详解以太坊状态机
在以太坊黄皮书中,介绍到以太坊是一个尝试达到通用性的技术项目,可以构建任何基于交易的状态机。 这篇文章将帮你深度理解以太坊状态机。
什么是状态机
状态机的概念其实已经很老了,全称是“有限自动机”,由 George H.Mealy 在1955年提出了状态机概念,称为Mealy机。一年后的1956年,Edward F.Moore 提出了另一篇被称为Moore机的论文。后来这个概念被广泛应用于语言学、计算机科学、生物学、数学和逻辑学,甚至于哲学等各种领域。
有限自动机 (Finite Automata Machine)是计算机科学的重要基石,它在软件开发领域内通常称作有限状态机( Finite State Machine,缩写 FSM),简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
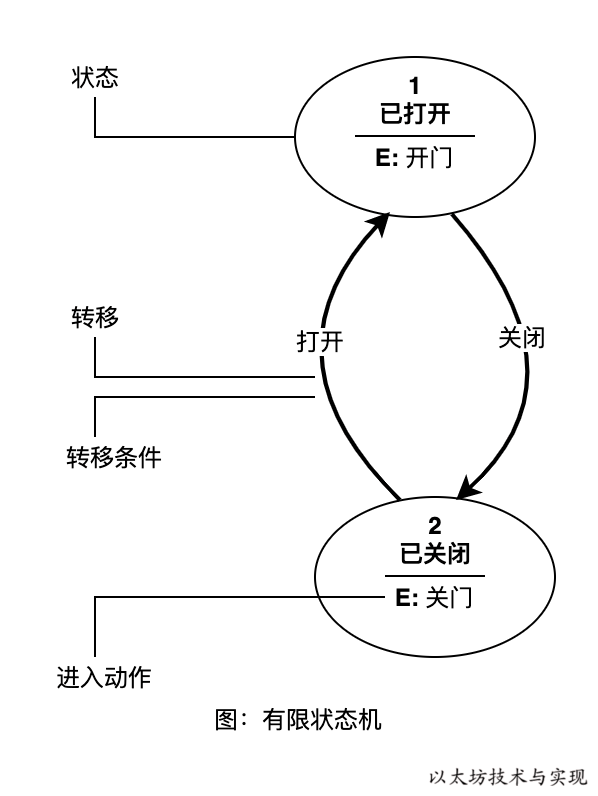
状态存储着关于过去的信息,可反映从系统开始到现在时刻的状态变化。状态即可归纳为4 个要素:
- 现态:当前所处状态。
- 条件:又称为“事件”。当一个条件被满足,将会触发一个动作,或者执行一次状态的转移。
- 动作:非必要要素,是条件满足后执行的动作。动作执行完毕后,可以迁移到新的状态,也可以保持原状态。当然满足条件后,也可以不执行任何动作,直接迁移到新状态。
- 次态:条件满足后要迁移的动作。”次态“是相对于”现态“,”次态“一旦被激活,将转移为新的”现态“。
在任意时刻,只会处于一个状态中。在某条件作用下,会从一种状态迁移到另一种状态。生活中的售货机、红绿灯、扫码机、检票口等都是有限状态机的应用。
状态机分”接受器/识别器“和”变换器“两类,其中转变器是基于给定的输入或状态生成输出。米利型有限状态机(Mealy machine)就是基于它的当前状态和输入生成输出的有限状态自动机,属于有限状态变换器。这意味着它的状态图将为每个转移包括输入和输出二者,即:
次态 = f(现态,输入)
输出 = f(现态,输入)
什么是以太坊世界状态
基于状态机模型,以太坊网络已变成一个依靠矿工维护的去中心化的大型状态机。在任意时刻,只会处于一个状态中,全世界唯一的状态。我们把这个状态机,称之为以太坊世界状态,代表着以太坊网络的全局状态。
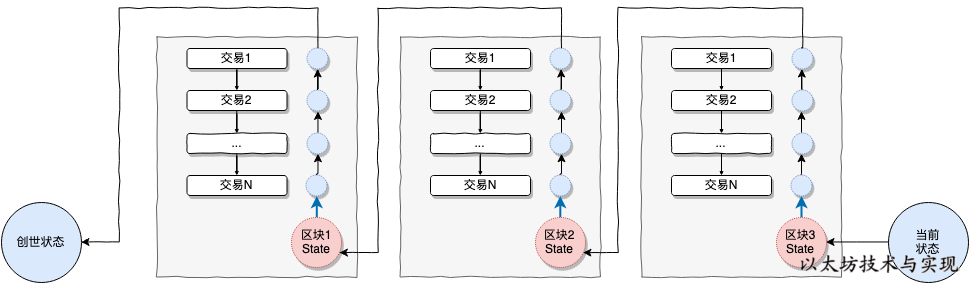
世界状态(state)由无数的账户信息组成,每个账户均存在一个唯一的账户信息。账户信息中存储着账户余额、Nonce、合约哈希、账户状态等内容,每个账户信息通过账户地址影射。 从创世状态开始,随着将交易作为输入信息,在预设协议标准(条件)下将世界态推进到下一个新的状态中。
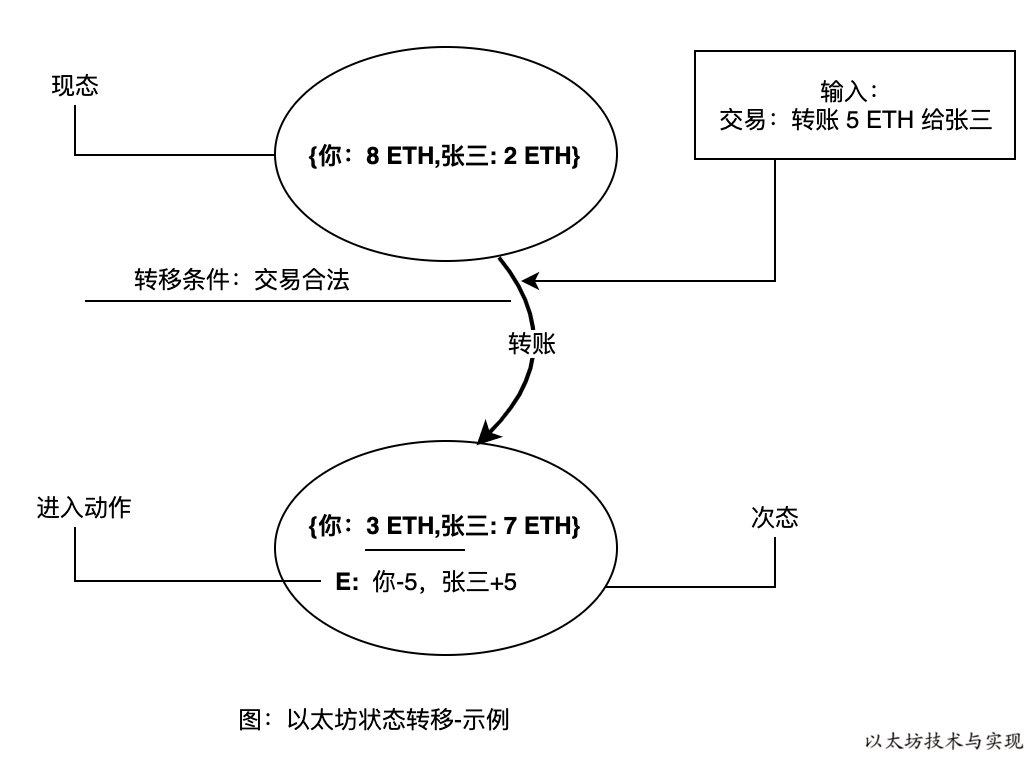
当你需要查询某账户余额时,将从从世界状态中定位到目标账户的账户状态,便可从中查询到在现态中账户余额。而当你转账 5 ETH 给张三时,则将使得状态从 {你: 8 ETH,张三:2 ETH} 转移到 {你: 3 ETH,张三:7 ETH} 状态。
交易被矿工收集到区块中的过程,就是矿工在执行状态转换的过程。即使无交易,矿工也可以直接将世界状态迁移到新状态中,比如挖出空快。
为什么有以太坊状态数据库 StateDB
即使在以太坊早期,当以太坊运行三个月后,以太坊客户端的本地文件夹存储已膨胀到惊人的 10 到40 GB。 截止到区块高度9001290,一个保留所有状态的以太坊归档节点,需要占用 216 GB 空间。如果说这些状态全部记录在区块链上,那么,这会是一个噩梦。
这会使得物联网设备、个人笔记本、手机等微设备无法使用以太坊客户端,会导致网络节点数量下降和影响用户使用。因此这些状态并非直接存储在区块链上,而是将这些状态维护在默克尔前缀树中,在区块链上仅记录对应的树 Root 值。使用简单的数据库来维护树的持久化内容,而这个用来维护映射的数据库叫做 StateDB。
