区块链基本知识入门(技术向)
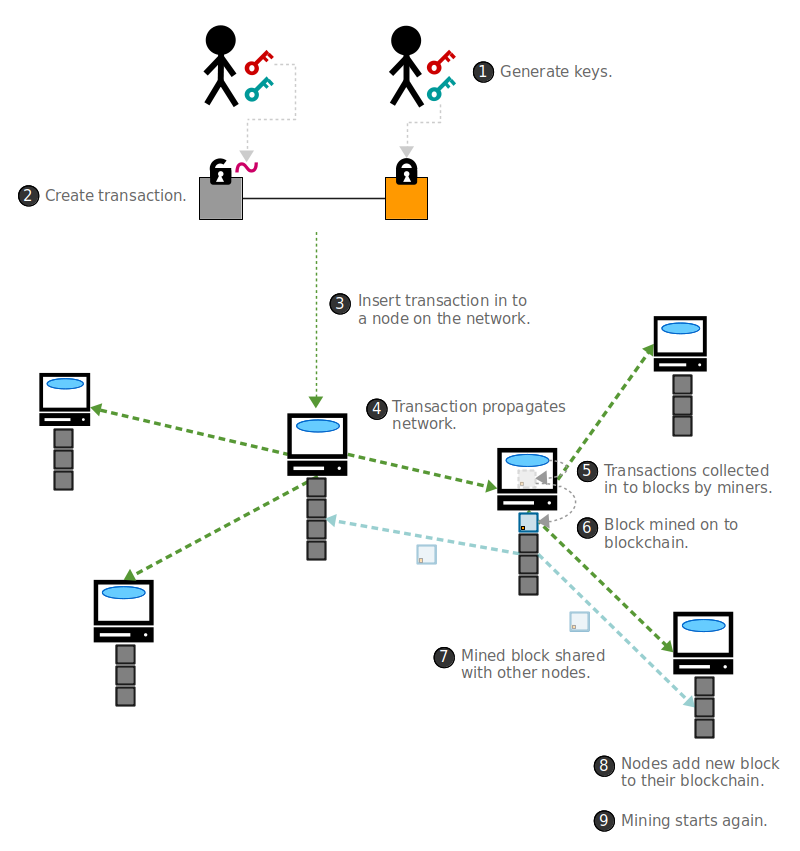
较为详尽的介绍了比特币的专业知识,非常适合入门者,了解到区块链是什么、如何运行。
区块链简介
区块链1.0(基于比特币的说明)——基本认知
指的是一个不可篡改的,分布式,去中心化账本,没有谁是中央登记员,因为大家都是中央登记员,大家的账本写的东西都一模一样,记着大家所有人的资产信息。(这大概是我们对它的基本认知)
区块链记账,会把上一次交易的账页信息(交易序号,记账(交易)时间,交易记录)作为原始信息,hash之后的值与本次的账页信息结合在一起,就成了一个区块;(这个数据结构类似于链表——简单地说,既能够存储来自上一个节点的数据,也能够连接下一个节点)
继续推导,下一个区块也会包含本次交易的账页信息hash值,和下一次交易的账页信息,这样一来,每一个区块都包含着上一次的账页信息,根据hash算法的雪崩效益以及不可逆向递推性质,从而达到区块链本身设计之初要达到的:不可篡改性
当一个区块更新之后,这个区块会把本次交易的所有信息,通过互联网同步给每一个在区块链之中的区块,每个区块在短时间内同步账本,使得区块链中所有区块的账本一致,就达到了区块链设计之初的:不可抵赖性
看下面的一个区块的完整信息示例:
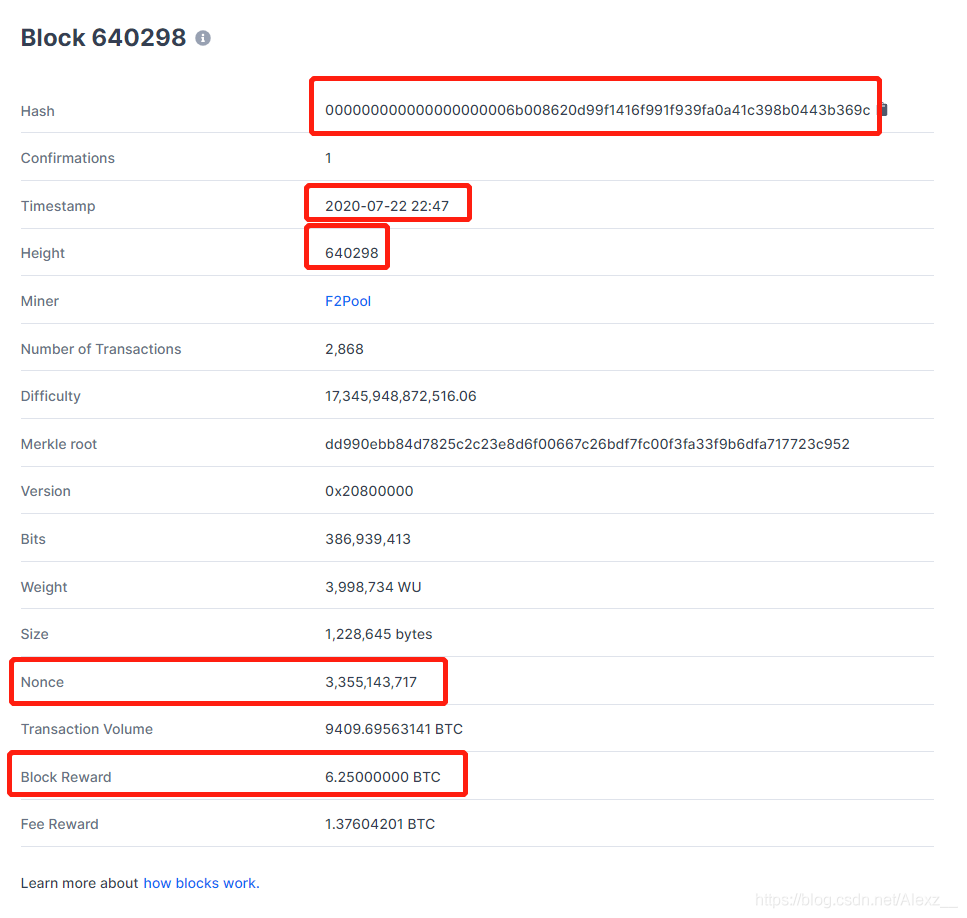
- 本区块的hash值;(第一个圈起来的)
- 记账时间戳
- 区块高度(第640298个区块)
- 随机数
本次奖励的比特币(这是第三个210000个区块,所以奖励是50/2/2/2=6.25bitcoin)
比特币运行概述
比特币是2009年创建的电子支付系统。你可以通过它向世界上任何人汇款,而无需中央机构来发行帐户或处理付款。(比如传统的金融汇款需要双方使用同平台的账户,所有的交易由平台的系统来控制。想一想支付宝和微信支付)
突然,有人不想所有的金融服务都是由少数大型银行来控制,因为这不公平,银行可以用别人的钱来制造泡沫,本来没有许多本金,却用着别人的几千亿来为自己牟利,而且一旦危机来临,急速贬值,甚至不能兑换。
这就造成了对金钱的绝对控制,并迫使用户必须信任银行。

而且在2007年,这种滥用的、被迫的信任造成了金融危机,刺激了没有中心化管理的比特币的产生。下面是中本聪首次在社区中提出比特币的帖子:


大概说他弄出了一个基于点对点的电子金融系统,下面是客户端的链接,快下载来看看呀。
(交易成本)接着说现有金融系统的弊病,因为是被人统一管理的,用户不得不相信自己的钱不会被窃取,中心会保护好我们的隐私。而且,传统支付以及PayPal在处理小额支付的时候成本很高(想一想银行系统里由多少员工。。PayPal基于传统的银行系统,它需要从银行调取信息,然后返回。不过支付宝和微信(Alipay,WeChat采用自己的体系,分别利用贸易平台优势和用户群体优势,使得小额支付的成本很低)。
(个人资产的绝对保护)然后进一步说当时的情况,个人信息(包括资产等)都是给账户设置密码来完成的。但是,出于管理者的顾虑或者是更高权力部门的要求,个人数据的不到保护。现密码学足够发达了,我们要改变这一状况,让其他的人完全不可能有权访问我们的账户,不论是出于什么原因、什么更好的理由、什么其他事情。他提出了无需信任中间人的基于密码证明的成本很低交易方式,以解决这个问题。
(原理浅析)接着说身份认证的过程(我来稍微详细的解释一下).....................但是提出了一个问题:如何防止再次花费。最后说想出了解决方案,利用信息易于传播但是难以扼杀(stifle)的特性。
最后提到了点对点(P2P)直接交易的的方式。
下面是他当年发表的论文(我也打包放在一起了):https://bitcoin.org/bitcoin.pdf
P2P
一般被称为点对点网络或者对等网络。因为在P2P网络环境中,彼此连接的多台计算机之间都处于对等的地位,各台计算机有相同的功能,无主从之分,一台计算机既可作为服务器,也可以作为工作站。这和传统的Client/Server模式很不一样。
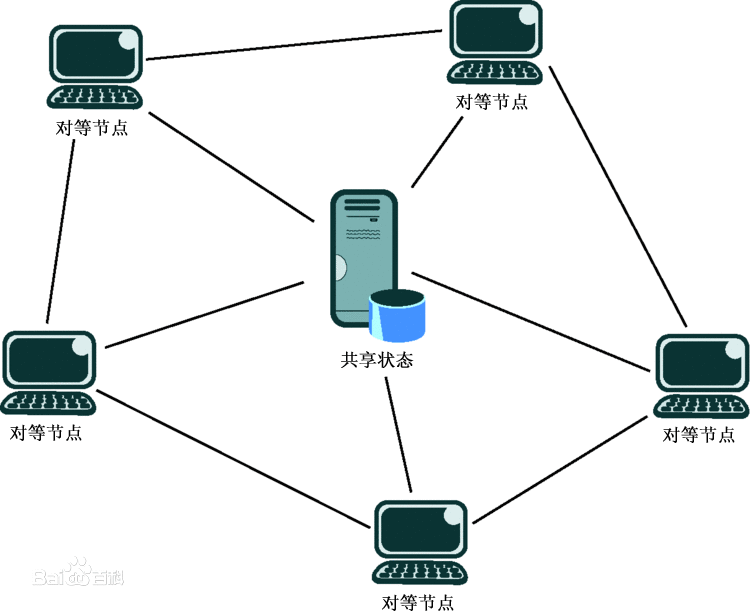
特点
- 直接交互 P2P就是直接将人们联系起来,让人们通过互联网直接交互。P2P使得网络上的沟通变得容易、更直接共享和交互,真正地消除中间商。
- 去中心化 P2P另一个重要特点是改变互联网现在的以太网站为中心的状态、重返“非中心化”,并把权力交还给用户。
- 性能拓展
对等网络是对分布式概念的成功拓展,它将传统方式下的服务器负担分配到网络中的每一节点上,每一节点都将承担有限的存储与计算任务,加入到网络中的节点越多,节点贡献的资源也就越多,其服务质量也就越高。 (特别是近几年个人计算机的运行、储存等能力大大提升,给这种“人海战术”创造了优势):在传统的通过FTP的文件下载方式中,当下载用户增加之后,下载速度会变得越来越慢,然而P2P网络正好相反,加入的用户越多,P2P网络中提供的资源就越多,下载的速度反而越快。
- 鲁棒性(Robust)
鲁棒性也叫做健壮性,指出现参数变动时性能不变的能力。P2P架构天生具有耐攻击、高容错的优点。由于服务是分散在各个节点之间进行的,部分节点或网络遭到破坏对其它部分的影响很小。P2P网络一般在部分节点失效时能够自动调整整体拓扑(节点的排列方式),保持其它节点的连通性。P2P网络通常都是以自组织的方式建立起来的,并允许节点自由地加入和离开。
- 隐私保护
在P2P网络中,由于信息的传输分散在各节点之间进行而无需经过某个集中环节,用户的隐私信息被窃听和泄漏的可能性大大缩小。在P2P中,所有参与者都可以提供中继转发的功能,因而大大提高了匿名通讯的灵活性和可靠性,能够为用户提供更好的隐私保护。
区块链的许多性质和P2P非常相似,因为区块链提出的时候时用P2P的计算机网络。
Digital Signatures
由私钥产生的能证明拥有它的公钥的数字,只需要能证明你知道公钥所对应的私钥即可,而不需要出示私钥。

