原生 Rollup:现状与未来
- l2beat
- 发布于 2025-05-20 17:41
- 阅读 1571
本文深入探讨了原生 Rollup 的概念,这是一种旨在重新定义以太坊扩展方式的技术,它将 Rollup 的自主性与以太坊基础层的深度集成相结合。文章详细介绍了原生 Rollup 的工作原理,通过 EXECUTE 预编译实现 EVM 等效性,并讨论了其在以太坊 Rollup 中心路线图中的作用。同时,文章也分析了原生 Rollup 面临的挑战,包括桥接、排序规则、费用和互操作性等方面的问题。
Conor McMenamin 和 Luca Donno 联合撰写,Nethermind x L2BEAT 合作出品。本文中的观点和梗图仅代表作者个人观点。

概述
以太坊的可扩展性路线图多年来发生了显著的变化——从 Layer 1 分片到以 Rollup 为中心的愿景,现在更朝着一个更具雄心的方向发展:原生 Rollup(Native Rollup)。原生 Rollup 承诺将 Rollup 的自主性与以太坊基础层的深度集成相结合,旨在重新定义“扩展以太坊”的含义,同时保留其中立性、模块化和信任最小化的核心价值观。
本文对原生 Rollup 进行了技术性的探讨:它们是什么,它们如何重塑以太坊的执行环境,以及仍然存在的一些未决问题。
用我们自己的话说,我们将在以下章节中介绍原生 Rollup。
- 什么是原生 Rollup。
- 其背后的愿景。
- 未决问题。
什么是原生 Rollup?
原生 Rollup 是指将其状态转换函数替换为 EXECUTE 的 Rollup,EXECUTE 是一个预编译函数,旨在与 EVM 等效,并作为以太坊 EVM 的一部分进行维护和升级。EVM 套娃!
最初提出的* EXECUTE 预编译函数接受以下输入:pre_state_root、post_state_root、trace 和 gas_used。当且仅当满足以下条件时,它才返回 true:
trace是一个格式良好的执行跟踪(例如,L2 交易列表和相应的状态访问证明)- 从
pre_state_root开始的trace的无状态执行在post_state_root结束 trace的无状态执行完全消耗gas_usedgas
关于运行预编译函数:
- 验证者可以简单地重新执行
trace以强制执行EXECUTE调用的正确性。在计算和验证者要求方面,这与通过交易执行手动更新状态相当。 - 验证者验证一个 SNARK,证明执行有效。请注意,即使
EXECUTE由 SNARK 强制执行,也不需要在共识中明确规定任何显式的证明系统或电路,因为预编译函数不接受任何显式的证明作为输入。相反,每个 staking 运营者都可以自由选择他们最喜欢的 zkEL 验证客户端,类似于今天主观选择 EL 客户端的方式。最近的争论主要集中在是否 Enshrine 证明系统。
除了 EXECUTE 预编译函数之外,Rollup 还需要一些额外的特定于 Rollup 的功能,特别是用于处理桥接、排序规则、费用和 Token 治理等(我们在“待解决的挑战”部分讨论这些问题)。
* 我们预计在 EXECUTE 的确切细节最终确定之前,还会看到进一步的迭代。
愿景(即,原生 Rollup 在以太坊路线图中处于什么位置?)
早在 2020 年,Vitalik 就发布了以 Rollup 为中心的路线图,提议将重点转移到支持 Rollup 作为以太坊扩展的“中短期”解决方案,同时暗示它们很可能也会成为长期解决方案,放弃了扩展 L1 执行的“eth2”努力。引用该博客文章:
这意味着对 eth2 采取“ phase 1.5 and done ”方法,其中基础层收缩并专注于做好几件事——即共识和数据可用性。
在该愿景中,鼓励所有用户和项目迁移到 L2,而 L1 只专注于支持它们。这种方法的缺点是,Rollup 不得不在信任最小化但不可变,或引入一种治理形式以实现功能升级之间做出选择。即使是与 EVM 等效的 Rollup 也无法自动地与 L1 一起升级,这会影响其安全性和中立性,即使存在退出窗口也是如此。在这种情况下,EXECUTE 预编译函数和原生 Rollup 的引入成为打破这种权衡并获得 EVM 环境的无治理升级的显而易见方式。
尽管如此,以太坊的研究重点最近已转移回重新优先考虑 L1 执行扩展。因此,有些人一直在质疑是否首先需要与 EVM 等效的 Rollup,包括原生 Rollup,或者以 Rollup 为中心的路线图从一开始就是一个错误。
首先要问的自然问题是,为什么会发生这种转变?
