零知识证明 - DIZK源代码导读
- Star Li
- 发布于 2020-02-14 12:50
- 阅读 5669
DIZK源代码导读
在理解了DIZK的基本原理后:零知识证明 - DIZK介绍。
对DIZK感兴趣的小伙伴可以看看DIZK的源代码:
https://github.com/scipr-lab/dizk
DIZK的更新比较少,最后一个patch也是2018年底了:
commit 81d72a3406e2500561551cbf4d651f230146bb92
Merge: e98dd9c 7afd0be
Author: Howard Wu <howardwu@berkeley.edu>
Date: Wed Dec 12 11:17:57 2018 -0800
Merge pull request #6 from gnosis/profiler_error
#5 - Throw Error when profiler has wrong APP parameter.01 源代码结构
DIZK是在Spark框架上,用java语言实现的分布式零知识证明系统。源代码的结构如下:
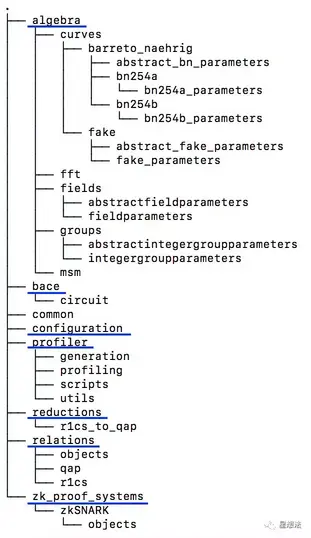
algebra - 各种计算:椭圆曲线,域/群,FFT以及多倍点(fixedMSM和VarMSM)。
bace - batch证明的相关实现。
relations - 电路的表示:r1cs以及QAP。
reductions - 实现r1cs到QAP的转化。
zk_proof_systems - Groth16证明系统
profiler - 性能测试逻辑
熟悉libsnark的小伙伴,对这些术语应该感到比较亲切。
02 DistributedSetup
DistributedSetup实现了分布式的Setup逻辑:
main/java/zk_proof_systems/zkSNARK/DistributedSetup.java
generate函数实现了Pk/Vk的生成。
public static <FieldT extends AbstractFieldElementExpanded<FieldT>,
G1T extends AbstractG1<G1T>,
G2T extends AbstractG2<G2T>,
GTT extends AbstractGT<GTT>,
PairingT extends AbstractPairing<G1T, G2T, GTT>>
CRS<FieldT, G1T, G2T, GTT> generate(
final R1CSRelationRDD<FieldT> r1cs,
final FieldT fieldFactory,
final G1T g1Factory,
final G2T g2Factory,
final PairingT pairing,
final Configuration config) {2.1 QAP转化
final QAPRelationRDD<FieldT> qap = R1CStoQAPRDD.R1CStoQAPRelation(r1cs, t, config);注意,QAP用QAPRelationRDD类表示。
2.2 计算deltaABC/gammaABC
final JavaPairRDD<Long, FieldT> betaAt = qap.At().mapValues(a -> a.mul(beta));
final JavaPairRDD<Long, FieldT> alphaBt = qap.Bt().mapValues(b -> b.mul(alpha));
final JavaPairRDD<Long, FieldT> ABC = betaAt.union(alphaBt).union(qap.Ct())
.reduceByKey(FieldT::add).persist(config.storageLevel());
final JavaPairRDD<Long, FieldT> gammaABC = ABC.filter(e -> e._1 < numInputs)
.mapValues(e -> e.mul(inverseGamma));
final JavaPairRDD<Long, FieldT> deltaABC = ABC.filter(e -> e._1 >= numInputs)
.mapValues(e -> e.mul(inverseDelta));2.3 计算At/Bt的密集度
final long numNonZeroAt = qap.At().filter(e -> !e._2.isZero()).count();
final long numNonZeroBt = qap.Bt().filter(e -> !e._2.isZero()).count();2.4 计算FixedMSM(G1/G2)
final G1T generatorG1 = g1Factory.random(config.seed(), config.secureSeed());
final int scalarSizeG1 = generatorG1.bitSize();
final long scalarCountG1 = numNonZeroAt + numNonZeroBt + numVariables;
final int windowSizeG1 = FixedBaseMSM.getWindowSize(scalarCountG1 / numPartitions, generatorG1);
final List<List<G1T>> windowTableG1 = FixedBaseMSM
.getWindowTable(generatorG1, scalarSizeG1, windowSizeG1);以上是G1的MSM的计算(G2类似),注意windowSizeG1,是所有的“非零”系数的个数除以Partition的个数。
