一个功能强大、可靠的实现,它:
-
不需要特定于电路的可信设置
-
在链上验证的成本很低
-
实际有效
-
不会花费太长时间
当涉及到证明器效率时,Groth16 是明显的领导者,但它需要一个我们更愿意避免的特定于电路的可信设置。从理论上讲,这里有很多不错的选择,包括 PLONK、FFLONK 和 Pianist。在实践中,这是另一个证明工程比理论更难的例子。我们选择 Groth16 主要是因为当我们准备投入生产时,可用的工具更实用。
在使用了当今可用的各种选项之后,我们仍然没有找到一种完全令人满意的方案:我们目前的分析表明,我们可以使用需要特定于电路的可信设置的系统,或者使用需要几分钟才能生成证明的系统。目前,我们选择具有最成熟工具的快速选项(Groth16)。我们希望通过从 rapidsnark 迁移到 gnark,并通过调整证明系统参数以缩小聚合证明最后阶段的证明大小,能够将我们的 Groth16 证明时间缩短到仅几秒钟。
执行
2023 年 5 月,我们推出了一项名为 延续 的新功能,使 RISC Zero 成为第一个能够为任意复杂计算生成证明的 zkVM。其基本思想是将大型计算分解为许多较小的 段,并分别证明每个段。
为了展示延续的力量,我们发布了 Zeth——第一个 1 型 zkEVM。在延续之前,我们甚至无法证明单个以太坊交易。有了延续,我们突然能够证明 整个以太坊区块。
如今,延续已成为 zkVM 的标准设计模式,但每个项目在处理跨多个段的内存一致性检查方面存在一些差异。例如,假设你在第一个段中将值 `5` 写入某个内存位置,然后在第二个段中从该位置读取。
zkVM 通常使用 排列参数 来强制执行内存读/写操作。证明者提交到“主跟踪”,然后生成 Fiat-Shamir 随机性,然后提交到“辅助跟踪”。为了使用延续来实现 zkVM,我们需要在 每个段运行一个排列参数 或 运行一个跨越多个段的单个排列参数 之间进行选择。换句话说,我们是按段生成 Fiat-Shamir 随机性,还是生成所有段 然后 计算 Fiat-Shamir 随机性?
.png?table=block&id=c7a17f92-ceb8-4ec3-bd20-40a90f0df86d&cache=v2)
我们选择按段运行一个排列参数。这种方法由于 分页成本 而带来了一些开销,但在横向扩展我们的证明基础设施的背景下,它使我们免于许多麻烦。值得注意的是,这种方法允许我们在每个段构建完成后立即开始证明。在 Bonsai 上,我们在 完成运行执行器之前开始证明段,这减少了证明时间并提高了系统利用率。使用跨越多个段的排列参数意味着你必须在构建最后一个段之后才能开始证明。
RISC-V 证明 & 聚合证明
对于 RISC-V 证明和聚合证明,我们的 zkVM 使用在 Baby Bear 字段 上定义的 多项式约束,并结合 基于 FRI 的承诺方案。查看证明系统的这部分,有很多新的选择,包括 JOLT、Circle STARK、Binius 和 STIR。
我们已经研究了所有这些选项,但在平衡我们的工程优先事项方面,除非我们看到巨大的好处,否则我们没有理由采用新的证明系统。在这个阶段,我们认为通过集成特定于应用程序的加速器电路、继续优化我们的 GPU 内核以及发布 V2 版本的 RISC-V 电路比通过重新设计证明系统获得更大的好处。
为了提供更多关于设计空间的背景信息,让我们仔细看看一些可用的较新技术。
JOLT
JOLT 使用 查找表 来最大限度地减少手写 多项式约束 的数量。
这在降低代码复杂性和提高可审计性方面提供了巨大的好处,并且使用 Sumcheck/GKR 在证明器效率方面始终是一个有吸引力的选择。不幸的是,底层证明系统——LASSO——导致比 FRI 更高的验证器复杂性(和更糟糕的递归)。
JOLT 正在 从 LASSO 迁移到 Binius,这使得这种以查找为中心的设计更具吸引力。我们肯定会密切关注这里的进展!
