初步理解EVM
- learnerL
- 发布于 2022-02-02 23:03
- 阅读 7987
本文参考许多书籍资料,分析了 EVM 的存储空间和运行机制,对操作码进行了一定的整理,给出了参考资源,基本上涵盖了分析字节码、操作码,单步调试,观察堆栈的基础。
EVM
体系结构
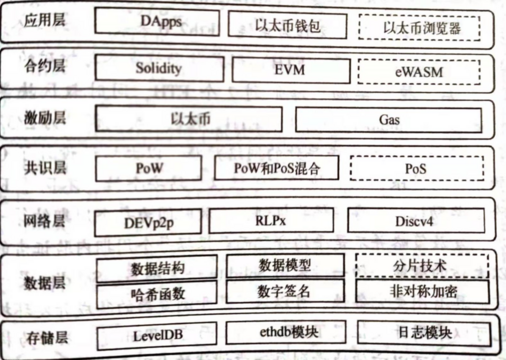
存储层
一般的客户端采用 LevelDB 数据库,而 OpenEthereum 采用了 RocksDB。LevelDB 是 Key-Value 的、基于 Log-Structured Merge Tree 的非关系数据库。例如 geth 的所有区块数据都是存储在 LevelDB 中,而 LevelDB 的实现在源代码的 ethdb 包内。
数据层
以太坊的数据层主要定义了数据结构、数据模型、哈希函数、签名算法等。以太坊采用独特的数据结构保护区块头和区块体,区块头含有交易的 Merkle 根哈希值,还有账户状态的 Merkle 根哈希值、日志的 Merkle 根哈希值。以太坊中Merkle 根哈希值是采用 Merkle Patricia Tree 计算的。哈希函数使用 keccak256,数字签名采用 ECDSA。
网络层
以太坊节点通信采用的 p2p 协议是 DEVp2p,包含了 RLPx、Discv4 等子协议。RLPx 是安全的数据传输协议,采用 ECIES([Elliptic Curve Integrated Encryption Scheme](https://cryptopp.com/wiki/Elliptic_Curve_Integrated_Encryption_Scheme)) 生成公私钥,传输用于加密数据的共享的对称密钥。Discv4 是节点发现协议,通过计算节点的举例实现节点发现。
共识层
Eth1.0 采用 Ethash PoW 共识算法,Eth2.0 现采用 Ethash PoW 和 Casper FFG 混合共识算法,其中主链采用 Ethash PoW,信标链采用 Casper FFG,在未来将完全采用 Pos 协议。
Eth1.0 的挖矿规则采用 GHOST(Greedy Heaviest-Observed Sub-Tree) 协议,未来 Eth2.0 将采用 LMD-GOHST(Latest Messafe Driven GOHST) 协议。
关于 Ethash PoW 算法的细节,可以看这篇博客。
激励层
以太坊通过以太币激励矿工,挖矿奖励。详细奖励机制可见这篇文章,可能规则有所更改,但是大体思想不变。
合约层
我自身是研究合约的,因此较为关注这一层。这一层主要关注交易和合约。交易是用户与以太坊交互的唯一途径,包含了许多的对象。合约部署前会编译生成 ABI 和字节码,字节码部署上链,ABI 规定 JSON-RPC 调用的规范。
应用层
应用层主要是采用合约的各种各样的应用,例如 DApp、钱包、链游等等。DApp 的数据交互大部分依赖于合约。
EVM 存储空间
在以太坊中,EVM 是无寄存器、基于栈的虚拟机,是合约的执行环境,任何人都可以将合约的字节码部署到 EVM,然后 EVM 作为沙盒,负责解释执行。操作系统上安装 geth 之类的区块链节点客户端,客户端维互 EVM, EVM 维护着可信的执行环境。而每台运行着客户端的计算机都算作节点,因此 EVM 可视为许多计算机构成的分布式的系统。
EVM 的存储空间有三类,stack、memory、storage。
- stack 和 memory 都是临时存储,在智能合约运行时有效,当运行结束后回收。memory 主要是临时存储数组、字符串等较大的交易时的数据,按 256 位读取,按 8 位或者 256 位读取,更加灵活;,
- 栈最多容纳 1024 个元素,以32字节为一组(也就是每个变量用 uint256 类型储存,以太坊是 256 位的虚拟机),这样可以方便地应用 256 位 Keccak 哈希计算和椭圆曲线计算。对栈的访问并不是完全严格按照 FILI(先进后出),而是一种寄存器栈,允许将顶端的16个元素种的某一个复制或者交换到栈顶。每次操作只能取栈顶的若干元素,把结果压栈。当然也能够把栈顶元素放到 memory 或者 storage 区域保存。
- storage 是永久性存储,采用映射的形式存储 uint256 的 Key 和 uint256 的 Value,因此它的操作更消耗计算资源,gas 也高得多。这样的储存空间分类,同样在 Solidity 中有所体现。
全局变量的存储方式
一般的静态类型
全局变量紧凑地存储在 storage,这样多个变量可能存储在同一个 slot (一个 solt 32 个字节) 里面。除了动态数组和映射类型,数据都是从 slot[0] 开始,连续地(如果不够32字节也不会扩充 0)存储在 slots 里。每个变量所需的字节由变量类型确定。多个变量打包在一个 slot 的规则如下:
