共识机制原理(三)—— 分布式一致性算法
本文为学校《共识机制原理》自己记录的笔记 完整链接请访问:https://blog.0xhowe.top/
本笔记为学校《共识机制原理》自己记录的笔记
讲义与实验代码仓库:<https://github.com/DestinyWei/ConsensusMechanism>
个人博客:Howe的个人博客
若有任何问题或错误,可直接评论,我会及时回复
4 分布式一致性算法
重难点
- 两阶段提交协议
- PAXOS 协议
- RAFT 算法
4.1 两阶段提交协议
两阶段提交(two phase commit)协议是一种历史悠久的分布式控制协议
最早用于在分布式数据库中,实现分布式事务
在经典的分布式数据库模型中,同一个数据库的各个副本运行在不同的节点上,每个副本的数据要求完全一致
流程描述
参与的节点分为两类:一个中心化协调者节点(coordinator)和 N 个参与者节点(participant)
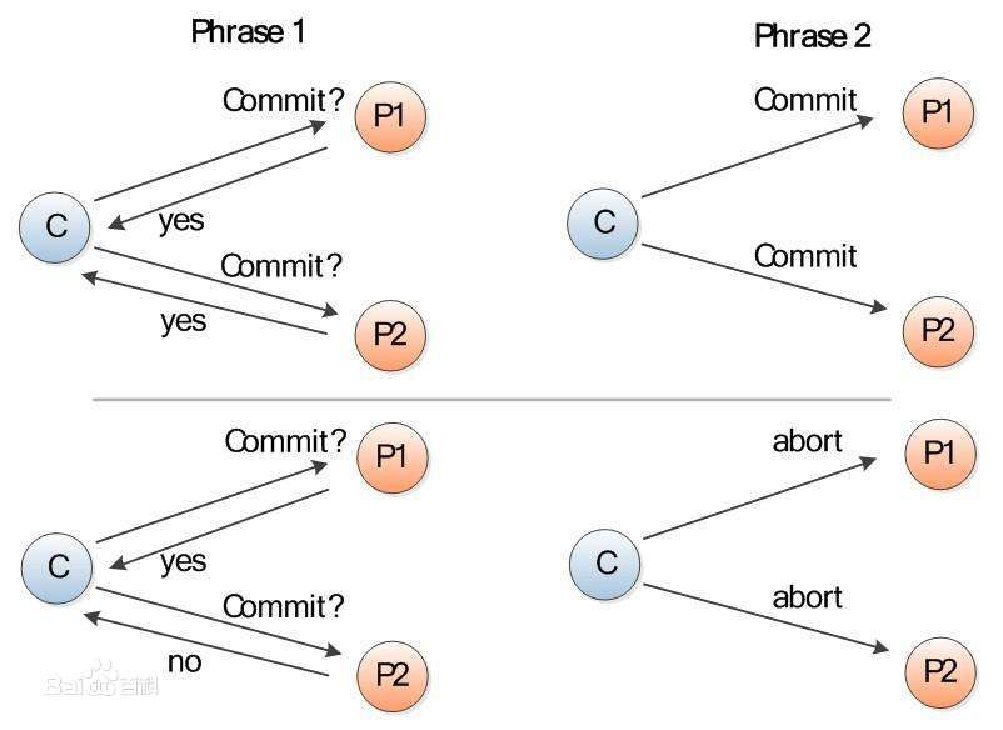
在第一阶段,协调者询问所有的参与者是否可以提交事务(请参与者投票),所有参与者向协调者投票。在第二阶段,协调者根据所有参与者的投票结果做出是否事务可以全局提交的决定,并通知所有的参与者执行该决定
Phase 1 Prepare:
- TC (协调者) 写本地日志,并持久化。TC 向所有参与者发送 Prepare T 消息
- 各参与者收到 Prepare T 消息,根据自身情况,决定是否提交事务 如果决定提交,参与者写日志并持久化,向 TC 发送 Ready T 消息 如果决定不提交,参与者写日志并持久化,向 TC 发送 Abort T 消息,本地也进入事务 abort 流程
Phase 2 Commit :
- 当 TC 收到所有节点的回应,或者等待超时,决定事务 commit 或 abort 如果所有参与者回应 Ready T,则 TC 先写日志并持久化,再向所有参与者发送 Commit T 消息。如果收到至少一个参与者 Abort T 回应,或者在超时时间内有参与者未回应,则 TC 先写日志,再向所有参与者发送 Abort T 消息
- 参与者收到 TC 的消息后,写日志并持久化
总结: TC 先询问其他参与者,在获得的回复中若有一个反对的声音就直接 abort,否则 commit。另外,无论是 abort 或者 commit,都是先写本地日志再发送消息
4.2 PAXOS 协议
流程描述
1990 年,Leslie Lamport 在论文《The Part-time Parliament》中提出了 Paxos 共识算法,在工程角度实现了一种最大化保障分布式系统一致性 (存在极小的概率无法实现一致) 的机制
希腊岛屿 Paxon 上的执法者在议会大厅中表决通过法律(一次 Paxos 过程),并通过服务员(proposer)传递纸条的方式交流信息,每个执法者会将通过的法律记录在自己的账目上。问题在于执法者和服务员都不可靠,他们随时会因为各种事情离开议会大厅(服务器宕机或网络断开),并随时可能有新的执法者进入议会大厅进行法律表决(新加入机器),使用何种方式能够使得表决过程正常进行,且通过的法律不发生矛盾(对一个值达成一致)
Paxos 是首个得到证明并被广泛应用的共识算法,其原理类似两阶段提交算法,进行了泛化和扩展,通过消息传递来逐步消除系统中的不确定状态
协议描述
Paxos 协议中,有三类节点:
- Proposer:提案者。Proposer 可以有多个,Proposer 提出议案(Value)。所谓 Value 在工程中可以是任何操作,对同一轮 Paxos 过程,最多只有一个 Value 被批准
- Acceptor:批准者。Acceptor 有 M 个,Proposer 提出的 Value 必须获得超过半数 ($\frac{M}{2}+1$) 的 Acceptor 批准后才能通过。Acceptor 之间完全对等独立
- Learner:学习者。Learner 学习被批准的 Value。所谓学习就是通过读取各个 Acceptor 对 Value的选择结果,如果某个 Value 被超过半数 Acceptor 通过,则 Learner 学习到了这个 Value。某个 Value 需要获得 $W=\frac{M}{2}+1$ 的 Acceptor 批准,从而学习者需要至少读取 $\frac{M}{2}+1$ 个 Accpetor,至多读取 M 个 Acceptor 的结果后,能学习到一个通过的 Value
协议描述 — Proposer 流程
准备阶段:
- 向所有的 Acceptor 发送消息 $Prepare(b)$ 。这里 b 是 Paxos 的轮数,每轮递增
- 如果收到任何一个 Acceptor 发送的消息 $Reject(b)$,则对于这个 Proposer 而言本轮 Paxos 失败,将轮数 b 设置为 b+1 后重新步骤 1
总结:只要有一个 Acceptor 发出 Reject 消息就增加提案号 b 并重新提出提案
批准阶段:
- 如果接收到的 Acceptor 的 $Promise(b,v_i)$ 消息达到 $\frac{M}{2}+1$ 个。$v_i$ 表示 Acceptor 最近一次在 i 轮批准过 Value V
- 如果收到的 $Promise(b,v)$ 消息中,V 都为空,Proposer 选择一个 Value V,向所有 Acceptor 广播 $Accept(b,v)$
- 否则在所有收到的 $Promise(b,v_i)$ 消息中,选择 i 最大的 Value V,向所有 Acceptor 广播消息 $Accept(b,v)$
- 如果收到 $Nack(B)$ (否定应答),将轮数 b 设置为 b+1 后重新步骤 1
协议描述 — Acceptor 流程
准备阶段:
- 接受某个 Proposer 的消息 $Prepare(b)$
- 如果 b > B,回复 $Promise(b,v_B)$,设置 B=b;表示保证不再接受编号小于 b 的提案。参数 B 是该 Acceptor 收到的最大 Paxos 轮数编号;V 是 Acceptor 批准的 Value,可以为空
- 否则,回复 $Reject(B)$
批准阶段:
- 接收 $Accept(b,v)$
- 如果 b < B,回复 $Nack(B)$,提示 Proposer 有一个更大编号的提案被这个 Acceptor 接收
- 否则设置 V=v。表示这个 Acceptor 批准的 Value 是 v,并广播 Accepted 消息
实例
- 初始状态

