重新定义排序器:理解聚合器和Header生产者
本文深入探讨了Rollup架构的各种变体,将sequencer分解为aggregator和header producer两个逻辑实体,并将sequencing过程分为inclusion、ordering和execution三个逻辑过程。
就像你一样,我也喜欢 Rollup。还有语义?哦,我爱死它们了。Jon 向我们介绍了 Rollup Multiverse,并打破了我们神圣的时间线。现在是探索所有被创造出来的变体的时候了。
所以,这就是我写这篇文章的目的:
- 我写这篇文章是为了更好地掌握整个系统,我希望你也能从中找到一些价值。
- 我希望我们挑战之前的定义,看看什么最适合我们现在所掌握的知识。这样,当我们在 CT 上争论最佳排序器设计时,我们都能了解最新的元数据。
- 我终于把我真正关心的主题写下来了(或者说敲到键盘上)。所以,不管你喜不喜欢,这都不会是你最后一次听到我的消息!
在这篇文章中,我将论证为什么将排序器分成两个逻辑实体是有意义的:聚合器(aggregator)和头部生产者(header producer)。别担心,我会在稍后给出定义。将排序(sequencing)分成三个逻辑过程也是一个好主意:包含(inclusion)、排序(ordering)和执行(execution)。
我将在本博客文章中重复以下结构:首先,我将介绍一个变体,并穿插我们将使用的一些定义。其次,我们将检查设计的抗审查性和活性(liveness)权衡。最后,我们将看看每个 Rollup 变体的最小化信任设置。
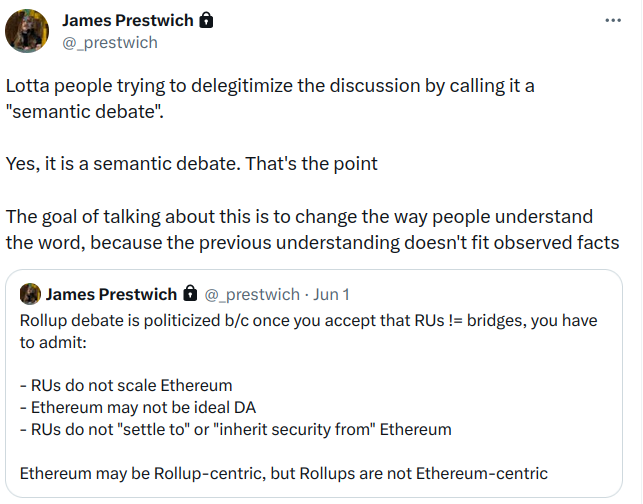
什么是 Rollup?
我们将从最简单的 Rollup 开始,并在需要时添加定义。我将从这篇 博客文章 中改编一个 Rollup 定义作为起点。
Rollups 是将它们的交易数据发布到另一个区块链,并继承其共识和数据可用性的区块链。
为什么我要把“区块(block)”改为“交易数据(transaction data)”呢?让我告诉你 Rollup 区块和 Rollup 数据之间的区别,并向你展示,通过我们的第一个变体,最小的 Rollup 只需要 Rollup 数据。
Rollup 区块 是一种数据结构,用于表示特定高度的区块链。它由 Rollup 数据和 Rollup 头部组成。
Rollup 数据 是交易批次(batch)或交易批次之间的状态差异。
变体 1:基于悲观 Rollup(Based Pessimistic Rollup)
构建 Rollup 最简单的方法是从用户将交易发布到另一个区块链开始。我们将这个区块链称为共识和数据可用性层,但在下面的所有图表中,我将把它缩短为 DA-Layer。在我们的第一个变体中,每个 Rollup 节点都必须重放区块链上的所有交易,以检查最新的状态。我们刚刚创建了一个悲观 Rollup!
