互联网是什么?
- Frank Mangone
- 发布于 2025-05-28 09:22
- 阅读 2203
本文通过作者亲身经历引入,解释了互联网的工作原理。从早期的计算机通信需求开始,介绍了数据包交换的概念和ARPANET的诞生,随后详细讲解了IP协议如何标识和路由数据包,以及TCP协议如何确保数据可靠传输。最后,解释了DNS系统如何将域名解析为IP地址,使得用户可以通过易记的域名访问网站。文章旨在帮助读者理解互联网的基础架构和关键技术。
我认为这篇文章可能看起来有点不寻常。所以为了给你一些背景信息,我想从一个小故事开始。
我最初的编程方法是用 Flash,使用 ActionScript 制作简单的游戏。
我打 赌 你们有些人可能还记得那些美好的旧时光。
啊... 美好的回忆
那时我没有接受过任何计算机科学的正式教育,所以当我尝试进行 Web 开发时——不像今天这么容易——我发现很多东西难以理解。特别是,我不太明白 互联网 是如何运作的。
但我最终专注于开发部分,没有过多关注后台发生的事情。因为见鬼,如果我只是想构建一个网页,我为什么要关心互联网是如何运作的?
快进大约 15 年,我决定将我的职业生涯转移到软件开发领域——就像最近很多人所做的那样。我发现我有很多 问题和不安全感。
你知道,典型的 冒名顶替综合症 案例。
如果我想要在这个新工作中取得成功,我需要理解软件开发的基本原则。而我再次想知道 互联网是怎么工作的,以及我需要了解多少才能成为一名优秀的专业人士。
我的直觉告诉我, 你们中的一些人可能会与我的个人经历产生共鸣。
因此,本文适合那些仍然对这个话题有点困惑,并且可能想要填补一些知识空白的人。
我只能代表我自己说,但我知道几年前阅读这篇文章会对我有帮助。
所以,是的!我认为从揭示底层发生的事情中有很多收获——不仅可以理解我们访问网站时发生的过程,还可以正确评估我们在构建软件时可能遇到的挑战和问题。
开始吧!
第一步
回到 20 世纪 60 年代,计算机科学还处于起步阶段。计算机与我们现在可以握在手中的小型但功能强大的设备完全不同。相反,它们是笨重的外壳,你永远不会期望在任何普通家庭中找到它们。

比如 ENIAC,有史以来第一台通用计算机之一,建于 1945 年。
当然,访问这些机器是有限的。计算时间是一种吸引人的新资源,主要针对研究人员。游戏名称是进行 分时 的能力:允许单个计算机同时(并发地)执行许多任务。
计算机相当于多任务处理。
然而,没有明确的方式来 远程执行任务。这可能让人难以置信,因为现在我们可以与地球另一端的人进行实时聊天——但情况并非总是如此!
因此,当时的一大研究课题是 如何远距离传输执行指令。当时世界已经看到了 电报——所以这不是一项无法实现的壮举。
更多的是 效率 问题。换句话说:
如何在计算机之间高效地远距离发送信息?
这是当时研究人员需要回答的问题。
分组交换
与电报非常相似,当时另一项非常成熟的发明是 电话。传统的电话网络使用所谓的 电路交换:在通信的整个持续时间内,在两点之间创建专用的 物理 连接。
这正是我们在当代电影中看到的——人们根据需要将电缆插入配电盘。

这对于语音通话来说效果很好,但对于计算机通信来说效率非常低,计算机通信往往以 突发 形式发生。
当你加载你的 Instagram 源时,你通常会进行初始的“重”加载,然后应用程序会“空闲”并等待你的交互,然后再请求更多信息。虽然某些事情可能会在后台发生,但总体流程大多是这样的。
为每个信息突发创建专用电缆连接效率不高。需要一种不同的方法。
解决方案是通过某种方式 反转问题:你在不同的设备之间构建一个静态的连接 高速公路,并且你不是让信息通过直接路径,而是允许它采用任何路线——只要它到达目的地,我们应该没问题!