要了解更多关于 JOLT 的信息,请查看 我的笔记 或 原始发布公告。
Circle STARK
虽然我们的 zkVM 是使用一个名为 Baby Bear 的 31 位字段构建的,但 STARKware 和 Plonky3 正在努力过渡到使用一个名为 Mersenne 31 的不同 31 位字段,使用一种名为 Circle STARK 的技术。根据作者的说法,在 CPU 证明的背景下,这种方法比 Baby Bear 提高了 30%。
但我们的系统是为 GPU 证明而设计和优化的,我们不希望这种 30% 的改进转化为我们正在优化的 GPU 环境——更不用说我们可能需要构建一套全新的 GPU 内核才能找到答案。
让我们退后一步,更广泛地了解 Baby Bear 和 Mersenne31 背后的背景。过去几年中,zkVM 设计中的主要主题之一是从大字段迁移到小字段。STARKware 的 Stone 证明器是在一个 251 位字段上构建的。使用如此大的字段会驱动 Binius 作者所说的 嵌入开销。尽管在 zkVM 中使用的大多数值都是位或字节,但用户被迫为整个字段元素的成本付费。
当 Mir Protocol(最终成为 plonky2)引入小字段 STARK 技术(在称为“Goldilocks”或“Oxfoi”的 64 位字段上运行)时,它降低了嵌入开销的重要性。RISC Zero 更进一步,在 31 位字段(称为“Baby Bear”)上构建了我们的 zkVM。Circle STARK 也遵循使用 31 位字段的选择,但目标是选择与我们不同的 31 位素数。
M31 由特别优雅的素数 `2^31 - 1` 定义。据我所知,当 Daniel Lubarov 在 2023 年 ETH Denver 推出 Plonky3 时,首先暗示了 M31 的使用。就高效乘法而言,这是一个特别好的字段,但在 NTT 方面却不太好。
2023 年晚些时候,Polygon 研究人员通过他们在 圆群上的 Reed-Solomon 码 中的工作解决了 M31 上的 NTT 的挑战,这为 Circle STARK 铺平了道路。要了解更多关于 Circle STARKS 的信息,请查看 Vitalik、STARKware 和 Lambdaworks 对该主题的介绍。
.png?table=block&id=a6b682dd-3414-415f-9496-123e2b68a2a3&cache=v2)
Binius
Binius 将小字段的想法发挥到极致,以 二元字段塔 为目标。二元字段在硬件上非常高效,Binius 利用了一种 打包 技术,该技术消除了我上面描述的“嵌入开销”。与 JOLT 一样,我们对 Binius 的第一印象是:“这对于 RISC-V 证明来说很棒,但对于聚合来说就不太好了。”
事实上,对于像 Ligero、Orion 和 Brakedown 这样的系统来说,也是如此——证明时间看起来很棒,但验证器的复杂性大于 FRI,这导致了较差的递归性能。
最近,Binius 背后的团队基于 BaseFold(以及其他)中的见解和技术,推出了一种与二元字段塔原生配合使用的 FRI 变体。通过这种添加,Binius 提供了一个非常有吸引力的选项——从段证明层中删除嵌入开销,而不会导致聚合证明层的成本飙升。
在这个阶段,Binius 团队正在研究他们的递归层,而 JOLT 正在研究将 Binius 集成到他们基于 RISC-V 的证明架构中。现在我们想要采用它仍然太早了,但这是我们肯定会密切关注的另一个项目!
要了解更多关于 Binius 的信息,请查看 Vitalik 和 Lambdaworks 的介绍,或者 Jim Posen 在 zkSummit 11 上的演讲。
押注未来
RISC Zero 在所有这些工作中都处于一个非常有趣的位置。在短期内,由于我们整体系统的成熟度,我们预计会比 Circle STARK 或 Binius 更高效——我们的系统在 GPU 而非 CPU 上运行,并且我们已经有近 2 年的时间来调整在运行证明集群的背景下节省成本。
但忽略代码成熟度,仅查看底层证明系统,Circle STARK 和 Binius 看起来都很有希望。从长远来看,我们希望我们的工具尽可能模块化——我们希望让用户在运行 zkVM 时可以在证明系统之间进行选择。但在实践中,我们构建和支持的一切都有工程负担和维护负担。
目前,我们看到 STARKware 和 Polygon 都花费大量资源来构建他们自己的 Circle STARK 实现,而 Irreducible 正在为 Binius 构建聚合证明(即,递归)。
现在说 M31 或 Baby Bear 或二元字段塔是否是 “最佳选择” 还为时过早。实际上,这个问题在很大程度上取决于上下文。因此,现在,我们不会重新发明我们的基础——这既需要我们大大减慢我们的工程进度,也 需要我们对是否选择 Circle STARK 或 Binius 下一个巨大的赌注——我们将坚持使用 Baby Bear,以便继续对我们的系统进行明显的迭代改进,同时扩大我们对真实用户支持真实用例的能力。
转向新的闪亮的证明系统的诱惑一直存在。但我们仍然没有抽出时间来实现一些非常容易实现的目标,例如研磨或 LogUp,因为阿姆达尔定律要求我们关注其他地方。类似地,STIR 看起来是对 FRI 的明显改进,但我们将注意力集中在其他地方,因为递归不是我们的瓶颈,并且 FRI 只是段证明成本的一小部分。当我们发现重新设计证明系统比工程工作具有更好的投资回报率时,我们将重新设计证明系统。
在那之前,我们的总体计划非常简单:继续发布 ?。

感谢阅读!
希望本文对你了解 zkVM 设计领域中发生的事情有所帮助。在长期以来是生态系统中唯一的 RISC-V zkVM 之后,很高兴有一些杰出的竞争者进入这个领域。我们才刚刚开始进入这样一个时代:可验证计算的成本足够低,以至于对于大多数用例来说都是合理的。我们很高兴看到这些成本因各个层面的改进而下降,并且我们期待共同成长。
?
问题、意见、更正或建议?
在 Discord 上找到我们。
- 原文链接: risczero.com/blog/design...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