- 这些变量所占空间之和不超过 32 字节。
- 大端存储,也就是第一个变量的存储位置在 slot 地址中最小的部分。
- 如果当前 slot 剩余空间无法容纳下一个变量,则下一个变量将存储在下一个 slot
- 结构体和数组总是分配新的 slot 给它们,其中的成员紧凑存储。
- 结构体或者数组的下一个全局变量,也往往不会与结构体或者数组在同一个 slot,而是在下一个 slot 中。
- 如果合约由继承关系,那么全局变量的存储的先后,遵循 C3 线性化顺序规则
设计思路说明:
EVM 是 32字节 为基础操作单位的虚拟机,如果元素不够 32 个字节,EVM 需要执行额外的操作,去读写这个元素,因此小于 32 个字节的元素消耗的 gas 可能会比 32 个字节的元素更多。为了优化这个问题,编译器会将多个小于 32 字节的元素,尽可能地紧凑存储在一个 slot。原本需要每个变量读取一次,变成了多个变量一起读取,即使只操作其中一个变量,也不会影响同一个 slot 的其他变量。
因此可知,全局变量的声明顺序也应当注意,uint128, uint128, uint256 的顺序会比 uint128, uint256, uint128 更好。
映射和动态数组的存储
映射和动态数组所需的空间是无法预计的,因此它们不是整个的放在某个位置,而是首先按照上面的规则占用 32 字节,然后将具体的值存储在其他的 slot,通过 keccak256 哈希来查找。(很难产生冲突的情况)
例如,假设映射类型或者动态数组占用了 slot[p],对于动态数组,slot[p] 存储元数个数(除了特殊的 byte[] 和 string);对于映射,slot[p] 为空。动态数组元素的位置将从 keccak256(p) 开始,按照上述规则排列。
对于动态数组的元素 x[i][j],假设 x 的类型是 uint24[][],那么存储它的 slot 的位置应该是 keccak256(keccak256(p)+i)+floor(j/floor(256/24)) ,也就是说递归的定义,二维动态数组先找到一维动态数组的位置,然后再哈希,找到起始元素的位置。最后,通过这个 slot 的数据 v,找到元素所在的片段 *`(v >> ((j % floor(256 / 24)) 24)) & type(uint24).max`**
对于映射类型,如果 Key 是k,那么存储值的 slot 为 keecak256(h(k)+p),其中 K 表示把 h(k) 和 p 组合成一个字符串。**h() 的定义如下
- 对于值类型,
h(k)通过填充 0 的方式,将k填充为 32 字节。 - 对于字节或者字符串类型,
h(k)直接计算k的keccak256哈希。
对于嵌套映射,按照递归定义的方式确定。详情可见文档。
bytes 和 string 的存储
bytes 和 string 是比较特殊的数组类型,它们的存储方式相同。因为它们的每个元素相当于 uint8,占用 8 位,也相当于 bytes1,因此可以把它们当作 bytes1[] 处理。
但是如果数组的元素比较少,那么就把数组元素和数组元素的个数存储在同一个 slot。例如,bytes 只有 31 字节,元素按照小端序存储,地址最小的 8 位存储length*2。
如果数组元素总共所占大小达到或者超过 32 字节,那么会在 slot[p] 存储 *`length2 + 1**,然后数据类似地存放在位置位 **keccak256(p)`** 的位置。
storage 存储结构的 JSON 表示
对于每个元素,都有个 JSON 片段表示,例如合约
contract A { uint x; }对应的 JSON 表示如下:
{
"astId": 2,
"contract": "fileA:A",
"label": "x",
"offset": 0,
"slot": "0",
"type": "t_uint256"
}astId是全局变量声明的 AST(abstract syntax tree) 节点的id。contract是合约的名称,包括其路径作为前缀。label是全局变量的名称。offset是根据编码在存储槽内以字节为单位的偏移量。slot是全局变量所在或开始的存储槽。这个数字可能非常大,被表示为一个字符串。type是一个类型标识符,来自types。
对于 types 中的每个类型 type,都包括如下属性
{
"encoding": "inplace",
"label": "uint256",
"numberOfBytes": "32",
}- encoding 表示数据在存储中的编码方式:
inplace: 数据在存储中连续排列.mapping: Keccak-256 基于映射类型的哈希的方法 .dynamic_array: Keccak-256 基于动态数组类型的哈希的方法bytes: 单槽或基于Keccak-256 bytes 类型的哈希的方法,取决于数据大小 .