世界状态中存储了哪些内容
首先,以太坊中有两种级别的状态,一个是顶级的世界状态,另一个是账户级的账户状态。账户状态中存储账户信息:
- nonce: 这个值等于由此账户发出的交易数量,或者由这个账户所创建的合约数量(当这个账户有关联代码时)。
- balance: 表示这个账户账户余额。
- storageRoot: 表示保存了账户存储内容的 MPT 树的根节点的哈希值。
- codeHash: 表示账户的 EVM 代码哈希值,当这个地址接收到一个消息调用时,这些代码会被执行; 它和其它字段不同,创建后不可更改。如果 codeHash 为空,则说明该账户是一个简单的外部账户,只存在 nonce 和 balance。

如上图所示,在以太坊中不止一颗默克尔树,所有账户状态通过以账户地址为键,维护在表示世界状态的树中。所有账户也存在一颗表示此账户的存储数据的树,此树是独立唯一的。
通过账户地址便可以从世界状态树中查找到该账户状态(如账户余额),如果是合约地址,还可以继续通过 storageRoot 从该账户存储数据树中查找对应的合约信息(如:拍卖合约中的商品信息)。
至于为什么使用默克尔树来维护状态,将在后续文章中讲解。
StateDB是如何管理状态的
从程序设计角度,StateDB 有多种用途:
- 维护账户状态到世界状态的映射。
- 支持修改、回滚、提交状态。
- 支持持久化状态到数据库中。
- 是状态进出默克尔树的媒介。
实际上 StateDB 充当状态(数据)、Trie(树)、LevelDB(存储)的协调者。可以从以下三个角度思考
如何实例化 StateDB
在对状态的任何操作前,我们要先构建一个 StateDB 来操作状态。
db: = state.NewDatabase(levelDB)
statedb, err := state.New(block.Root(), db)首先,我们要告诉 StateDB ,我们要使用哪个状态。因此需要提供 StateRoot 作为默克尔树根去构建树。StateRoot 值相当于数据版本号,根据版本号可以明确的知道要使用使用哪个版本的状态。当然,数据内容并没在树中,需要到一个数据库中读取。因此在构建 State DB 时需要提供 stateRoot 和 db 才能完成构建。
任何实现 state.Database 接口的 db 都可以使用,因为需要通过 db 来访问树和合约代码。
// core/state/database.go:42
type Database interface {
OpenTrie(root common.Hash) (Trie, error)
OpenStorageTrie(addrHash, root common.Hash) (Trie, error)
CopyTrie(Trie) Trie
ContractCode(addrHash, codeHash common.Hash) ([]byte, error)
ContractCodeSize(addrHash, codeHash common.Hash) (int, error)
// TrieDB retrieves the low level trie database used for data storage.
TrieDB() *trie.Database
}通过 db 可以访问:
- OpenTrie: 打开指定状态版本(root)的含世界状态的顶层树。
- OpenStorageTrie: 打开账户(addrHash)下指定状态版本(root)的账户数据存储树。
- CopyTrie: 深度拷贝树。
- ContractCode:获取账户(addrHash)的合约,必须和合约哈希(codeHash)匹配。
- ContractCodeSize 获取指定合约大小
- TrieDB:获得 Trie 底层的数据驱动 DB,如: levedDB 、内存数据库、远程数据库
