完全理解函数调用的 ABI 编码
完全理解函数调用的 ABI 编码
- 原文链接:https://www.rareskills.io/post/abi-encoding
- 译者:AI翻译官
- 本文永久链接:learnblockchain.cn/article…
ABI 编码是用于调用智能合约的数据格式。当智能合约调用其他智能合约时,也是智能合约如何编码数据的方式。
本指南将展示如何解释 ABI 编码数据,如何计算 ABI 编码,并教授函数签名与 ABI 编码之间的关系。
让我们开始吧...
Solidity abi.encodeWithSignature 和低级调用
如果我们要对另一个具有公共函数 foo(uint256 x)(传递 x = 5 作为参数)的智能合约进行低级调用 ,我们将执行以下操作:
我们可以使用以下代码查看由 abi.encodeWithSignature("foo(uint256)", (5)) 返回的实际数据:
function seeEncoding() external pure returns (bytes memory) {
return abi.encodeWithSignature("foo(uint256)", (5));
}
我们将得到以下结果(即 ABI 编码):
0x2fbebd380000000000000000000000000000000000000000000000000000000000000005
像这样解释和理解这些数据是本文的目标。
ABI 编码函数调用的关键组件
编码的 ABI 函数调用是函数选择器和函数的编码参数(如果函数接受参数)串联后的数据。
函数签名
函数签名是函数名称及其参数类型的组合,不包含空格。
例如,对于以下函数:
function transfer(address _to, uint256 amount) public {
//
}
其函数签名为 transfer(address,uint256)。请注意,必须使用完整的参数数据类型,例如 uint256 而不是 uint。此外,像 _to 和 amount 这样的变量名称不是函数签名的一部分。重要的是字符串中没有空格,例如 transfer(addres, uint256)。
根据 Solidity 文档 ,在计算函数签名时需要注意一些“特殊情况”:
- 结构体被视为元组
- 可支付地址、接口和合约类型被视为地址
- “memory” 和 “calldata” 修饰符被忽略
- 枚举是
uint8 - 用户定义的类型被视为其基础类型
函数选择器
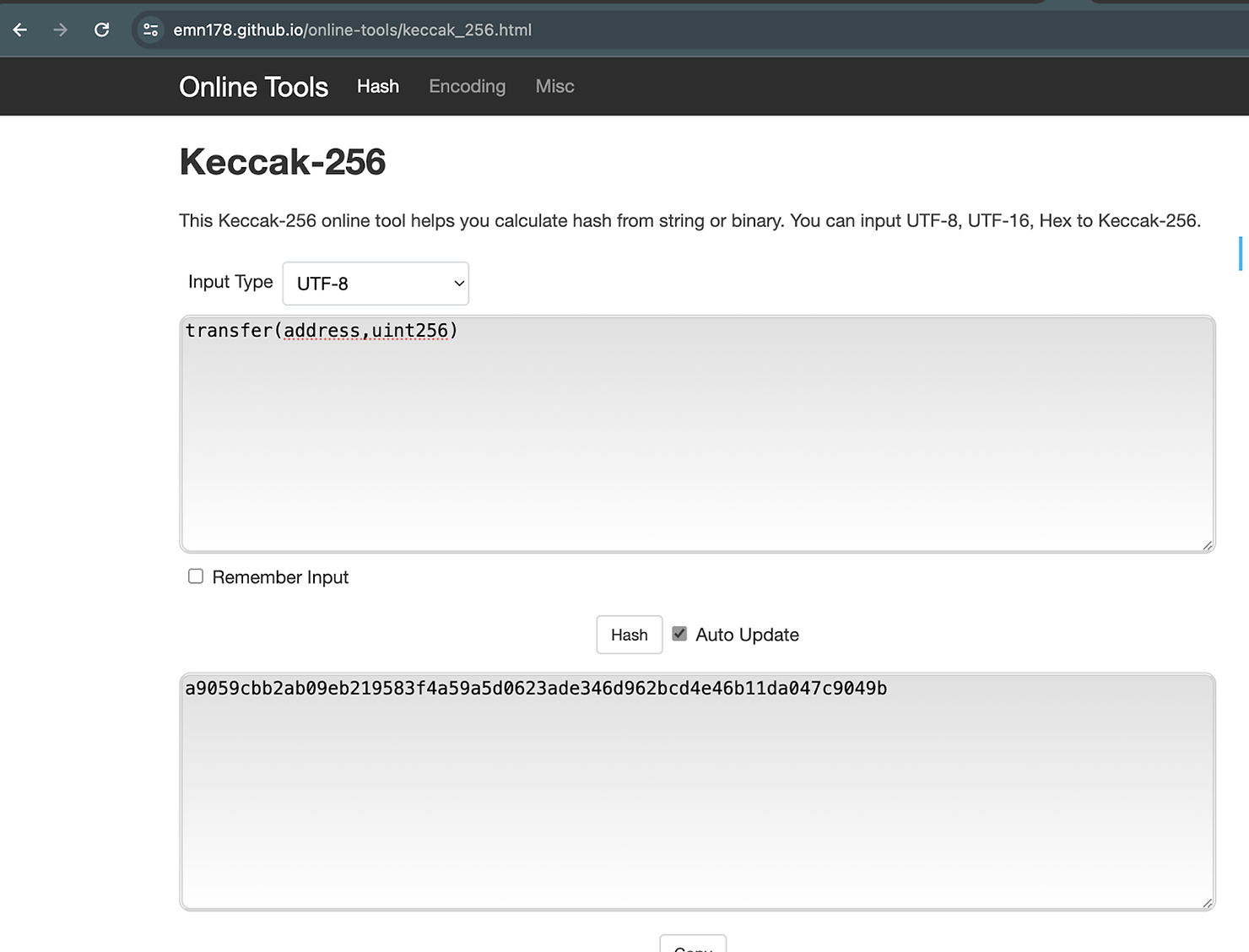