label是规范的类型名称 (比如别称uint要写成规范名称uint256) 。numberOfBytes是使用的字节数(十进制字符串)。 如果numberOfBytes>32意味着使用了一个以上的 slot。
对于下面这个合约:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.4.0 <0.9.0;
contract A {
struct S {
uint128 a;
uint128 b;
uint[2] staticArray;
uint[] dynArray;
}
uint x;
uint y;
S s;
address addr;
mapping (uint => mapping (address => bool)) map;
uint[] array;
string s1;
bytes b1;
}JSON 格式的存储结构说明:
"storageLayout": {
"storage": [
{
"astId": 14,
"contract": "fileA:A",
"label": "x",
"offset": 0,
"slot": "0",
"type": "t_uint256"
},
{
"astId": 16,
"contract": "fileA:A",
"label": "y",
"offset": 0,
"slot": "1",
"type": "t_uint256"
},
{
"astId": 18,
"contract": "fileA:A",
"label": "s",
"offset": 0,
"slot": "2",
"type": "t_struct(S)12_storage"
},
{
"astId": 20,
"contract": "fileA:A",
"label": "addr",
"offset": 0,
"slot": "6",
"type": "t_address"
},
{
"astId": 26,
"contract": "fileA:A",
"label": "map",
"offset": 0,
"slot": "7",
"type": "t_mapping(t_uint256,t_mapping(t_address,t_bool))"
},
{
"astId": 29,
"contract": "fileA:A",
"label": "array",
"offset": 0,
"slot": "8",
"type": "t_array(t_uint256)dyn_storage"
},
{
"astId": 31,
"contract": "fileA:A",
"label": "s1",
"offset": 0,
"slot": "9",
"type": "t_string_storage"
},
{
"astId": 33,
"contract": "fileA:A",
"label": "b1",
"offset": 0,
"slot": "10",
"type": "t_bytes_storage"
}
],
"types": {
"t_address": {
"encoding": "inplace",
"label": "address",
"numberOfBytes": "20"
},
"t_array(t_uint256)2_storage": {
"base": "t_uint256",
"encoding": "inplace",
"label": "uint256[2]",
"numberOfBytes": "64"
},
"t_array(t_uint256)dyn_storage": {
"base": "t_uint256",
"encoding": "dynamic_array",
"label": "uint256[]",
"numberOfBytes": "32"
},
"t_bool": {
"encoding": "inplace",
"label": "bool",
"numberOfBytes": "1"
},
"t_bytes_storage": {
"encoding": "bytes",
"label": "bytes",
"numberOfBytes": "32"
},
"t_mapping(t_address,t_bool)": {
"encoding": "mapping",
"key": "t_address",
"label": "mapping(address => bool)",
"numberOfBytes": "32",
"value": "t_bool"
},
"t_mapping(t_uint256,t_mapping(t_address,t_bool))": {
"encoding": "mapping",
"key": "t_uint256",
"label": "mapping(uint256 => mapping(address => bool))",
"numberOfBytes": "32",
"value": "t_mapping(t_address,t_bool)"
},
"t_string_storage": {
"encoding": "bytes",
"label": "string",
"numberOfBytes": "32"
},
"t_struct(S)12_storage": {
"encoding": "inplace",
"label": "struct A.S",
"members": [
{
"astId": 2,
"contract": "fileA:A",
"label": "a",
"offset": 0,
"slot": "0",
"type": "t_uint128"
},
{
"astId": 4,
"contract": "fileA:A",
"label": "b",
"offset": 16,
"slot": "0",
"type": "t_uint128"
},
{
"astId": 8,
"contract": "fileA:A",
"label": "staticArray",
"offset": 0,
"slot": "1",
"type": "t_array(t_uint256)2_storage"
},
{
"astId": 11,
"contract": "fileA:A",
"label": "dynArray",
"offset": 0,
"slot": "3",
"type": "t_array(t_uint256)dyn_storage"