当前有两种类型的 DB 实现了 Database 接口,轻节点使用的 odrDatabase ,和正常节点端使用的带有缓存的 cachingDB 。 因为轻节点并不存储数据,需要通过向其他节点查询来获得数据,而 odrDatabase 就是这种数据读取方式的封装。一个普通节点已内置 levelDB,为了提高读写性能,使用 cachingDB 对其进行一次封装。
至此,我们借助 StateRoot 和 db 创建了 StateDB 实例:
//core/state/statedb.go:92
func New(root common.Hash, db Database) (*StateDB, error) {
tr, err := db.OpenTrie(root)//①
if err != nil {
return nil, err
}
return &StateDB{
db: db,//②
trie: tr,
stateObjects: make(map[common.Address]*stateObject),
stateObjectsDirty: make(map[common.Address]struct{}),
logs: make(map[common.Hash][]*types.Log),
preimages: make(map[common.Hash][]byte),
journal: newJournal(),
}, nil
}在实例化 StateDB 时,需要立即打开含有世界状态的 Trie 树。如果 root 对应的树不存在,则会实例化失败①。实例化的 StateDB 中将记录多种信息。
//core/state/statedb.go:59
type StateDB struct {
db Database
trie Trie
stateObjects map[common.Address]*stateObject
stateObjectsDirty map[common.Address]struct{}
dbErr error
refund uint64
thash, bhash common.Hash
txIndex int
logs map[common.Hash][]*types.Log
logSize uint
preimages map[common.Hash][]byte
journal *journal
validRevisions []revision
nextRevisionId int
}
这里,先介绍写必要内容,其他部分将在下文中分别出场介绍。
- db: 操作状态的底层数据库,在实例化 StateDB 时指定 ②。
- trie: 世界状态所在的树实例对象,现在只有以太坊改进的默克人前缀压缩树。
- stateObjects: 已账户地址为键的账户状态对象,能够在内存中维护使用过的账户。
- stateObjectsDirty: 标记被修改过的账户。
- journal: 是修改状态的日志流水,使用此日志流水可回滚状态。
StateDB 如何读写状态
需要注意,世界态中的所有状态都是已账户为基础单位存在的。你所访问的任何数据必然属于某个账户下的状态,世界状态态仅仅是通过一颗树来建立安全的映射。因此你所访问的数据可以分为如下几种类型:
- 访问账户基础属性:Balance、Nonce、Root、CodeHash
- 读取合约账户代码
- 读取合约账户中存储内容
在代码实现中,为了便于账户隔离管理,使用不开放的 stateObject 来维护。 stateObject 注意代码如下:
type stateObject struct {
address common.Address//对应的账户地址
addrHash common.Hash // 账户地址的哈希值
data Account //账户属性
db *StateDB //底层数据库
//...