函数选择器 简单地是 Solidity 用于识别函数的函数签名的 Keccak-256 哈希的前 4 个字节。例如,我们先前提到的函数签名 transfer(address,uint256) 的 Keccak-256 哈希是这个十六进制值:
0xa9059cbb2ab09eb219583f4a59a5d0623ade346d962bcd4e46b11da047c9049b
然而,只使用哈希结果的前 4 个字节 0xa9059cbb 来识别函数;这四个字节就是函数选择器。
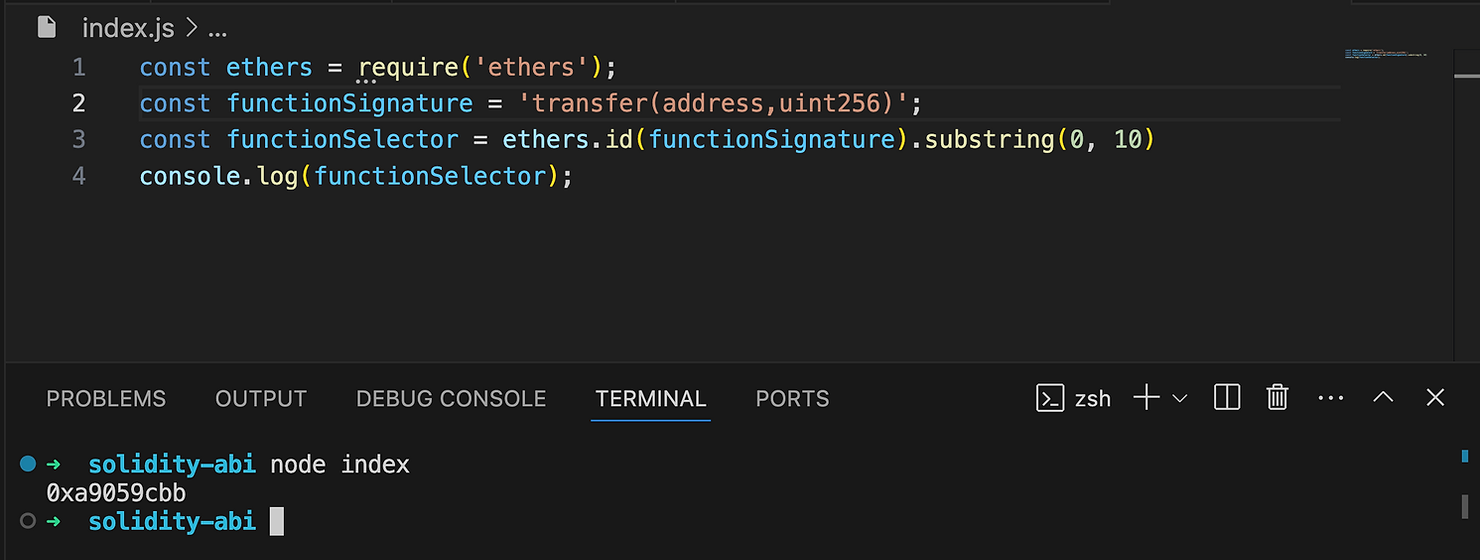
你可以使用 ethers JavaScript 库将 transfer() 函数签名转换为其选择器,如下所示:
const ethers = require('ethers'); // Ethers v6
const functionSignature = 'transfer(address,uint256)';
const functionSelector = ethers.id(functionSignature).substring(0, 10)
console.log(functionSelector);
结果将如下所示:
在 Solidity 中,此函数计算函数选择器:
function getSelector() public pure returns (bytes4 ret) {
return bytes4(keccak256("transfer(address,uint256)")); // 0xa9059cbb
}
现在我们清楚了函数选择器是什么,让我们考虑 ABI 编码函数调用的下一个组件 —— 函数输入或参数。
函数输入或参数
当调用不带参数的函数时,仅函数选择器将是调用函数所需的全部编码。例如,函数 play() 将由其函数选择器 0x93e84cd9 识别,这将是调用函数所需的全部数据。
然而,如果函数接受参数,例如 transfer(address to, uint256 amount),那么函数参数必须进行 ABI 编码并连接到函数选择器。
让我们以 transfer(address to, uint256 amount) 作为示例来帮助我们理解如何进行参数编码:
function transfer(address to, uint256 amount) public {
//
}
此函数调用的数据并不永久存储在函数或合约本身中。相反,它存在于一个称为“calldata”的空间中。你无法修改 calldata 中的数据,因为它是由交易发送方创建的,然后变为只读。
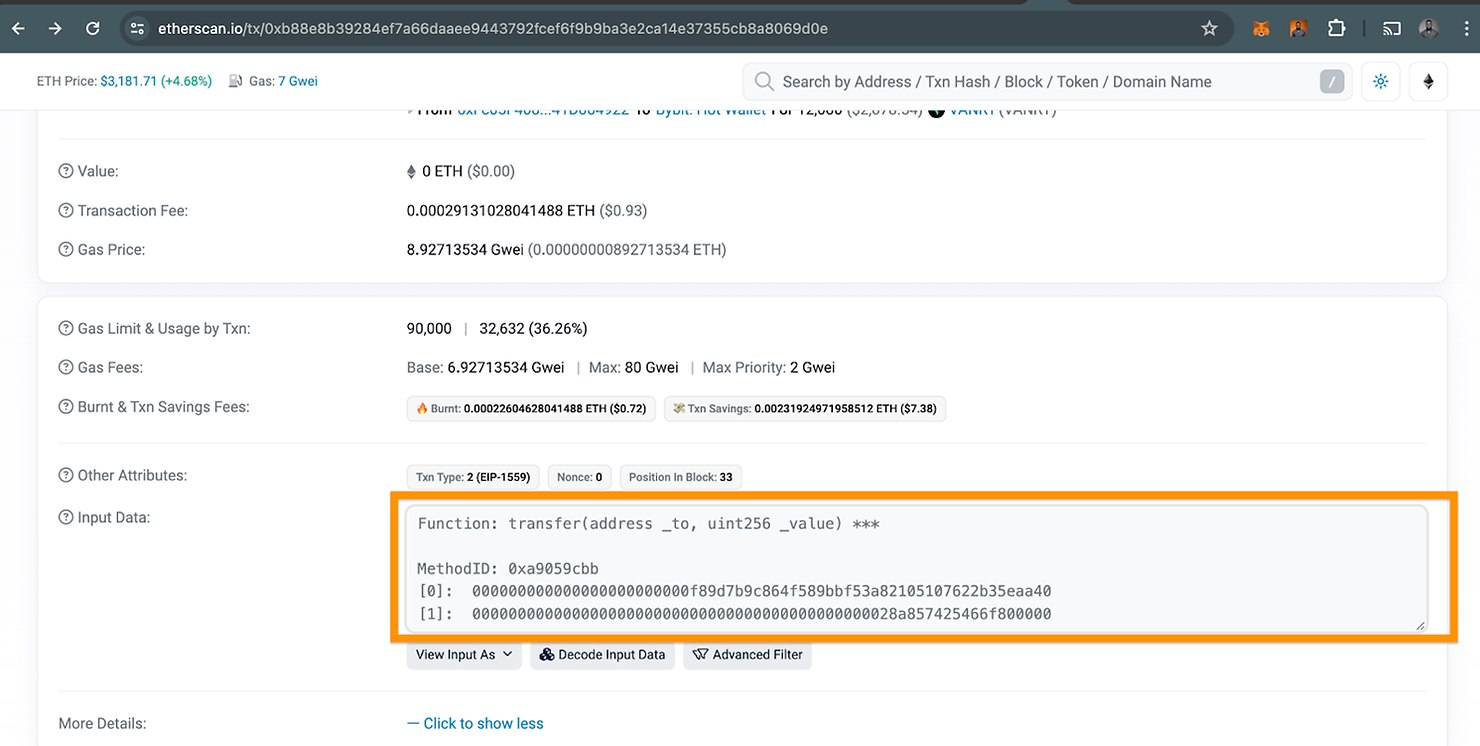