就像亚马逊运送你的好东西一样——他们有包裹的来源、目的地,并且他们会为你决定采取什么路线。

这就是所谓的 分组交换。这是当时的一个革命性概念,由保罗·巴兰 (Paul Baran) 和唐纳德·戴维斯 (Donald Davies) 等计算机科学家在 20 世纪 60 年代初独立开发。
数据被分成称为 数据包 的小块,每个数据包都包含有关其来源和去向的信息。这些数据包通过 网络 传输,采取不同的路线,然后在目的地重新组装。
很棒吧?
唯一的问题是我们 需要一个网络——这些数据包传输的高速公路。而这种基础设施实际上还不存在!
ARPANET
对我们来说幸运的是,这个 分组交换 想法并没有被搁置。相反,创建了必要的基础设施来充分利用它。
1969 年,高级研究计划局 (ARPA) 创建了第一个分组交换网络,并将其命名为 (请敲鼓) ARPANET。
是的……我们工程师并不是以最有创造力的人而闻名。
最初,它只连接了四个研究机构,但这足以证明分组交换技术是可行的。
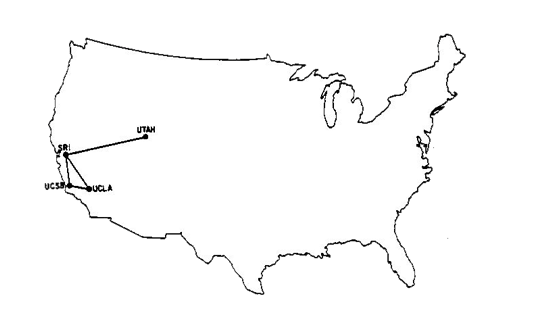
一开始它看起来并不像一条高速公路!
在接下来的十年里,越来越多的机构开始接入 ARPANET。慢慢地,它开始变得庞大。
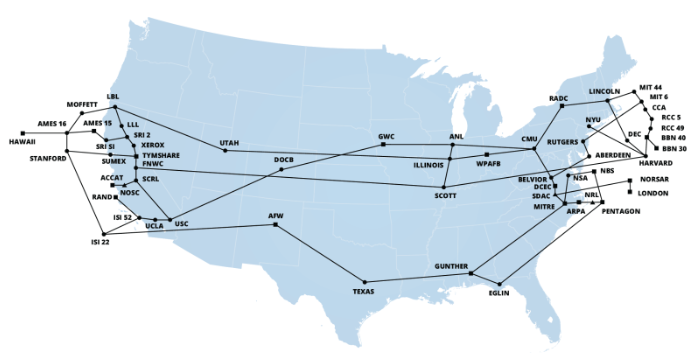
1977 年的 ARPANET
更大的网络非常酷——因为它能够与更多的计算机进行通信。然而,这也伴随着另一个问题。
你看,只有四个距离相对较近的机构,研究人员可以就如何 识别彼此以及他们交换的消息的格式达成一致。随着计算机和机构被添加到网络中,它们需要能够被其他现有计算机 识别,并且需要某种程度上 遵守一些规则 才能正确地将数据包从一个位置发送到另一个位置( 数据包路由 ),并让其他计算机理解它们的消息。
但是什么规则?谁来定义如何做事?
为了使一切不变得混乱,需要某种 标准。一套明确的规则需要遵守。一种 协议。
互联网规则
提问时间:你认为当你在浏览器上导航到网站时会发生什么?