// 写缓存
trie Trie // 存储树,第一次访问时初始化
code Code // contract bytecode, which gets set when code is loaded
//...
}
type Account struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}可以看到 stateObject 中维护关于某个账户的所有信息,涉及账户地址、账户地址哈希、账户属性、底层数据库、存储树等内容。
当你访问状态时,需要指定账户地址。比如获取账户合约,合约账户代码,均是通过账户地址,获得获得对应的账户的 stateObject。因此,当你访问某账户余额时,需要从世界状态树 Trie 中读取账户状态。
// core/state/statedb.go:408
func (self *StateDB) getStateObject(addr common.Address) (stateObject *stateObject) {
if obj := self.stateObjects[addr]; obj != nil {//①
if obj.deleted {
return nil
}
return obj
}
enc, err := self.trie.TryGet(addr[:])//②
if len(enc) == 0 {
self.setError(err)
return nil
}
var data Account
if err := rlp.DecodeBytes(enc, &data); err != nil {//③
log.Error("Failed to decode state object", "addr", addr, "err", err)
return nil
}
obj := newObject(self, addr, data)//④
self.setStateObject(obj)
return obj
}state.getStateObject(addr)方法,将返回指定账户的 StateObject,不存在时 nil。
state的 stateObject Map 中记录这从实例化 State 到当下,所有访问过的账户的 StateObject。 因此,获取 StateObject 时先从 map 缓存中检查是否已打开①,如果存在则返回。 如果是第一次使用,则以账户地址为 key 从树中查找读取账户状态数据②。读取到的数据,是被 RLP 序列化过的,因此,在读取到数据后,还需要进行反序列化③。为了降低 IO 和在内存中维护可能被修改的 Account 信息,会将其组装成 StateObjec ④存储在 State 实例中。
//core/state/state_object.go:108
func newObject(db *StateDB, address common.Address, data Account) *stateObject {
if data.Balance == nil {
data.Balance = new(big.Int)
}
if data.CodeHash == nil {
data.CodeHash = emptyCodeHash
}
return &stateObject{
db: db,
address: address,
addrHash: crypto.Keccak256Hash(address[:]),//⑤
data: data,
originStorage: make(Storage),
dirtyStorage: make(Storage),
}
}newObject 就是将对 Account 的操作进行辅助,其中记录了账户地址、地址哈希⑤等内容,最终你读写状态都经过 stateObject 完成。
以太坊读取账户余额
最常见的操作是读取账户余额,下面是一段读取账户 addr1 的余额的操作:
db: = state.NewDatabase(levelDB)
block = blockchain.CurrentBlock()
statedb, err := state.New(block.Root(), db)
balance := statedb.GetBalance(addr1)
//core/state/statedb.go:207
func (self *StateDB) GetBalance(addr common.Address) *big.Int {
stateObject := self.getStateObject(addr)//①
if stateObject != nil {
return stateObject.Balance()//③
}
return common.Big0//②
}balance 可能是 0,也可能是 1000,反应的是账户在当前区块中的状态。 在 GetBalance 中,首先需要获取 addr1 的 stateObject①。 当 addr1 在世界状态树中不存在时, stateObject 则为空,那么余额也就是 0 ②。 如果存在,则可以 stateObject 中读取余额③。
//core/state/state_object.go:390
func (self *stateObject) Balance() *big.Int {
return self.data.Balance
}在 stateObject 中是直接读取的 Account.Balance。
以太坊转移以太币
在以太坊中,张三转账给李四 100 ETH,实际是在当前状态中,完成两个状态修改操作:
- 张三的账户余额减少 100 ETH。
- 李四的账户余额增肌 100 ETH。
下面是对应的代码实现:
db: = state.NewDatabase(levelDB)
block = blockchain.CurrentBlock()
statedb, err := state.New(block.Root(), db)
statedb.SubBalance(张三,100 ETH)
statedb.AddBalance(李四,100 ETH)非常简洁的在两个账户间完成了100 ETH 转移。我们聚焦在 SubBalance和AddBalance方法中。