因为必须由正确的私钥才能产生正确的数字签名,所以使用数字签名就可以证明自己的身份。
为什么需要使用数字签名?
当进行一次交易的时候,需要解锁地址(address,可以视为账户)对应的Outputs.
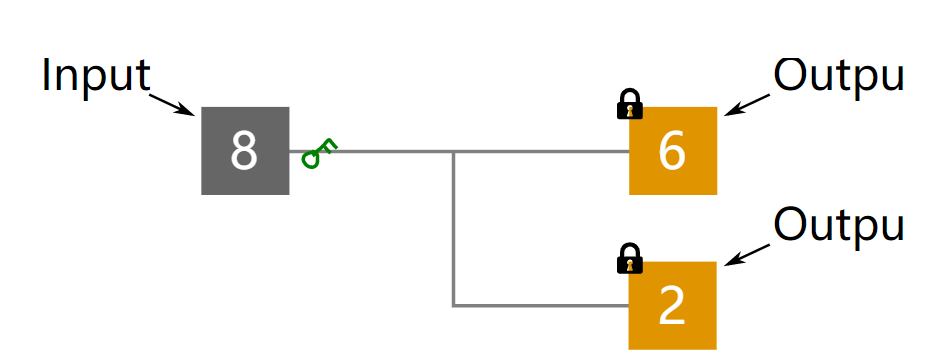
如果直接使用私钥的话所有的人都能知道,其他人就能解锁其他的Outputs来花我们的钱了。
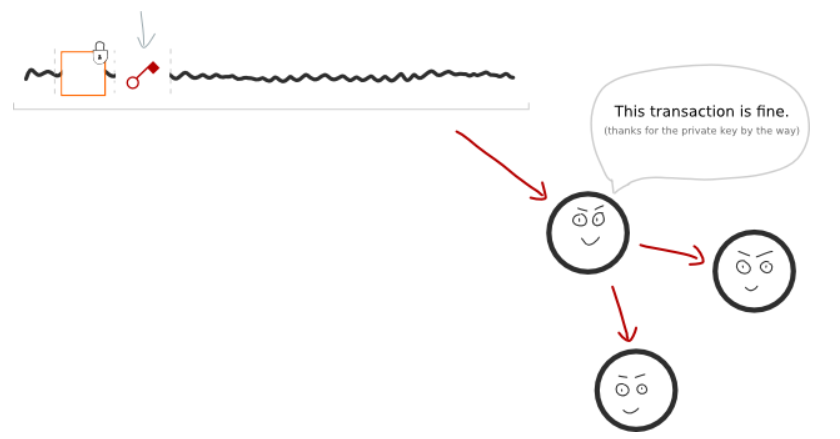
这就是为什么使用数字签名的原因。
每次交易的数字签名是唯一的,只用一次。
那想一想,其他人既然知道我的的数字签名,它们直接拿来用,可不可以?
不可以。实际上并不只用私钥来产生数字签名,而是私钥和交易数据(transaction data)一起来产生数字签名。数字签名和交易必须匹配。
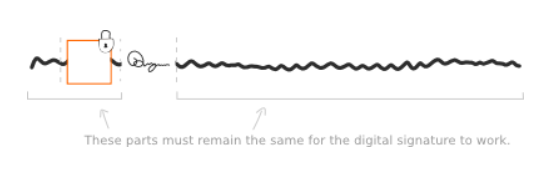
如果不匹配就会被其他节点拒绝。
签名如何发挥作用?

Hash
- 哈希是一种函数或者算法,有着固定的长度,它的作用是加密。
- 哈希值(哈希散列)几乎是不可逆、不可破解的,甚至第一眼不能确定输入值的长度。
- 哈希值是由区块的标识(the block header)决定的。
哈希算法是一种不可逆的加密算法,全称“哈希散列函数”。其最大的特点就是把任意长度的输入通过散列算法转变为固定长度的输出(这样简化并标识了信息),该输出值就称为 “ 散列值 ” ;这种转换是一种信息的压缩映射,散列值的空间远小于输入值的空间,从信息论的角度来说是会损耗信息量;而且输入值的微小变动都会引发最终散列值的巨大波动的雪崩效益;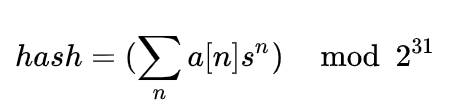
Block
- 然后矿工把这些交易打包,放入候选块(candidate block)中,接着把预选块添加到区块链中。
- 赋予这个候选块一个元数据(可以理解为数据的标识,之后的数据都与它有关),叫做块头(block header),包括是版本、上一个区块的信息、交易数、时间戳、目标值。
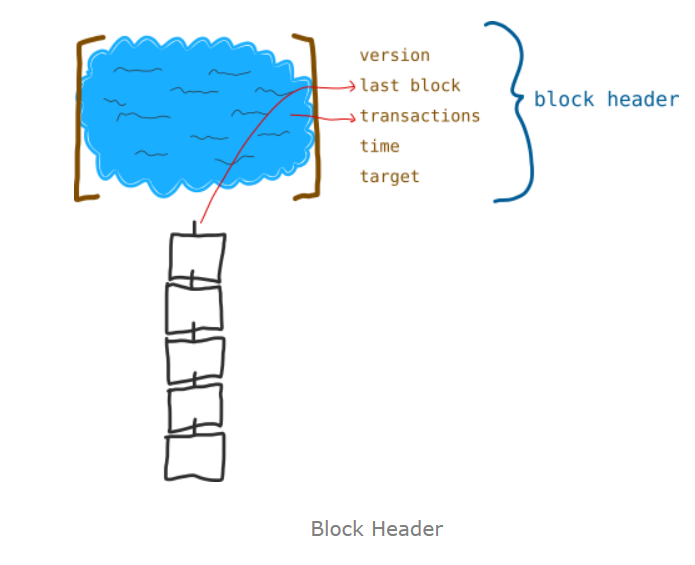
Version:这个块的数据结构,描述它的协议。
Last Block:上一个块的标识
Merkle Root:所有交易一起哈希加密后产生的值,非常的重要。
Time: 时间戳
Target:目标值,和挖矿有关。(后面会解释的)
比如这个值
010000009500c43a25c624520b5100adf82cb9f9da72fd2447a496bc600b0000000000006cd862370395dedf1da2841ccda0fc489e3039de5f1ccddef0e834991a65600ea6c8cb4db3936a1ae3143991
完整的一串就是block header,每一段都有唯一的含义:
01000000——version
9500c43a25c624520b5100adf82cb9f9da72fd2447a496bc600b000000000000——previous block
6cd862370395dedf1da2841ccda0fc489e3039de5f1ccddef0e834991a65600e——Merkle root
a6c8cb4d——time
b3936a1a——bits
e3143991——nonce
下面是一个模拟过程图:
怎么把区块添加进区块链呢?
矿工们创造一个随机数(nonce)(只用一次的用于加密传输的数),然后用随机数(nonce)对块头数据进行哈希处理。这个随机数从0开始,如果不行的话就递增。