好吧,说实话,发生了很多事情——但最重要的是,你的浏览器正在从世界上某个地方的 另一台计算机 中提取一堆文件。
现在谈论“云”是很常见的,但当然,网站不仅仅是漂浮在以太坊中——它们是存储在某个地方的文件组合,精确地传送到你的屏幕上。
这意味着至少两件事:我们需要正确 识别 源计算机和目标计算机,并且我们需要一种方法来确保 数据包 或 数据报 有效地从源计算机发送到我们的屏幕上。这就是 互联网协议 的由来。
互联网协议
想象一下邮局递送卡片。显然,他们希望每张卡片都有某种通用格式的地址,如 街道 + 门牌号 + 套房 + 邮政编码。其他事物的组合可能会让人觉得很奇怪,并且递送服务公司也不知道该如何处理它们。
让我们从简单的部分开始—— 识别。与真实地址非常相似, IP 地址 成为识别将通过网络连接的计算机的方式。
最常见的地址类型是 IPv4,它看起来像这样:
172.16.254.1
我们看到的是一个 32 位数字,分为 4 个 8 位(一个字节)的部分,用点分隔,并且是十进制格式。
这是一种很好且方便的方式来表示 0 到 2³² 之间的数字。
那个数字 ( 2³²) 实际上并不大。大约是 40 亿。统计和市场分析估计,计算机和个人设备的数量 超过了这个标记,这非常令人震惊,因为它可能意味着 IP 不是唯一的!
我的意思是,这应该是一个在 1983 年定义的标准的预期结果——当时很难预见到大规模采用的程度,我想。
虽然有一些解决方法——例如 网络地址转换 (NAT),它允许多个设备共享单个 IP 地址——但这种限制导致了 IPv6 的开发。
IPv6 地址如下所示:
2001:0db8:85a3:0000:0000:8a2e:0370:7334

这到底是什么?
这看起来不如 IPv4 那么友好——但在表面之下,它只是呈现 128 位的另一种方式。总共有大约 340 涧 个唯一地址(那是 340 后面跟着 36 个零)。
为了便于理解,我们可以为地球表面上的每个原子分配一个 IP 地址,并且仍然有剩余。
IPv6 的采用非常缓慢,今天,IPv4 和 IPv6 共存。是的,更新互联网很困难。谁会想到呢?
路由
现在我们已经识别了我们的计算机,我们需要确保数据包到达它们的目的地。但请记住,互联网本质上是一个连接系统的 图(网络),我们的数据包可能需要在途中停靠几次。
这就是 IP 路由 发挥作用的地方。路由实际上非常简单:就像询问 方向 一样。每当数据包到达 路由器 时,它基本上会问:“我如何到达这个目的地?”。
路由器是专门的计算机,其主要工作是 指挥流量。我们互联网高速公路上的交叉路口,那些大的绿色标志告诉数据包应该走哪个出口。

你的家庭路由器是你的个人网络与更广泛的互联网相遇的地方——如果你愿意,可以将其视为信息高速公路的入口匝道。
为了使其正常工作,需要两个要素:
- 这个路由器需要能够 理解 包裹的去向,并且
- 它还需要知道 将它指向哪里。
第一部分很容易:同样,我们依靠标准化,并让我们的数据包包含一个标头,其中包含一些关键信息——例如它的来源地、目的地、包裹的长度以及其他一些信息。
所有这些都捆绑在我们称之为 IP 数据包 的东西中。
不是那么直接的是第二部分。
你看,如果每个路由器都必须保留一个所有其他路由器及其连接对象的列表,我们会很快遇到问题。首先,大量信息(世界上所有网络的信息)将需要太多的内存。
更不用说这个列表是 高度动态的——它一直在变化。始终保持每个路由器更新是不可能的:互联网将花费更多的时间来八卦网络变化,而不是实际移动数据。
那我们该怎么办?

