通过 Concrete ML 加速 ML 的 FHE:超越我们之前论文的基准测试结果
- ZamaFHE
- 发布于 2024-07-24 16:22
- 阅读 2049
Zama团队使用Concrete ML加速了同态加密(FHE)在机器学习中的应用,并成功超越了之前论文中的基准测试结果。他们通过改进编译器,分离了机器学习和密码学任务,并采用了MLIR框架,支持多种硬件加速器。实验结果表明,新的Concrete ML在执行速度上有了显著提升,例如NN-20模型比2021年的结果快21倍。
加速 FHE ML
在 Zama,我们的目标不仅是让所有开发者都能访问 FHE,还要让它变得非常快。实际上,提高 FHE 的速度和效率是使其在实际应用中有用的关键。在这篇博文中,我们将向你展示我们如何通过使用 Concrete ML 使 FHE 更快,以及我们如何打破我们之前论文中的性能基准,该论文名为:“可编程引导使深度神经网络的高效同态推理成为可能”。
制作 FHE 编译器
从一开始,我们 Zama 就意识到,制作 FHE 编译器是简化用户体验并防止他们处理复杂的密码学参数和复杂设置(这对于安全性和确保计算的正确性至关重要)的关键。我们还决定,添加对各种后端(首先是 CPU,然后是 GPU / FPGA / ASIC)的支持应该是首要任务。当然,对于任何复杂的深度技术项目来说,这条路都不是一条直线。
我们最初基于 ONNX 的编译器的尝试
我们最初从一个完全基于 Python 的、构建在 ONNX 上的编译器开始。虽然这个实验没有完成,因此没有开源,但它提供了宝贵的见解。这个概念是从机器学习用户那里获取一个 ONNX 模型,并逐步修改它,使其对全同态加密(FHE)友好。最后一步是在我们的 FHE 虚拟机上生成可执行的 FHE 字节码。我们的目标是雄心勃勃的:处理用户的每个方面。
回顾我们 2021 年的隐私保护 ML 论文
在 2020 年和 2021 年,我们取得了快速进展,并成功转换了多层感知器(MLP)。我们的目标是证明,使用 TFHE(我们在 Zama 使用的密码学方案),可以处理非常深的神经网络。这非常重要,因为密码学噪声在历史上限制了密码学中神经网络的深度。我们在我们的论文中展示了这一突破,该论文名为:“可编程引导使深度神经网络的高效同态推理成为可能”。
在这篇论文中,我们使用我们基于 ONNX 的原型将 NN-20、NN-50 和 NN-100 转换为它们的 FHE 等效物,并在强大的服务器上运行它们。NN-i 模型是 CNN 神经网络,从Rollup层和 ReLU 激活开始,然后是 (i-1) 个具有 ReLU 激活的密集层,最后是一个最终的密集层。NN-20、NN-50 和 NN-100 是非常深的神经网络。我们的目标是展示 TFHE 的能力,而不是解决特定的机器学习问题,因为 MNIST 是一个相对简单的任务。
结果如下:
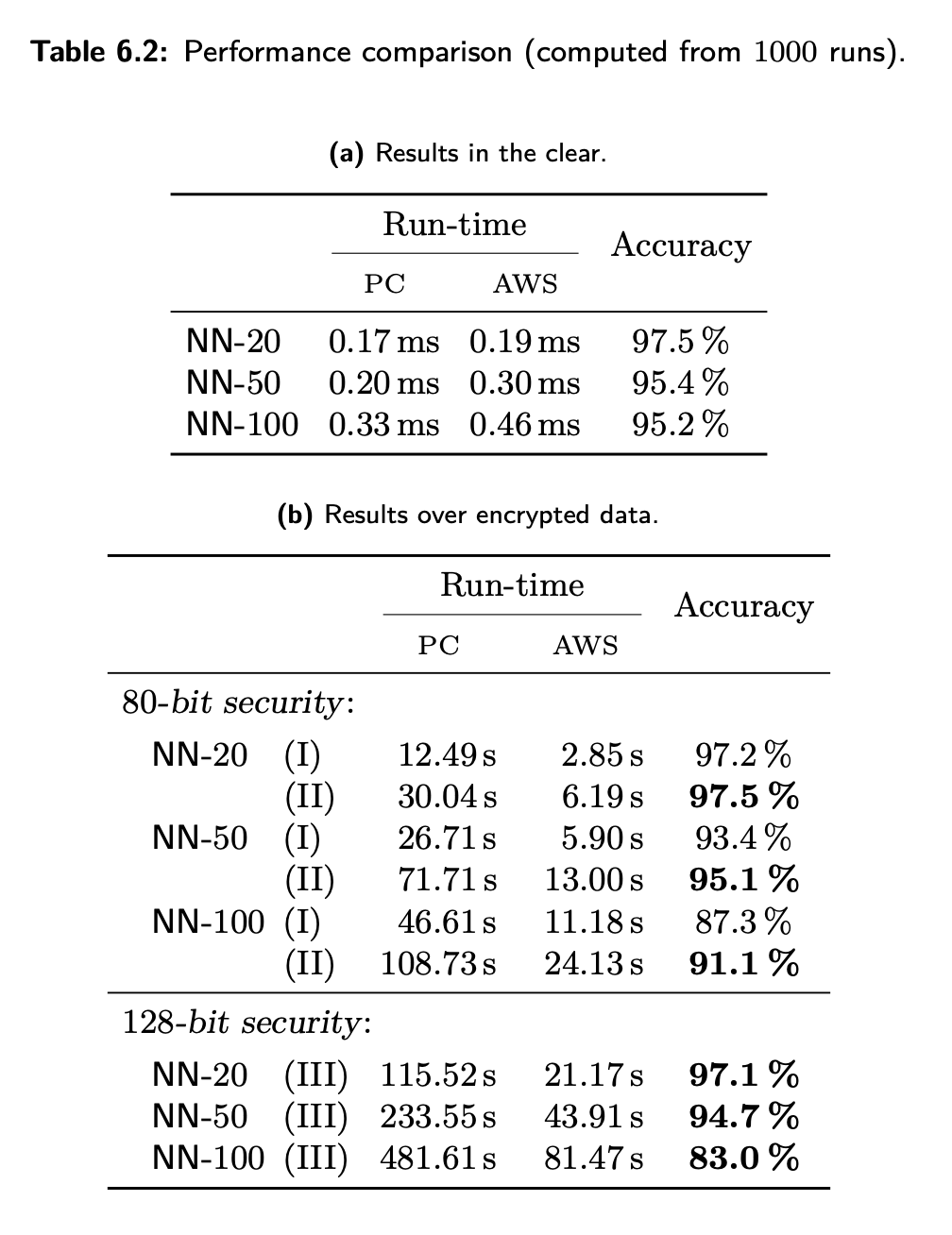
来自 Programmable Bootstrapping Enables Efficient Homomorphic Inference of Deep Neural Networks 论文的表 6.2
从手动优化到 FHE 编译器