}
],
"numberOfBytes": "128"
},
"t_uint128": {
"encoding": "inplace",
"label": "uint128",
"numberOfBytes": "16"
},
"t_uint256": {
"encoding": "inplace",
"label": "uint256",
"numberOfBytes": "32"
}
}
}memory 的存储方式
Solidity保留了前 4 个特殊用途的32字节的 slot,内部二进制的序列的范围不同,代表的功能也不同:
0x00-0x3f(前面64 字节,占用 2 个slot): 计算哈希时临时存储数据的空间,在语句之间使用。0x40-0x5f(32 字节,占用 1 个 slot): 当前分配的内存大小 ,或者说是内存指针所在位置(因为可以通过内存空间大小计算内存指针位置)。0x60-0x7f(32 字节,占用 1 个 slot): slot[0],正式内存,用于保存动态 memory 数组的初始值,而且只读。然后下一个位置0x80是开始写入的位置。
注意:
- 执行期间,内存永远不会释放,新的将写入的对象会放在空闲内存指针上。
- memory 数组中的元素始终占据32字节的倍数(特殊的 bytes 和 string 除外)。
- 对于多维 memory 数组,它的名字实际上也是代表指向内存数组的指针。
- 对于动态数组,存储它的第一个 slot 里是它的长度,然后数组元素按顺序排列。
- 如果需要临时存储的操作需要大于 64 字节的空间,那么不会放入
0x00-0x3f的暂存空间,又考虑到临时存储的生命周期很短,因此直接在当前内存指针的下一个位置写入,但是内存指针不变,0x40-0x5f 记录的内存大小也不变,然后继续写入内存时直接覆盖。因此,在直接操作未使用的内存时,这块内存可能不是初始值。
memory 的存储方式和 storage 比较相似,但是有一些区别。例如下面的表达式,在 storage 中会紧密排列,只占 1 个 slot,而 memory 中不会紧密排列,占用 4 个 slot
uint8[4] a;calldata 的存储方式
按照 ABI 的方式编码,值得提出来的是构造函数部署时才给参数,因此它的参数的编码在最后面附上去,仍然按照 ABI 的方式编码。
清洗和优化
当一个变量类型不够占用256位时(如 uint8),而 EVM 往往是 32 字节一组读取,因此除了变量占的空间外的其它位,可能需要清洗,防止这些多余数据造成的未知的影响。
例如,在将一个变量写入 storage 时,storage 中的这一串序列可能用于计算哈希值或作为消息调用的数据,那么多余的数据可能会造成异常。
注意:
- 通过内联汇编访问变量,并不保证这一串序列已被清洗。
- 如果多余的位并不直接影响下一个操作,那么将不会进行变量的清洗。
- 压栈的时候,编译器会默认执行变量清洗。
变量清洗的规则如下:
| 类型 | 有效值 | 无效值 |
|---|---|---|
| n 个成员的枚举类型 | 0 到 n - 1 | 其他 |
| bool | 0 or 1 | 1(导致恒为 1) |
| 有符号整数 | 符号扩充的 32字节 | |
| 无符号整数 | 高位清零 |
EVM 运行机制
EVM 只能接受外部账户发送的调用请求(统称交易)或者合约账户发送的消息。结果是修改后的状态数据库和日志。日志将以 MPT 的形式组织成交易的收据树,然后将收据树的树根的哈希值记录在区块头上。
实际上,外部账户或者合约账户的操作,都将转化成 Message 对象传入 EVM,EVM 根据 Message 生成 Contract 对象。如果只是普通转账,直接修改状态数据库种的账户余额即可。如果 Message 的 data 成员不为空,那么将会根据 data 中的 ABI 编码后的序列,部署合约或者调用合约中的函数。调用合约时,EVM 将根据 Contract 对象中的 CodeAddr 获取地址,当调用合约代码的某个函数时,就会通过函数签名匹配入口和参数。,从状态数据库中加载对应字节码(包含函数选择器和函数入口),解释器根据合约字节码中的操作码执行。
EVM 的操作码占用 1 字节,最多有 256 个操作码(目前可能还没全部用上)。在解释器中,首先根据函数签名选择被被调用的函数,然后获取操作码,从 (跳转表) JumpTable 中检索对应的操作,具体调用过程由合约决定。
Gas 机制始终贯穿整个运行过程中,如果 Gas 不足,将随时执行 execute(),按照要求回滚。如果 gas 有剩余,则返还这部分给调用者。
EVM 操作码
EVM通过一组指令来执行特定任务,这组指令被称为操作码,每个操作码只占一个字节,因此目前的操作码如下:
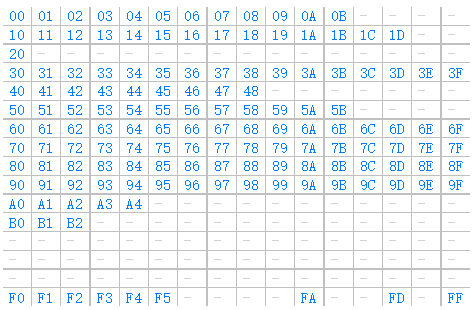
每个数字都是十六进制表示,蓝色标出的为正在使用的操作码,灰色横杠表示未被使用。具体功能可以浏览这里。每个操作码的作用都是将栈顶元素出栈,然后将结果入栈。
操作码主要分为以下:
- 栈操作相关的字节码(POP, PUSH, DUP, SWAP)
- 运算/比较/位操作相关的字节码(ADD, SUB, GT, LT, AND, OR)
- 环境相关的字节码(CALLER, CALLERVALUE, NUMBER)
- 内存操作字节码(MLOAD, MSTORE, MSTORE8, MSIZE)
- 存储操作字节码(SLOAD, SSTORE)
- 程序计数器相关的字节码(JUMP, JUMPI, PC, JUMPDEST)
- 终止相关的字节码(STOP, RETURN, REVERT, INVALID, SELFDESTRUCT)
EVM 字节码
操作码以字节码的形式存储,一串字节码会被解释为多个字节。例如 0x6001600101 会根据操作码的编码解释称如下操作:
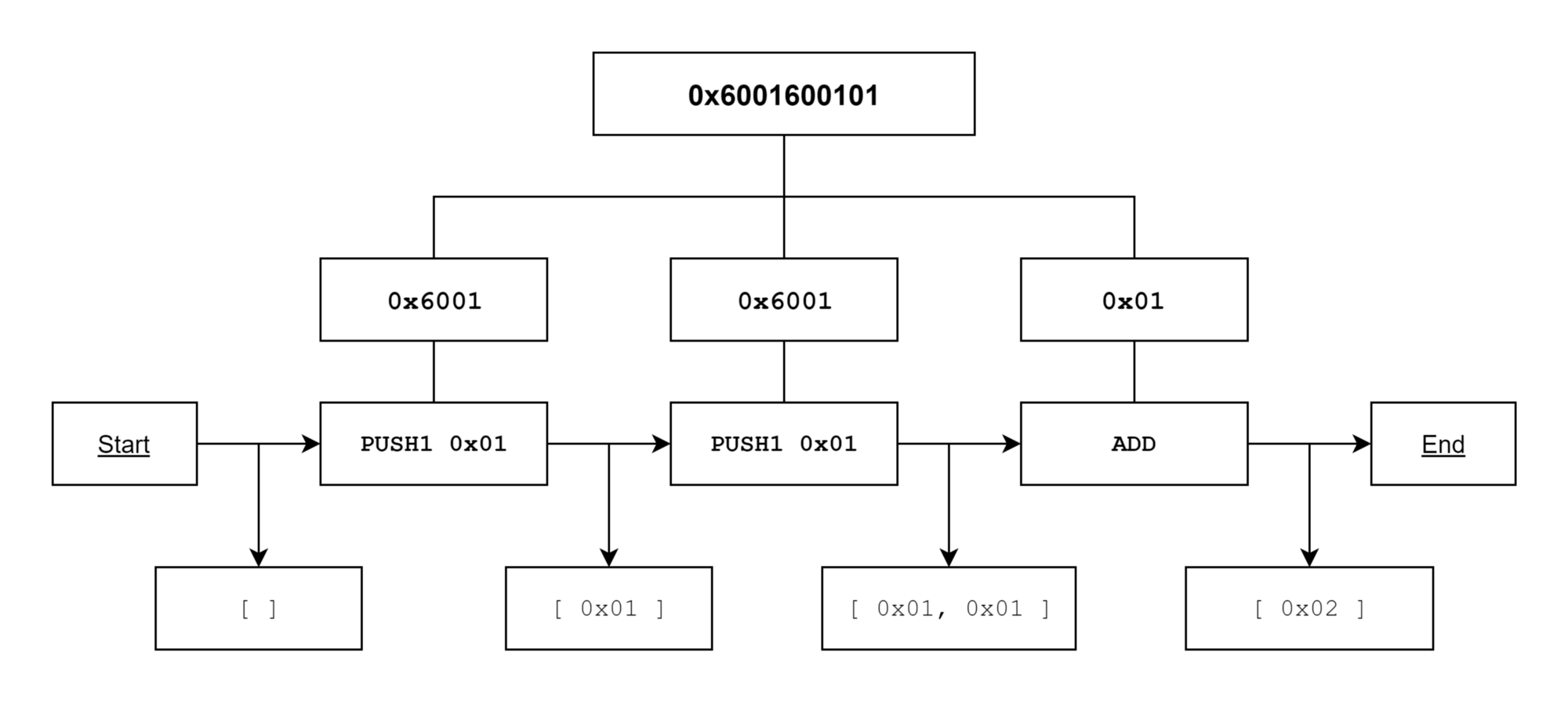
先将两个值压栈,然后加起来,结果压栈。由于一个字节的二进制范围是 [0, 127],所以操作码的范围是 [0x00,0x7f]
GAS 开销的精确计算
这是官网文档总结的 gas 开销,其中带链接的 gas 表示动态开销,计算较为复杂。我将在下面解释一些不是那么容易理解的部分。更详细的说明见这里。(表格较长,可以按住 SHIFT 滚动鼠标转轮,横向)
实际计算的话,这个工具很好用.
| 编码 | 名字 | Gas | 描述 | 操作前的栈 | 操作后的栈 | Mem / Storage | |