//core/state/statedb.go:346
func (self *StateDB) AddBalance(addr common.Address, amount *big.Int) {
stateObject := self.GetOrNewStateObject(addr)
if stateObject != nil {
stateObject.AddBalance(amount)
}
}
func (self *StateDB) SubBalance(addr common.Address, amount *big.Int) {
stateObject := self.GetOrNewStateObject(addr)
if stateObject != nil {
stateObject.SubBalance(amount)
}
}
func (c *stateObject) AddBalance(amount *big.Int) {
if amount.Sign() == 0 {//①
if c.empty() {
c.touch()//③
}
return
}
c.SetBalance(new(big.Int).Add(c.Balance(), amount))//④
}
func (c *stateObject) SubBalance(amount *big.Int) {
if amount.Sign() == 0 {
return
}
c.SetBalance(new(big.Int).Sub(c.Balance(), amount))
}
func (self *stateObject) SetBalance(amount *big.Int) {
self.db.journal.append(balanceChange{//⑤
account: &self.address,
prev: new(big.Int).Set(self.data.Balance),
})
self.setBalance(amount)
}
func (self *stateObject) setBalance(amount *big.Int) {
self.data.Balance = amount
}从上面代码可以看到,state 的SubBalance和AddBalance方法一一对应指定账户的 stateObject 的SubBalance和AddBalance方法。先看 stateObject 的 AddBalance 方法,有一个特殊的 amount 检查。 如果 amount 等于 0,则不会修改什么。但如果是这个空账户,则进行 touch ③。一旦账户被 touched ,则会在 Commit 时删除。否则,在账户中重置账户余额④。在重置时,需要增加一条变更流水到 StateDB 的 journal 中 ⑤。 添加流水的目的是方便回滚。
同理,stateObject 的 SubBalance方法,逻辑基本一致,添加变更流水,重置余额到减去 amount 后的余额。
以太坊如何存储和读取合约账户信息
合约账户,区别于外部账号的最大行为特征是拥有自己的存储树。获取合约中存储数据入口如下:
// core/state/statedb.go:282
func (self *StateDB) GetState(addr common.Address, hash common.Hash) common.Hash {
stateObject := self.getStateObject(addr)
if stateObject != nil {
return stateObject.GetState(self.db, hash)
}
return common.Hash{}
}同样是从 stateObject 中获取数据。需要注意的是合约中存储数据的 Key 并不是一个哈希值,仅仅是 32 字节的 bytes。 不能被参数类型 common.Hash 所迷惑,同样存储的返回值也是一个 32 bytes。 关于合约的 Key 是如何确定的,详见详解Solidity合约数据存储布局。
// core/state/state_object.go:152
func (c *stateObject) getTrie(db Database) Trie {
if c.trie == nil {
var err error
c.trie, err = db.OpenStorageTrie(c.addrHash, c.data.Root)//①
if err != nil {
c.trie, _ = db.OpenStorageTrie(c.addrHash, common.Hash{})//②
c.setError(fmt.Errorf("can't create storage trie: %v", err))
}
}
return c.trie
}
func (self *stateObject) GetState(db Database, key common.Hash) common.Hash {
value, dirty := self.dirtyStorage[key]//③
if dirty {
return value
}
return self.GetCommittedState(db, key)
}
func (self *stateObject) GetCommittedState(db Database, key common.Hash) common.Hash {
value, cached := self.originStorage[key]//⑤
if cached {
return value
}
if metrics.EnabledExpensive {
defer func(start time.Time) { self.db.StorageReads += time.Since(start) }(time.Now())
}
enc, err := self.getTrie(db).TryGet(key[:])//⑥
if err != nil {
self.setError(err)
return common.Hash{}
}
if len(enc) > 0 {
_, content, _, err := rlp.Split(enc)//⑦
if err != nil {
