DuneSQL 如何编写高效查询
DuneSQL 如何编写高效查询
- 原文链接:https://docs.dune.com/query-engine/writing-efficient-queries
- 译者:AI翻译官
- 本文永久链接:learnblockchain.cn/article…
编写高效的查询
通过编写高效的查询来充分利用 DuneSQL。
编写高效的查询对于充分利用 Dune 至关重要。本指南将帮助你了解如何在 DuneSQL 上编写高效的查询。
为了在 DuneSQL 上编写高效的查询,了解系统的基础架构是很重要的。本指南将帮助你了解 DuneSQL 在幕后的工作原理,以便你可以编写更高效的查询并充分利用 Dune。遗憾的是,并没有一种魔法弹药可以使你的所有查询运行得更快,但了解 DuneSQL 的基础架构将有助于你编写更高效的查询并充分利用该系统。
DuneSQL 架构
DuneSQL 是基于 Trino 的查询引擎,专为处理以列存储格式存储的数据而设计。更具体地说,我们使用 Parquet 文件作为底层存储格式。这样可以实现高效的数据访问和查询处理,以及快速的数据加载和数据压缩。为了了解如何在 DuneSQL 上编写高效的查询,了解 DuneSQL 中数据的存储和访问方式是很重要的。因此,本指南将从数据库简介开始,然后深入了解 DuneSQL 的工作原理。
数据库简介
让我们从数据库简介开始,以便了解在 DuneSQL 上编写查询时需要优化的内容。
在本质上,数据库是设计用于存储、检索和管理数据的复杂系统。它们的主要目标是提供对大量结构化信息的快速、高效和可靠访问。你可以将数据库视为一组表,其中每个表都是行和列的集合。从概念上讲,这些表以两种方式存在:
- 逻辑视图(Logical):表的逻辑视图是数据组织和向用户呈现的方式。这是你查询表时看到的视图。
- 物理视图(Physical):表的物理视图是数据存储在磁盘上的方式。这是你查看组成表的底层文件时看到的视图。
数据库旨在优化表的逻辑视图,这是用户交互的视图。然而,表的物理视图也很重要,因为它决定了数据的存储和访问方式。为了优化表的逻辑视图的可用性,数据库使用各种技术来优化表的物理视图。这些技术包括:
- 数据分区:数据分区是一种将数据分成称为分区的较小块的技术。这减少了需要存储和访问的数据量,从而提高性能。
- 数据索引:数据索引是一种创建称为索引的数据结构的技术。这个数据结构包含有关表中数据的信息,这使得数据库可以快速找到所需的数据。
- 数据存储布局:数据存储布局涉及数据在磁盘上的存储方式。这包括文件格式、数据在磁盘上的物理存储方式以及数据在内存中的组织方式。正确的数据存储布局可以显著提高性能。
- 数据压缩:数据压缩是一种通过删除冗余信息来减小数据大小的技术。这减少了需要存储和访问的数据量,从而提高性能。
- 数据缓存:数据缓存是一种将经常访问的数据存储在内存中的技术。这减少了需要存储和访问的数据量,从而提高性能。
在很大程度上,这些技术是在后台使用的,用户看不到。然而,了解数据分区、数据索引和数据存储布局的工作原理对于在 DuneSQL 上编写高效的查询是至关重要的。
数据库采用这些技术来应对它们最重要的挑战:数据存储的 I/O 限制性质。I/O 限制指的是数据访问速度受存储设备速度限制的事实。读取速度,即从存储加载数据到内存所需的时间,是数据库的一个重要约束。
每次查询表时,数据库都需要将数据从磁盘读入内存。这发生在一个称为页面的单位中。页面是可以从磁盘读入内存的最小数据单元。由于从磁盘读取页面很慢,数据库会尽量减少查询表时需要读入内存的页面数。这就是数据分区和数据索引发挥作用的地方。在下一节中,我们将更详细地了解 DuneSQL 的工作原理以及如何编写查询以最小化需要读入内存的页面数。