|---|---|---|---|---|---|---|---|
| 00 | STOP | 0 | 停止执行 | ||||
| 01 | ADD | 3 | (u)int256 加法模 2256** | a, b |
a + b |
||
| 02 | MUL | 5 | (u)int256 乘法模 2256** | a, b |
a * b |
||
| 03 | SUB | 3 | (u)int256 减法模 2256** | a, b |
a - b |
||
| 04 | DIV | 5 | uint256 除法 | a, b |
a // b |
||
| 05 | SDIV | 5 | int256 除法 | a, b |
a // b |
||
| 06 | MOD | 5 | uint256 模 | a, b |
a % b |
||
| 07 | SMOD | 5 | int256 模 | a, b |
a % b |
||
| 08 | ADDMOD | 8 | (u)int256 相加后模 N | a, b, N |
(a + b) % N |
||
| 09 | MULMOD | 8 | (u)int256 相乘后模 N | a, b, N |
(a * b) % N |
||
| 0A | EXP | A1 | uint256 幂次模 2256** | a, b |
a ** b |
||
| 0B | SIGNEXTEND | 5 | 符号扩展 x 从 (b+1) 字节 到 32 字节 |
b, x |
SIGNEXTEND(x, b) |
||
| 0C-0F | invalid | ||||||
| 10 | LT | 3 | uint256 less-than | a, b |
a < b |
||
| 11 | GT | 3 | uint256 greater-than | a, b |
a > b |
||
| 12 | SLT | 3 | int256 less-than | a, b |
a < b |
||
| 13 | SGT | 3 | int256 greater-than | a, b |
a > b |
||
| 14 | EQ | 3 | (u)int256 equality | a, b |
a == b |
||
| 15 | ISZERO | 3 | (u)int256 iszero | a |
a == 0 |
||
| 16 | AND | 3 | bitwise AND | a, b |
a && b |
||
| 17 | OR | 3 | bitwise OR | a, b |
a \|\| b |
||
| 18 | XOR | 3 | bitwise XOR | a, b |
a ^ b |
||
| 19 | NOT | 3 | bitwise NOT | a |
~a |
||
| 1A | BYTE | 3 | ith byte of (u)int256 x, from the left |
i, x |
(x >> (248 - i * 8)) && 0xFF |
||
| 1B | SHL | 3 | shift left | shift, val |
val << shift |
||
| 1C | SHR | 3 | logical shift right | shift, val |
val >> shift |
||
| 1D | SAR | 3 | arithmetic shift right (关于 logical shift 和 arithmetic shift 的差别可见这里) | shift, val |
val >> shift |
||
| 1E-1F | invalid | ||||||
| 20 | SHA3 | A2 | 对memory 序列中的一段做 keccak256 | ost, len |
keccak256(mem[ost:ost+len]) |
||
| 21-2F | invalid | ||||||
| 30 | ADDRESS | 2 | 正在执行的合约的地址 | . |
address(this) |
||
| 31 | BALANCE | A5 | balance, in wei | addr |
addr.balance |
||
| 32 | ORIGIN | 2 | address that originated the tx | . |
tx.origin |
||
| 33 | CALLER | 2 | address of msg sender | . |
msg.sender |
||
| 34 | CALLVALUE | 2 | msg value, in wei | . |
msg.value |
||
| 35 | CALLDATALOAD | 3 | 从 idx 开始读取 msg data 的32个字节 |
idx |
msg.data[idx:idx+32] |
||
| 36 | CALLDATASIZE | 2 | length of msg data, in bytes | . |
len(msg.data) |
||
| 37 | CALLDATACOPY | A3 | 将msg.data[ost, ost+len] 复制到栈顶 | dstOst, ost, len |
. |
mem[dstOst:dstOst+len] := msg.data[ost:ost+len | |
| 38 | CODESIZE | 2 | length of executing contract's code(字节码), in bytes | . |
len(this.code) |
||
| 39 | CODECOPY | A3 | mem[dstOst:dstOst+len] := this.code[ost:ost+len] | dstOst, ost, len |
. |
copy executing contract's bytecode | |
| 3A | GASPRICE | 2 | gas price of tx, in wei per unit gas ** | . |
tx.gasprice |
||
| 3B | EXTCODESIZE | A5 | size of code at addr, in bytes | addr |
len(addr.code) |
||
| 3C | EXTCODECOPY | A4 | copy code from addr |
addr, dstOst, ost, len |
. |