self.setError(err)
}
value.SetBytes(content)//⑨
}
self.originStorage[key] = value//④
return value
}
func (self *stateObject) SetState(db Database, key, value common.Hash) {
prev := self.GetState(db, key)
if prev == value {
return
}
self.db.journal.append(storageChange{
account: &self.address,
key: key,
prevalue: prev,
})
self.setState(key, value)
}
func (self *stateObject) setState(key, value common.Hash) {
self.dirtyStorage[key] = value
}
func (self *stateObject) updateTrie(db Database) Trie {
if metrics.EnabledExpensive {
defer func(start time.Time) { self.db.StorageUpdates += time.Since(start) }(time.Now())
}
tr := self.getTrie(db)
for key, value := range self.dirtyStorage {
delete(self.dirtyStorage, key)
if value == self.originStorage[key] {
continue
}
self.originStorage[key] = value
if (value == common.Hash{}) {
self.setError(tr.TryDelete(key[:]))
continue
}
v, _ := rlp.EncodeToBytes(bytes.TrimLeft(value[:], "\x00"))//⑧
self.setError(tr.TryUpdate(key[:], v))
}
return tr
}上面代码是关于合约存储的读写实现,因为合约存储的数据均在该合约的存储树中,所以每次读写前均需要getTrie。 该方法是,保证树的懒加载。只有在第一次使用时,才加载树。这棵树和顶层的世界状态树结构完成一直,只是存储的内容不同而已。 利用此合约地址和存储树 root 加载树,加载不一定成功①。比如像一个不存在的合约读取存储数据,因此在加载失败时,将使用空 root 来初始化出一颗空树,保证在 stateObject 中,trie 不会为nil ②。
调用 GetState 读取合约存储数据时,将检查是否内存中维护的数据草稿集 dirtyStorage 中是否存在③。 使用草稿的原因是,所有对 State 的修改,并不是直接修改底层数据库。而是,暂时记录在内存中,只要在最终需要提交到数据库时,才从尝试 tryUpdate。如果未改动,则从树中读取数据。 为了避免重复从树中读取,提高效率。所有获取过的数据,将会缓存在 originStorage 中④。 下次读取时,优先从内存中读取⑤。否则,尝试从树中读取数据⑥。如果数据存在,则还需要 RLP 解码⑦。
需要解码的原因是,在将存储树更新到数据库中(updateTrie)时,有对数据进行 RLP 序列化 ⑧。序列化的好处是可以压缩数据。 在区块链中,存储永远是昂贵的。每节省 1 字节,积少成多,都是有意义的。 同时在序列化前还有清理数据前面的 0 值。 比如,如果数据是一个用户年龄,值 20,是会用 32 字节填充的。在写入 State 时,将为 [0,0,0,......,2],前面有 30 个 0 字节,这些 0 值会浪费存储空间,所以存储前将清理左侧的 0 值,只存储 [2]。 不用担心取值问题,因为读取出 [2]后,也将被写入 32 字节中 ⑨。
StateDB 如何完成持久化
在区块中,将交易作为输入条件,来根据一系列动作修改状态。 在完成区块挖矿前,只是获得在内存中的状态树的 Root 值。 StateDB 可视为一个内存数据库,状态数据先在内存数据库中完成修改,所有关于状态的计算都在内存中完成。 在将区块持久化时完成有内存到数据库的更新存储,此更新属于增量更新,仅仅修改涉及到被修改部分。
// core/state/statedb.go:680
func (s *StateDB) Commit(deleteEmptyObjects bool) (root common.Hash, err error) {
defer s.clearJournalAndRefund()
for addr := range s.journal.dirties {//①⑧⑨⑩
s.stateObjectsDirty[addr] = struct{}{}
}
for addr, stateObject := range s.stateObjects {//②
_, isDirty := s.stateObjectsDirty[addr]
switch {
case stateObject.suicided || (isDirty && deleteEmptyObjects && stateObject.empty()):
//③
s.deleteStateObject(stateObject)
case isDirty:
if stateObject.code != nil && stateObject.dirtyCode {//④
s.db.TrieDB().InsertBlob(common.BytesToHash(stateObject.CodeHash()), stateObject.code)
stateObject.dirtyCode = false
}
if err := stateObject.CommitTrie(s.db); err != nil {//⑤
return common.Hash{}, err
}
s.updateStateObject(stateObject)//⑥
}
delete(s.stateObjectsDirty, addr)
}
//...