适度扩展 L1 以支持 Rollup 在通过强制交易实现的抗审查性、互操作性、大规模退出和证明验证等方面具有明显的优势。
但是,经过 5 年的时间,没有 Rollup 能够提供足够的安全性或中立性,可以与 L1 提供的安全性或中立性相媲美。出于类似的原因,过去有些人一直倡导由 EF 驱动的或公共利益 Rollup,它们没有 Token,并且计划在启动时达到 Stage 2。虽然 Rollup 不应受到指责(……或者至少并非全部都应受到指责),因为必要的技术确实很难构建,但与其他 L1 的竞争给寻找比完全依赖外部 Rollup 团队的更快、更安全的解决方案带来了更大的压力。
第二个问题是,L1 是否可以有效地扩展到与通过 Rollup 扩展所能实现的水平相媲美的水平?
一般来说,扩展是通过利用原始执行和验证之间的不对称性来实现的。Rollup 使用 ZK 进行执行,使用 DAS 进行数据来实现这一点。没有理由相信这些改进无法直接在 L1 上实施,并且已经在 进行中:今天,完整节点通过下载所有必要的交易 calldata 并重新执行它们来验证 L1 链,将来有一天,它们将验证 ZK 证明并采样 blob。
Rollup 的附加价值
如果 L1 可以扩展到数千 TPS,为什么我们需要 Rollup?我们可以确定三个原因:
- 扩展以太坊的需求比 ZK 技术成熟的时间要早得多,当时 L1 只能支持 12-13 TPS 的真实活动。为了避免 Enshrine 不成熟的证明系统,以太坊采取了一种“自由市场”方法,允许 Rollup 进行试验、开发技术,并在某些证明系统被证明为次优时承担风险。考虑到自 Rollup 采用 ZK 技术以来,ZK 技术中出现的 Bug 数量和发展速度,这可以说是非常成功的。虽然仍然有些实验性,但某些方法(例如使用 zk-VM 而不是 zk-EVM)似乎正在巩固,并且可能很快就能用于 L1。
- 从 10K 到 10M TPS 的唯一方法是通过异步执行分片。这可以通过 L1 上 Enshrine 的执行分片来实现,类似于 NEAR 的做法,或者通过 Rollup 来实现。
- Rollup 是 L1 的自定义扩展/试验场。Arbitrum、Starknet、Fuel Ignition 或 Eclipse 等项目集成了与以太坊不同的 VM,它们都具有自己的优势,这对于以太坊来说在短期和中期内,甚至可能永远都无法采用。
那么,在这种未来中,L1 的作用可能是充当将这些不同的 Rollup 社区联系在一起的中立的抗审查粘合剂。
原生 Rollup 的附加价值……
关于 Rollup 的一般信息已经足够了,那原生 Rollup 呢?
…… 与 L1 和现有 Rollup 生态系统相比:L1 安全性
以太坊 L1 已经通过其现有的 Rollup 生态系统实现了显著的扩展。原生 Rollup 及其随附的技术堆栈有望增加一些关键优势,这些优势对某些 Rollup 用户和部署者具有吸引力。主要的附加价值是与 EVM 等效的 EXECUTE 预编译函数,旨在消除 Rollup 创建、维护和升级自定义 VM 的需求。除了一些特定于 Rollup 的逻辑之外,EXECUTE 将取代今天以太坊上 Rollup 中存在的自定义状态转换函数。Rollup 部署者和用户都可以直接利用以太坊的安全性,并知道 EXECUTE 预编译函数中的任何 Bug 都会像 EVM 本身的 Bug 一样得到解决,通过硬分叉。与 L1 一起分叉可以将 Rollup 风险隔离为智能合约风险,从而大大减少 Rollup 的攻击和防御面。这种共享 EVM 的次要影响包括提高用户对 Rollup 的信心、更轻松的 Rollup 部署以及共享的开发者资源等等。
…… 与 L1 执行分片相比:自主性
一些读者可能不知道,但前一个要点中列出的好处与如果以太坊上的 Rollup 被执行分片取代,几乎是相同的。执行分片将底层区块链的状态拆分为能够独立处理交易的并行环境。从一个分片移动到另一个分片可以通过协调层来完成,该协调层类似于今天的 L1 执行层。由于执行分片今天已经在以太坊之外实现,因此存在一种可行的途径来调整该技术以在以太坊本身中使用。