mem[dstOst:dstOst+len] := addr.code[ost:ost+len] | |
| 3D | RETURNDATASIZE | 2 | size of returned data from last external call, in bytes | . |
size |
||
| 3E | RETURNDATACOPY | A3 | copy returned data from last external call | dstOst, ost, len |
. |
mem[dstOst:dstOst+len] := returndata[ost:ost+len] | |
| 3F | EXTCODEHASH | A5 | hash = addr.exists ? keccak256(addr.code) : 0 | addr |
hash |
||
| 40 | BLOCKHASH | 20 | 将区块高度哈希 | blockNum |
blockHash(blockNum) |
||
| 41 | COINBASE | 2 | address of miner of current block | . |
block.coinbase |
||
| 42 | TIMESTAMP | 2 | timestamp of current block | . |
block.timestamp |
||
| 43 | NUMBER | 2 | number of current block | . |
block.number |
||
| 44 | DIFFICULTY | 2 | difficulty of current block | . |
block.difficulty |
||
| 45 | GASLIMIT | 2 | gas limit of current block | . |
block.gaslimit |
||
| 46 | CHAINID | 2 | push current chain id onto stack | . |
chain_id |
||
| 47 | SELFBALANCE | 5 | balance of executing contract, in wei | . |
address(this).balance |
||
| 48 | BASEFEE | 2 | base fee of current block | . |
block.basefee |
||
| 49-4F | invalid | ||||||
| 50 | POP | 2 | remove item from top of stack and discard it | _anon |
. |
||
| 51 | MLOAD | 3***** | read word from memory at offset ost |
ost |
mem[ost:ost+32] |
||
| 52 | MSTORE | 3***** | write a word(指 32 字节) to memory | ost, val |
. |
mem[ost:ost+32] := val | |
| 53 | MSTORE8 | 3***** | write a single byte to memory | ost, val |
. |
mem[ost] := val && 0xFF | |
| 54 | SLOAD | A6 | read word from storage(注意 storage 每个元素是 uint256 到 uint256 的键值对存储) | key |
storage[key] |
||
| 55 | SSTORE | A7 | write word to storage | key, val |
. |
storage[key] := val | |
| 56 | JUMP | 8 | $pc := dst 当 dst 是有效的跳转目标时,pc 会被赋值。pc的含义具体见 0x58 操作码 |
dst |
. |
||
| 57 | JUMPI | 10 | $pc := condition ? dst : $pc + 1 当条件为真时, pc 为 dst 处内容,否则 pc 为当前位置的下一个位置的内容。 |
dst, condition |
. |
||
| 58 | PC | 2 | 程序计数器,用于指定当前读取字节码的字段。比如可以通过 JUMP 跳转到需要执行的函数。 | . |
$pc |
||
| 59 | MSIZE | 2 | size of memory in current execution context, in bytes | . |
len(mem) |
||
| 5A | GAS | 2 | 获取此刻可用的 gas | . |
gasRemaining |
||
| 5B | JUMPDEST | 1 | 返回一个当前有效的跳转目标 | mark valid jump destination | |||
| 5C-5F | invalid | ||||||
| 60 | PUSH1 | 3 | push 1-byte value onto stack | . |
uint8 |
||
| 61 | PUSH2 | 3 | push 2-byte value onto stack | . |
uint16 |
||
| 62 | PUSH3 | 3 | push 3-byte value onto stack | . |
uint24 |
||
| 63 | PUSH4 | 3 | push 4-byte value onto stack | . |
uint32 |
||
| 64 | PUSH5 | 3 | push 5-byte value onto stack | . |
uint40 |
||
| 65 | PUSH6 | 3 | push 6-byte value onto stack | . |
uint48 |
||
| 66 | PUSH7 | 3 | push 7-byte value onto stack | . |
uint56 |
||
| 67 | PUSH8 | 3 | push 8-byte value onto stack | . |
uint64 |
||
| 68 | PUSH9 | 3 | push 9-byte value onto stack | . |
uint72 |
||
| 69 | PUSH10 | 3 | push 10-byte value onto stack | . |