简要总结: 数据库的目标是提供对大量结构化信息的快速、高效和可靠访问。最终,我们希望尽快访问表的逻辑视图。为此,数据库管理员使用各种技术来优化表的物理视图。这些技术包括数据分区、数据索引、数据压缩和数据缓存。这些技术的目标是在查询表时最小化需要读入内存的页面数。
DuneSQL 架构
现在我们了解了数据库的工作原理,让我们看看 DuneSQL 在幕后是如何工作的。具体来说,让我们看看 DuneSQL 中数据是如何存储和访问的。
Dune 将数据存储在 Parquet 文件中,这些文件首先是列存储文件,但也利用了部分面向行的存储的优势。Parquet 系统中的数据按行分区存储在多个 Parquet 文件中,而在每个文件内,数据进一步分区为行组。然而,行组内的页面以列而不是行的方式存储数据。因此,在更高级别上,数据库看起来是面向行的,但在访问特定值时,它会从面向列的页面中读取数据。此外,每个 Parquet 文件包含有关其存储的数据的元数据,主要是每列的 min/max 列统计信息。这使得数据库可以在扫描表时有效地跳过整个 Parquet 文件或文件内的行组,前提是列包含的值不是随机的并且可以排序。编写利用此功能的查询对于在 DuneSQL 上编写高效的查询至关重要。
在一个非常简化的示意图中,我们的 ethereum.transactions 表存储在一个 Parquet 文件中,看起来像这样:
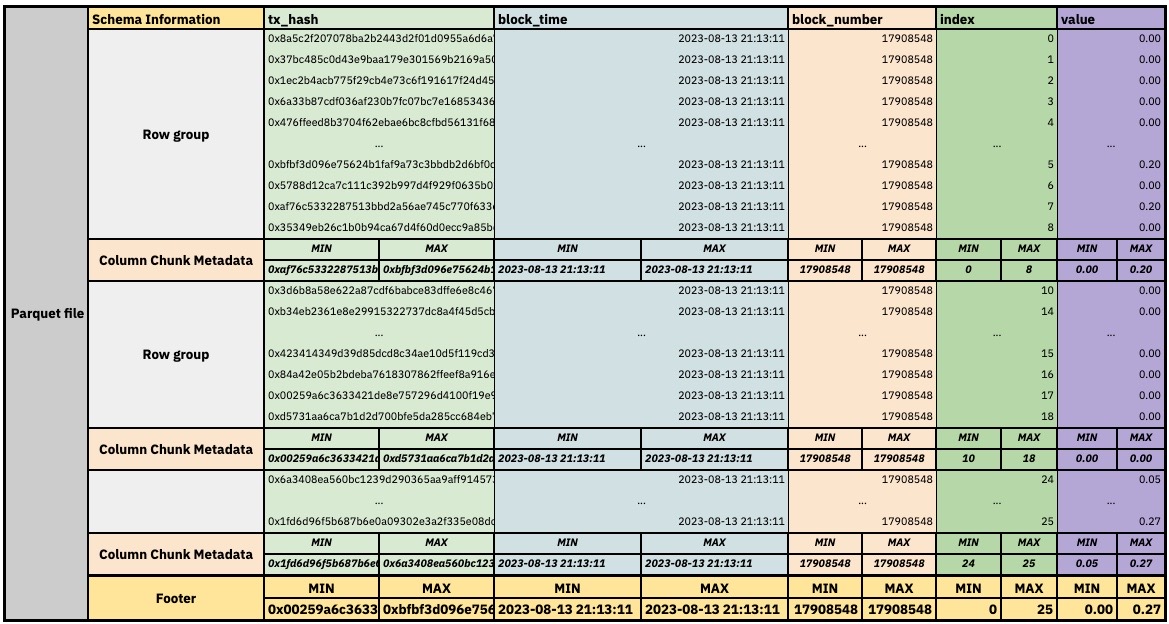
Parquet 文件的非常简化内容
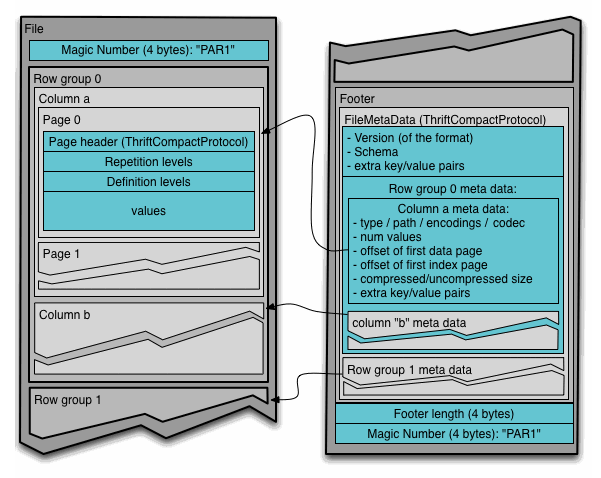
Parquet 文件的示意图
这里重要的是要理解的是,DuneSQL 不需要传统数据库的索引结构。相反,每列的 min/max 值用于在扫描表时有效地跳过整个 Parquet 文件或文件内的行组,前提是列包含的值不是随机的并且可以排序。这是 DuneSQL 与 Snowflake 等系统之间的一个关键区别。
如果在 DuneSQL 中查询表,系统将按以下顺序访问数据:
-
文件级别: 在基础级别,查询引擎定位与正在查询的表或表部分相关联的特定 parquet 文件。它读取每个 parquet 文件底部包含的元数据,以确定它是否可能包含查询所需的数据。它将跳过不包含查询所需数据的文件。
-
行组级别: 一旦确定了适当的 Parquet 文件,引擎将根据查询条件访问文件中的相关行组。同样,它将首先读取每个行组的元数据,以确定它是否可能包含查询所需的数据。如果行组不包含查询所需的数据,它将跳过该行组并继续下一个。
-
列块级别: 一旦确定了适当的行组,系统将根据查询条件访问行组内的相关列块。列块包含查询所需的实际数据。数据库将仅读取包含查询所需数据的列块。它不会读取逻辑行 - 从而节省时间和资源。
-
页面级别: 在列块内,数据进一步分段为页面。数据库将这些页面读入内存,从中获益于任何压缩或编码优化。
在此过程中,引擎从其已读取的第一个数据块开始流处理。它将根据已读取的数据进行优化:如果识别出某些数据是无关的,则可以放弃读取其他数据。这称为动态过滤,通常可以节省大量资源。
如果查询太大而无法在内存中处理,则数据将从内存“溢出”到磁盘。这称为“溢出到磁盘”,在数据库中很常见。这将对查询性能产生负面影响,因为从磁盘读取数据比从内存读取数据要慢得多。为避免此问题,编写高效的查询很重要,以最小化需要读入内存的数据量。
在 DuneSQL 上编写高效查询的提示