使分片与 Rollup 分开的是 Rollup 与生成执行分片相比所实现的自主性。这在关于普通 Rollup 与执行分片的一对帖子 中得到了很好的讨论。其中的结论是,Rollup 作为自主中心,可以保留决定诸如排序、桥接、强制包含、治理、Gas Token 等事物的权利。除了保留这些权利之外,允许 Rollup 拥有的文化和技术独立性使 Rollup 成为 L1 的理想试验场。* 这是所有 Rollup 都可以带来的好处。
待解决的挑战
哦:原生 Rollup 是一种潮流。
为了使原生 Rollup 成为现实,仍然存在一些很大的未决问题。在本节中,我们将看一下原生 Rollup 揭示的一些有趣的技术挑战和研究领域。

Rollup 特定功能
- 桥接/交易如何在 Rollup 上排序:
– 本地原生 Rollup 交易: 我们预计这将由 L1 上的收件箱合约处理,即对于原生 Rollup 与当前 Rollup 相比,这不应发生变化。
– L1 存款/信令 & 强制包含交易: 这些是 EVM 当前未处理的特定于 Rollup 的功能。例如,op-geth(Optimism VM)需要 geth(EVM)的一个分支来处理存款。 关于此特定功能的详细信息不足,但到目前为止,所有讨论都集中在向 EVM 添加 DERIVE 预编译函数/功能。这在原始帖子中有所暗示,“可以部署最小的原生和基于的 Rollup……具有简单的派生函数……用于特殊处理排序、强制包含或治理”。缺乏关于 DERIVE 的具体细节,但目前的提议要求 Rollup 在执行之前/期间调用此 DERIVE 函数,从而将来自 L1 的信号加载并执行到 Rollup 状态中,例如将资产桥接到原生 Rollup 中。从这个意义上讲,DERIVE 的可证明调用将成为原生 Rollup 的跟踪生成的一部分。这里一个有趣的设计选择/长期愿景问题是:
— Rollup 需要调用 DERIVE,但 L1 不需要。在这种设计中,L1 会将 Rollup 视为不同的执行环境,反之亦然。
— L1 和 Rollup 在执行交易时都需要调用 DERIVE 预编译函数,其中 L1 状态被视为 Rollup(可能禁用某些特定于 Rollup 的功能)。
- 谁可以将交易发送到收件箱: 原生 Rollup 已被承诺具有完全可定制的常规排序(规则、选择)和强制包含。这似乎是 Rollup 的
DERIVE函数的一个_经典_用例。 - 如何证明状态转换: 原生 Rollup 的最初提议是使每个
EXECUTE调用都附带一个链下证明,该证明将作为 L1 有效性检查的一部分进行验证。为了实现这一点,需要以 DA 的形式提供执行跟踪,而不是交易数据。这是一个实验性的概念,它破坏了与原生 Validium 或状态差异 Rollup 的兼容性,但从理论上讲,此最初提议的好处是:
– 无需在链上重新执行证明验证(成本高昂)。
– 允许每个验证者运行自己的证明验证器,就像我们今天拥有执行客户端多样性一样。这避免了 Enshrine 特定证明系统,这是一个可信的中立主义者的梦想。
– 无需分叉即可修复证明系统 Bug。
- 谁证明状态转换: 在原生 Rollup 的最终游戏中,最终确定一个区块需要证明 L1 插槽中的每个执行。最初的提议依赖于以下假设:所有这些证明都可以由一个利他主义的证明者在一个插槽中提供,从而使系统在“利他主义的少数证明者假设”下是安全的。为了限制此利他主义的英雄证明者的证明要求,提出了一个
EXECUTE_CUMULATIVE_GAS_LIMIT,它限制了给定插槽中可以消耗的总EXECUTEGas。 - 会有特定于 Rollup 的费用吗? 从理论上讲,对于同一组交易,每个 Rollup 应消耗相同数量的 L1 资源。但是,每个 Rollup 都可以通过