直到出现符合要求的值。
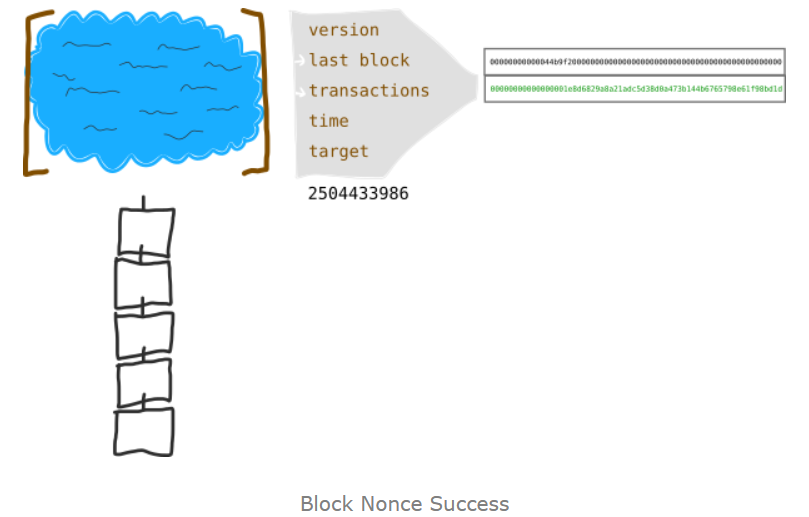
congratulations!!成功了,大家到下一个新区去竞争了。
Nodes
- 节点是运行着比特币程序的计算机,它连接着其他运行着相同程序(客户端)(a client)的计算机,形成网络(network)
所以运行客户端时,它将连接到其他节点并开始下载区块链的完整副本(包含所有已验证交易的文件)。之后,客户端将开始从其他节点接收交易并在网络上中继给其他节点。但是,这不代表成为节点之后才能交易,只要能向网络发送消息就足够了
作用:
-
遵循规则。
-
传递信息。
-
确认并且保存交易的副本。
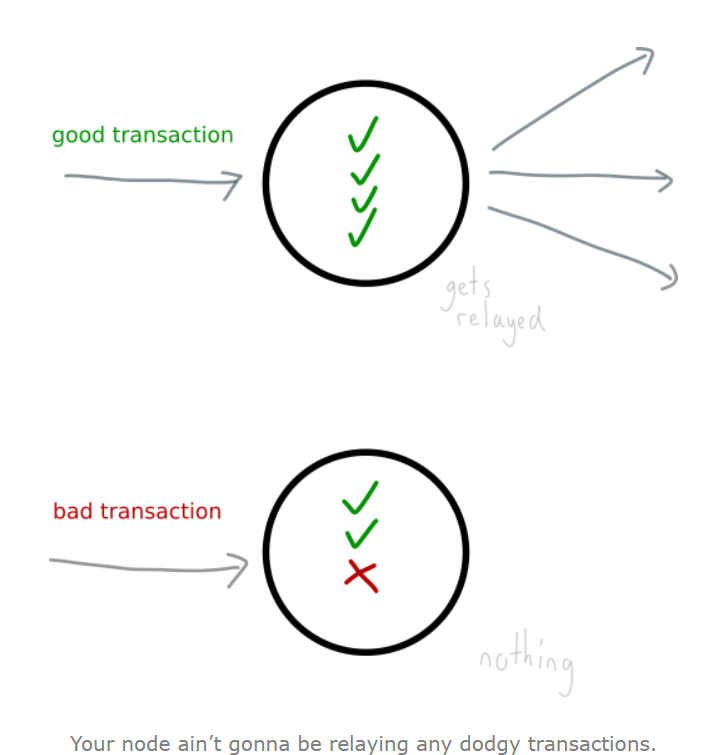
Follow rules
只有交易的所有信息都正确无误时,交易才会被储存并中继到其他的块。(比如转账的人的账户的余额必须大于花费数才能被认证)
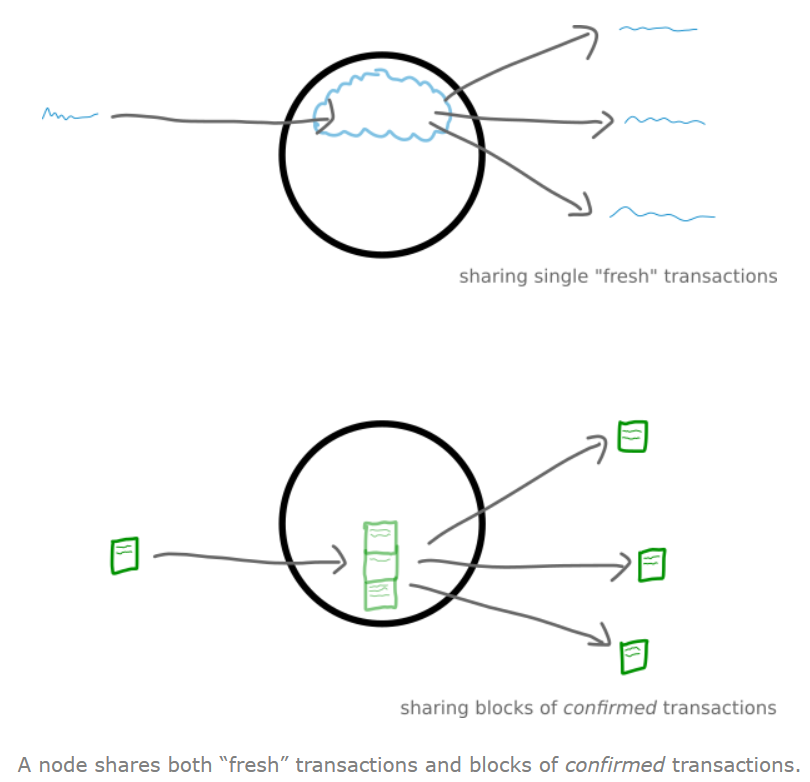
Share information
包括两类:一,刚进入的未确认的交易。二、已确认的交易,信息公开课查询。
Keep a copy of confirmed transactions
每个节点都有一个用于储存交易信息的副本,如果它不是最新的,那么它就会分享出去。分布式任何一点变化和副本相比都是显然的。(这里设计交易,后面来讲)每个节点会信息共享,让每个节点都有最新的数据。
因此,比特币网络被称为“点对点(Peer-to-peer, P2P in short)网络”,因为:
- 每个人都相互连接,因此它是一个网络。
- 网络上的每个人都是平等的,所以我们是点(Peer)。
-
Mining
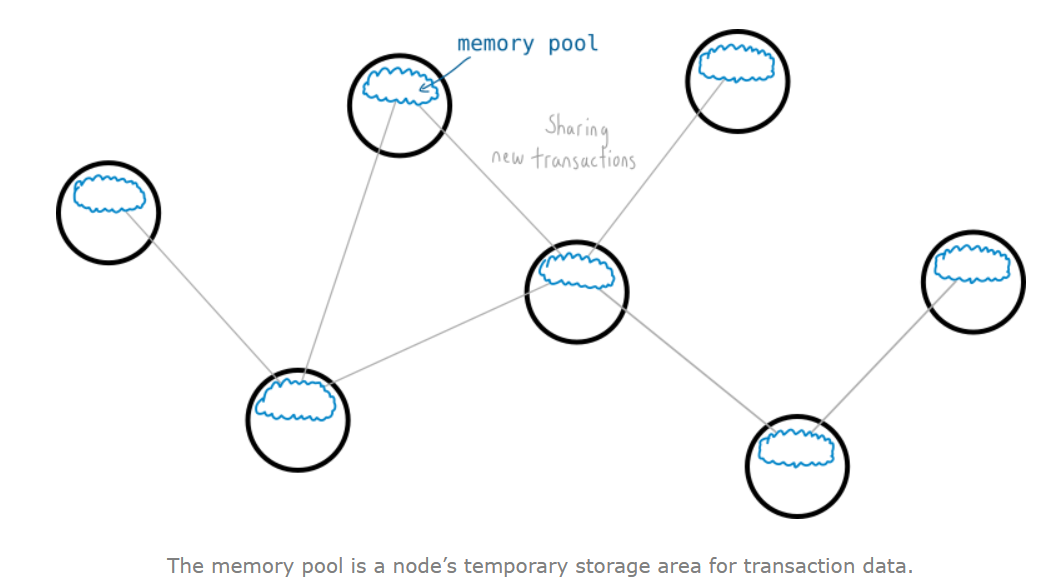
将交易添加到区块链的过程叫做挖矿。
每个比特币的节点都会共享新的交易信息,它们会被暂时储存在内存池(memory pool,也叫交易池)
然后每个节点都可以通过挖矿把交易变成文件(file),这个文件就叫分类账本(ledger)。
这个过程需要使用大量的算力,首先把交易转化成字符串(string)。
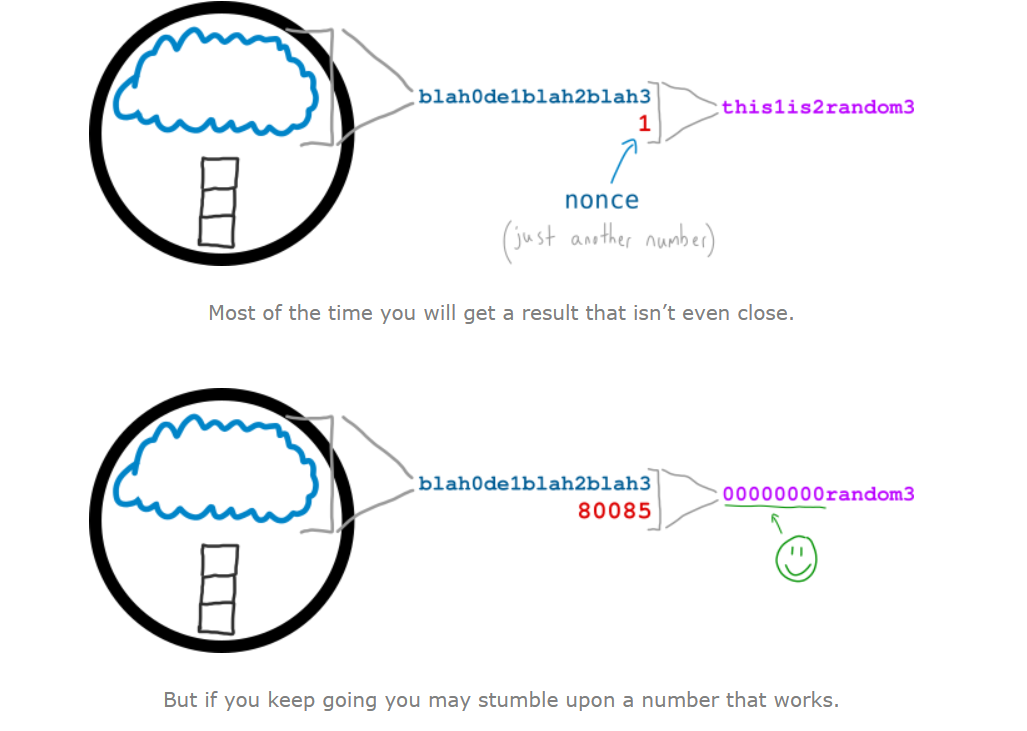
然后对这个十六进制的数哈希处理(像在介绍block那一样)
然后,如果比较走运,你最先在这个超级随机的瞎蒙中胜出,你将会拿到报酬(rewards)。这个不停试错的过程叫做工作量证明(proof of word,PoW in short)
为什么挖矿的过程是必须的呢?
因为这是用于确认交易已经完成的手段,是数字货币用于防止欺诈的方法。(这时,张三投机取巧,在A区用10块钱买了啤酒,然后马上在B区用这个十块钱买披萨(double-spending),因为还没有完成记录和广播......)
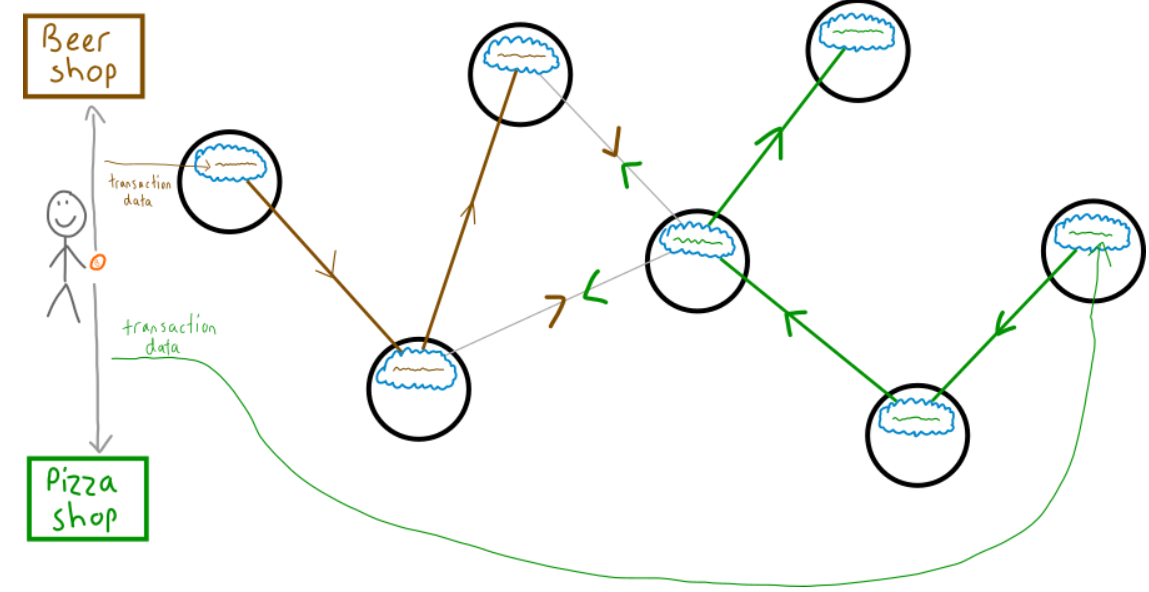
(为了防止这样的欺骗(fraud),张三必须先买啤酒,确认后再买披萨。否则由于节点确认的规则,二者都会被拒绝成立。)(如果包括张三啤酒的内存池通过挖矿变成了区块,并且添加进入区块链,被其他区块认证后,他的等待着的披萨的交易就会自动取消。)————这就是比特币网络面对矛盾(conflicting)的消息来达成共识(consensus)的方法
因此,比特币网络是通过挖矿来确认需要进行哪一项交易。
How do I start mining?——想不想挖矿?
现在挖矿的基本是一些矿机(完全定制的专门为了无限次哈希处理的高度集成电路):
不用担心有没有开始,因为这个效果非常明显,因为CPU会混乱、风扇仿佛要离心飞走。。??
Transactions
- 交易是区块链的核心概念之一,它是一堆数据。
- address可以理解为拥有比特币的账户,它是独一无二的。
也就是说交易的信息变成了一串字符,然后发送到比特币网络(区块链1.0均是以比特币为例),挖矿之后就被加入确认说的交易文件里,即区块链。
交易的过程?
它并不是我们想的那样,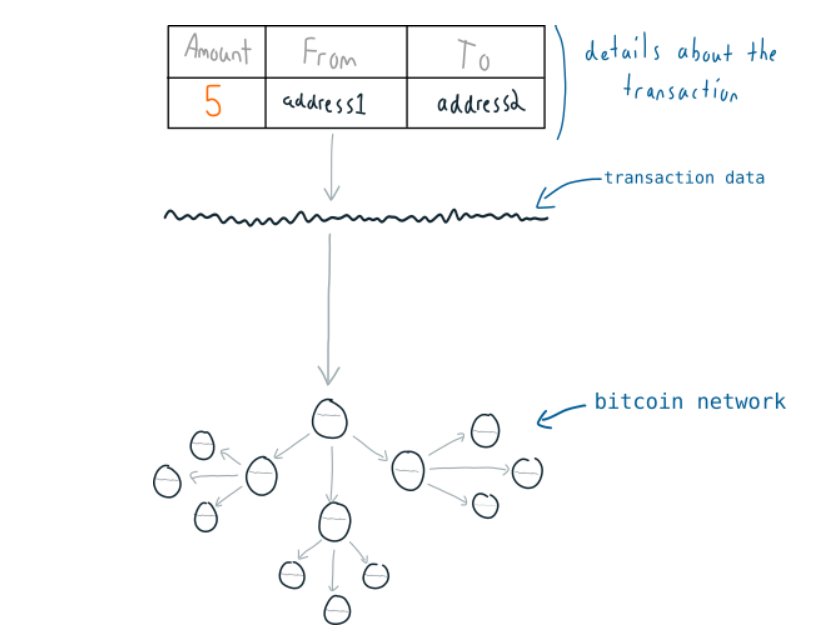
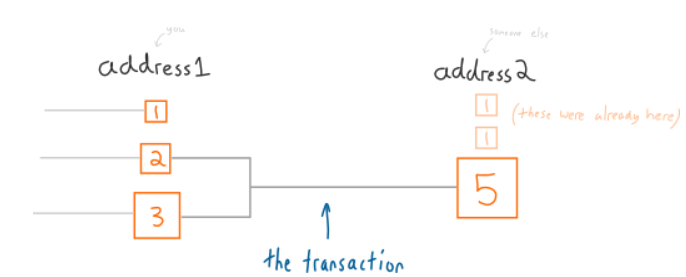
每一个账户的交易均是这么进行的:
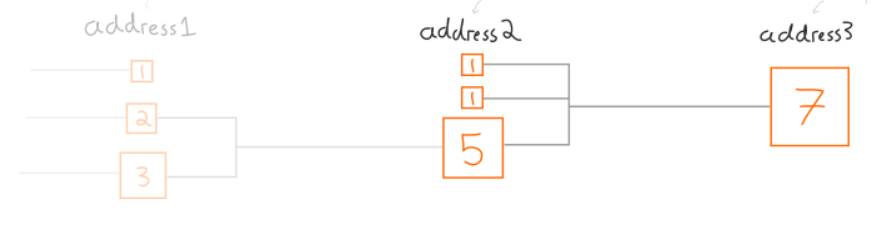
但是问题来了,如果我不能刚好凑出来需要的金额呢?
那么它就会返回一个差值。

