Layer2 Calldata Gas优化
- RareSkills
- 发布于 2024-02-01 10:46
- 阅读 1995
这篇文章深入探讨了以太坊层2(L2)中calldata优化的重要性及其实现方法。文章解释了与calldata相关的gas成本,并在不同L2架构间的差异,提供了代码示例和具体技术细节,涵盖了如何通过技术手段减少calldata的尺寸,进而优化交易成本。
2024年中期更新 截至Dencun升级,calldata优化的影响不再那么显著,因为大多数L2上的交易存储在blobs中,而不是calldata。我们保留这篇文章以供历史参考。
在L2上开发应用程序时,大多数的gas费用来自calldata。因此,L2的gas优化主要强调减少此费用。
本文探讨了calldata优化的工作原理,提供了一些示例,并讨论了链特定的技术。
先决条件
作者
本文由Rati Montreewat(Linkedin,Twitter)撰写,他是一位区块链工程师,也是L2 calldata优化工具Solid Grinder的作者,并且是RareSkills Solidity培训营的校友。
Calldata的成本
以太坊对每个字节的calldata收费,对零字节收费Gtxdatazero,对非零字节收费Gtxdatanonzero,分别为4 gas和16 gas,如黄皮书所示:

Layer 2将calldata发送到Layer 1,因此必须支付Layer 1的calldata费用。此外,Layer 2还增加了“安全费”。
从数学上看,总的Layer 2交易gas可以定义为:
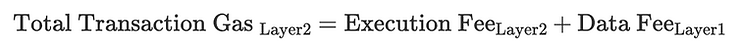
L1 gas通常占总gas费用的90%到99%(L1 + L2 gas)。值得注意的是,这些数据 heavily 依赖于L1的网络拥堵。
不同L2链的不同规则
虽然大多数L2的gas成本确实来自数据/安全部分,但在不同的L2上,相同的智能合约可能会产生不同的gas结果。这是因为不同的L2链(如Arbitrum/Optimism/Starknet等)使用不同的规则和公式来计算他们将向用户收取多少calldata费用。因此,如果一种gas优化方法在一个L2链上产生最佳效果,并不意味着它在其他L2链上也会产生相同的最优结果。
此外,随着客户端和以太坊生态系统的成熟,这些规则将不断演变。举例来说,EIP4844(又名 Proto-Danksharding)会使gasLayer2的数据/安全部分变得更便宜,而Layer2的执行部分会变得更为重要,从而可能改变Layer2执行费用的计算方式,以反映适当的激励和经济模式。
以下是不同L2的交易gas如何计算的:
Arbitrum
以下是Arbitrum用来计算交易gas费用的公式:

ExecutionFee 的计算方式与在EVM链上计算交易的方式相似,除了它受到PriceFloor的限制。
Arbitrum试图在将calldata发布到L1之前使用 Brotli算法 来压缩calldata。
Optimism
Optimism在calldata收费模型上稍有不同:
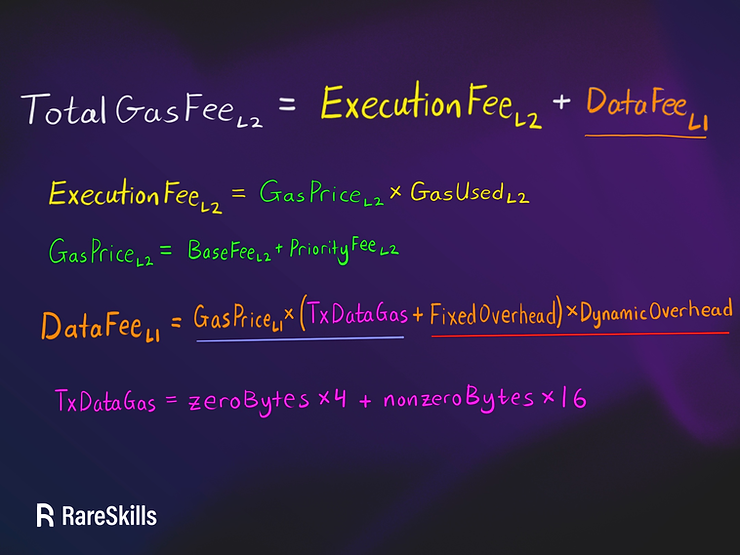
你可以将蓝色下划线的术语视为以太坊的收费,而红色下划线的术语则视为Optimism的利润空间。
优化Calldata的方法
确定calldata组件所需的gas量的关键因素是calldata大小,而这由ABI编码规则指定。具体来说,ABI(应用程序二进制接口)根据 Solidity的官方文档 说明。
获取calldata格式化直观理解的最好方法是通过示例。
首先,让我们安装cast,一个与EVM交互的工具包,并使用Foundryup作为工具链安装器:
curl -L https://foundry.paradigm.xyz | bash
foundryup
然后我们使用以下cast命令展示如何使用参数对Solidity编码函数:
cast calldata "addLiquidity(address,address,uint256,uint256,uint256,uint256,address,uint256)" 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD 1200000000000000000000 2500000000000000000000 1000000000000000000000 2000000000000000000000 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD 100
结果是520个十六进制字节,总计520/2 = 260字节:
0xe8e33700000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead0000000000000000000000000000000000000000000000410d586a20a4c000000000000000000000000000000000000000000000000000878678326eac90000000000000000000000000000000000000000000000000003635c9adc5dea0000000000000000000000000000000000000000000000000006c6b935b8bbd400000000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead0000000000000000000000000000000000000000000000000000000000000064
如你所见,calldata的前四个字节是该函数签名(addLiquidity(address,..))的Keccak256哈希的前四个字节。在 函数选择器 之后,接下来一组32字节是函数参数。如果参数短于32字节,则它默认“左填充”额外的零,以适应32字节。
例如,calldata可以分成以下几部分:
- 0xe8e33700 作为 函数选择器
- 000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead 作为 地址 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD
- 000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead 作为 地址 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD
- 0000000000000000000000000000000000000000000000410d586a20a4c00000 作为 uint256 1200000000000000000000
- 0000000000000000000000000000000000000000000000878678326eac900000 作为 uint256 2500000000000000000000
- 00000000000000000000000000000000000000000000003635c9adc5dea00000 作为 uint256 1000000000000000000000
- 00000000000000000000000000000000000000000000006c6b935b8bbd400000 作为 uint256 2000000000000000000000
- 000000000000000000000000deaddeaddeaddeaddeaddeaddeaddeaddeaddead 作为 地址 0xdeaDDeADDEaDdeaDdEAddEADDEAdDeadDEADDEaD
- 0000000000000000000000000000000000000000000000000000000000000064 作为 uint256 64
有许多技巧可以在不丢失信息的情况下减少calldata的总字节数。该概念是尽量以紧凑的方式编码calldata,以尽量少地使用calldata字节。然后,编码的数据可以在后面解码成可用格式。
解压缩calldata的开销通常与通过压缩calldata节省的gas相比可以忽略不计。
这里讨论的技巧不会在每种可能的情况下都有效。节省的字节数量 heavily 依赖于智能合约的具体业务逻辑。
绕过最常用的字节
如果我们知道函数签名或函数参数的确切值,我们可以将它们硬编码为常量,以便在需要时使用。由于我们有有限数量的函数,例如,我们不需要完整的四个字节来标识它们。
我们可以设计一组使用工厂模式的智能合约,使工厂以每种方法和参数的组合部署一个唯一的合约。以下提供了一些gas优化的示例:
函数签名
我们可以通过在合约中只使用fallback函数节省4字节的calldata:
fallback() external payable {
// 业务逻辑
}
函数参数
我们可以通过从函数中删除一个参数来节省32字节的calldata
例如,ERC20合约的 地址 可以硬编码为常量,从而可以从函数中删除。这可能会节省总共20个非零字节(与地址大小相同)和12个零字节(填充字节以满32字节)。
address public constant USDC = <address>;
function TEST() external {
// 使用USDC的业务逻辑
}
如果你对此感到好奇,并希望了解更多实践中的实现,可以查看以下具有有趣设计的项目:
使用地址表缓存地址
AddressTable 可以视为一个缓存数据库,用于存储先前注册的地址及其id。
例如,用户首先注册地址,然后该地址自动映射为id。以后,用户可以只使用id,而不是完整地址。这将使calldata的大小从20字节减少到只有几个字节。
在幕后,表只是一个存储地址和索引之间映射的智能合约。它还具有使用相关映射id查找注册地址的功能。
这个设计被Arbitrum采用并实现。接口如下:
interface ArbAddressTable {
/**
* @notice 检查地址是否存在于地址表中
* @param addr 需要检查是否存在于表中的地址
* @return 如果地址在表中,则返回true