- Proposer 向所有 Acceptor 发送 $Prepare(1)$,所有 Acceptor 正确处理,并回复 $Promise(1,NULL)$

- Proposer 收到 5 个 $Promise(1,NULL)$,满足多余半数的 Promise 的 Value 为空,此时发送 $Accept(1,v_1)$,其中 $v_1$ 是 Proposer 选择的 Value

- $v_1$ 被超过半数的 Acceptor 批准, $v_1$ 即是本次 Paxos 协议实例批准的 Value。如果 Learner 学习 Value,学到的只能是 $v_1$
批准的 Value 无法改变
当前的状态

假设 Proposer 发送 $Prepare(4)$ 消息”,由于 4 大于所有的 Acceptor 的 B 值,所有收到 Prepare 消息的 Acceptor 回复 Promise 消息。但前三个 Acceptor 只能回复 $Promise(4,v_3)$,后两个Acceptor 回复 $Promise(4,NULL)$
回复 3 个 Promise 消息中,至少有 1 个消息是 $Promise(4,v_1_3)$,至多 3 个消息都是 $Promise(4,v_1_3)$。另一方面,Proposer 始终不可能收到 3 个 $Promise(4,NULL)$ 消息,最多收到 2 个。综上,按协议流程,Proposer 发送的 Accept 消息只能是 $Accept(4,v_1)$,而不能自由选择 Value
无论这个 Accept 消息是否被各个 Acceptor 接收到,都无法改变 v 是被批准的 Value 这一事实。即从全局看,有且只有 v 是满足超过多数 Acceptor 批准的 Value。例如,假设 $Accept(4,v_i)$ 消息被 Acceptor 1、Acceptor 2、Acceptor 4 收到,那么最终状态为:

一种不可能出现的状态
Paxos 协议的核心在于“批准的 Value 无法改变”
当前的状态

假设此时发生新的一轮 b=3 的 Paxos 过程,Proposer 有可能收到 Acceptor 3、4、5 发出的 3 个Promise 消息分别为 $Promise(3,v_1_1)$,$Promise(3,v_2_2)$,$Promise(3,v_2_2)$。按协议,Proposer 选择 Value 编号最大的 Promise 消息,即 $v_2_2$ 的 Promise 消息,发送消息 $Accept(3,v_2)$,从而使得最终批准的 Value 成为 $v_2$。就使得批准的 Value 从 $v_1$ 变成了 $v_2$(这是不可能出现的,已批准的 Value 值不能更改)
反推后证明该状态不可能存在
上述假设看似正确,其实不可能发生。这是因为本节中给出的初始状态就是不可能出现的。这是因为,要到达成上述状态,发起 $Prepare(2)$ 消息的 Proposer 一定成功地向 Acceptor 4、Acceptor 5发送了 $Accept(2,v_2)$。但发送 $Accept(2,v_2)$ 的前提只能是 Proposer 收到了 3 个 $Promise(2,NULL)$ 消息。然而,从状态我们知道,在 b=1 的那轮 Paxos 协议里,已经有 3 个 Acceptor 批准了 $v_1$,这 3 个 Acceptor 在 b=2 时发出的消息只能是 $Promise(2,v_1_1)$,从而造成Proposer 不可能收到 3 个 $Promise(2,NULL)$,至多只能收到 2 个 $Promise(2,NULL)$。另外,只要 Proposer 收到一个 $Promise(2,v_1_1)$,其发送的 Accept 消息只能是 $Accept(2,v_1)$ 从这个例子我们看到 Prepare 流程中的第 3 步是协议中最为关键的一步,它的存在严格约束了“批准的 Value无法改变”这一事实
节点异常
这里给一个较为复杂的异常状态下Paxos运行实例
本例子中有 5 个 Acceptor 和 2 个 Proposer。 Proposer 1 发起第一轮 Paxos 协议,然而由于异常,只有 2 个 Acceptor 收到了 $Prepare(1)$ 消息

Proposer 1 只收到 2 个 Promise 消息,无法发起 Accept 消息;此时,Proposer 2 发起第二轮 Paxos协议,由于异常,只有 Acceptor 1、3、4 处理了 Prepare 消息,并发送 $Promise(2,NULL)$ 消息

Proposer 2 收到了 Acceptor 1、3、4 的 $Promise(2,NULL)$ 消息,满足协议超过半数的要求,选择了 Value 为 $v_1$,广播了 $Accept(1,v_1)$ 的消息。由于异常,只有 Acceptor 3、4 处理了这个消息

Proposer 1 以 b=3 发起新一轮的 Paxos 协议,由于异常,只有 Acceptor 1、2、3、5 处理了 $Prepare(3)$ 消息

由于异常,Proposer 1 只收到 Acceptor 1、2、5 的 $Promise(3,NULL)$ 的消息,符合协议要求,Proposer 1 选择 Value为 $v_2$,广播 $Accept(3,v_2)$ 消息。由于异常,这个消息只被 Acceptor 1、2 处理

当目前为止,没有任何 Value 被超过半数的 Acceptor 批准,所以 Paxos 协议尚没有批准任何 Value。然而由于没有 3 个 NULL 的 Acceptor,此时能被批准的 Value 只能是 $v_1$ 或者 $v_2$ 其中之一。 此时 Proposer 1 以 b=4 发起新的一轮 Paxos 协议,所有的 Acceptor 都处理了 $Prepare(4)$ 消息

由于异常,Proposer 1 只收到了 Acceptor 3 的 $Promise(4,v_1_3)$ 消息、Acceptor 4 的 $Promise(4,v_1_2)$ 、Acceptor 5 的 $Promise(4,NULL)$ 消息,按协议要求,只能广播 $Accept(4,v_1)$ 消息。假设 Acceptor 2、3、4 收到了 $Accept(4,v_1)$ 消息。由于批准 $v_1$ 的 Acceptor 超过半数,最终批准的 Value 为 $v_1$
注意:这里的 Acceptor 2 的 Value 能从 $v_2$ 变为 $v_1$ 是因为其 $v_2$ 并没有被批准,满足 Paxos 协议中“批准的 Value 无法改变”的条件