(虽然看起来这货有点尴尬,但是编程的时候需要这么做)
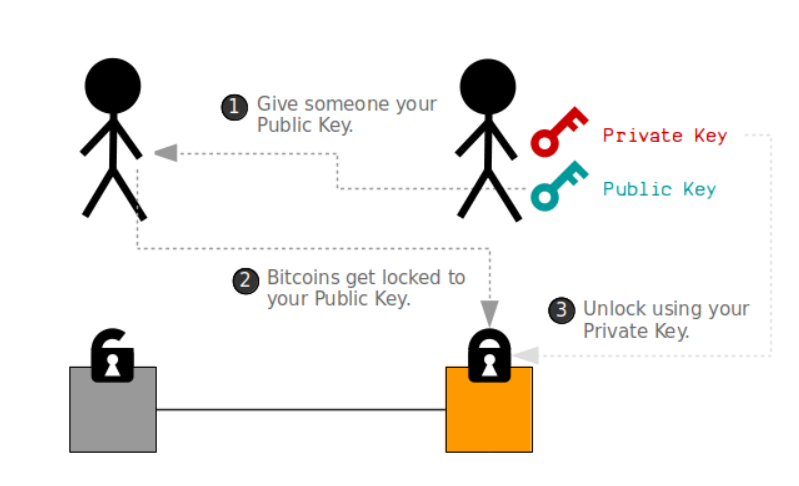
怎么让别人不能花我的钱?
既然交易就是一串数据输入进网络,那么为什么别人不能构建包括了地址得一摸一样得数据来支付呢?
因为每一个output都有一把锁,全部打开之后才能被节点识别,否则不遵守规则就会被拒绝。
你需要用私钥(a private key)来解锁,直到需要用到的outputs都解锁了,才能继续交易。
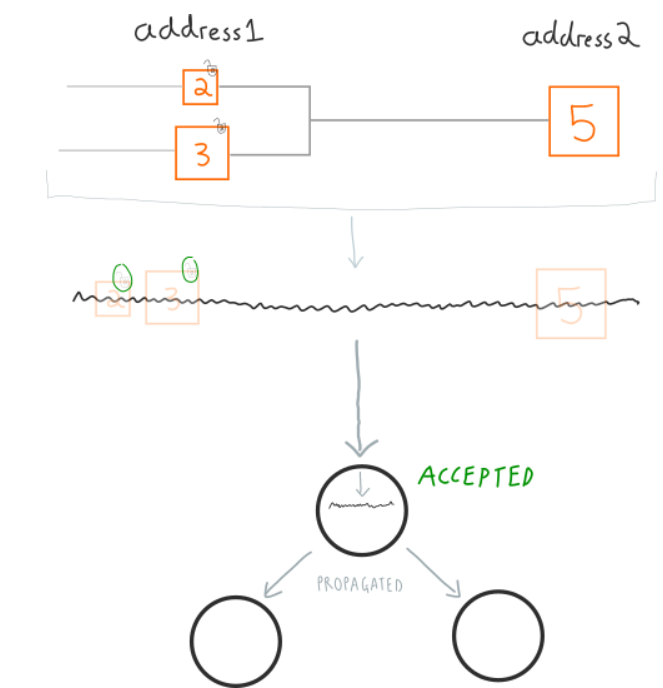
下面是稍微详细的过程:
如果你有十个比特币,但是需要花8个,找零两个。那么,就会在8个的那个Output里加入接收者的公钥,接收者用它的私钥就可以解锁,接下来的两个的Outputs则只有你自己可以解锁。
(解释下面的图)
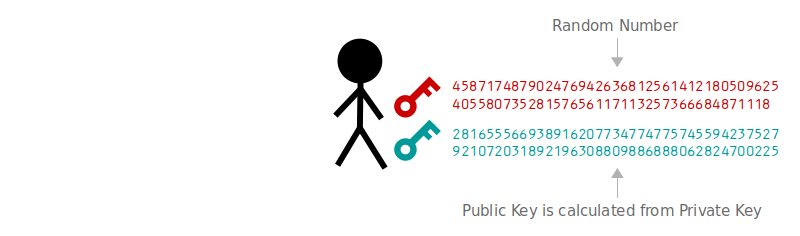
公钥是基于私钥产生的,但是不能通过公钥推算出私钥。
总的过程图:
Difficulty
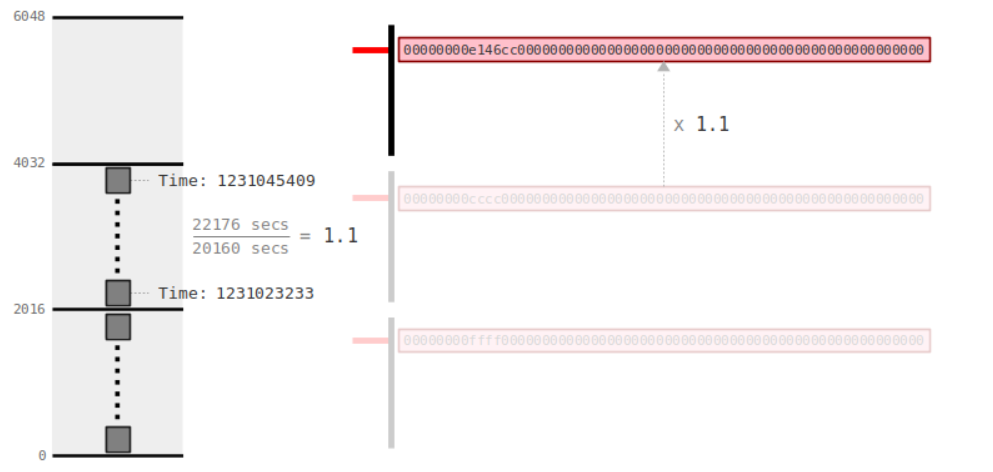
网络的平均块时间是在n个块数后评估的,如果大于预期块时间,则工作证明算法的难度会降低,如果小于预期块时间,则难度会增加。比特币以10min为标准,并且每隔2016个区块(即大约每2周)重新评估一次难度级别。
计算公式如下:new_difficulty = old_difficulty X(2016块X 10分钟)/(挖掘最后2016块所需的时间(分钟))
一般设置创世区块的难度为1。为了保持相对稳定,每次调整的范围在原来的1/4到4倍,下面是变化曲线:
17年1月12号的难度是678亿,2018年1月24号是2208亿,到了20年7月的难度大约是17345亿,计算机发展非常块。(不要小瞧指数,它们都还不到4^24^
Target
刚刚提到了挖矿的过程,它并不轻松,块头被哈希加密后的值必须小于等于某一个值,才被算作成功。也就是目标值越大越容易(可以想象为一个洞,洞口越小越不容易通过)