uint80 |
||
| 6A | PUSH11 | 3 | push 11-byte value onto stack | . |
uint88 |
||
| 6B | PUSH12 | 3 | push 12-byte value onto stack | . |
uint96 |
||
| 6C | PUSH13 | 3 | push 13-byte value onto stack | . |
uint104 |
||
| 6D | PUSH14 | 3 | push 14-byte value onto stack | . |
uint112 |
||
| 6E | PUSH15 | 3 | push 15-byte value onto stack | . |
uint120 |
||
| 6F | PUSH16 | 3 | push 16-byte value onto stack | . |
uint128 |
||
| 70 | PUSH17 | 3 | push 17-byte value onto stack | . |
uint136 |
||
| 71 | PUSH18 | 3 | push 18-byte value onto stack | . |
uint144 |
||
| 72 | PUSH19 | 3 | push 19-byte value onto stack | . |
uint152 |
||
| 73 | PUSH20 | 3 | push 20-byte value onto stack | . |
uint160 |
||
| 74 | PUSH21 | 3 | push 21-byte value onto stack | . |
uint168 |
||
| 75 | PUSH22 | 3 | push 22-byte value onto stack | . |
uint176 |
||
| 76 | PUSH23 | 3 | push 23-byte value onto stack | . |
uint184 |
||
| 77 | PUSH24 | 3 | push 24-byte value onto stack | . |
uint192 |
||
| 78 | PUSH25 | 3 | push 25-byte value onto stack | . |
uint200 |
||
| 79 | PUSH26 | 3 | push 26-byte value onto stack | . |
uint208 |
||
| 7A | PUSH27 | 3 | push 27-byte value onto stack | . |
uint216 |
||
| 7B | PUSH28 | 3 | push 28-byte value onto stack | . |
uint224 |
||
| 7C | PUSH29 | 3 | push 29-byte value onto stack | . |
uint232 |
||
| 7D | PUSH30 | 3 | push 30-byte value onto stack | . |
uint240 |
||
| 7E | PUSH31 | 3 | push 31-byte value onto stack | . |
uint248 |
||
| 7F | PUSH32 | 3 | push 32-byte value onto stack | . |
uint256 |
||
| 80 | DUP1 | 3 | clone 1st value on stack | a |
a, a |
||
| 81 | DUP2 | 3 | clone 2nd value on stack | _, a |
a, _, a |
||
| 82 | DUP3 | 3 | clone 3rd value on stack | _, _, a |
a, _, _, a |
||
| 83 | DUP4 | 3 | clone 4th value on stack | _, _, _, a |
a, _, _, _, a |
||
| 84 | DUP5 | 3 | clone 5th value on stack | ..., a |
a, ..., a |
||
| 85 | DUP6 | 3 | clone 6th value on stack | ..., a |
a, ..., a |
||
| 86 | DUP7 | 3 | clone 7th value on stack | ..., a |
a, ..., a |
||
| 87 | DUP8 | 3 | clone 8th value on stack | ..., a |
a, ..., a |
||
| 88 | DUP9 | 3 | clone 9th value on stack | ..., a |
a, ..., a |
||
| 89 | DUP10 | 3 | clone 10th value on stack | ..., a |
a, ..., a |
||
| 8A | DUP11 | 3 | clone 11th value on stack | ..., a |
a, ..., a |
||
| 8B | DUP12 | 3 | clone 12th value on stack | ..., a |
a, ..., a |
||
| 8C | DUP13 | 3 | clone 13th value on stack | ..., a |
a, ..., a |
||
| 8D | DUP14 | 3 | clone 14th value on stack | ..., a |
a, ..., a |
||
| 8E | DUP15 | 3 | clone 15th value on stack | ..., a |
a, ..., a |
||
| 8F | DUP16 | 3 | clone 16th value on stack | ..., a |
a, ..., a |
||
| 90 | SWAP1 | 3 | 交换栈顶元素(下标为 0)与下标为 1 的元素 | a, b |
b, a |
||
| 91 | SWAP2 | 3 | 交换栈顶元素与下标为 2 的元素 | a, _, b |
b, _, a |
||
| 92 | SWAP3 | 3 | a, _, _, b |
b, _, _, a |
|||