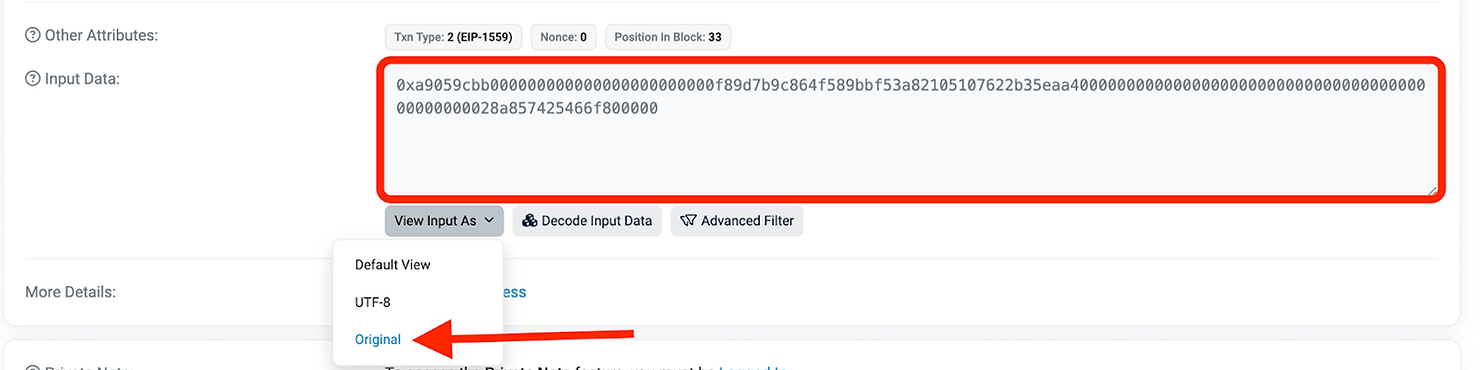
Etherscan 在函数描述下方将函数选择器称为 MethodID(请参见下方截图中的红色框)。因此,transfer() 的 methodID 是 0xa9059cbb。
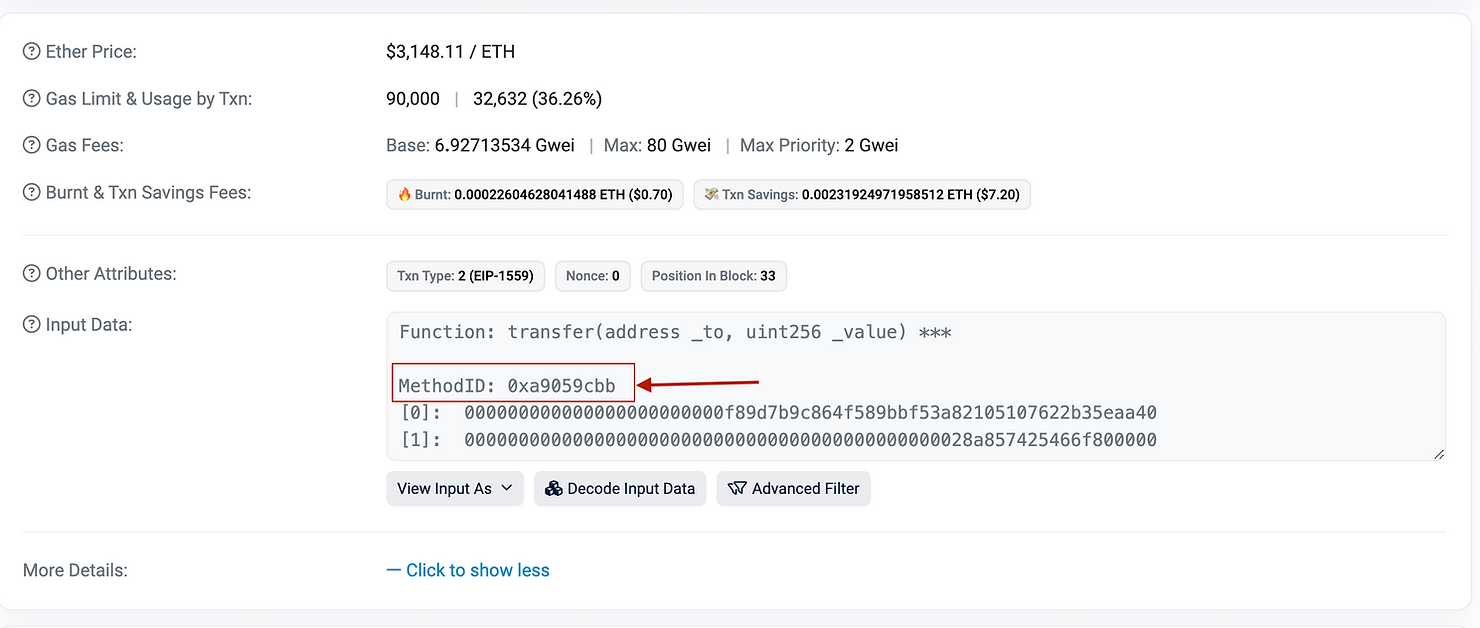
接着是两个长十六进制值,标记为 [0] 和 [1]。这些十六进制值代表两个输入数据参数:_to,地址 和 _value,uint256。
Etherscan 帮助我们将 calldata 信息分隔并解释为每行 32 字节(64 个字符)。然而,实际的 calldata 将被捆绑在一起并作为一个长字符串发送,应该看起来像下面这样:
0xa9059cbb000000000000000000000000f89d7b9c864f589bbf53a82105107622b35eaa4000000000000000000000000000000000000000000000028a857425466f800000
你还可以通过单击“View input as”并选择“Original”选项在 Etherscan 上查看原始格式中的实际完整 calldata,如下所示:
为了更好地理解发生的情况,让我们分解 calldata 并提取交易的相关信息。
分解 calldata
让我们考虑下面的 calldata 并识别其组件:
0xa9059cbb0000000000000000000000003f5047bdb647dc39c88625e17bdbffee905a9f4400000000000000000000000000000000000000000000011c9a62d04ed0c80000
首先,我们需要知道函数签名 —— 没有它,我们无法解码数据。因此,这是上述 calldata 的函数签名:
transfer(address,uint256)然后我们将十六进制表示(0x)和函数选择器放在各自的一行上。函数选择器始终为 4 个字节(8 个十六进制字符)。最后,我们将以下每个 32 字节分成各自的一行。正如我们将在后面看到的,Solidity 将数据编码为 32 字节的增量。
0x <---------- 十六进制表示 a9059cbb <---- 函数选择器 0000000000000000000000003f5047bdb647dc39c88625e17bdbffee905a9f44 00000000000000000000000000000000000000000000011c9a62d04ed0c80000
函数选择器
函数选择器是 calldata 的前 4 个字节 0xa9059cbb。