虽然我们论文中的方法取得了良好的结果,但我们意识到,创建一个单一的编译器来同时处理机器学习任务(如量化)和密码学任务对于实际使用来说过于繁琐。有必要改变计划,将模型转换为 FHE 的不同阶段分开:
- 用户控制:用户将处理与机器学习相关的选择和任务,例如选择 FHE 兼容的层,应用剪枝,或选择适当的量化方法(例如,PTQ 或 QAT)。
- 编译器关注点:新的编译器将只关注密码学和安全性,这是我们专业知识的核心。
这个转变也是调整我们战略的正确时机。我们放弃了纯粹面向 ML 的编译器概念,转而采用更通用的编译器框架,并配有专门的前端。这些前端中的第一个将是 Concrete ML(用于机器学习)和 Concrete Python(用于经典的 Python 数学计算)。
我们用 MLIR 方法取代了我们基于 ONNX 的方法。MLIR 是编译器中使用的一个经典框架,它允许我们利用现有社区构建的传统编译器工具,并在其上分层 FHE 约束。这种转换使我们能够构建一个更强大和灵活的解决方案。
这种转变还有其他优势,例如,由于 Concrete 后端,改进了对 GPU、FPGA 和 ASIC 等硬件加速器的支持。此外,这种改变简化了我们的 Concrete 优化器,使整个系统更加高效和通用。
我们改变的影响
在我们基于 ONNX 的编译器中,我们使用了一种近似计算方法,其中明文计算被加密数据上的计算所取代,这些计算是接近但不完全精确的。使用 Concrete,我们决定只在效果良好的情况下才使用近似方法。我们还提供了工具,供用户验证不精确性对准确性的影响。
对于需要完全精确的模型,以及当近似计算不够准确时的后备方案,Concrete 提供了一种完全精确的方法。今天,通过这两种方法,我们允许高级用户根据他们的需要设置“近似”的程度。
在 Concrete 的开始,像 roundPBS 或 truncatePBS 这样的运算符(用 T′[i′] 替换表查找 T[i],其中 i′ 包含 i 的前导位)并不存在。这些运算符在机器学习的上下文中特别有价值,因为模型本质上可以抵抗这些计算简化。较短的 i′ 索引使计算速度显著加快。在我们基于 ONNX 的编译器中,由于复杂的原因,这些运算符是本地可用的。今天,它们也可以在 Concrete 中使用,并且在 Concrete ML 中被广泛使用。
由于这些变化(精确方法和最初缺少 roundPBS),在 Concrete ML 的第一个版本上重现像 NN-20 这样的实验会导致更长的执行时间。作为一个团队,我们的目标是使 Concrete 的性能超过我们的第一个编译器。我们很高兴地宣布,我们已经实现了这个里程碑,并且我们已经创建了 notebook 来向你展示这种改进。
使用 Concrete ML 复制 NN-20 和 NN-50 实验
现在,通过这个 notebook,你可以轻松地重现 NN 实验。一个 20 层的神经网络,Fp32MNIST,以通常的方式使用 Pytorch 在 MNIST 明文数据上进行训练,具有交叉熵损失。要初始化网络,只需指定层数并创建一个实例,如下所示:
fp32_mnist = Fp32MNIST(nb_layers=20)在 MNIST 上用几个 epoch 训练网络,直到收敛。为了加速 50 层模型的训练,我们首先使用先前训练的 20 层网络的权重初始化前 20 层。然后冻结这些层,只专注于训练最后 30 层。最后,我们解冻所有层并微调整个网络。