root, err = s.trie.Commit(func(leaf []byte, parent common.Hash) error {//⑦
var account Account
if err := rlp.DecodeBytes(leaf, &account); err != nil {
return nil
}
if account.Root != emptyRoot {
s.db.TrieDB().Reference(account.Root, parent)
}
code := common.BytesToHash(account.CodeHash)
if code != emptyCode {
s.db.TrieDB().Reference(code, parent)
}
return nil
})
return root, err
}因为在修改某账户信息是,将会记录变更流水(journal),因此在提交保存修改时只需要将在流水中存在的记录作为修改集①。 所有访问过的账户信息,均被记录在 stateObjects 中,只需要遍历此集合 ② 便可以提交所有修改。
当合约账户被销毁或者外部账户余额为 0 时可以从树中移除该账户,避免空账户影响树操作性能 ③。 这里仅仅是从树中移除,并不能直接从持久层抹除。因为旧 State 依然依赖此账户,一旦缺失将因为数据不完整而导致 OpenTrie 无法加载。同时,可方便其他节点同步 State 时不会缺失数据。
另外,如果集合中的账户有变更(isDirty),则需要提交此账户。如果该账户是刚部署的新合约(dirtyCode)④,则需要根据合约代码 HASH 作为键,存储对应的合约字节码。同时还将该账户专属的存储树提交⑤,而账户属性也许有被修改,因此需要将此信息也更新到账户树中⑥。
处理完每个需要提交的账户内容外,最后需要将账户树提交⑦。在提交过程中涉及账户内容作为叶子节点,在发送变动时,将更新账户节点和父节点的关系。记录关系的原因是用于在树的缓存使用,仅可能快速定位所需数据位置和快速释放,以便降低 GC 压力。
在持久化 StateDB 时只对内存中存在的账户进行更新。
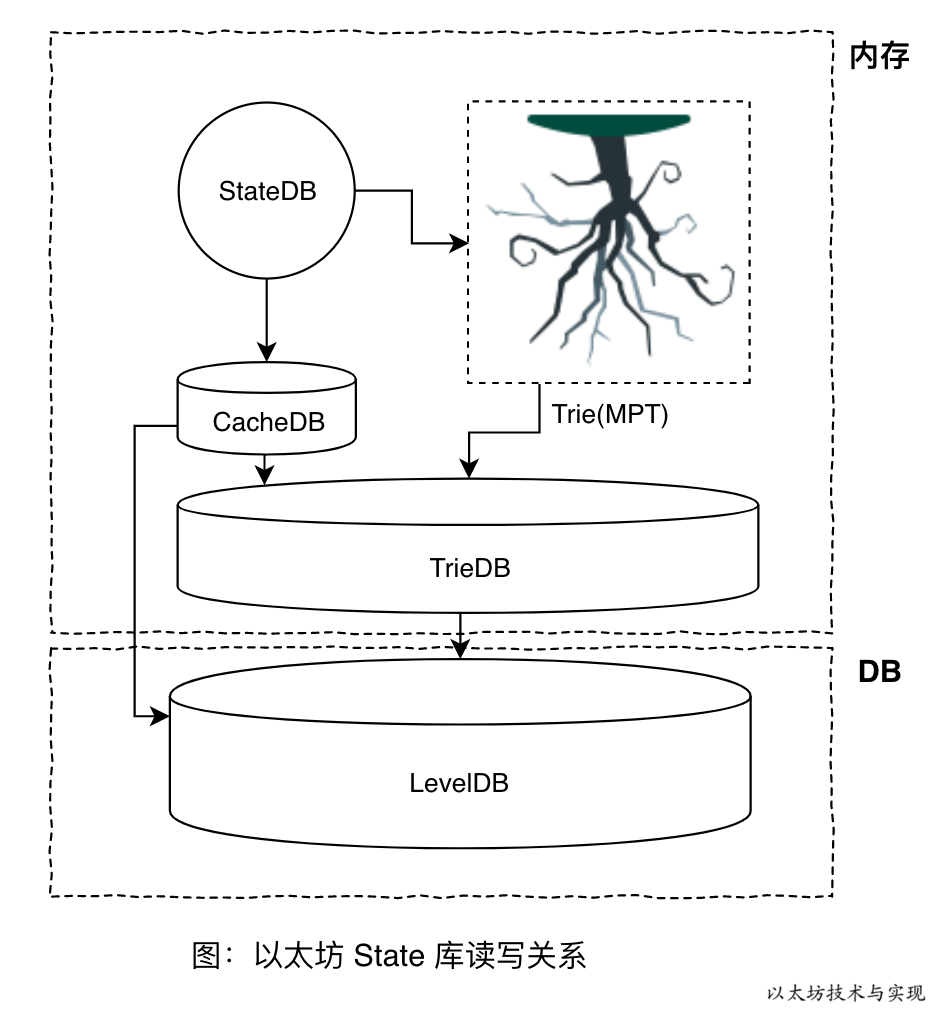