竞争及活锁
从前面的例子不难看出,Paxos 协议的过程类似于“占坑”,哪个 value 把超过半数的“坑”(Acceptor)占住了,哪个 value 就得到批准了 这个过程也类似于单机系统并行系统的加锁过程。假如有这么单机系统:系统内有 5 个锁,有多个线程执行,每个线程需要获得 5 个锁中的任意 3 个才能执行后续操作,操作完成后释放占用的锁。我们知道,上述单机系统中一定会发生“死锁”。例如,3 个线程并发,第一个线程获得 2 个锁,第二个线程获得 2 个锁,第三个线程获得 1 个锁。此时任何一个线程都无法获得 3 个锁,也不会主动释放自己占用的锁,从而造成系统死锁 但在 Paxos 协议过程中,虽然也存在着并发竞争,不会出现上述死锁。这是因为,Paxos 协议引入了轮数的概念,高轮数的 Paxos 提案可以抢占低轮数的 Paxos 提案。从而避免了死锁的发生。然而这种设计却引入了“活锁”的可能,即 Proposer 相互不断以更高的轮数提出议案,使得每轮 Paxos 过程都无法最终完成,从而无法批准任何一个 value
Proposer 1 以 b=1 提起议案,发送 $Prepare(1)$ 消息,各 Acceptor 都正确处理,回应 $Promise(1,NULL)$

Proposer 2 以 b=2 提起议案,发送 $Prepare(2)$ 消息,各 Acceptor 都正确处理,回应 $Promise(2,NULL)$

Proposer 1 收到 5 个 $Promise(1,NULL)$ 消息,选择 Value 为 $v_1$ 发送 $Accept(1,v_1)$ 消息,然而这个消息被所有的 Acceptor 拒绝,收到 5 个 $Nack(2)$ 消息。Proposer 1 以 b=3 提起议案…