fp32_mnist = Fp32MNIST(nb_layers=50)
checkpoint = torch.load(f"MLP_20/fp32/MNIST_fp32_state_dict.pt")
del checkpoint["linears.54.weight"] # 删除最后一层分类器
del checkpoint["linears.54.bias"] # 删除最后一层分类器
for k, v in fp32_mnist.named_parameters():
if "linears.54" in k: # 在这一层停止冻结
break
v.requires_grad = False
print(f"Frozen {k}")
fp32_mnist.load_state_dict(checkpoint, strict=False)没有重现训练 NN-100 和使用此模型进行实验,因为具有如此高的深度不会提供任何准确性优势,并且训练如此深的神经网络非常耗时。但是,我们强调 Concrete ML 仍然会支持 NN-100。由于 TFHE 的引导能力,它可以支持任何深度,这可以无限期地减少噪声。
NN-20 和 NN-50 模型使用 Concrete ML 编译以在加密数据上工作,如下所示:
q_module = compile_torch_model(
fp32_mnist,
torch_inputset=data_calibration,
n_bits=6,
rounding_threshold_bits={"n_bits": 6, "method": "APPROXIMATE"},
p_error=0.1,
)量化 n_bits 设置为 6。通过 compile_toch_model 执行的后训练量化,应使用大于或等于 6 位的数值,以避免降低准确性。为了确保加密数据的最佳延迟,通过实验设置了 rounding_threshold_bits 和 p_error 值。有关更多详细信息,请参阅舍入文档和 TLU 单次误差容限文档。
新结果
我们在 hpc7a 机器上运行了实验。结果可以在下表中找到:

正如我们所看到的,NN-20 的执行时间比 2021 年我们论文中的快 21 倍,NN-50 快 14 倍。最后,我们已经达到了我们转变的每个方面都是积极的:
- 这对我们的用户来说更容易
- 我们可以从 MLIR 框架的优势中受益
- 我们可以轻松支持多个前端,从而能够编译 Python、ML 和几乎所有其他语言
- 我们可以支持各种后端,用于不同的硬件加速器。
在这种改进比率中,一部分(大约 2 倍)来自机器的改进。其余的来自:
(i) 我们在软件工程方面的努力,特别是在底层 TFHE-rs 库中
(ii) 我们在密码学方面的改进,特别是 roundPBS 运算符
(iii) ML 部分中更好的量化技术,以及 roundPBS 的有效使用
(iv) 在我们基于 MLIR 的 Concrete 中,编译的管理得到了很大改进。
附加链接
- 关注 Concrete ML Github 仓库 以支持我们的工作。
- 查看 Concrete ML 文档。
- 原文链接: zama.ai/post/making-fhe-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