target就是用来确认区块是否符合要求,并且借此调整难度一个值。

这是一个16进制的数,(作为对比,我们来看创世区块的目标值,明显大许多。)

比如发现0-2016的区块建立的速度很快,那么我们就把目标值调大,增大后面2017-4032难度:

相反,如果之后发现2017-4032个区块用的时间很长,那么增大目标值,第4033-6048个区块生成的速度就会快一点。
下面是计算的规则的模拟:(当然是不能在PDF里输入的啦)

它对应的代码如下:
# 403,200 - NEW TARGET
# 403,199 | last block
# |
# |
# |
# 401,184 - NEW TARGET | first block (target = 0x000000000000000006f0a8000000000000000000000000000000000000000000)
# 1. Get the timestamps for the first and last block in the target adjustment period
first = 1457133956 # block 401,184
last = 1458291885 # block 403,199
# 2. Work out the ratio of the actual time against the expected time
actual = last - first # 1157929 (number of seconds between first and last block)
expected = 2016 * 10 * 60 # 1209600 (number of seconds expected between 2016 blocks)
ratio = actual.to_f / expected.to_f
# 3. Limit the adjustment by a factor of 4 (to prevent massive changes from one target to the next)
ratio = 0.25 if ratio < 0.25
ratio = 4 if ratio > 4
# 4. Multiply the current target by this ratio to get the new target
current_target = 0x000000000000000006f0a8000000000000000000000000000000000000000000
new_target = (current_target * ratio)
# 5. Don't let the target go above the maximum target
max_target = 0x00000000ffff0000000000000000000000000000000000000000000000000000
new_target = max_target if new_target > max_target
# 5. Truncate the target, because the official target is the truncated "bits" format stored in the block header
# This code is a bit rough, because it's working with strings when I should really be working with actual bytes.
new_target = new_target.to_i.to_s(16) # convert from decimal to hexadecimal
new_target = new_target.size % 2 != 0 ? '0' + new_target : new_target # make sure it's an even number of characters (i.e. bytes)
truncated = new_target.scan(/../).each_with_index.map { |byte, i| byte = i >= 3 ? "00" : byte }.join # set all bytes apart from first 3 to zeros
# e.g. 6a4c316c01f354000000000000000000000000000000000 <- full precision
# e.g. 6a4c3000000000000000000000000000000000000000000 <- official target
# 6. Display the full target (with leading zeros)
target = truncated.rjust(64, '0')
puts target
# 000000000000000006a4c3000000000000000000000000000000000000000000
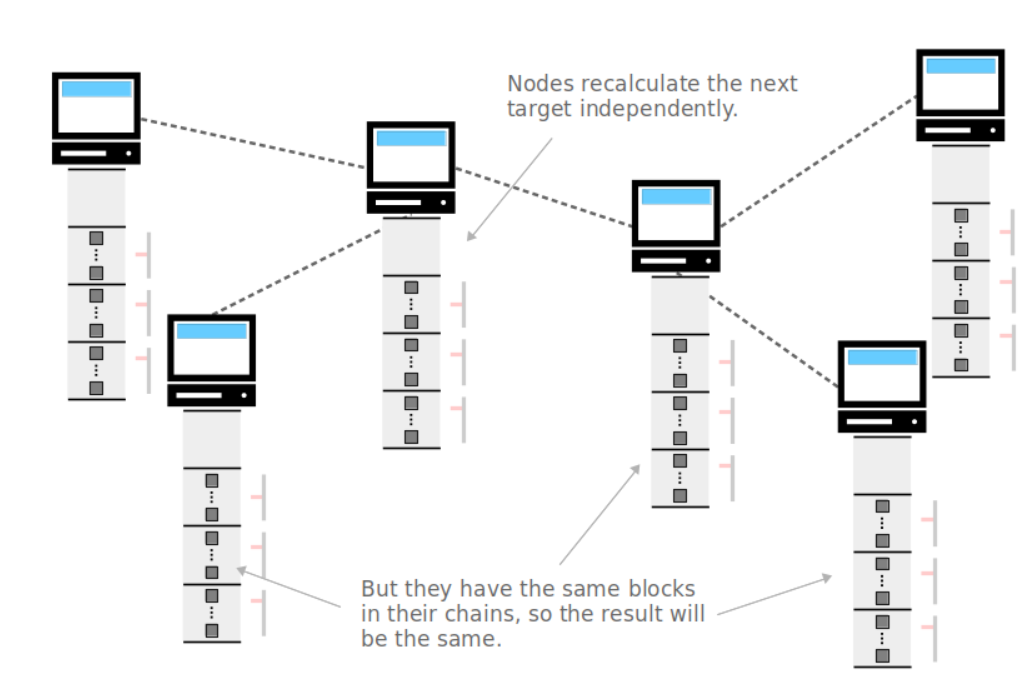
所有的节点都共用同一个target
因为所有的节点都是采纳最长链构成的区块,当第一次运行客户端时,计算机会自动接受初始区块的数据,并且和其他节点保持一致,所以最终它们会共用相同的target。