要在 DuneSQL 上编写高效查询,关键是使用基于非随机且可排序的列的过滤条件。像 block_time、block_date 和 block_number 这样的列是最佳选择,因为它们是顺序排列的,可以有效地跳过整个 parquet 文件或文件内的行组。
让我们看一个例子。假设你想查询 ethereum.transactions 表以获取特定交易哈希。查询通常如下所示:
SELECT * FROM ethereum.transactions
WHERE hash = 0xce1f1a2dd0c10fcf9385d14bc92c686c210e4accf00a3fe7ec2b5db7a5499cff
使用上述步骤,查询引擎将执行以下操作:
- 文件级别: 查询引擎尝试定位与正在查询的表或表部分相关联的特定 parquet 文件。它读取每个 parquet 文件底部包含的元数据,以确定它是否可能包含查询所需的数据。它将尝试跳过不包含查询所需数据的文件。然而,由于查询基于随机哈希,引擎将无法跳过任何文件。它将不得不读取与表相关联的所有文件。
我们可以在这里停止按步骤进行,因为查询引擎将不得不读取几乎所有与表相关联的文件和行组。这将对查询性能产生负面影响,因为不得不从所有 parquet 文件中的所有列块中读取所有页面非常低效。可能存在一些非常不太可能的边缘情况,引擎可以跳过一些文件,但一般来说,引擎将不得不读取与表相关联的所有文件。对于此查询可以跳过的行组或列块的一个示例是,如果行组或文件的哈希列奇迹般地仅包含来自 0xd... - 0xz... 的值。在这种情况下,由于我们的哈希是 0xc...,那么该行组或文件不可能包含我们正在寻找的哈希,引擎可以跳过它。然而,这种情况发生的可能性非常低,很可能引擎将不得不读取与表相关联的所有文件。
现在让我们看一个使用非随机且可排序列(如 block_number)的查询:
SELECT * FROM ethereum.transactions
WHERE block_number = 14854616
AND hash = 0xce1f1a2dd0c10fcf9385d14bc92c686c210e4accf00a3fe7ec2b5db7a5499cff
使用上述步骤,查询引擎将执行以下操作:
-
文件级别: 查询引擎尝试定位与正在查询的表或表部分相关联的特定 parquet 文件。它读取每个 parquet 文件底部包含的元数据,以确定它是否可能包含查询所需的数据。在这种情况下,引擎将检查我们正在搜索的
block_number是否在每个 parquet 文件底部的block_number列的min/max值范围内。例如,如果引擎开始读取第一个 parquet 文件并看到block_number列的min/max值为14854600和14854620,它将知道该文件不包含查询所需的数据。它将跳过该文件并继续下一个。这将显著减少需要读入内存的数据量,从而提高查询性能。 -
行组级别: 一旦确定了适当的 Parquet 文件,引擎将根据查询条件访问文件中的相关行组。同样,它将首先读取每个行组的元数据,以确定它是否可能包含查询所需的数据。如果行组不包含查询所需的数据,它将跳过该行组并继续下一个。这将进一步减少需要读入内存的数据量,从而提高查询性能。
-
列块级别: 一旦确定了适当的行组,系统将根据查询条件访问行组内的相关列块。列块包含查询所需的实际数据。数据库将仅读取包含查询所需数据的列块。它不会读取逻辑行 - 从而节省时间和资源。
-
页面级别: 在列块内,数据进一步分段为页面。数据库将这些页面读入内存,从中获益于任何压缩或编码优化。
正如你所见,查询引擎可以在扫描表时跳过整个 parquet 文件和文件内的行组,前提是列包含非随机且可排序的值。这就是为什么使用基于非随机且可排序的列(如 block_number、block_time 或 block_date)的过滤条件很重要。