地址
在 transfer(address,uint256)中,地址是接下来的 32 字节值。实际地址为 20 字节,但左侧填充了前导零以使其成为 32 字节。
地址:000000000000000000003f5047bdb647dc39c88625e17bdbffee905a9f440

基本上,接收地址将是上面的值,但没有额外的零填充:即 0x3F5047BDb647Dc39C88625E17BDBffee905A9F44。
金额
最后,在 transfer(address,uint256)中的最后一项是金额。金额(0000000000000000000011c9a62d04ed0c80000)左侧填充了前导零,变成了 32 字节,如下所示:

以下是一个 Python 片段,可帮助你快速将十六进制转换为十进制:
>>> int("0x11c9a62d04ed0c80000", 16)
5250000000000000000000
我们也可以将十进制转换回十六进制,如下所示:
hex(5250000000000000000000)
0x11c9a62d04ed0c80000
数据类型和填充
我们已经确定 calldata 中的每个项目都被编码为 32 字节字,并且如果项目未占据整个 32 字节字,则用零填充。
根据规则 ,每个固定大小的数据类型,如 int、bool 和各种大小的 uint(unit8-uint256),将被编码为 32 字节字,如果需要,则左侧用零填充。
例如,如果你有一个值为 5 的 uint8,它将被编码为
0x0000000000000000000000000000000000000000000000000000000000000005。
类似地,具有真值的 bool 也将被左填充并编码为 0x0000000000000000000000000000000000000000000000000000000000000001。
但是,动态大小的数据类型 bytes 和 string 是右填充的。例如,表示 hello 的字节 0x68656c6c6f 将被编码为 32 字节字,右侧用零填充为 0x68656c6c6f000000000000000000000000000000000000000000000000000000。
Solidity 中的固定大小数据类型包括:
-
布尔
-
无符号整数
-
固定大小的字节(byteN)
-
地址
-
元组,具有固定数据的结构
-
固定大小数组
以下是 Solidity 中的动态数据类型:
-
字节
-
字符串
-
动态数组
-
包含动态类型的固定大小数组
-
包含上述任何动态类型的结构
处理动态 calldata
到目前为止,我们的重点一直放在静态 calldata 参数类型上,如地址和 uint256。虽然静态类型相对容易编码,但由于数组和字符串所包含数据的大小不同,编码数组和字符串可能有点复杂。
让我们考虑一个接受 uint 数组和单个地址的函数。虽然我们这里不涉及我们函数的实现细节,但函数签名应如下所示:
transfer(uint256[],address)
现在,让我们将重点转移到编码数组上。假设我们将以下数据传递给 transfer 函数:
transfer([5769, 14894, 7854], 0x1b7e1b7ea98232c77f9efc75c4a7c7ea2c4d79f1)
这是我们上面示例函数的 calldata,其签名为 transfer(uint256[],address)。让我们来检查它,并看看如何按照我们上面描述的模式对每个部分进行编码。
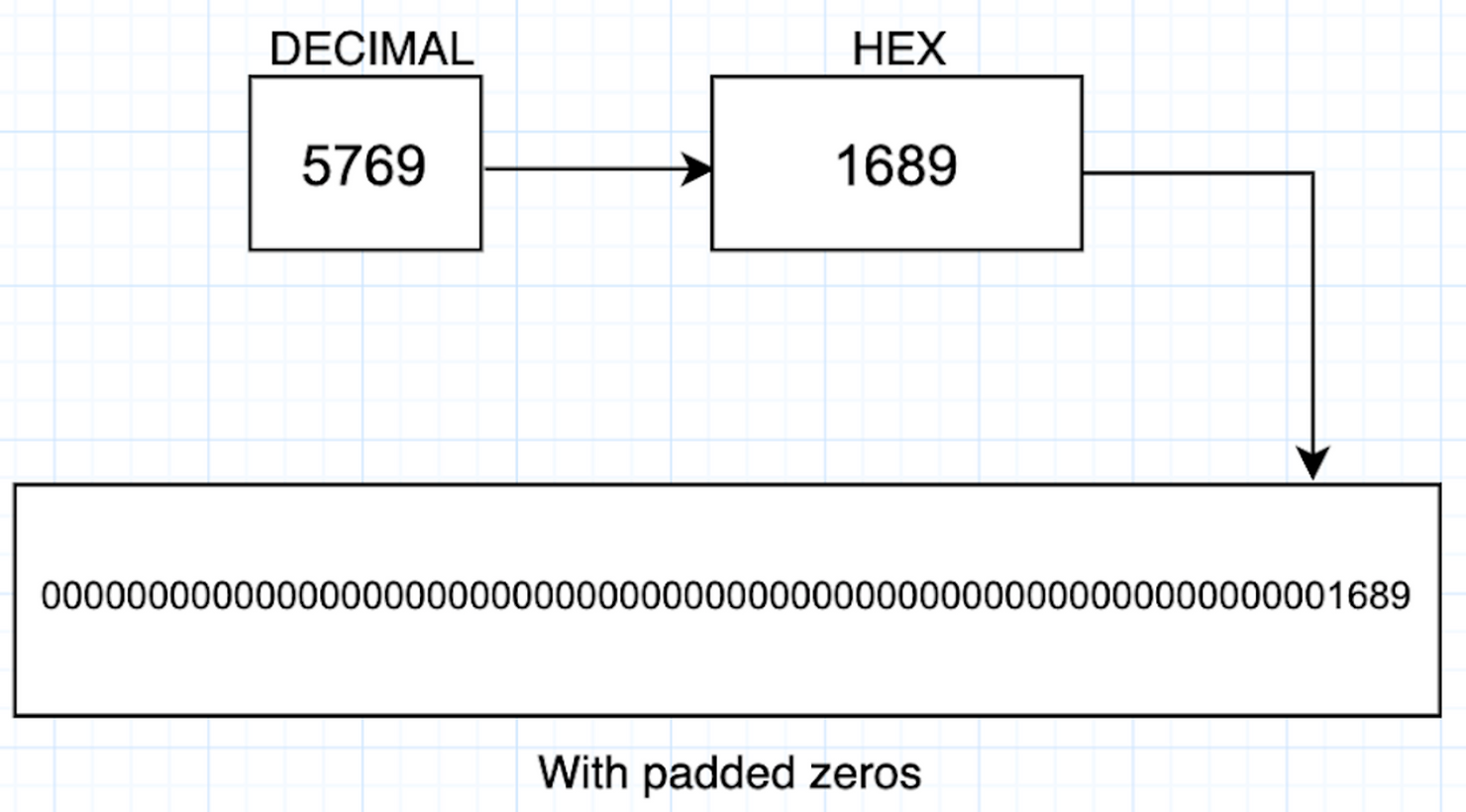
首先,我们将从编码数组 uint256[]的“偏移量”开始,但是什么是偏移量?

偏移量
偏移量用于定位 calldata 中特定动态数据的开始或位置。
根据我们的示例,我们有一个动态数据类型 uint256[]和一个静态类型 address。在上述 calldata 中,uint256[]的偏移量为 40(十六进制)(64(十进制)),其编码占用 32 个字节。
由于动态数组是函数的第一个参数,所以偏移量是 calldata 中的第一个 32 字节字长:

为了进一步解释偏移量的工作原理,上面的图像高亮显示了数组的偏移量在 calldata 中的位置。每个字字节字长:
- 0-31(32 字节的第一行)
- 32-63(32 字节的第二行)
- 64-95(32 字节的第三行)
- 等等
因此,64(40 十六进制)是第三行最左边的字节(一对十六进制字符),绿色高亮结束的地方。这就是偏移量指向的位置。
在这个示例中,偏移量是从函数选择器后的第一个字节开始到动态数据(数组)开始的距离。然而,我们将在后面看到,偏移量并不总是指“从函数选择器后的第一个字节的偏移”。
编码静态数据 —— 地址
下一行是地址,这是一个静态的 32 字节字,前面填充了前导零。这是我们已经传递的相同地址,因为地址已经是十六进制格式。

编码动态数据的长度 —— 数组
下一行是数组的长度,即数组中的项目数。正如你所看到的,数组中有 3 个项目:[5769, 14894, 7854]。如下图所示,数组的长度为 3:

将数组元素进行十六进制编码
到目前为止,我们已经对静态类型、偏移量和数组长度进行了编码。接下来,让我们对实际的数组元素进行编码。数组的每个元素将被表示为类似下面图片中的十六进制数字:
我们将每个整数转换为其十六进制表示,并在前面添加前导零。因此,数组项将如下所示:

这完成了我们对此 ABI 编码的 calldata 的讨论。
以下视频总结了我们学到的有关如何为 transfer(uint[], address)编码 calldata 的所有内容:
https://video.wixstatic.com/video/706568_29bfe4ea94b94cf49a0bd42a0e4d9f44/1080p/mp4/file.mp4
ABI 编码字符串参数
编码字符串很简单,你只需要编码以下内容:
-
偏移量
-
字符串的长度
-
字符串的内容(UTF-8 编码)
以下是一个使用包含字符串参数的函数的示例:
play(string)
当我们传入一个值时:
play("Eze")
calldata 将如下文本所示:
0x
718e6302
0000000000000000000000000000000000000000000000000000000000000020
0000000000000000000000000000000000000000000000000000000000000003
457a650000000000000000000000000000000000000000000000000000000000
偏移量表示为十六进制的 20,因为字符串编码的位置距离 calldata 开头的函数选择器仅 32 字节(十进制 32 在十六进制中为 20)。我们还可以看到字符串的长度(Eze)为 3,因为字符串中只有 3 个字符,每个字符占一个字节(一个字节是两个十六进制字符)。
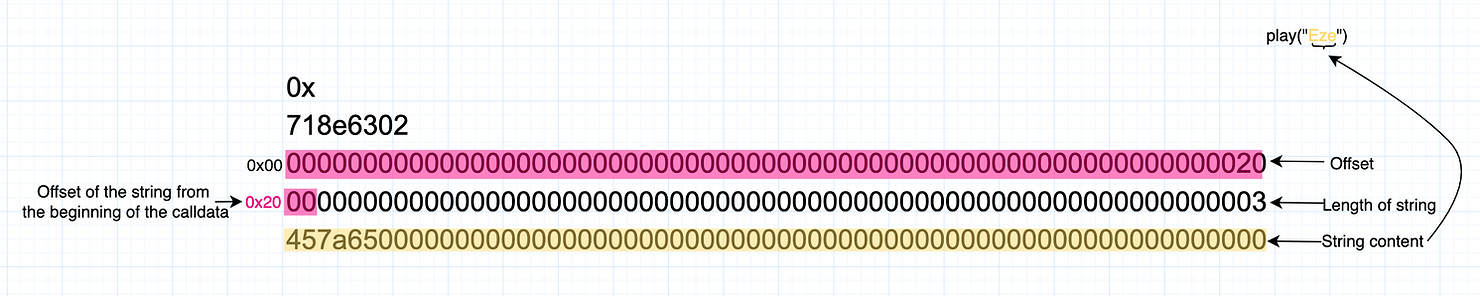
字符串“Eze”仅使用 ASCII 字符,每个字符占一个字节(因此长度为 3)。但是,像“好”这样的 Unicode 字符占用 3 个字节。utf-8 编码字符的最大字节数为 4 个 。字符串“你好”的长度为 6 个字节。
在 calldata 中编码结构/元组
元组和结构的编码方式相同,因为结构被映射到 ABI 类型元组。
根据 Solidity ABI 编码规范,结构的编码是其成员的编码串联,静态类型填充为 32 字节。
假设我们有以下合约:
contract C {
struct Point {
uint256 x;
uint256 y;
}
function foo(Point memory point) external pure {
//...
}
}
foo 的函数签名将是 foo((uint256, uint256))。这与将元组作为输入的情况没有区别。如果它接受一个点(结构)的动态数组,函数签名将是 foo((uint256, uint256)[])。
如果结构的元素都是固定大小数据,则我们将整个结构编码为静态类型,不需要偏移量。但是,如果结构具有动态大小数据类型作为其字段之一,结构的编码将会改变。
例如,像下面这样的结构:
RareToken {
uint256 n;
}
send(RareToken,address)
如果我们向其传递以下参数 send( RareToken(1), 0x1b7e1b7ea98232c77f9efc75c4a7c7ea2c4d79f1)),如下图所示,将被编码为静态类型:

然而,如果结构中有动态类型,我们将不得不将结构编码为动态类型。让我们以这个为例:
RareToken {
uint256;
string;
}
send(RareToken)
如果我们向其传递以下数据 send(RareToken(50,"Eze")),则上图中显示的代码将是函数的编码。该结构包含一个动态类型和一个静态类型,如下图所示:

ABI 编码多个结构参数
现在,假设我们的函数 send()接受 3 个结构作为参数而不是一个。calldata 将如下所示:

前三个 32 字节的单词是偏移量,因为该函数接受 3 个参数作为输入,每个参数都是动态数据类型(具有动态类型字段的结构)。
左侧的 0x00、0x20、…、0x1c0 列显示了偏移量指向 calldata 中的位置。请注意,偏移量从第一个偏移量开始,而不是从偏移量所在位置开始。当我们查看嵌套动态数据时,我们将更深入探讨偏移量。
编码具有静态类型的固定大小数组
编码固定大小数组取决于数组中的内容,如果固定大小数组包含动态类型,则该固定大小数组将被编码为动态类型。如果它只包含静态类型,它将被视为静态类型并进行相应编码。这与上面部分中包含动态数据的结构的逻辑相同。
让我们从长度为 3 的仅包含静态类型的固定大小数组开始:
play(uint256[3])
并将这些数据传递给它:
play([1,2,3])
以下是数组的编码:
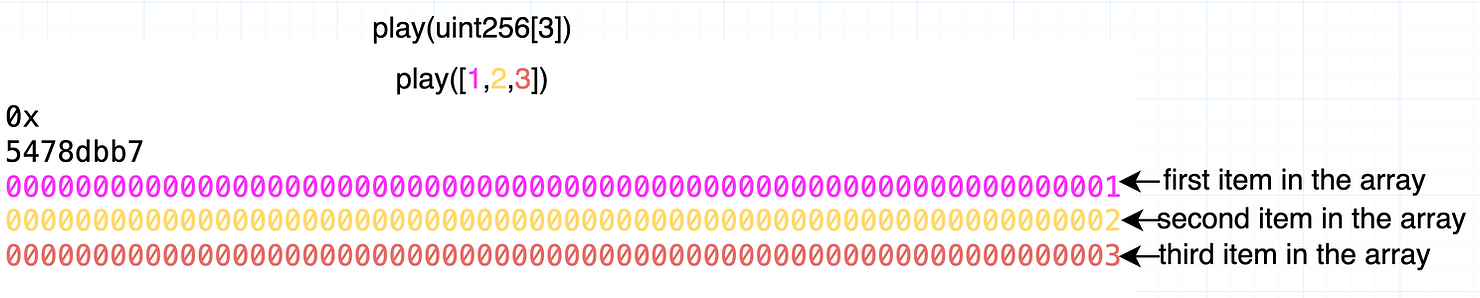
如你所见,calldata 中没有偏移量。只是数组元素的编码。
编码包含动态类型的固定大小数组
让我们考虑一个固定大小数组包含动态数据的情况。下面的函数将包含两个字符串的数组。
plays(string[2])
如果我们向其传递以下字符串:
play(["Eze","Sunday"])
当编码时,我们将得到以下 calldata:

因为固定大小数组是动态数据类型的数组,所以它的整体被编码为动态数组,唯一的区别是数组的长度没有被编码,因为函数签名将其定义为长度为 2 的固定长度数组。如果我们考虑相同的函数但具有动态长度:
plays(string[])
我们将注意到数组的长度也将被编码:

在 calldata 中处理多个数组参数和嵌套数组
在 calldata 中处理多个和嵌套数组可能有点复杂和棘手。然而,一般模式仍然相似。在本节中,我们将学习如何编码和解码嵌套数组,并更好地理解偏移量的工作方式。
我们将使用以下函数签名作为示例:
transfer(uint256[][],address[])
依旧让我们将以下数据作为函数的参数传递:
transfer([[123, 456], [789]],
[0x5B38Da6a701c568545dCfcB03FcB875f56beddC4,
0x7b38da6a701c568545dcfcb03fcb875f56bedfb3])
因此,此函数和参数的 calldata 将是下面的十六进制:
0x7a63729a000000000000000000000000000000000000000000000000000000000
0000040000000000000000000000000000000000000000000000000000000000000
0140000000000000000000000000000000000000000000000000000000000000000
2000000000000000000000000000000000000000000000000000000000000004000
000000000000000000000000000000000000000000000000000000000000a000000
0000000000000000000000000000000000000000000000000000000000200000000
0000000000000000000000000000000000000000000000000000007b00000000000
0000000000000000000000000000000000000000000000000007b00000000000000
0000000000000000000000000000000000000000000000000100000000000000000
0000000000000000000000000000000000000000000007b00000000000000000000
0000000000000000000000000000000000000000000200000000000000000000000
05b38da6a701c568545dcfcb03fcb875f56beddc40000000000000000000000005b
38da6a701c568545dcfcb03fcb875f56beddc4
我们 transfer()函数的新特性是它有两个数组,其中一个数组有两个子数组。
以下是关于嵌套和多维数组的 calldata 结构的高级构建方式:
- 偏移量:首先定义数组不同位置的偏移量。假设有多个数组参数,那么这些数组的偏移量编码将首先被定义。在我们的示例中,将有两个偏移量。
- 第一个动态类型的偏移量
- 第二个动态类型的偏移量
- 第 n 个动态类型的偏移量(如果适用)
- 接下来是第一个数组参数的长度(在我们的示例中为 2:
[[123, 456], [789]]),它位于第一个偏移量指向的位置。这是整个数组的长度。在开始处理每个数组之前,你需要先定义其长度。因此,对于每个子数组,你将定义它们的长度(稍后在 ABI 编码中)。 - 接下来,编码第一个数组参数的子数组
- 第一个子数组的偏移量(
[123, 456]) - 第二个子数组的偏移量(
[789])- 第一个子数组的长度(在我们的示例中为 2)
- 第一个子数组的第一个项(
123) - 第一个子数组的第二项(
456)
- 第一个子数组的第一个项(
- 第二个子数组的长度(在我们的示例中为 1)
- 第二个子数组的第一个项(
789)
- 第二个子数组的第一个项(
- 第一个子数组的长度(在我们的示例中为 2)
- 第一个子数组的偏移量(
- 完成第一个数组参数的所有项后,开始编码下一个数组参数
- 第二个参数数组的长度(在我们的示例中为 2 个地址)
- 第二个参数的元素(在我们的示例中为地址),如果第二个数组参数有子数组,则遵循上述描述的相同模式。
现在,让我们将示例的 calldata 可视化。
首先,将其排列在每行 32 字节(64 个字符)的格式中,除了 0x 和函数选择器之外,以便更容易阅读。函数签名和 calldata 位于图像顶部:
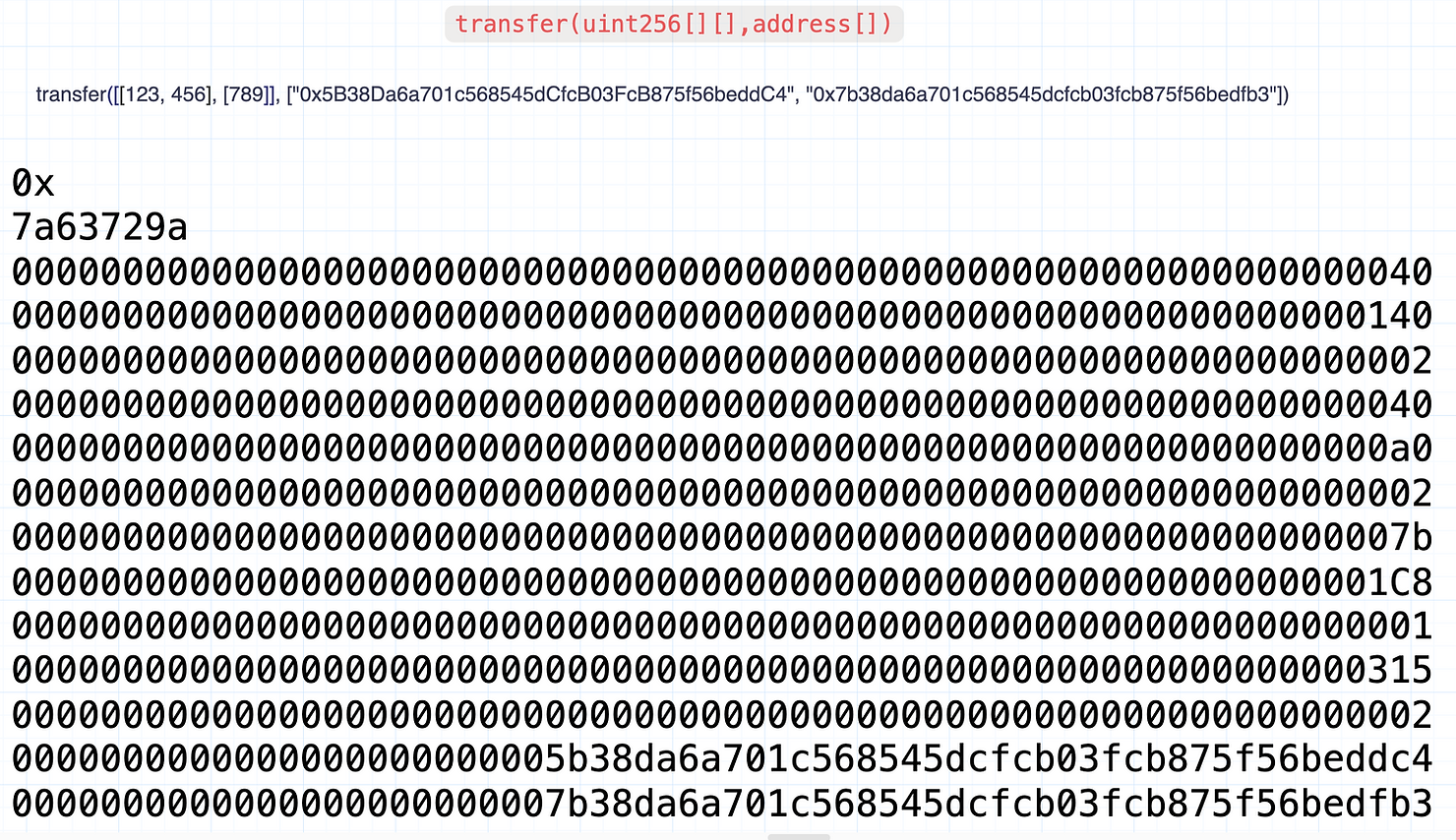
第一个数组参数的偏移量
calldata 字符串的第一个 32 字节单词是偏移量,指示第一个数组参数的数据从哪里开始。以下是可视化表示:

第二个数组参数的偏移量
下一步是为第二个数组参数编码偏移量。
正如我们在多个动态结构的示例中看到的那样,这个偏移量并不是从偏移量的位置“开始计数”,而是从第一个偏移量开始。
偏移量通常不是从它们当前位置“开始计数”,而是从描述该嵌套数据结构“级别”的第一个偏移量开始。随着我们探索子数组,这个概念将变得更加清晰。
下面的图像高亮显示了第二个偏移量指向第二个参数数据(地址数组)。请注意,偏移量指向“2”,因为第二个参数是包含两个地址的数组。