为什么要设置target来调控时间间隔?
为了让区块链能拓展下去(挖矿),需要让刚产生的区块广播(propagate)到网络中的其他节点,避免重复无用的挖矿造成资源浪费和标准混乱。
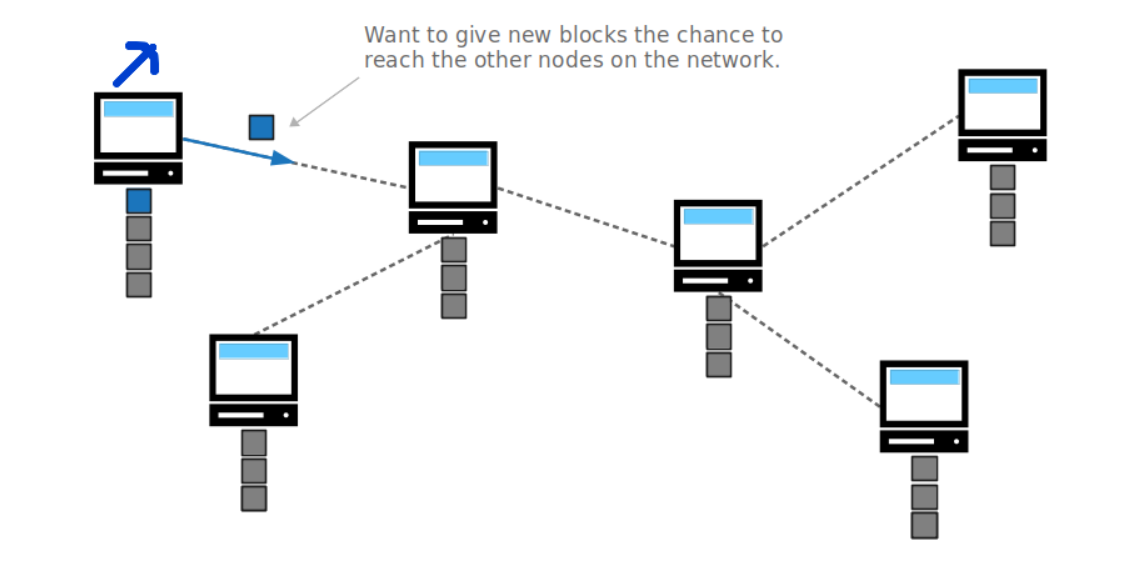
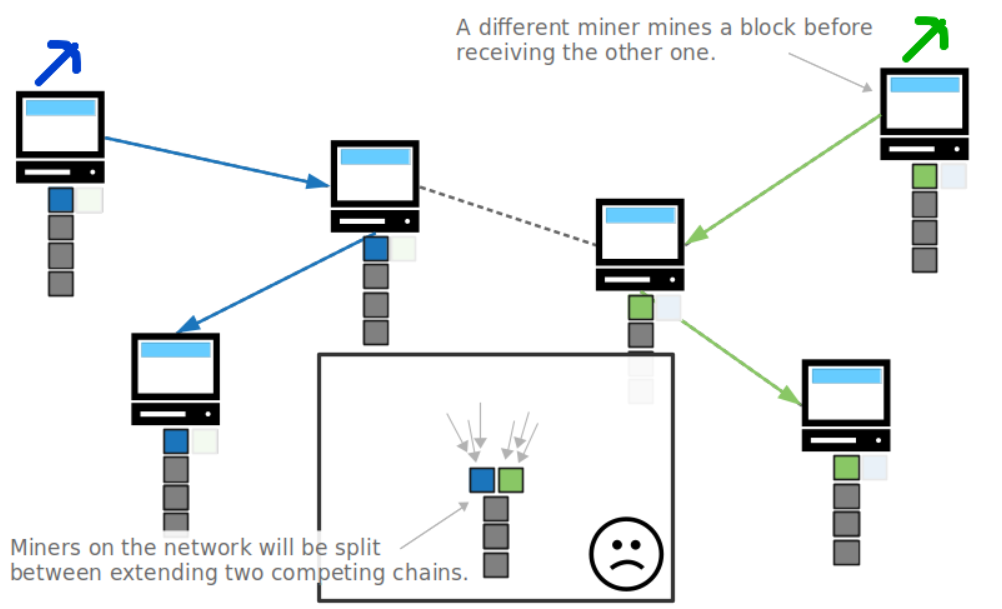
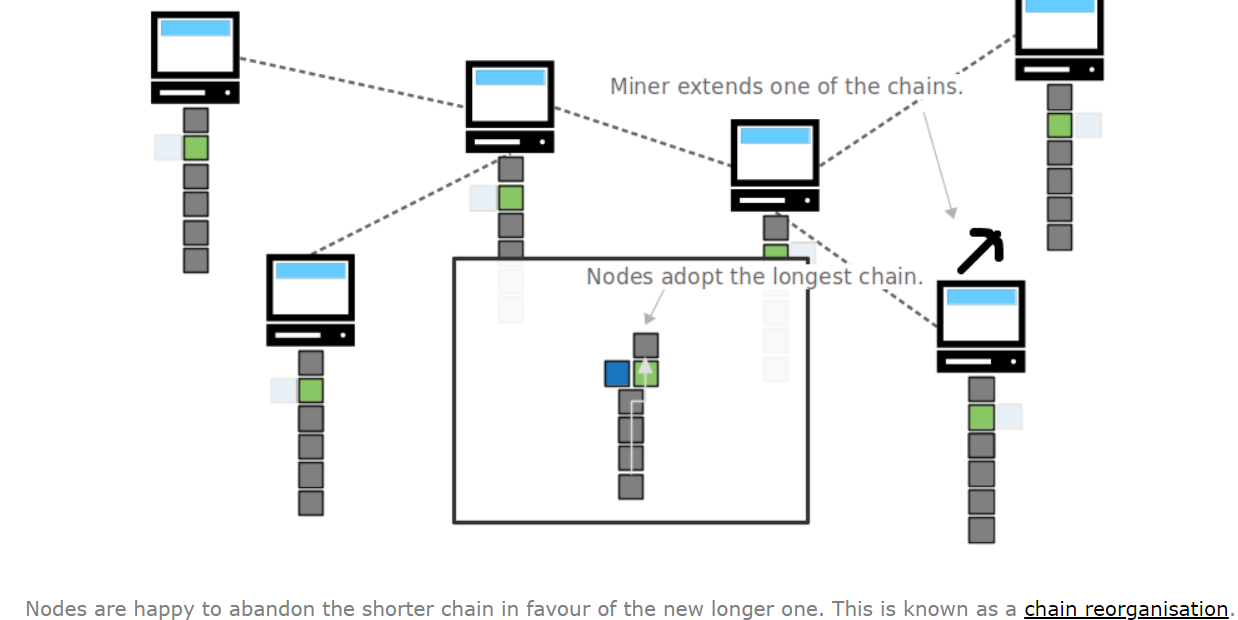
因为区块链必须遵循最长链原则(longest chain)如果没有区块之间没有间隔,那么当一个矿工完成了一个区块之后,其它没有收到消息的矿工还在挖原来的那一层,等他完成了就会产生竞争链(competing chains),发生链重组(chain reorganization,也叫reorg),只有一条能够保留,其余全部 作废。
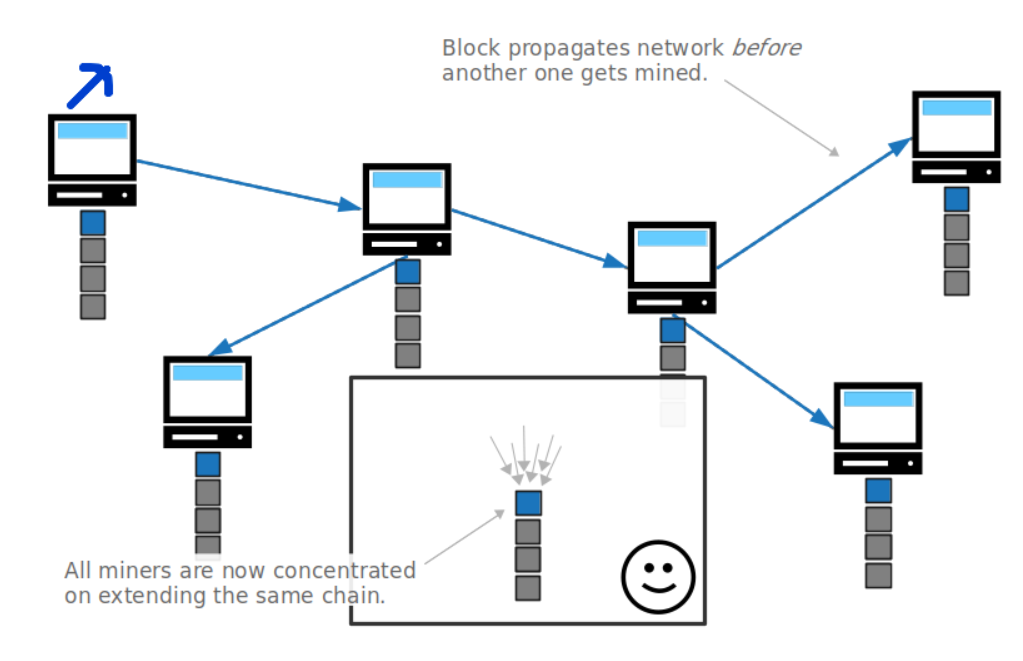
重组之后,矿工就能集中算力来做有用功了。
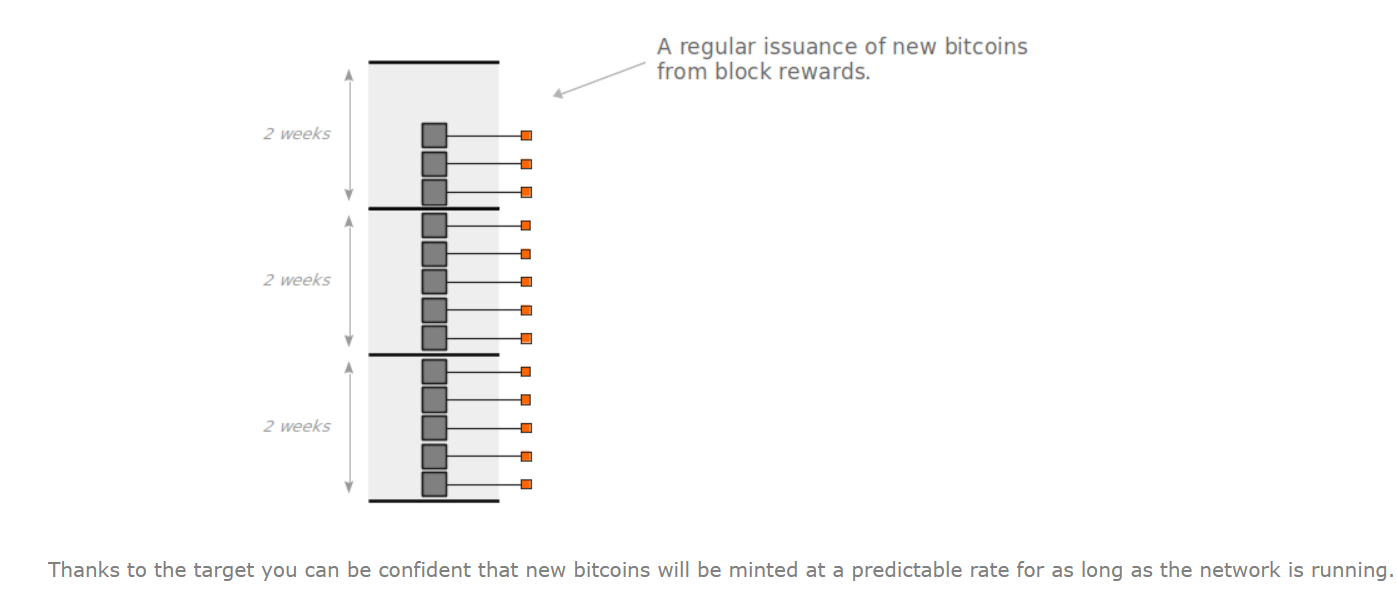
中本聪对这个设置有一个阐述:

以恒定的速率发行货币
比特币是一种货币,他必须保持稀缺性而且需要发行,设定好目标值就能让比特币以可预料的方式发行。

Longest Chain
最长链是节点采用的作为区块链的那一条链
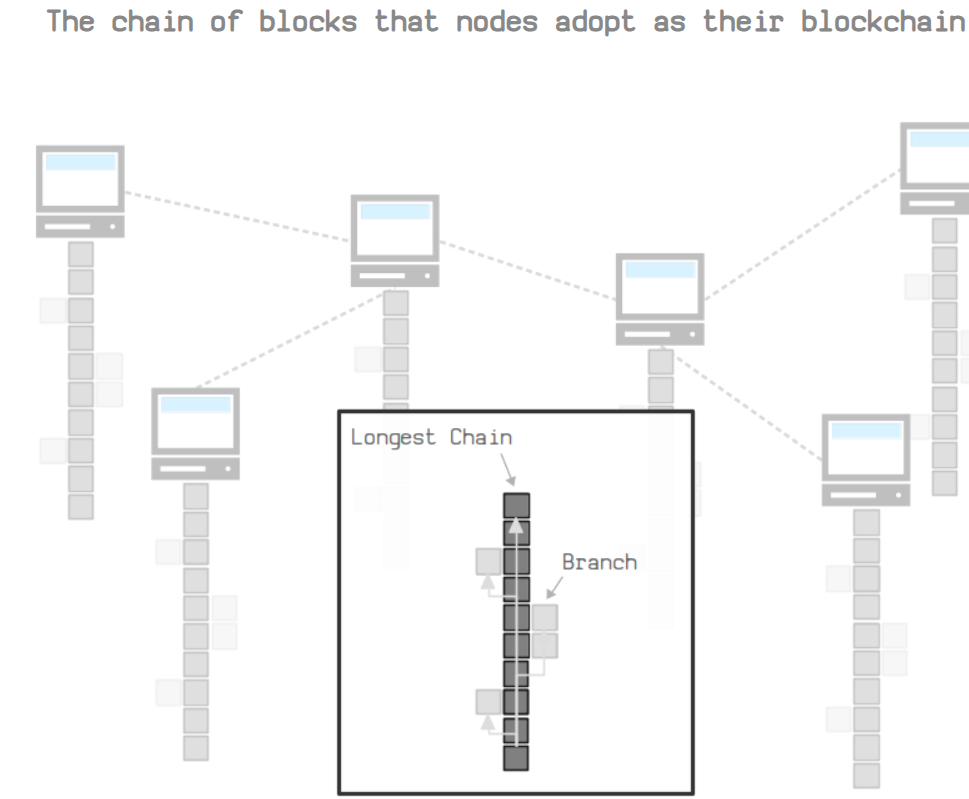
其余的支链或者分叉会被视为无效。
判定标准:
我们知道,不同的难度需要的算力不一样,目标值越小,难度越高,工作量越大。因此,它的判定标准不是区块的个数,而工作量(work)。但是一般而言拥有更多的区块的链消耗的工作量越大。
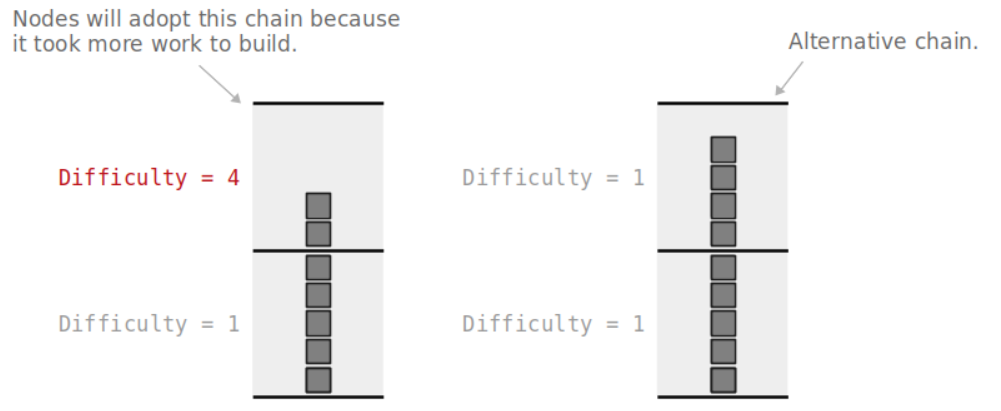
左边的链比右边的短,但是它的工作量是大于右边的,因此左边的链作为最长链。