一个 悲观 Rollup 是一个只支持完整节点(full node)的 Rollup,这些完整节点重放 Rollup 中的所有交易以检查其有效性。
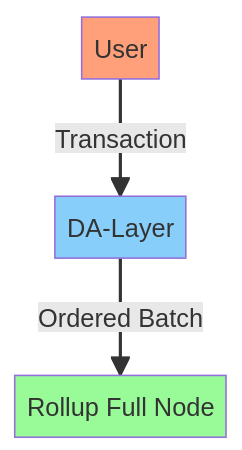
现在等等,在这种情况下谁是排序器(sequencer)?除了 Rollup 完整节点本身之外,没有实体实际执行交易。通常,排序器会聚合交易并生成一个 Rollup 头部,但这种情况下没有头部!将排序器分成两个逻辑实体:聚合器和头部生产者可以区分它。一个实体必须是状态感知的(即,必须执行状态以计算头部),但聚合器不需要理解状态就能够聚合它。
排序(sequencing) 是将交易聚合和头部生产的过程。
聚合(Aggregation) 是将交易批处理成一个批次(batch)的过程。一个交易批次由一个或多个交易组成。
头部生产(Header production) 是创建由特定安全属性支持的 Rollup 头部(header)的过程。
Rollup 头部(Rollup header) 是关于区块的元数据,至少包括对该区块中交易的承诺。

有了这个新的理解,我们可以重新措辞这个问题,并询问谁是聚合器,因为我们最初没有头部生产者。交易发布在 DA-Layer 上,这意味着 DA-Layer 是聚合器,这非常基于(based)。
一个 Based Rollup(based rollup) 是一个将聚合委托给 DA-Layer 的 Rollup。
感谢 colludingnode,他发布了 无领导者 Rollup 的想法,以及 Justin Drake,他创造了术语 Based Rollup。
Based Rollup 享有与 DA-Layer 相同的抗审查性和活性。Rollup 节点的最小化信任设置是运行一个 DA-Layer 轻节点和一个 Rollup 完整节点。
变体 2:使用共享聚合器的悲观 Rollup

让我们来谈谈使用共享排序器的悲观 Rollup。这个设计基于 Evan Forbes 首次介绍 共享排序器设计 的论坛帖子。这里的关键假设是,共享排序器是排序交易的唯一合法方式。任何其他批次?忽略。什么都没有。我将让 Evan 解释共享排序器的一个好处:
为了解锁一个相当于 web2 的用户体验,共享排序器可以提供快速的软承诺。这些软承诺提供了一些关于交易最终排序的任意承诺,并且可以被用来创建过早更新版本的状态。一旦 blockdata 被确认为已经发布在 baselayer 上,状态就可以被认为是最终的。
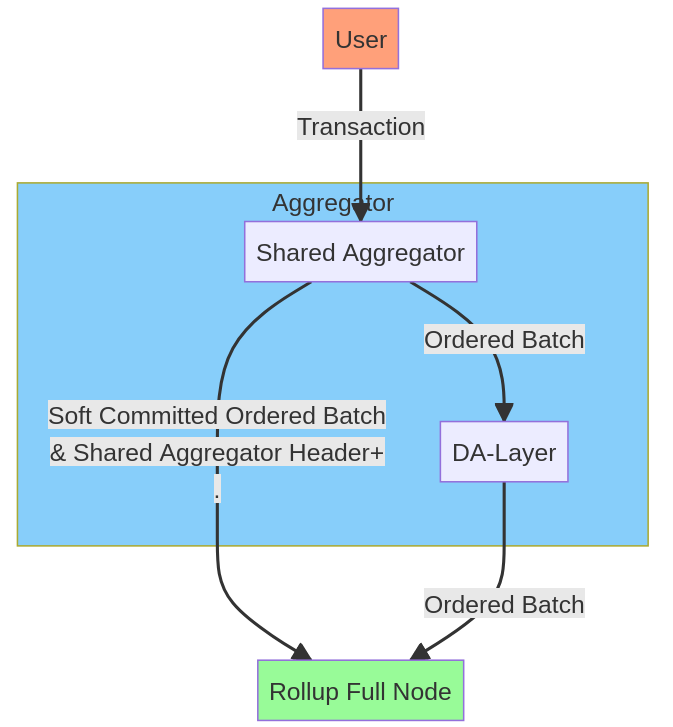