2.5 生成CRS(Pk/Vk)
final ProvingKeyRDD<FieldT, G1T, G2T> provingKey = new ProvingKeyRDD<>(
alphaG1,
betaG1,
betaG2,
deltaG1,
deltaG2,
deltaABCG1,
queryA,
queryB,
queryH,
r1cs);
final VerificationKey<G1T, G2T, GTT> verificationKey = new VerificationKey<>(
alphaG1betaG2,
gammaG2,
deltaG2,
UVWGammaG1);注意:Pk使用RDD(ProvingKeyRDD)表示。
03 DistributedProver
DistributedProver实现了分布式的Prover逻辑:
main/java/zk_proof_systems/zkSNARK/DistributedProver.java
prove函数实现了证明生成逻辑。
public static <FieldT extends AbstractFieldElementExpanded<FieldT>, G1T extends
AbstractG1<G1T>, G2T extends AbstractG2<G2T>>
Proof<G1T, G2T> prove(3.1 生成witness
final QAPWitnessRDD<FieldT> qapWitness = R1CStoQAPRDD .R1CStoQAPWitness(provingKey.r1cs(), primary, oneFullAssignment, fieldFactory, config);QAPWitnessRDD定义在main/java/relations/qap/QAPWitnessRDD.java,包括输入信息以及H多项式系数(FFT计算获得)。
3.2 产生随机数
final FieldT r = fieldFactory.random(config.seed(), config.secureSeed());
final FieldT s = fieldFactory.random(config.seed(), config.secureSeed());3.3 计算Evaluation
final JavaRDD<Tuple2<FieldT, G1T>> computationA = style="box-sizing: border-box; padding-right: 0.1px;"> .join(provingKey.queryA(), numPartitions).values();
final G1T evaluationAt = VariableBaseMSM.distributedMSM(computationA);通过VariableBaseMSM计算A/B/deltaABC以及H的Evaluation。
3.4 生成证明
// A = alpha + sum_i(a_i*A_i(t)) + r*delta
final G1T A = alphaG1.add(evaluationAt).add(deltaG1.mul(r));
// B = beta + sum_i(a_i*B_i(t)) + s*delta
final Tuple2<G1T, G2T> B = new Tuple2<>(
betaG1.add(evaluationBt._1).add(deltaG1.mul(s)),
betaG2.add(evaluationBt._2).add(deltaG2.mul(s)));
// C = sum_i(a_i*((beta*A_i(t) + alpha*B_i(t) + C_i(t)) + H(t)*Z(t))/delta) + A*s + r*b - r*s*delta
final G1T C = evaluationABC.add(A.mul(s)).add(B._1.mul(r)).sub(rsDelta);04 Profiling
main/java/profiler/Profiler.java是性能测试的入口类,提供了各种算子的性能测试能力,包括分布式和单机版本。在scripts目录下也提供了Spark运行的脚本。默认,DIZK是使用Amazon的EC2机器进行测试的。
./spark-ec2/copy-dir /home/ec2-user/
export JAVA_HOME="/usr/lib/jvm/java-1.8.0"
for TOTAL_CORES in 8; do
for SIZE in `seq 15 25`; do
export APP=dizk-large
export MEMORY=16G
export MULTIPLIER=2
export CORES=1
export NUM_EXECUTORS=$((TOTAL_CORES / CORES))
export NUM_PARTITIONS=$((TOTAL_CORES * MULTIPLIER))
/root/spark/bin/spark-submit \
--conf spark.driver.memory=$MEMORY \
...
--class "profiler.Profiler" \
/home/ec2-user/dizk-1.0.jar $NUM_EXECUTORS $CORES $MEMORY $APP $SIZE $NUM_PARTITIONS
done
done感兴趣的小伙伴,可以自己改一下脚本,在本地环境运行DIZK。
总结:
DIZK,是在Spark大数据计算框架下的分布式零知识证明系统。DIZK的代码比较清晰,注释也比较完整。DistributedSetup和DistributedProver是Setup和Prover的实现。DIZK提供了完整的Profiling的代码。
我是Star Li,我的公众号星想法有很多原创高质量文章,欢迎大家扫码关注。