互联网使用了一种巧妙的方法: 分层路由。一个例子将在这里有所帮助:
想象一下,你想从你的家乡寄一封信给日本的某人。
你当地的邮局不需要知道东京每条街道的确切布局。它只需要知道将国际邮件发送到 区域分拣设施,该设施知道将其发送到 国际枢纽,该枢纽知道将其发送到日本,依此类推。
路由器的工作方式类似。它们维护 路由表,其中包含以下信息:
- 它们直接连接到的网络(相邻连接)
- 将数据包传递给 遥远目的地 的哪个相邻路由器
例如,你的家庭路由器不知道如何直接到达 Google 的服务器。它只知道将所有“非本地”流量发送到你的 互联网服务提供商 ( ISP) 的路由器。你的 ISP 路由器可能知道将 Google 流量发送到特定的主要 互联网交换点。以此类推,直到数据包到达其目的地。
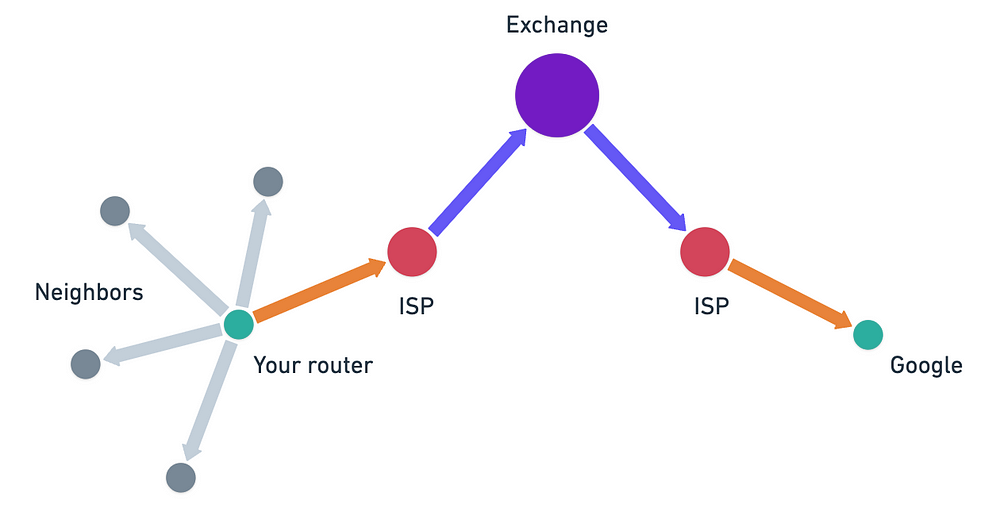
这不仅效率高,而且还是一个非常 有弹性 的模型。当某个地方的某些连接失败时,只有该区域中的路由器需要找到替代路径并将该信息与其邻居共享。互联网的其余部分大多不受这些局部中断的影响!
解释信息
好的,所以我们现在知道数据包是如何从一个地方到达另一个地方的。但请记住——我们的原始数据被分解成更小的片段,捆绑到这些数据包中,然后发送出去。
因此,接收者不会得到一个单一、整洁的传输中的所有数据,而是得到一堆 块,他们需要以某种方式将这些块组织成有意义的内容。
加载网页时,你希望所有数据包都以使网页看起来很好的方式重新构建,而不是仅仅学习 CSS 的人尽力而为!

他们是怎么做到的?
简短的回答:我们需要 更多协议。
在此级别上有两个主要的 传输 协议: 用户数据报协议 (UDP) 和 传输控制协议 (TCP)。我们将首先关注后者,因为它是使用最广泛的协议。
传输控制协议
对数据包进行排序需要额外的工作。TCP 提出的建议如下:
- 建立初始连接:就像敲接收者的门一样,看看他们是否在家,并准备好接收数据包。
- 对数据包进行编号:每个数据包都收到一个唯一的、递增的数据包编号,以便接收者可以按正确的顺序放置它们。
- 接收确认:接收者告诉发送者“是的,收到数据包 #47”,以便发送者知道已到达。
- 丢失的数据包重传:如果数据包 #47 永远没有得到确认,发送者将重试发送它。
- 流量控制:TCP 阻止发送者一次向接收者发送过多的数据。
通过这些相对简单的规则,我们确保了数据的 可靠 和 有序 传输。没有半加载的猫图片。 很好。
当然,这种可靠性不是免费的——TCP 有 开销。确认、编号和重传需要 时间 和 带宽。
对于某些应用程序,如 视频流 或 在线游戏,这种开销可能会成为一个关键的瓶颈——最好快速获取新数据,而不是等待旧数据被重传。在这些情况下, UDP 真正发挥作用:它使用“发送即忘记”策略, 更快,但 不可靠。
将它们放在一起
为了开始总结,让我们回到我们最初的问题:当你在浏览器上导航到网站时会发生什么?