上述示例在很大程度上是理论性的,你很可能不会为特定交易哈希查询 ethereum.transactions 表。然而,相同的原则也适用于其他表和查询。例如,如果我们想查询 ethereum.traces 以获取对特定智能合约的所有调用,我们可以使用 block_number、block_time 或 block_date 来在扫描表时跳过整个 parquet 文件和文件内的行组。通常,你会这样编写查询:
Select
*
FROM ethereum.traces
WHERE to = 0x510100D5143e011Db24E2aa38abE85d73D5B2177
有了我们的新知识,我们可以推断这个查询将非常低效,因为引擎将不得不读取与表相关的几乎所有文件和行组。相反,我们可以通过帮助引擎跳过block_number大于特定值的文件来优化查询。例如,如果我们知道智能合约部署在块17580248中,我们可以这样编写查询:
Select
"from"
,to
,block_time
,tx_hash
,input
FROM ethereum.traces
where block_number > 17580247
and to = 0x510100D5143e011Db24E2aa38abE85d73D5B2177
通过在查询中包含block_number列,引擎可以快速缩小搜索范围,以便读取block_number大于17580247的文件和行组。这显著减少了需要读取的数据量,从而提高了查询性能。此外,仅查询你绝对需要的列也将提高查询性能。
我们还可以将相同的原则应用于连接表。例如,如果我们想要将ethereum.transactions与uniswap_v3_ethereum.Pair_evt_Swap连接,我们可以这样编写查询:
Select
to,
"from",
value,
block_date,
sqrt_price_x96,
FROM
uniswap_v3_ethereum.Pair_evt_Swap swap
inner join ethereum.transactions t
on swap.evt_tx_hash = t.hash
and swap.evt_block_number = t.block_number
where
swap.contract_address = 0x510100D5143e011Db24E2aa38abE85d73D5B2177
通过在连接条件中包含block_number列,引擎可以快速缩小搜索范围,从ethereum.transactions中包含uniswap_v3_ethereum.Pair_evt_Swap中特定行中包含的block_number的文件和行组。这显著减少了需要读取的数据量,从而提高了查询性能。
连接ethereum.transactions和uniswap_v3_ethereum.Pair_evt_Swap的顺序也很重要。下面的查询将更快:
Select
to,
"from",
value,
block_time,
sqrt_price_x96
FROM ethereum.transactions t
inner join uniswap_v3_ethereum.Pair_evt_Swap swap
on t.hash = swap.evt_tx_hash
and t.block_number = swap.evt_block_number
where
swap.contract_address = 0x510100D5143e011Db24E2aa38abE85d73D5B2177