如上图所示,上半部分均属于内存操作,仅仅在 stateDB.Commit() 时才将状态通过树提交到 leveldb 中。
StateDB 如何回滚状态
在将交易打包到区块中,当其中一笔交易执行失败时,此交易将不会包含到此区块中,同时需要回退状态到执行此交易前的状态。 下面代码是挖矿模块处理交易的逻辑代码。
snap := w.current.state.Snapshot()
receipt, _, err := core.ApplyTransaction(w.config, w.chain, &coinbase, w.current.gasPool, w.current.state, w.current.header, tx, &w.current.header.GasUsed, *w.chain.GetVMConfig())
if err != nil {
w.current.state.RevertToSnapshot(snap)
return nil, err
}在执行ApplyTransaction前,先对 State 进行快照,如果执行交易失败,则将恢复状态(RevertToSnapshot)。 从这里可以看出,StateDB 实现回退的两个关键是:创建快照(Snapshot)、恢复到指定快照(RevertToSnapshot)。
如前面所说,对 State 的任何修改都将产生修改日志。形同于关系数据库的 log 文件,对数据库的操作都将产生日志流水。 可以根据日志文件恢复数据库。StateDB 也采用同样的机制,
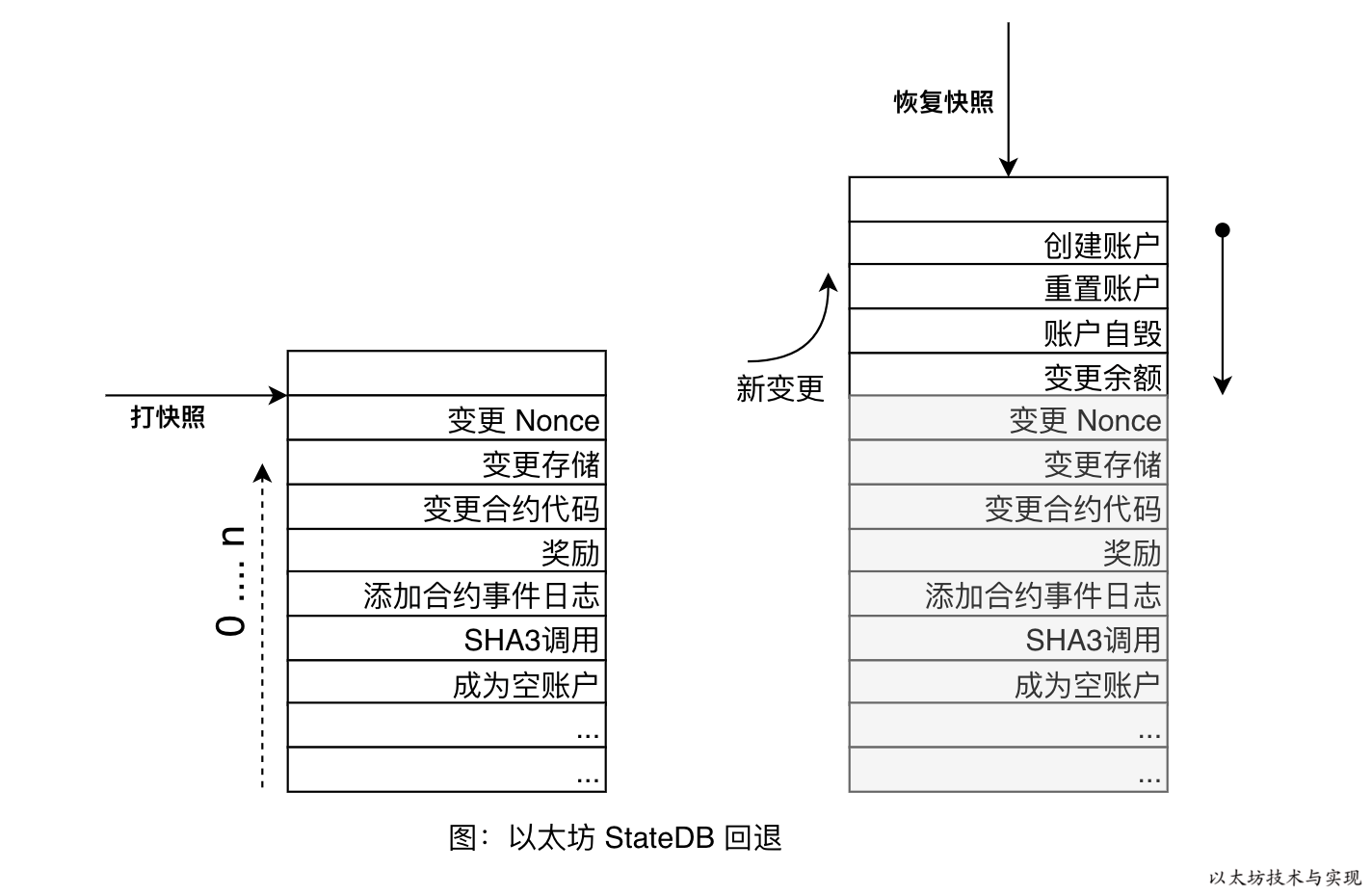
如上图所示,在执行Snapshot时,将会获得一个状态版本号(snap),版本号对应记录该版本状态的变更日志索引位置。当需要恢复状态到此版本时,只需要版本的日志索引位置以上的所有变更日志从最新到最旧顺序依次回退即可。
从上图也可看到,变更日志有多重类型,每种类型均提供了回退(revert)方法。比如变更余额的流水中将会记录变更前的值,回退时只需要将该账户的余额重置到变更前的值即可。
StateDB 如何校验数据
在轻节点中,因为本地并不存储状态数据。但有必须校验某数据的合法性,这依赖于默克尔树的校验。 StateDB 仅提供数据的读取实现。因此,关于校验数据的合法性将在另外一篇文章中介绍。