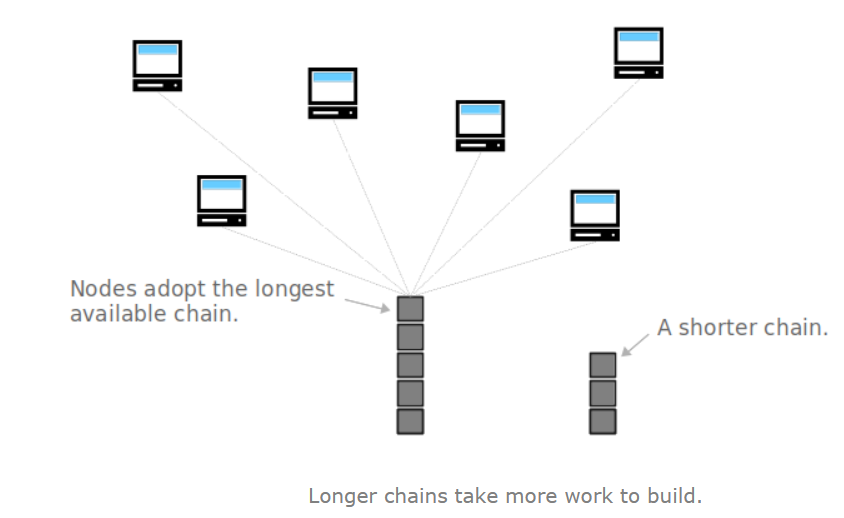
那条短的链一般会被废弃,实际上,从来没有出现含有三个连续的孤块(orphan blocks)。
计算方法:
把每一层挖矿的哈系数累加。
由图可知,哈希数取决于目标值的大小,和难度正相关,和工作量是正相关。
节点为什么要采用最长链
1.解决同时产生两个区块造成的分歧
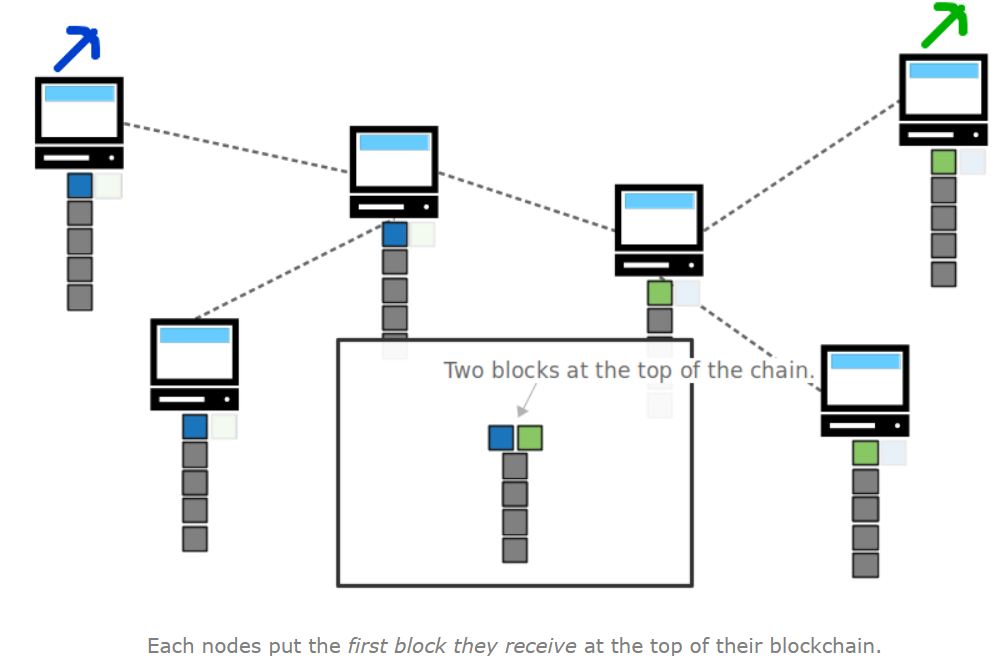
虽然这两个块的起始数据是一样的,但是必须要有一个可信的有效的最长链,确保一致性(consensus)。
那么,接下来形成的区块最先建立在哪一个区块上,它就会被确认为最长链的一部分。
2.保护已添加到区块链中的区块
采用最长链,会让每一个块变得不可代替,进而保护的一致的、真是的分布式账本。如果有人想覆盖某一个交易,那么他需要重新建立最长链,但是不仅区块的高度已经非常大了,而且还有非常多的矿工在延申最长链,单个算力是几乎不可能完成的。即使是巨大算力的攻击,也需要付出高昂的代价。
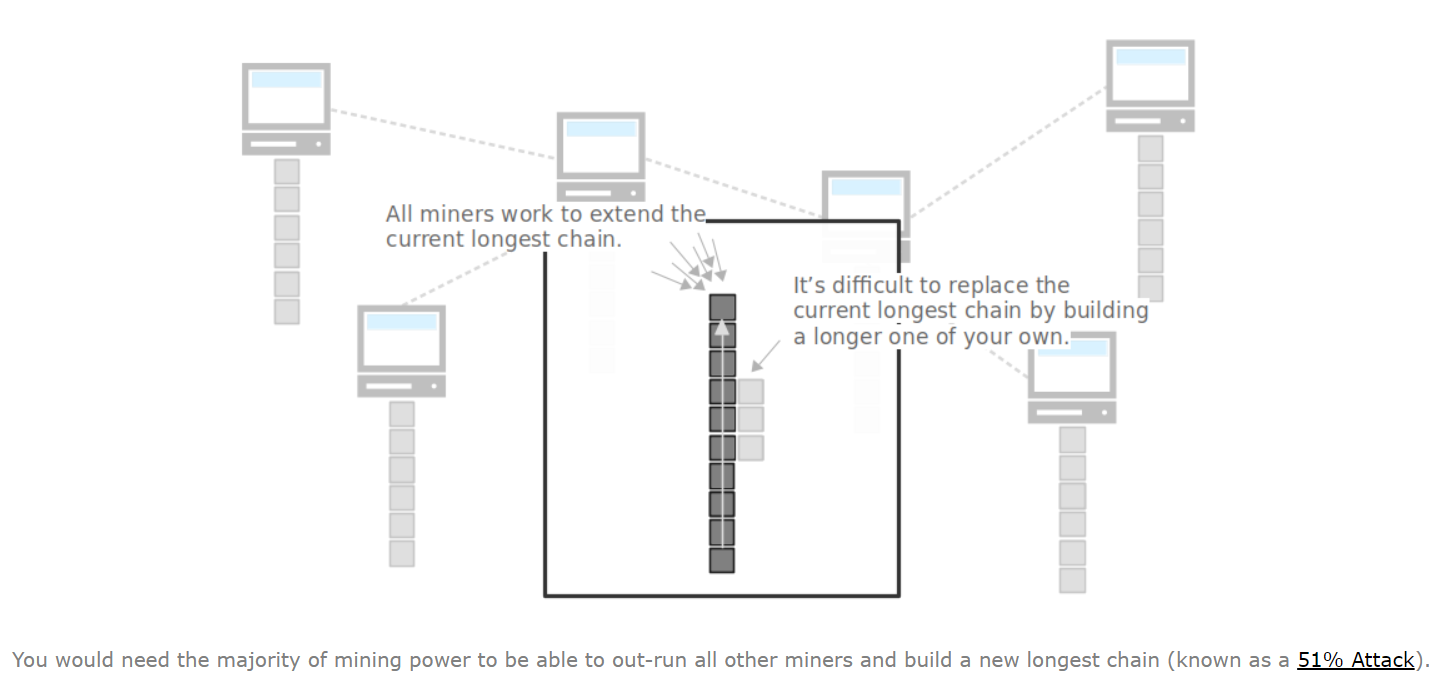
需要一个比所有其他矿工的算力之和还强的算力才可能实现(51%攻击)。
为什么矿工们要在最长链上下功夫
比特币区块链有一个变态的设定,每个矿工必须在最长链挖矿才能获得收益(block reward),如果链重组被废了,就亏大了。也就是说建立新的最长链是不成功则成仁的行为。
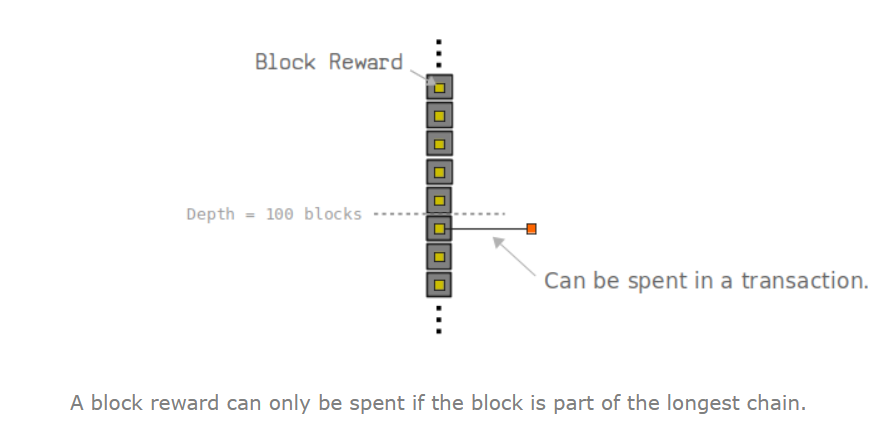
此外,挖矿的收益也必须要等到它后面又100个区块形成后才能用。。。。如果最长链被试图篡改,非常多挖矿的收益都不能用,按照市值来算,钱包里少了几千万美元。。要拼命的。
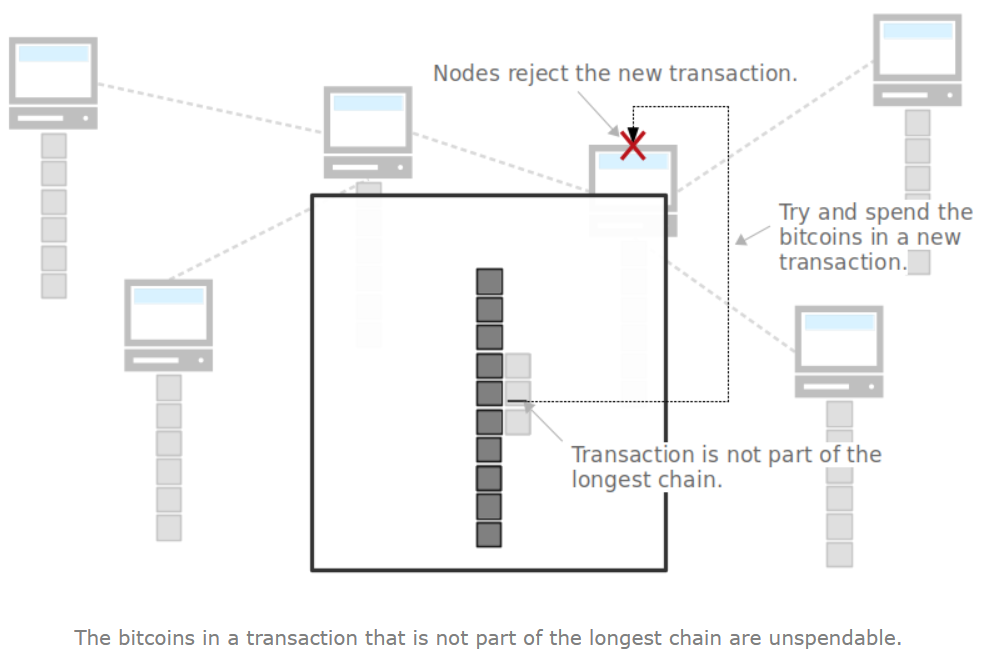
不在最长链的交易会发生什么?
在竞争块里面的交易会无效,被所有节点拒绝,无法存档。不在竞争链的交易会被重新送回内存池,等待机会通过挖矿重新进入新的区块中。
Confirmations
- 图中block confirmation可以简单的理解为后面的区块数。
- 一般指交易确认数,每当一个块完成就加一,而且对于需要达到一定的数量才被视为可信,超过6个就能防止百分之40的算力的攻击(攻击成功率小于1%)。它在在交易中,比特币是6,以太坊是12。但是有时候实在太便宜不在乎或者是不可替代的物品,可以跳过这个审查。
- 这是每一个区块确认的时间间隔
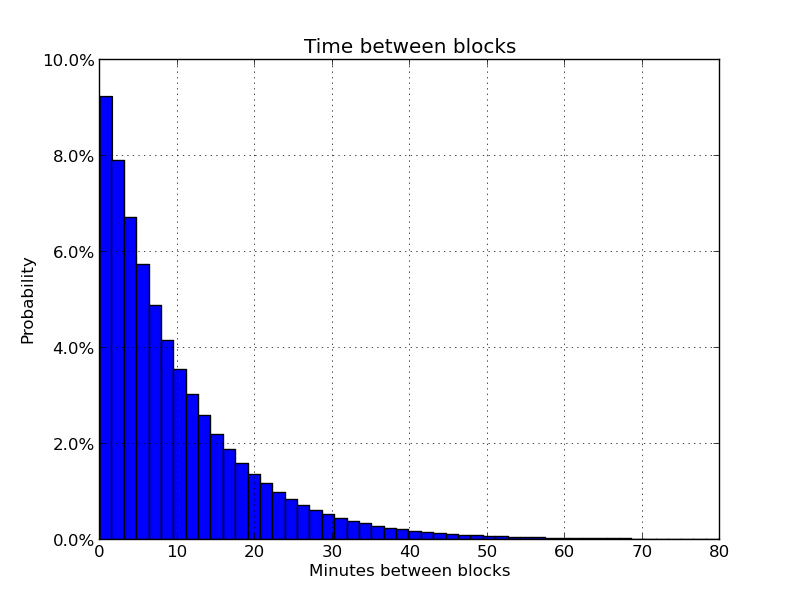
- 这就是交易被确认的时间,大概在10min内有66.3%的概率找到一个区块,有99.7%在一个小时内找到。

以上是基于Bitcoin network的讲解,不同的技术会有差别,但是基本概念是共通的
科尔达(R3-Corda)
R3 公司创始于 2014 年,正式成立于 2015 年 9 月,是一家区块链创业公司,主要致力于为银行提供探索区块链技术以及建立区块链概念性产品。迄今 R3 联盟已拥有 70 多家金融机构,100 多会员,成员几乎遍布全球,通过这个联盟一起研究区块链在金融业的应用,运用它的分布式账本技术帮助金融机构变革基础设施,节约成本,提高效率。Corda 是由 R3 推出的一款分布式账本平台,其借鉴了区块链的部分特性,例如 UTXO 模型以及智能合约,但它在本质上又不同于区块链,并非所有人都可以使用这种平台,其面向的是银行间或银行与其商业用户之间的互操作场景。Corda 是由网络参与者运营的可公开提供的 Corda 节点互联网。每个节点由网络身份服务颁发的证书标识,并且还可以在网络图上标识。
以太坊(Ethereum)
2014 年是由俄罗斯人 Vitalik Buterin 发起的区块链项目,是区块链 2.0 的代表,是现在最流行的公链,它是一个区块链的平台,可以在上面开发各种智能合约,部署后合约就永远生效,需要支付一些代币(ETH)。以太坊的愿景是创建一个无法停止,抗屏蔽(审查)和自我维持的去中心化世界计算机,目前为共识机制为:工作量证明(POW)+ 权益证明(POS)混合模式。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