因为我们仍然是一个悲观 Rollup,我们只有 Rollup 完整节点。每一个都必须执行所有交易以保证有效性。这个系统中没有轻节点,所以不需要 Rollup 头部,也就是头部生产者。
由于这种类型的共享排序器不进行任何执行,我将从现在开始称其为共享聚合器。
这里的最小化信任设置是 DA-Layer 轻节点+共享聚合器轻节点+ Rollup 完整节点。我们需要一个共享聚合器轻节点来验证共享聚合器的头部。记住我们假设共享聚合器固定了顺序吗?好吧,共享聚合器在其头部中对交易的顺序有一个密码学承诺。这样,我们可以确认我们从 DA-Layer 收到的批次是由共享聚合器创建的,而不是由其他人创建的。为了验证共享聚合器的头部,我们至少需要一个共享聚合器轻节点。
包含(Inclusion) 是一个交易被接受到区块链中的过程。
排序(Ordering) 是在区块链中以特定顺序排列交易的过程。
执行(Execution) 是区块链中的交易被处理,并且它们的影响被应用到区块链状态的过程。
因为共享聚合器控制包含和排序,我们继承了它的抗审查性。
如果我们假设 L_ss 是共享聚合器的活性(liveness),L_da 是 DA-Layer 的活性,那么这个方案的活性是 L = L_da && L_ss。换句话说,如果任何一个系统出现活性故障,Rollup 也会出现活性故障。为了简单起见,我将使用活性作为一个布尔值。如果共享聚合器失败,我们就无法继续 Rollup。如果 DA-Layer 失败,我们可以继续使用共享聚合器的软承诺。但是,我们将依赖于共享聚合器的共识和数据可用性,这将比原始数据可用性层更糟糕。
我在这里区分了抗审查性和活性,但实际上并没有定义它。我正在做这篇博文试图阻止的事情,所以让我试着解释一下。在这个方案中,DA-Layer 不能审查特定的交易。它只能审查共享聚合器已经聚合的整个 Rollup 批次。
因为共享聚合器定义了交易之间和批次之间的排序,这种审查除了延迟 Rollup 的最终性之外没有任何作用。这就是为什么我认为抗审查性侧重于确保没有一个实体可以控制或操纵系统中的信息流动,而活性则关注于维护系统的功能和可用性,即使在出现中断和对抗行为时也是如此。即使这可能与当前的学术定义相冲突,我也会在整个博客中使用这些宽松的解释,但我对如何区分我试图区分的内容持开放态度。
让我们回到可以审查的人也可以获利的事实。
变体 3:具有基于和共享聚合的悲观 Rollup