- 你的浏览器确定要与之通信的服务器的 IP 地址
- 通过 TCP,与该服务器建立可靠的连接
- 你的浏览器通过该 TCP 连接发送请求
- 服务器使用网页数据响应
- TCP 确保所有数据都正确且按顺序到达
- 你的浏览器呈现该页面
非常令人震惊的是,由于数十年的工程改进,所有这些步骤通常在 毫秒 内发生。
我简化了一些细节——但我敢打赌,阅读完之后你仍然有一个挥之不去的问题。
当你输入“google.com”时,你的浏览器如何知道要连接到哪个 IP 地址?
域名系统
对了——你输入“google.com”或“twitter.com”或“stackoverflow.com”——而不是一些奇怪的数字序列。但是 TCP 只 理解 IP 地址,因此我们需要一种方法将这些 域名 映射到 IP 地址。
我们可以将这些域名视为 别名 ——但问题是 每个人 都应该就 别名到 IP 地址的映射 达成一致。我们如何确保此映射在整个庞大的互联网上保持一致?
这就是 域名系统 (DNS) 解决的问题。
又名互联网的电话簿。
不过,与我们之前的路由问题非常相似,由于其 大小 以及需要 更新 的频率,将此映射保存在每台计算机中是不可行的。
因此,DNS 也以 分层、分布式 方式工作。你首先检查你的计算机的 缓存 ——已知 IP 地址到域名转换的小列表。如果未找到匹配项,则下一步是询问你的 ISP。如果他们不知道,他们会将查询升级到所谓的 根域名服务器(也称为 根服务器)。
全世界共有 13 个“主”根服务器!
这些服务器反过来询问 .com 服务器,这些服务器询问较小的 权威服务器,这些服务器最终会回复“这是 google.com 的 IP 地址”。
一旦你的 ISP 了解了正确的 IP 地址,它就会记住它(缓存它!)以供后续查询。你的计算机也是如此!
总而言之,这是一个非常巧妙的系统。
它不仅仅是这个简短的解释——可以通过使用不同的 DNS 记录 以多种方式设置 DNS,它们可以实现很酷的技巧,例如:
- 负载平衡:将域名解析为不同的 IP 地址。
- 冗余:为同一域名返回多个 IP。
它确实存在一些缺陷:因为它是在一个更加“信任”的时代设计的,所以它忽略了一些可能的攻击。特别是,DNS 污染 可以将用户重定向到恶意站点,并且 DNS 中断 可以有效地使互联网的大部分无法访问。
总结
如果这感觉像是大量的信息,那是因为 确实如此。
毕竟,互联网是一个非常复杂和错综复杂的系统。即使在我们已经介绍的所有内容之后,还有很多东西需要学习。例如:
- 信息究竟是如何以 物理 意义上传输的?
- 什么是 HTTP,Web 浏览器实际上是如何请求和接收网页的?
- 互联网 安全 是如何工作的?
- 当出现问题时会发生什么(以及我们可以做什么)?
- 互联网的未来会怎样?
这是一个非常复杂的主题——正如我在本文开头提到的那样,根据你所做的事情或你正在构建的内容,你并不真正需要了解所有细节。
尽管如此,我坚信从尝试理解这些复杂的系统中有很多收获,因为它们展示了解决问题的巧妙方法,这些方法可能在其他情况下派上用场。
因此,下次你毫不费力地导航到你最喜欢的网站时,请记住有一个 完整的全球基础设施,它们在短短的 毫秒 内工作,让你获得珍贵的每日文章。
所有这些复杂性都隐藏在像输入 URL 这样简单的事情背后,这不是很棒吗?
- 原文链接: medium.com/@francomangon...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~