*/
function addressExists(address addr) external view returns (bool);
/**
* @notice 压缩地址并返回结果
* @param addr 需要压缩的地址
* @return 压缩后的地址字节
*/
function compress(address addr) external returns (bytes memory);
/**
* @notice 从字节缓冲区读取压缩后的地址
* @param buf 包含地址的字节缓冲区
* @param offset 目标地址的偏移量
* @return 返回的地址和更新后的缓冲区偏移量(如果缓冲区过短,则回退)
*/
function decompress(bytes calldata buf, uint256 offset)
external
view
returns (address, uint256);
/**
* @param addr 要查找的地址
* @return 地址表中地址的索引(如果地址不在表中,则回退)
*/
function lookup(address addr) external view returns (uint256);
/**
* @param index 查找地址的索引
* @return 地址表中给定索引的地址(如果索引超出表的末端,则回退)
*/
function lookupIndex(uint256 index) external view returns (address);
/**
* @notice 在地址表中注册地址
* @param addr 要注册的地址
* @return 地址的索引(存在的索引或新创建的索引,如果未注册)
*/
function register(address addr) external returns (uint256);
/**
* @return 地址表的大小(= 第一个未使用的索引)
*/
function size() external view returns (uint256);
}
但是,实施是一个用Go编写的预编译合约。你可以在OffchainLabs的 git仓库中查看。它意在成为一个单一的通用地址表,任何人都可以注册并使用它。
如果你想看看另一个用Solidity编写的实现及其应用,这个Solid Grinder的 git仓库 包含对 UniswapV2 的修改版本,其中采用了其自己的 地址表。
数据序列化
数据序列化 的工作原理是将参数序列化和反序列化为适当的类型和适当的数据大小。
例如,如果我们选择通过使用uint40(5字节)作为参数而不是uint256来减少calldata,则calldata应在正确的偏移量被切分,结果(去掉零字节之后)即可在下一步中正确使用。
让我们再次查看Solid Grinder的实现 此处。这个合约是一个很好的起点:
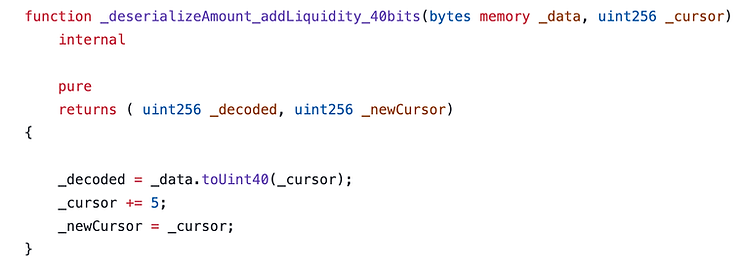
这个解码器函数是特定于Uniswapv2的,它是通过查看原始未优化的函数与Solid Grinder的CLI生成的。在这种情况下,它是UniswapV2Router02。基本上,你可以在这里实验并跟随详细步骤 快速开始。
权衡
上述calldata gas优化技巧最明显的权衡是可读性和复杂性。例如,
在智能合约中添加编码和解码逻辑并明确去除函数的参数不仅会使直接通过 Etherscan 与合约交互的用户感到困惑,也会使开发人员在你的修改智能合约上构建时变得更困难,从而降低组成性,而这恰恰是无许可世界的独特优势。
最后思考
如上所述,calldata gas优化是一个新话题,但随着Layer2/汇总技术的日益普及,这将变得更加相关。此外,目前尚无明确的标准和实践。本文仅提供和提议可能的设计决策和方法。对此范式的重新发掘仍然有更多的空间。
参考文献
- <https://docs.arbitrum.io/arbos/l1-pricing#l1-fee-collection>
- <https://docs.arbitrum.io/stylus/reference/opcode-hostio-pricing#opcode-costs>
- <https://github.com/OffchainLabs/arbitrum-tutorials/tree/master/packages/address-table>
- <https://community.optimism.io/docs/developers/build/transaction-fees/>
- <https://scopelift.co/blog/calldata-optimizooooors>
- <https://github.com/clabby/op-kompressor>
-
<https://github.com/Ratimon/solid-grinder>
最初发布于2024年1月30日
- 原文链接: rareskills.io/post/l2-ca...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