DERIVE和/或智能合约对交易和/或交易批次应用独特的预处理/后处理,具体取决于 Rollup 的用例,例如一个 Rollup 可能只接受加密交易,另一个 Rollup 可以根据权重函数(例如优先级 Gas 排序)强制执行交易排序,而其他 Rollup 可以强制执行某些交易的批量执行。
跟踪的优点和局限性
最初的原生 Rollup 提议 采用带有状态访问证明的完整跟踪作为原生 Rollup 的 DA 形式,因为它们允许无状态重新执行和无状态 ZK 证明生成。通过不 Enshrine 任何实现,L1 节点可以决定运行哪个 ZK 验证器,包括同一证明系统的不同实现,或完全不同的证明系统。因此,必须通过 p2p 网络生成和传播多个证明,因此证明生成的任何摩擦都可能会阻碍证明的多样性。通过跟踪,各种利他主义(或间接激励)的无状态证明者可以为每个 EXECUTE 调用生成和共享证明。
另一方面,带有状态访问证明的跟踪比仅交易数据大得多,而交易数据是当今许多 Rollup 使用的 DA 形式。由于每个节点都必须下载整个跟踪,因此这种 DA 形式与采样(例如 PeerDAS)不兼容,从而阻止 EXECUTE 预编译函数利用 blob。因此,原生 Rollup 的交易费用可能大大超过非原生 Rollup 的交易费用,但无风险执行溢价仍然可以吸引规避风险的用户。另一方面,如果重新执行变为可选,则可以将跟踪发布到 blob,其中只有那些决定下载所有 blob 的节点才能支持它。然后,需要外部无状态证明者才能属于这一类别。
如果放弃完全重新执行支持,则可以采取进一步的步骤来用交易数据替换跟踪,从而可以精确地维护今天的 DA 成本。由于现在链上没有跟踪,因此有状态节点将需要直接生成证明,或者生成和共享跟踪,以供希望无状态重新执行的无状态证明者或客户端使用,这些跟踪可以按需发送。我们假设只有无状态才有可能实现的利他主义证明者将依赖于此类节点的可用性,从而可能会损害多样性。
一个更激进的替代方案是用任意数据承诺替换跟踪,从而允许支持原生 Alt-DA L2 和原生状态差异 L2。在 Alt-DA 下,由于不保证数据可用性,因此重新执行(可以将其视为最后的后备方案)变得不可能,并且第三方证明者的无许可生成跟踪也变得不可能。然后,证明生成和多样性将完全依赖于交易发送者。或者,要求链上证明将自动强制执行证明多样性,但代价是 Enshrine 某些证明系统。
互操作性
互操作性有不同的层次。同步执行与同步可组合性这两个层次说明了原生 Rollup 的优点和挑战。
同步可执行: 可以在同一时间/按顺序执行交易。
原生 Rollup、当前 Rollup 和 L1 都提供了跨其各自状态即时原子执行交易的能力。了解作用于多个状态的一组交易的执行需要跨这些状态进行严格的排序器协调,当所有状态的排序器共享时,这种协调最为严格。基于和共享的排序协议承诺跨其排序的所有状态提供同步交易执行。原生 Rollup 可以通过可定制的排序规则选择与 L1 和/或任意数量的其他原生 Rollup 同步执行。
同步可组合(跨多个执行环境): 能够跨多个执行环境执行交易/交易批次,就像它们是同一执行环境一样。
由于 L1 是一个单一的执行环境,因此在 L1 上同步组合交易非常简单。当我们想要跨两个或多个 Rollup 同步组合交易时,事情变得有趣和相当困难。
要实现同步可组合性,除了同步执行之外,还需要一些额外的技巧,因为同步执行仅涉及执行时序,而不涉及正在执行的状态。对于同步可组合性,我们需要排序器协调和一些时髦的原子终结技术。概括地说,这项技术涉及:
- 能够最终确定尝试同步组合的所有状态或不最终确定任何状态。AggLayer 尝试通过一个协调层(一个元 Rollup)来实现这一点,该协调层的执行决定了选择加入 AggLayer 的 Rollup 的最终性。目前,这涉及 Rollup 根据其本地最终性规则临时最终确定其状态,而真正的最终性需要所有 AggLayer Rollup 都被临时最终确定且不冲突;换句话说,跨 Rollup 记帐已以有效方式完成。有关更详细和最新的说明,请参阅 AggLayer 文档。请注意,AggLayer-Rollup 互操作性不需要共享排序器,但同步可组合性需要。