想象一下,你的社区,即使它享受着共享聚合器的好处,也想避免依赖它,并且想要有一个 DA-Layer 的后备方案。我们将结合排序,并允许用户直接向 DA-Layer 提交交易。它结合了基于和共享的聚合。我们假设最终的排序将被解释为所有由共享聚合器排序的交易,然后是每个 DA-Layer 区块之后的所有基于交易。我们称之为 Rollup 的分叉选择规则。
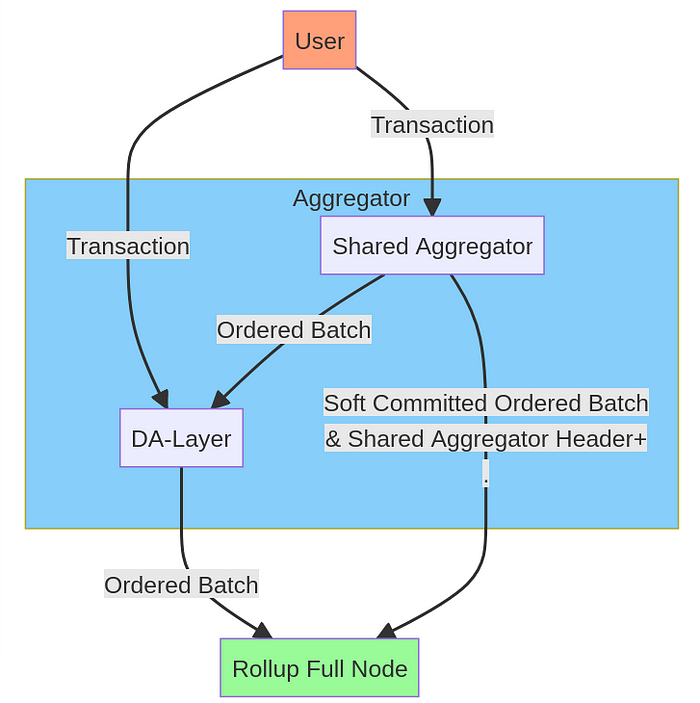
聚合在这里是一个两步舞。首先,共享聚合器带头,聚合一些交易。然后,DA-Layer 将已经排序的批次和用户直接提交的交易进行聚合。
抗审查性现在不再那么简单了。共享聚合器仍然可以通过共享聚合器的头部给出排序的软承诺。但这些承诺对排序的保证较弱,因为 DA-Layer 可能会审查来自共享聚合器的批次,直到下一个 DA-Layer 区块。因此,你只知道某些交易在批次中的排序,但你不能确定在批次之间是否有任何基于交易。这意味着你正在将 MEV 泄漏回 DA-Layer。我建议观看研究日关于 可盈利审查 MEV 的演讲。
已经有一些设计涌现出来,以减少 DA-Layer 执行这种审查价值提取的能力,比如我们称之为 重组窗口 的附加组件,它扩展了解释窗口,使其跨越多个区块,缺点是延长了执行时间。Sovereign Labs 在他们的设计提案中更详细地介绍了 基于软确认的排序,使用了“首选排序器”。由于 MEV 取决于你选择的聚合器方案和 Rollup 的分叉选择规则,有些不会泄漏任何 MEV,有些会泄漏一些或全部 MEV 给 DA-Layer,但那是另一天的话题。
至于活性,这种 Rollup 设计比仅仅拥有一个共享聚合器更胜一筹。如果共享聚合器出现活性故障,用户仍然可以向 DA-Layer 提交交易。
最后,让我们来谈谈最小化信任设置:DA-Layer 轻节点+共享聚合器轻节点+ Rollup 完整节点。我们仍然需要验证共享聚合器的头部,以便我们的 Rollup 完整节点能够区分交易批次以进行分叉选择规则。
变体 4:具有中心化头部生产者的基于乐观 Rollup

让我们开始使用一个名为基于乐观 Rollup 且具有中心化头部生产者的变体来构建一些轻节点。这个设计使用 DA-Layer 来聚合交易,但我们引入了一个中心化的头部生产者,以启用 Rollup 轻节点。
我们将为 Rollup 轻节点选择单轮欺诈证明,以间接检查 Rollup 交易的有效性。轻节点将乐观地信任头部生产者的执行,并在欺诈证明窗口结束后最终确定,或者从一个诚实的完整节点收到一个欺诈证明,该证明表明头部生产者进行了欺诈。