由于每个字编号为:
- 0-31
- 32-63
- 64-95
- 等
高亮显示结束的行上,320 字节(十六进制140 )最左边为 0。
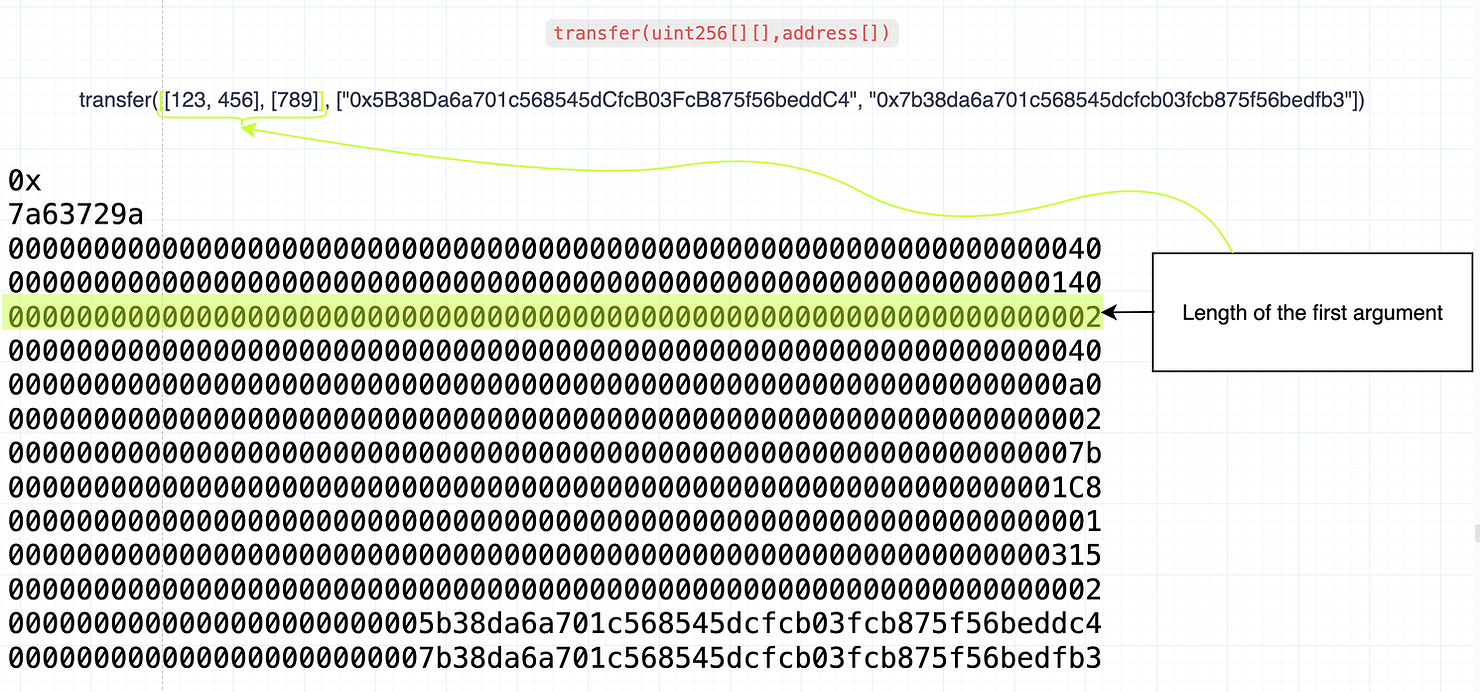
第一个数组的长度
接下来,我们需要对第一个数组的长度进行编码。子数组包括[123, 456]和[789],形成[[123, 456], [789]]。由于有两个嵌套数组,所以长度为 2。长度在 calldata 中表示如下:
第一个数组参数中子数组的偏移量
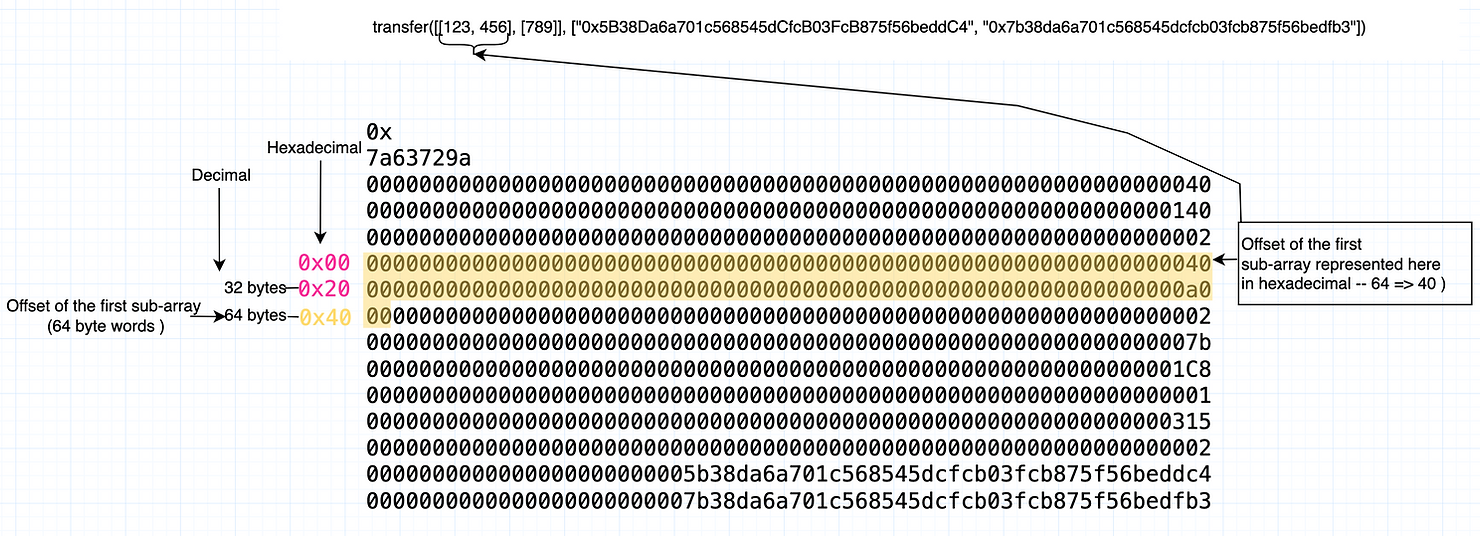
在数组的长度之后,我们有偏移量,显示了这些数组的内容存储位置。由于有两个子数组:[123, 456]和[789],所以有两个偏移量。
第一个子数组的偏移量
第一个子数组([123,456])的偏移量是右侧方框指向的 40。它们都是从定义数组长度后的第一个字开始“计数”。请注意,它指向一个包含 2 的字,因为[123,456]的长度为 2。
第二个子数组的偏移量
第二个子数组([789])的偏移量不是从 calldata 的开头开始。它位于 a0(下图中最后的红色高亮显示)处,距离第一个子数组偏移量声明的位置有 160 字节(十进制)。
请记住,偏移量通常不是从其当前位置开始“计数”,而是从描述该嵌套数据结构“级别”的第一个偏移量开始。我们现在深入了嵌套数组的一层,因此我们的第一个偏移量是下图中紫色高亮显示的 40。此偏移量不是从其自身位置开始计数:

第一个子数组的长度
接下来是第一个子数组的长度。第一个子数组包含 2 个项目,如下图中的黄色高亮显示:
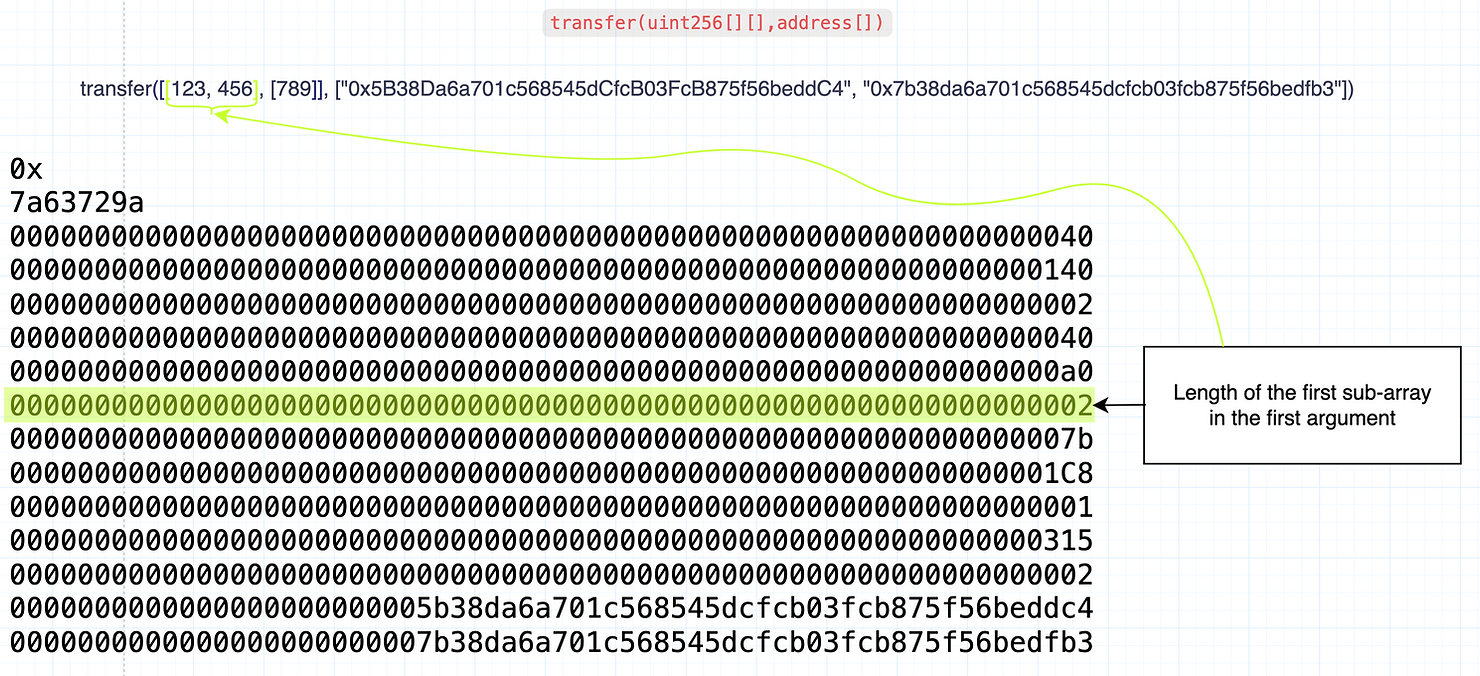
第一个子数组中的项目
接下来的两个字是第一个子数组中两个项目的十六进制表示,如下图所示:

第二个子数组的长度
然后我们转到第二个子数组的长度,它只包含一个项目:

第二个子数组中的项目
第二个数组只有一个项目,如其长度所示。我们还在接下来的 32 字节中表示数组中单个项目的值(315),这是 789 的十六进制值,如下所示。

第二个数组的长度
最后,我们要表示第二个参数的长度,即地址数组。我们有 2 个地址,因此长度为 2;这两个参数是在此图表中表示的地址。

第二个数组中的地址项目
这就是我们如何将函数 transfer([[123, 123], [123]], [0x5b38da6a701c568545dcfcb03fcb875f56beddc4,0x7b38da6a701c568545dcfcb03fcb875f56bedfb3])转换为其在 EVM 中的十六进制表示形式。

以下视频总结了本节示例中的 calldata。
https://video.wixstatic.com/video/706568_87da162471bf43169763c48738e89ee9/1080p/mp4/file.mp4
一个三重嵌套数组动画
下面是一个视频演示如何对 3D uint 数组进行 ABI 编码:f(uint[][][] memory data)。
https://video.wixstatic.com/video/706568_8fa44b44606645e29888a23532238b74/720p/mp4/file.mp4
Calldata 长度和 gas 成本
作为 Solidity 开发人员,你关注的一个关键问题是节省 gas。此外,使用 calldata 会带来额外的成本 — 每个 calldata 中的字节都会消耗 gas。
要确定调用数据的成本,我们首先需要通过计算字节数来确定 calldata 的长度。让我们以先前的 calldata 字符串作为案例研究:
0xa9059cbb0000000000000000000000003f5047bdb647dc39c88625e17bdbffee9
05a9f4400000000000000000000000000000000000000000000011c9a62d04ed0c8
0000
我们首先去掉 0x,因为它只是一个前缀,让我们知道这是与以太坊相关的十六进制。现在,我们剩下这个:
a9059cbb0000000000000000000000003f5047bdb647dc39c88625e17bdbffee905
a9f4400000000000000000000000000000000000000000000011c9a62d04ed0c800
00
这个字符串有 136 个十六进制数字,代表 68 个字节。在 calldata 字符串中,每个字节由两个字符(十六进制数字)表示。因此,我们可以通过将 136 除以 2 来计算长度 = 68。
每个非零字节在 calldata 中的成本为 16 gas,而零字节的成本为 4 gas。因此,我们需要将它们分开以继续计算。
我们有:
-
32 个非零字节 = 32 × 16 = 512 gas
-
36 个零字节 = 36 × 4 = 144 gas
Calldata 的总 gas 成本 = 512 gas + 144 gas = 656 gas。
由于零字节更便宜,一些开发人员会寻找具有多个前导零字节的地址或智能合约地址,因为这样可以减少传递该地址作为参数的 gas 成本。
结论
通过本指南,我们学习了用于函数调用的 ABI 编码的基础知识,ABI 编码函数调用的关键组件,并对 calldata 有了更详细的了解。我们还探讨了如何计算 calldata 的 gas 成本,甚至进一步探讨了更复杂的 calldata 解码和编码练习,以帮助巩固知识,希望你觉得有用。为了进一步巩固你在本文中学到的知识,我建议阅读更多关于 Ethereum ABI 编码规范的内容,并练习下一节中的问题。
祝编码愉快!
练习问题
-
调用
foo(uint16 x)的 calldata 中有多少字节? -
当传递参数为(
2, [5, 9])时,foo(uint256 x, uint256[])的 ABI 编码是什么? -
当 S 是具有字段
uint256 x; uint256[] a;的结构体 S 时,foo(S[] memory s)的 ABI 编码是什么?(感谢这个 tweet 提供灵感)。
夺旗练习
RareSkills Solidity Riddles: Forwarder DamnVulnerableDeFi: ABI Smuggling
作者
本文由 Eze Sunday 与 RareSkills 合作撰写。
本文由 AI 翻译,欢迎小伙伴们来校对。
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
深度好文