- 用于组合 Rollup 的数据结构,以向协调层发出信号,说明从其他组合 Rollup 的有效输出和预期输入。通过从一组临时最终确定的 Rollup 收集信号,协调层可以相对简单地验证所有输出和输入是否在所有 Rollup 中匹配。如果输出和输入匹配,则新的 Rollup 状态将变为最终状态。否则,所有状态更新都将回滚。
在同步可组合性范例中,协调层将完全控制如何在它们各自的桥接器中管理组合 Rollup 的资产。尽管这给控制桥接器的智能合约的安全性带来了沉重的负担,但原生 Rollup 的承诺是,组合和协调 Rollup 状态的执行将变得像 L1 执行一样可靠。
风险隔离: 由于原生 Rollup 的 EVM 等效性,原生 Rollup 的执行保证与以太坊本身一样强大。这会将同步可组合性的主要风险隔离到桥接器安全性和排序器选择。
- 桥接器风险: 这本身将被降低为审核智能合约,从理论上讲,Rollup 部署者和用户有能力理解这种受控风险。
- 排序器选择风险: 恶意共享排序器可以向组合 Rollup 发出不匹配的输入和输出信号,这将导致组合 Rollup 的状态回滚。Rollup 可以通过多种方式处理此问题,包括回退到默认排序器或禁用可组合性。
吞吐量与可组合性
当将每个 Rollup 或执行分片视为异步执行环境时,可以使用 Rollup 或执行分片将以太坊从 10k TPS L1 扩展到 >1M TPS 生态系统。引入 Rollup/分片之间的可组合性时,此吞吐量会下降。实际上,可能会下降很多。
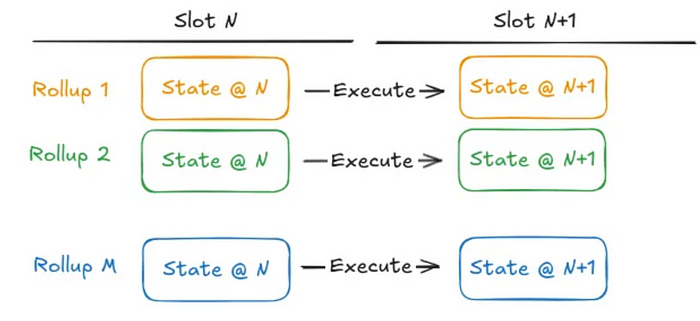
异步执行 Rollup 可以在没有任何其他 Rollup 状态依赖项的情况下执行。
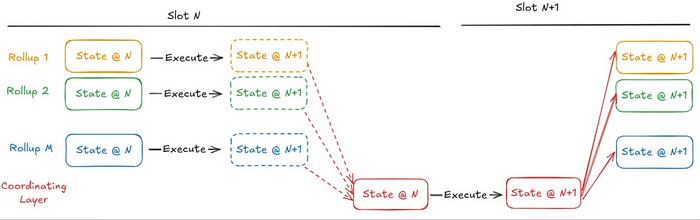
同步可组合 Rollup 必须依赖于协调层的执行才能最终确定其状态。这是同步可组合性被利用时,减少系统组合吞吐量的几个相互依赖因素之一。
考虑一个具有 2 个原生 Rollup 的 L1,所有 Rollup 都能处理 10k TPS,从而使以太坊生态系统的最大吞吐量约为 30k TPS。
如果这两个 Rollup 互操作以创建临时联合状态,则每个复合交易都在两种状态下执行,这意味着如果发生任何互操作,则这两个 Rollup 的累积吞吐量必须小于 20k TPS。乐观地讲,这些 Rollup 的吞吐量可能能够保持接近 20k - # 复合交易。但是,鉴于需要在 L1 上进行一些协调才能最终确定组合 Rollup 的全有或全无联合状态,因此 L1 上也会引入一些开销。
在最坏的情况下,由于两个 Rollup 之间存在许多交易依赖项,因此有必要对联合状态进行单线程处理,因此这些 Rollup 的累积吞吐量会降至 10k TPS。再加上通过协调原生 Rollup 的可组合性(向后运行原生 Rollup 的临时最终确定状态)而在 L1 上引入的开销,以太坊生态系统的总吞吐量将降至小于 20k TPS。
一般来说,对于每对同步组合的执行环境,如果所有交易都具有可组合性依赖项,则此联合执行环境的吞吐量将回落到最低吞吐量执行环境的数量级。
当同步组合一组执行环境时,确切的交易集将决定联合系统的吞吐量,但可以肯定地说(你可以对此下注),执行环境之间的每个复合交易都会降低共享系统的吞吐量。但至关重要的是,Rollup 和执行分片的可组合性只需要按需执行,这与始终可组合(因此吞吐量受到限制)的 L1 不同。
对于 Rollup 来说,吞吐量和可组合性之间的反比关系提供了一个有趣的研究领域,既可以了解确切的权衡,也可以有效地实现吞吐量与可组合性均衡点(例如通过市场)的发现。
- 原文链接: medium.com/l2beat/native...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