我不会详细介绍单轮欺诈证明的工作原理,因为这将打破本文的范围。这里的好处是,你可以将欺诈证明窗口时间从 7 天 减少到 某个量,这个量尚未确定,但比 7 天小得多。轻节点能够通过 p2p 层接收欺诈证明,而无需等待争议,因为所有内容都包含在一个证明中。
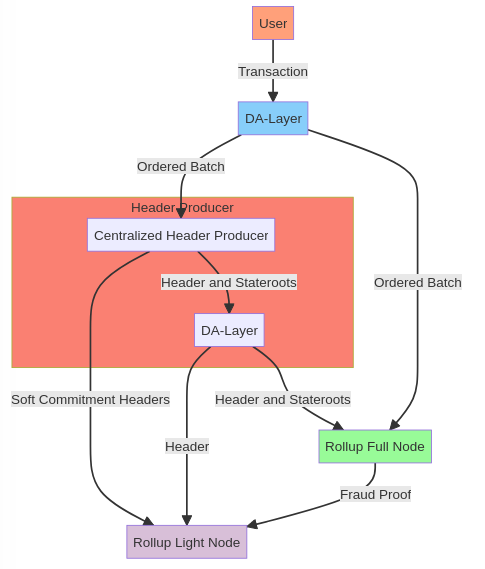
我们使用 DA-Layer 作为聚合器,继承了它的抗审查性。它进行包含和排序。中心化的头部生产者将从 DA-Layer 读取规范顺序,并能够从中构建一个有效的头部。中心化的头部生产者会将头部和状态根发布到 DA-Layer。这些状态根对于创建针对此承诺的欺诈证明至关重要。聚合器进行包含和排序,而头部生产者进行执行。
让我们假设 DA-Layer,因此聚合器是去中心化的,并且具有良好的抗审查性。此外,头部生产者无法更改交易的顺序,因为此设计假设我们从给定的交易顺序中进行确定性的状态执行。现在,去中心化头部生产者唯一能给你的就是更好的活性。Rollup 的所有其他属性都相同,因此这是一个给读者的问题,如果排序已经是去中心化的,我们是否需要去中心化执行。
如果头部生产者出现活性故障,Rollup 也会出现活性故障。轻节点将无法跟随链,而完整节点仍然可以跟随链(如果需要),退回到基于悲观 Rollup。
变体 5:具有去中心化证明者市场的基于 ZK-Rollup

我们有了悲观和乐观 Rollup,所以现在是有效性或 zk-rollup 的时候了。Toghrul 最近做了一个关于分离聚合器(排序器)和头部生产者(证明者)的演讲(零知识 Rollup 中的排序器-证明者分离)。如果你想要这种分离,发布交易 作为 Rollup 数据而不是状态差异更容易,所以我将专注于此。我将要研究的变体是具有去中心化证明者市场的基于 zk-rollup。
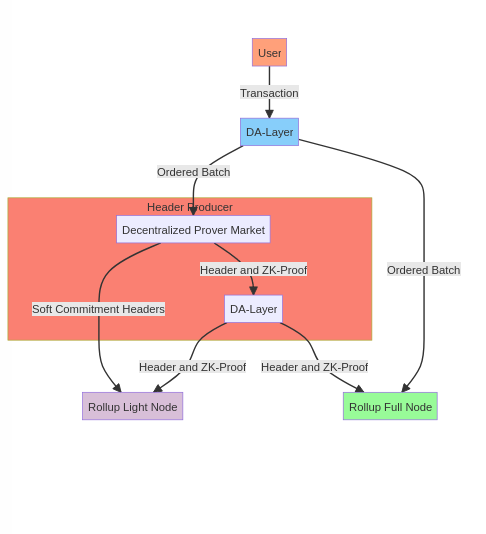
到目前为止,你应该熟悉了Based Rollup 的作用。它将我们的聚合器委托给 DA-Layer,DA-Layer 进行包含和排序。我将引用 Sovereign-Labs 的 文档,该文档对解释其设计生命周期做得非常出色。我将稍微调整它,使其适合上述变体。
[用户将]一个新的数据 blob 发布到 L1 链上。一旦 blob 在 L1 上最终确定,它在逻辑上就是最终的。在 L1 区块最终确定后,Rollup 的完整节点立即扫描并通过它,并按出现的顺序处理所有相关的数据 blob,生成一个新的 Rollup 状态根。此时,从所有完整节点的角度来看,该区块在主观上是最终的。
我们在此设计中的头部生产者是去中心化的证明者市场。