这种连接顺序优化与表的大小有关。你应该始终将较小的表连接到较大的表上。在这种情况下,ethereum.transactions比uniswap_v3_ethereum.Pair_evt_Swap大得多,因此我们应该将uniswap_v3_ethereum.Pair_evt_Swap与ethereum.transactions连接。
内连接通常比外连接快。如果可以使用内连接而不是外连接,它将提高查询性能。
值得注意的例外情况
在使用顺序列排序列的一般规则的情况下,Solana 数据集account_activity是一个显着的例外,它是按account_keys而不是block_time排序的。这允许在基于原始 Solana 数据构建查询时利用account_keys的最小/最大值。
在 DuneSQL 上编写高效查询的额外提示
除了利用列式存储格式和使用顺序排序的列之外,在前一节中讨论的内容外,以下是更多的提示,可帮助你在 DuneSQL 上编写高效的查询:
-
限制 SELECT 子句中的列:仅请求你需要的列,因为这会减少查询引擎需要处理的数据量。
-
使用 LIMIT 子句:如果你只对特定数量的行感兴趣,请使用 LIMIT 子句,以避免处理比必要更多的数据。
-
利用分区修剪:如果你的数据已分区,请在 WHERE 子句中使用分区键,以帮助查询引擎修剪不必要的分区并减少扫描的数据量。在 Dune 中,几乎所有表都是按时间和/或块编号进行分区的。
-
尽早过滤并使用谓词下推:尽早在查询中应用过滤器,以减少正在处理的数据量。这利用了谓词下推,将过滤条件推送到存储层,减少从存储读取的数据量。
-
使用窗口函数:窗口函数可以比自连接或子查询更高效地计算与当前行相关的一组行的聚合。
-
在可能的情况下避免使用 DISTINCT:DISTINCT 可能在大型数据集上计算成本高昂。Trino 已实现了一系列 近似聚合函数,可用于以更低的计算成本获得列中不同值的良好估计。
-
使用
UNION ALL而不是UNION:如果要组合多个查询的结果,请使用UNION ALL而不是UNION,以避免删除重复行的开销。 -
谨慎使用 CTE:CTE 在引用它们的每个地方内联(它们不是预先计算的)-因此多次使用 CTE 或将 CTE 组合在 CTE 中可能导致庞大的查询计划。
-
优化数据类型:为列使用适当的数据类型,可以通过减少处理的数据量来提高查询性能。例如,
varbinary操作比varchar操作快,因为数据被压缩和编码。始终为列使用可能的最小数据类型。 -
仅在必要时排序:对结果进行排序可能计算成本高昂。如果不需要有序结果,请避免使用
ORDER BY。 -
在过滤时始终使用实际数据。不要在过滤列上使用函数:例如,如果要根据日期进行过滤,请不要使用
date_trunc('day', block_time) > '2022-01-01'。而是使用block_time > '2022-01-01'。第一个示例将无法使用block_time列的最小/最大值跳过整个 parquet 文件或文件中的行组,而扫描表时,第二个示例将能够。其他函数,如substr,lower,upper等也是如此。 -
使用
EXPLAIN命令:使用EXPLAIN命令了解查询引擎如何处理你的查询。这可以帮助你识别潜在的性能瓶颈,并相应地优化你的查询。 -
检查执行统计信息:单击“上次运行 x 秒前”以查看查询的执行统计信息。这可以帮助你识别潜在的性能瓶颈,并相应地优化你的查询。
本文由 AI 翻译,欢迎小伙伴们来校对。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