4.3 Raft 算法
简介
由于 Paxos 算法过于复杂、实现困难,极大地制约了其应用
Raft 算法在斯坦福 Diego Ongaro 和 John Ousterhout 于 2013 年发表的《In Search of an Understandable Consensus Algorithm》中提出
相较于 Paxos,Raft 通过逻辑分离使其更容易理解和实现
Raft 角色
- Leader(领导者) :负责日志的同步管理,处理来自客户端的请求,与 Follower 保持 HeartBeat 的联系
- Follower(追随者) :响应 Leader 的日志同步请求,响应 Candidate 的邀票请求,以及把客户端请求到 Follower 的事务转发(重定向)给 Leader
- Candidate(候选者) :负责选举投票,集群刚启动或者 Leader 宕机时,状态为 Follower 的节点将转为 Candidate 并发起选举,选举胜出(获得超过半数节点的投票)后,从 Candidate 转为 Leader 状态
Raft 三个子问题
- 选举(Leader Election) :当 Leader 宕机或者集群初创时,一个新的 Leader 需要被选举出来
- 日志复制(Log Replication) :Leader 接收来自客户端的请求并将其以日志条目的形式复制到集群中的其它节点,并且强制要求其它节点的日志和自己保持一致
- 安全性(Safety) :如果有任何的服务器节点已经应用了一个确定的日志条目到它的状态机中,那么其它服务器节点不能在同一个日志索引位置应用一个不同的指令
选举
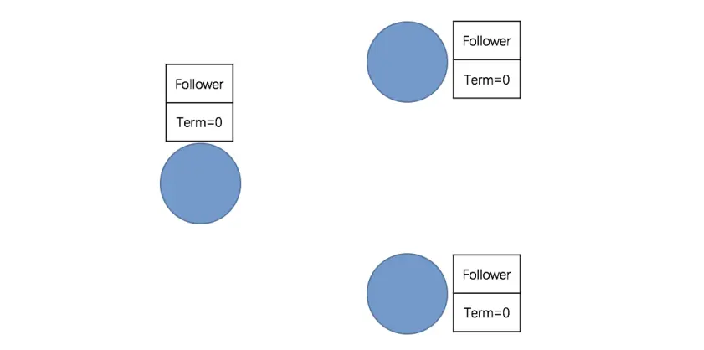
- 第一阶段:所有节点都是 Follower
所有节点的状态都是 Follower,初始 Term(任期)为 0
同时启动选举定时器,每个节点的选举定时器超时时间都在 100~500 毫秒之间且并不一致(避免同时发起选举)
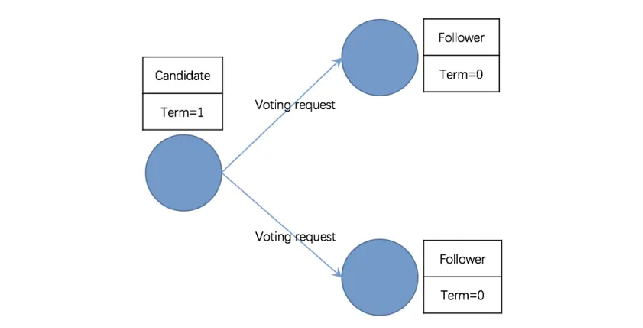
- 第二阶段:Follower 转为 Candidate 并发起投票
没有 Leader, Followers 无法与 Leader 保持心跳(HeartBeat),节点启动后在一个选举定时器周期内未收到心跳和投票请求,则状态转为候选者 Candidate 状态,且 Term 自增