[P]证明者节点(在 ZKVM 中运行的完整节点)执行的过程与完整节点大致相同——扫描 DA 区块并按顺序处理所有批次——生成证明并将其发布在链上。(如果 Rollup 想要激励证明者,则需要在链上发布证明——否则,无法判断哪个证明者是第一个处理给定批次的)。一旦链上发布了给定批次的证明,该批次对包括轻[节点]在内的所有节点都是主观上最终的。
此变体享有与 DA-Layer 相同的抗审查性。去中心化的证明者市场无法审查交易,因为 DA-Layer 确定了规范的排序。我们只为了更好的活性和创建一个激励市场而去中心化头部生产者。这里的活性是 L = L_da && L_pm(证明者市场)。如果证明者市场的激励措施不一致,或者它出现活性故障,轻节点将无法跟随链,但 Rollup 完整节点仍然可以跟随链(如果需要),退回到基于悲观 Rollup。最小化信任设置与乐观情况一样,都是拥有一个 DA-Layer 轻节点+一个 Rollup 轻节点。
变体 6:具有中心化乐观头部生产者和去中心化证明者的基于混合 Rollup

我希望你准备好迎接我们的最终变体。我们将深入研究这种分离的组合性,并拥有 2 个不同的头部生产者!介绍“基于混合 Rollup,具有中心化乐观头部生产者和去中心化证明者”。我将尝试说明 Kelvin 在他的 博客 中首次提到的这种混合 Rollup,如下图所示:
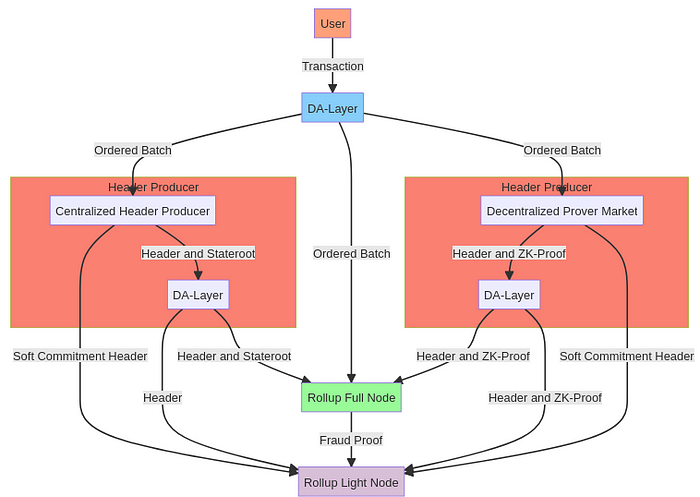
好吧,请听我说;这里有很多事情要做,但是如果你有一个变体和另一个变体,为什么不结合这两种方法并获得两者的好处呢?我们仍然使用 DA-Layer 作为聚合器,以保持该部分简单并委托包含和排序。
从图中可以看出,ZK Rollup 和乐观头部生产者都使用相同的排序批次作为其真理来源。这就是为什么我们可以并行使用这两种证明系统,因为排序批次可以与构建在其之上的证明系统无关。
让我们来谈谈最终性。从 Rollup 完整节点的角度来看,当 DA-Layer 最终确定时,Rollup 也就完成了,因为它只需要为这个变体执行交易即可。但我们更关心轻节点的最终性。让我们假设中心化的头部生产者拿出一些赌注,签署一个头部,并将计算的状态根发布到 DA-Layer。
就像以前一样,轻节点将乐观地信任执行并等待来自诚实完整节点的欺诈证明,该证明表明头部生产者进行了欺诈。在欺诈证明窗口结束后,从 Rollup 轻节点的角度来看,Rollup 区块是最终的。
现在是关键时刻,当我们获得 ZKP 时,我们可以停止等待欺诈证明。除了单轮欺诈证明之外,我们还可以使用生成的 ZKP 作为欺诈证明,并驳回乐观头部生产者生成的任何恶意头部!