| 93 | SWAP4 | 3 | a, _, _, _, b |
b, _, _, _, a |
|||
| 94 | SWAP5 | 3 | a, ..., b |
b, ..., a |
|||
| 95 | SWAP6 | 3 | a, ..., b |
b, ..., a |
|||
| 96 | SWAP7 | 3 | a, ..., b |
b, ..., a |
|||
| 97 | SWAP8 | 3 | a, ..., b |
b, ..., a |
|||
| 98 | SWAP9 | 3 | a, ..., b |
b, ..., a |
|||
| 99 | SWAP10 | 3 | a, ..., b |
b, ..., a |
|||
| 9A | SWAP11 | 3 | a, ..., b |
b, ..., a |
|||
| 9B | SWAP12 | 3 | a, ..., b |
b, ..., a |
|||
| 9C | SWAP13 | 3 | a, ..., b |
b, ..., a |
|||
| 9D | SWAP14 | 3 | a, ..., b |
b, ..., a |
|||
| 9E | SWAP15 | 3 | a, ..., b |
b, ..., a |
|||
| 9F | SWAP16 | 3 | a, ..., b |
b, ..., a |
|||
| A0 | LOG0 | A8 | LOG0(memory[ost:ost+len]) 将内存中存 ost 开始的 len 个字节写入日志 |
ost, len |
. |
||
| A1 | LOG1 | A8 | LOG1(memory[ost:ost+len], topic0) 将内存中从 ost 开始的 len 个字节写入日志,同时生成 1 个可检索的 topic 结构 |
ost, len, topic0 |
. |
||
| A2 | LOG2 | A8 | LOG1(memory[ost:ost+len], topic0, topic1) 将内存中从 ost 开始的 len 个字节写入日志,同时生成 2 个可检索的 topic 结构 |
ost, len, topic0, topic1 |
. |
||
| A3 | LOG3 | A8 | LOG1(memory[ost:ost+len], topic0, topic1, topic2) 将内存中从 ost 开始的 len 个字节写入日志,同时生成 3 个可检索的 topic 结构 |
ost, len, topic0, topic1, topic2 |
. |
||
| A4 | LOG4 | A8 | LOG1(memory[ost:ost+len], topic0, topic1, topic2, topic3) 将内存中从 ost 开始的 len 个字节写入日志,同时生成 4 个可检索的 topic 结构 |
ost, len, topic0, topic1, topic2, topic3 |
. |
||
| A5-EF | invalid | ||||||
| F0 | CREATE | A9 | addr = keccak256(rlp([address(this), this.nonce])) 创建合约账户,传入 发送的以太币 (wei),读取内存的 ost 开始的 len 个字节 |
val, ost, len |
addr |
||
| F1 | CALL | AA | gas: 给调用的函数分配的 gas, 现在版本最多为当前剩余 gas 的 1/64. addr: 被调用的账户的地址. val: 发送过去的以太币 (wei) argOst, argLen: 复制 calldata 中 [argOst, argOst+argLen] 的内容. retOst、 retLen: 粘贴到 memory 中 [retOst, retLen] 的部分。 |
gas, addr, val, argOst, argLen, retOst, retLen |
success |
mem[retOst:retOst+retLen] := returndata | |
| F2 | CALLCODE | AA | 与 DELEGATECALL 类似,但是不会传递初始的 msg.sender 和 msg.value | gas, addr, val, argOst, argLen, retOst, retLen |
success |
mem[retOst:retOst+retLen] = returndata | |
| F3 | RETURN | 0***** | return mem[ost:ost+len] | ost, len |
. |
||
| F4 | DELEGATECALL | AA | 类似于 call,但是上下文被调用者替换。 | gas, addr, argOst, argLen, retOst, retLen |
success |
mem[retOst:retOst+retLen] := returndata | |
| F5 | CREATE2 | A9 | addr = keccak256(0xff ++ address(this) ++ salt ++ keccak256(mem[ost:ost+len]))[12:] 为了防止生成合约地址被恶意预测,可以在创建时加 solt,在新的地址上部署合约 | val, ost, len, salt |
addr |
||
| F6-F9 | invalid | ||||||
| FA | STATICCALL | AA | 不改变状态的 call | gas, addr, argOst, argLen, retOst, retLen |
success |
mem[retOst:retOst+retLen] := returndata | |
| FB-FC | invalid | ||||||
| FD | REVERT | 0***** | 停止当前上下文的调用,并且回滚当前调用的状态改变,栈顶压栈 0,并且返回内存中的 revert(mem[ost:ost+len]) | ost, len |
. |
||
| FE | INVALID | AF | 无效操作,会发挥 REVERT 的作用,但是消耗所有当前上下文的可用 gas | designated invalid opcode - EIP-141 | |||
| FF | SELFDESTRUCT | AB | 自毁,余额强制返回给 addr |
addr |