并向集群中所有节点发送投票请求并且重置选举定时器
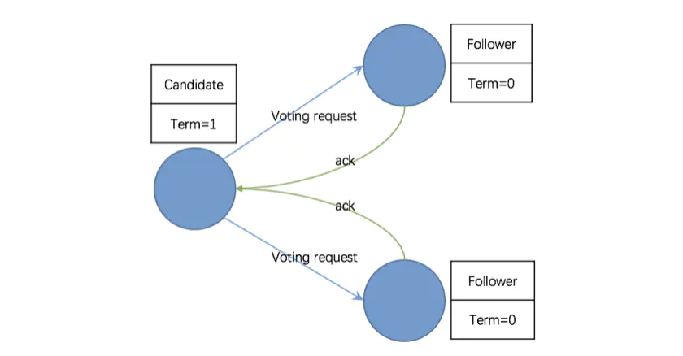
- 第三阶段:投票策略
请求节点的 Term 大于自己的 Term,且自己尚未投票给其它节点,则接受请求,把票投给它
请求节点的 Term 小于自己的 Term,且自己尚未投票,则拒绝请求,将票投给自己
- 第四阶段:Candidate 转为 Leader
一轮选举过后,正常情况下,会有一个 Candidate 收到超过半数节点 $(\frac{M}{2}+1)$ 的投票,它将胜出并升级为 Leader
定时发送心跳给其它的节点,其它节点会转为 Follower 并与 Leader 保持同步
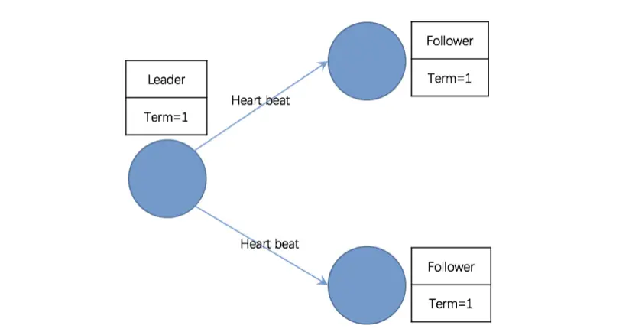
日志复制
- 在一个 Raft 集群中,只有 Leader 节点能够处理客户端的请求
- 客户端的每一个请求都包含一条被复制状态机执行的指令。Leader 把这条指令作为一条新的日志条目(Entry)附加到日志中去,然后并行地将附加条目发送给 Followers,让它们复制这条日志条目
- 当这条日志条目被 Followers 安全复制,Leader 会将这条日志条目应用到它的状态机中,然后把执行的结果返回给客户端
- 如果 Follower 崩溃或者运行缓慢,再或者网络丢包,Leader 会不断地重复尝试附加日志条目(尽管已经回复了客户端)直到所有的 Follower 都最终存储了所有的日志条目,确保强一致性
日志结构
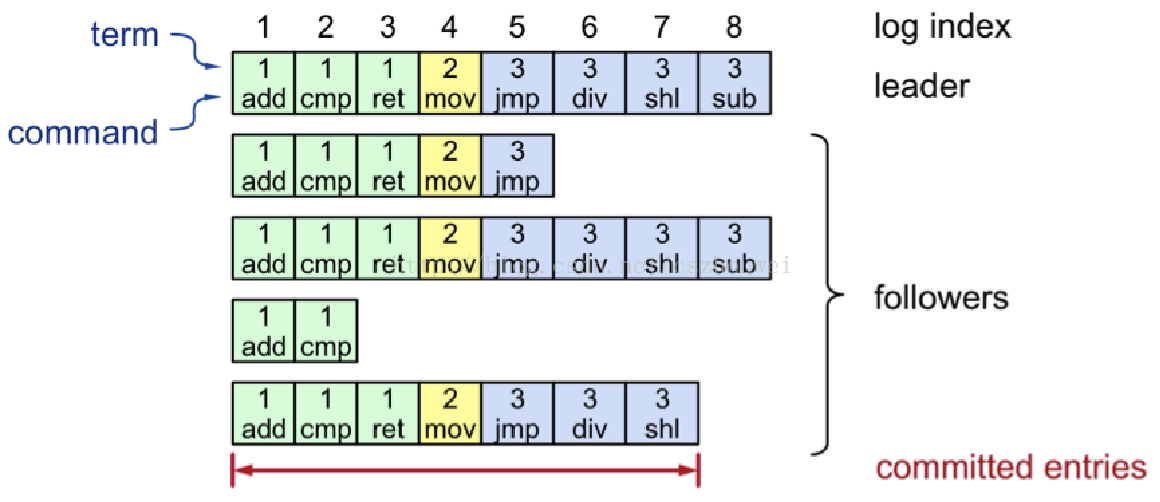
日志复制流程
- 第一阶段:客户端请求提交到 Leader
Leader 在收到请求后,会将它作为日志条目(Entry)写入本地日志中
此时该 Entry 的状态是未提交(Uncommitted),Leader 并不会更新本地数据,因此它是不可读的
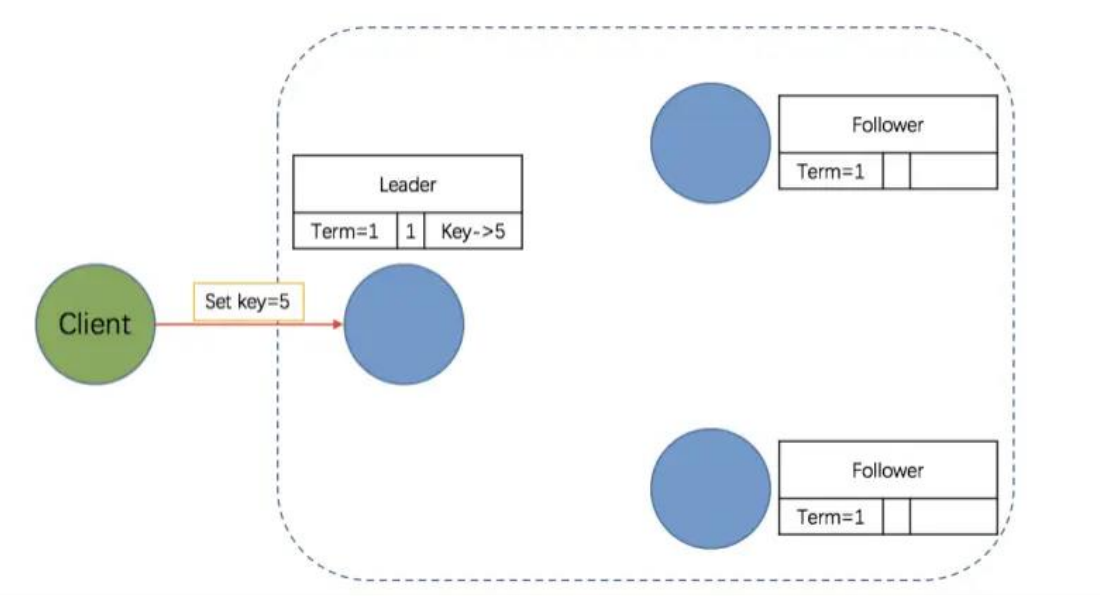
- 第二阶段:Leader 将 Entry 发送到其它 Follower
Leader 与 Followers 之间保持着心跳联系,随心跳 Leader 将追加的 Entry(AppendEntries)并行地发送给其它的 Follower,并让它们复制这条日志条目
有几点需要注意:
- 为什么 Leader 向 Follower 发送的 Entry 是 AppendEntries 呢?
因为 Leader 与 Follower 的心跳是周期性的,而一个周期间 Leader 可能接收到多条客户端的请求,因此,随心跳向 Followers 发送的大概率是多个 Entry,即 AppendEntries。当然,在本例中,我们假设只有一条请求,自然也就是一个 Entry 了
- Leader 向 Followers 发送的不仅仅是追加的 Entry (AppendEntries)
在发送追加日志条目的时候,Leader 会把新的日志条目紧接着之前条目的索引位置 (prevLogIndex) , Leader 任期号 (Term) 也包含在其中。如果 Follower 在它的日志中找不到包含相同索引位置和任期号的条目,那么它就会拒绝接收新的日志条目,因为出现这种情况说明 Follower 和 Leader 不一致
- 如何解决 Leader 与 Follower 不一致的问题?
在正常情况下,Leader 和 Follower 的日志保持一致,所以追加日志的一致性检查从来不会失败。然而,Leader 和 Follower 一系列崩溃的情况会使它们的日志处于不一致状态。Follower 可能会丢失一些在新的 Leader 中有的日志条目,它也可能拥有一些 Leader 没有的日志条目,或者两者都发生。丢失或者多出日志条目可能会持续多个任期
要使 Follower 的日志与 Leader 恢复一致,Leader 必须找到最后两者达成一致的地方(说白了就是回溯,找到两者最近的一致点),然后删除从那个点之后的所有日志条目,发送自己的日志给 Follower。所有的这些操作都在进行附加日志的一致性检查时完成
Leader 为每一个 Follower 维护一个 nextIndex,它表示下一个需要发送给 Follower 的日志条目的索引地址。当一个 Leader 刚获得权力的时候,它初始化所有的 nextIndex 值,为自己的最后一条日志的 index 加 1。如果一个 Follower 的日志和 Leader 不一致,那么在下一次附加日志时一致性检查就会失败。在被 Follower 拒绝之后,Leader 就会减小该 Follower 对应的 nextIndex 值并进行重试。最终 nextIndex 会在某个位置使得 Leader 和 Follower 的日志达成一致。当这种情况发生,附加日志就会成功,这时就会把 Follower 冲突的日志条目全部删除并且加上 Leader 的日志。一旦附加日志成功,那么 Follower 的日志就会和 Leader 保持一致,并且在接下来的任期继续保持一致