轻节点达到最终性的另一种方式是当它收到 Rollup 高度的 ZKP 时。
现在我们有了一个快速、乐观、经济支持的软保证和一个快速的最终性。
此变体仍然享有与 DA-Layer 相同的抗审查性,因为它基于 DA-Layer。对于活性,我们将拥有 L = L_da && (L_op || L_pm ),这意味着我们提高了活性保证。如果中心化的头部生产者或证明者市场中的任何一个出现活性故障,我们可以退回到另一个方案。最后,最小化信任设置是 DA-Layer 轻节点+ Rollup 轻节点。
你会选择哪个变体?

来源:Marvel
TL;DR:
- 我们将排序器分成两个逻辑实体:聚合器和头部生产者
- 我们将排序器分成三个逻辑过程:包含、排序和执行。
- 悲观 Rollup 和Based Rollup 是一回事
- 你可以根据需要即插即用聚合器和头部生产者
- 这篇文章中的每个变体都遵循了这个设计模式:
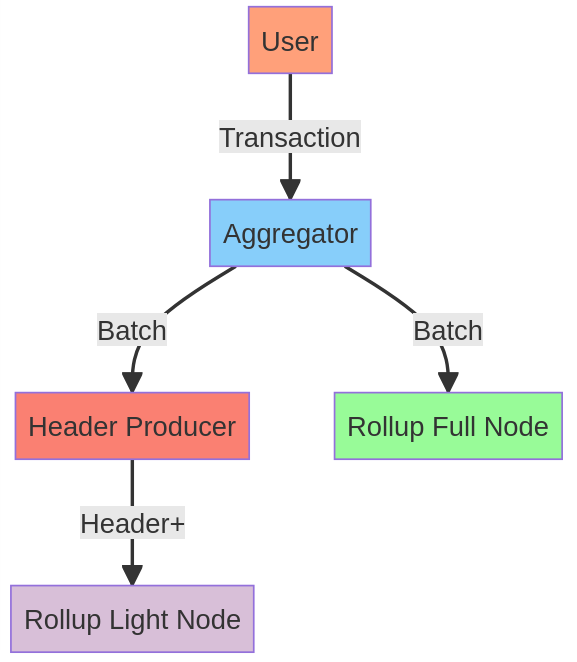
脑筋急转弯

好了,在我让你走之前,先说一些最后的想法。我们正在构建的模块化堆栈将以变体的形式爆炸式增长,你可以看到每个组件都形成了专门的软件。在这篇文章中,我向你展示了 Rollup 变体的冰山一角。我省略了很多细节,并特意保持非常抽象,以创建一个基本的思维模型。我简直不敢相信我写了一篇没有提到**主权(sovereign)或桥(bridges)**的 Rollup 文章。以下是我将在未来回答的一些脑筋急转弯,并邀请你思考。
- 经典的 Rollup 如何适应这一点?
- 在所有变体中,我们只让聚合器进行包含+排序,头部生产者进行执行。如果聚合器只进行包含,而头部生产者进行排序和执行呢?考虑链上拍卖。我们可以将所有 3 个都分开吗?
- 什么是共享头部生产者/头部生产者市场?
- 谁获得 MEV?我们能把它拿回来吗?
- 冗余和可组合性将降低退出游戏的成本,可组合性越低,退出成本越高
- 最小化信任桥=链上轻节点
- 意图?
感谢 Callum 审核了这篇文章。感谢 Evan、c-node、Wondertan、Mustafa、John 和加密 Twitter(Jon、Kelvin、Toghrul、Anatoly、James、Preston、kydo、rain&coffee、Patrick、Espresso、Josh、Alex),他们的大量讨论、博客文章和研究促使我写了这篇文章。如果你想了解 Rollup 讨论的最新进展,你应该关注他们。
如果你有任何问题、不同意我的观点或想看看如何解决一些脑筋急转弯,请随时在 Twitter 上与我联系。

- 原文链接: medium.com/@nashqueue/re...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