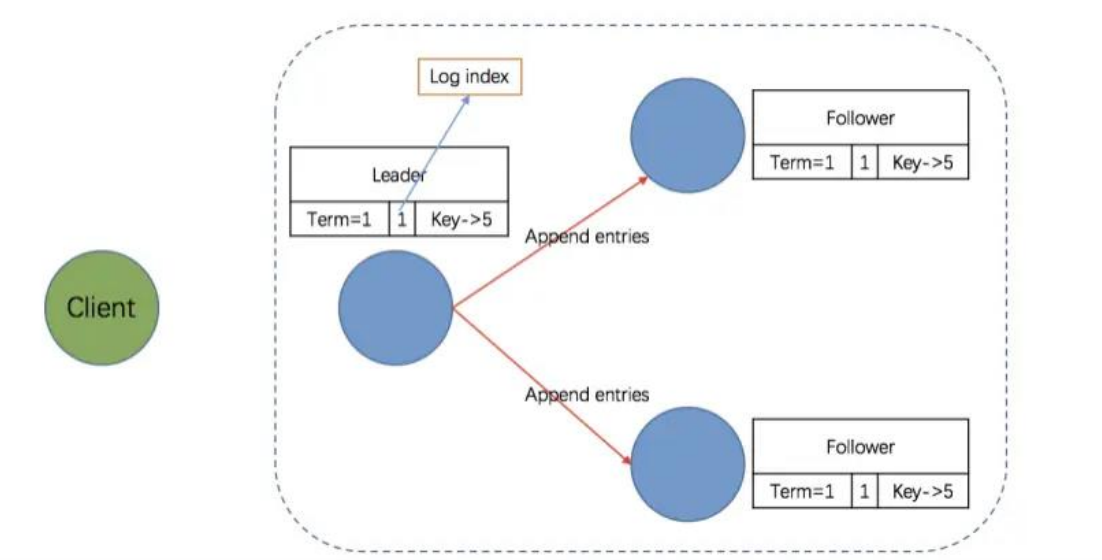
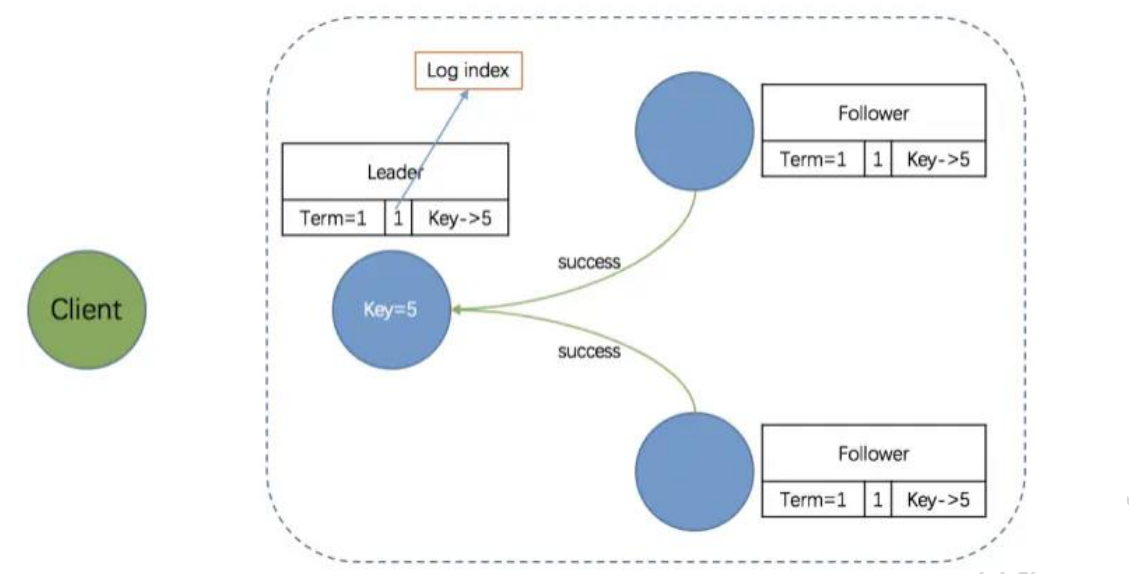
- 第三阶段:Leader 等待 Followers 回应
写入本地日志中,返回 Success
一致性检查失败,拒绝写入,返回 False
在发送追加日志条目的时候,Leader 会把新的日志条目紧接着之前条目的索引位置(prevLogIndex), Leader 任期号(Term)也包含在其中。如果 Follower 在它的日志中找不到包含相同索引位置和任期号的条目,那么它就会拒绝接收新的日志条目,因为出现这种情况说明 Follower 和 Leader 不一致
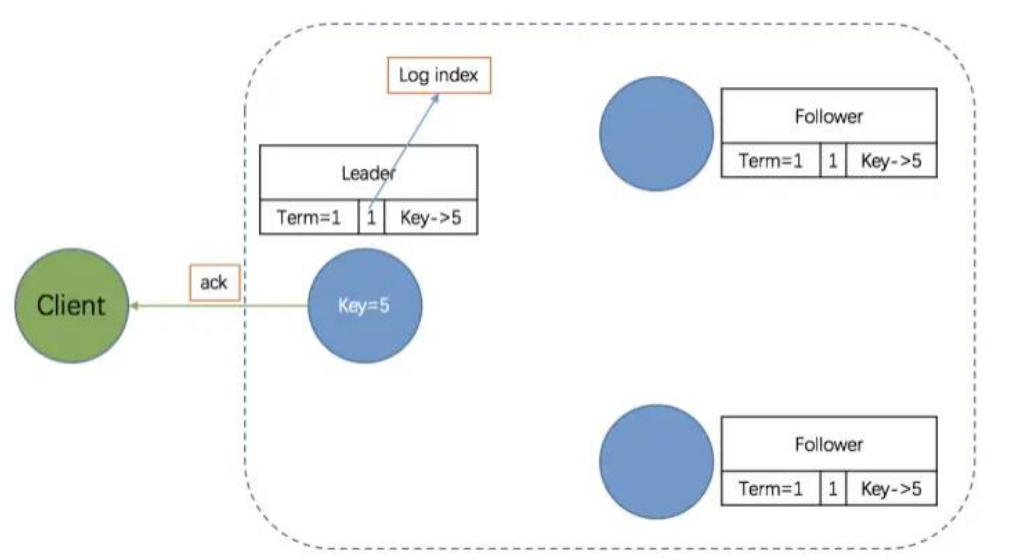
- 第四阶段:Leader 回应客户端
Leader 会向客户端回应 OK,表示写操作成功
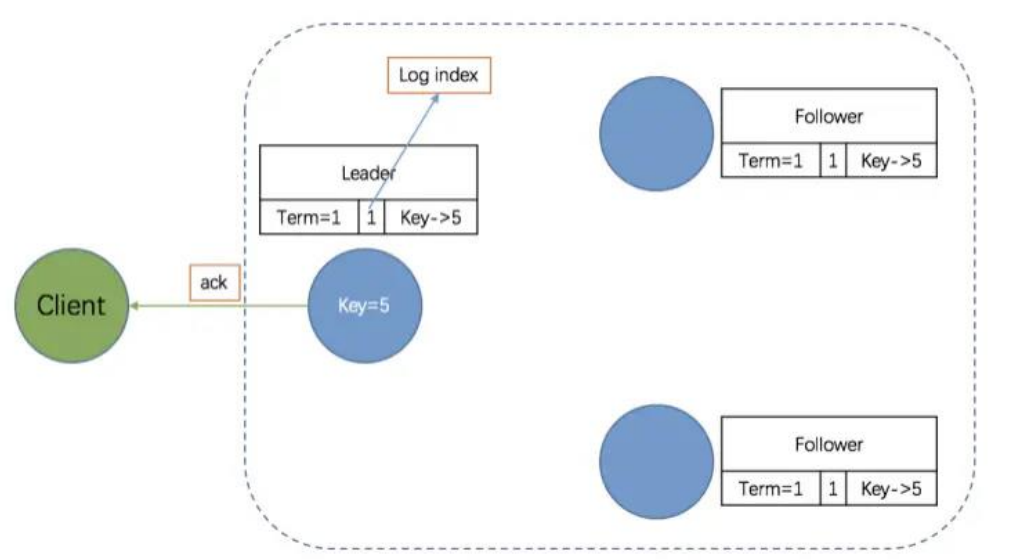
- 第五阶段,Leader 通知 Followers Entry 已提交
Leader 回应客户端后,将随着下一个心跳通知 Followers, Followers 收到通知后也会将 Entry 标记为提交状态
算法安全性
- Election Safety
在任意指定 Term 内,最多选举出一个 Leader
- Leader Append-Only
Leader 从不“重写”或者“删除”本地 Log,仅仅“追加”本地 Log
- Log Matching
如果两个节点上的日志项拥有相同的 Index 和 Term,那么这两个节点 $[0,Index]$ 范围内的 Log 完全一致
- Leader Completeness
如果某个日志项在某个 Term 被 commit,那么后续任意 Term 的 Leader 均拥有该日志项
- State Machine Safety
一旦某个 server 将某个日志项应用于本地状态机,以后所有 server 对于该偏移都将应用相同日志项
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
